ade 3novriana bunga
TRANSCRIPT

Regresi Robust Kelompok VI:
Noveriana K.Bunga 111013011
Maria Pura 121013017

Regresi linear
Gunakan data agar sesuai dengan garis prediksi yang berhubungan variabel dependen y dan satu variabel independen x. Artinya, kita ingin menulis y sebagai fungsi linear dari x: y = 0 + 1x +
Asumsi analisis regresi
1.Relasi adalah linear sehingga kesalahan semua diharapkan nilai nol, E (ei) = 0 untuk semua I
2. Kesalahan semua memiliki varian yang sama: Var (ei) = S2E untuk semua i
3. Kesalahan yang independen satu sama lain.
4. Kesalahan yang semua terdistribusi secara normal: ei biasanya didistribusikan untuk semua i.
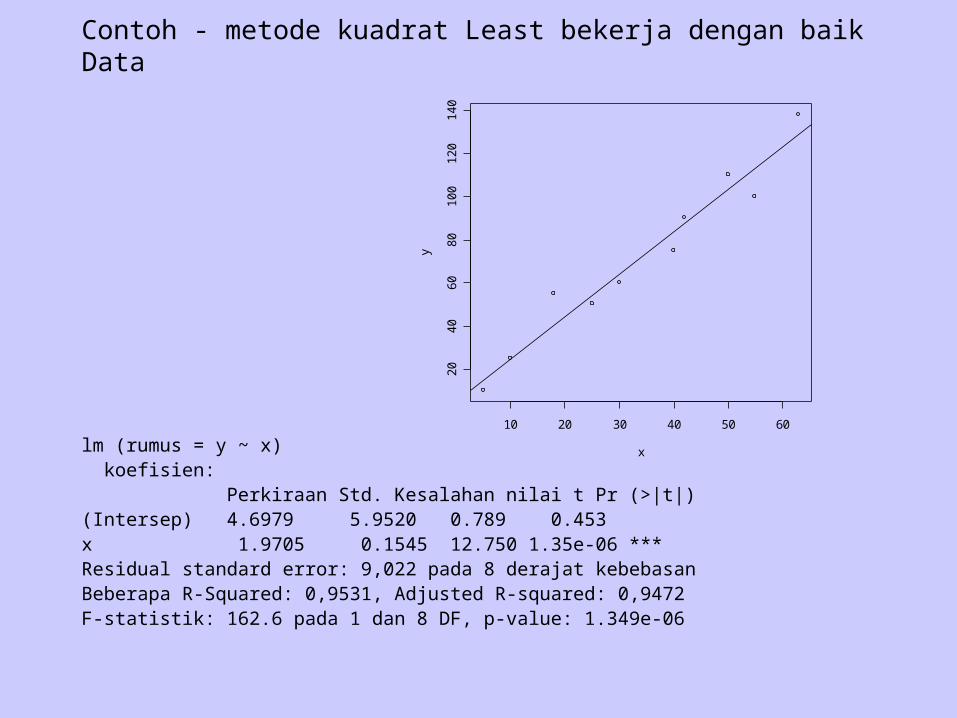
Contoh - metode kuadrat Least bekerja dengan baik Data
lm (rumus = y ~ x) koefisien: Perkiraan Std. Kesalahan nilai t Pr (>|t|) (Intersep) 4.6979 5.9520 0.789 0.453 x 1.9705 0.1545 12.750 1.35e-06 ***Residual standard error: 9,022 pada 8 derajat kebebasan Beberapa R-Squared: 0,9531, Adjusted R-squared: 0,9472 F-statistik: 162.6 pada 1 dan 8 DF, p-value: 1.349e-06
10 20 30 40 50 60
20
40
60
80
10
01
20
14
0x
y

Tapi apa yang terjadi jika data Anda memiliki outlier dan / atau tidak memenuhi asumsi analisis regresi?
Data: ponsel kumpulan data di perpustakaan MASS.
Data ini menunjukkan jumlah panggilan telepon dalam jutaan di Belgia antara tahun 1950 dan 1973. Namun, antara 1964 dan 1969 total panjang panggilan (dalam menit) tercatat bukan nomor, dan kedua sistem pencatatan yang digunakan selama bagian dari tahun 1963 dan 1970.
50 55 60 65 70
05
01
00
15
02
00
year
calls

pencilan
Pencilan dapat menyebabkan estimasi garis regresi kemiringan berubah drastis. Dalam pendekatan kuadrat terkecil kita mengukur nilai respon dalam kaitannya dengan mean. Namun, rata-rata sangat sensitif terhadap pencilan - satu pencilan dapat mengubah nilai ini sehingga memiliki titik kerusakan 0%. Di sisi lain, median tidak sensitif - itu adalah tahan terhadap kesalahan kotor dan memiliki titik kerusakan 50%. Jadi jika data tidak normal, berarti tidak mungkin ukuran terbaik dari tendensi sentral. Pilihan lain dengan titik pemecahan lebih tinggi adalah mean dipangkas.

Mengapa kita tidak bisa hanya menghapus pencilan dicurigai?
Menolak pencilan mempengaruhi teori distribusi, yang seharusnya disesuaikan. Secara khusus, varians akan diremehkan dari "dibersihkan" data.
Keputusan tajam untuk menjaga atau menolak oberservation adalah boros. Kita bisa berbuat lebih baik dengan down-bobot pengamatan ekstrim daripada menolak mereka, meskipun kita mungkin ingin menolak pengamatan benar-benar salah.
Jadi cobalah regresi robust

Apa regresi kuat dan tahan?
Regresi kuat dan tahan analisis memberikan alternatif ke kotak model yang paling saat data melanggar asumsi mendasar.
Prosedur regresi yang kuat dan tahan meredam pengaruh pencilan, dibandingkan dengan estimasi kuadrat terkecil biasa, dalam upaya untuk memberikan lebih cocok untuk sebagian besar data.
Dalam buku V & R, ketahanan mengacu pada yang kebal terhadap pelanggaran asumsi sementara resistensi mengacu untuk menjadi kebal terhadap pencilan.
Regresi yang kuat, yang menggunakan M-estimator, sangat tidak tahan terhadap pencilan dalam banyak kasus.

Telepon data dengan Least Squares, Kuat, dan garis regresi Tahan
50 55 60 65 70
05
01
00
15
02
00
year
calls
Least SquaresM-estimate (Robust)Least Trimmed Squares (Resistant)

Kontras Tiga Metode Regresi
- Least Model Persegi Linear
- Metode robust
- Metode tahan

Least Model Persegi Linear
• Adalah tradisional Regression Model Linear
• Menentukan garis pas sebagai garis yang meminimalkan Sum Square Kesalahan.
• SSE=Σ(Yi - Yi-hat)
• Jika semua asumsi terpenuhi, ini adalah estimasi terbaik berisi linear. (biru)
• Kurang kompleks dalam hal perhitungan, tapi sangat sensitif terhadap pencilan.

Regresi Robust
Adalah sebuah alternatif untuk metode Least Square ketika kesalahan non-normal.
Menggunakan metode iteratif untuk menetapkan bobot yang berbeda untuk residu sampai proses estimasi konvergen.
Berguna untuk mendeteksi pencilan dengan mencari kasus-kasus yang berat akhir relatif kecil.
Dapat digunakan untuk mengkonfirmasi kesesuaian model kuadrat terkecil biasa.
Terutama membantu dalam menemukan kasus yang terpencil sehubungan dengan nilai-nilai y mereka (kesalahan ekor panjang). Mereka tidak bisa mengatasi masalah karena struktur varians.
Lebih kompleks untuk mengevaluasi ketepatan koefisien regresi, dibandingkan dengan model yang biasa.

Salah satu metode yang kuat (V & Rp.158
M-estimator
Asumsikan f adalah pdf berskala, set ρ = - log f, estimator maksimum likelihood meminimalkan berikut untuk menemukan β ini:Σ ρ(yi-xib)/s + n log s
s adalah skala, dan itu harus ditentukan

Regresi resistant
• Tidak seperti Regresi Robust, itu model berbasis. Jawabannya selalu sama.
• Tolak semua outlier mungkin. • Berguna untuk mendeteksi outlier • Membutuhkan lebih banyak komputasi daripada kuadrat • Tidak efisien, hanya memperhitungkan sebagian dari data • Dibandingkan dengan metode yang kuat, mereka lebih tahan
terhadap outlier. • Dua jenis umum:? Median paling Squares (LMS) • Least Squares pakai (LTS) l

Metode LMS (V & Rp.159)
• Minimalkan median dari residual kuadrat
• min mediani |yi − xib|^2
Menggantikan jumlah dalam metode Model Kuadrat Terkecil dengan median.
Sangat tidak efisien.
Tidak dianjurkan untuk sampel kecil, karena titik tembus tinggi.

Metode LTS (V & Rp.159)
• Minimalkan jumlah kotak untuk q terkecil dari residual. • Resistensi yang lebih efisien dibandingkan dengan
LMS, tapi sama kesalahan • Q yang disarankan adalah: q=(n+p+1)/2
min Σ |yi − xib|2(i)

Regresi robust• Mulai teknik tahun 1960-an berkembang • Fitting dilakukan dengan iterasi ulang tertimbang-kuadrat (IWLS) • IWLS (IRLS) menggunakan bobot berdasarkan seberapa jauh terpencil kasus ini, yang diukur
dengan residual untuk kasus itu. • Berat bervariasi berbanding terbalik dengan ukuran residual • Lanjutkan iterasi sampai proses konvergenR Code: RLM () = model linier yang kuat
Ringkasan (RLM (panggilan ~ tahun, data = telepon, Maxit = 50), cor = F)
Hubungi: RLM (rumus = panggilan ~ tahun, data = telepon, Maxit = 50) residu: Min 1Q Median 3Q Max -18,314 -5,953 -1,681 26,460 173,769
koefisien: Nilai Std. Kesalahan nilai t (Intercept) -102,6222 26,6082 -3,8568 tahun 2,0414 0,4299 4,7480
Standar Residual error: 9,032 pada 22 derajat kebebasan

Fungsi berat untuk Robust Regression:? (Regresi Linear buku kutipan)
Huber M estimator (default di R) digunakan dengan penyetelan parameter c = 1.345
w = ψ = { 1 , |u| ≤ 1.345 }
{ (1.345/ |u| ) , |u| >1.345 }
u menunjukkan sisa skala dan diperkirakan menggunakan deviasi absolut median (MAD) estimator (bukan sqrt (MSE))
MAD = (1/.6745) * median {| ei - median {ei} |}
Jadi ui = ei / MAD
Bisquare (redescending estimator)w = ψ = { [1 – (u / 4.685)2 ]2 , |u| ≤ 4.685 }
{ 0 , |u| > 4.685 }

R output untuk 3 model linier yang berbeda (LM, RLM dengan Huber dan Bisquare):Ringkasan (lm (panggilan ~ tahun, data = telepon), cor = F)
koefisien: Perkiraan Std. Kesalahan nilai t Pr (> | t |) (Intercept) -260,059 102,607 -2,535 0,0189 tahun 5,041 1,658 3,041 0,0060
Residual standard error: 56.22 pada 22 derajat kebebasan
Ringkasan (RLM (panggilan ~ tahun, data = telepon, Maxit = 50), cor = F)
koefisien: Nilai Std. Kesalahan nilai t (Intercept) -102,6222 26,6082 -3,8568 tahun 2,0414 0,4299 4,7480
Standar Residual error: 9,032 pada 22 derajat kebebasan
Ringkasan (RLM (panggilan ~ tahun, data = telepon, psi = psi.bisquare), cor = F)
koefisien: Nilai Std. Kesalahan nilai t (Intercept) -52,3025 2,7530 -18,9985 tahun 1,0980 0,0445 24,6846
Standar Residual error: 1.654 pada 22 derajat kebebasan

Perbandingan Berat Handal dengan menggunakan R
melampirkan (ponsel), plot (tahun, panggilan); detach (); abline (lm (panggilan ~ tahun, data = telepon), lty = 1, col = 'hitam') abline (RLM (panggilan ~ tahun, ponsel, Maxit = 50), lty = 1, col = 'red') # default abline (RLM (panggilan ~ tahun, ponsel, psi = psi.bisquare, Maxit = 50), lty = 2, col = biru ')abline (RLM (panggilan ~ tahun, ponsel, psi = psi.hampel, Maxit = 50), lty = 3, col = ungu ') legenda (locator (1), lty = c (1,1,2,3), col = c ('hitam', 'merah', 'biru', 'ungu'), legenda = c ("LM", "Huber", "Bi-Square", "Hampel"))
50 55 60 65 70
05
01
00
15
02
00
year
calls
LMHuberBi-SquareHampel

Regresi resistantLebih estimator yang dikembangkan pada 1980-an dirancang untuk menjadi lebih tahan
terhadap outlier Tujuannya adalah untuk menyesuaikan regresi untuk poin yang baik dalam dataset
sehingga mencapai estimator regresi dengan titik tembus tinggi
Least Squares Berarti (LMS) dan Least Squares pakai (LTS) Keduanya efisien, tetapi keduanya sangat tahan
S-estimasi (lihat hal. 160) Lebih efisien daripada LMS dan LTS ketika data normal
MM-estimasi (kombinasi M-estimasi dan teknik regresi tahan) MM-estimator adalR Code: LQs ()
LQs (panggilan ~ tahun, data = telepon) # default metode LTS
koefisien: (Intercept) tahun -56,162 1,159 Skala memperkirakan 1,249 1,131ah M-perkiraan mulai dari koefisien yang diberikan
oleh S-estimator dan dengan tetap skala yang diberikan oleh S-estimator

bandingan estimator Tahan menggunakan Rmelampirkan (ponsel), plot (tahun, panggilan); detach (); abline (lm (panggilan ~ tahun, data = telepon), lty = 1, col = 'hitam') abline (LQs (panggilan ~ tahun, data = telepon), lty = 1, col = 'red') abline (LQs (panggilan ~ tahun, data = telepon, metode = "LMS"), lty = 2, col = 'biru') abline (LQs (panggilan ~ tahun, data = telepon, metode = "S"), lty = 3, col = 'ungu') abline (RLM (panggilan ~ tahun, data = telepon, metode = "MM"), lty = 4, col = 'green') legenda (locator (1), lty = c (1,1,2,3,4), col = c ('hitam', 'merah', 'biru', 'purple', 'hijau'),
legenda = c ("LM", "LTS", "LMS", "S", "MM"))
50 55 60 65 70
05
01
00
15
02
00
year
ca
lls
LMLTSLMSSMM

• Terimah kasih