bab 2 landasan teori 2 -...
TRANSCRIPT

7
BAB 2
LANDASAN TEORI
2.1 Intelegensia Semu
Intelegensia semu adalah bidang studi yang mempelajari bagaimana cara untuk
membuat sebuah komputer dapat melakukan hal yang membutuhkan intelegensi
ketika dioperasikan oleh manusia (Luger and Stubblefield, 1993).
Kecerdasan semu terkategorikan menjadi 4 bagian besar, yaitu sistem yang
berpikir seperti manusia (pendekatan kognitif), sistem yang berpikir secara rasional
(Pendekatan the laws of thought), sistem yang bertindak seperti manusia
(Pendekatan Turing Test) dan sistem yang bertindak secara rasional (Pendekatan
Rasional Agent).
Apabila dilihat secara keseluruhan, kecerdasan semu dapat dibedakan menjadi
2 jenis konsep, yaitu kecerdasan semu konvensional dan kecerdasan semu
komputasional.
1. Kecerdasan Semu Konvensional
Teknik pembuatan program intelegensia semu sangat berbeda dengan teknik
pemrograman menggunakan bahasa konvensional. Dalam software
konvensional kita memerintah komputer bagaimana menyelesaikan suatu
masalah. Sebaliknya, dalam intelegensia semu kita tidak memerintah komputer
untuk menyelesaikan masalah, tetapi memberitahu komputer tentang adanya
masalah. Dalam komputasi konvensional, kita memberikan data kepada
komputer dan program yang telah kita susun terlebih dahulu dengan langkah

8
demi langkah kemudian memspesifikasikan cara data digunakan sampai
komputer bisa memberikan solusi. Dalam komputasi intelegensia semu,
komputer mendapatkan pengetahuan tentang suatu wilayah subyek masalah
tertentu dengan ditambah kemampuan inferensi. Kita tidak memerintahkan
komputer untuk memecahkan masalah tetapi sebaliknya komputer dan
software-nya yang menentukan metode untuk mencapai suatu solusi.
Program komputer konvensional didasarkan pada suatu algoritma yang disusun
dengan jelas, rinci, serta langkah sampai pada hasil yang sudah ditentukan
sebelumnya. Program bisa berupa rumus matematika atau prosedur berurutan
yang tersusun dengan jelas yang mengarah ke suatu solusi. Algoritma tersebut
kemudian dipindahkan ke dalam program komputer. Daftar instruksi disusun
berurutan untuk mengarahkan komputer agar bisa sampai pada hasil yang
diinginkan. Selanjutnya, algoritma bisa digunakan untuk mengolah data
bilangan, huruf, atau kata lainnya.
2. Kecerdasan Semu Komputasional
Software intelegensia semu tidak didasarkan pada algoritma, tetapi
didadasarkan pada representasi dan manipulasi simbol. Di dalam intelegensia
semu, sebuah simbol bisa merupakan huruf, kata, atau bilangan yang digunakan
untuk menggambarkan objek, proses, dan hubungannya. Sumber bisa
merupakan cetakan atau elektronik. Objek bisa berupa orang, benda, ide,
pikiran, peristiwa, atau pernyataan suatu fakta. Dengan menggunakan simbol,
komputer bisa menciptakan suatu basis pengetahuan yang menyatakan fakta,
pikiran, dan hubungannya satu sama lain. Berbagai proses digunakan untuk
memanipulasi simbol agar mampu memecahkan masalah. Pengolahannya

9
bersifat kuantitatif, bukan kualitatif seperti halnya komputasi yang didasarkan
pada algoritma.
Dalam perkembangannya intelegensia semu dapat dikelompokkan sebagai
berikut:
1. Sistem pakar (Expert System), komputer sebagai sarana untuk menyimpan
pengetahuan para pakar sehingga komputer memiliki keahlian menyelesaikan
permasalahan dengan meniru keahlian yang dimiliki pakar.
2. Pengolahan bahasa alami (Natural Language Processing), pengguna dapat
berkomunikasi dengan komputer menggunakan bahasa sehari-hari, misalnya
bahasa inggris, Bahasa Indonesia, dan sebagainya.
3. Pengenalan ucapan (Speech Recognition), manusia dapat berkomunikasi dengan
komputer menggunakan suara.
4. Robotika & Sistem Sensor.
5. Computer Vision, menginterpretasikan gambar atau objek-objek tampak melalui
komputer.
6. Intelligent Computer-Aided Instruction, komputer dapat digunakan sebagai tutor
yang dapat melatih & mengajar.
7. Game Playing.
8. Soft Computing.

10
2.2 Information Retrieval
Inti dari information retrieval adalah sekumpulan, algoritma dan teknologi
untuk melakukan pemrosesan, penyimpanan dan menemukan kembali informasi
yang ada. Proses dari information retrieval terdiri dari beberapa langkah, dimulai
dari peinginputan query untuk menentukan dokumen mana yang sesuai dengan
query yang diinput hingga memprioritaskan dokumen mana yang paling relevan
dengan query yang diinput. Langkah-langkah dalam penemuan dokumen yang
sesuai dengan query akan dilakukan di belakang layar atau disembunyikan dari
user, sehingga user hanya perlu melakukan input query dan melihat hasil dari query
tersebut. Langkah-langkah dalam penemuan dokumen yang sesuai juga bervariasi,
beberapa diantaranya yaitu: Boolean Model, Vector Space Model, Probabilistic
Model, Latent Semantic Indexing Model dan lain-lainnya (Jae-wook: 2010).
2.2.1 Arsitektur Information Retrieval
2.2.1.1 Proses Retrieval
Proses information retrieval secara garis besar digambarkan dalam diagram di
bawah ini :
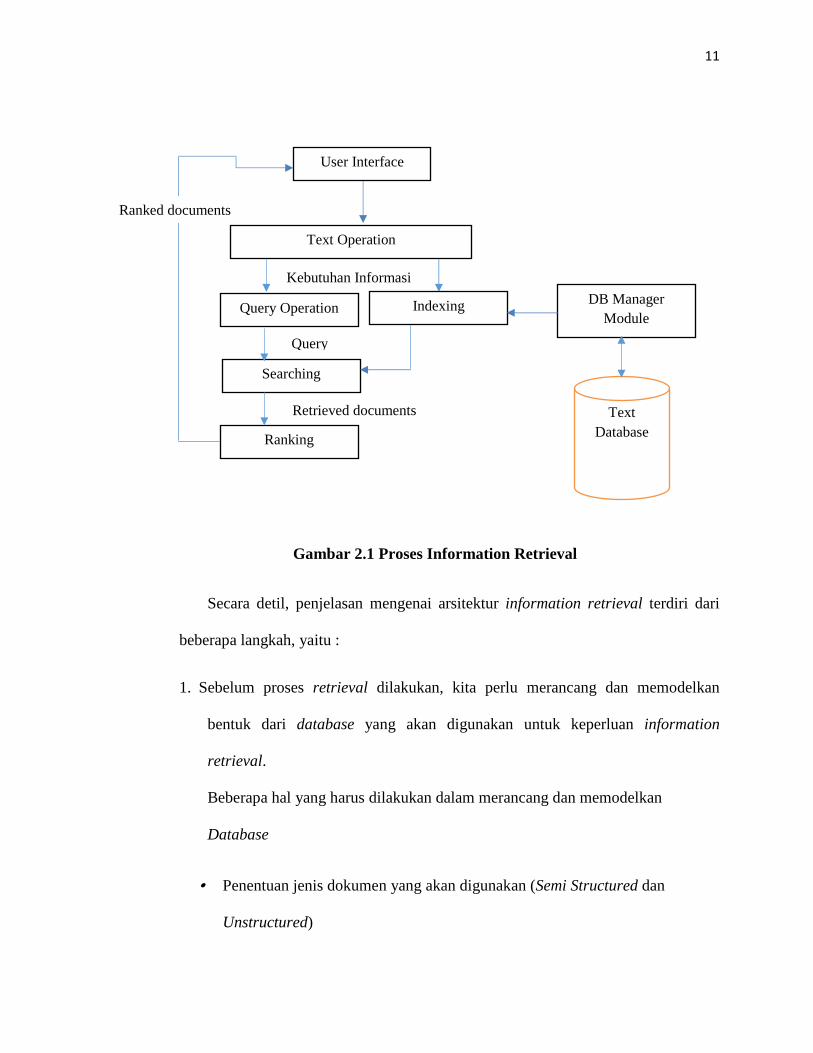
11
Gambar 2.1 Proses Information Retrieval
Secara detil, penjelasan mengenai arsitektur information retrieval terdiri dari
beberapa langkah, yaitu :
1. Sebelum proses retrieval dilakukan, kita perlu merancang dan memodelkan
bentuk dari database yang akan digunakan untuk keperluan information
retrieval.
Beberapa hal yang harus dilakukan dalam merancang dan memodelkan
Database
• Penentuan jenis dokumen yang akan digunakan (Semi Structured dan
Unstructured)
User Interface
Text Operation
Query Operation
Searching
Ranking
Indexing
Text Database
Query
Retrieved documents
DB Manager Module
Kebutuhan Informasi
Ranked documents

12
- semi–structured (dokumen yang memiliki struktur tree, misalnya
dokumen XML) biasanya memberikan tag tertentu pada term – term
pada dokumen, sedangkan pada dokumen.
- unstructured (dokumen yang tidak memiliki pola, misalnya artikel
atau paragraf) proses ini akan dilewati dan term pada dokumen akan
dibiarkan tanpa imbuhan tag.
• Operasi dasar yang akan dilakukan terhadap text pada isi dokumen.
• Sistem akan membentuk indeks dari text.
• Indeks merupakan bagian yang sangat kritikal karena akan berpengaruh pada
proses pencarian yang cepat dalam volume data yang sangat besar. Struktur
indeks dapat berbeda-beda, namun yang paling popular untuk digunakan
adalah inverted index. (Modern Information Retrieval:2010). Pembuatan
indeks akan melibatkan DB Manager Module untuk mengambil data-data
indeks yang telah disimpan pada text database sebelumnya.
• indeks tersebut akan disimpan ke dalam text database melalui DB Manager
Module.
2. Ketika document text database selesai dibentuk, maka user sudah dapat
melakukan pencarian. Untuk melakukan pencarian, langkah – langkah yang
harus dilakukan adalah sebagai berikut :
• Pada suatu kebutuhan pencarian data atau kebutuhan informasi pengguna
akan merepresentasikan kebutuhan tersebut dengan menggunakan query.
• Query Operation akan dilakukan setelah user menginput query.

13
• Proses searching pada query akan menghasilkan retrieved documents.
• Sebelum data dikembalikan ke user, dokumen yang di-retrieved akan di-
ranking berdasarkan kedekatan dokumen dengan query.
2.2.1.2 Text Operation
Text Operation berperan penting dalam proses information retrieval, karena
seluruh proses yang berhubungan dengan penggalian informasi dari sumber
dokumen ataupun teks dilakukan pada proses text operation. Dari awal mulanya
sebuah sumber yang memberikan informasi yang kurang ter-summarize dan kurang
tepat, menjadi sebuah sumber yang lebih akurat dan ter-summarize. Pada text
operation, terdapat beberapa langkah yang harus dan tidak harus dilakukan di dalam
sebuah sistem Information Retrieval tergantung kepada model retrieval yang
digunakan, langkah-langkah tersebut adalah sebagai berikut :
• Tokenisasi
• Penghilangan Stop-word
• Normalisasi
• Stemming dan Lemmatisasi
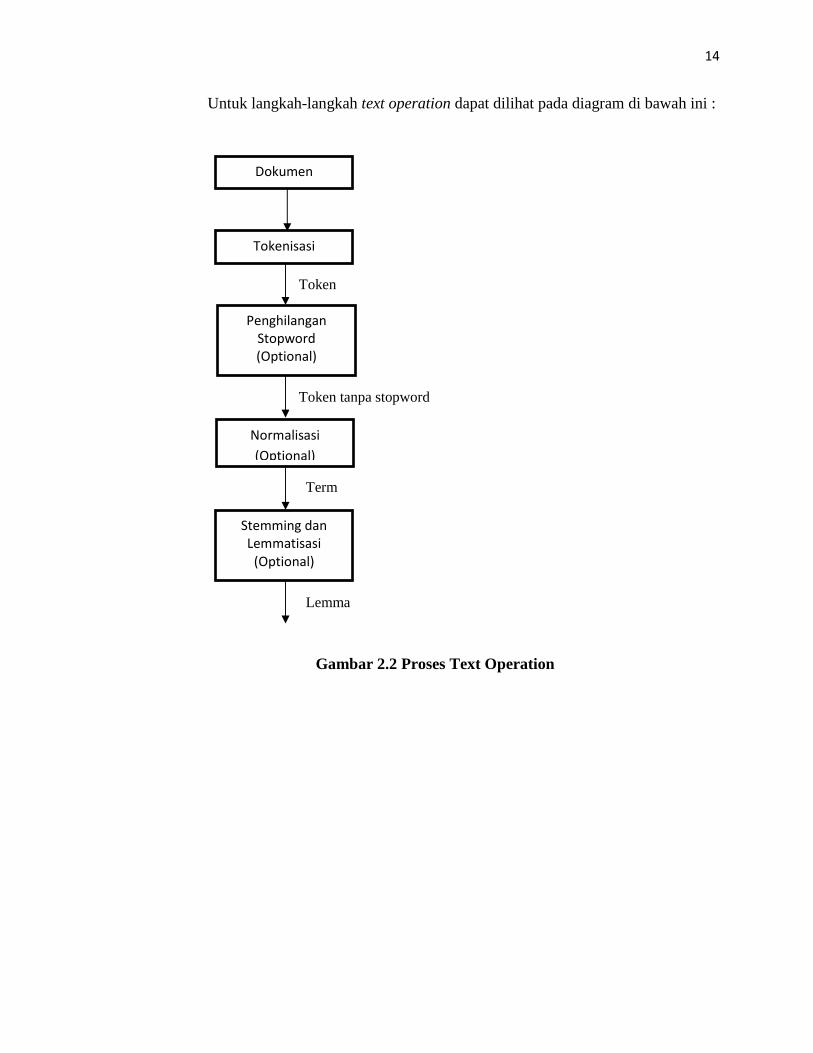
14
Untuk langkah-langkah text operation dapat dilihat pada diagram di bawah ini :
Gambar 2.2 Proses Text Operation
Tokenisasi
Penghilangan
Stopword
(Optional)
Normalisasi
(Optional)
Stemming dan
Lemmatisasi
(Optional)
Token
Token tanpa stopword
Term
Lemma
Dokumen

15
1. Tokenisasi
Tokenisasi merupakan proses pemotongan kumpulan karakter menjadi sebuah
kata tunggal atau token.
Contoh tokenisasi :
• Input : Friends, Romans, Countrymen, Lend, Me, Your, Eyes
• Output : Friends Romans Countrymen Lend Me Your Eyes
Terkadang token dapat dikatakan juga sebagai term atau kata. Pemotongan
kumpulan karakter biasanya berdasarkan karakter spasi, namun beberapa
permasalahan yang terjadi dalam proses tokenisasi yaitu terdapat beberapa kata
yang akan berbeda arti bila dipotong berdasarkan spasi seperti San Fransisco akan
memiliki arti yang berbeda bila dipotong menjadi San dan Fransisco.
Setiap dokumen dan query direpresentasikan dengan model bag-of-words, yaitu
model yang mengabaikan urutan dari kata – kata dan struktur yang ada di dalam
dokumen. Dokumen diubah menjadi sebuah ‘tas’ yang berisi kata – kata yang
independen.
2. Penghilangan Stop Word
Stop-word didefinisikan sebagai term yang tidak berhubungan (non-relevant)
dengan subjek utama dari database meskipun kata tersebut sering muncul di dalam
dokumen.
Penghilangan stop-word tidak bersifat wajib pada beberapa desain dari modern
information retrieval memliki cara sendiri untuk menyelesaikan masalah kata-kata
yang sering digunakan dengan menggunakan data statistik.

16
Contoh stop-word dalam bahasa inggris:a, an, the, this, that, these, those, her,
his, its, my, our, their, your, all, few, many, several, some, every, for, and, nor, bit,
or, yet, so, also, after, although, if, unless, because, on, beneath, over, of, during,
beside, dan etc.
Contoh stop-word dalam bahasa Indonesia : yang, juga, dari, dia, kami, kamu,
aku, saya, ini, itu, atau, dan, tersebut, pada, dengan, adalah, yaitu, ke, tak, tidak, di,
pada, jika, maka, ada, pun, lain, saja, hanya, namun, seperti, kemudian, dll.
3. Normalisasi (Equivalence classing of term)
Normalisasi merupakan pengelompokan kata yang memiliki nilai sama. Proses
normalisasi dapat mengurangi nilai recall den meningkatkan nilai precision. Cara
standar yang paling sering dilakukan untuk melakukan normalisasi adalah membuat
sebuah equivalence class, yang biasanya dinamakan menjadi salah satu member dari
class. Sebagai contoh: anti-discriminatory dan anti discriminatory keduannya akan
dikelompokkan kedalam sebuah term yaitu anti discriminatory. Kegunaan utama
dari pengelompokkan ini adalah menghilangkan karakter tanda hubung. Cara lain
untuk membuat sebuah equivalence class adalah memberikan hubungan antara kata
yang saling berhubungan , dengan membuat daftar kata yang memiliki arti sama
seperti car dan automobile.

17
4. Stemming dan Lemmatisasi
Sebuah kata kerja dalam dokumen sering kali memiliki banyak bentuk atau tata
bahasa yang berbeda, untuk mengatasinya dilakukan stemming dan lemmatisasi.
Tujuan akhir dari stemming maupun lemmatisasi merupakan proses mereduksi kata
menjadi kata dasar, proses ini dilakukan dengan pemotongan akhiran dan awalan
kata. Dengan cara ini, diperoleh kelompok kata yang mempunyai makna serupa
tetapi berbeda wujud sintaktis satu dengan lainnya. Kelompok tersebut dapat
direpresentasikan oleh satu kata tertentu. Meskipun demikian stemming dan
lemmatisasi memiliki perbedaan dalam cara kerjanya. Stemming melakukan proses
pemotongan akhiran dan awalan untuk mencapai tujuan tersebut, sedangkan
lemmatisasi melihat penggunaan kata kerja serta analisis morfologi terlebih dahulu
sebelum melakukan pemotongan, hasil dari lemmatisasi biasa disebut dengan
lemma. Misalkan sebuah kata saw, stemming hanya akan mengembalikan kata see,
sedangkan lemmatisasi akan memotongnya ke bentuk see atau saw tergantung pada
penggunaan katanya sebagai verb atau noun. Meskipun lemmatisasi membantu
meningkatkan precision untuk sebagian besar query namun lemmatisasi akan
menurunkan performa karena membutuhkan proses yang cukup besar. Stemming
akan meningkatkan recall dan menurunkan precision.
2.2.1.3 Indexing
Proses indexing adalah proses yang merepresentasikan document collection ke
dalam bentuk tertentu untuk memudahkan dan mempercepat proses pencarian
dokumen yang relevan.

18
Pembuatan index dari document collection adalah tugas pokok pada tahapan
pre-processing di dalam information retrieval. Efektitifitas dan efisiensi information
retrieval dipengaruhi oleh kualitas indeks-nya. Pengindeksan membedakan
dokumen satu dengan dokumen yang lain yang berada di dalam satu collection.
Indeks dengan ukuran yang kecil dapat memberikan hasil yang kurang baik dan bisa
saja beberapa dokumen yang seharusnya relevan terabaikan. Sementara indeks
dengan ukuran yang besar memungkinkan ditemukannya dokumen yang tidak
relevan dan menurunkan kecepatan pencarian.
Pembuatan inverted index harus melibatkan konsep linguistic processing yang
bertujuan mengekstrak term-term penting dari dokumen yang direpresentasikan
sebagai bag-of-words.
Gambar 2.3 Proses Esktraksi Term
Query Dokumen
Representasi
query
Representasi
dokumen
Proses
pencocokan
Daftar
dokumen

19
2.3 Model-Model Information Retrieval
2.3.1 Boolean Model
Boolean Model adalah model yang paling sederhana dalam information
retrieval. Pada model ini, setiap query yang dibentuk menggunakan sekumpulan
kata-kata yang biasanya disebut sebagai Keyword dan dihubungkan menggunakan
Boolean operator seperti AND, OR dan NOT (Peter : 2010).
Boolean Model adalah salah satu teknik pemecahan masalah dalam information
retrieval. Boolean Model hanya menentukan apakah di dalam dokumen-dokumen
yang tersedia mengandung query yang ingin dicari dengan logika NOT, AND dan
OR. Boolean Model merupakan teknik yang paling sederhana dalam menyelesaikan
permasalahan information retrieval karena Boolean Model hanya menggunakan
logika 1 (mengandung) dan 0 (tidak mengandung) dalam menemukan query di
dalam dokumen-dokumen yang ada, berbeda dengan halnya dengan model-model
lainnya yang melakukan perhitungan rumit dalam menentukan seberapa besar
keterkaitan antara query dan dokumen yang ada.
Gambar 2.4 Flowchart Training Boolean Model

20
Gambar 2.5 Flowchart Testing Boolean Model
Untuk dapat memahami lebih detil tentang Boolean Model, berikut diberikan
contoh penyelesaian sistem information retrieval dengan Boolean Model.
Pada sebuah document collection, terdapat :
- Dokumen : Anthony, Julius, Tempest, Hamlet, Othello, Bert.
- Word : Anthony, Brutus, Caiser, Calpurnia, Cleopatra, Mercy, Worser.
- Query : Brutus AND Caiser AND NOT Calpurnia
Hal yang diketahui selain informasi di atas adalah mengenai keterkaitan antara
dokumen dengan word, keterkaitan dokumen dengan word akan diilustrasikan
dengan tabel di bawah ini :
0 = apabila word tidak terdapat di dalam dokumen
1 = apabila word terdapat di dalam dokumen
Tabel 2.1 Keterkaitan Antara Word dan Dokumen Boolean Model
Word/dokumen Anthony Julius Tempest Hamlet Othello Bert
Anthony 1 1 0 0 0 1
Brutus 1 1 0 1 0 0
Caiser 1 1 0 1 1 1
Calpurnia 0 1 0 0 0 0

21
Cleopatra 1 0 0 0 0 0
Mercy 1 0 1 1 1 1
Worser 1 0 1 1 1 0
Untuk mendapatkan hasil pencarian untuk Caiser AND Brutus AND NOT
Calpurnia, hal yang harus dilakukan adalah :
1. Mengambil nilai matriks dari masing-masing query (Caiser, Brutus dan
Calpurnia)
Caiser : 110111
Brutus : 110100
Calpurnia : 010000 � NOT Calpurnia : 101111
2. Melakukan operasi bitwise AND untuk seluruh query, agar mendapatkan
dokumen mana yang mengandung query yang diminta.
Caiser : 110111
Brutus : 110100
NOT Calpurnia : 101111
Hasil bitwise : 100100
3. Melakukan pengecekan pada tabel dokumen dan word dengan
menggunakan hasil bitwise untuk mendapatkan dokumen mana yang dapat
memenuhi query yang diminta.

22
Tabel 2.2 Hasil Pencarian Menggunakan Bitwise Boolean Model
Word/dokumen Anthony Julius Tempest Hamlet Othello Bert
Brutus 1 1 0 1 0 0
Caiser 1 1 0 1 1 1
Calpurnia 0 1 0 0 0 0
Bitwise 1 0 0 1 0 0
Maka dapat ditentukan bahwa dokumen yang dapat memenuhi query yang
diminta adalah Anthony dan Hamlet.
Menggunakan cara di atas belum menyelesaikan permasalah sistem information
retrieval secara keseluruhan. Kasus yang terjadi adalah jumlah dokumen yang besar
dan masing-masing dokumen memiliki konten yang banyak, sehingga table yang
dimiliki akan sangat besar dan perbandingan yang harus dilakukan oleh sistem
menjadi sangat banyak. Misalkan untuk 100 dokumen dengan masing-masing
memiliki 500 word didalamnya maka matriks yang akan dihasilkan adalah
100 x 500 = 5000, dapat dibayangkan untuk membandingkan query dengan dua kata
saja sebagai contoh: Calpuria and Brutus akan membutuhkan operasi bitwise
sejumlah 2 x 500 kali.
Tentu saja cara di atas sangat tidak efektif untuk melakukan pencarian pada
query, karena akan memberikan performa yang sangat buruk atau dengan kata lain
pencarian yang sangat lambat. Untuk itu perlu dilakukan optimasi dan indeksing
pada saat melakukan pencarian, penyelesaian yang dapat dilakukan untuk

23
menyelesaikan masalah di atas adalah dengan cara membuat inverted index.
Langkah – langkah pembuatan inverted index adalah sebagai berikut :
1. Kumpulkan dokumen-dokumen yang ada untuk diindeks. Dalam hal ini
pengindeksan yang dimaksud adalah memberikan penomoran pada setiap
dokumen untuk dijadikan sebagai indeks.
2. Potong kalimat-kalimat yang telah diindeks.
3. Potong setiap kata yang terdapat pada masing-masing dokumen yang telah
diindeks.
Hasil dari langkah pertama hingga langkah ketiga dapat dilihat pada gambar
di bawah ini :
Tabel 2.3 Hasil Index Pada Boolean Model
Word dokumen yang telah diindeks
Brutus 1 2 4 11 31 45 173
Caesar 1 2 4 5 6 16 57 132 ...
Calpurnia 2 31 54 101
Pada gambar di atas menjelaskan bahwa setiap word telah dindeks pada
dokumen yang tersedia. Apabila kata yang ingin dicari terdapat pada
dokumen tersebut, maka cukup menuliskan nomor indeks dokumen
tersebut.
4. Urutkan inverted indeks berdasarkan jumlah dokumen yang mengandung
keyword secara ascending.

24
5. Melakukan proses pengambilan informasi mulai dari jumlah dokumen
terkecil dibandingkan dengan dokumen terkecil berikutnya. Contohnya :
Diketahui dokumen dan word sebagai berikut :
Word dokumen
Brutus 1 3 6 7 9
Caiser 2 3 7
Calpurnia 3 5 7 8
Diurutkan berdasarkan jumlah dokumen terkecil, sehingga menjadi :
Word dokumen
Caiser 2 3 7
Calpurnia 3 5 7 8
Brutus 1 3 6 7 9
Setelah diurutkan, maka dokumen yang akan dibanding adalah word Caiser
dan Calpurnia.
6. Proses perbandingan untuk proses pengambilan informasi dilakukan dengan
algoritma berikut :

25
o Membuat sebuah variabel vektor untuk menampung hasil
perbandingan antara 2 dokumen,
o Melakukan proses perulangan while dengan kondisi “Selama salah
satu word masih mengandung dokumen, maka proses perbandingan
akan terus berjalan”,
o Selama proses perulangan berjalan akan dilakukan pengecekan
terhadap word yang satu dengan yang lainnya apakah mengandung
indeks dokumen yang sama, dengan kondisi sebagai berikut :
� Apabila terdapat indeks dokumen yang sama, maka indeks
dokumen akan ditambahkan ke dalam vektor jawaban dan
masing-masing word indeksnya akan ditambah.
� Apabila tidak terdapat dokumen dengan indeks dokumen
yang sama, maka akan dilakukan pengecekan terhadap
indeks dokumen mana yang lebih besar, dengan kondisi
“word dengan indeks terkecil akan ditambah dan yang
terbesar akan tetap pada posisinya”.
o Setelah proses perulangandan selection di atas selesai, maka
informasi telah ditemukan dan akan di return berupa nilai vektor.
7. Apabila jumlah word yang ingin dicari lebih dari dua, maka proses keenam
akan dilakukan hingga semua word yang ingin dicari pada dokumen
ditemukan. Dengan cara membandingkan 2 dokumen. Contoh :
Word dokumen
Caiser 2 3 7
Calpurnia 3 5 7 8
Jawaban : 3,7
Jawaban : 3,7

26
Brutus 1 3 6 7 9
Maka jawaban untuk pencarian informasi untuk keyword Caiser, Calpurnia
dan Brutus terdapat pada dokumen 3 dan 7.
Untuk inverted index sebenarnya telah cukup untuk menyelesaikan masalah
performa dari sistem information retrieval, proses pencarian dapat lebih
dioptimalkan dengan menambahkan operator-operator logika.
2.3.2 Vector Space Model
Vector Space Model berbeda dengan Boolean Model dalam berbagai aspek,
walaupun pada Vector Space Model query yang diinput oleh user juga dianggap
sebagai kumpulan kata-kata, akan tetapi kata-kata tersebut dapat dihitung bobotnya,
dapat juga difokuskan tingkat kepentingan kata-katanya (Edie : 2010).
Vector Space Model (VSM) menganggap dokumen sebagai kumpulan dari kata-
kata dan biasanya digunakan dalam penelusuran informasi seperti pencarian kata-
kata. Dalam VSM, kata-kata di dalam dokumen direpresentasikan dengan vektor
matematika. Dengan kata lain, tingkat pentingnya sebuah kata dalam dokumen
dinyatakan dengan Word Frequncy (TF) dan Inverse Dokumen Frequency (IDF).
TF-IDF didesain untuk menyatakan kekuatan keterkaitan antar kata dalam sebuah
dokumen ataupun antar dokumen. (Salton, 1971).
Menurut Salton, vector space model adalah model information retrieval yang
menggabungkan informasi lokal dan global dan mengibaratkan baik query maupun
dokumen sebagai sebuah vektor n-dimensi. Pada vektor tersebut, tiap dimensi
diwakili oleh sebuah term. Term yang digunakan biasanya adalah term yang

27
terdapat di keyword atau query, dengan demikian jika ada term yang ada pada
dokumen tetapi tidak ada pada query atau keyword maka term tersebut bisa
diabaikan
Gambar 2.6 Flowchart Training Vector Space Model
Gambar 2.7 Flowchart Testing Vector Space Model
Berikut adalah persamaan vector space model untuk menghitung bobot term
yang diperkenalkan oleh Salton:
Dimana:

28
jumlah term atau seberapa sering term i muncul di dalam sebuah dokumen.
jumlah dokumen yang mengandung term i
jumlah dokumen secara kesuluruhan
Pada persamaan diatas, nilai rasio dari adalah besarnya peluang terpilihnya
dokumen yang mengandung term-query. Lalu adalah frekuensi dari
inverse dokumen, dan merupakan informasi global dan adalah informasi lokal
Untuk lebih jelasnya mengenai hubungan antara informasi global dan informasi
lokal, berikut akan disediakan contohnya:
Berikut adalah kumpulan dokumen yang terdiri dari lima dokumen, D1, D2,
D3, D4, dan D5. Dari semua dokumen yang ada, hanya ada tiga dokumen yang
mengandung term “CAR”, yaitu dokumen D1, D2, dan D3, sehingga nilai dari IDF
untuk term ini adalah = 0.2218
Gambar 2.8 Diagram Dokumen TF-IDF

29
Pada D1, nilai = 1 dikarenakan D1 hanya mengandung satu kata “car”.
Nilai dari adalah nilai untuk informasi lokal, sementara nilai
adalah nilai dari informasi global yang ada.
Nilai di atas adalah yang merupakan jumlah term
secara keseluruhan dari semua dokumen.
Persamaan vector space model untuk menghitung bobot term yang
diperkenalkan oleh salton menunjukkan bahwa nilai akan bertambah seiring
dengan bertambahnya nilai . Hal ini akan menyebabkan model di atas rentan
terhadap pengulangan term yang akan mengakibatkan nilai menjadi tinggi (hal
ini dikenal dengan keyword spamming), jika diberikan query q, maka
1. Dokumen yang dengan jumlah kata yang sama, maka dokumen yang
mengandung term yang terdapat pada query q tentunya akan mendapatkan nilai
yang lebih tinggi
2. Dokumen yang panjangnya tidak sama, maka kemungkinan dokumen yang lebih
panjang akan mendapatkan nilai yang lebih tinggi karena dokumen tersebut
mungkin saja lebih banyak mengandung term pada query .
2.3.2.1 TF – IDF
Term Frequency (TF) menurut Polettini (2004) adalah formula yang dipakai
untuk menghitung berapa kali suatu term muncul di sebuah dokumen. Frekuensi
term i dalam dokumen j didefinisikan oleh Cios et al (2007) sebagai:

30
Dimana: = jumlah kemunculan term i pada dokumen j
Inverse Dokumen Frequency (IDF) digunakan untuk mengidentifikasi seberapa
besar perbedaan yang dihasilkan oleh term i. Biasanya term yang muncul dalam
berbagai dokumen kurang dapat digunakan untuk mengukur suatu topik yang
spesifik. Rumus untuk mengukur inverse document frequency adalah:
Dimana = jumlah dokumen yang mengandung term i
digunakan untuk menekan efek relatif terhadap
Vector space model dapat diterapkan pada indeks kata tertentu atau pada
keseluruhan teks. Vector space model terdiri dari dua kali langkah perhitungan,
yaitu:
1. Bobot tiap indeks kata pada seluruh dokumen dihitung. Perhitungan ini
menentukan seberapa penting sebuah kata di dalam collection.
2. Bobot tiap index kata di dalam dokumen yang diberikan dihitung sesuai
sebanyak N dokumen. Perhitungan ini menentukan seberapa penting sebuah
kata di dalam sebuah dokumen.
Berikut adalah contoh sederhana perhitungan vector space model, untuk
penyederhanaan, kita akan menggunakan vector space model sederhana yang:
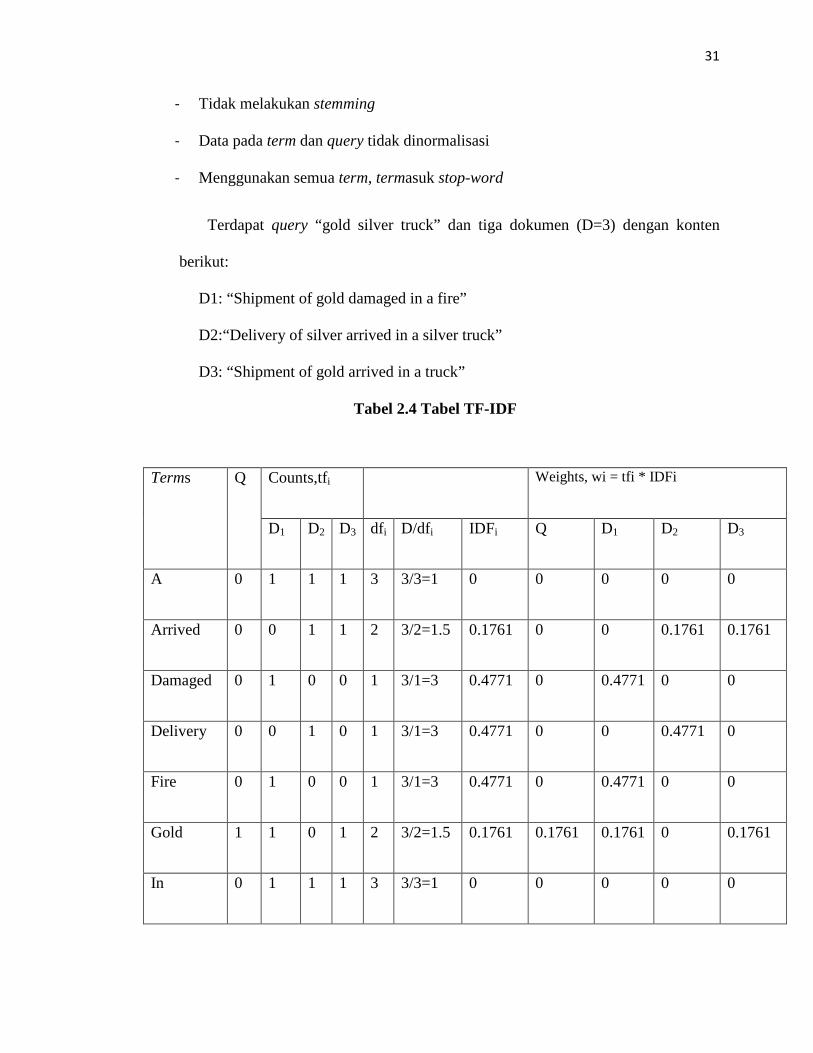
31
- Tidak melakukan stemming
- Data pada term dan query tidak dinormalisasi
- Menggunakan semua term, termasuk stop-word
Terdapat query “gold silver truck” dan tiga dokumen (D=3) dengan konten
berikut:
D1: “Shipment of gold damaged in a fire”
D2:“Delivery of silver arrived in a silver truck”
D3: “Shipment of gold arrived in a truck”
Tabel 2.4 Tabel TF-IDF
Terms Q Counts,tfi Weights, wi = tfi * IDFi
D1 D2 D3 dfi D/dfi IDFi Q D1 D2 D3
A 0 1 1 1 3 3/3=1 0 0 0 0 0
Arrived 0 0 1 1 2 3/2=1.5 0.1761 0 0 0.1761 0.1761
Damaged 0 1 0 0 1 3/1=3 0.4771 0 0.4771 0 0
Delivery 0 0 1 0 1 3/1=3 0.4771 0 0 0.4771 0
Fire 0 1 0 0 1 3/1=3 0.4771 0 0.4771 0 0
Gold 1 1 0 1 2 3/2=1.5 0.1761 0.1761 0.1761 0 0.1761
In 0 1 1 1 3 3/3=1 0 0 0 0 0

32
Tiga kolom terakhir di atas adalah perhitungan bobot dari semua term yang ada.
Berikut adalah penjelasan mengenai kolom – kolom di atas:
- Kolom 1 – 6: Pertama kita menganalisis indeks dari term dari dokumen dan
menentukan jumlah tfi untuk query dan setiap dokumen Dj.
- Kolom 7 – 9: Lalu hitung frekuensi dokumen Dj untuk setiap dokumen.
- Kolom 10 - 12: Kita akan menghitung tf * IDF dan menghitung bobot dari
masing – masing term.
Setelah melakukan perhitungan seperti diatas, selanjutnya akan dilakukan
perhitungan similarity analysis. Terdapat beberapa metode perhitungan similarity
pada vector space model, antara lain: cosine, dot product, Jaccard coefficient dan
Euclidean distance. Metode yang dipakai pada penelitian kali ini adalah metode
cosine.
Langkah - langkah perhitungan similarity dengan metode cosine adalah :
1. Hitung panjang vektor untuk setiap dokumen dan query (abaikan term dengan
nilai 0)
Of 0 1 1 1 3 3/3=1 0 0 0 0 0
Silver 1 0 2 0 1 3/1=3 0.4771 0.4771 0 0.9542 0
Shipment 0 1 0 1 2 3/2=1.5 0.1761 0 0.1761 0 0.1761
Truck 1 0 1 1 2 3/2=1.5 0.1761 0.1761 0 0.1761 0.1761

33
2. Kemudian hitung semua dot product (abaikan nilai 0)
3. Kemudian hitung tingkat kemiripan pada tiap dokumen

34
Sehingga hasil pemeringkatannya adalah:
1. D2 = 0.8246
2. D3 = 0.3271
3. D1 = 0.0801
Normalisasi frekuensi dari sebuah term i pada dokumen j bisa dilakukan dengan
rumus berikut:
Dimana:
= frekuensi normalisasi

35
= frekuensi dari term i di dalam dokumen j
= frekuensi maksimum term i di dalam dokumen j
Contoh, jika sebuah dokumen terdiri dari term – term berikut:
- Motherboard , 5
- RAM , 10
- Memory , 3
- Speed , 2
- Casing , 5
Pada contoh di atas, term RAM adalah term yang paling banyak muncul
sehingga normalisasi frekuensi adalah sebagai berikut:
- Motherboard , 5 / 10 = 0.50
- RAM , 10 / 10 = 1
- Memory , 3 / 10 = 0.30
- Speed , 2 / 10 = 0.20
- Casing ,5 / 10 = 0.50
Bobot pada term i di dalam dokumen j dapat dinormalisasi dengan rumus:
Sementara bobot term i pada query q dapat dinormalisasi dengan rumus:

36
Hasil dari normalisasi bobot di atas kemudian digunakan untuk menghitung
vektor dokumen dan query.
2.3.3 Latent Semantic Indexing (LSI)
LSI adalah metode pengindeksan secara otomatis yang dibuat untuk mengatasi
dua masalah dasar yang kerap ditemui pada pengindeksan tradisional yang memakai
metode pencocokan keyword: synonymy dan polysemy. Synonymy adalah keadaan
dimana terdapat beberapa kata berbeda, tetapi kata - kata tersebut mempunyai arti
yang sama, sementara polysemy adalah keadaan dimana satu kata mempunyai lebih
dari satu arti. LSI adalah metode pengindeksan hasil pengembangan dari ruang
model vektor. Pada ruang model vektor, dokumen dan term dinyatakan sebagai
sebuah vektor, sementara LSI (latent semantic indexing) lebih condong
menggunakan matriks untuk me-retrieve dokumen.
Gambar 2.9 Flowchart Training LSI Model

37
Gambar 2.10 Flowchart Testing LSI Model
2.3.3.1 SVD (Singular Value Decomposition)
SVD adalah metode dari aljabar linear untuk faktorisasi terhadap sebuah
matriks dengan dimensi menjadi tiga matriks. Hal ini terkait dengan
dekomposisi nilai Eigen dari matriks (Golub and Van Loan, 1996).
SVD digunakan untuk menurunkan peringkat dari matriks tanpa harus
menghilangkan konten – konten yang penting dan SVD juga berguna untuk
mengurangi noise (konten – konten yang tidak penting).
Pada vector space model, hanya term atau dokumen yang direpresentasikan ke
dalam vector space model. Sementara pada LSI, term dan dokumen
direpresentasikan ke dalam satu ruang. Hal ini memungkinkan dihitungnya tingkat
kemiripan antara sesama dokumen, antara sesama term, antara term dan dokumen.

38
SVD membagi matriks matriks A dimana dan menjadi tiga
matriks
LSI dirancang untuk menemukan struktur lemantik laten dari document
collection dengan membuat sebuah ruang semantik. Karena itu LSI menganalis pola
penggunaan kata yang ada pada document collection. Pada ruang semantik yang
dibuat oleh LSI, terdapat term dan document.
Latent Semantic Indexing dikembangkan untuk mengatasi kelemahan model
ruang vektor. Misalnya kita mempunyai lima buah document:
: Romeo and Juliet.
: Juliet :O happy dagger!
: Romeo died by dagger.
: “ live free or die”, that’s the New-Hampsphire’s motto.
: Did you know, New-Hampspire is in New-England
Dan query yang dipakai adalah : dies, dagger.
Jika dilakukan pencarian dokumen yang relevan, jelas bahwa berada pada
peringkat teratas karena dokumen tersebut mengandung kata dies, dan dagger.
Dokumen dan berada dibawah dokumen karena masing – masing
dokumen mengandung satu query. Lalu bagaimana dengan dokumen dan ?
Jika yang menganalisis dokumen – dokumen di atas adalah seorang manusia, akan
disimpulkan bahwa dokumen sebenarnya berhubungan dengan query diatas,
sementara itu dokumen tidak terlalu berkaitan dengan query yang dimasukkan.

39
Dengan kata lain dokumen seharusnya berada di posisi yang lebih tinggi
daripada dokumen .
Jika menggunakan metode vector space model, hal tersebut tidak dapat
dilakukan, tetapi dengan menggunakan LSI, hal tersebut mungkin dilakukan. Pada
contoh diatas LSI bisa mengetahui bahwa term dagger sebenarnya berhubungan
dengan dokumen karena term dagger muncul bersamaan bersama term pada
dokumen , yaitu pada dokumen dan dokumen . Term dies juga berhubungan
dengan dokumen dan dokumen karena muncul bersamaan dengan term
Romeo pada dokumen di dalam dokumen dan term New-Hampshire pada
dokumen di dalam dokumen . Dari hubungan antar dokumen di atas, LSI
menyimpulkan bahwa dokumen lebih berhubungan dengan query daripada
dokumen karena dokumen mempunyai hubungan dengan term dagger
melalui Romeo dan Juliet dan juga mempunyai hubungan dengan term die melalui
term Romeo, sementara dokumen hanya mempunyai satu hubungan dengan term
die melalui term New-Hamspire.
Pada LSI, proses pengindeksannya menggunakan Singular Value
Decomposition (SVD) yang berguna untuk menemukan struktur semantik.
Pada LSI, terjadi dua proses utama, yaitu preprocessing dan proses pencarian.
1. The Preprocessing
Pada tahap preprocessing, ruang term-dokumen dari document collection
dibuat, biasanya proses ini selesai pada saat pertama kali dijalankan, atau pada saat
terjadi perubahan pada corpus (subjek yang independent) atau pada saat document

40
collection telah selesai dibuat. Karena itu, waktu yang diperlukan pada proses ini
tidak begitu mempengaruhi efisiensi sistem.
Langkah – langkah preprocessing adalah :
1. LSI pertama – tama mengindeksan semua term yang ada di dalam corpus atau di
setiap dokumen yang ada pada document collection. Kemudian stop- word yang
terdapat pada dokumen tersebut dihilangkan. Hasilnya adalah table yang berisi
seberapa seringnya sebuah term muncul di setiap dokumen.
2. Menghitung seberapa pentingnya sebuah term di dalam dokumen dan di
keseluruhan document collection dengan melakukan pembobotan lokal dan
global.
3. Nilai dari setiap indeks dimasukkan ke dalam Term Document Matrix (TDM)
dimana setiap baris merepresentasikan term dan setiap kolom
merepresentasikan dokumen. adalah jumlah term i yang terdapat pada
dokumen j. Biasanya TDM menghasilkan matrix sparse m * n, hal ini karena
secara umum tidak setiap kata muncul di setiap dokumen . Matrix sparse adalah
matrix yang nilai selnya sebagian besar nol.
4. SVD adalah metode matematika yang digunkana untuk melakukan faktorisasi
dari sebuah matrix menjadi 3 matrix, yaitu matrix U, matrix S dan matrix V.
2. Proses Pencarian
Berikut adalah proses yang akan dijalankan setiap kali terjadi proses pencarian :
1. Pertama pengguna menentukan tipe pencarian yang akan digunakan. Tipe – tipe
yang ada adalah :
• Pencarian term yang mirip dengan term yang dimasukkan

41
• Pencarian dokumen yang mirip dengan dokumen yang dimasukkan
• Pencarian dokumen yang mirip dengan term yang dimasukkan
• Pencarian dokumen yang mirip dengan query yang dimasukkan
2. Pengguna memasukkan query
Berikut adalah contoh sederhana perhitungan Latent Semantic Indexing:
Terdapat query “silver gold truck” dan tiga dokumen (D=3) dengan konten berikut:
D1: “Shipment of gold damaged in a fire”
D2:“Delivery of silver arrived in a silver truck”
D3: “Shipment of gold arrived in a truck”
Tabel 2.5 Data Dokumen LSI Model
Terms D1 D2 D3
Shipment 1 0 1
Damaged 1 0 0
Gold 1 0 1
Fire 1 0 0
Arrive 0 1 1
Truck 0 1 1
Silver 0 2 0

42
Langkah – langkah yang dilakukan untuk menghitung hasil dari LSI adalah:
1. Buat matrix TDM (Term Document Matrix) dimana kolom matriks mewakili
dokumen dan baris mewakili term
2. Cari nilai SVD (Singular Value Decomposition) dari matriks di atas.
Cari matriks U, S, V dari matriks di atas.
a. Cari nilai matriks U.
Buat matriks transpose dari matriks A. Matriks transpose adalah matriks dimana
kolom matriks A menjadi baris dan baris menjadi kolom. Matriks transpose A
dilambangkan dengan . Kalikan matriks untuk menghasilkan matriks
Delivery 0 1 0
Of 1 1 1
A 1 1 1
In 1 1 1

43
Hitung nilai eigen dari vektor eigen di atas

44
Untuk mencari nilai , jadikan persamaan matriks di atas
sebagai persamaan sistem linear

45
Selesaikan persamaan diatas sehingga terdapat 11 nilai eigen, yaitu 16.80, 5.58,
0 , 1.62, 0, 0, 0, 0, 0, 0, dan 0 dan vektor eigen yang dihasilkan adalah:
Kemudian lakukan proses ortonormalisasi Gram-Schmidt pada matriks di atas
untuk mendapatkan matriks U, sehingga:

46
b. Setelah menghitung nilai ,cari nilai matriks V. Pertama hitung nilai
Cari nilai eigen dari matriks di atas:
Untuk mencari nilai jadikan persamaan matriks di atas sebagai
persamaan sistem linear:
Yang bisa ditulis menjadi:

47
Selesaikan persamaan diatas sehingga nilai eigen yang didapat adalah ,
dan dan vektor eigen yang didapat adalah:
c. Matriks terakhir yang dicari adalah matriks S, dimana matriks ini adalah matriks
diagonal. Untuk matriks ini, akarkan semua nilai eigen non-zero matriks U dan
V dari yang terbesar sampai yang terkecil. Nilai yang terbesar ditaruh di kolom
1 baris 1 dan seterusnya.
d. Setelah menemukan matriks U, V dan matriks S. Rumus untuk menghitung nilai
LSI adalah:
Dimana : matriks invers S
matriks transpose query

48
Matriks invers dari matriks adalah:
Matriks transpose dari matriks query adalah:
Sehingga:
e. Setelah menemukan nilai matriks R, tentukan panjang vektor tiap dokumen:

49
Sehingga, urutan dokumen yang paling similar adalah: D2,D3,D1
2.4 Tools Penelitian
Dalam penelitian ini, digunakan beberapa tools yang mendukung terbentuknya
hasil dari penelitian ini, diantaranya yaitu :
- Standford NLP
- IrTester
- Matlab

50
2.4.1 Standford NLP
Standford NLP (Standford Natural Languages Processing) adalah tools yang
disediakan oleh Standford University yang digunakan untuk pengolahan kata yang
nantinya hasil dari pengolahan kata tersebut akan digunakan dalam membantu
penelitian ini. Seperti yang kita ketahui bahwa di dalam information retrieval
terdapat beberapa langkah yang harus dilakukan agar sebuah informasi yang
awalnya hanya berbentuk kata-kata pada umumnya menjadi sebuah hasil
kesimpulan yang dapat digunakan.
2.4.2 IrTester
IrTester merupakan tools yang digunakan untuk membandingkan ketiga model
yang diteliti yang dibuat menggunakan algoritma dan cara kerja dari masing-masing
model. Tools IrTester yang dibuat hampir menyerupai tools pembanding Weka yang
biasanya digunakan untuk membandingkan antara model-model information
retrieval. Perbedaan antara Weka dan IrTester adalah IrTester hanya
membandingkan 3 model yaitu model Boolean Model, Vector Space Model dan
Latent Semantic Indexing, sedangkan Weka membandingkan hampir keseluruhan
model information retrieval yang ada.
IrTester merupakan tools yang berbasiskan web, tools ini dibuat menggunakan
bahasa pemrograman Java, dibantu dengan menggunakan framework Struts dan
Maven.
Cara penggunaannya sangat sederhana, beberapa hal yang harus dilakukan oleh
tester untuk mendapatkan kesimpulan model mana yang terbaik adalah sebagai
berikut:

51
- Melakukan inisialisasi atau upload dokumen ke dalam repository/database,
- Tester dapat menginput query-query tertentu ke dalam suatu textbox yang
tersedia, sehingga query tersebut dapat diproses oleh sistem sesuai dengan
model masing-masing dan menghasilkan informasi yang sesuai.
Selain itu tester juga dapat menggunakan IrTester sebagai pembanding ketiga
model yang ada, dengan cara memberikan input query yang diinginkan, sistem akan
melakukan kalkulasi, dari ketiga model, model manakah yang memiliki proses yang
paling baik dalam information retrieval.
2.4.3 MATLAB
MATLAB ( matrix laboratory) diciptakan pada akhir tahun 1970-an oleh Cleve
Moler. MATLAB adalah bahasa pemrograman bahasa tingkat tinggi dan
mempunyai GUI yang interaktif untuk komputasi numerik, visualisasi dan
programming. Matlab juga bisa digunakan untuk menganalisa data,
mengembangkan sebuah algoritma dan membuat aplikasi atau model. Untuk
mempermudah perhitungan matriks pada penelitian ini, digunakan software
MATLAB dalam melakukan perhitungan matriksnya terutama dalam perhitungan
SVD pada LSI Model.
2.5 Evaluasi Information Retrieval
Secara standard untuk mengukur keefektifan dari sebuah information retrieval,
kita membutuhkan tiga komponen:
1. Koleksi dokumen

52
2. Test untuk informasi yang dibutuhkan (dapat direpresentasikan melalui
sebuah query)
3. Tolak ukur perbandingan, untuk menentukan dokumen mana yang relevan
dan dokumen mana yang tidak relevan
Jumlah dari dokumen pengetesan harus berada pada ukuran yang logis,
dibutuhkan koleksi dokumen dalam jumlah besar, agar hasil pengetesan dapat
berbeda untuk tiap kebutuhan informasi user.
Dalam pengetesan koleksi dokumen akan ditandai dengan relevan dan tidak
relevan. Dokumen akan dinyatakan relevan jika memenuhi kebutuhan user, bukan
hanya karena dokumen tersebut mengadung sebagian atau keseluruhan kata dari
query yang user masukkan.
Misalkan informasi yang dibutuhkan adalah :
“Informasi mengenai apakah meminum anggur merah lebih efektif untuk
menurunkan penyakit jantung dibandingkan dengan anggur putih”
Kebutuhan informasi ini dapat diterjemahkan menjadi sebuah query berikut:
“Wine AND red AND White AND Heart AND Attack AND Effective”
Tolak ukur standard yang sering dijadikan perbandingan antara suatu model
information retrieval yang satu dengan model yang lainnya adalah membandingkan
precision dan recall untuk masing-masing model dengan bahan/dokumen yang
sama.
Tujuan melakukan pengukuran menggunakan precision dan recall adalah agar
dapat mengetahui mana dokumen yang ditemukan, relevan dan yang tidak relevan.
Selain itu tujuan lainnya adalah mengetahui hasil pengukuran relevansi antara
dokumen yang terurut dari tingkat relevansi tertinggi ke tingkat relevansi terendah.

53
Semakin tinggi nilai precision, maka semakin besar tingkat akurasi sistem dalam
melakukan retrieval informasi, sedangkan semakin tinggi nilai recall, maka
semakin besar performa sistem dalam melakukan retrieval informasi.
Dalam kondisi tertentu salah satu dari penilaian precision dan recall akan
menjadi lebih penting. Misalnya untuk kebanyakan pengguna internet yang
melakukan pencarian di web akan sangat senang bila data yang dicari muncul di
page pertama (precision yang tinggi) , namun orang dengan tipe seperti ini tidak
memiliki keinginan untuk mencari semua dokumen yang relevan. Sedangkan untuk
seorang researcher professional akan lebih mengharapkan untuk mendapatkan
recall setinggi mungkin , dan akan mentolerir precision yang kecil untuk
mendapatkan recall tinggi tersebut.
2.5.1 Evaluasi Unrank Retrieval Model
Unrank retrieval digunakan untuk model information retrieval yang bersifat
exact match dimana kata dalam query dipastikan terdapat dalam dokumen yang di-
retrieve.
Pengukuran unrank retrieval yang mengasumsikan bahwa semua koleksi
dokumen yang di-retrieve sudah dievaluasi atau sudah dilihat oleh user.
2.5.1.1 Precision
Precision adalah perbandingan jumlah materi relevan yang di-retrieve terhadap
jumlah materi yang di-retrieve. Average precision adalah suatu ukuran evaluasi
yang diperoleh dengan menghitung rata-rata tingkat precision pada berbagai tingkat
recall (Grossman D 2002). Berikut adalah rumus umum untuk menghitung nilai
precision:

54
2.5.1.2 Recall
Recall adalah perbandingan jumlah materi relevan yang di-retrieve terhadap
jumlah materi yang relevan (Grossman D 2002). Berikut adalah rumus umum untuk
menghitung nilai recall:
2.5.1.3 F-Measure
Jika hanya menggunakan precision dan recall untuk parameter evaluasi
information retrieval, hasil yang didapatkan tidak akan optimal karena:
o Nilai precision dan recall mengandung trade-off
o Setiap pengguna mempunyai kebutuhan berbeda antara precision dan
recall.
Untuk itu, pada penelitian ini menggunakan parameter pengukuran yang baru,
yaitu F-Measure yaitu pengukuran yang mengkombinasikan precision dan recall
yang diterapkan ke dalam deret harmonik. Berikut adalah rumus umum untuk
menghitung F-measure:

55
2.5.2 Evaluasi Rank Retrieval Model
Pada standard sebuah search engine hasil retrieval berupa koleksi dokumen
akan diurutkan berdasarkan ranking, dengan demikian user akan mengevaluasi
dokumen mulai dari dokumen dengan rating tertinggi, sehingga belum tentu seluruh
koleksi dokumen yang di-retrieve dievaluasi atau dilihat oleh user. Dalam situasi ini
dibutuhkan suatu standard pengukuran baru untuk mengevaluasi hasil retrieval yang
berbentuk ranking.
Pada rank based retrieval, akan dibentuk sebuah kurva precision recall,
dimana nilai precision dihitung berdasarkan pada nilai 11 nilai level recall standard
yaitu 100%, 90%, 80%, 70%, 60%, 50%, 40%, 30%, 20%, 10%, 0%.
Diberikan sebuah query (q) nilai precision dan recall untuk kurva precision
recall akan dibentuk berdasarkan perhitungan dari keseluruhan dokumen yang di-
retrieve, dimulai dari ranking yang teratas (a = 1) hingga ranking terakhir (a =
jumlah dokumen yang di-retrieve).
Agar untuk tiap query documen yang di-retrieve dipastikan dapat memenuhi
syarat dari seluruh level recall yang sudah ditentukan, dan untuk mehilangkan

56
gejolak pada kurva precision recall maka digunakan Precision interpolasi yang
dirumuskan:
Precision interpolasi pada suatu titik r didefinsikan sebagai nilai precision
terbesar pada semua titik recall .
2.5.2.1 Average Precision Pada 11 Level Recall
Dimana
: Rata-rata precision pada level recall ke-r
: Jumlah dari query yang dilakukan
: Precision pada level recall ke-r untuk query ke-i
2.5.2.2 Mean Average Precision (MAP)
Mean average precision memberikan sebuah nilai tunggal terhadap seluruh titik
recall, dari seluruh pengukuran Mean Average Precision dan sudah terbukti dapat
menunjukkan tingkat perbedaan dan stabilitas yang baik. (Cambridge University
Press:2010, pg 159).

57
Mean average precision akan dihitung terhadap sejumlah k dokumen teratas
dari dokumen yang di-retrieve dan relevan, dan angkanya akan dirata-ratakan sesuai
dengan kebutuhan informasi user.
Mean Average Precision hanya akan mempehitungkan dokumen yang relevan
saja, dengan menggunakan Mean Average Precision level recall tidak ditetapkan
secara baku, dan sehingga tidak ada interpolasi. Mean Average Precision untuk
sebuah koleksi dokumen merupakan rata-rata precision untuk sebuah kebutuhan
informasi.
2.5.2.3 Precision@K
Pengukuran MAP dan Average Precision pada 11 level recall akan
menganalisis seluruh data yang di-retrieve sedangkan untuk sebuah aplikasi seperti
web search, yang terpenting adalah berapa banyak hasil yang relevan di halaman
pertama atau untuk tiga halaman pertama, hal ini dapat digambarkan dengan
menggunakan pengukuran Precision@K, dimana K merupakan batas pengukuran.