populasi sasaran sampling desain sampling ukuran sampel · sampel perlu kehati-hatian, sebab akan...
TRANSCRIPT

Populasi Sasaran
Sampling
Desain Sampling
Ukuran Sampel
tedi – last 09/18

Populasi keseluruhan objek/unsur yang memiliki
karakteristik/kualitas/sifat tertentu yang akan diteliti,
misalnya : seluruh bank umum di Indonesia, jumlah tenaga
kerja di sektor Perbankan, jumlah laba bersih per tahun
yang diraih PT A sejak berdiri, dll.
Populasi sasaran populasi yang telah didefinisikan
dengan jelas dengan cara memberikan batasan yang ketat
guna keperluan penarikan sampel, misal : seluruh bank
umum devisa yang beroperasi di Jawa Barat ; Jumlah
tenaga kerja asing pada bank umum swasta yang listing di
BEI, jumlah laba bersih per tahun yang diraih PT A sejak
perusahaan diakuisisi oleh PT Q.

Berdasarkan sifatnya, populasi dikelompokan menjadi :
1.Populasi homogen populasi dimana unsur-unsurnya
memiliki sifat-sifat yang relatif seragam, misal : bank
umum devisa di Indonesia, keseluruhan buruh di
departemen pabrikasi sektor manufaktur di kawasan
industri karawang.
2.Populasi heterogen populasi dimana unsur-unsurnya
memiliki sifat-sifat yang relatif berbeda, misal : seluruh
wajib pajak di Jawa Barat (WP Orang Pribadi : WP
dengan penghasilan dari pekerjaan, WP dengan
penghasilan dari usaha, WP dengan penghasilan dari
pekerjaan bebas dll ; WP Badan : WP Besar, WP
Menengah, WP Kecil dst)

Berdasarkan ukurannya, populasi dikelompokan menjadi :
1. Populasi terhingga Populasi dengan unsur/objek yang
dapat diperkirakan atau diketahui secara pasti
jumlahnya, atau memiliki batasan yang jelas secara
kuantitatif, misal : Jumlah Bank Umum yang beroperasi
di Indonesia dalam 5 tahun terakhir ; Jumlah PNS di
Kota Tasikmalaya.
2. Populasi tak hingga populasi dengan unsur/objek
yang tidak dapat diperkirakan atau tidak dapat
diketahui jumlahnya, atau batas-batasnya tidak dapat
ditentukan secara kuantitatif, misal : Jumlah pedagang
K.5 di Tasikmalaya ; Jumlah mukena bordir khas Kawalu
yang diproduksi oleh seluruh perusahaan/pengusaha
bordir di Tasikmalaya tahun 2015.

Model Sampling :
Sumber : Newman (2014 )

Pada statistika induktif, terdapat metode yang
memungkinkan peneliti mempelajari sebagian dari
unsur/objek anggota populasi, dan kemudian menarik
kesimpulan/generalisasi yang berlaku untuk populasinya
melalui pengujian parameter (misal : µ, σ, σ2, β, ρ)
dengan statistik ( 𝑥, s, s2, b, r)
Sumber : Sekaran et al (2009)

Beberapa alasan dilakukannya sampling dalam proses
pengumpulan data adalah :
1. Ukuran populasi yang besar/tak hingga
2. Sensus memerlukan biaya yang besar/mahal
3. Sensus memerlukan waktu yang relatif lama
4. Adanya percobaan yang sifatnya merusak, sehingga
tidak mungkin dilakukan sensus
5. Masalah ketelitian, dimana semakin banyak objek
yang harus dipelajari, maka tingkat ketelitiannya
cenderung berkurang
6. Pertimbangan ekonomis, yaitu biaya, waktu, dan
tenaga harus dipertimbangan sedemikian rupa
disesuaikan dengan manfaat/kegunaan hasil
penelitiannya.

Pengambilan keputusan untuk menetapkan/memilih
sampel perlu kehati-hatian, sebab akan jarang sampel
menjadi replika yang tepat dari populasinya.
Secara ilmiah, peneliti umumnya dapat memperoleh
keyakinan bahwa statistik sampel ( 𝑥, s, s2, b, r) cukup
dekat dengan/mampu mendekati nilai parameter
populasinya (misal : µ, σ, σ2, β, ρ). Hal tersebut
dimungkinkan dengan menetapkan sampel yang
representatif dengan menggunakan Teknik Sampling.
Sampling adalah proses pemilihan unsur yang tepat dalam
jumlah yang memadai dari populasinya, sehingga kajian
dan pemahaman tentang sifat atau karakteristik unsur
dalam sampel memungkinkan untuk digeneralisasi seperti
pada populasinya.

Langkah-langkah utama dalam pengambilan sampel
meliputi :
1. Tentukan dan definiskan populasi sasaran secara
jelas (misal : dalam hal unsur-unsur, batas
geografis, dan waktu).
2. Tentukan kerangka sampel yang
merepresentasikan semua unsur dalam populasi
dari mana sampel diambil (misal : Standar Gaji
Pemerintah sebagai kerangka sampling dari PNS
yang diteliti kesejahteraannya).
3. Tentukan desain sampel (Probability dan
nonprobability sampling),
4. Tentukan ukuran sampel yang representatif.

Dipandang dari sudut peluang/probabilitas, desain
sampling dibagi menjadi 2 (dua) tipe, yaitu :
1.Non Probability Sampling :
a) Haphazard/fortuitous/accidental sampling,
b) Convinience Sampling
c) Voluntary sampling,
d) Purposive/judgement sampling/expert choise)
e) Snowball Sampling,
f) Quota Sampling,
2.Probablility Sampling :
a) Simple Random Sampling,
b) Systematic Sampling,
c) Stratified Random Sampling,
d) Cluster Random Sampling,

Haphazard/fortuitous/accidental sampling sampling
seadanya, yaitu sampling dimana satuan sampling
diperoleh secara sembarang karena besarnya populasi
tidak diketahui secara kuantitatif, dimana peneliti
menetapkan sifat item yang dijadikan responden, batas
geografis, dan rentang waktu untuk pengumpulan data
sekaligus finalisasi ukuran sampel. (misal : sampel
konsumen yang berbelanja di pasar modern menggunakan
kartu kredit – responden adalah orang yang datang ke
toserba ‘A’ di Kota tasikmalaya dalam rentang waktu 14
hari (tgl … s/d … bln … th) dan memenuhi kriteria
(pengguna kartu kredit, dll) yang ditetapkan peneliti, serta
bersedia memberikan informasi).
Catatan :
Haphazard sampling juga meliputi Convenience sampling

Convenience sampling yaitu sampling yangmengacu pada pengumpulan data/informasi darisatuan sampling yang dengan sukarela (dengansenang hati) bersedia memberikan informasi yangdiperlukan. Peneliti biasanya menggunakan samplingtsb pada tahap awal eksplorasi guna memperolehinformasi dasar secara cepat dan efisien (Sekaranand Bougie, 2009). Sampling tsb biasanya digunakanpada penelitian eksploratory yang bersifat kualitatif(Zikmund and Babin, 2010 ; Newman, 2014). Misal :peneliti ingin memperoleh informasi mengenaistrategi penjualan dan harga produk tertentu yangdihasilkan oleh 15 perusahaan -- maka peneliti akanmenjadikan Costumer Service atau manajerpenjualan dari ke-15 perusahaan yang menghasilkanproduk ydm sebagai responden.

Voluntary sampling sampling sukarela, yaitusatuan sampling yang ditetapkan berdasarkankesediannya secara sukarela untuk menjadiresponden yang dikontrol (mendapatkan perlakuankhusus) oleh peneliti (misal : sampel konsumenyang bersedia mengkonsumsi produk suplemenmakanan Merk ‘X’ dari suatu Perusahaan untukdipelajari peningkatan kualitas kesehatannya –-peneliti akan menyeleksi orang yang bersediauntuk dijadikan responden (sebanyak yangditentukan peneliti), memberikan arahan danmelakukan monitoring kepada responden terpilihselama mengkonsumsi suplemen merk ‘X’ tsbdalam kurun waktu yang telah ditentukan).

Purposive/judgemental sampling sampling
dengan pertimbangan yaitu pemilihan satuan
sampling dilakukan atas dasar pertimbangan orang
yang kompeten (pakar, pimpinan) yang berada
pada posisi yang tepat untuk memberikan
informasi pada bidang yang sedang diteliti
sehingga dapat menentukan dan mengakses satuan
sampling yang diperlukan peneliti (contoh : sampel
saldo piutang usaha yang perlu konfirmasi positif,
memerlukan pertimbangan auditor senior/ketua
tim audit untuk menentukan ukuran dan memilih
item sampel).
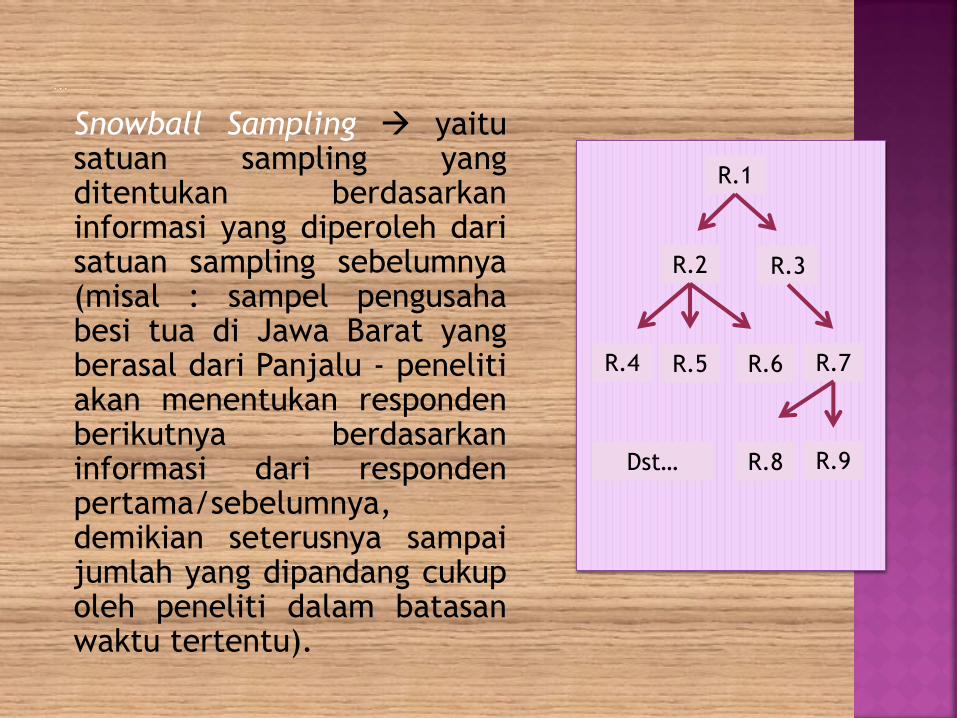
Snowball Sampling yaitusatuan sampling yangditentukan berdasarkaninformasi yang diperoleh darisatuan sampling sebelumnya(misal : sampel pengusahabesi tua di Jawa Barat yangberasal dari Panjalu - penelitiakan menentukan respondenberikutnya berdasarkaninformasi dari respondenpertama/sebelumnya,demikian seterusnya sampaijumlah yang dipandang cukupoleh peneliti dalam batasanwaktu tertentu).
R.1
R.2
R.4 R.5
R.3
R.7R.6
R.9R.8Dst…

Quota Sampling yaitu satuan sampling yangdikumpulkan berdasarkan kategori yang telahdirinci terlebih dahulu (contoh : Peneliti inginmengetahui tingkat kepatuhan Wajib Pajak –peneliti menentukan satuan sampling dengan cara(a) quota I : ditentukan jumlah responden,misalnya 100 Wajib Pajak di Kota Tasikmalaya ; (b)quota II : 50 WP Badan dan 50 WP Orang Pribadi ;(c) quota III : untuk responden WP Orang Pribadiditentukan 20 WP dengan penghasilan daripekerjaan, 15 WP dengan penghasilan dari usaha,15 WP dengan penghasilan dari pekerjaan bebas, …dst -- umumnya distribusi kuota ditentukan secaraproporsional --).

Simple Random Sampling yaitu proses memilih
satuan sampling dari populasi yang dianggap
homogen dan terhingga, dimana setiap satuan
sampling dalam populasi mempunyai peluang yang
sama besar untuk terpilih (peluang yang dimaksud
diketahui sebelum pemilihan dilakukan baik dengan
cara replacement ataupun placement). Penentuan
satuan sampling ditetapkan dengan menggunakan
angka random (tabel/kalkulator/program komputer)
dengan terlebih dahulu anggota populasi diberi
kode/nomor urut berdasarkan aturan angka random,
sehingga hasilnya objektif/tidak bias.

Systematic Sampling simple random samplingyang dimodifikasi dalam menetapkan satuansampling dari populasinya yaitu denganmenghitung jarak interval waktu/ruang, atauurutan yang uniform dari satuan sampling pertamayang ditetapkan menggunakan angka random.Systematic sampling dipandang lebih praktis dancepat dibanding dengan simple random sampling.
Catatan :
Menghitung Interval (k) : 𝐤 =𝐍
𝐧Dimana :k = interval/jarak satuan samplingN = ukuran populasiN = ukuran sampel

Contoh :
Misal :
N = 40 ; n = 10
Maka :
𝑘 =40
10= 4
Misal angka
random I
terpilih 90122,
Satuan
sampling
berikutnya
adalah :
ARn= Arn-1 + k
AR2= 22+4 = 26

Stratified Random Sampling
yaitu proses pemilihan satuan
sampling dengan cara
mengelompokkan terlebih
dahulu anggota-anggota
populasinya yang heterogen ke
dalam beberapa strata
berdasarkan karakteristiknya
sehingga satuan sampling pada
setiap strata menjadi homogen.
Contoh :
Bila N = 200 terdiri atas : Ka.
Dinas = 20 orang ; Kabag. =
60 orang, dan ; Kasubag. = 120
orang
Bila n = 40 orang, maka :
Strata
(Jabatan)
N = 200n=40
niNi %
Ka. Dinas 20 10 4
Kabag 60 30 12
Kasubag 120 60 24
200 100 40
Catatan :
Distribusi satuan sampling pada setiap
strata secara proporsional : 𝑛𝑖 =𝑁𝑖
𝑁∗ 𝑛 ; misal ; 𝑛1 =
20
200∗ 40 = 4

Cluster Random Sampling
yaitu proses memilih satuan
sampling dgn cara anggota-
anggota populasinya yang
heterogen dikelompokan terlebih
dahulu kedalam beberapa kluster
yang tidak berjenjang
berdasarkan karakteristiknya,
sehingga satuan sampling pada
setiap kluster menjadi homogen.
Contoh :
Bila N = 200 terdiri atas : TNI =
20 orang ; PNS = 60 orang, dan ;
Buruh = 120 orang
Bila n = 40 orang, maka :
Kluster
(Pekerjaan)
N = 200n=40
niNi %
TNI 20 10 4
PNS 60 30 12
Buruh 120 60 24
200 100 40
Catatan :
Distribusi satuan sampling pada setiap
kluster secara proporsional : 𝑛𝑖 =𝑁𝑖
𝑁∗ 𝑛 ; misal ; 𝑛1 =
20
200∗ 40 = 4

Catatan :Pendistribusian satuan sampling pada setiap strata ni
(stratified random sampling) atau kluster nj (cluster
random sampling) dapat juga menggunakan pendekatan
disproporsional (Optimum allocation) dengan
mempertimbangkan ukuran dan variabilitas setiap
strata/kluster populasi Nj.
Informasi tambahan yang diperlukan adalah simpangan
baku populasi ke-j (σj) setiap strata/kluster (Nj), dimana
alokasi/distribusi satuan sampling dapat ditetapkan sbb :
Sumber : Newbold et al (2013)
Dimana :
σj = simpangan baku strata/kluster ke-j

Faktor yang perlu dipertimbangkan dalam
menentukan ukuran sampel :
1. Tujuan penelitian yang ingin dicapai.
2. Sifat dan ukuran populasi (populasi homogen vs
populasi heterogen, dan populasi terhingga vs
populasi tak hingga),
3. Tingkat keragaman (variabilitas) anggota populasi
sasaran.
4. Keterbatasan/kendala yang dihadapi peneliti
(biaya, waktu, dll.)
5. Taraf Nyata yang dapat diterima (penelitian
dalam ilmu sosial umumnya menggunakan taraf
nyata α = 5% atau tingkat keyakinan 95% ).

Roscoe (1975) seperti dikutif oleh Sekaran dan Bougie
(2009) mengemukakan pedoman praktis untuk menentukan
ukuran sampel, yaitu :
1. Ukuran sampel 30 ≤ n ≤ 500 dipandang paling memadai
pada kebanyakan penelitian.
2. Bila sampel dibagi menjadi beberapa sub-sampel ni
(strata/kluster), maka sebaiknya ukuran sampel
minimum untuk masing-masing sub-sampel ni
(strata/kluster) adalah 30.
3. Pada penelitian multivariat (termasuk analisis regresi
berganda), ukuran sampel sebaiknya beberapa kali
(misal : ≥ 10 kali) lebih besar besar dari jumlah variabel
yang diteliti.
4. Untuk penelitian eksperimental sederhana dengan
kontrol yang ketat, penelitian dipandang berhasil pada
ukuran sampel 10 ≤ n ≤ 30.
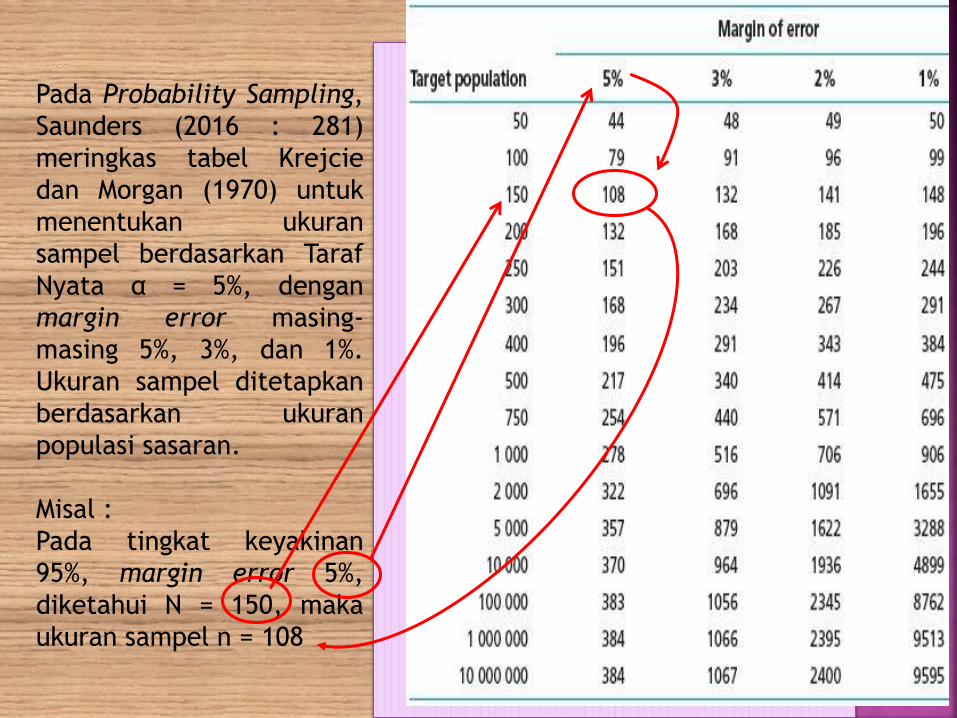
Pada Probability Sampling,
Saunders (2016 : 281)
meringkas tabel Krejcie
dan Morgan (1970) untuk
menentukan ukuran
sampel berdasarkan Taraf
Nyata α = 5%, dengan
margin error masing-
masing 5%, 3%, dan 1%.
Ukuran sampel ditetapkan
berdasarkan ukuran
populasi sasaran.
Misal :
Pada tingkat keyakinan
95%, margin error 5%,
diketahui N = 150, maka
ukuran sampel n = 108
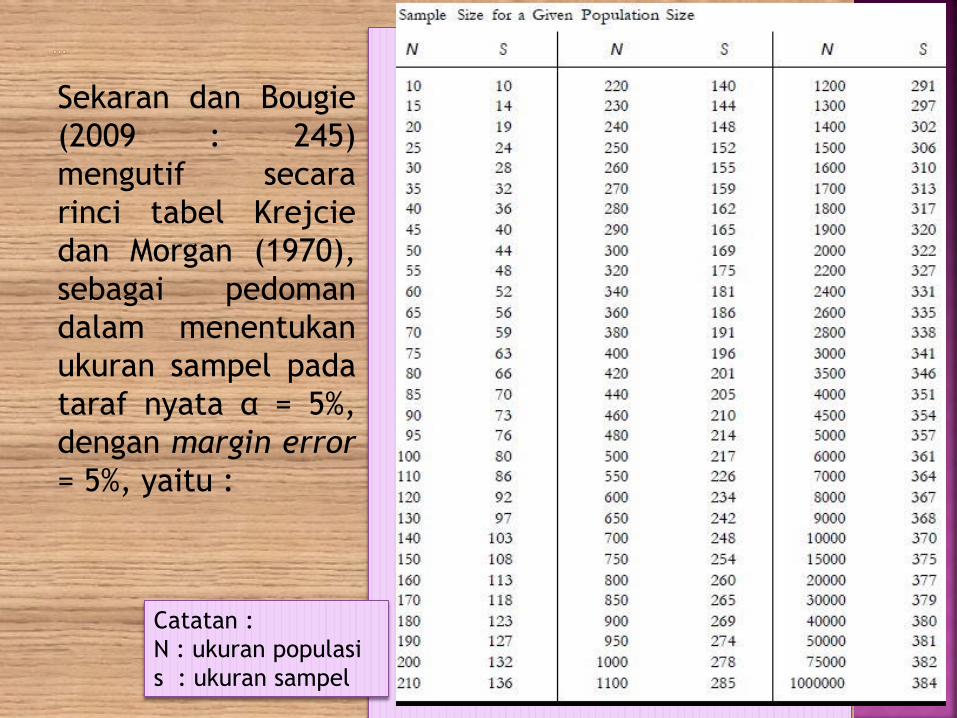
Sekaran dan Bougie
(2009 : 245)
mengutif secara
rinci tabel Krejcie
dan Morgan (1970),
sebagai pedoman
dalam menentukan
ukuran sampel pada
taraf nyata α = 5%,
dengan margin error
= 5%, yaitu :
Catatan :
N : ukuran populasi
s : ukuran sampel
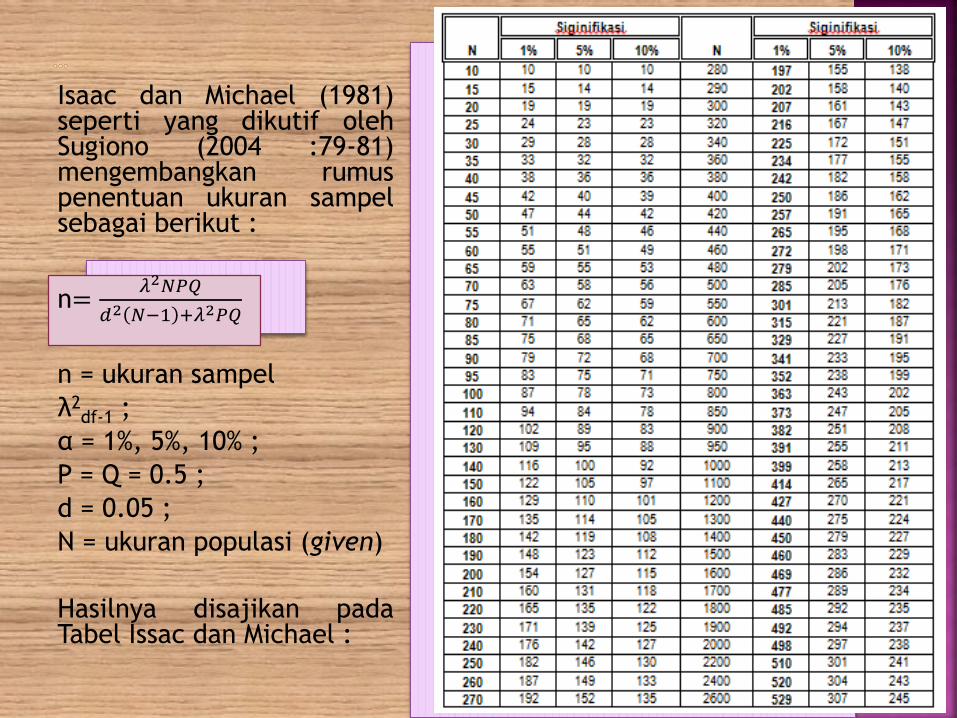
Isaac dan Michael (1981)seperti yang dikutif olehSugiono (2004 :79-81)mengembangkan rumuspenentuan ukuran sampelsebagai berikut :
n=𝜆2𝑁𝑃𝑄
𝑑2 𝑁−1 +𝜆2𝑃𝑄
n = ukuran sampel
λ2df-1 ;
α = 1%, 5%, 10% ;
P = Q = 0.5 ;
d = 0.05 ;
N = ukuran populasi (given)
Hasilnya disajikan padaTabel Issac dan Michael :

Para pakar statistik, mengembangkan rumus
penentuan ukuran sampel berdasarkan teori
probabilitas dengan asumsi bahwa data berdistribusi
normal. Rumus ydm al :
Slovin (1960), menentukan ukuran sampel suatu
populasi terhingga (diketahui ukurannya) yang
diasumsikan berdistribusi normal dengan persamaan
sebagai berikut :
𝑛 =𝑁
1 + 𝑁𝑒2Dimana :
n : ukuran sampel
N : ukuran populasi sasaran
e : error tolerance limmit (misal : 1%, 5%, 10%)

Bila populasi tak hingga, maka perlu ditarik asumsi a.l :1. N tak hingga tetapi diperkirakan sangat besar danberdistribusi normal, maka t = Z
2. Taraf nyata yang digunakan 5% (tingkat keyakinan95%), sehingga nilai t = Z = 1.96 (lihat pada Tabel Z)
3. Distribusi proporsi populasi (P) diasumsikan 0.5,sehingga Q = 1 – P = 0.5 (asumsi ini ditarik bila nilai Ptidak diketahui berdasarkan rujukan penelitiansebelumnya atau literatur lain yang reliabel)
Maka ukuran sampel dapat ditentukan sbb :
𝑛 =𝑡2𝑃𝑄
𝑑2+ 1
Dimana :
d = batas kesalahan (misal : 1%, 5%, 10%),
semakin kecil nilai d maka tingkat
presisinya semakin baik
Rumus penarikan sampel untuk proporsi Cochran, 1977

tedi.share
Disclaimer :
Sumber referensi dapat dilihat pada tautan
http.//tedirustendi32.wordpress.com/… pada laman yg terkait