gvyhvdxhy
DESCRIPTION
t5fg7ygyTRANSCRIPT

BAB VI
BASIS DATA TERDISTRIBUS
(DISTRIBUTED DATABASE)
6.1 BASIS DATA TERDISTRIBUSI (BDT)
adalah sekumpulan database yang saling terhubung secara logikal dan secara fisik terdistribusi pada berbagai
tempat melalui jaringan komputer.
Sistem Manajemen Basis Data Terdistribusi (SMBDT)/Distributed Database Management System (DDBMS)
Software yang mengelola BDT dan menyediakan mekanisme agar distribusi tersebut transparent di hadapan
user.
Distributed Database System (DDBS) /Sistem Basis Data Terdistribusi (SBDT) adalah DDB yang
menggunakan DDBMS.
6.1.1 CIRI-CIRI SISTEM YANG BUKAN MERUPAKAN SBDT
Ciri-ciri untuk sistem yang bukan merupakan SBDT adalah :
1. Sistem yang berupa sekumpulan file.
2. Berbagai arsitektur fisik berkait dengan sistem multiprocessor berikut:
a. Shared Memory Multiprocessor (disebut juga dengan tightly couple)
Multiprosesor dengan memori yang saling berbagi. Jika share memory merupakan primary memory, maka
sistem multiprosesor ini disebut shared memory/tightly coupled.
CPU CPU CPU
MEMORY
I/O System
b. Shared Disc Multiprocessor (disebut juga dengan loosely couple)
Multiprosesor dengan memori yang saling berbagi. Jika share memory merupakan secondary memory,
maka disebut shared disk/loosely coupled.
SHARED SECONDARY
STORAGE
CPU
MEMORY
CPU
MEMORY
CPU
MEMORY
c. Shared Nothing Multiprocessor System
Model shared nothing adalah tiap prosesor masing-masing mempunyai memori primer dan sekunder
maupun periperalnya yang berkomunikasi dengan prosesor lain melalui high speed interconect (misalnya
bus atau switch)
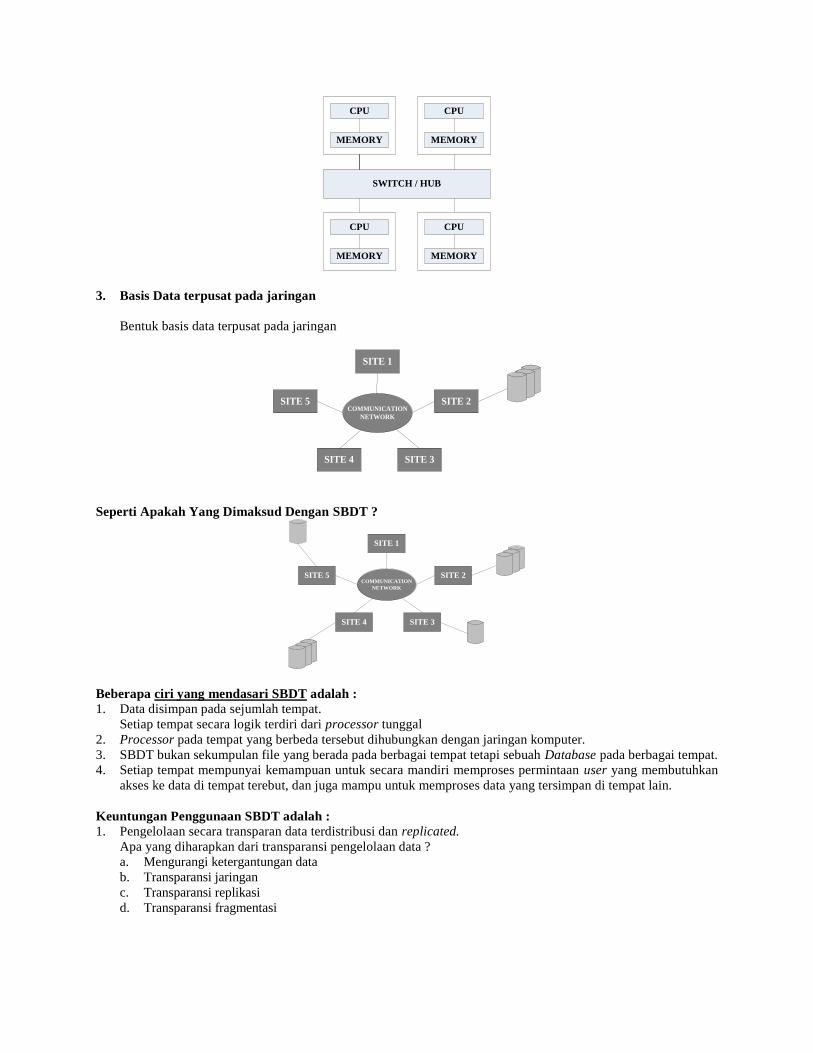
SWITCH / HUB
CPU
MEMORY
CPU
MEMORY
CPU
MEMORY
CPU
MEMORY
3. Basis Data terpusat pada jaringan
Bentuk basis data terpusat pada jaringan
COMMUNICATION
NETWORK
SITE 1
SITE 2
SITE 3SITE 4
SITE 5
Seperti Apakah Yang Dimaksud Dengan SBDT ?
COMMUNICATION
NETWORK
SITE 1
SITE 2
SITE 3SITE 4
SITE 5
Beberapa ciri yang mendasari SBDT adalah :
1. Data disimpan pada sejumlah tempat.
Setiap tempat secara logik terdiri dari processor tunggal
2. Processor pada tempat yang berbeda tersebut dihubungkan dengan jaringan komputer.
3. SBDT bukan sekumpulan file yang berada pada berbagai tempat tetapi sebuah Database pada berbagai tempat.
4. Setiap tempat mempunyai kemampuan untuk secara mandiri memproses permintaan user yang membutuhkan
akses ke data di tempat terebut, dan juga mampu untuk memproses data yang tersimpan di tempat lain.
Keuntungan Penggunaan SBDT adalah :
1. Pengelolaan secara transparan data terdistribusi dan replicated.
Apa yang diharapkan dari transparansi pengelolaan data ?
a. Mengurangi ketergantungan data
b. Transparansi jaringan
c. Transparansi replikasi
d. Transparansi fragmentasi

COMMUNICATION
NETWORK
Tokyo
Paris
MontrealNew York
BostonITLM
Boston Projects
Boston Employees
Boston Assignments
Boston Projects
New York Employees
New York Projects
New York Assignments
Paris Projects
Paris Employees
Paris Assignments
Boston Employees
Montreal Projects
Paris Projects
New York Projects
with budget >200000
Montreal Employees
Montreal Assignments 2. Mengacu pada struktur organisasi.
3. Meningkatkan kemampuan untuk berbagi dan otonomi lokal.
Melakukan penyebaran data memungkinkan kelompok lokal melakukan kendali yang lebih mandiri pada data-
data mereka. Pada gilirannya ini memungkinkan perbaikan pada integritas data dan perbaikan pada
administrasi data. Pada saat yang sama, pengguna-pengguna dapat mengakses data yang tidak bersifat lokal
saat dibutuhkan. Perangkat keras dapat dipilih untuk lokasi lokal agar sesuai dengan kebutuhan pemrosesan
lokal.
4. Meningkatkan ketersediaan data.
5. Meningkatkan kehandalan.
Saat sistem terpusat mengalami kegagalan, basis data menjadi tidak dapat digunakan oleh pengguna. Sistem
tersebar akan terus berfungsi (dengan kekurangan tertentu) saat salah satu komponennya mengalami
kegagalan.
6. Meningkatkan unjuk kerja.
7. Menudahkan pengembangan sistem.
8. Pertumbuhan secara modular.
Misalkan organisasi berkembang/berekspansi ke lokasi yang baru atau menambah kelompok kerja (work-
group) maka sering kali lebih mudah dan lebih ekonomis untuk menambah komputer lokal dan data-data yang
berhubungan pada jaringan tersebar alih-alih mengembangkan komputer besar terpusat. Juga dengan sistem
tersebar, kemungkinan terjadinya kekacauan pada pengguna lebih kecil saat komputer pusat dimodifikasi atau
dikembangkan.
9. Biaya komunikasi yang lebih rendah.
Dengan sistem tersebar, data dapat dilokalisasi dekat dengan pengguna yang membutuhkan. Hal ini akan
mengurangi biaya komunikasi dibandingkan dengan sistem terpusat.
10. Waktu tanggap yang lebih baik.
Bergantung pada bagaimana data disebarkan, kebanyakan permintaan data dapat dipenuhi dengan data yang
tersimpan pada lokasi yang bersangkutan tempat permintaan itu dilakukan. Ini mempercepat proses Query dan
penundaan (delay) oleh komputer pusat dapat diminimisasi. Juga mungkin untuk memecah Query yang
kompleks ke subQuery-subQuery bagiannya sehingga dapat diproses secara paralel pada lokasi-lokasi yang
berbeda; hasilnya adalah Query yang lebih cepat.
Kerugian Penggunaan SBDT adalah :
1. Kompleksitas manajemen
2. Kontrol integritas lebih sulit
3. Biaya pengembangan
4. Keamanan
5. Kurang standarisasi
6. Menambah kebutuhan penyimpanan
7. Lebih sulit dalam mengatur lingkungan data
8. Menambah biaya pelatihan
9. Harga software yang mahal
10. Kemungkinan kesalahan lebih besar
11. Biaya pemrosesan tinggi

6.1.2 KOMPONEN SOFTWARE DIDALAM MENGEMBANGKAN DATABASE TERDISTRIBUSI
Komponen software di dalam mengembangkan Database terdistribusi adalah :
1. The Database management component (DB)
2. The data communication component (DC)
3. The data dictionary (DD), which is extended to represent information about the distribution of data in the
network
4. The distributed Database component (DDB)
Local
Database 1
DB DC
DDDDB
DD
DCDDB
DB
SITE 1
SITE 2
T T T
T T T
Local
Database 2
Tipe sistem di atas adalah mensupport :
1. Remote Database access by an application program. Feature ini sangat penting dan harus disediakan oleh
semua sistem yang memiliki komponen Database terdistribusi.
2. Some degree of distribution transparency.
Support for Database administration and control. Feature ini termasuk tool untuk memonitor Database,
menggabungkan informasi menyangkut penggunaan Database dan keberadaan file-file data pada site yang
berbeda.
6.1.3 MODEL ARSITEKTUR DBMS
Model arsitektur untuk DBMS adalah sebagai berikut:
Gambar. Alternatif -alternatif implementasi DBMS
A. Autonomy
Autonomy mengacu pada pendistribusian kontrol, bukan pada data.
Autonomy dikelompokkan atas :
1. Tight Integration
Image tunggal dari keseluruhan Database tersedia untuk semua user yang ingin berbagi informasi yang terdapat
pada banyak Database. User hanya melihat data secara logikal tersimpan pada satu Database pada satu tempat.
2. Semi Otonomous
DBMS dapat beroperasi secara independen tetapi akan bekerja secara bersama untuk membuat lokal data dapat
dipakai bersama-sama.
3. Isolasi Total
Satu sistem memiliki satu DBMS dan tidak dapat berkomunikasi dengan DBMS yang lain.

* Alternatif arsitektural Autonomy :
A (autonomy), 0=tight integration, 1=semiaoutonomous systems, 2=total isolation
B. Distribution
Merupakan kebalikan dari autonomy, distribusi merujuk ke data. Terdapat dua alternatif, yaitu : distribusi
client/server dan distribusi peer-to-peer (full distribusi).
1. Distribusi client/server. Server menyediakan data management sedangkan client menyediakan aplikasi termasuk user interface.
a. Multiple client-single server dari sudut pandang manajemen data tidak berbeda dengan centralized
Database sepanjang data hanya terletak di satu server.
b. Multiple client-multiple server. Ada dua alternatif strategi manajemen :
- Fungsi data manajemen dipusatkan pada server.
- Tiap client mengetahui home servernya dan kemudian berkomunikasi dengan server lain bila
dibutuhkan. Pendekatan ini memudahkan server, tapi membebani mesin client dengan
penambahan tanggung jawab. (lebih mirip ke peer-to-peer)
Op
ea
rtin
g
Sy
stem
User
Interface
Application
Program…..
Client DBMS
Communication Software
Communication Software
Semantic Data Controller
Query Ortimizer
Transaction Manager
Recovery Manager
Runtime Support Processor
O
p
e
r
a
t
I
n
gS y s t e m
SQL
queries
Result
relation
Database
2. Distribusi peer-to-peer (full distribusi).
Tidak ada perbedaan antara mesin client dan mesin server. Setiap mesin mempunyai fungsi DBMS utuh
dan dapat berkomunikasi dengan mesin yang lain untuk mengeksekusi Query dan transaksi.
a. Arsitektur umum DBMS telah dijabarkan sebelumnya.
b. Physical data organization tiap mesin bisa jadi berbeda. Berarti dibutuhkan individual internal schema
pada tiap site, disebut local internal schema (LIS).
c. Enterprise view dijabarkan oleh global conceptual schema (GCS)
d. Telah diterangkan bahwa data pada distributed Database biasanya difragmenasi dan direplikasi. Untuk
menghandlenya pengorganisasian data secara logis di tiap site perlu dijabarkan, sehingga dibutuhkan a
third layer dalam arsitektur ini yaitu local conceptual schema (LCS).
e. Akhirnya aplikasi dan pengaksesan user ke Database dilayani oleh external schemas (ESs).

External
view
External
view
External
view
Conceptual
view
Internal
view
Users
External
Schema
Conceptual
Schema
Internal
Schema
* Alternatif arsitektural Distribution :
D (distribution), 0=no distribution, 1=client/ server, 2=peer-to-peer
C. Heterogeneity.
Heterogeneity merupakan keragaman bentuk di dalam distributed systems, mulai dari hardware heterogeinity hingga
networking protocols. Utamanya adalah keragaman menyangkut model data, bahasa Query dan transaction
management protocols.
Heterogen bisa terjadi pada hardware atau pada sebagian protokol jaringan atau perbedaan manajer data.
* Alternatif arsitektural Heterogeneity :
H (heterogeinity), 0 = homogeneous systems, 1 = heterogenous systems
Arsitektur SBDT jika dipandang dari fungsi setiap komponen dari struktur dapat dibagi menjadi 3 yaitu :
1. Client-Server System
2. Collaborating System
2. Middleware System
1. Client-Server System
Sistem berbasis client-server memiliki satu atau lebih client proses dan satu atau lebih server proses. Client
proses dapat mengirimkan sebuah Query ke beberapa server proses. Client bertanggung jawab terhadap layanan
antar muka dan server bertanggung jawab untuk mengatur data dan mengeksekusi transaksi.
Arsitektur berbasis client-server ini sangat populer karena beberapa alasan :
Sederhana dalam implementasi karena adanya pemisahan fungsi dan pemusatan server.
Mesin server yang mahal menjadi tidak mubazir karena client mesin yang murah dapat mengoptimalkan
kerja server
User lebih familiar menjalankan antar muka grafis pada mesin client, daripada pada mesin server.
Yang harus diingat saat menulis aplikasi pada sistem berbasis client-server adalah membedakan antara sisi
client dan sisi server serta harus tetap mempertahankan komunikasi antara keduanya seefisien mungkin.
Khususnya jika kita membuka jalur dan kemudian mengambil data dari server dapat menimbulkan beban di
jaringan. Yang masih perlu dipelajari adalah menyimpan sementara (cache) pada sisi client untuk mengurangi
kepadatan jalur jaringan, meskipun harus tetap memperhatikan status data.
2. Collaborating System
Arsitektur client-server tidak dapat mengirimkan sebuah Query tunggal untuk dikerjakan oleh beberapa
server, hal ini disebabkan client proses harus dapat memecah sebuah Query menjadi beberapa subQuery untuk
dieksekusi pada beberapa lokasi dan kemudian menggabungkan potongan jawaban ke subQuery yang lain. Hal
ini mengakibatkan client proses mengerjakan pekerjaan yang sangat kompleks sehingga tidak dapat dibedakan
dengan server proses.

Kesulitan di atas diatasi dengan collaborating server system yang memungkinkan untuk memiliki beberapa
server Database dan setiap server proses dapat menjalankan transaksi menggunakan data lokal kemudian secara
bersama-sama mengeksekusi transaksi yang melibatkan banyak server.
Ketika sebuah server menerima Query yang membutuhkan akses ke data pada lain server, maka server
akan membangkitkan subQuery yang sesuai untuk dieksekusi oleh server yang lain dan kemudian mengambil
hasil Query tersebut untuk digunakan sebagai data agar dapat menghasilkan hasil akhir yang diminta Query
awal. Yang harus diperhatikan adalah proses pemecahan Query menjadi sub Query harus mempertimbangkan
biaya komunikasi jaringan.
3. Middleware System
Arsitektur middleware memungkinkan Query tunggal untuk dikerjakan oleh banyak server, tetapi tidak perlu
semua server Database dapat melakukan strategi eksekusi Query pada banyak server. Ide ini muncul karena
hanya ada satu server Database yang dapat mengatur Query dan transaksi pada banyak server, tetapi server
yang lain hanya dapat menangani Query lokal dan transaksi lokal. Kita memiliki server khusus yang memiliki
software untuk mengkoordinasikan eksekusi Query dan transaksi untuk beberapa server Database lainnya.
Software ini disebut middleware. Pada sisi middleware akan dapat melakukan eksekusi join dan operator relasi
lain yang diperoleh dari server lain, tetapi server ini tidak mengatur data sendiri.
6.2 DATA WAREHOUSE
Prepository (arsip) informasi yang dikumpulkan dari banyak sumber disimpan pada skema yang disatukan di
satu situs tunggal.
Basis data dimana data dikumpulkan dari banyak sistem untuk mendukung pelaporan dan pengambilan
keputusan manajemen.
Begitu data dikumpulkan, data disimpan selama waktu yang lama. Data warehouse menyediakan satu
antarmuka terkonsolidasi tunggal, mempermudah pembuatan Query yang mendukung pembuatan keputusan.
Dengan mengakses informasidari Data warehouse, pembuat keputusan menjamin sistem pengolahan transaksi
online nya tidak terganggu.
Karakteritsik Data Warehouse
1. Data dikumpulkan dari sumber-sumber lain seperti sistem lama ataupun sistem OLTP
2. Data dibuat konsisten dengan menyimpan di data warehouse
3. Data diringkas. Data warehouse umumnya tidak menyimpan serinci sistem berorientasi transaksi
4. Data berumur lebih lama. Sistem transaksi dapat mempertahankan data hanya sampai selesainya transaksi,
sedangkan data warehouse dapat mempertahankan data sampai bertahun-tahun
5. Data disimpan dalam suatu format yang nyaman untuk melakukan Query dan analisis
6. Data biasanya read-only
Data warehouse memungkinkan pemakai memeriksa data historis untuk melakukan analisis terhadap data
ini dalam beragam cara dan membuat keputusan didasarkan pada hasil analisis. Data warehouse menggunakan
beragam teknologi seperti mesin basis data dan kakas Query, perangkat keras komputer SMP (Symmetric
multiprocessing) dan RAID (Redundant Array of Inexpensive Disk). Semua teknologi ini tanpa guna bila pemakai
tidak dapat memperoleh jawaban atas pertanyaannya secara cepat dan mudah. Begitu terbangun data warehouse,
perusahaan mempunyai sumber data skala perusahaan yang konsisten yang memungkinkan jawaban yang cepat.
Data warehouse adalah satu metode penyimpanan data historis dan terpadu untuk sistem pendukung
keputusan atau sistem intelijen bisnis (busines intelegence system). Data warehouse adalah pemisahan secara fisik
antara sistem fisik antara sistem data operasional dengan sistem data untuk pendukung pengambilan keputusan.
Data warehouse beroperasi pada satu Database, atau campuran banyak basis data perusahaan. Data
warehouse membantu transformasi data menjadi pengetahuan sehingga membantu perusahaan berkompetisi. Pada
data warehouse, data diekstraksi dari banyak sistem sumber, dipadukan dan ditransformasi sebelum dimuatkan ke
data warehouse.
Tujuan dari Data Warehouse
1. Menyediakan sumber tunggal informasi koorporasi yang handal dan tunggal

2. memberi pemakaian akhir sarana pengaksesan data tanpa bergantung pada laporan-laporan yang dihasilkan
bagian sistem informasi
3. memungkinkan analis bisnis menganalisa data korporasi, bahkan memodelkan “what-if” prediktif dari data.
Isu-isu di Data Warehouse
1. Kapan dan bagaimana mengumpulkan data
2. Skema apa yang digunakan
3. Pembersihan/pemusnahan data (data cleansing)
4. Bagaimana cara melakukan propagasi pembaharuan-pembaharuan
5. Data apa yang diringkas
6.2.1 Siklus Hidup Dan Manfaat Data Warehouse
Gambar siklus Hidup Data Warehouse
Da
ta
Wa
reh
ou
se
Source OLTP
Systems
Transformatin
tools
Data marts
Cubes
Clients
Metadata
Data di satu atau banyak OLTP merupakan sumber data untuk data warehouse. Data di sistem sumber
melewati proses ETL-C (extracting, transforming, loading – atau disertai cleansing) menggunakan kakas
transformasi. Data warehouse yang terbentuk dapat dianalisis per bagian yang disebut data mart melalui Query
secara langsung terhadap data mart atau dipandang sebagai struktur multidimensi (hypercubes).
Data Mart adalah :
1. Data Mart (departmental data warehouse) adalah sistem yang mengumpulkan data yang dibutuhkan sebuah
departemen atau aplikasi yang terkait.
2. Data Mart dapat diimplementasikan di data warehouse dengan cara membuat view khusus, spesifik aplikasi
tertentu.
3. Data Mart dapat juga diimplementasikan sebagai materialized view suatu departemen yang fokus pada subjek
tertentu. Materialized view adalah view yang tupel hasil disimpan.
4. Data Mart dapat memiliki representasi berbeda dan menggunakan OLAP engineI sendiri.
6.2.2 Manfaat Data Warehouse
Secara garis besar data warehouse dapat meningkatkan produktivitas pembuat keputusan melalui
konsolidasi, konversi, transformasi, dan pemaduan data operasional sehingga menyediakan pandangan konsisten
terhadap perusahaan.
Manfaat-manfaat yang diperoleh antara lain :
1. Kemampuan mengkases data yang berskala perusahaan
2. Kemampuan memiliki data yang konsisten
3. Kemampuan melakukan analisis secara cepat
4. Dapat digunakan untuk mencari redundansi usaha di perusahaan
5. penemuan gap anatara pengetahuan bisnis atau proses bisnis
6. Merendahkan ongkos administrasi
7. Memberdayakan anggota perusahaan dengan informasi yang diperlukan untuk melakukan tugasnya secara
efektif.

Teknik-teknik analisis dan pengambilan keputusan yang didukung antara lain :
1. Data Mining
Proses ekstraksi informasi yang belum diketahui sebelumnya namun signifikan dari basis data besar dan
menggunakannya untuk membantu pembuatan keputusan bisnis penting.
2. Kakas intelijensia bisnis
Membantu pemakai menentukan jenis informasi yang diperlukan untuk dianalisis dan cara pengaksesan serta
analisis informasi itu.
3. Analisis data multidimensi
Melakukan fungsi statistik dan matematika, peramalan dan pemodelan multidimensi.
4. Kakas Query terhadap data warehouse
Melacak operasi-operasi bisnis sehari-hari dan mendukung kepurtusan bisnis taktis.
6.2.3 Arsitektur Data Warehouse
Gambar arsitektur data warehouse adalah :
Data
Source
Data
Source
Data
Source
BATCHING ENGINE
TM
P
DB
Preparing Staging Area Metadata
Schedular Agent
Extracting, Transforming, Loading (ETL)
DP
A
DB
DW
H
DB
Schedular Agent
OLAP ENGINE
DP
A
DB
OLAP REPORT APPLICATION
Perform batching copy from
OLTP DB to temporary DB
Done with MSSQL Enterprise
Manager Tools
Perform periodic caller to ETL
1. Extracts from TMPDB
2. Mapping Data
3. Summarize Data
4. Break Down Data
5. Apply Surrogate Keys
6. Cleanse Data
7. Load Data from DPA to
Warehouse Database
Perform Periodic Cube
Definition from DWH DB
6.2.4 Karakteristik dan Ciri Data Warehouse
Karakteristik data warehouse adalah :
1. Berorientasi sunjek, berarti data warehouse berfokus pada entitas-entitas bisnis level tinggi. Hal ini berbeda
dengan sistem operasional yang lebih berurusan langsung dengan proses operasi sehari-hari.
2. Terpadu, berarti data tersimpan dalam terformat yang konsisten (dalam konvensi penanaman, konstrain domain,
atribut fisik, dan pengukuran).
3. Data diringkas. Data warehouse biasanya tidak dijaga agar serinci di sistem transaksi.
4. Data disimpan dalam format yang nyaman untuk Query dan analisis.
5. Data biasanya bersifat read-only.
6.2.5 Pemodelan Pada Data Warehouse
Data Warehouse model berbasis pada dimensi, hirarki, fakta dan sparsity.
Karakteristik model data warehouse adalah sebagai berikut :
1. Data ringkasan untuk dukungan keputusan dan analisis
2. Banyak level peringkasan
3. Data yang jarang diperbaharui
4. Data terpadu dari banyak sumber

5. Rancangan diarahkan oleh kebutuhan informasi yang berevolusi
6. Berorientasi area bisnis, fungsi atau subjek
7. Menyediakan informasi terpadu melewati bagian perusahaan
8. Granularitas dta untuk analisis melampaui periode waktu yang diperluas
9. Secara interaktif dibangun oleh area subjek
10. Menyediakan data bersih, handal untuk data mart atau dukungan keputusan area bisnis.
6.2.6 Skema Bintang
Basis data multidimensi yang merupakan basis sistem OLAP multidimensi memberikan solusi berorientasi
basis untuk menjawab pertanyaan kompleks. Pendekatan ini mempunyai tingkat keberhasilan tinggal ketika
jawaban paling sering disusun dari matriks atau data kuantitatif. Product dimension
Organization dimension
Sales fact
Store dimension
Time dimension
Product key
Product name
Product size
Product form
Product package
Product dept
Product cat
Product subcat
...
Organization key
Division name
Area name
Region name
Market name
....
Product key
Units sold qty
local currency sale
amt
US$ sale amount
US$ cost amount
product gross margin
intercompany profit
royalty amount
….
Organization key
Store key
Time key
Time key
Time date
week
month
quarter
year
….
Store key
Store name
Store address
Store manager
Floor plan type
Store size
...
Karakteristik utama skema bintang :
1. Pusat skema bintang adalah tabel fakta (fact table)
2. Tabel fakta berisi indikator-indikator kinerja pokok (KPI – key performance indicators)
3. Indikator-indikator kinerja pokok adalah atribut-atribut dari tabel fakta
4. Objek-objek informasi dan waktu adalah kunci utama di tabel fakta
5. tabel-tabel yang di sekeliling tabel fakta adalah tabel dimensi
6. Tabel dimensi berisi data mengenai objek-objek informasi atau waktu
7. Tabel fakta dan dimensi di-join dengan kunci banyak bagian di tabel fakta
8. Skema bintang diimplementasikan menggunakan teknologi basis data relasional.
6.2.7 Hirarki Dimensi
Hirarki dimensi merupakan hubungan parent-childs.
Anggota hirarki disusun umum menuju keanggota lebih spesifik.
Grocery
Drinks
Soda
Deli
Meat
Paper
Beer
Bottled Water
Cola
Orange
Grape
Salah satu pokok keberhasilan implementasi data warehouse adalah perancangan. Perancangan sistem
meliputi :
1. Perancangan kapasitas pendefinisian arsitektur

2. Integrasi servers, media penyimpanan, clients
3. Perancangan skema data warehouse, views
4. Perancangan organisasi fisik data warehouse, penempatan data, partisi, metode akses
5. Menghubungkan sumber : gateways, ODBC drivers
6. Perancangan metadata dan pengisian aplikasi pengguna
7. Membuat data warehouse dan aplikasi
Pembangunan data warehouse dapat dilakukan dengan dua cara, yaitu:
1. Top Down
a. Membuat perancangan data warehouse keseluruhan
b. Menentukan sumber data dan mekanisme pemanduan data ke data warehouse
2. Bottom Up
a. Membuat data marst untuk setiap sub sistem yang ada
b. Menggabungkan data marts untuk menghasilkan data warehouse utuh
6.3 DATA MINING
Data Mining (DM) adalah salah satu bidang yang berkembang pesat karena besarnya kebutuhan akan nilai
tambah dari Database skala besar yang makin banyak terakumulasi sejalan dengan pertumbuhan teknologi
informasi. Definisi umum dari DM itu sendiri adalah serangkaian proses untuk menggali nilai tambah berupa
pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data.
Perkembangan data mining(DM) yang pesat tidak dapat lepas dari perkembangan teknologi informasi yang
memungkinkan data dalam jumlah besar terakumulasi. Sebagai contoh, toko swalayan merekam setiap penjualan
barang dengan memakai alat POS(point of sales). Database data penjualan tersebut. bisa mencapai beberapa GB
setiap harinya untuk sebuah jaringan toko swalayan berskala nasional. Perkembangan internet juga punya andil
cukup besar dalam akumulasi data.
Tetapi pertumbuhan yang pesat dari akumulasi data itu telah menciptakan kondisi yang sering disebut
sebagai “rich of data but poor of information” karena data yang terkumpul itu tidak dapat digunakan untuk aplikasi
yang berguna. Tidak jarang kumpulan data itu dibiarkan begitu saja seakan-akan “kuburan data” (data tombs).
DM adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan
yang selama ini tidak diketahui secara manual. Patut diingat bahwa kata mining sendiri berarti usaha untuk
mendapatkan sedikit barang berharga dari sejumlah besar material dasar. Karena itu DM sebenarnya memiliki akar
yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistik dan
database.
Beberapa teknik yang sering disebut-sebut dalam literatur DM antara lain : clustering, classification,
association rule mining, neural network, genetic algorithm dan lain-lain.
Yang membedakan persepsi terhadap DM adalah perkembangan teknik-teknik DM untuk aplikasi pada
database skala besar. Sebelum populernya DM, teknik-teknik tersebut hanya dapat dipakai untuk data skala kecil
saja.
Di sini, penulis mencoba untuk memberi gambaran sekilas atas perkembangan terakhir teknik-teknik DM
sambil memberikan juga ilustrasi pemakaian di dunia bisnis. Penulis juga menyajikan pengertian konfigurasi
penyimpanan data yang memudahkan pemakai untuk
melakukan DM yang umum disebut dengan data warehouse.
Proses Data Mining
Disini akan diuraikan tahap-tahap DM dan pengertian data warehouse. Tahap-Tahap Data Mining Karena
DM adalah suatu rangkaian proses, DM dapat dibagi menjadi beberapa tahap yang diilustrasikan berikut:

1. Pembersihan data (untuk membuang data yang tidak konsisten dan noise)
2. Integrasi data (penggabungan data dari beberapa sumber)
3. Transformasi data (data diubah menjadi bentuk yang sesuai untuk di-mining)
4. Aplikasi teknik DM
5. Evaluasi pola yang ditemukan (untuk menemukan yang menarik/bernilai)
6. Presentasi pengetahuan (dengan teknik visualisasi)
Tahap-tahap tersebut bersifat interaktif di mana pemakai terlibat langsung atau dengan perantaraan
knowledge base.
6.4 DATA MINING
Biasanya perusahaan-perusahaan memakai Database dalam operasi sehari-harinya seperti pencatatan
transaksi jual-beli, administrasi pengiriman barang, inventori, penggajian dsb yang lazim disebut dengan OLTP
(Online TransactionPprocessing). Dengan makin besarnya kebutuhan akan analisa data untuk mempertahankan
keunggulan dalam kompetisi, banyak perusahaan yang juga membangun Database tersendiri yang khusus digunakan
untuk menunjang proses pengambilan keputusan (Decision Making) atau lazim juga disebut dengan OLAP (Online
Analytical Processing).
Perbeda dengan OLTP yang hanya memakai operasi Query yang sederhana dan berulang-ulang, Query
untuk OLAP biasanya lebih rumit, bersifat adhoc, dan tidak melibatkan operasi data update. OLAP juga tidak
memakai data operasi sehari-hari begitu saja, tetapi memakai data yang sudah terangkum dengan model data yang
disebut data cube. Data cube adalah presentasi data multidimensi seperti jenis barang, waktu, lokasi dsb. Ilustrasi
dari data cube ditunjukkan di gambar berikut :
Dimensi pada data cube dapat dibuat bertingkat, contohnya dimensi lokasi dapat dibagi menjadi kota,
propinsi dan negara. Sedangkan dimensi waktu mencakup jam, hari, minggu, bulan, tahun dsb. Dengan ini pemakai
dapat dengan mudah mendapat rangkuman informasi dari tingkatan dimensi yang lebih luas/umum seperti negara
atau tahun dengan operasi yang disebut roll-up seperti ditunjukkan di diatas. Sebaliknya dengan operasi drill-down,
pemakai dapat menggali informasi dari tingkatan dimensi yang lebih detil seperti data harian atau data di lokasi yang
spesifik.

Data cube yang tersedia pada data warehouse memungkinkan pemakai untuk menganalisa data operasi
sehari-hari dengan berbagai sudut pandang, dan sangat berguna untuk mengevaluasi suatu asumsi bisnis. Akan tetapi
untuk mendapatkan informasi yang tidak diketahui secara eksplisit diperlukan satu tahap lagi yaitu aplikasi teknik
DM. Disini data warehouse merupakan data mentah untuk DM. Data warehouse sendiri secara periodik diisi data
dari OLTP setelah menjalani pembersihan dan integrasi data. Karena itu ada pula anggapan bahwa DM adalah tahap
lanjut dari OLAP.
6.4.1 TEKNIK-TEKNIK DATA MINING
Dengan definisi DM yang luas, ada banyak jenis teknik analisa yang dapat digolongkan dalam DM. Karena
keterbatasan tempat, disini penulis akan memberikan sedikit gambaran tentang tiga teknik DM yang paling populer.
1. Association Rule Mining
Association rule mining adalah teknik mining untuk menemukan aturan assosiatif antara suatu kombinasi
item. Contoh dari aturan assosiatif dari analisa pembelian di suatu pasar swalayan adalah bisa diketahui berapa
besar kemungkinan seorang pelanggan membeli roti bersamaan dengan susu. Dengan pengetahuan tersebut.
pemilik pasar swalayan dapat mengatur penempatan barangnya atau merancang kampanye pemasaran dengan
memakai kupon diskon untuk kombinasi barang tertentu. Penting tidaknya suatu aturan assosiatif dapat
diketahui dengan dua parameter, support yaitu persentase kombinasi item tersebut. dalam Database dan
confidence yaitu kuatnya hubungan antar item dalam aturan assosiatif.
Algoritma yang paling populer dikenal sebagai Apriori dengan paradigma generate and test, yaitu
pembuatan kandidat kombinasi item yang mungkin berdasar aturan tertentu lalu diuji apakah kombinasi item
tersebut memenuhi syarat support minimum. Kombinasi item yang memenuhi syarat tersebut disebut frequent
itemset, yang nantinya dipakai untuk membuat aturan-aturan yang memenuhi syarat confidence minimum.
Algoritma baru yang lebih efisien bernama FP-Tree.
2. Classification
Classification adalah proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan
konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak
diketahui. Model itu sendiri bisa berupa aturan “jika-maka”, berupa decision tree, formula matematis atau
neural network.
Decision tree adalah salah satu metode classification yang paling populer karena mudah untuk
diinterpretasi oleh manusia. Contoh dari decision tree dapat dilihat di pada gambar diatas. Disini setiap
percabangan menyatakan kondisi yang harus dipenuhi dan tiap ujung pohon menyatakan kelas data. Contoh
pada gambar diatas adalah identifikasi pembeli komputer, dari decision tree tersebut. Diketahui bahwa salah
satu kelompok yang potensial membeli komputer adalah orang yang berusia di bawah 30 tahun dan juga pelajar.
Algoritma decision tree yang paling terkenal adalah C4.5, tetapi akhir-akhir ini telah dikembangkan
algoritma yang mampu menangani data skala besar yang tidak dapat ditampung di main memory seperti
RainForest. Metode-metode classification yang lain adalah Bayesian, neural network, genetic algorithm, fuzzy,
case-based reasoning, dan k-nearest neighbor. Proses classification biasanya dibagi menjadi dua fase : learning
dan test. Pada fase learning, sebagian data yang telah diketahui kelas datanya diumpankan untuk membentuk
model perkiraan.
Kemudian pada fase test model yang sudah terbentuk diuji dengan sebagian data lainnya untuk
mengetahui akurasi dari model tersebut. Bila akurasinya mencukupi model ini dapat dipakai untuk prediksi
kelas data yang belum diketahui.
3. Clustering

Berbeda dengan association rule mining dan classification dimana kelas data telah ditentukan sebelumnya,
clustering melakukan pengelompokan data tanpa berdasarkan kelas data tertentu. Bahkan clustering dapat dipakai
untuk memberikan label pada kelas data yang belum diketahui itu. Karena itu clustering sering digolongkan sebagai
metode unsupervised learning.
Prinsip dari clustering adalah memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan
kesamaan antar kelas/cluster. Clustering dapat dilakukan pada data yan memiliki beberapa atribut yang dipetakan
sebagai ruang multidimensi. Ilustrasi dari clustering dapat dilihat di pada gambar dibawah ini dimana lokasi
dinyatakan dengan bidang dua dimensi, dari pelanggan suatu toko dapat dikelompokkan menjadi beberapa cluster
dengan pusat cluster ditunjukkan oleh tanda positif (+).
Banyak algoritma clustering memerlukan fungsi jarak untuk mengukur kemiripan antar data, diperlukan
juga metode untuk normalisasi bermacam atribut yang dimiliki data.
Beberapa kategori algoritma clustering yang banyak dikenal adalah metode partisi dimana pemakai harus
menentukan jumlah k partisi yang diinginkan lalu setiap data dites untuk dimasukkan pada salah satu partisi, metode
lain yang telah lama dikenal adalah metode hierarki yang terbagi dua lagi : bottom-up yang menggabungkan cluster
kecil menjadi cluster lebih besar dan top-down yang memecah cluster besar menjadi cluster yang lebih kecil.
Kelemahan metode ini adalah bila bila salah satu penggabungan/pemecahan dilakukan pada tempat yang salah, tidak
dapat didapatkan cluster yang optimal. Pendekatan yang banyak diambil adalah menggabungkan metode hierarki
dengan metode clustering lainnya seperti yang dilakukan oleh Chameleon.
Akhir-akhir ini dikembangkan juga metode berdasar kepadatan data, yaitu jumlah data yang ada di sekitar
suatu data yang sudah teridentifikasi dalam suatu cluster. Bila jumlah data dalam jangkauan tertentu lebih besar dari
nilai ambang batas, data-data tersebut dimasukkan dalam cluster. Kelebihan metode ini adalah bentuk cluster yang
lebih fleksibel. Algoritma yang terkenal adalah DBSCAN.
PENERAPAN DATA MINING Sebagai cabang ilmu baru di bidang komputer (lihat artikel sebelumnya berjudul ‘Data Mining’) cukup
banyak penerapan yang dapat dilakukann oleh Data Mining. Apalagi ditunjang ke-kaya-an dan ke-anekaragam-an
berbagai bidang ilmu (artificial intelligence, Database, statistik, pemodelan matematika, pengolahan citra dsb.)
membuat penerapan data mining menjadi makin luas. Di bidang apa saja penerapan data mining dapat dilakukan?
Artikel singkat ini berusaha memberikan jawabannya.
Analisa Pasar dan Manajemen
Untuk analisa pasar, banyak sekali sumber data yang dapat digunakan seperti transaksi kartu kredit, kartu
anggota club tertentu, kupon diskon, keluhan pembeli, ditambah dengan studi tentang gaya hidup publik.
Beberapa solusi yang bisa diselesaikan dengan data mining diantaranya:
Menembak target pasar Data mining dapat melakukan pengelompokan (clustering) dari model-model pembeli dan melakukan
klasifikasi terhadap setiap pembeli sesuai dengan karakteristik yang diinginkan seperti kesukaan yang sama,
tingkat penghasilan yang sama, kebiasaan membeli dan karakteristik lainnya.
Melihat pola beli pemakai dari waktu ke waktu Data mining dapat digunakan untuk melihat pola beli seseorang dari waktu ke waktu. Sebagai contoh, ketika
seseorang menikah bisa saja dia kemudian memutuskan pindah dari single account ke joint account (rekening
bersama) dan kemudian setelah itu pola beli-nya berbeda dengan ketika dia masih bujangan.
Cross-Market Analysis Kita dapat memanfaatkan data mining untuk melihat hubungan antara penjualan satu produk dengan produk
lainnya.
Berikut ini beberapa contoh:
- Cari pola penjualan Coca Cola sedemikian rupa sehingga kita dapat mengetahui barang apa sajakah yang
harus kita sediakan untuk meningkatkan penjualan Coca Cola?

- Cari pola penjualan IndoMie sedemikian rupa sehingga kita dapat mengetahui barang apa saja yang juga
dibeli oleh pembeli IndoMie. Dengan demikian kita bisa mengetahui dampak jika kita tidak lagi menjual
IndoMie.
- Cari pola penjualan
Profil Customer Data mining dapat membantu Anda untuk melihat profil customer/pembeli/nasabah sehingga kita dapat
mengetahui kelompok customer tertentu suka membeli produk apa saja.
Identifikasi Kebutuhan Customer
Anda dapat mengidentifikasi produk-produk apa saja yang terbaik untuk tiap kelompok customer dan menyusun
faktor-faktor apa saja yang kira-kira dapat menarik customer baru untuk bergabung/membeli.
Menilai Loyalitas Customer
VISA International Spanyol menggunakan data mining untuk melihat kesuksesan program-program customer
loyalty mereka. Informasi Summary
Anda juga dapat memanfaatkan data mining untuk membuat laporan summary yang bersifat multi-dimensi dan
dilengkapi dengan informasi statistik lainnya.
Analisa Perusahaan dan Manajemen Resiko
Perencanaan Keuangan dan Evaluasi Aset Data Mining dapat membantu Anda untuk melakukan analisis dan prediksi cash flow serta melakukan
contingent claim analysis untuk mengevaluasi aset. Selain itu Anda juga dapat menggunakannya untuk analisis
trend.
Perencanaan Sumber Daya (Resource Planning) Dengan melihat informasi ringkas (summary) serta pola pembelanjaan dan pemasukan dari masing-masing
resource, Anda dapat memanfaatkannya untuk melakukan resource planning.
Persaingan (Competition)
- Sekarang ini banyak perusahaan yang berupaya untuk dapat melakukan competitive intelligence. Data Mining
dapat membantu Anda untuk memonitor pesaing-pesaing Anda dan melihat market direction mereka.
- Anda juga dapat melakukan pengelompokan customer Anda dan memberikan variasi harga/layanan/bonus
untuk masing-masing grup.
- Menyusun strategi penetapan harga di pasar yang sangat kompetitif. Hal ini diterapkan oleh perusahaan
minyak REPSOL di Spanyol dalam menetapkan harga jual gas di pasaran.
Telekomunikasi
Sebuah perusahaan telekomunikasi menerapkan data mining untuk melihat dari jutaan transaksi yang
masuk, transaksi mana sajakah yang masih harus ditangani secara manual (dilayani oleh orang). Tujuannya tidak
lain adalah untuk menambah layanan otomatis khusus untuk transaksi-transaksi yang masih dilayani secara manual.
Dengan demikian jumlah operator penerima transaksi manual tetap bisa ditekan minimal.
Keuangan
Financial Crimes Enforcement Network di Amerika Serikat baru-baru ini menggunakan data mining untuk
me-nambang trilyunan dari berbagai subyek seperti property, rekening bank dan transaksi keuangan lainnya untuk
mendeteksi transaksi-transaksi keuangan yang mencurigakan (seperti money laundry). Mereka menyatakan bahwa
hal tersebut akan susah dilakukan jika menggunakan analisis standar.
Asuransi
Australian Health Insurance Commision menggunakan data mining untuk mengidentifikasi layanan
kesehatan yang sebenarnya tidak perlu tetapi tetap dilakukan oleh peserta asuransi. Hasilnya? Mereka berhasil
menghemat satu juta dollar per tahunnya. Tentu saja ini tidak hanya bisa diterapkan untuk asuransi kesehatan, tetapi
juga untuk berbagai jenis asuransi lainnya.
Olah Raga
IBM Advanced Scout menggunakan data mining untuk menganalisis statistik permainan NBA (jumlah
shots blocked, assists dan fouls) dalam rangka mencapai keunggulan bersaing (competitive advantage) untuk tim
New York Knicks dan Miami Heat.

Astronomi
Jet Propulsion Laboratory (JPL) di Pasadena, California dan Palomar Observatory berhasil menemukan 22
quasar dengan bantuan data mining. Hal ini merupakan salah satu kesuksesan penerapan data mining di bidang
astronomi dan ilmu ruang angkasa.
Internet Web Surf-Aid
IBM Surf-Aid menggunakan algoritma data mining untuk mendata akses halaman Web khususnya yang
berkaitan dengan pemasaran guna melihat prilaku dan minat customer serta melihat ke-efektif-an pemasaran melalui
Web.
Dengan melihat beberapa aplikasi yang telah disebutkan di atas, terlihat sekali potensi besar dari penerapan
Data Mining di berbagai bidang. Bahkan beberapa pihak berani menyatakan bahwa Data Mining merupakan salah
satu aktifitas di bidang perangkat lunak yang dapat memberikan ROI (return on investment) yang tinggi. Namun
demikian, perlu diingat bahwa Data Mining hanya melihat keteraturan atau pola dari sejarah, tetapi tetap saja sejarah
tidak sama dengan masa datang. Contoh: jika orang terlalu banyak minum Coca Cola bukan berarti dia pasti akan
kegemukan, jika orang terlalu banyak merokok bukan berarti dia pasti akan kena kanker paru-paru atau mati muda.
Bagaimanapun juga data mining tetaplah hanya alat bantu yang dapat membantu manusia untuk melihat pola,
menganalisis trend dsb. dalam rangka mempercepat pembuatan keputusan. Kapankah data mining akan banyak
digunakan di Indonesia? Kita tunggu saja.