bab 2 landasan teori - library.binus.ac.idlibrary.binus.ac.id/ecolls/ethesisdoc/bab2/2009-1-00066-if...
TRANSCRIPT

7
BAB 2
LANDASAN TEORI
2.1 Data dan Informasi
Menurut Laudon (2006, p13), data adalah kumpulan fakta yang masih
mentah yang menjelaskan aktivitas-aktivitas yang terjadi dalam organisasi atau
lingkungan fisik, sebelum terorganisir dan diubah menjadi bentuk yang
dimengerti dan dapat digunakan.
Menurut Inmon (2005, p493) data adalah rekaman dari fakta, konsep,
atau instruksi di dalam media penyimpanan untuk komunikasi, perolehan, dan
pemrosesan oleh cara otomatis dan presentasi sebagai informasi yang dapat
dimengerti oleh manusia.
Informasi adalah data yang dapat dimengerti dan dievaluasi oleh manusia
untuk memecahkan masalah atau membuat keputusan. Sehingga dapat
disimpulkan, data adalah fakta-fakta yang memuat kejadian, tempat dan subyek
yang terjadi, dan informasi adalah data yang telah diolah dan menjadi berguna
bagi perusahaan.

8
2.2 Pengertian Database
Menurut Connolly (2005, p14), database adalah suatu kumpulan dari data
yang terhubung secara logis, dan deskripsi dari data ini, dirancang untuk
memenuhi kebutuhan informasi dari sebuah organisasi. Database bersifat
tunggal, memiliki tempat penyimpanan data yang besar di mana dapat digunakan
secara bersama-sama oleh banyak departemen dan user.
Menurut Inmon (2002, p388), “a database is a collection of interrelated
data stored (often with controlled, limited redundancy) according to a schema”
yang dapat diartikan bahwa database adalah sekumpulan penyimpanan data yang
berhubungan (sering dengan pengontrolan, redudansi yang terbatas) yang
berdasarkan suatu skema.
Berdasarkan definisi diatas, dapat disimpulkan bahwa database
merupakan suatu kumpulan data yang saling berhubungan dan terintegrasi, yang
dirancang untuk kebutuhan informasi perusahaan.
2.3 Pengertian Entity Relationship Modeling
Menurut Connoly dan Begg (2005, p342), salah satu aspek yang sulit
dalam perancangan database adalah kenyataan bahwa perancang, programmer
dan pemakai akhir cenderung melihat data dengan cara yang berbeda. Untuk
memastikan pemahaman secara alamiah dari data dan bagaimana data digunakan
oleh perusahaan dibutuhkan sebuah bentuk komunikasi non-teknis dan bebas dari

9
kebingungan. Berikut ini adalah notasi Entity Relationship Modeling menurut
Connoly dan Begg :
Relate to >
Gambar 2.1 Notasi Entity – Relationship Modeling
2.3.1 Entity Type
Menurut Connoly dan Begg (2005, p343), Entity type adalah
kumpulan objek-objek yang berproperti sama, dimana properti tersebut
diidentifikasikan memiliki keberadaan yang bebas.
2.3.2 Attribute
Menurut Connoly dan Begg (2005, p350-352), atribut adalah sifat
dari sebuah entity atau sebuah tipe relationship. Atribut menyimpan nilai
dari setiap entity occurrence dan mewakili bagian utama dari data yang
disimpan dalam basis data.
A B
Ent ity Name
Relationship Name

10
Atribut domain adalah sejumlah nilai yang diperkenankan untuk
satu atau lebih atribut. Setiap atribut yang dihubungkan dengan sejumlah
nilai disebut domain. Domain mendefinisikan nilai-nilai yang dimiliki
sebuah atribut yang sama dengan konsep domain pada model relational.
Simple attribute adalah atribut yang terdiri dari satu komponen
tunggal dengan keberadaan yang bebas. Simple attribute tidak bisa dibagi
lagi kedalam komponen yang lebih kecil.
Single value attribute adalah atribut yang hanya menyimpan nilai
tunggal untuk suatu sifat dari entity. Multi value entity adalah atribut yang
bisa menyimpan nilai lebih dari satu untuk suatu sifat entity.
Derived attribute adalah atribut yang menunjukkan nilai yang
diperoleh dari atribut yang berhubungan, tidak terlalu dibutuhkan dalam
tipe entity yang sama.
2.3.3 Relationship Type
Menurut Connoly dan Begg (2005, p346), relationship type
adalah sekumpulan hubungan antara satu atau lebih tipe-tipe entity.
Menurut Connoly dan Begg (2005, p347), derajat dari
relationship adalah jumlah dari partisipasi tipe entity dalam sebuah tipe
relationship tertentu. Sebuah relationship berderajat dua disebut binary,
berderajat tiga disebut ternary dan berderajat empat disebut quarternary.

11
2.3.4 Kunci
Menurut Connoly dan Begg (2005, p78), kunci relasi sangat
dibutuhkan untuk mengidentifikasi satu atau lebih atribut yang memiliki
nilai unik untuk setiap tuple dalam relasi. Macam-macam kunci relasi :
a. Composite key adalah kunci yang disusun berdasarkan lebih
dari satu atribut.
b. Candidate key adalah suatu atribut atau set minimal atribut
yang mengidentifikasikan secara unik suatu kejadian spesifik
dari entity.
c. Primary key adalah satu atribut atau set minimal atribut yang
tidak hanya mengidentifikasikan secara unik suatu kejadian
spesifik, tapi juga dapat mewakili setiap kejadian dari suatu
entity.
d. Alternative key adalah kunci kandidat yang tidak terpakai
sebagai kunci primer.
e. Foreign key adalah satu atribut yang melengkapi satu
hubungan (relationship) yang menunjuk ke induknya.

12
2.4 Pengertian OLTP (On-Line Transaction Processing)
Menurut Inmon (2005, p500) OLTP adalah lingkungan permrosesan
transaksi performance tingkat tinggi. OLTP (On-Line Transaction Processing)
menggambarkan kebutuhan sistem dalam ruang lingkup operasional dan
merupakan proses yang mendukung operasi bisnis sehari-hari.
OLTP dirancang untuk memungkinkan terjadinya pengaksesan secara
bersamaan oleh beberapa user terhadap sumber data yang sama dan mengatur
proses yang diperlukan. Sesuai dengan namanya, OLTP mengizinkan transaksi
untuk mengakses langsung ke database. Transaksi yang dilakukan termasuk
operasi insert, update, dan delete. Database OLTP biasanya bersifat relasional
dan dalam bentuk normal ketiga, serta yang terpenting, database OLTP dibangun
untuk mampu menangani banyak transaksi dengan performa tinggi.
Jadi dapat disimpulkan, bahwa OLTP memungkinkan banyak user untuk
mengakses secara bersamaan terhadap sumber database yang sama, dimana
database-nya bersifat relasional dan sudah ternormalisasi.
2.5 Pengertian Data warehouse
Menurut Connnolly (2005, p1151) , data warehouse adalah koleksi data
yang mempunyai sifat berorientasi pada subjek, terintegrasi, memiliki rentang
waktu, dan koleksi datanya tidak mengalami perubahan dalam mendukung
proses pengambilan keputusan ditingkatan manajerial.

13
Menurut Inmon (2002, p495), data warehouse adalah koleksi data yang
berorientasi subjek (subject oriented), terintegrasi (integrated) memiliki rentang
waktu (time variant), dan tidak mengalamai perubahan (non volatile) untuk
mendukung proses pembuatan keputusan manajemen.
Menurut McLeod (2004, p406), data warehouse adalah sebuah sistem
penyimpanan data yang berkapasitas besar, dimana data dikumpulkan dengan
menambahkan record baru daripada meng-update record yang sudah ada dengan
informasi baru. Data jenis ini digunakan hanya untuk proses pengambilan
keputusan dan bukan untuk kegiatan operasional perusahaan sehari-hari.
Berdasarkan pengertian-pengertian diatas, dapat disimpulkan bahwa data
warehouse adalah kumpulan-kumpulan data yang dapat mendukung proses
pengambilan keputusan dalam suatu perusahaan.
2.6 Karakteristik Data warehouse
Menurut Inmon (Connolly, 2005, p1151), data warehouse memiliki
karakteristik:
• Subject-oriented
Data warehouse diorganisasikan pada subjek-subjek utama dari
perusahaan (seperti pelanggan, produk, dan penjualan), bukan pada area-
area aplikasi utama (seperti faktur pelanggan, kontrol stok, dan penjualan

14
produk). Hal ini tercermin dalam kebutuhan untuk menyimpan data
pendukung keputusan daripada data berorientasi aplikasi.
• Integrated
Sumber data berasal dari sistem-sistem aplikasi perusahaan yang
berbeda-beda. Sumber data sering tidak konsisten misalnya perbedaan
format data. Integrasi sumber data harus dibuat konsisten dalam
menampilkan data agar dapat menyatukan pandangan user terhadap data.
• Time variant
Data dalam data warehouse hanya akurat dan valid pada suatu rentang
waktu tertentu.
Tabel 2.1 Perbandingan waktu data operasional dengan Data warehouse
Data Operasional Data Warehouse
Berisi current data value. Berisi snapshot data sesuai waktu
tertentu.
Horizon waktu dalam range 60-90
hari
Horizon waktu dalam range 5-10 tahun.
Element waktu adalah optional
sebagai key .
Element waktu memiliki key.
Data dapat dirubah. Sekali snapshot dibuat, record tidak
dapat dirubah.

15
• Non-volatile
Salah satu karakteristik data warehouse adalah nonvolatile. Dalam data
warehouse hanya ada 2 operasi data yaitu “load data” dan “acces data”
atau dengan kata lain hanya ada perintah insert dan select. Sehingga
konsekuensi logis bahwa pada desain fisikal dapat dilakukan optimisasi
akses terhadap data serta tidak terdapatnya redundancy data karena
terlebih dahulu sudah dilakukan penyaringan atau seleksi data, Data
warehouse hanya berisi “summary data”, data yang masuk sudah
mengalami transformasi serta terjadinya horizon waktu
Tabel 2.2 Perbandingan Sistem OLTP dengan Data warehouse
Sistem OLTP Sistem Data warehouse
Current Value Data Historical Data
Berorientasi Aplikasi Berorientasi Subjek
Data bersifat dinamis Data bersifat statis
Transaction Driven Analysis driven
Non-reduncancy (normalisasi) Redundancy (denormalisasi)
Menyimpan detail data Menyimpan detail, lightly dan highly
summarized data
Melayani banyak user (operational) Melayani sedikit user (managerial)

16
Mendukung keputusan harian Mendukung keputusan strategis
Sumber : (Connoly, 2005, p1153)
2.7 Struktur Data warehouse
Menurut Inmon (2005, p33), struktur data warehouse terdiri dari older
level of detail, current level of detail, lightly summarized data, dan highly
summarized data. Data yang mengalir ke dalam data warehouse berasal dari
lingkungan operasional. Biasanya transformasi data yang penting terjadi pada
perjalanan dari level operasional ke level data warehouse. Seiring berjalannya
waktu, data dari current detail dapat berubah menjadi older detail. Karena data
diringkas, data mengalami perubahan dari current detail ke lightly summarized
data, kemudian dari lightly summarized data menjadi highly summarized data.
Struktur data warehouse terdiri dari:
• Current Detail Data
Data yang aktif saat ini merupakan level terendah dari data
warehouse, dan biasanya memerlukan tempat penyimpanan (storage)
yang besar. Beberapa alasan mengapa current detail data menjadi
perhatian utama :
- Menggambarkan kejadian yang baru terjadi dan selalu menjadi
perhatian utama.

17
- Sangat besar jumlahnya dan disimpan pada tingkatan penyimpanan
terendah.
- Hampir selalu disimpan di media penyimpanan karena cepat diakses
tetapi mahal dan kompleks diatur.
- Biasa digunakan dalam membuat rekapitulasi data sehingga current
detail data harus akurat.
• Older Detail Data
Merupakan data historis yang bisa berupa hasil backup yang disimpan
dalam media penyimpanan yang terpisah dan dapat diakses kembali pada
saat tertentu. Penyusunan direktori untuk older detail data harus
berdasarkan umur data sehinga dapat memudahkan dalam mengakses.
• Lightly Summarized Data
Merupakan ringkasan dari current detail data, belum bersifat total
summary. Data-data ini memiliki tingkatan detail yang lebih tinggi dan
mendukung kebutuhan data warehouse pada tingkat departemen. Akses
terhadap data jenis ini biasanya digunakan untuk memantau kondisi yang
sedang dan sudah berjalan.
• Highly Summarized Data
Merupakan data yang bersifat total summary. Digunakan untuk
melakukan analisa perbandingan data berdasarkan urutan waktu dan
analisis yang menggunakan database multidimensi.

18
Gambar 2.2 Struktur Data Warehouse
(Johan Setiawan,”Teori Data Warehouse”)
2.8 Metadata
Metadata merupakan data tentang data, gambaran tentang struktur, isi,
kunci, indeks dari data. Metadata bukan merupakan data hasil dari kegiatan
operasional seperti current detail data, older detail data, lightly summarized data,
dan highly summarized data. Metadata memuat informasi penting dalam data
warehouse.
Metadata
Highly summarize
Light ly summarized(Data
Current det ail
Operational transformat io Old detail

19
Metadata digunakan dalam banyak fungsi antara lain :
• Sebagai direktori yang dipakai oleh user dalam mencari lokasi data
dalam data warehouse.
• Sebagai panduan pemetaan dalam proses transformasi dari data
operasional ke dalam lingkungan data warehouse.
• Sebagai panduan untuk proses detail data menjadi summary data untuk
diolah menjadi lightly summarized data dan kemudian menjadi highly
summarized data.
Metadata merupakan suatu bentuk jaringan yang sangat penting bagi
pengguna data warehouse. Data yang tersedia haruslah dapat digunakan oleh
pemakai dengan menggunakan istilah yang sesuai dengan cara pemakai dalam
melakukan pekerjaannya.
Karena data warehouse harus melayani banyak fungsi, metadata penting
memahami data yang sama dengan nama yang berbeda pula. Metadata dibuat
untuk menjawab kebutuhan dari suatu fungsi tertentu karena tiap departemen
biasanya menggunakan struktur data yang spesifik meskipun asal datanya sama.
2.9 Arsitektur Data Warehouse
Arsitektur Data Warehouse adalah sekumpulan aturan dari suatu
struktur yang memberikan kerangka suatu perancangan sistem. Arsitektur data
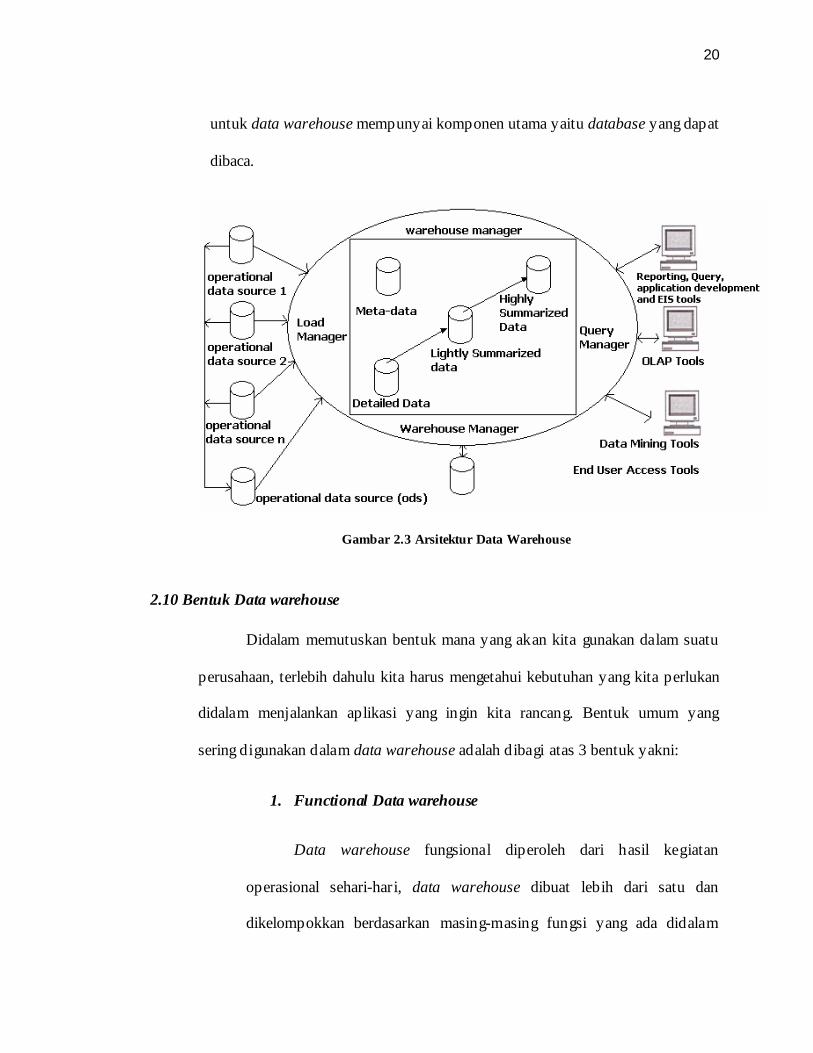
20
untuk data warehouse mempunyai komponen utama yaitu database yang dapat
dibaca.
Gambar 2.3 Arsitektur Data Warehouse
2.10 Bentuk Data warehouse
Didalam memutuskan bentuk mana yang akan kita gunakan dalam suatu
perusahaan, terlebih dahulu kita harus mengetahui kebutuhan yang kita perlukan
didalam menjalankan aplikasi yang ingin kita rancang. Bentuk umum yang
sering digunakan dalam data warehouse adalah dibagi atas 3 bentuk yakni:
1. Functional Data warehouse
Data warehouse fungsional diperoleh dari hasil kegiatan
operasional sehari-hari, data warehouse dibuat lebih dari satu dan
dikelompokkan berdasarkan masing-masing fungsi yang ada didalam

21
perusahaan seperti fungsi keuangan atau financial, fungsi marketing,
fungsi kinerja personalia, dan lain-lainnya. Keuntungan dari bentuk ini
adalah sistem mudah dibangun dengan biaya yang relatif murah
sedangkan kerugiannya adalah resiko kehilangan konsistensi data dan
terbatasnya kemampuan dalam pengumpulan data bagi pengguna.
Gambar 2.4 Functional Data Warehouse
(Johan Setiawan,”Teori Data Warehouse”)
2. Centralized Data warehouse
Centralized Data warehouse mempunyai bentuk seperti
functional data warehouse, namun disini sumber data terlebih dahulu
dikumpulkan atau diintegrasikan pada suatu tempat terpusat, kemudian

22
barulah data tersebut dibagi-bagi berdasarkan fungsi-fungsi yang
dibutuhkan oleh perusahaan, dan bentuk ini sering digunakan oleh
perusahaan-perusahaan yang belum memiliki jaringan eksternal.
Keuntungan dari bentuk ini adalah data benar-benar terpadu karena
konsistensinya yang tinggi sedangkan kerugiannya adalah biaya yang
mahal serta perlu waktu yang cukup lama dalam membangun bentuk
ini.
Gambar 2.5 Centralized Data warehouse
(Johan Setiawan,”Teori Data Warehouse”)
3. Distributed Data warehouse
Distributed Data warehouse menggunakan Gateway yang
berguna sebagai jembatan antara lokasi data warehouse dengan
workstation yang menggunakan sistem yang beraneka ragam atau
berbeda, sehingga pada bentuk ini memungkinkan kita untuk

23
mengakses sumber data yang berada diluar lokasi perusahaan
(eksternal). Data warehouse ini memungkinkan tiap departemen dalam
perusahaan membangun sistem operasionalnya sendiri, serta dapat
membangun pengumpulan data fungsionalnya masing-masing dan
menggabungkan bagian-bagian tersebut dengan teknologi client-server.
Keuntungan dari bentuk ini adalah kelebihan dalam mengakses
data dari luar perusahaan yang telah mengalami sinkronisasi terlebih
dahulu dan tetap terjaga konsistensinya, namun kerugian dari bentuk ini
adalah bentuk yang paling mahal dan kompleks untuk diterapkan,
karena sistem operasinya dikelola secara terpisah.
Gambar 2.6 Distributed Data warehouse
(Johan Setiawan,”Teori Data Warehouse”)

24
2.11. Perancangan Data warehouse
Menurut metodologi Kimball (Connolly, 2005, p1187), terdapat
Sembilan tahapan dalam membangun data warehouse (nine step methodology),
yaitu:
1. Pemilihan proses (choosing the process)
Proses yang mengacu pada subyek yang dibutuhkan oleh data mart.
Pada tahap ini, ditentukan proses bisnis apa yang akan digunakan data
warehouse.
2. Pemilihan grain (choosing the grain)
Tahap yang menentukan apa yang dipresentasikan oleh record tabel
fakta. Pada tahap ini, akan ditentukan tingkat detail data.
3. Identifikasi dan penyesuaian dimensi (identifying and conforming the
dimension)
Membuat dimensi yang dibutuhkan untuk menjelaskan seluruh isi
yang terdapat pada tabel fakta. Sekumpulan dimensi yang terbangun dengan
baik membuat data mart menjadi mudah dimengerti dan mudah digunakan.
Tabel dimensi juga memuat hubungan dari measurement.
4. Pemilihan fakta (choosing the fact)
Tahap pemilihan fakta yang dimaksudkan sebagai sebuah proses yang
menentukan tabel fakta yang dapat mengimplikasikan semua grain yang

25
digunakan pada data mart. Keseluruhan fakta harus diekspresikan pada level
yang dinyatakan oleh grain. Pada tahap ini juga diidentifikasi measurement
yang diperlukan.
5. Penyimpanan pre-calculation di tabel fakta (storing pre-calculation in the
fact table)
Setelah tabel fakta terpilih, setiap tabel fakta tersebut harus diperiksa
ulang untuk menentukan apakah ada fakta-fakta yang dapat diterapkan pre-
calculation dan dilakukan penyimpanan pada tabel fakta.
6. Memastikan tabel dimensi (Roundingn out the dimension table)
Pada tahap ini dilakukan pemeriksaan ulang pada tabel dimensi dan
menambah sebanyak mungkin deskripsi teks dalam dimensi, serta
menentukan hierarki atribut dimensi untuk mempermudah proses analisis.
Gambaran teks haruslah mudah digunakan dan dimengerti user.
7. Pemilihan durasi database (choosing the duration of the database)
Mengukur waktu periode database untuk beberapa tahun kebelakang.
Pada beberapa perusahaan ada kebutuhan untuk melihat data pada waktu
yang sama, atau data setahun, atau dua tahun sebelumnya.
8. Melacak perubahan dari dimensi secara perlahan (tracking slowly changing
dimension)

26
Dimensi dapat berubah secara perlahan seiring berjalannya waktu dan
kebutuhan. Perubahan dalam dimensi yang dimaksud terjadinya perubahan
data (update) dari dimensi. Untuk memantau perubahan tersebut, digunakan
tipe-tipe slowly changing dimension (SCD), yaitu:
• Tipe 1 : Menulis ulang dimensi yang berubah
• Tipe 2 : Menambah baris baru pada tabel dimensi dengan surrogate key
yang baru, tetapi masih menggunakan id yang sama.
• Tipe 3 : Adanya penambahan atribut alternative yang baru sehingga
penggunaan record yang lama dan baru bisa digunakan secara bersamaan
pada satu record dimensi yang sama.
9. Penentuan prioritas dan model query (deciding the query priorities and the
query modes)
Pada tahap ini, kita menentukan masalah desain fisik dari data
warehouse yaitu dengan menentukan urutan fisik dari tabel fakta pada media
penyimpanan dan adanya penggunaan agregasi. Selain itu pada tahap ini
dilakukan pertimbangan terhadap masalah indexing, backup, dan security. Isu
rancangan fisik yang paling kritis yang mempengaruhi persepsi end-user data
mart.

27
2.12 Perancangan Data Warehouse dengan Skema Bintang
Menurut Connoly (2005, p1183), skema bintang adalah sebuah struktur
logika yang mempunyai sebuat tabel fakta yang berisi data fakta di tengah dan
dikelilingi oleh tabel-tabel dimensi yang berisi data referensi atau keterangan
yang biasanya dapat didenormalisasi.
Menurut Poe (1996, p33) metode yang digunakan untuk merancang data
warehouse adalah dengan menggunakan skema bintang, yaitu metode
perancangan yang dilakukan dengan struktur yang sederhana dengan
menggunakan beberapa tabel atau jalur yang terhubung dengan baik dan jelas.
Dengan menggunakan skema bintang ini akan menghasilkan waktu
respon yang lebih cepat dalam query data dibandingkan dengan proses
transaksional dengan menggunakan normalisasi. Selain itu skema bintang
memudahkan end user untuk memahami struktur database pada data warehouse
yang dirancang.
Keuntungan dari penggunaan skema bintang:
1. Respon data lebih cepat daripada perancangan database operasional.
2. Mempermudah dalam hal modifikasi atau pengembangan data warehouse
yang terus menerus.
3. End-user dapat menyesuaikan cara berfikir dan menggunakan data.
4. Menyederhanakan pemahaman dan penelusuran metadata bagi pemakai
dan pengembang.

28
Tabel dalam Skema Bintang
Dalam skema bintang terdapat 2 tipe tabel yaitu tabel fakta dan tabel
dimensi. Tabel fakta disebut juga tabel mayor terdiri dari data kuantitatif atau
data fakta mengenai bisnis, informasi yang diquery. Informasi ini sering diukur
secara numerik dan dapat mengandung banyak kolom dan baris. Tabel dimensi
disebut juga tabel minor karena lebih kecil dan mencerminkan dimensi bisnis.
Jenis Skema Bintang
Dengan penggunaanya terdapat 2 jenis skema bintang yang tergantung
dengan kebutuhan, yaitu Skema Bintang Sederhana dan Skema Bintang
Majemuk yang akan terinci lebih lanjut berikut ini:
Skema Bintang Sederhana
Dalam skema bintang sederhana, setiap tabel
mempunyai primary key yang terdiri dari sebuah kolom atau
lebih. Primary key akan membuat setiap baris menjadi unik.
Primary key tersebut pada tabel fakta akan menjadi foreign key.
Primary key pada tabel fakta, terdiri dari satu atau lebih foreign
key.

29
Gambar 2.7 Skema Bintang Sederhana
(Johan Setiawan,”Teori Data Warehouse”)
Pada gambar menunjukan hubungan antara satu tabel
fakta dan tiga tabel dimensi. Tabel utama terdapat primary key
yang terdiri dari tiga foreign key, yaitu kunci-1, kunci-2 dan
kunci-3, yang masing– masing merupakan primary key di tabel
masing-masing.
Dalam sebuah skema bintang, dapat juga memiliki lebih
dari satu tabel fakta, karena adanya fakta yang tidak saling
berhubungan. Tabel semacam ini umumnya digunakan untuk
jumlah data yang besar dan untuk berbagai macam tabel data yang
teragregasi

30
Gambar 2.8 Skema Bintang Dengan Beberapa Tabel Fakta
(Johan Setiawan,”Teori Data Warehouse”)
Pada gambar diatas terdapat dua tabel fakta dan tiga tabel
dimensi yang memperlihatkan hubungan many to one antara foreign
key pada kedua tabel fakta tersebut dengan primary key pada
masing masing tabel dimensi.
Tabel dimensi mungkin juga mengandung foreign key yang
mereferensikan primary key di tabel dimensi yang lain. Tabel
dimensi yang direferensikan ini dinamakan outboard atau
secondary dimension tabel.

31
Gambar 2.9 Skema Bintang Dengan Tabel Dimensi Tambahan
(Johan Setiawan,”Teori Data Warehouse”)
2.13 ETL (Extract, Transform dan Loading)
ETL merupakan proses-proses dalam data warehouse yang meliputi :
1. mengekstrak data dari sumber-sumber eksternal
2. mentransformasikan data
3. memasukkan data ke bentuk akhir, yaitu data warehouse.
Tujuan ETL adalah mengumpulkan, menyaring, mengolah dan
menggabungkan data-data dari berbagai sumber untuk disimpan ke dalam data
warehouse.

32
Karakteristik dari data ETL antara lain:
• Detailed
Data detail menyediakan fleksibilitas bagi user untuk membentuk
stuktur data menjadi struktur yang paling tepat sesuai dengan yang
dibutuhkan.
• Historical
Data periodik digunakan untuk menyediakan historical perspective.
• Normalized
Normalized data menyediakan integritas dan fleksibilitas yang lebih
baik dibandingkan dengan denormalized data. Pada denormalisasi, data
biasanya digunakan untuk mengakses secara periodik menggunakan
batch process. Beberapa struktur data warehouse adalah denormalisasi.
• Comprehensive
Reconcile data menggambarkan perspektif yang luas, yang dirancang
sesuai model data perusahaan.
• Timely
Untuk data warehousing, data harus lengkap sehingga pembuat
keputusan dapat bertindak saat itu juga.
• Quality Control

33
Kualitas data tidak diragukan dan integritas, karena data sudah
diringkas ke dalam data mart dan digunakan untuk pengambilan
keputusan.
2.14 Pengertian Real Time Data warehouse
Real time data warehouse adalah pengembangan dari data warehouse
tradisional dengan mengurangi waktu proses ETL dari database source ke
database OLAP (data warehouse), sehingga jeda waktu dapat ditekan seminimal
mungkin. Dalam hal ini, bukan berarti tidak ada jeda waktu sama sekali dalam
proses tersebut.
Dalam real-time data warehouse, terdapat 2 hal penting yang harus
dilakukan :
1. Mengurangi atau menghilangkan waktu yang diperlukan untuk
mendapatkan dan mengganti data dari sistem sumber
2. Menghilangkan, atau mengurangi sebanyak mungkin waktu yang
diperlukan untuk extract, transform, dan loading data
Menurut Mike Schmitz, untuk membangun real time data warehouse,
dapat dilakukan dengan dua cara, yaitu:
1. Continuous
Proses ETL secara terus menerus dari database source ke data
warehouse, menggunakan trigger.

34
2. Periodic batch
Menggunakan job dalam menjalankan proses transform ke data
warehouse.
2.14.1 Proses CTF (Capture, Transform, Flow)
Proses ETL merupakan proses yang membutuhkan resource yang
besar dan waktu yang panjang. Kebanyakan tools ETL juga bukan
merupakan engine real-time. Karena pertumbuhan bisnis dan peningkatan
data, proses ETL semakin tidak efektif untuk dipakai. Karena itulah
diberikan solusi yaitu proses CTF (Capture, Transform, Flow)
Gambar 2.10 Proses CTF dalam Data Warehouse
(www.grcdi.nl/considerations.pdf

35
A. Capture
Terdapat beberapa teknik digunakan oleh data
integration/software tambahan untuk memindahkan data. Pada dasarnya,
integration tools melakukan salah satu ”push” dan ”pull” pada data yang
akan dipindah pada sebuah event driven atau polling basis.
Push integration dimulai pada sumber setiap target yang ter-
subscribe, artinya, seiring perubahan terjadi, maka akan terjadi capture
dan pengiriman atau “push” melalui setiap target.
Pull integration dimulai pada target oleh setiap target yang di-
subscribe. Dengan kata lain, sistem target meng-extract perubahan yang
di-capture dan melakukan “pull” ke database local.
Event driven integration merupakan teknik yang melibatkan
kejadian pada sumber memulai capture dan transmisi perubahan yang
terjadi.
Polling melibatkan proses pengawasan yang menyelidiki status
untuk memulai capture dan aplikasi perubahan database.
”Change data capture”, setiap terjadi penambahan, perubahan,
atau penghapusan dalam lingkungan database, secara otomatis di-capture
dan dilakukan ”push” secara real-time ke data warehouse. Update pada
data warehouse dilakukan secara incremental, sehingga hanya data
terbaru saja dari update terakhir yang akan di-push ke data warehouse.

36
B. Transformation
Proses transform data melalui beberapa lingkungan komputer dan
database bisa memperbaiki masalah pada saat menggabungkan informasi
untuk data warehouse.
Transformasi data dan integrasi software bisa memenuhi
kebutuhan ini untuk membuat data warehouse lebih berguna dan
bermakna untuk user.
Proyek data warehouse memerlukan data operasional di ubah
formatnya, peningkatan dan standarnisasi untuk mengoptimalkan
performance data warehouse.
C. Flow
Proses flow menunjuk kepada proses melengkapi bahan dari data
yang telah di-transfrom pada real time dari sistem operasional kesatu atau
lebih sistem subscriber. Aliran data harus lancar dan arus informasi bits
yang berlanjut sambil melawan batch loading dari data.
2.15 Oracle Real Time Data Warehouse
Oracle secara bertahap telah memperkenalkan fitur-fitur dalam database
yang telah mensupport real time data warehouse, fitur-fitur tersebut meliputi :
1. change data capture

37
2. external tabel, tabel functions, pipelining, dan merge command
3. fast refresh materialized views
Dalam penulisan ini, hanya akan dijelaskan fitur change data capture
yang akan digunakan dalam pembuatan skripsi kami.
2.15.1 Change Data Capture (CDC)
Dalam proses extract hal yang sangat penting adalah incremental
extraction, yang disebut Change Data Capture. Pada saat data warehouse
mengambil data dari sistem operasional, maka data warehouse
memerlukan data yang hanya telah mengalami perubahan sejak proses
extract terakhir. Change Data Capture merupakan kunci yang
memungkinkan teknologi real time data warehousing.
Change Data Capture adalah sebuah set software dengan pola
design untuk menetapkan dan mengecek data yang telah berubah dalam
database sehingga data tersebut dapat diambil sebagai data yang berubah.
Change Data Capture (CDC) adalah pendekatan innovative untuk
data terintegrasi yang berdasarkan proses identifikasi, menangkap, dan
mengirim perubahan yang terjadi kedalam sumber data perusahaan.
Change Data Capture merupakan elemen penting untuk
mengoptimalkan proses extract dari source sistem. Chage data capture
tidak meng-extract ulang semua data dari sumber, tetapi hanya
mengambil data yang berubah dan terbaru. Change Data Capture

38
membantu mengidentifikasi data dalam sumber sistem yang telah
berubah sejak proses extract terakhir. Dengan Change Data Capture,
proses extract data berlangsung pada waktu yang sama dengan operasi
INSERT, UPDATE dan DELETE yang terjadi pada tabel sumber, dan
data yang berubah disimpan di dalam database change tabel. Data yang
berubah, saat ditangkap, lalu tersedia untuk target sistem dalam suatu
cara terkendali, menggunakan database view.
Change Data Capture melakukan extract dengan efisien hanya
pada data yang baru, telah berubah datanya, sehingga change data
capture melakukan extract pada volume data yang lebih kecil. Change
data capture dapat mengidentifikasi data yang berubah pada source
sistem.
Oracle Change Data Capture dapat mengatasi masalah-masalah berikut :
1. Oracle Change Data Capture menyediakan kemampuan untuk
menangkap data yang berubah dari oracle database. Yang dapat
diambil pada keadaan synchronously dan asynchronously dengan
memanfaatkan archive redo log.
2. Oracle Change Data Capture menyediakan kemampuan tidak
hanya menangkap data yang berubah, tapi juga mempublikasikan
data tersebut dan mengijinkan aplikasi untuk menggunakan data
tersebut.

39
3. Oracle Change Data Capture framework dapat digunakan untuk
mengoptimalkan proses ETL (Extract, Transformation dan
Loading).
Change Data Capture memiliki komponen-komponen :
1. Source sistem : OLTP database dalam database Oracle. Karena
CDC menangkap perubahan yang terjadi dalam sumber tabel
secara terus menerus dan real time, overhead yang drastis terjadi
selama waktu penangkapan.
2. Change Source : (SYNC_SOURCE merupakan sistem yang
dihasilkan oleh sumber perubahan), menampilkan sistem sumber
dan memuat set perubahan (koleksi dari tabel yang berubah).
3. Change Set : (SYNC_SET merupakan sistem yang dihasilkan dari
set perubahan) merupakan koleksi dari satu atau banyak tabel
yang berubah.
4. Change Tabel merupakan tabel relational yang memuat semua
sumber data tabel yang berubah dan juga sistem metadata yang
dibutuhkan untuk mengatur tabel yang berubah. Publisher,
sebagai DBA yang bertanggung jawab untuk mensetting CDC
data sistem dan mengaturnya. Publisher mengidentifikasi tabel
sumber dimana data yang berubah harus ditangkap dan
mengirimnya ke dalam tabel yang berubah. Publisher juga

40
mengatur akse untuk mempublikasikan data tersebut dengan
menggunakan hak akses seperti GRANT dan REVOKE.
5. Subscriber merupakan aplikasi data warehouse yang
menggunakan data yang berubah.
Arsitektur Change Data Capture didasarkan pada
publisher/subscriber model. Publisher menangkap data yang berubah
tersebut dan membuat data tersebut tersedia untuk subscriber. Subscriber
menggunakan data yang diperoleh dari publisher. Pada umumnya,
Change Data Capture sistem mempunyai satu publisher dan banyak
subscriber.
Publisher pertama kali mengidentifikasi tabel sumber dimana
perubahan data perlu untuk ditangkap. Kemudian, menangkap data yang
berubah tersebut dan menyimpannya dalam tabel perubahan yang
diciptakan. Lalu, mengijinkan subscriber mengawasi akses kepada data
tersebut
Change Data Capture dapat menangkap dan menerbitkan
perubahan data yang dilakukan dalam salah satu mode berikut :
1. Synchronous

41
Dengan menggunakan trigger pada source database,
setiap perubahan data akan langsung ditangkap setelah operasi
DML (INSERT, UPDATE dan DELETE). Dalam mode ini,
perubahan data ditangkap sebagai bagian dari transaksi saat
merubah tabel sumber.
Gambar 2.11 Synchronous Change Data Capture
(Oracle Database Data Warehousing Guide 10g Release 2)
2. Asynchronous
Perubahan data ditangkap setelah SQL statement
menjalankan operasi DML, dengan menggunakan kelebihan
dari data yang dikirim pada redo log file. Dalam mode ini,

42
perubahan data tidak ditangkap sebagai bagian dari transaksi
yang merubah tabel sumber dan karena itu tidak
mempengaruhi transaksi.
Gambar 2.12 Asynchronous AutoLog Change Data Capture
(Oracle Database Data Warehousing Guide 10g Release 2)
Berikut ini merupakan keuntungan dari menangkap perubahan
data menggunakan Change Data Capture :
1. Completeness

43
Change Data Capture dapat menangkap semua
dampak dari operasi insert, update dan delete, termasuk nilai
dari sebelum dan sesudah operasi update.
2. Performance
Asynchronous Change Data Capture dapat
dikonfigurasi untuk meminimalkan dampak performance
dalam sumber database.
3. Interface
Change Data Capture berisi paket PL/SQL
DBMS_CDC_PUBLISH dan DBMS_CDC_SUBSCRIBE, yang
memberikan kemudahan untuk digunakan dalam mem-publish
dan subscribe interface.
4. Cost
Change Data Capture mengurangi biaya pengeluaran
karena proses ini menyederhanakan proses extract dari
perubahan data dari database sumber.