dari data ranking tidak lengkap...
TRANSCRIPT

BIAStatistika (2012) Vol. 6, No.2, hal. 9-18
ANALISIS OBJEK DAN ASSESSOR
DARI DATA RANKING TIDAK LENGKAP
MENGGUNAKAN DISTATIS
Irlandia Ginanjar1, 2,
*, Bambang Widjanarko O.1
email : [email protected],
1Jurusan Statistika ITS, Surabaya,
2Jurusan Statistika UNPAD, Bandung
ABSTRAK
Data ranking tidak lengkap karena, objek tidak lengkap atau data ranking
berbentuk selang. Makalah ini bertujuan untuk memperkenalkan cara
menganalisis objek dan assessor dari data ranking tidak lengkap dengan
menggunakan alat yang disebut DISTATIS. DISTATIS adalah generalisasi
Multidimensional Scaling (MDS) yang menggunakan Aljabar Linier untuk
menganalisis beberapa matriks jarak dari objek dengan set yang sama. Matriks
jarak untuk data ranking tidak lengkap didapatkan dengan langkah; (1)
mentransformasi data ranking tidak lengkap ke data penyortiran menggunakan
metoda K-mean Clustering, (2) mentransformasi data penyortiran ke matriks
jarak. Keluaran dari DISTATIS adalah peta assessor berdasarkan penilaian
keseluruhan objek dan peta yang menampilkan objek dan assessor untuk setiap
objek dalam satu peta. Berdasarkan dua peta yang dihasilkan, maka dapat
diidentifikasi informasi kesamaan antar objek, kesamaan assessor berdasarkan
penilaian keseluruhan objek, dan kesamaan penilaian assessor untuk setiap objek.
Aplikasi dalam makalah ini menggunakan data ranking dunia perguruan tinggi.
Kata Kunci : DISTATIS, Multidimensional Scaling, Aljabar Linier, K-mean
Clustering, Pemetaan.
1 Pendahuluan
Ranking adalah hubungan antara satu set objek yang berurutan, ranking
memungkinkan untuk mengevaluasi informasi yang kompleks sesuai dengan

BIAStatistika (2012) Vol. 6, No.2, hal. 9-18
kriteria tertentu (Wikipedia, 2011). Tapi bagaimana jika peneliti harus
menganalisis data ranking yang tidak lengkap. Data ranking tidak lengkap karena
objek tidak lengkap, dengan kata lain peneliti harus meneliti sebayak n objek dari
data ranking sebanyak N objek, dimana n lebih kecil dari N. Data ranking tidak
lengkap juga karena data ranking berbentuk selang.
Data ranking umumnya berupa variabel ganda (multivariat), dimana
variabel kategori baris berupa objek dan variabel kategori kolom berupa assessor,
dimana assessor adalah orang atau institusi yang meranking sifat-sifat objek.
Analisis data ranking multivariat umumnya menggunakan statistika non-
parametrik, dimana salah satunya adalah melalui metoda pemetaan. Berbagai
metoda statistika yang dapat digunakan untuk pemetaan adalah multidimensional
scaling (MDS) (Kruskal, 1978) tapi kekurangannya adalah informasi tentang
assessor hilang, karena data assessor dikumpulkan untuk mendapatkan matriks
kesamaan, akibatnya informasi perbedaan antar assessor tersembunyi (Lawless,
1995). Dalam Multiple Correspondence Analysis (MCA) (Grenecre, 1984) data
yang digunakan adalah data diskrit sehingga MCA tidak dapat digunakan untuk
data penyortiran. Tiga metoda lainnya adalah individual difference scaling
(INDSCAL) (Husson, 2006), Parallel factor analysis (PARAFAC) (Harshman,
1994) dan general procrustean analysis (GPA) (Gower, 2004), tetapi tiga metoda
ini menggunakan metode iteratif hal itu mengakibatkan diperlukannya sejumlah
besar iterasi. Pemetaan juga dapat menggunakan analisis Biplot (Gabriel, 1971),
tapi kekurangan analisis Biplot tidak dapat diaplikasikan untuk data ranking.
Metode yang disebut DISTATIS (Abdi, 2006) yang menggunakan Aljabar
Linier untuk menghitung eigenvalues dan eigenvector, dapat memetakan objek
dan assessor untuk setiap objek dengan menggunakan metoda non-iteratif dari
matriks jarak antar objek untuk setiap assessor, dimana data ranking berupa
variabel ganda dapat ditransformasi ke matriks jarak antar objek untuk setiap
assessor. Berdasarkan hal sebelumnya maka makalah ini bertujuan untuk
memperkenalkan cara menganalisis objek dan assessor dari data ranking tidak
lengkap dengan menggunakan alat yang disebut DISTATIS.
2 Metode

BIAStatistika (2012) Vol. 6, No.2, hal. 9-18
Berdasarkan tujuan makalah ini maka analisis data dilakukan mulai dari
transformasi data ranking tidak lengkap ke data penyortiran, transformasi data
penyortiran ke matriks jarak antar objek untuk setiap assessor, mendapatkan peta
persepsi, menghitung persentase keragaman yang diterangkan oleh peta dan
mengidentifikasi informasi dari peta yang dihasilkan. Langkah-langkah penelitian
yang dilakukan digambarkan dalam bentuk diagram alur analisis data yang
disajikan di Gambar 1.
Gambar 1 Diagram Alur Analisis Data.
3 Hasil dan Pembahasan
3.1 Transformasi data ranking tidak lengkap ke data penyortiran
Membuat matriks indikator
Transformasi ke matriks co-occurrence
Transformasi ke matriks jarak
Transformasi ke matriks cross-product
Normalisasi matriks cross-product
Menghitung matriks
kesamaan antar assessor
Menghitung eigenvectors dan
eigenvalues dari matriks
kesamaan antar assessor
Menghitung vektor bobot
optimal bagi assessor
Menghitung matriks compromise
Menghitung matriks eigenvectors dan
eigenvalues dari matriks compromise
Menghitung skor faktor
matriks compromise
a
Menghitung skor faktor bagi assessor ke-t
Memetakan objek dan assessor untuk
setiap objek
a
Peta objek dan assessor
untuk setiap objek
Mengidentifikasi informasi kesamaan
assessor berdasarkan penilaian keseluruhan
perguruan tinggi, kesamaan antar
perguruan tinggi, dan kesamaan antar
assessor untuk setiap perguruan tinggi
Mengidentifikasi persentase keragaman
yang diterangkan oleh peta
Transformasi data ranking tidak
lengkap ke data penyortiran
Menghitung skor faktor dari
matriks kesamaan antar assessor
Memetakan assessor berdasarkan
penilaian keseluruhan objek
Peta assessor berdasarkan
penilaian keseluruhan objek
Data

BIAStatistika (2012) Vol. 6, No.2, hal. 9-18
Data ranking tidak lengkap karena objek tidak lengkap mempunyai sifat bahwa,
jumlah objek yang ada diantara objek ke i dengan ke i+1 berbeda dengan jumlah objek
yang ada diantara data ke i+1 dengan ke i+2 untuk i = 1, 2, ..., n-2. Berdasarkan hal itu
maka transformasi data ranking ke data penyortiran dapat menggunakan metoda K-
mean Clustering dengan matriks jarak Euclidean (Johnson ,2007). Nomor cluster yang
didapatkan ditransformasi berdasarkan urutan ranking, sehingga didapatkan data
penyortiran yang merupakan kelompok objek yang berurut. Data ranking tidak lengkap
karena data ranking berbentuk selang, dapat langsung ditransformasi ke data
penyortiran.
3.2 Transformasi data penyortiran ke matriks jarak antar objek untuk setiap
assessor.
Matriks indikator dinotasikan dengan L[t] (t menyatakan assessor yang ke t),
setiap baris L[t] menyatakan objek dan setiap kolomnya menyatakan kelompok. Nilai
1 pada matriks indikator menyatakan bahwa objek yang direpresentasikan oleh baris
dikelompokan dalam kelompok yang direpresentasikan oleh kolom, selain itu
mempunyai nilai 0. L[t] ditransformasi ke matriks co-occurrence antar objek
(dinotasikan dengan R[t]), dengan cara:
][][][ ttt L'LR . (1)
R[t] ditransformasi ke matriks jarak (dinotasikan dengan D[t]), dengan cara:
][][ tt R1D , (2)
sehingga didapatkan D[t] yang merupakan set individu data jarak.
3.3 Pemetaan DISTATIS.
Langkah pertama metoda DISTATIS adalah mentransformasi D[t]
(persamaan (2)) ke matriks cross-product (dinotasikan dengan ][
~tS ). Transformasi
dari (kuadrat) jarak ke cross-product, dihitung dengan cara:
Ξ'ΞDS ][21
][
~tt ; dimana
NNNNNN
1
m'1IΞ ; dimana mi = N1 (3)
Normalisasi Matriks cross-product dilambangkan dengan ][tS , didapatkan dengan
cara:
][
1
1][
~tt SS ; 1 adalah eigenvalue pertama dari ][
~tS . (4)

BIAStatistika (2012) Vol. 6, No.2, hal. 9-18
Koefisien RV antara dua individu ][tS dan *][tS (Assessor urutan ke t dan
t*) dihitung dengan cara:
*][*][][][
*][][
*,
tttt
tt
ttV
tracetrace
tracecR
SS'SS'
SS'
. (5)
Koefisien RV merupakan elemen matriks kesamaan antar assessor (dilambangkan
dengan C). Eigendecomposition C menghasilkan corresponding eigenvectors dan
eigenvalues ( ), diperoleh dengan cara:
P'ΘPC . dengan IPP' (6)
dimana Θ adalah matriks diagonal yang merupakan eigenvalues dan P adalah
matriks corresponding eigenvectors (eigenvectors yang dinormalisasi) (Johnson,
2007) dari matriks C, dihitung dengan cara:
iiii e'eep ; ie adalah eigenvector yang ke i dari C. (7)
Persentase keragaman (inertia) yang digunakan sebagai ukuran kualitas pemetaan
dihitung dengan cara:
λλ1'τ1
, (8)
Skor faktor dari C (dilambangkan dengan G), diperoleh dengan cara:
21PΘG . (9)
dimana 21Θ adalah matriks diagonal akar eigenvalues. Dua kolom pertama matriks
skor faktor dari C (mempunyai persentase keragaman maksimal untuk pemetaan
dua dimensi), menjadi titik koordinat untuk pemetaan assessor berdasarkan penilaian
keseluruhan objek.
Matriks compromise adalah rata-rata terbobot dari setiap individu matriks
cross-product ( ][tS ) yang didapatkan dari persamaan (4). Bobot optimal diperoleh
dengan membagi setiap elemen p1 (yang dihasilkan dari persamaan (6)) dengan
jumlah elemen p1. Vektor yang mengandung bobot ini lambangkan dengan dan
dihitung dengan cara:
1
1
1 pp1'α
, (10)
dengan t yang menunjukkan bobot bagi assessor yang ke-t, maka matriks
compromise (dilambangkan dengan S[+]), dihitung dengan cara:

BIAStatistika (2012) Vol. 6, No.2, hal. 9-18
T
t
tt ][][ SS . (11)
Eigendecomposition dari S[+] adalah:
V'ΛVS ][ , (12)
dimana V adalah matriks corresponding eigenvectors (Persamaan (7)) dan
adalah matriks diagonal yang merupakan eigenvalues. Persentase keragaman
dihitung dengan menggunakan persamaan (8). Skor faktor dari S[+] dihitung
dengan cara:
21ΛVF , (13)
dimana 21Λ adalah matriks diagonal akar eigenvalues. Dua kolom pertama
matriks skor faktor dari S[+] menjadi titik koordinat untuk pemetaan objek.
Mekanisme proyeksi dapat disimpulkan dari persamaan (12) dan (13), dan
dari V’V = I (karena kolom V dinormalisasi), didapatkan bahwa:
21212121
][ ΛVΛΛVΛVV'ΛVΛVSF
, (14)
maka, matriks 21ΛV memproyeksikan matriks cross-product ke pemetaan
compromise (dengan kata lain, matriks 21ΛV adalah operator proyeksi). Selain
itu juga matriks ini dapat digunakan untuk memproyeksikan matriks cross-
product assessor ke pemetaan. Secara khusus, skor faktor bagi assessor ke-t
dihitung dengan cara:
21
][][
ΛVSF tt . (15)
Dua kolom pertama untuk setiap ][tF menjadi titik koordinat untuk pemetaan
assessor untuk setiap objek
3.4 Aplikasi menggunakan data ranking dunia perguruan tinggi.
Aplikasi makalah ini menggunakan data ranking tidak lengkap hasil
perankingan tiga assessor (Webometrics, 4ICU dan QS) terhadap delapan perguruan
tinggi negeri di Indonesia (IPB, ITB, ITS, Unair, Undip, UGM, UI, dan Unpad),
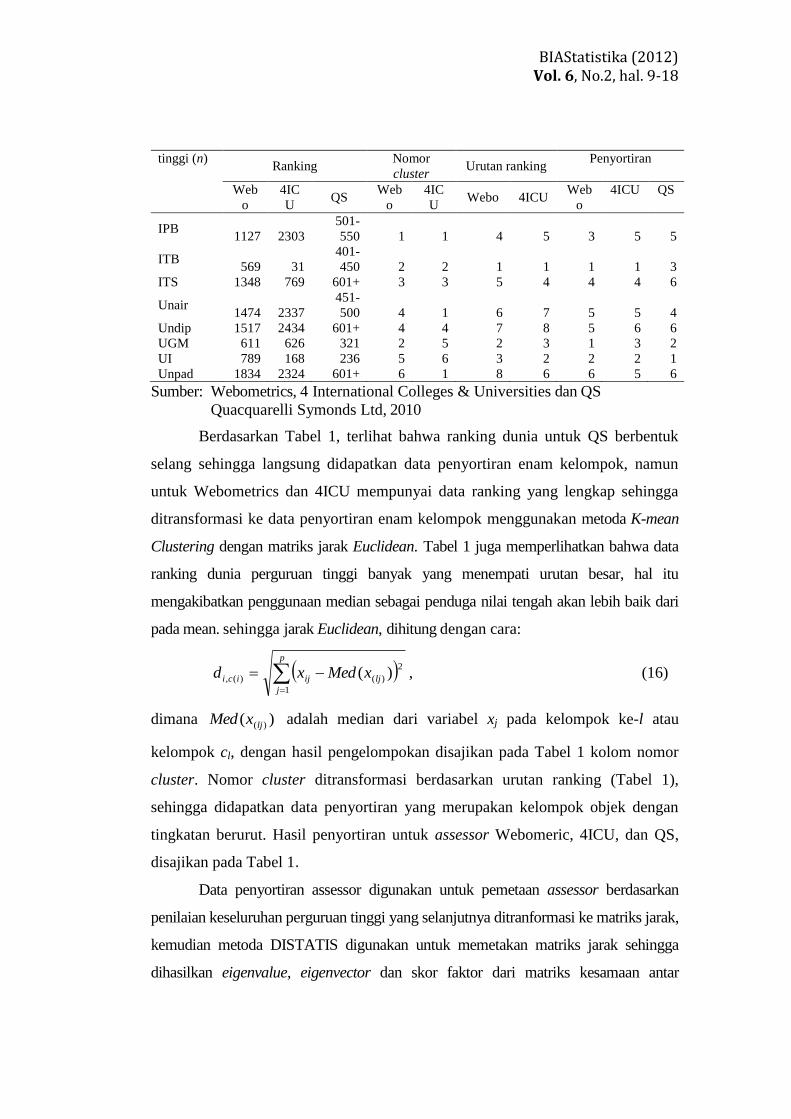
ditampilkan di Tabel 1 kolom ranking.
Tabel 1 Data Ranking Dunia Delapan Perguruan Tinggi oleh Tiga Assessor Perguruan Assessor (t)
BIAStatistika (2012) Vol. 6, No.2, hal. 9-18
tinggi (n) Ranking
Nomor
cluster Urutan ranking
Penyortiran
Web
o
4IC
U QS
Web
o
4IC
U Webo 4ICU
Web
o
4ICU QS
IPB 1127 2303
501-
550 1 1 4 5 3 5 5
ITB 569 31
401-
450 2 2 1 1 1 1 3
ITS 1348 769 601+ 3 3 5 4 4 4 6
Unair 1474 2337
451-
500 4 1 6 7 5 5 4
Undip 1517 2434 601+ 4 4 7 8 5 6 6
UGM 611 626 321 2 5 2 3 1 3 2
UI 789 168 236 5 6 3 2 2 2 1
Unpad 1834 2324 601+ 6 1 8 6 6 5 6
Sumber: Webometrics, 4 International Colleges & Universities dan QS
Quacquarelli Symonds Ltd, 2010
Berdasarkan Tabel 1, terlihat bahwa ranking dunia untuk QS berbentuk
selang sehingga langsung didapatkan data penyortiran enam kelompok, namun
untuk Webometrics dan 4ICU mempunyai data ranking yang lengkap sehingga
ditransformasi ke data penyortiran enam kelompok menggunakan metoda K-mean
Clustering dengan matriks jarak Euclidean. Tabel 1 juga memperlihatkan bahwa data
ranking dunia perguruan tinggi banyak yang menempati urutan besar, hal itu
mengakibatkan penggunaan median sebagai penduga nilai tengah akan lebih baik dari
pada mean. sehingga jarak Euclidean, dihitung dengan cara:
p
j
ljijici xMedxd1
2
)()(, )( , (16)
dimana )( )(ljxMed adalah median dari variabel xj pada kelompok ke-l atau
kelompok cl, dengan hasil pengelompokan disajikan pada Tabel 1 kolom nomor
cluster. Nomor cluster ditransformasi berdasarkan urutan ranking (Tabel 1),
sehingga didapatkan data penyortiran yang merupakan kelompok objek dengan
tingkatan berurut. Hasil penyortiran untuk assessor Webomeric, 4ICU, dan QS,
disajikan pada Tabel 1.
Data penyortiran assessor digunakan untuk pemetaan assessor berdasarkan
penilaian keseluruhan perguruan tinggi yang selanjutnya ditranformasi ke matriks jarak,
kemudian metoda DISTATIS digunakan untuk memetakan matriks jarak sehingga
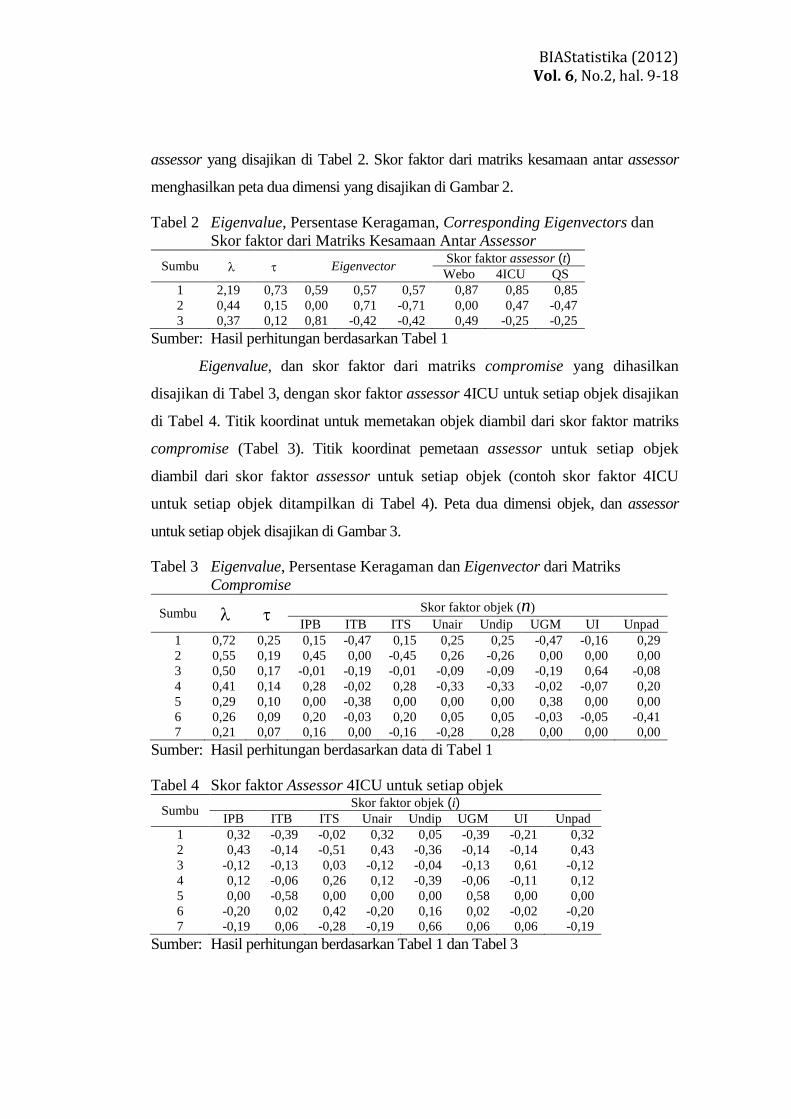
dihasilkan eigenvalue, eigenvector dan skor faktor dari matriks kesamaan antar
BIAStatistika (2012) Vol. 6, No.2, hal. 9-18
assessor yang disajikan di Tabel 2. Skor faktor dari matriks kesamaan antar assessor
menghasilkan peta dua dimensi yang disajikan di Gambar 2.
Tabel 2 Eigenvalue, Persentase Keragaman, Corresponding Eigenvectors dan
Skor faktor dari Matriks Kesamaan Antar Assessor
Sumbu Eigenvector Skor faktor assessor (t)
Webo 4ICU QS
1 2,19 0,73 0,59 0,57 0,57 0,87 0,85 0,85
2 0,44 0,15 0,00 0,71 -0,71 0,00 0,47 -0,47
3 0,37 0,12 0,81 -0,42 -0,42 0,49 -0,25 -0,25
Sumber: Hasil perhitungan berdasarkan Tabel 1
Eigenvalue, dan skor faktor dari matriks compromise yang dihasilkan
disajikan di Tabel 3, dengan skor faktor assessor 4ICU untuk setiap objek disajikan
di Tabel 4. Titik koordinat untuk memetakan objek diambil dari skor faktor matriks
compromise (Tabel 3). Titik koordinat pemetaan assessor untuk setiap objek
diambil dari skor faktor assessor untuk setiap objek (contoh skor faktor 4ICU
untuk setiap objek ditampilkan di Tabel 4). Peta dua dimensi objek, dan assessor
untuk setiap objek disajikan di Gambar 3.
Tabel 3 Eigenvalue, Persentase Keragaman dan Eigenvector dari Matriks
Compromise
Sumbu Skor faktor objek (n)
IPB ITB ITS Unair Undip UGM UI Unpad
1 0,72 0,25 0,15 -0,47 0,15 0,25 0,25 -0,47 -0,16 0,29
2 0,55 0,19 0,45 0,00 -0,45 0,26 -0,26 0,00 0,00 0,00
3 0,50 0,17 -0,01 -0,19 -0,01 -0,09 -0,09 -0,19 0,64 -0,08
4 0,41 0,14 0,28 -0,02 0,28 -0,33 -0,33 -0,02 -0,07 0,20
5 0,29 0,10 0,00 -0,38 0,00 0,00 0,00 0,38 0,00 0,00
6 0,26 0,09 0,20 -0,03 0,20 0,05 0,05 -0,03 -0,05 -0,41
7 0,21 0,07 0,16 0,00 -0,16 -0,28 0,28 0,00 0,00 0,00
Sumber: Hasil perhitungan berdasarkan data di Tabel 1
Tabel 4 Skor faktor Assessor 4ICU untuk setiap objek
Sumbu Skor faktor objek (i)
IPB ITB ITS Unair Undip UGM UI Unpad
1 0,32 -0,39 -0,02 0,32 0,05 -0,39 -0,21 0,32
2 0,43 -0,14 -0,51 0,43 -0,36 -0,14 -0,14 0,43
3 -0,12 -0,13 0,03 -0,12 -0,04 -0,13 0,61 -0,12
4 0,12 -0,06 0,26 0,12 -0,39 -0,06 -0,11 0,12
5 0,00 -0,58 0,00 0,00 0,00 0,58 0,00 0,00
6 -0,20 0,02 0,42 -0,20 0,16 0,02 -0,02 -0,20
7 -0,19 0,06 -0,28 -0,19 0,66 0,06 0,06 -0,19
Sumber: Hasil perhitungan berdasarkan Tabel 1 dan Tabel 3
BIAStatistika (2012) Vol. 6, No.2, hal. 9-18
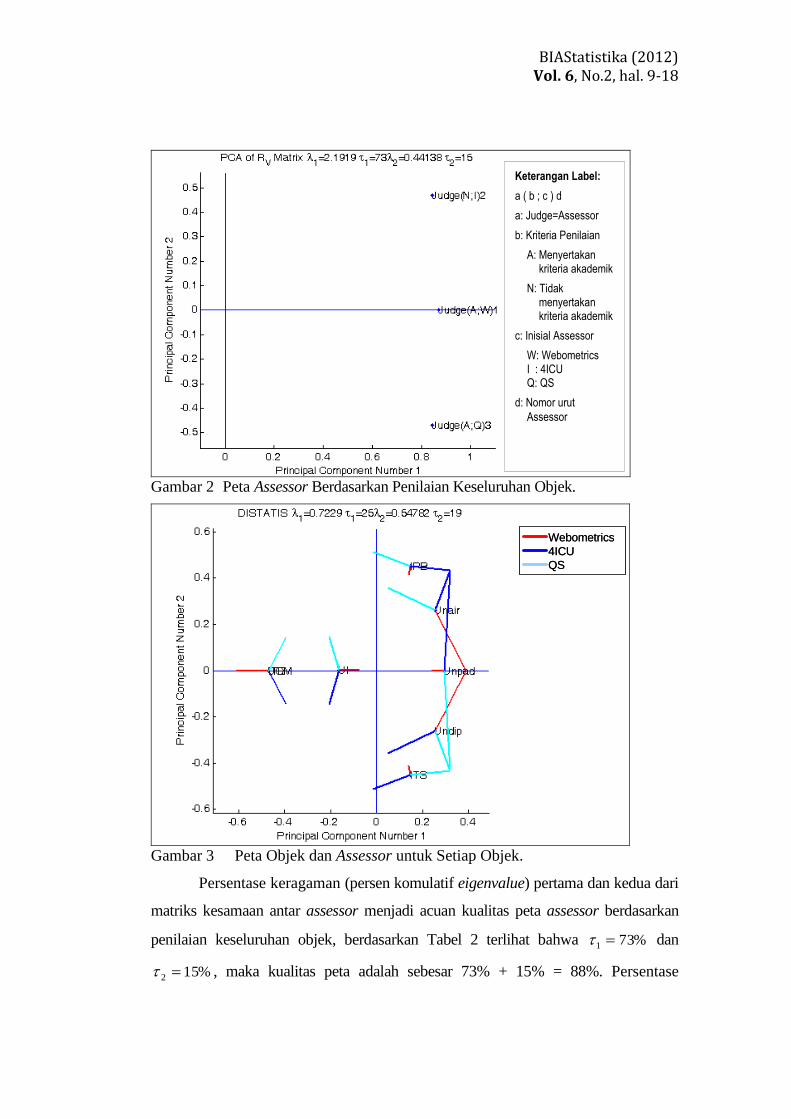
Gambar 2 Peta Assessor Berdasarkan Penilaian Keseluruhan Objek.
Gambar 3 Peta Objek dan Assessor untuk Setiap Objek.
Persentase keragaman (persen komulatif eigenvalue) pertama dan kedua dari
matriks kesamaan antar assessor menjadi acuan kualitas peta assessor berdasarkan
penilaian keseluruhan objek, berdasarkan Tabel 2 terlihat bahwa %731 dan
%152 , maka kualitas peta adalah sebesar 73% + 15% = 88%. Persentase
Keterangan Label:
a ( b ; c ) d
a: Judge=Assessor
b: Kriteria Penilaian
A: Menyertakan kriteria akademik
N: Tidak menyertakan kriteria akademik
c: Inisial Assessor
W: Webometrics I : 4ICU Q: QS
d: Nomor urut
Assessor
Webometrics
4ICU
QS
Webometrics
4ICU
QS

BIAStatistika (2012) Vol. 6, No.2, hal. 9-18
keragaman pertama dan kedua dari matriks compromise menjadi acuan kualitas peta
objek dan assessor untuk setiap objek, berdasarkan Tabel 3 terlihat bahwa
%251 dan %192 , maka kualitas peta sebesar 25% + 19% = 44%.
Gambar 2 memberikan informasi bahwa, ketiga assessor memberikan
penilaian yang berbeda terhadap delapan perguruan tinggi. dari sisi kriteria penilaian
terlihat mempengaruhi penyortingan dimana Webometrics dengan QS yang
menyertakan kriteria akademik berada dibawah sedangkan 4ICU yang tidak
menyertakan kriteria akademik berada di atas.
Gambar 3 memberikan informasi bahwa, ketiga assessor memiliki penilaian
yang relatif sepakat untuk ITB dan UGM, enam perguruan tinggi lainnya
mengindikasikan bahwa ketiga assessor memiliki penilaian yang relatif tidak sepakat.
Perguruan tinggi dapat dikelompokan menjadi dua, dimana ITB, UGM dan UI adalah
perguruan tinggi yang mempunyai penilaian baik, sedangkan lima perguruan tinggi
lainnya mempunyai penilaian jelek. Webometrics menilai UGM dengan ITB adalah
sama, Undip sama dengan Unair. 4ICU menilai UGM dengan ITB adalah sama, Unpad
sama dengan Unair dan IPB. QS menilai UGM sama dengan ITB, ITS sama dengan
Undip dan Unpad.
4 Kesimpulan dan Saran
4.1 Kesimpulan
DISTATIS dapat digunakan jika data ranking tidak lengkap ditransformasi ke
matriks jarak antar objek untuk setiap assessor. Peta assessor berdasarkan penilaian
keseluruhan objek memberikan informasi bahwa, semakin dekat jarak antar titik maka
assessor semakin sepakat dalam menilai objek, semakin jauh jarak antar titik maka
assessor semakin tidak sepakat dalam menilai objek. Peta objek dan assessor untuk
setiap objek memberikan informasi bahwa, semakin dekat jarak antar titik maka
semakin mirip, semakin jauh jarak antar titik maka semakin beda, semakin dekat titik
suatu assessor antar objek maka assessor menilai objek semakin mirip, semakin jauh
titik suatu assessor antar objek maka assessor menilai objek semakin berbeda. Kualitas
pemetaan assessor berdasarkan penilaian keseluruhan objek didapatkan berdasarkan
persentase keragaman dari matriks kesamaan antar assessor. Kualitas pemetaan yang

BIAStatistika (2012) Vol. 6, No.2, hal. 9-18
memuat objek, dan assessor untuk setiap objek didapatkan berdasarkan persentase
keragaman dari matriks compromise.
4.2 Saran
1. Jika data berasal dari sampel dan hasil yang diinginkan dapat
mempresentasikan populasi maka harus menggunakan teknik Probability
sampling.
2. Mengembangkan Versi DISTATIS dari jenis data lainnya, karena selama
data tersebut dapat ditransformasi ke matriks jarak maka DISTATIS dapat
digunakan.
3. Matriks jarak Euclidean sangat sensitif bila ada outlier, maka diperlukan
pengembangan versi robust dari DISTATIS dengan menggunakan
algoritma robust eigendecomposition.
5 Persantunan
Terima kasih kami ucapkan untuk Dr. Sutikno, M.Si. dan Dr. Irhamah,
M.Si. yang telah memberikan pengarahan, koreksi dan solusi untuk
kesempurnaan makalah ini.
6 Daftar Pustaka
Abdi, H., Valentin, D., Chollet, S., dan Chrea, C. (2006), “Analyzing Assessors
and Products in Sorting Tasks: DISTATIS, Theory and Applications”,
Food Quality and Preference, Vol. 18, hal. 627–640.
Gabriel, K.R. (1971), “The biplot graphic display of matrices with application to
principal component analysis”, Biometrika, Vol. 58, No. 3, hal. 453–467.
Gower, J.C., dan Dijksterhuis, G.B. (2004), Procrustes problems, Oxford
University Press, Inc., New York.
Grenacre, M.J., (1984), Theory and Applications of Correspondence Analysis,
Academic Press, Inc., London.
Johnson, R.A. dan Wichern, D.W. (2007), Applied Multivariate Statistical
Analysis, 6th
edition, Pearson Education, Inc., New Jersey.
Kruskal, J., dan Wish, M. (1978), Multidimensional Scaling, Sage University
Papers Series. Quantitative Applications in the Social Sciences ; No. 07-
011, Sage Publications, Inc., Iowa.

BIAStatistika (2012) Vol. 6, No.2, hal. 9-18
Lawless, H.T., Sheng T., dan Knoops, S. (1995), “Multidimensional scaling of
sorting data applied to cheese perception”, Food Quality and Preference,
Vol. 6, hal. 91–98.
Husson, F., & Pagès, J. (2006), “INDSCAL model: geometrical interpretation and
methodology”, Computational Statistics and Data Analysis, Vol. 50, hal.
358–378.
Harshman, R.A., dan Lundy, M.E., (1994), “PARAFAC: Parallel factor analysis”,
Computational Statistics and Data Analysis, Vol. 18, hal. 39–72.
QS Quacquarelli Symonds Ltd. (2010), University Rankings,
http://www.topuniversities.com/university-rankings/asian-university-
rankings/overall, diunduh pada tanggal 30 Desember 2010.
Webometrics. (2010), Ranking Web: Universities, http://www.webometrics.info/
rank_by_country.asp?country=id, diunduh pada tanggal 30 Desember 2010.
Wikipedia. (2011), Ranking, http://en.wikipedia.org/wiki/Ranking, diunduh pada
tanggal 14 Maret 2011.
4 International Colleges & Universities. (2010), University Web Rankings,
http://www.4icu.org/id/, diunduh pada tanggal 30 Desember 2010.