korelasi
DESCRIPTION
analisis dataTRANSCRIPT

KORELASIKORELASI
Merupakan teknik statistik yang digunakan untuk meguji ada/tidaknya hubungan serta arah hubungan dari dua variabel atau lebih
Korelasi yang akan dibahas dalam pelatihan ini adalah : Korelasi sederhana pearson & spearman
Korelasi partial
Korelasi ganda
KOEFISIEN KORELASI
Besar kecilnya hubungan antara dua variabel dinyatakan dalam bilangan yang disebut Koefisien Korelasi
Besarnya Koefisien korelasi antara -1 0 +1
Besaran koefisien korelasi -1 & 1 adalah korelasi yang sempurna
Koefisien korelasi 0 atau mendekati 0 dianggap tidak berhubungan antara dua variabel yang diuji
ARAH HUBUNGAN Positif (Koefisien 0 s/d 1)
Negatif (Koefisien 0 s/d -1)
Nihil (Koefisien 0)
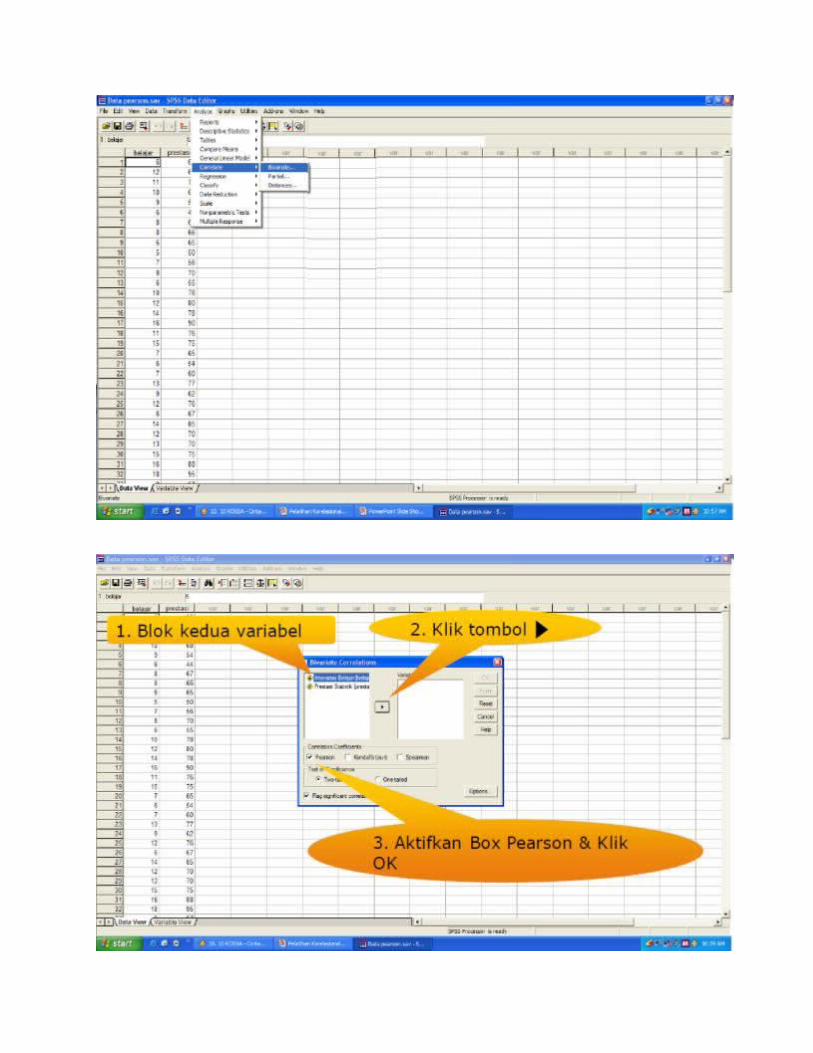
PEARSON CORRELATION Digunakan untuk data interval & rasio
Distribusi data normal
Terdiri dari dua variabel
1 Variabel X (Independen)
1 Variabel Y (dependen)
CONTOH
Judul: Hubungan antara intensitas belajar dengan prestasi mata kuliah statistik Variabel X : Intensitas belajar (diukur dari lamanya belajar dalam satu minggu)
Variabel Y : Prestasi matakuliah statistik (diukur dari nilai ujian akhir semester)
Hipotesa: H0: Tidak ada hubungan antara Intenitas belajar dengan prestasi mata kuliah statistik
Ha: Ada hubungan antara Intenitas belajar dengan prestasi mata kuliah statistik
INPUT DATA KE SPSS

SPSSAda dua view dalam SPSS
Data View : digunakan untuk memasukkan data yang akan dianalisis
Variabel View : digunakan untuk memberi nama variabel dan pemberian koding
UJI NORMALITAS
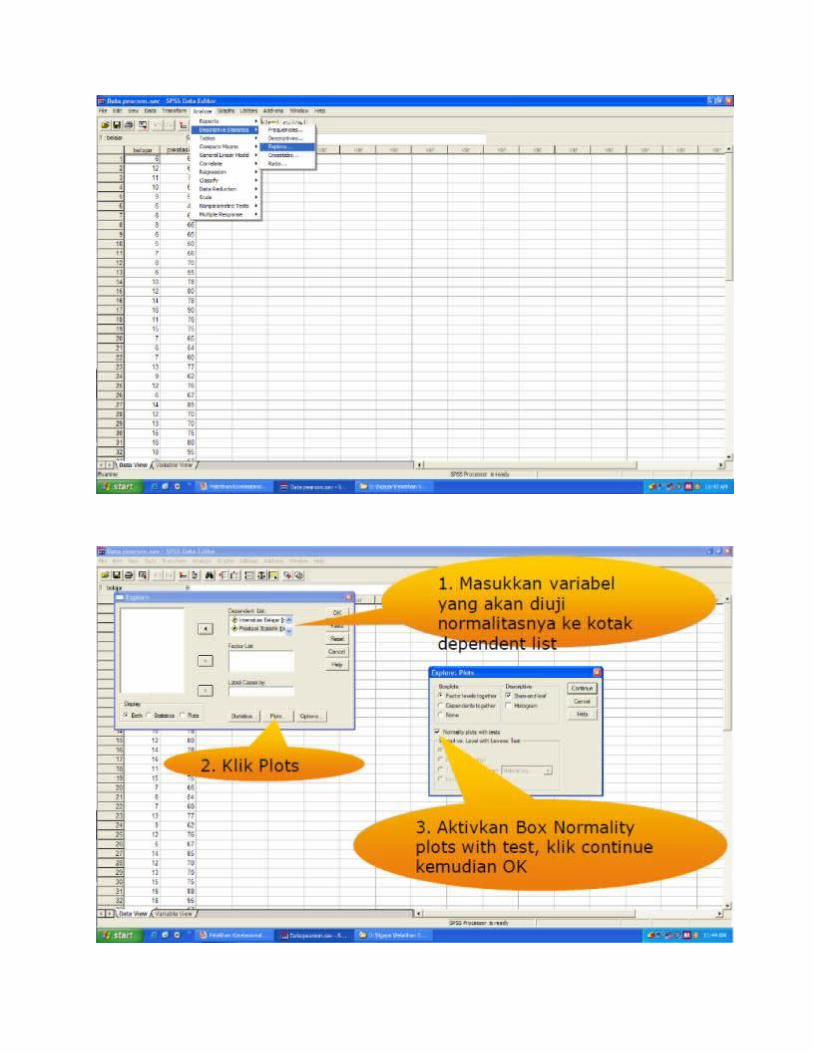

INTERPRETASI NORMALITAS
TAHAP ANALISIS
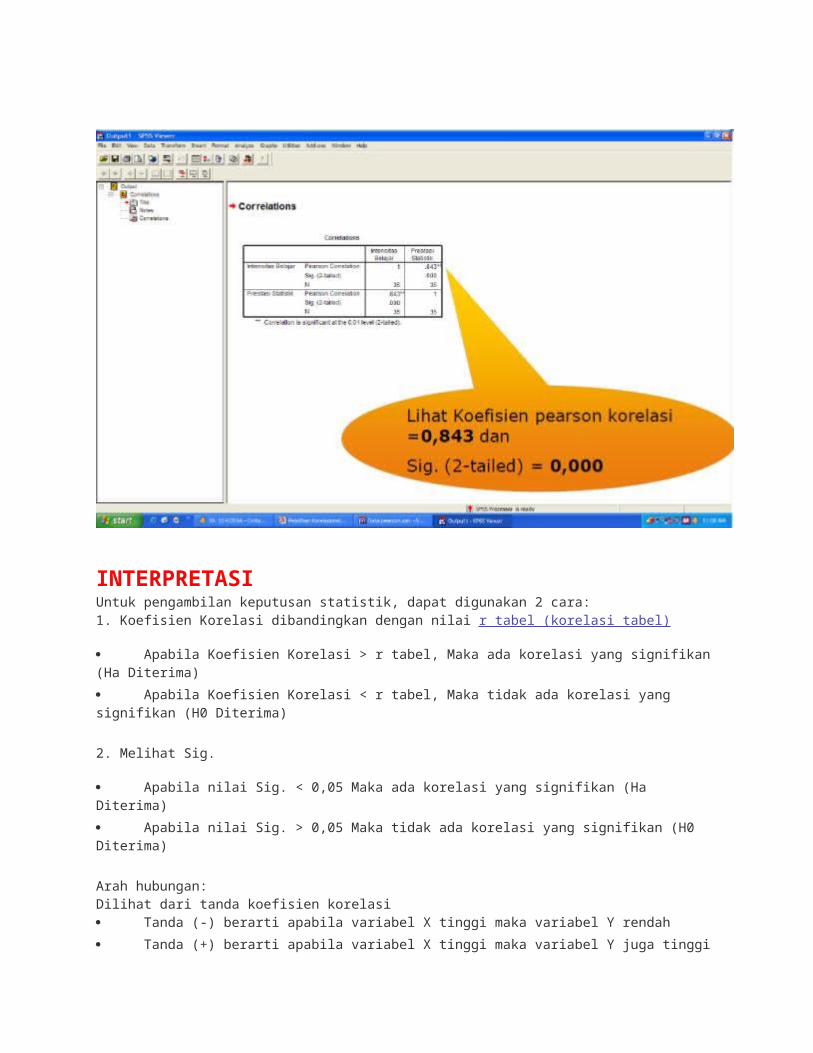
INTERPRETASIUntuk pengambilan keputusan statistik, dapat digunakan 2 cara:1. Koefisien Korelasi dibandingkan dengan nilai r tabel (korelasi tabel)
Apabila Koefisien Korelasi > r tabel, Maka ada korelasi yang signifikan (Ha Diterima)
Apabila Koefisien Korelasi < r tabel, Maka tidak ada korelasi yang signifikan (H0 Diterima)
2. Melihat Sig.
Apabila nilai Sig. < 0,05 Maka ada korelasi yang signifikan (Ha Diterima)
Apabila nilai Sig. > 0,05 Maka tidak ada korelasi yang signifikan (H0 Diterima)
Arah hubungan:Dilihat dari tanda koefisien korelasi Tanda (-) berarti apabila variabel X tinggi maka variabel Y rendah
Tanda (+) berarti apabila variabel X tinggi maka variabel Y juga tinggi
SPEARMAN Digunakan untuk jenis data ordinal
Cara analisis dan interpretasi sama dengan Pearson.
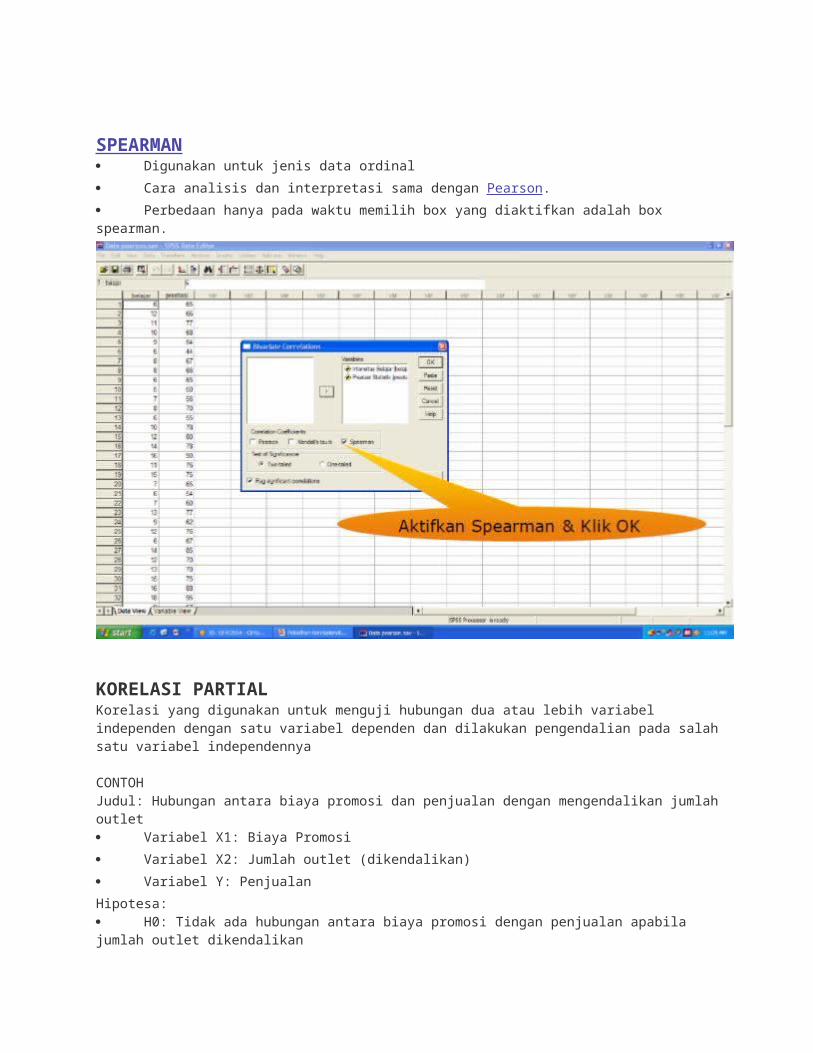
Perbedaan hanya pada waktu memilih box yang diaktifkan adalah box spearman.
KORELASI PARTIALKorelasi yang digunakan untuk menguji hubungan dua atau lebih variabel independen dengan satu variabel dependen dan dilakukan pengendalian pada salah satu variabel independennya
CONTOHJudul: Hubungan antara biaya promosi dan penjualan dengan mengendalikan jumlah outlet Variabel X1: Biaya Promosi
Variabel X2: Jumlah outlet (dikendalikan)
Variabel Y: Penjualan
Hipotesa: H0: Tidak ada hubungan antara biaya promosi dengan penjualan apabila jumlah outlet dikendalikan
Ha: Ada hubungan antara biaya promosi dengan penjualan apabila jumlah outlet dikendalikan
CONTOHBuka data : Korelasi ganda dan partial.sav Data
ANALISIS
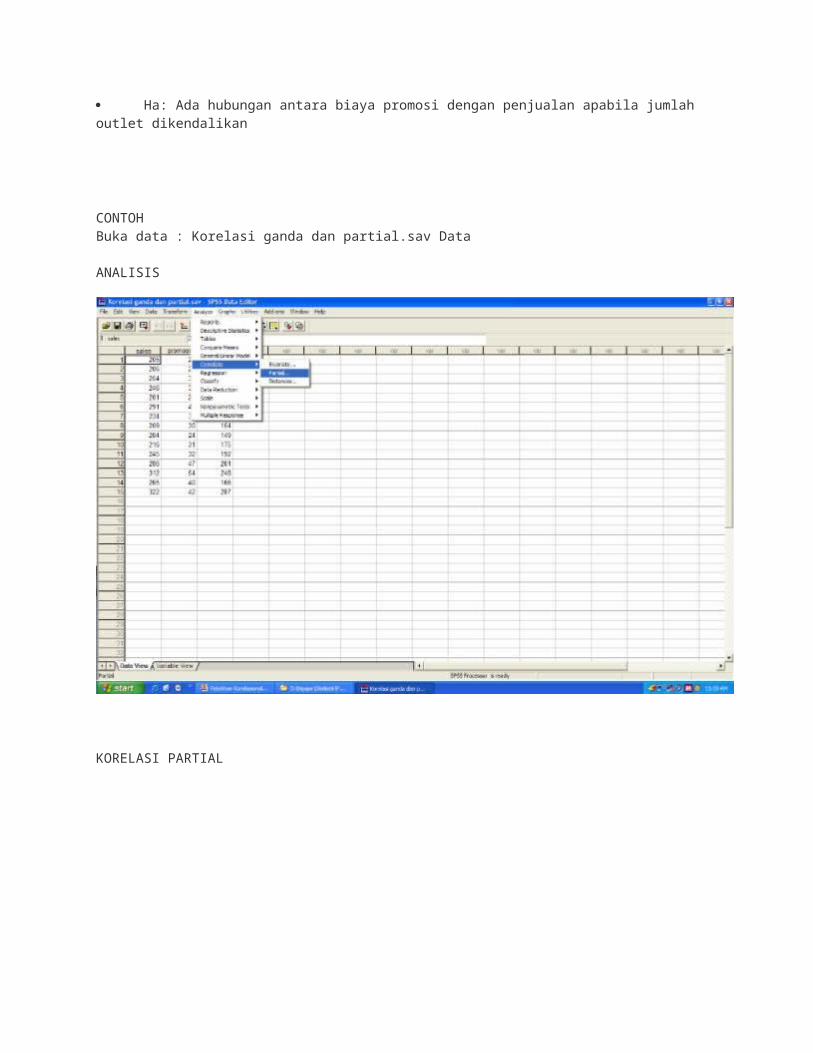
KORELASI PARTIAL

OUTPUT PARTIAL

KORELASI GANDAKorelasi yang digunakan untuk menguji hubungan dua atau lebih variabel independen dengan satu variabel dependen secara bersamaan.
CONTOHJudul: Hubungan antara biaya promosi dan jumlah outlet dengan penjualan
Variabel X1: Biaya Promosi
Variabel X2: Jumlah outlet
Variabel Y: Penjualan
Hipotesa:
H0: Tidak ada hubungan antara biaya promosi dan jumlah outlet dengan penjualan
Ha: Ada hubungan antara biaya promosi dan jumlah outlet dengan penjualan
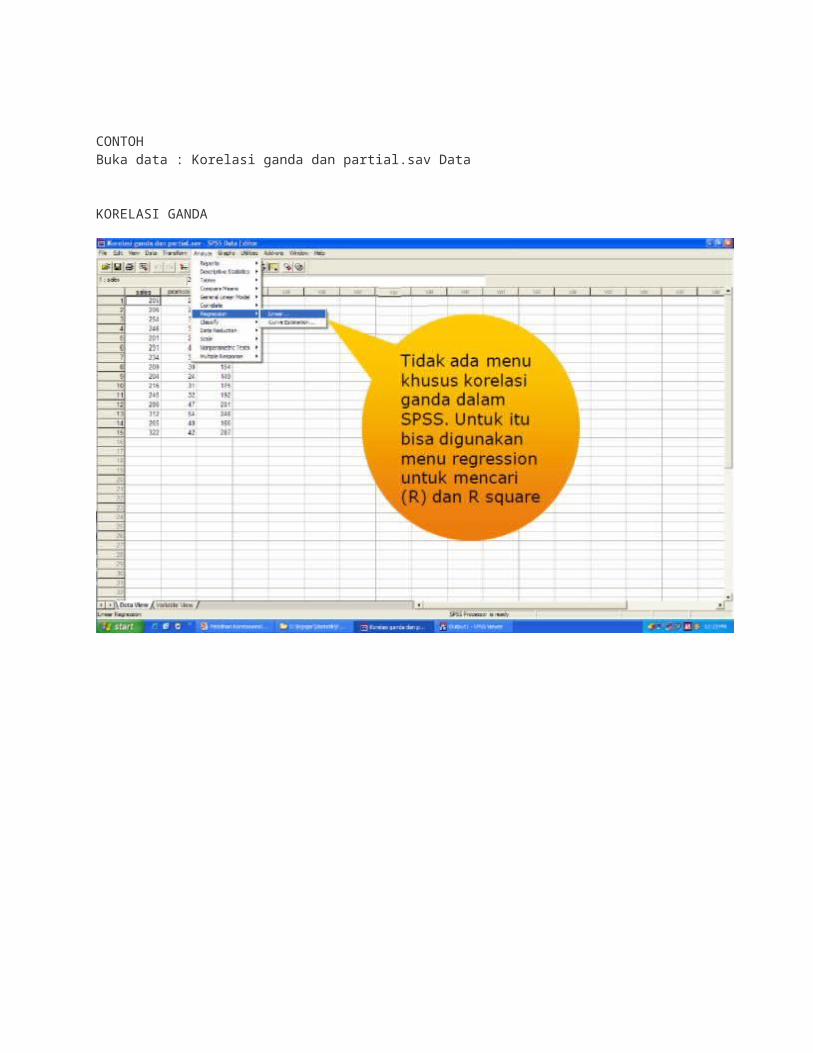
CONTOHBuka data : Korelasi ganda dan partial.sav Data
KORELASI GANDA

INTERPRETASI KORELASI GANDA
Untuk menginterpretasi korelasi ganda lihat nilai R, semakin mendekati 1 maka korelasi semakin kuat
Guna memperkaya analisis, sebelum dianalisis korelasi ganda dapat juga ditambahkan analisis korelasi pada masing-masing variabel independen dengan variabel dependen (caranya sama dengan analisis korelasi pearson.
REGRESI
Analisis regresi adalah analisis lanjutan dari korelasi
Menguji sejauh mana pengaruh variabel independen terhadap variabel dependen setelah diketahui ada hubungan antara variabel tersebut
Data harus interval/rasio
Data Berdistribusi normal.
Yang akan dibahas dalam pelatihan ini adalah: Regresi sederhana: yaitu regresi untuk 1 variabel independen dengan 1 variabel dependen
Regresi ganda: yaitu regresi untuk lebih dari satu variabel independen dengan 1 variabel dependen.
REGRESI SEDERHANABuka data : Pearson.sav Data
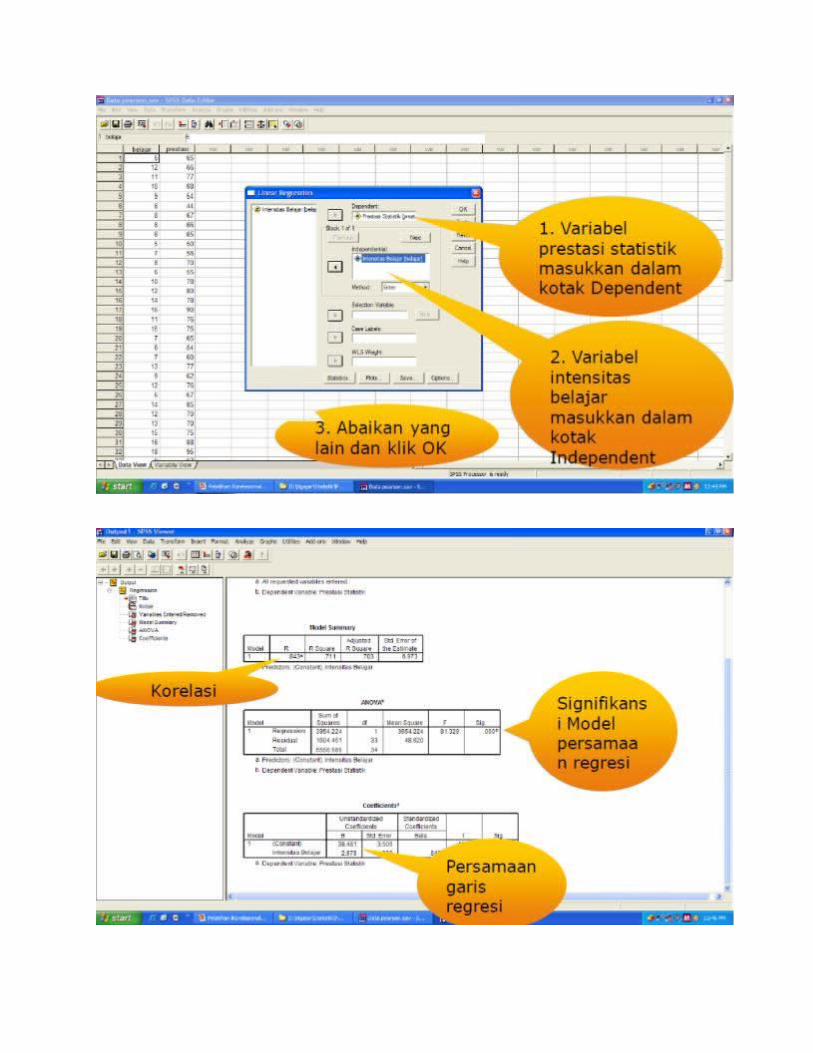

INTERPRETASI REGRESI SEDERHANAOutput 1
Lihat nilai R = 0,843 ini berarti bahwa korelasi antara variabel X dengan Y adalah 0,843
INTERPRETASI REGRESI SEDERHANAOTPUT 2
Untuk melihat signifikansi persamaan regresi dapat dilihat dari nilai F = 81,329 dan dibandingkan dengan F tabel
Apabila nilai F < F tabelmaka persamaan garis regresi tidak dapat digunakan untuk prediksi
Apabila nilai F > F tabelmaka persamaan garis regresi dapat digunakan untuk prediksi
Selain itu dapat pula dengan melihat nilai Sig. dapat digunakan untuk prediksi apabila nilai Sig. < 0,05
INTERPRETASI REGRESI SEDERHANAOUTPUT 3
Untuk membuat persamaan garis regresi dapat dilihat dari kolom B.
Constan = 38,481 dan intensitas belajar= 2,978
Berarti persamaan garisnya adalah: Y=38,481 + 2,978 X.
REGRESI GANDA
Digunakan untuk analisis regresi dengan jumlah variabel independen lebih dari satu dengan satu variabel dependen
Ada tambahan asumsi yang harus dipenuhi, yaitu tidak boleh ada korelasi antar variabel-variabel independennya (multikolinearitas)
CONTOHBuka data : Korelasi ganda dan partial.sav
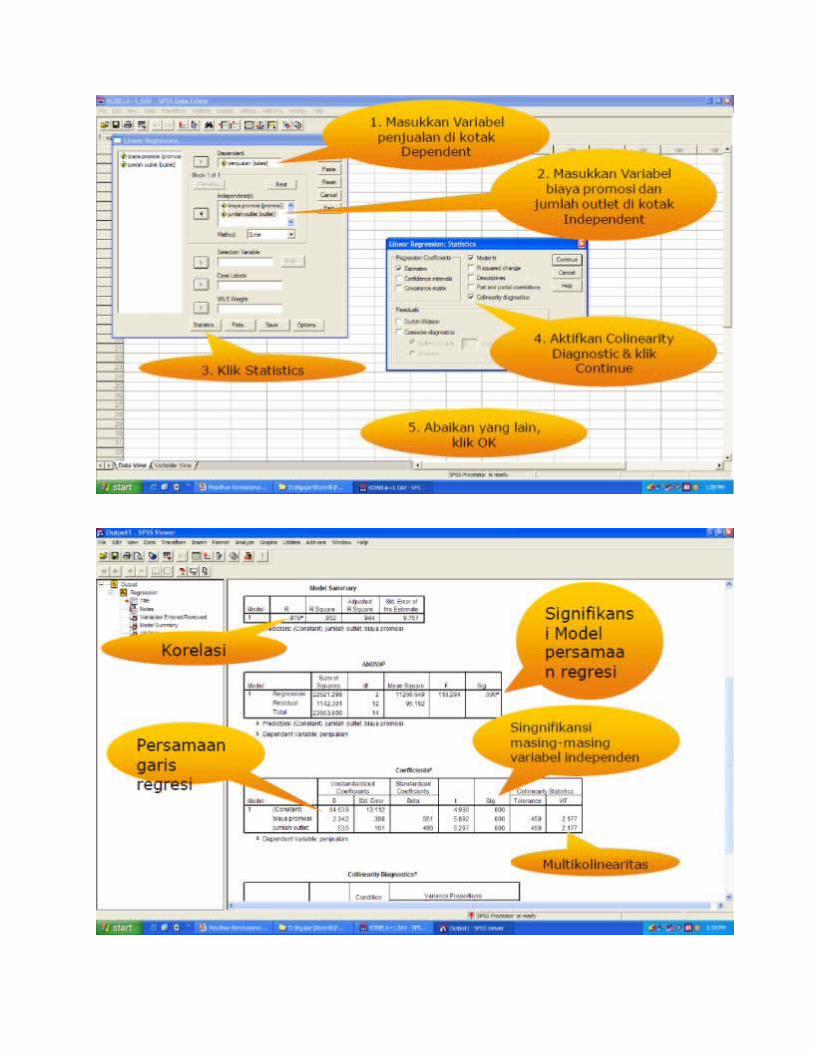

INTERPRETASI REGRESI GANDAOutput 1
Lihat nilai R = 0,976 ini berarti bahwa korelasi antara variabel X1dan X2secara bersamaan dengan Y adalah 0,976.
INTERPRETASI REGRESI GANDAOutput 2
Untuk melihat signifikansi persamaan regresi dapat dilihat dari nilai F = 118,294 dan dibandingkan dengan F tabel Apabila nilai F < F tabelmaka persamaan garis regresi tidak dapat digunakan untuk prediksi
Apabila nilai F > F tabelmaka persamaan garis regresi dapat digunakan untuk prediksi
Selain itu dapat pula dengan melihat nilai Sig. dapat digunakan untuk prediksi apabila nilai Sig. < 0,05
INTERPRETASI REGRESI GANDAOutput 3

Untuk membuat persamaan garis regresi dapat dilihat dari kolom B.
Constan = 64,639
Biaya promosi= 2,342
Jumlah Outlet= 0,535
Berarti persamaan garisnya adalah: Y=64,639 + 2,342 biaya promosi + 0,535 Jumlah Outlet
INTERPRETASI REGRESI GANDAOutput 4
Identifikasi kolinieritas dapat dilakukan dengan melihat:
Output 3, Kolom VIF. : terjadi kolinearitas apabila nilai VIF > 5
Output 4, Kolom eugenvalue: terjadi kolinearitas apabila nilai eugenvalue mendekati 0
Output 4, Kolom condition index: terjadi kolinearitas apabila nilai condition index > 15. Dikatakan parah apabila > 30
Analisis Regresi Dalam Excel Regresi Dalam Excel
Artikel ini merupakan kelanjutan dari artikel sebelumnya: Aktivasi Add-Ins Analysis ToolPak
Analisis Regresi di dalam MS Excel 2007 atau 2010 dapat dilakukan dengan mudah tanpa perlu menggunakan alat atau software tambahan seperti SPSS, Minitab, dll.
1. Misalnya kita ingin menduga persamaan regresi untuk melihat pengaruh harga dan pendapatan terhadap
permintaan suatu barang. Katakanlah kita punya 10 set data (tahun atau daerah). Permintaan kita hitung dalam
jumlah unit barang, harga dalam ribu rupiah perunit barang dan pendapatan dalam ribu rupiah perkapita. Sebagai
latihan ketikkan angka-angka berikut pada range A1:C11 seperti terlihat pada tampilan 1 berikut:
Tampilan 1. Data untuk Regresi

2. Klik menu Tool kemudian klik Data Analysis. (Catatan: jika setelah mengklik Tool, ternyata tidak muncul
pilihan Data Analysis, berarti menu tersebut belum diaktifkan di program Excel Anda. Untuk mengaktifkannya,
klik Tool, kemudian klik Add ins, selanjutnya conteng pada pilihan Analysis Toolpak, setelah itu klik ok. Lalu
ulangi tahap 2 ini).
Tampilan yang muncul setelah mengklik Data Analysis adalah seperti tampilan 2. Selanjutnya klik Regression
dan klik OK.
Tampilan 2. Data Analysis
3. Selanjutnya akan muncul tampilan 3 berikut:
Tampilan 3. Regression
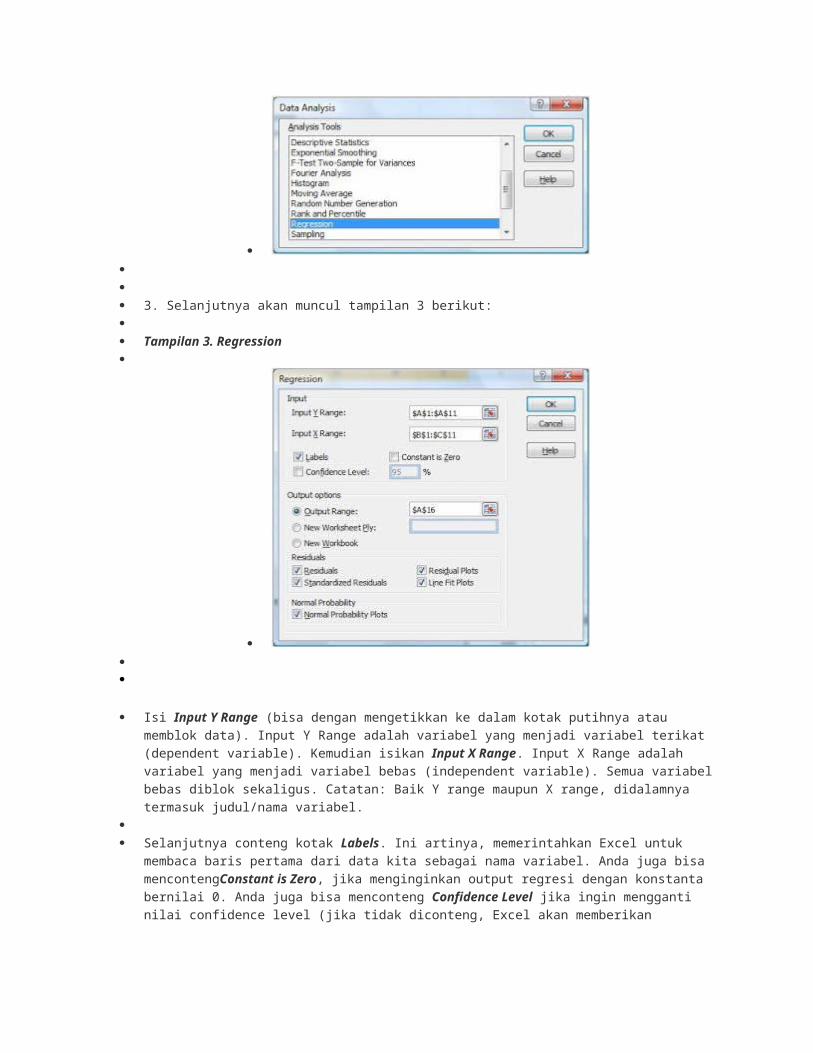
Isi Input Y Range (bisa dengan mengetikkan ke dalam kotak putihnya atau memblok data). Input Y Range
adalah variabel yang menjadi variabel terikat (dependent variable). Kemudian isikan Input X Range. Input X
Range adalah variabel yang menjadi variabel bebas (independent variable). Semua variabel bebas diblok
sekaligus. Catatan: Baik Y range maupun X range, didalamnya termasuk judul/nama variabel.
Selanjutnya conteng kotak Labels. Ini artinya, memerintahkan Excel untuk membaca baris pertama dari data kita
sebagai nama variabel. Anda juga bisa mencontengConstant is Zero, jika menginginkan output regresi dengan
konstanta bernilai 0. Anda juga bisa menconteng Confidence Level jika ingin mengganti nilai confidence level
(jika tidak diconteng, Excel akan memberikan confidence level 95%). Dalam latihan kita kedua pilihan tersebut
tidak kita conteng.
Selanjutnya pada Output Option kita bisa menentukan penempatan output/hasilnya. Bisa pada worksheet baru
atau workbook baru. Katakanlah kita menempatkan output di worksheet yang sama dengan data kita.
Conteng Output Range dan isi kotak putihnya dengan sel pertama dimana output tersebut akan ditempatkan.
Dalam contoh ini, misalnya ditempatkan pada sel A16.
Pada pilihan Residual, terdapat 4 pilihan. Anda bisa menconteng sesuai dengan keinginan. Dalam kasus ini kita
conteng semua pilihan tersebut. Selanjutnya, terdapat pilihan untuk menghasilkan Normal Probability. Dalam
kasus kita, juga kita conteng pilihan ini.
Setelah itu, klik OK. Maka akan muncul hasil regresi berikut:
SUMMARY OUTPUT
Regression StatisticsMultiple R 0.9714R Square 0.9436Adjusted R 0.9275

SquareStandard Error 81.0698Observations 10
ANOVA
df SS MS FSignificanc
e F
Regression 2769993.7
8384996.8
958.5
8 0.00Residual 7 46006.22 6572.32
Total 9816000.0
0
Coefficients
Standard Error t Stat
P-valu
e Lower 95%Upper
95%
Intercept 607.53 274.67 2.21 0.06 -41.971257.0
3Harga -13.31 4.59 -2.90 0.02 -24.17 -2.44Pendapatan 0.36 0.09 3.78 0.01 0.13 0.58
RESIDUAL OUTPUTPROBABILITY OUTPUT
Observation
Predicted Permintaan Residuals
Standard Residuals
Percentile
Permintaan
1498.236219
31.76378070
70.02466934
3 5 300
2262.979328
937.0206710
60.51779432
1 15 500
3738.248951
5
-38.2489514
7
-0.53497382
1 25 600
4743.004793
356.9952067
10.79717070
3 35 700
5747.760635
1
-147.760635
1
-2.06667290
3 45 800
6880.834331
919.1656680
60.26806305
2 55 900
7921.236518
978.7634811
3 1.10163544 65 1000
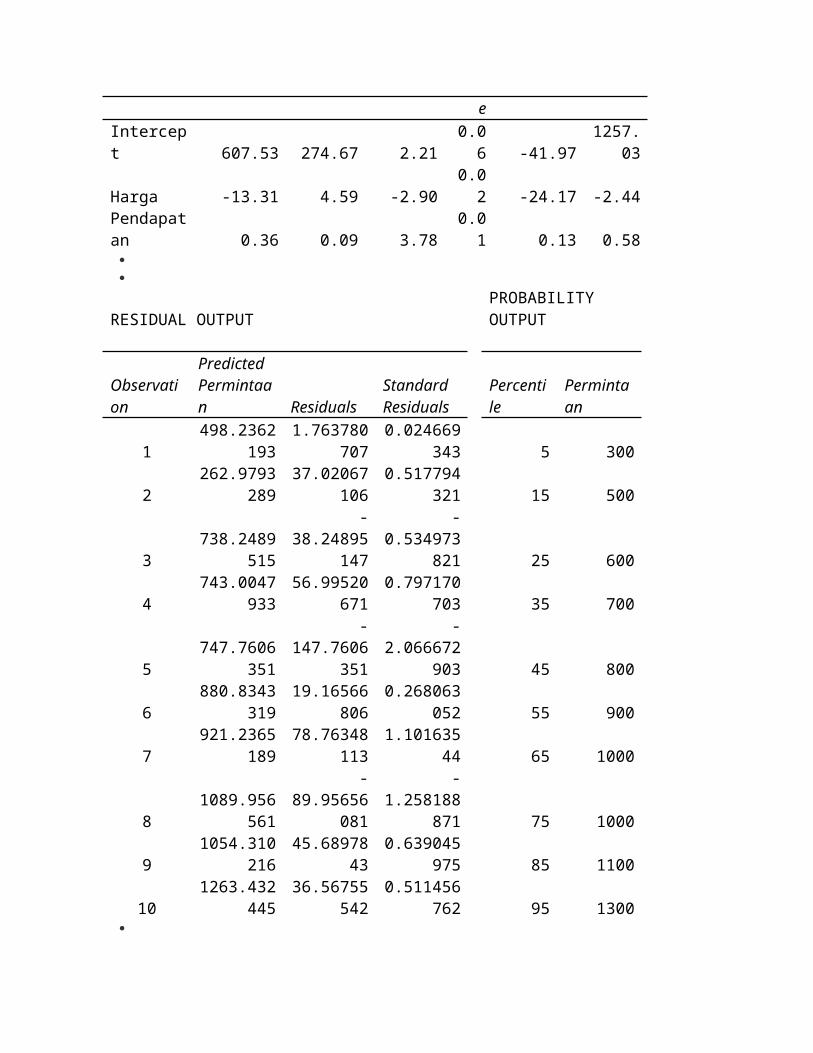
81089.95656
1
-89.9565608
1
-1.25818887
1 75 1000
91054.31021
6 45.68978430.63904597
5 85 1100
101263.43244
536.5675554
20.51145676
2 95 1300 Ada empat tabel hasil yang ditampilkan (yang tergantung pada pilihan yang kita buat sebelumnya), yaitu
SUMMARY OUTPUT, ANOVA, RESIDUAL OUTPUT, dan PROBABILITY OUTPUT. Pada SUMARY
OUTPUT ditampilkan nilai multiple R, R square, adjusted R square, standard error dan jumlah observasi. Pada
ANOVA ditampilkan analisis variance dan nilai F serta pengujiannya. Selanjutnya ditampilkan perhitungan
regresi kita yang mencakup intercept (konstanta) dan koefisien-koefisien regresi untuk masing-masing variabel.
Dari hasil ini kita bisa membentuk persamaan regresi menjadi:
Permintaan = 607,53 – 13,31Harga + 0,36 Pendapatan.
Selanjutnya, pada tabel tersebut juga dimunculkan standard error, t stat, P-value, confidence level untuk 95%
(karena kita tidak mengganti default nilai ini pada tahap sebelumnya).
Selain itu, karena tadi kita menconteng empat pilihan residual output dan 1 pilihan normal probability, maka juga
ditampilkan 5 kurva untuk pilihan-pilihan tersebut. Tetapi seperti yang kita lihat di bawah ini, kelima kurva tersebut bertumpuk . Untuk itu, kita perlu memindahkan (menarik) kurva-kurva tersebut ke bagian yang lain dari worksheet kita sehingga bisa dibaca.
Tampilan 5. Hasil Perhitungan 2
Sementara, kita cukupkan dulu artikel ini sampai di sini. Untuk membaca output dari hasil regresi di atas, akan
kita bahas pada artikel berikutnya: Interprestasi Output Regresi Dalam Excel.
Agar anda memahami artikel ini, pelajari juga tentang Uji F dan Uji T: "Uji F dan Uji T"

Contoh Uji Pearson dan Persamaan Regresi Dalam ExcelContoh Uji Pearson dan Persamaan Regresi dengan Scatter Diagram Dalam Excel
Artikel ini merupakan kelanjutan dari artikel sebelumnya yang berjudul "Uji Pearson dan Scatter Diagram dalam Excel".
Pada bahasan kali ini dijelaskan bagaimana melakukan uji pearson, R Square, Persamaan Regresi dan Membuat Scatter diagram dengan mudah melalui Software MS Excel 2007/2010.
Langsung saja lihat atau download file Excel di bawah ini:
Tahapan Langkah:
1. Buat 2 Array: Variabel 1 dan Variabel 2 dengan mengisi cell A4 sampai A23 untuk Array 1 dan cell B4sampai B23 untuk Array 2.
2. Tuliskan kode =PEARSON(A4:A23;B4:B23) pada cell E3
3. Tuliskan kode =RSQ(A4:A23;B4:B23) pada cell E4
4. Pada Menu, Klik Insert, Pilih Scatter, Pilih Scatter With Only Markers.
5. Muncul tampilan chart, klik pada chart
6. Klik Kanan, Klik Select Data
7. Arahkan pointer kursor pada kolom Chart Data Range
8. Blok Cell A4 sampai B23, Lalu Klik OK
9. Pada Chart, Klik Plot (Titik-Titik) yang baru muncul
10. Klik Kanan, Lalu Add Trendline, Pilih Linear, Centang Display Equation on Chart dan Display R-Squared Value on Chart, Lalu Close
11. Untuk Mempercantik Tampilan, Pada Menu Klik Design
12. Pilih Chart Layout
13. Ubah Axis Title pada sumbu X dan Y dengan nama Variabel 1 dan variabel 2
14. Pada Chart Style, pilih yang anda suka
15. Lihat hasilnya
Demikian Cara mudah melakukan Uji Pearson, R Squared dan Persamaan Regresi dengan Scatter Diagram pada Excel.
Agar anda memahami artikel ini, pelajari juga tentang Uji F dan Uji T: "Uji F dan Uji T"
Selamat Mencoba!
Transformasi Data Ordinal Dengan ExcelTransformasi Data Ordinal Dengan Excel
Menanggapi pertanyaan seorang sahabat dan pengunjung blog ini melalui telpon perihal transformasi data ordinal ke interval, maka saya mencoba contohnya dalam bentuk perhitungan manual menggunakan alat bantu software MS Excel 2007/2010.

Tulisan ini juga sebagai kelanjutan dari artikel yang berjudul Transformasi data ordinal ke interval.
Perlu diketahui, metode transformasi ini menggunakan Method of Succesiv Internal (MSI) (Hays, 1976).
Langsung saja anda lihat dalam format excel di bawah ini. Untuk lebih jelasnya anda download filenya melalui link ini di skydrive.com.
Metode MSI tersebut digunakan untuk melakukan transformasi data ordinal menjadi data interval. Pada umumnya jawaban responden yang diukur dengan menggunakan skala likert (Lykert scale) diadakan scoring yakni pemberian nilai numerikal 1, 2, 3, 4 dan 5, setiap skor yang diperoleh akan memiliki tingkat pengukuran ordinal.Untuk latihan mari kita misalkan ada 20 responden (data), dengan skore nilai antara 1 sampai 5. (catatan: minimal untuk setiap skore ada 1 nilai). Maka tahapan-tahapan yang kita lakukan sebagai berikut:1. Ketik data asli di kolom A mulai dari baris 17 (atau sel A17) sampai baris 36 (sel A36).
2. Ketik angka 1, 2, 3, 4, 5 secara berurut ke bawah mulai dari sel A4 sampai A8.
3. Tulis rumus =COUNTIF(A$17:A$36;A4) di sel B4. Selanjutnya kopi sampai ke sel B8.
4. Di sel B9 tulis rumus =SUM(B4:B8)
5. Di sel C4 tulis rumus =A4*B4. Copy sampai sel C8
6. Di sel D4 tulis rumus =B4/B$9. Copy sampai sel D8
7. Di sel E4 tulis rumus =D4+E3. Copy sampai sel E8
8. Di sel F4 tulis rumus =NORMSINV(E4). Copy sampai F7.
9. Di sel G4 tulis rumus =NORMDIST(F4,0,1,0). Copy sampai G7
10. Di sel H4 tulis rumus =(G3-G4)/(E4-E3). Copy sampai H8
11. Di sel I4 tulis rumus =H4+ABS(MIN(H$4:H$8))+1. Copy sampai I8.
12. Di sel B17 tulis rumus =IF(A17=1;I$4;IF(A17=2;I$5;IF(A17=3;I$6;IF(A17=4;I$7;I$8)))). Copy sampai B36.
13. Hasil transformasi data anda sudah terlihat di sel B17 sampai B36 tersebut.
Apabila anda menggunakan data responden lebih atau kurang dari 20 orang, rumus A36 di tahap 3 bisa diganti dengan alamat sel dari data terakhir.
Dalam contoh format excel di atas, dicoba melakukan perhitungan transformasi data pada 2 variabel, yaitu variabel 1 (pada sheet 1) dan 2 (pada sheet 2). Selanjutnya pada sheet 3 uji coba data hasil transformasi digunakan untuj uji parametrik person correlation product momen dan t paired.
Sumber: http://www.suhartoumm.blogspot.com/
Membuat R Tabel Dalam ExcelMembuat R Tabel Dalam Excel

Pembuatan Tabel Koefisien Korelasi Momen-produk Pearson (Pearson Product-moment Correlation Coefficient) dengan Microsoft Excel
Dalam pengujian validitas konstruk, koefisien korelasi momen-produk Pearson (ρ atau r) digunakan sebagai batas valid atau tidaknya sebuah item (butir). Jika skala (kuesioner) Anda terdiri dari 30 item (pertanyaan) dan semua item disusun mengikuti prinsip skala Likert (Likert Summated Ratings), maka sebuah item dianggap valid jika koefisien hubungan item tersebut dengan total keseluruhan item yang kemudian kita notasikan sebagai R haruslah lebih besar atau sama dengan R dalam Tabel r (R ≥ r). Pada taraf nyata 5% batas validitas butir Anda adalah 0.361.(Lihatlah tabel r di bawah ini).
Buku ajar Statistika kadang melampirkan tabel ini pada dua taraf nyata yang lazim 5% dan 1%, tetapi tidak setiap nilai runtuk setiap nilai N (yaitu banyak item) dicantumkan. Perhatikan Tabel 1 di bawah ini: (seperti inilah umumnya, Tabel Koefisien Korelasi Momen-produk Pearson dalam buku teks).
Pertanyaan yang kerap terlontar dalam kelas (atau konsultasi informal dengan para peneliti muda a.k.a mahasiswa-mahasiswa S1) adalah bagaimana bila banyak item dalam skala tidak tercantum dalam tabel. Misalnya jika N = 57, berapa nilai ryang dipakai? Sebagian besar kemudian menggunakan nilai r = 0.266 (yaitu nilai r untuk N = 55) atau r = 0.254 (untuk N = 60) pada taraf nyata uji = 5%. Bagaimana menetapkan nilai r yang tepat untuk N = 57? Berapa nilaiTerinspirasi kebiasaan menggunakan Excel untuk membuat distribusi peluang teoretis, penjelajahan di internet mencari fungsi pembangkit koefisien ini dimulai. Analogi saran dari seorang anggota/nara sumber forum SPSS Indonesia (http://spss.co.id/pipermail/forum-spss_spss.co.id) menjadi dasar pembuatan tabel yang sama dengan Excel. Pada SPSS, pembuatan tabel melibatkan menu transform, compute, dan fungsi IDF.T [probability.degree of freedom) yang pada Excel ditulis sebagai TINV(probability, degree of freedom). TINV menghasilkan nilai t untuk suatu derajat bebas pada suatu taraf nyata. Setelah nilai t didapat, r dihitung dengan menggunakan cari rumus berikut:
Rumus 1
Berikut adalah cara pembuatan tabel dengan Excel:1. Isi sel C2 = 0,05 (yaitu nilai taraf nyata 5%)
2. Sel A3, B3, dan C3 secara berurutan masing-masing diisi dengan label df, t 0.05, r0.05, t0.01 dan r0.01 (df adalah degree of freedom, t0.05 adalah nilai t pada taraf nyata 5%, r adalah nilai r pada taraf nyata 5%, dst)
3. Mulai dari sel A4 tuliskan nilai df, yaitu dari angka 1, 2, 3, . . . N (N adalah banyak item)
4. Pada sel B4 tuliskan formula ini =TINV(C$1;(A4-2))
5. A4-2 adalah df-2, degree of freedom dikurang 2. Pada uji coba pertama kali, A4 tidak dikurangi 2, hasilnya tidak sama dengan Tabel r dalam buku teks (Lihat Tabel r di atas), nilai r pada N = 1 (pada uji coba pertama) = r (tabel dalam buku teks) pada N = 3, karena itulah pada rumus di sel B4 kemudian A4 – 2.
6. Selanjutnya tuliskan formula ==(B4/(SQRT((A4-2)+B4^2))), dan r untuk setiap N didapat.
7. Atur banyak angka dibelakang koma, sesuai kebutuhan Anda (tiga atau empat angka di belakang koma)
8. Karena nilai r untuk df = 1 dan 2, tidak terdefinisi, abaikan nilai-nilai tersebut. Tabel dapat digunakan mulai dari df = 3.
9. Jika diperlukan nilai r pada suatu df, tuliskan df di kolom A, dan secara otomatis nilai r akan ditampilkan

10. Lakukan hal yang sama untuk nilai taraf nyata lain, misalnya taraf nyata 1%.
Berikut adalah cuplikan Tabel Koefisien Korelasi Momen-produk Pearson yang dibuat dengan Microsoft Excel.
One Way Anova dalam SPSSUji One Way Anova
Pada artikel kali ini, kita akan membahas tentang melakukan uji One Way Anova atau Anova Satu Jalur dengan menggunakan software SPSS For Windows.
Anova merupakan singkatan dari "analysis of varian" adalah salah satu uji komparatif yang digunakan untuk menguji perbedaan mean (rata-rata) data lebih dari dua kelompok. Misalnya kita ingin mengetahui apakah ada perbedaan rata-rata IQ antara siswa kelas SLTP kelas I, II, dan kelas III. Ada dua jenis Anova, yaitu analisis varian satu faktor (one way anova) dan analisis varian dua faktor (two ways anova). Pada artikel ini hanya akan dibahas analisis varian satu faktor.
Untuk melakukan uji Anova, harus dipenuhi beberapa asumsi, yaitu:1. Sampel berasal dari kelompok yang independen
2. Varian antar kelompok harus homogen
3. Data masing-masing kelompok berdistribusi normal (Pelajari juga tentang uji normalitas)
Asumsi yang pertama harus dipenuhi pada saat pengambilan sampel yang dilakukan secara random terhadap beberapa (> 2) kelompok yang independen, yang mana nilai pada satu kelompok tidak tergantung pada nilai di kelompok lain. Sedangkan pemenuhan terhadap asumsi kedua dan ketiga dapat dicek jika data telah dimasukkan ke komputer, jika asumsi ini tidak terpenuhi dapat dilakukan transformasi terhadap data. Apabila proses transformasi tidak juga dapat memenuhi asumsi ini maka uji Anova tidak valid untuk dilakukan, sehingga harus menggunakan uji non-parametrik misalnya Kruskal Wallis.
Prinsip Uji Anova adalah melakukan analisis variabilitas data menjadi dua sumber variasi yaitu variasi di dalam kelompok (within) dan variasi antar kelompok (between). Bila variasi within dan between sama (nilai perbandingan kedua varian mendekati angka satu), maka berarti tidak ada perbedaan efek dari intervensi yang dilakukan, dengan kata lain nilai mean yang dibandingkan tidak ada perbedaan. Sebaliknya bila variasi antar kelompok lebih besar dari variasi didalam kelompok, artinya intervensi tersebut memberikan efek yang berbeda, dengan kata lain nilai mean yang dibandingkan menunjukkan adanya perbedaan.
Setelah kita pahami sedikit tentang One Way Anova, maka mari kita lanjutkan dengan mempelajari bagaimana melakukan uji One Way Anova dengan SPSS.
Sebagai bahan uji coba, maka kita gunakan contoh sebuah penelitian yang berjudul "Perbedaan Pendapatan Berdasarkan Pekerjaan". Di mana pendapatan sebagai variabel terikat bertipe data kuantitatif atau numerik sedangkan pekerjaan sebagai variabel bebas berskala data kualitatif atau kategorik, yaitu dengan 3 kategori: Tani, Buruh dan Lainnya. (Ingat bahwa uji One Way Anova dilakukan apabila variabel terikat adalah interval dan variabel bebas adalah kategorik). (Pelajari juga tentang Pengertian Data)
Langsung Saja:
Tutorial One Way Anova Buka SPSS
Buka Tab Variable View, buat 2 variabel: Pekerjaan dan Pendapatan

Ubah Type Pekerjaan ke "Numeric", Decimals "0", beri label "Pekerjaan", ubah measure menjadi "Nominal" dan isi value dengan kategori: 1 = Tani, 2 = Buruh dan 3 = Lainnya
Ubah Type Pendapatan ke "Numeric", Decimals "0", beri label "Pendapatan", ubah measure menjadi "Scale".
Buka Data View dan isikan data sebanyak 24 responden sebagai berikut:

Pada menu, pilih Analyze, Compare Means, One-Way ANOVA, sampai muncul jendela One-Way ANOVA seperti di bawah ini:
Pilih variabel "Pendapatan" lalu masukkan ke kotak "Dependent List:" Kemudian pilih variabel "Pekerjaan" lalu masukkan ke kotak "Factor:" Sehingga nampak seperti di bawah ini:
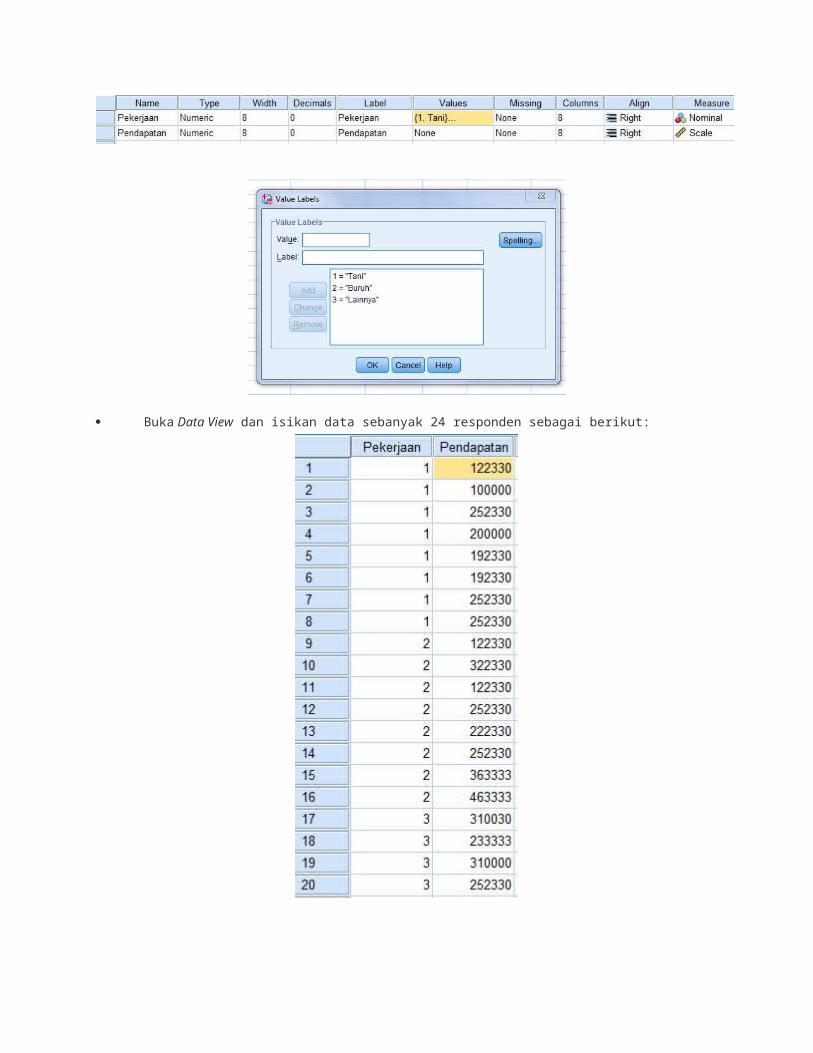
Klik tombol Options, akan muncul jendela ini: Centang "Descriptive" dan "Homogenity of variance test"
Klik Continue
Masih dijendela One Way ANOVA, klik tombol Post Hoc, sampai muncul jendela ini: CentangBonferroni dan Games-Howell serta biarkan significance level = 0,05.
Klik Continue
Lalu Klik OK dan Lihatlah hasil!
Hasil terilhat sebagai berikut:
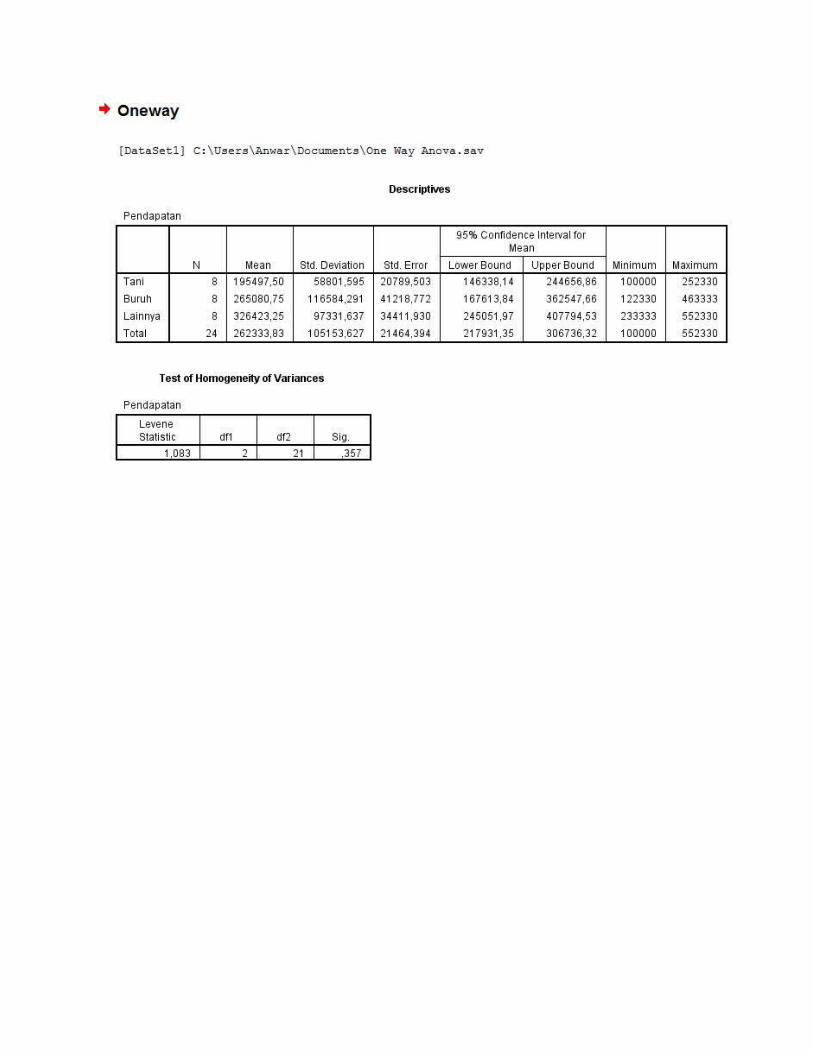
Interprestasi Baca adalah sebagai berikut: Dari tabel Descriptives nampak bahwa responden yang bekerja sebagai Tani rata-rata berpendapatan sebesar 195497,50, Buruh rata-rata berpendapatan sebesar 265080,75 dan Lainnya rata-rata berpendapatan 326423,25. Selanjutnya untuk melihat uji kita lihat di tabel ANOVA.
Sebelum melanjutkan uji perlu diingat bahwa salah satu asumsi uji Anova adalah variansnya sama. Dari tabel Test of Homegeneity of Variances terlihat bahwa hasil uji menunjukan bahwa varian ketiga kelompok tersebut sama (P-value = 0,357), sehingga uji Anova valid untuk menguji hubungan ini.
Selanjutnya untuk melihat apakah ada perbedaan pendapatan dari ketiga kelompok pekerja tersebut, kita lihat tabel ANOVA , dari tabel itu pada kolom Sig. diperoleh nilai P (P-value) = 0,037. Dengan demikian pada taraf nyata = 0,05 kita menolak Ho, sehingga kesimpulan yang didapatkan adalah ada perbedaan yang bermakna rata-rata pendapatan berdasarkan ketiga kelompok pekerjaan tersebut.
Jika hasil uji menunjukan Ho gagal ditolak (tidak ada perbedaan), maka uji lanjut (Post Hoc Test) tidak dilakukan. Sebaliknya jika hasil uji menunjukan Ho ditolak (ada perbedaan), maka uji lanjut (Post Hoc Test) harus dilakukan.
Karena hasil uji Anova menunjukan adanya perbedaan yang bermakna, maka uji selanjutnya adalah melihat kelompok mana saja yang berbeda.
Untuk menentukan uji lanjut mana yang digunakan, maka kembali kita lihat tabel Test of Homogeneity of Variances, bila hasil tes menunjukan varian sama, maka uji lanjut yang digunakan adalah ujiBonferroni.
Namun bilai hasil tes menunjukan varian tidak sama, maka uji lanjut yang digunakan adalah uji Games-Howell.
Dari Test of Homogeneity menghasilkan bahwa varian ketiga kelompok tersebut sama, maka uji lanjut (Post Hoc Test) yang digunakan adalah Uji Bonferroni.
Dari tabel Post Hoc Test di atas memperlihatkan bahwa kelompok yang menunjukan adanya perbedaan rata-rata pendapatan (ditandai dengan tanda bintang "*") adalah Kelompok "Tani" dan "Lainnya".
Pelajari juga cara melakukan uji One Way Anova dengan menggunakan software MS Excel dengan membaca artikel "One Way Anova dalam Excel"
Demikian Ulasang Singkat Tutorial Uji One Way Anova dalam SPSS. Kami anjurkan anda juga membaca artikel yang berkaitan erat dengan uji ini, yaitu Uji MANOVA.
DOWNLOADBagi Anda yang ingin mendownload file SPSS uji One Way Anova ini, silahkan download di link berikut: Data: One Way Anova.sav
Output: One Way Anova.spv
Baca Artikel Terkait: Analisis Regresi Dalam Excel
Uji Ancova Dalam SPSS
Interprestasi Hasil Uji Ancova dengan SPSS
Regresi Logistik Ganda dalam SPSS
Regresi Linear Sederhana dengan SPSS
Posted by Anwar Hidayat at 23.07