jurnal fix
TRANSCRIPT

Automatic Speech Recognition (ASR) dan
Text To Speech (TTS) pada Perangkat Mobile
Lia Saputri Program Studi Ilmu Komputer
Fakultas Pendidikan Matematika dan Ilmu Pengetahuan Alam
Universitas Pendidikan Indonesia
Jl. Dr. Setiabudhi No. 229Bandung
Abstrak— Bahasa Inggris adalah bahasa wajib saat
kita sedang berbicara dengan orang asing atau saat
kita sedang berada di luar negeri. Untuk itu kita
dituntut untuk dapat memahami bahasa
Internasional tersebut. Cara yang paling sering
digunakan adalah menggunakan kamus atau
menggunakan jasa penerjemah. Namun hal itu
seringkali merepotkan. Penulisan jurnal ini
dilakukan untuk mengkaji sebuah aplikasi yaitu
kamus suara yang merupakan aplikasi mobile yang
dikembangkan pada smartphone berbasis Android 2.3
keatas dengan menggunakan teknologi pemrosesan
bahasa yaitu Automatic Speech Recognition (ASR)
dan Text-to-Speech (TTS). Pembahasan dalam jurnal
ini diharapkan dapat membantu dalam pembuatan
aplikasi kamus suara yang dapat digunakan sebagai
alat bantu dalam mempelajari bahasa Inggris.
Kata kunci— Aplikasi Mobile, kamus suara,
Automatic Speech Recognation (ASR), Text-to-Speech
(TTS)
I. PENDAHULUAN
Pada era globalisasi, saat ini sudah tidak aneh
lagi jika kita melihat orang asing di sekitar kita.
Bepergian ke luar negeri pun sudah bukan hal yang
sulit dilakukan saat ini. Tetapi saat kita berada di
luar negeri, kita sering kesulitan dalam memahami
bahasa yang mereka gunakan. Begitu juga jika kita
kebetulan bertemu dengan orang asing yang sedang
menanyakan arah kepada kita, kita terkadang
kebingungan untuk menjelaskan kepada mereka,
karena bahasa yang mereka gunakan berbeda
dengan bahasa kita. Untuk menyelesaikan
persolaan ini, hal yang paling sering dilakukan
adalah membawa kamus, namun hal itu sering kali
merepotkan karena kita harus mencari arti perkata.
Atau cara lain yang sering kali para wisatawan
lakukan adalah menggunakan jasa penerjemah.
Untuk menyewa penerjemah sudah pasti membuat
biaya liburan kita bertambah. Selain masalah
tersebut, masalah yang sering dihadapi adalah
masalah spelling atau pelafalan. Karena penulisan
dan pelafalan dalam bahasa Inggris seringkali
berbeda.
Berdasarkan hal tersebut, maka dalam jurnal ini
dilakukan pembahasan tentang Kamus Suara
menggunakan Automatic Speech Recognition
(ASR) dan Text to Speech (TTS) pada Smartphone
berbasis Android. Kamus suara ini diharapkan
dapat digunakan sebagai alat bantu dalam
pembelajaran bahasa Inggris. Selain untuk
pembelajaran, kamus suara ini dapat berperan
sebagai penerjemah saat kita bepergian ke luar
negeri ataupun saat kita berbicara dengan orang
asing. Karena sifatnya yang mobile, kamus suara
ini sangat praktis digunakan dimana saja dan kapan
saja.
II. METODOLOGI PENELITIAN
Penulisan jurnal ini dilakukan dengan
pendekatan studi literatur yang berkenaan tentang
permasalahan secara umum tentang Automatic
Speech Recognition (ASR) dan Text To Speech
(TTS).
III. BATASAN MASALAH
Penelitian ini dilakukan dalam batasan sebagai
berikut : 1. Penulisan jurnal ini hanya pada tahap
pembahasan ASR dan TTS dalam
Kamus Suara. Tidak sampai pada tahap
pengembangan.
2. Bahasa target adalah Bahasa Inggris
untuk ASR dan Bahasa Indonesia untuk
TTS.
IV. PEMBAHASAN
A. (Marietha, dkk. 2012) SMSsuara adalah sebuah aplikasi SMS (Short
Message Service) yang menggunakan teknologi
sistem pengucapan, seperti Automatic Speech
Recognition (ASR) dan Text to Speech (TTS),
untuk meminimalkan penggunaan keypad
handphone.
Aplikasi SMSsuara ditujukan kepada
pengemudi dan lansia. Pengguna dapat
mengirimkan pesan teks dengan suara. Jika selama
ini kita mengirim SMS yang berupa teks, maka
dengan SMSsuara ini kita dapat mengirimkan SMS
dengan perintah suara. Sedangkan untuk si
penerima pesan, akan menerima pesan yang berupa
suara juga. Bahasa yang digunakan dalam ASR dan
TTS pada SMSsuara ini adalah bahasa Indonesia.
Penelitian ini dibagi menjadi dua tahap, yaitu
pelatihan ASR dan implementasi sistem SMSsuara.
Dalam ASR Training ada beberapa tahap yang
harus dilakukan yaitu :
1. Menyiapkan daftar kalimat
2. Membangun kamus/kosakata
3. Menciptakan model bahasa
4. Menciptakan model akustik
Dalam pengimplementasian SMSsuara
tahap yang harus dilakukan, yaitu :
1. Implementasi dan konfigurasi perekam
ASR
2. Implementasi TTS
3. Penanganan perintah suara
4. Penanganan ejaan kata
5. Penanganan penyingkatan kata pada
SMS
Dari hasil pengujian ASR dan SMSsuara
application dapat disimpulkan bahwa aplikasi
SMSsuara berhasil di integrasikan dengan ASR
untuk menulis SMS. Aplikasi SMSsuara juga
berhasil diintegrasikan dengan TTS unuk
membaca SMS. Selain itu aplikasi ini juga
berhasil menangani masukan berupa perintah
suara untuk menunjang kinerja aplikasi
SMSsuara ini.
B. (Violante, dkk., 2013)
Penelitian ini menyajikan sebuah metode untuk
meningkatkan kealamian dari speech-synthesizer
berbasis corpus dengan menghilangkan puncak
pitch suara pada speech recognition. Corpus yang
digunakan adalah SECYT corpus, buatan
Laboratorio de Investigaciones Sensoriales
(Universidad de Buenos Aires).
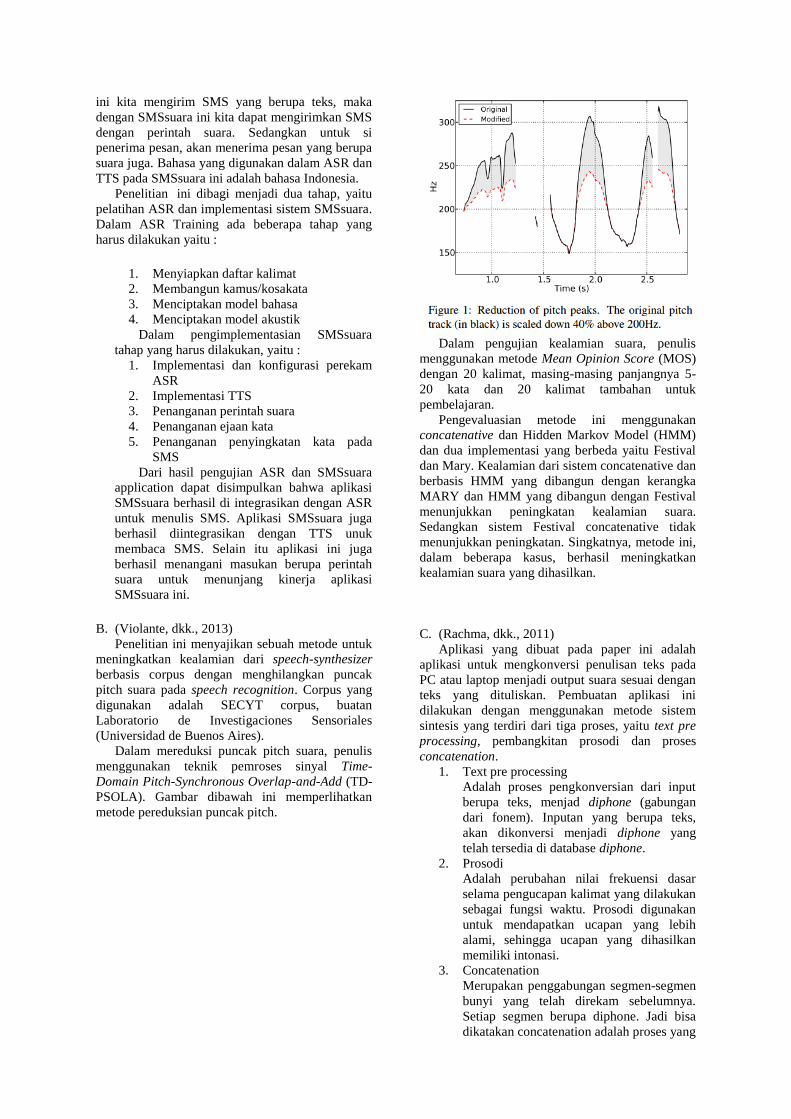
Dalam mereduksi puncak pitch suara, penulis
menggunakan teknik pemroses sinyal Time-
Domain Pitch-Synchronous Overlap-and-Add (TD-
PSOLA). Gambar dibawah ini memperlihatkan
metode pereduksian puncak pitch.
Dalam pengujian kealamian suara, penulis
menggunakan metode Mean Opinion Score (MOS)
dengan 20 kalimat, masing-masing panjangnya 5-
20 kata dan 20 kalimat tambahan untuk
pembelajaran.
Pengevaluasian metode ini menggunakan
concatenative dan Hidden Markov Model (HMM)
dan dua implementasi yang berbeda yaitu Festival
dan Mary. Kealamian dari sistem concatenative dan
berbasis HMM yang dibangun dengan kerangka
MARY dan HMM yang dibangun dengan Festival
menunjukkan peningkatan kealamian suara.
Sedangkan sistem Festival concatenative tidak
menunjukkan peningkatan. Singkatnya, metode ini,
dalam beberapa kasus, berhasil meningkatkan
kealamian suara yang dihasilkan.
C. (Rachma, dkk., 2011)
Aplikasi yang dibuat pada paper ini adalah
aplikasi untuk mengkonversi penulisan teks pada
PC atau laptop menjadi output suara sesuai dengan
teks yang dituliskan. Pembuatan aplikasi ini
dilakukan dengan menggunakan metode sistem
sintesis yang terdiri dari tiga proses, yaitu text pre
processing, pembangkitan prosodi dan proses
concatenation.
1. Text pre processing
Adalah proses pengkonversian dari input
berupa teks, menjad diphone (gabungan
dari fonem). Inputan yang berupa teks,
akan dikonversi menjadi diphone yang
telah tersedia di database diphone.
2. Prosodi
Adalah perubahan nilai frekuensi dasar
selama pengucapan kalimat yang dilakukan
sebagai fungsi waktu. Prosodi digunakan
untuk mendapatkan ucapan yang lebih
alami, sehingga ucapan yang dihasilkan
memiliki intonasi.
3. Concatenation
Merupakan penggabungan segmen-segmen
bunyi yang telah direkam sebelumnya.
Setiap segmen berupa diphone. Jadi bisa
dikatakan concatenation adalah proses yang

menggabungkan ekedua proses diatas
untuk mendapatkan output suara sesuai
yang dituliskan pada teks inputan.
Inputan yang bisa dimasukkan adalah kata,
kalimat atau angka. Inputan tersebut masuk ke
dalam blok text pre processing. Kata atau kalimat
tersebut lalu dikonversikan kedalam bentuk
diphone. Jika masukan berupa angka, maka sistem
akan mengkonversikan angka menjadi string. Dari
bentuk string inilah, angka kemudian dikonversikan
ke dalam bentuk diphone. Setelah inputan menjadi
diphone, maka selanjutnya adalah proses
penggabungan diphone-diphone tersebut
(concatenation). Maka inputan kita sebelumnya,
akan berubah menjadi suara.
V. KESIMPULAN
Automatic speech recognition adalah sebuah
proses algoritma untuk mengkonversi inputan
berupa suara menjadi urutan kata yang disesuaikan
dengan inputannya. Sedangkan Text to speech
adalah sebuah sistem yang dapat mengkonversi
masukan berupa teks menjadi suara. Dalam TTS
terdapat dua sub proses dalam pengkonversiannya,
yaitu teks ke fonem dan fonem ke suara.
Aplikasi Kamus Suara adalah sebuah kamus
yang dapat menerima masukan berupa perintah
suara. Selain dalam bentuk tulisan, hasil
terjemahannya juga dalam bentuk suara. Kamus
suara ini menggunakan Automatic Speech
Recognition (ASR) untuk menerima masukan
berupa suara. Lalu suara akan di konversi ke text.
Setelah inputan menjadi text, maka kata tersebut
akan dibandingkan dengan text yang tersedia pada
database sistem. Setelah terdapat kecocokan antara
kata yang dicari dan kata yang tersedia, maka
selanjutnya adalah proses text to speech (TTS)
untuk menterjemahkan hasil yang berupa teks ke
suara. Dan hasil akhirnya user akan mendengarkan
hasil terjemahan kata yang diinginkan dalam
bahasa Inggris.
DAFTAR PUSTAKA
[1] Marietha, Sonya, dkk. (2012). SMSsuara
Application with Automatic Speech Recognition
and Text to Speech on Mobile Phone. Institut
Teknologi Bandung.
[2]Violante, dkk. (2013). Improving Speech
Synthesis Quality by Reducing Pitch Peaks in
the Source Recordings. Universidad de Buenos
Aires.
[3] Rachma, H.D., dkk. (2011). Pembuatan Text-
To-Speech Synthesis System untuk Penutur
Berbahasa Indonesia. Institut Teknologi
Sepuluh November.