bab ii tinjauan pustaka - sinta.unud.ac.id ii.pdf · untuk membentuk fungsi tujuan dari cso. 1.1...
TRANSCRIPT

6
BAB II
TINJAUAN PUSTAKA
Pada bab ini akan dibahas mengenai konsep-konsep yang akan digunakan
dalam penelitian ini, yaitu metode Regresi Logistik Ordinal (RLO) dan Algoritma
Cat Swarm Optimization (CSO). Dalam hal ini digunakan pendekatan regresi
untuk membentuk fungsi tujuan dari CSO.
1.1 Metode Regresi
Metode regresi merupakan alat statistik untuk menganalisis data yang
memanfaatkan hubungan antara dua atau lebih peubah kuantitatif, sehingga salah
satu peubah bisa diprediksi dari peubah lainnya (Agresti, 1990). Analisis regresi
memperlihatkan hubungan dan pengaruh antara peubah bebas dengan peubah
respon.
Hosmer & Lemeshow (2000) memberikan asumsi-asumsi yang harus
dipenuhi dalam penggunaan model regresi linier, yaitu:
1. Harus diketahui dengan pasti bentuk hubungan antara peubah respon dengan
peubah bebas.
2. Sisaan mengikuti sebaran normal.
3. Kehomogenan ragam sisaan.
Jika hubungan peubah respon dengan peubah bebas bersifat linier dan
ketiga asumsi terpenuhi, maka model regresi linier bisa diterapkan. Adapun model
umum dari regresi linier adalah:
pp XXXY 22110 (2.1)

7
dengan peubah respon; peubah bebas, i= 1,2,...,p ; parameter,
j= 0,1,...,p; = sisaan, yang diasumsikan menyabar normal dengan rataan 0 dan
ragam 1. Apabila peubah bebasnya hanya satu dan berpangkat 1, maka model
yang terbentuk disebut model regresi linier sederhana, sedangkan apabila peubah
bebasnya lebih dari satu, model yang terbentuk dinamakan regresi linier berganda.
Selain regresi linier sederhana dan regresi linier berganda, terdapat beberapa
macam regresi lainnya seperti regresi nonlinier, regresi dummy, dan regresi
logistik dengan peubah respon dalam berskala ordinal (kategorik). Akan tetapi di
sini hanya akan dibahas mengenai metode regresi logistik.
1.2 Metode Regresi Logistik
Tujuan melakukan analisis data kategori menggunakan regresi logistik
adalah untuk mendapatkan model dalam bentuk sederhana, namun model tersebut
sejalan dengan tujuan untuk menjelaskan hubungan antara keluaran dari peubah
respon dengan peubah bebas (Agresti, 1990). Metode regresi logistik merupakan
metode regresi dengan peubah respon dalam bentuk kategorik yaitu peubah
biner atau dikotomi (mempunyai dua kemungkinan nilai), sedangkan peubah
bebasnya bisa berupa peubah kategorik maupun kontinu. Apabila peubah
merupakan peubah biner atau dikotomi dalam arti perubah respon terdiri dari dua
kategori yaitu nilai 1 untuk kejadian sukses atau nilai 0 untuk kejadian gagal,
maka peubah mengikuti sebaran Bernoulli yang mempunyai fungsi peluang
(Hosmer & Lemeshow, 2000):
ii y
i
y
ii xxyf
1
))(1()()( (2.2)

8
dengan )( ix adalah peluang sukses, {0,1}
Dengan demikian berdasarkan persamaan (2.2)
- untuk yi = 0 berlaku )(1))(1()()0( 010
iii xxxf
- untuk yi = 1 berlaku )())(1()()1( 111
iii xxxf
Nilai harapan dari peubah respon untuk nilai peubah bebas dinotasikan
dengan xYE | . Selanjutnya xYE | ditulis )(x dengan peubah respon
)(XgY untuk masing-masing amatan ditulis )( ii xgy . Dari persamaan (2.1)
maka diperoleh ippiii xxxxg 22110)( . Apabila digunakan
distribusi logistik (Hosmer & Lemeshow, 2000), rumus untuk dapat dilihat
pada persamaan (2.3):
)exp(1
)exp(
)(exp1
)(exp)(
22110
22110
ippii
ippii
i
i
ixxx
xxx
xg
xgx
(2.3)
Hubungan antara peubah bebas dan peluangnya adalah hubungan tidak
linier sehingga untuk mendapatkan hubungan yang linier dilakukan suatu
transformasi logit. Hasil transformasinya sebagai berikut (Hosmer & Lemeshow,
2000):
)()(1
)(ln))((log 22110 iippii
i
i
i xgxxxx
xxit
(2.4)
Untuk memperoleh model dengan lebih dari dua peubah respon yang
berbentuk kategori dapat digunakan regresi logistik ordinal.

9
1.3 Regresi Logistik Ordinal (RLO)
Regresi logistik ordinal adalah regresi logistik dengan peubah respon
dalam bentuk kategorik yang memiliki lebih dari dua kemungkinan nilai (Hosmer
& Lemeshow, 2000). Metode ini merupakan perluasan dari metode regresi
logistik dengan peubah respon biner.
Salah satu cara yang dapat digunakan untuk membentuk model dengan
respon kategorik yang berskala ordinal adalah dengan membentuk fungsi logit
peluang kumulatif kategori ke- (Agresti, 1990). Model logistik untuk data respon
ordinal ini sering disebut sebagai model logit kumulatif. Peubah respon dalam
model logit kumulatif berupa data bertingkat yang diwakili dengan angka
1,2,3,..., J, dengan J adalah banyaknya kategori pada peubah respon ordinal dan
X menyatakan vertor peubah bebas dengan ),,,( 21 mXXX X , banyaknya
peubah bebas.
Langkah awal untuk membuat model regresi logistik ordinal adalah
membentuk persamaan peluang kumulatif )(Xj seperti pada persamaan (2.5)
(Hosmer & Lemeshow, 2000)
)()()()|()( 21 XXXXX jj jYP
(2.5)
dengan )(Xj adalah peluang peubah respon kategori ke- , dan )(Xj adalah
peluang kumulatif peubah respon ordinal kategori ke-j; = 1,2,..,J.
Selanjutnya dibuat fungsi logit kumulatif )(Xj yang dibentuk melalui
transformasi logit dari fungsi peluang kumulatif )(Xj (Hosmer & Lemeshow,
2000) yaitu:

10
)(log)( XX jj it
)()(
)()(ln
)(1
)(ln
1
1
XX
XX
X
X
Jj
j
j
j
(2.6)
Dengan melibatkan peubah bebas X berdasarkan persamaan (2.4), maka
dihasilkan model regresi logistik ordinal (Hosmer & Lemeshow, 2000):
mmjj XXX 22110)(X
m
mj
X
X
X
2
1
210
Xβ T j0 (2.7)
dengan merupakan intersep peubah respon ordinal kategori ke- ;
1,...,2,1 Jj , merupakan vector slope parameter tanpa intersep;
m 21 .
Dengan demikian, model regresi logistik ordinal yang terbentuk apabila
terdapat kategori respon adalah
mm XXX 2211011 )(X
mm XXX 2211022 )(X
mmJ XXX 2211021 )(X
(2.8)
Selanjutnya peluang untuk masing-masing kategori dari persamaan model regresi
logistik ordinal adalah (Hosmer & Lemeshow, 2000)

11
j
j jYP0exp1
1|
XβXX
T (2.9)
dan 1| XX JYPJ yang merupakan total dari peluang untuk J kategori.
1.4 Pendugaan Parameter
Metode paling umum yang digunakan untuk menduga parameter pada
model regresi logistik adalah metode kemungkinan maksimun (Methode of
Maximum Likelihood) (Ryan, 1997).
Bentuk umum dari fungsi likelihood untuk nilai peubah respon yang
diasumsikan saling bebas dengan sampel sebanyak amatan adalah (Hosmer &
Lemeshow, 2000)
n
i
y
ih
y
i
y
ihiii xxxl
1
1010 (2.10)
dengan ih x adalah fungsi dari parameter yang tidak diketahui, h merupakan
banyaknya fungsi dari parameter yang tidak diketahui.
Logaritma dari fungsi likelihood bersamanya dapat ditulis seperti pada
persamaan (2.10) (Hosmer & Lemeshow, 2000):
ihhiii
n
i
ii xyxyxyL lnlnln 11
0
00
(2.11)
dengan 'y = ),...,,( 10 hiii yyy merupakan peubah respon ordinal.
Untuk mendapatkan nilai penduga dari yang memaksimumkan L ,
didapat dengan cara menurunkan persamaan (2.11) terhadap , kemudian hasil

12
turunannya disamakan dengan nol (Hosmer & Lemeshow, 2000). Persamaan yang
diperoleh adalah:
01
n
i
jihi yxL
(2.12)
dengan 1,2,3,...,q ; q merupakan banyaknya fungsi dari parameter yang sudah
diturunkan. Nilai duga dari selanjutnya dinotasikan ̂
1.5 Pengujian Signifikansi Model RLO
Uji signifikansi dilakukan untuk mengetahui signifikansi parameter dan
mengevaluasi kecocokan model. Uji signifikansi yang dilakukan meliputi
pengujian fungsi secara simultan dan secara parsial.
2.5.1 Pengujian Koefisien Regresi Simultan
Uji simultan adalah uji untuk melihat pengaruh semua peubah bebas secara
bersama-sama terhadap peubah respon. Apabila model signifikan maka model
bisa digunakan untuk prediksi, sebaliknya apabila model tidak signifikan maka
model tidak bisa digunakan untuk prediksi (Ryan, 1997).
Uji simultan dilakukan dengan hipotesis:
H0 : (model tidak signifikan)
H1 : terdapat (model signifikan)
dengan = 1,2,3,..., dan k merupakan banyaknya parameter koefisien
regresi

13
Statistik uji yang digunakan dengan taraf signifikansi adalah uji G (Hosmer &
Lemeshow, 2000) yaitu:
[
]
dengan merupakan fungsi maksimum likelihood tanpa peubah bebas dan
merupakan fungsi maksimum likelihood dengan peubah bebas. Statistik uji G
mengikuti sebaran chi-square dengan derajat bebas db. Kriteria uji yang
digunakan adalah apabila maka keputusan terima H0, sebaliknya tolak
H0, yang berarti model signifikan.
Selanjutnya, untuk menjelaskan keragaman pada peubah respon digunakan
tiga uji dalam menentukan nilai dari Pseudo R-Square yaitu Cox & Snell,
Nagelkerke, dan McFadden. Pada regresi logistik digunakan uji Cox & Snell dan
Nagelkerke yang secara bersama menjelaskan keragaman peubah respon terhadap
peubah bebas. Cox & Snell dan Nagelkerke memiliki analogi yang sama dengan
nilai R-Square pada regresi linier, akan tetapi pada regresi logistik digunakan
Nagelkerke yang menghasilkan nilai R-Square tertinggi. (O'Connell, Ann
A.,2006). Berdasarkan model yang signifikan dengan keragaman yang diperoleh,
maka untuk mengetahui parameter mana yang signifikan dilakukan uji parsial.
2.5.2 Pengujian Koefisien Regresi Parsial
Uji signifikansi secara parsial yang digunakan adalah uji Wald, yaitu untuk
menguji pengaruh masing-masing peubah bebas terhadap peubah respon.
Hipotesis pada uji parsial adalah

14
Hipotesis: H0 : (parameter tidak berpengaruh terhadap model)
H1 : (parameter berpengaruh terhadap model)
dengan {1,2,3,..., }
Adapun statistik uji Wald dengan taraf signifikansi yang digunakan (Hosmer
& Lemeshow, 2000) adalah:
[ ̂
( ̂ )]
dengan ̂ adalah penduga dari dan ( ̂ ) adalah penduga galat baku dari .
W diasumsikan mengikuti sebaran chi-square dengan derajat bebas 1. Keputusan
tolak H0 apabila nilai atau , yang berarti parameter ke-i
berpengaruh signifikan terhadap model dan terima H0 apabila .
1.6 Pengklasifikasian dengan Metode RLO
Pengklasifikasian amatan dilakukan dengan menggunakan peubah-peubah
bebas yang berpengaruh signifikan terhadap peubah respon. Berdasarkan
persamaan (2.5), diperoleh (Hosmer & Lemeshow, 2000):
(2.15)

15
Oleh karena itu, berdasarkan persamaan (2.15) dapat diperoleh peluang
suatu amatan untuk masuk ke dalam salah satu kategori yang dimiliki peubah
respon . Nilai peluang untuk masing-masing kategori adalah:
( )
(2.16)
1.7 Klasifikasi
Klasifikasi (classification) adalah metode untuk mempelajari fungsi-fungsi
yang memetakan tiap item data ke dalam kelas yang telah ditentukan (Olson,
2001). Dengan adanya set kelas, jumlah atribut, dan set pembelajaran (learning
set), metode klasifikasi dapat memprediksi kelas dari data baru yang belum
terklasifikasi. Dengan kata lain klasifikasi bertujuan menempatkan data baru ke
dalam kelas yang telah tersedia sebelumnya.
Dalam klasifikasi, metode untuk mengukur kinerja model adalah dengan
menggunakan metode “train and test” (Suyanto, 2010). Pada metode ini, data
dipisah menjadi dua bagian, masing-masing disebut training set dan test set.
Training set digunakan untuk membangun fungsi pemisah, yang selanjutnya

16
digunakan untuk memprediksi klasifikasi pada test set. Jika terdapat sebanyak N
data yang diuji, dan sebanyak C data yang terklasifikasi benar, maka keakuratan
prediksi dari fungsi pemisah tersebut adalah (Suyanto, 2010).
1.8 Misklasifikasi
Johnson (1998) menyatakan bahwa, misklasifikasi adalah pengamatan yang
pengelompokannya tidak tepat. Untuk menghitung keakuratan pengklasifikasian,
biasanya dengan menghitung peluang kesalahan pengklasifikasian. Ukuran ini
dinamakan Apparent Error Rate (APER) yang didefinisikan sebagai proporsi
kesalahan pada klasifikasi. Komplemen dari rata-rata kesalahan adalah rata-rata
pengklasifikasian yang benar (Apparent Correct Classification Rate). APER
dihitung dengan terlebih dahulu membuat tabel klasifikasi, seperti pada Tabel 2.1
Tabel 2.1 Tabel Klasifikasi
Actual
Group
Prediction Group Total
n
j jr1 1
n
j jr1 2
n
j jr1 3
Total
n
i ir1 1
n
i ir1 2
n
i ir1 3
n
i
n
j ijr1 1
Sumber: Olson (2001)
dengan
= kelompok ke-s, s = 1,2,...,n
ijr = kelompok sebenarnya i yang diprediksi sebagai
kelompok prediksi j

17
n
i
n
j ijr1 1
= jumlah pengamatan
Untuk menghitung nilai APER digunakan rumus (Hosmer & Lemeshow, 2000):
APER =
n
i
n
j ij
n
i ii
n
i
n
j ij
r
rr
1 1
11 1
=
n
i
n
j ij
n
i ii
r
r
1 1
11 (2.17)
dengan
n
i iir1
= jumlah pengamatan yang terklasifikasi dengan benar.
Oleh karena itu, tingkat pengklasifikasian yang benar (Hosmer & Lemeshow,
2000):
Apparent Correct Classification Rate = 1- APER
= 1-
n
i
n
j ij
n
i ii
r
r
1 1
11
=
n
i
n
j ij
n
i ii
r
r
1 1
1 (2.18)
1.9 Algoritma
Algoritma adalah susunan yang logis dan sistematis untuk memecahkan
suatu masalah atau untuk mencapai tujuan tertentu (Munir, 1999). Menurut Hasad
(2011) sebuah algoritma merupakan langkah komputasi yang mengubah input ke
output. Secara umum, masalah yang ingin dipecahkan adalah melalui hubungan

18
antara input dan ouput, sedangkan algoritma akan menggambarkan prosedur
komputasi tertentu untuk mencapai hubungan input dan output tersebut.
Umumnya sebuah algoritma dibangun dari tiga buah struktur dasar, yaitu
barisan (sequence), pemilihan (selection), dan pengulangan (repetition) (Hasad,
2011). Sequence merupakan satu atau lebih instruksi, dengan tiap instruksi
dikerjakan secara berurutan sesuai dengan urutan yang diberikan pada awal
instruksi. Disini sebuah instruksi dilaksanakan setelah instruksi sebelumnya
dilaksanakan. Selection merupakan kemampuan yang memungkinkan proses
dapat mengikuti jalur aksi yang berbeda berdasarkan kondisi yang ada. Tanpa
struktur selection tidak mungkin dapat menulis algoritma untuk permasalahan
yang kompleks. Repetition merupakan pengulangan pada sebuah pekerjaan dan
Repetition juga disebut loop. Bagian algoritma yang diulang disebut loop body
(Hasad, 2011).
1.10 Algoritma Optimasi
Algoritma optimasi dapat didefinisikan sebagai algoritma atau metode
numerik untuk menemukan nilai sedemikian sehingga menghasilkan nilai fungsi
yang bernilai sekecil atau sebesar mungkin untuk suatu fungsi yang
diberikan, yang mungkin disertai dengan beberapa batasan pada . Di sini, bisa
berupa skalar atau vektor dari nilai-nilai kontinu maupun diskrit. (Suyanto, 2010)
Pada beberapa cabang matematika terapan dan analisa numerik dijumpai
pembahasan mengenai optimasi dengan kriteria yang tunggal, ganda, bahkan
mungkin kompleks. Kriteria tersebut diwujudkan sebagai himpunan fungsi

19
matematika , yang disebut fungsi-fungsi objektif (objective
functions). Suatu himpunan masukan yang membuat fungsi-fungsi objektif
menghasilkan nilai-nilai optimal yang berupa maksimal atau minimal disebut
hasil dari proses optimasi.
Menurut metode operasinya, algoritma optimasi dapat dibagi menjadi dua,
yaitu algoritma deterministik dan algoritma probabilistik (Suyanto, 2010). Pada
setiap langkah algoritma deterministik (deterministic algorithm) terdapat
maksimum satu jalan untuk diproses. Jika tidak ada jalan berarti algoritma sudah
selesai. Pada umumnya, algoritma probabilistik menggunakan konsep dasar dari
metode Monte Carlo. Metode Monte Carlo bertumpu pada proses pengambilan
sampel secara acak yang berulang-ulang (repeated random sampling) untuk
menghasilkan solusi. Dengan karakteristik ini, maka proses-proses pada Monte
Carlo dapat dilakukan dengan bantuan komputer. Metode Monte Carlo digunakan
apabila suatu permasalahan tidak mungkin diselesaikan melalui algoritma
deterministik. (Suyanto, 2010)
Terdapat banyak algoritma optimasi yang menggunakan konsep Monte
Carlo, salah satu diantaranya adalah Swarm Intelligence (SI). Swarm Intelligence
berhubungan dengan alam dan sistem-sistem buatan yang tersusun atas banyak
individu. Swarm dapat diartikan sebagai kawanan, kelompok, kerumunan,
gerombolan, rombongan, atau koloni. Oleh karena itu, Swarm Intelligence (SI)
dapat diartikan sebagai kecerdasan yang dihasilkan dari adanya tingkah laku
kawanan atau kelompok.

20
Algoritma optimasi yang termasuk ke dalam kelas Swarm Intelligence (SI)
diantaranya, adalah Particle Swarm Optimization (PSO), Ant Colony Optimization
(ACO), Artificial Bee Colony Algorithm (ABC), Cat Swarm Optimization (CSO),
dan lain-lain. Akan tetapi, yang akan dibahas disini adalah Algoritma Cat Swarm
Optimization (CSO).
1.11 Algoritma Cat Swarm Optimization (CSO)
Algoritma CSO merupakan algoritma yang diusulkan oleh Shu-Chuan Chu
dan Pei-Wei Tsai pada tahun 2006 melalui pengamatan terhadap perilaku
sekumpulan kucing. Tahap awal dalam CSO adalah menentukan seberapa banyak
kucing yang akan digunakan dalam iterasi. Kucing yang diterapkan dalam CSO
digunakan untuk menyelesaikan suatu permasalahan. Setiap kucing memiliki
posisi berdimensi tertentu, kecepatan untuk setiap dimensi, nilai kecocokan (nilai
fitness), dan tanda untuk menyatakan apakah kucing berada dalam posisi seeking
mode atau tracing mode. Solusi akhir yang didapat melalui tahapan-tahapan
algoritma CSO adalah posisi terbaik (nilai fitness tertinggi) dari salah satu kucing.
(Chu & Tsai, 2006)
Algortima CSO dibagi dalam dua sub mode yang terinspirasi dari dua
perilaku utama kucing, yaitu ”seeking mode” (kondisi mencari) dan ”tracing
mode” (kondisi melacak). (Chu & Tsai, 2006)
1. Seeking Mode
Sub mode ini merupakan langkah dari algoritma CSO yang digunakan untuk
memodelkan situasi kucing ketika dalam keadaan beristirahat dan melihat keadaan

21
untuk bergerak mencari posisi berikutnya. Dalam seeking mode terdapat 4 faktor
penting (parameter), yaitu seeking memory pool (SMP), seeking range of the
selected dimension (SRD), counts of dimension to change (CDC), dan self-
position considering (SPC).
SMP digunakan untuk mendefinisikan ukuran memori dalam pencarian
untuk masing-masing kucing, yang menunjukkan titik-titik yang dicari oleh
kucing. Kucing tersebut kemudian akan memilih titik dari kelompok memori
berdasarkan SRD, CDC, dan SPC. SRD menyatakan rasio perpindahan untuk
dimensi yang dipilih dengan rentang SRD adalah [0,1]. CDC memperlihatkan
berapa banyak dimensi pada masing-masing kucing yang akan berubah yang
memiliki rentang [0,1]. Jika suatu dimensi diputuskan berubah, selisih antara nilai
baru dengan yang lama tidak boleh melebihi suatu rentang, yaitu rentang yang
didefinisikan oleh SRD. SPC merupakan variabel Boolean (bernilai “benar” atau
“salah”), untuk menunjukkan apakah suatu titik yang pernah menjadi posisi
kucing akan menjadi salah satu kandidat untuk berpindah.
Langkah-langkah dalam seeking mode dapat dideskripsikan dalam 5 tahap
(Chu & Tsai, 2006), yaitu:
Tahap 1 : membuat salinan sebanyak dari posisi kucing ke- , dengan
= SMP. Jika nilai dari SPC bernilai benar, maka masukkan
= (SMP–1), kemudian pertahankan posisi saat ini sebagai salah
satu kandidat;
Tahap 2 : untuk setiap salinan, berdasarkan CDC, pilih dimensi sebagai
kandidat untuk berubah, kemudian secara acak tambahkan atau

22
kurangkan sebanyak presentase SRD dari nilai sekarang dan
gantikan nilai sebelumnya;
Tahap 3 : hitung nilai kecocokan atau nilai fitness ( ) untuk semua titik
kandidat;
Tahap 4 : jika semua tidak sama, hitung peluang terpilih masing-masing
titik kandidat dengan menggunakan persamaan (2.19)
ji
FSFS
FSFS
FSFS
P bii 0,
,1
minmax
minmax
(2.19)
dengan merupakan peluang memilih kucing ke- dan
merupakan nilai fitness kucing ke- . Jika semua FS sama, peluang
setiap titik kandidat terpilih diberi nilai 1;
Tahap 5 : berdasarkan nilai fitness, pilih titik untuk bergerak dari titik-titik
kandidat, dan ganti posisi kucing ke-
Jika tujuan dari fungsi fitness adalah untuk menemukan solusi minimum maka
, sebaliknya untuk menemukan solusi maksimum.
2. Tracing Mode
Tracing mode merupakan sub mode yang menggambarkan keadaan ketika
kucing sedang melacak targetnya. Setelah kucing memasuki tracing mode, kucing
akan bergerak sesuai dengan kecepatannya untuk masing-masing dimensi.
Tahapan tracing mode dapat dijelaskan dalam 3 tahap berikut (Chu & Tsai,
2006):

23
Tahap 1 : perbarui nilai kecepatan untuk setiap dimensi ( ) berdasarkan
persamaan (2.20);
( )
dengan sebagai kecepatan kucing ke- saat iterasi ke- t+1
pada dimensi ke- ; 1,2,..., M, sebagai kecepatan kucing
ke- saat iterasi ke–t pada dimensi ke-d sebelumnya;
merupakan nilai acak pada interval kontinu [0,1]; merupakan
sebuah konstanta, dan merupakan posisi kucing yang
memiliki nilai fitness terbesar, merupakan posisi dari kucing
ke- pada dimensi ke- ;
Tahap 2 : periksa apakah kecepatan berada dalam rentang kecepatan
maksimum. Jika kecepatan yang baru melebihi rentang kecepatan
maksimum, maka tetapkan nilai kecepatan sama dengan batas
kecepatan maksimum;
Tahap 3 : Perbarui posisi kucing ke- berdasarkan persamaan (2.21).
(2.21)
Seperti yang telah dibahas pada sebelumnya, CSO terdiri dari dua sub mode,
yaitu seeking mode dan tracing mode. Untuk mengkombinasikan kedua mode
dalam satu algoritma, didefinisikan rasio campuran/mixture ratio (MR) dengan
rentang [0,1]. Dengan mengamati perilaku kucing, dapat diketahui bahwa kucing
menghabiskan sebagian besar waktunya untuk beristirahat.
Selama beristirahat, kucing mengubah posisinya secara perlahan dan
berhati-hati, terkadang tetap pada posisi awalnya. Untuk menerapkan perilaku ini

24
ke dalam CSO, digunakan seeking mode. Perilaku mengejar target diaplikasikan
dalam tracing mode. Oleh karena itu, MR harus bernilai kecil untuk memastikan
bahwa kucing menghabiskan sebagian besar waktu kucing dalam posisi seeking
mode. (Chu & Tsai, 2006)
Proses dalam algoritma CSO dapat dijelaskan dalam 6 langkah sebagai
berikut (Chu & Tsai, 2006):
Langkah 1 : Bangkitkan kucing dalam proses;
Langkah 2 : Sebarkan kucing secara acak dalam ruang solusi berdimensi M
dan secara acak pula pilih nilai dalam rentang kecepatan
maksimum untuk menjadi kecepatan kucing. Kemudian pilih
sejumlah kucing secara sembarang dan masukkan dalam tracing
mode sesuai mixture ratio (MR), sisanya dimasukkan dalam
seeking mode.
Langkah 3 : Hitung nilai fitness masing-masing kucing dengan memasukkan
nilai posisi kucing ke dalam fungsi fitness, yang menunjukkan
kriteria tujuan, dan simpan kucing terbaik dalam memori. Perlu
diingat bahwa yang perlu disimpan adalah posisi kucing terbaik
( ) karena kucing terbaik akan mewakili solusi terbaik.
Langkah 4 : Pindahkan kucing sesuai ruangnya, jika kucing ke- berada dalam
seeking mode, maka dilakukan sesuai proses seeking mode,
sebaliknya jika kucing ke- berada dalam tracing mode, maka
dilakukan sesuai tracing mode. Proses masing-masing telah
dijelaskan sebelumnya.

25
Langkah 5 : Pilih lagi beberapa kucing dan masukkan dalam tracing mode
sesuai MR dengan kata lain ( MR , sisanya masukkan ke
dalam seeking mode.
Langkah 6 : Perhatikan kondisi akhirnya (termination condition). Jika telah
memuaskan maka hentikan program. Jika sebaliknya, maka
ulangi langkah 3 hingga 5.
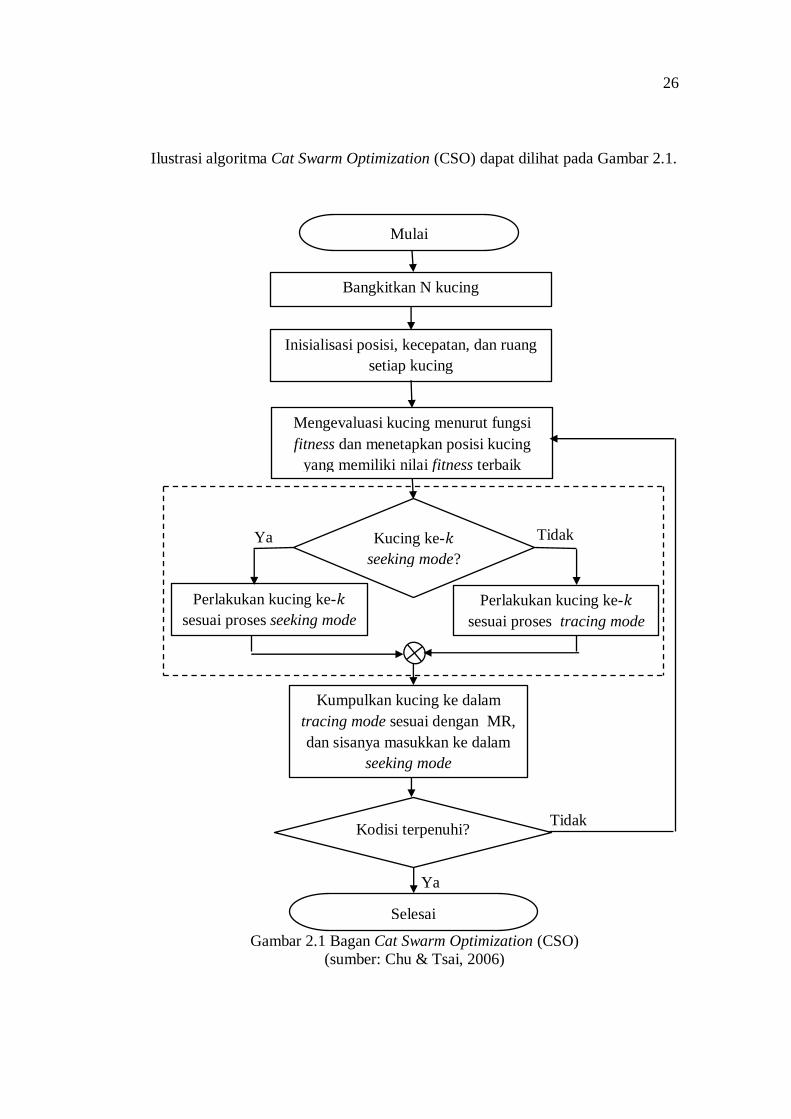
26
Ilustrasi algoritma Cat Swarm Optimization (CSO) dapat dilihat pada Gambar 2.1.
Gambar 2.1 Bagan Cat Swarm Optimization (CSO)
(sumber: Chu & Tsai, 2006)
Tidak Ya
Tidak
Ya
Mulai
Selesai
Kucing ke-𝑘
seeking mode?
Bangkitkan N kucing
Inisialisasi posisi, kecepatan, dan ruang
setiap kucing
Mengevaluasi kucing menurut fungsi
fitness dan menetapkan posisi kucing
yang memiliki nilai fitness terbaik
Perlakukan kucing ke-𝑘
sesuai proses seeking mode
Perlakukan kucing ke-𝑘
sesuai proses tracing mode
Kumpulkan kucing ke dalam
tracing mode sesuai dengan MR,
dan sisanya masukkan ke dalam
seeking mode
Kodisi terpenuhi?

27
Algoritma CSO yang awalnya digunakan untuk menyelesaikan masalah
dalam mencari solusi optimal dikembangkan, sehingga dapat digunakan dalam
kasus klasifikasi (Liu & Shen, 2010). Pada penelitian ini, digunakan pendekatan
regresi pada CSO. Dalam kasus klasifikasi, CSO dimodifikasi dengan
penambahan nilai pada kecepatan kucing berupa nilai inersia , yaitu CSO with
inertia dan CSO steady flag (CSOsf) (Sharafi dkk, 2013). Perbedaan antara CSO
with inertia dan CSOsf terletak pada nilai inersia yang digunakan. Pada CSOsf
nilai inersia yang diberikan konstan yaitu 1, sedangkan CSO with inertia berupa
nilai inersia yang berubah secara acak, sehingga kecepatan pada persamaan (2.20)
menjadi:
( ) 1,2,..., (2.22)
Pada penelitian ini, pendekatan menggunakan regresi logistik ordinal
bertujuan membentuk fungsi tujuan yang dijelaskan pada persamaan (2.9).
Langkah dari algoritma Cat Swarm Optimization dengan pendekatan regresi dapat
dilihat dari flow chart pada Gambar 2.2.
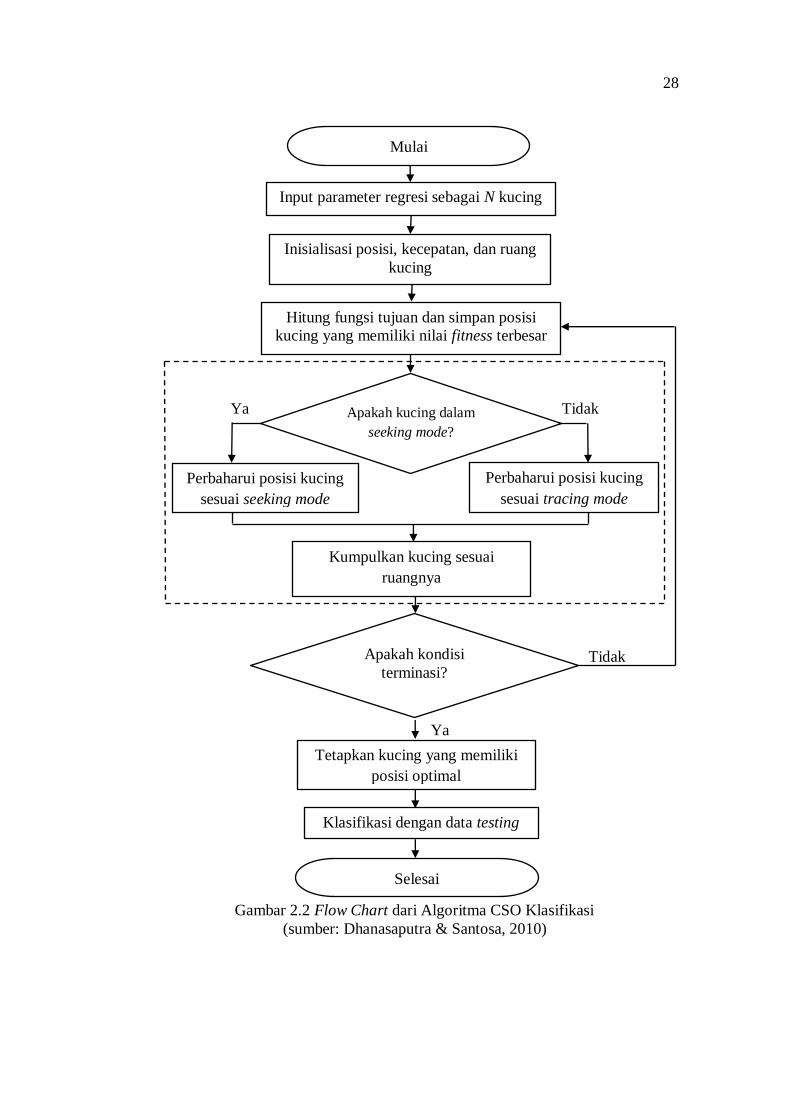
28
Gambar 2.2 Flow Chart dari Algoritma CSO Klasifikasi
(sumber: Dhanasaputra & Santosa, 2010)
Ya
Ya
Tidak
Tidak
Selesai
Apakah kucing dalam
seeking mode?
Input parameter regresi sebagai N kucing
Inisialisasi posisi, kecepatan, dan ruang
kucing
Hitung fungsi tujuan dan simpan posisi
kucing yang memiliki nilai fitness terbesar
Perbaharui posisi kucing
sesuai seeking mode
Perbaharui posisi kucing
sesuai tracing mode
Kumpulkan kucing sesuai
ruangnya
Apakah kondisi
terminasi?
Tetapkan kucing yang memiliki
posisi optimal
Klasifikasi dengan data testing
Mulai

29
1.12 Bank
Bank adalah lembaga keuangan yang kegiatan utamanya adalah
menyalurkan kembali dana tersebut ke masyarakat serta memberikan jasa bank
lainnya (Kasmir, 2012). Bank sebagai lembaga yang menjalankan usaha di bidang
jasa keuangan bukanlah sembarang usaha melainkan secara hukum bank memiliki
status yang kuat dengan kekayaan sendiri yang mampu melayani kebutuhan
masyarakat.
Pasal 1 Undang-Undang Nomor 10 Tahun 1998 tanggal 10 November 1998
tentang Perubahan Atas Undang-Undang Nomor 7 Tahun 1992 tentang Perbankan
(dalam Kasmir, 2012) menyebutkan bahwa: ”bank adalah badan usaha yang
menghimpun dana dari masyarakat dalam bentuk simpanan, dan menyalurkannya
kepada masyarakat dalam bentuk kredit dan atau bentuk-bentuk lainnya rangka
meningkatkan taraf hidup rakyat banyak”. Dengan kata lain, bank merupakan
suatu lembaga yang berfungsi dan berwenang untuk menghimpun dana dari
masyarakat dan menyalurkan dana kepada masyarakat dengan tujuan untuk
mendapatkan keuntungan bersama (Kasmir, 2012).
1.13 Kredit Perbankan
Peranan bank sebagai lembaga keuangan tidak terlepas dari masalah kredit.
Besarnya jumlah kredit yang disalurkan akan menentukan keuntungan bank
karena hanya dengan menghimpun dana tanpa menyalurkan dana, akan
mengakibatkan kerugian bagi bank. Para pengambil kredit disebut debitur,

30
sedangkan pihak pemberi kredit (bank) disebut kreditur. Dengan kata lain, debitur
adalah penerima dana dan kreditur adalah penyedia dana (Kasmir, 2012).
1.14 Kredit Usaha Rakyat pada Bank Rakyat Indonesia (BRI)
Kredit Usaha Rakyat (KUR) merupakan Kredit Modal Kerja (KMK) dan
atau Kredit Investasi (KI) dengan plafond kredit sampai dengan 500 juta rupiah
yang diberikan kepada pemilik usaha produktif skala mikro dan usaha rumah
tangga baik berbentuk perusahaan, kelompok usaha, atau perorangan (seperti:
pedagang, petani, peternak, dan nelayan). KUR mensyaratkan bahwa angunan
pokok kredit adalah proyek yang dibiayai, akan tetapi karena agunan tambahan
yang dimiliki oleh UMKM pada umumnya kurang, maka sebagian dijamin
dengan program penjaminan. Berdasarkan pihak unit BRI, plafond KUR hanya
mencapai 20 juta rupiah dengan tingkatan bunga maksimal 1,025%.
Berdasarkan Addendum III MoU KUR yang berlaku terhitung sejak tanggal
16 September 2010 tentang pelaksanaan KUR, maka jenis Kredit Usaha Rakyat
(KUR) yang disalurkan oleh bank dijelaskan pada Tabel 2.2
Tabel 2.2 KUR Mikro
Keterangan Persyaratan
Calon Debitur Individu yang melakukan usaha produktif yang layak
Lama Usaha Minimal 6 bulan
Besar Kredit Maksimal 20 juta rupiah
Bentuk Kredit KMK : maksimal tiga tahun
KI : maksimal lima tahun
Suku Bunga Pinjaman 1,025% perbulan
Legalitas KTP, KK, Surat Keterangan Usaha
Sumber: BRI Unit Melati Denpasar, 2015

31
1.15 Analisis Kredit
Analisis kredit merupakan penilaian terhadap suatu permohonan kredit (baik
permohonan kredit baru maupun perpanjangan/pembaharuan) layak atau tidak
untuk disalurkan kepada debitur. Terdapat beberapa prinsip penilaian kredit yang
sering dilakukan oleh pihak bank, yaitu dengan analisis 5 C’s (Kasmir, 2012).
Prinsip pemberian kredit dengan 5 C’s dapat dijelaskan sebagai berikut:
1. Penilaian Watak (Character)
Penilaian watak atau kepribadian calon debitur dimaksudkan untuk
mengetahui kejujuran dan keinginan calon debitur untuk melunasi atau
mengembalikan pinjaman, sehingga yang akan diberikan kredit benar-benar
dapat dipercaya.
2. Penilaian Kemampuan (Capacity)
Bank harus dapat melihat kemampuan calon debitur dalam membayar
kredit yang nantinya dihubungkan dengan kemampuan mengola bisnis dan
mencari laba, sehingga bank yakin bahwa usaha yang akan dibiayainya
dikelola oleh orang-orang yang tepat. Dengan harapan calon debitur dalam
jangka waktu tertentu mampu melunasi atau mengembalikan pinjamannya.
3. Penilaian terhadap modal (Capital)
Bank harus melakukan analisis terhadap posisi keuangan serta
mengetahui sumber-sumber pembiayaan yang dimiliki calon debitur
terhadap usaha yang akan dibiayainya. Hal ini dilakukan agar bank dapat
mengetahui kemampuan permodalan calon debitur dalam menunjang
pembiayaan proyek atau usaha calon debitur yang bersangkutan.

32
4. Penilaian terhadap agunan (Collateral)
Collateral merupakan jaminan yang diberikan calon debitur yang
berfungsi sebagai pelindung bank dari risiko kerugian. Untuk menghindari
hal tersebut, calon debitur umumnya wajib menyediakan jaminan berupa
agunan yang mudah dicairkan yang nilainya melebihi jumlah kredit yang
diberikan.
5. Penilaian terhadap kondisi perekonomian (condition of economy)
Bank menganalisis keadaan pasar di dalam dan di luar negeri baik
masa lalu maupun yang akan datang, sehingga masa depan pemasaran dari
hasil proyek atau usaha calon debitur yang dibiayai bank dapat diketahui.