chapter 19
DESCRIPTION
chapter 19TRANSCRIPT

Chapter 19
PENCEGAHAN KEGAGALAN DAN PEMULIHAN
PENGANTAR
Salah satu cara yang jelas untuk meningkatkan kinerja operasi adalah dengan mencegah
kegagalan. Kegagalan terkadang tidak penting, tetapi dalam beberapa operasi sangat penting
bahwa proses tersebut tidak gagal. Kegagalan di pesawat dalam penerbangan, sebagai contoh
misalnya, atau pasokan listrik untuk rumah sakit, atau sabuk pengaman mobil, atau keadaan
darurat layanan dapat harfiah fatal. Untuk operasi ini ketergantungan tidak hanya diinginkan,
adalah penting. Bahkan di kurang kritis situasi, memiliki proses diandalkan dapat memberikan
keunggulan kompetitif. Tapi tidak ada proses sempurna dan kegagalan akan terjadi. Jadi,
penting bahwa kita belajar dari semua kegagalan dan memiliki rencana di tempat yang
membantu mereka pulih dan meminimalkan efek mereka. gambar 19,1 menunjukkan
bagaimana bab ini cocok dengan operasi ini perbaikan kegiatan.
gambar 19.1 Mencakup Pencegahan Kegagalan dan Pemulihan

Pertanyaan Kunci
Mengapa operasi gagal?
Bagaimana mengukur kegagalan?
Bagaimana kegagalan dan potensi kegagalan dapat diketahui dan dianalisis?
Bagaimana cara meningkatkan keandalan operasi?
Bagaimana cara pemulihan ketika terjadi kegagalan operasi?
Operasi (Tidak) Dalam Praktek
Barings Banks dan Nick Leeson
Pada 3 Maret 1995 Nick Leeson, yang 'nakal berbasis di Singapura trader ', ditangkap
segera setelah penerbangannya dari Far East mendarat di Frankfurt. Sejak 27 Februari,
komunitas keuangan dunia telah shock setelah Barings Bank runtuh menyusul penemuan besar
hutang. Selama periode sembilan bulan Leeson dihabiskan di Penjara Jerman sebelum akhirnya
kembali ke Singapura untuk diadili, auditor, regulator dan legislator belajar bahwa meskipun
sebagian besar menyalahkan kecelakaan itu bisa ditempatkan pada Leeson, yang penawaran
semakin berisiko dan penipuan Barings akhirnya biaya $ 1,3 milyar itu juga bank sistem tidak
memadai untuk memantau operasi perdagangan yang sama-sama harus disalahkan.
Pada bulan Maret 1993 Barings Securities dan Baring Saudara digabung operasi mereka
untuk membentuk Baring Bank Investasi (BIB). Meskipun ini memiliki logika keuangan, tindakan
ini efektif menciptakan struktur operasi yang akan memungkinkan Nick Leeson untuk pergi
dengan dealing terlarang sampai Bank bangkrut. Ini memungkinkan Barings untuk membuat
pinjaman besar untuk bagian-bagian penyusunnya tanpa mengacu pada Bank Inggris, yang
prinsip utama adalah bahwa tidak ada bank harus pernah mempertaruhkan uang lebih dari itu
bisa mampu untuk kehilangan. Besar eksposur (lebih dari 10 persen dari modal bank) harus
secara resmi dilaporkan akan, namun pada akhir tahun 1993 Paparan Baring adalah hampir 45
persen dari modal. Di Juli 1992, Leeson membuka rekening perdagangan 88.888 sebagai sebuah
'akun error' biasanya digunakan untuk rekor penjualan pending investigasi dan pembersihan
mereka. Volume tersebut perdagangan biasanya kecil dan mereka dengan cepat dibersihkan
dari Akun. Namun, Leeson dari awal digunakan rekening 88888 tidak tepat. Pada saat

keruntuhan ukuran posisi memesan dalam akun ini begitu besar itu, ketika harga pasar
bergerak tidak baik, itu menyebabkan runtuhnya Baring Group.
Pendanaan untuk posisi dalam bentuk uang tunai atau surat berharga disimpan dengan
pertukaran dikenal sebagai margin. Margin A panggilan adalah permintaan dari pertukaran atau
broker / dealer untuk uang tambahan atau agunan untuk menutup posisi itu. Dalam urutan
untuk membiayai SIMEX yang (exchange Singapura) marjin deposito untuk akun 88.888
transaksi, Leeson dibutuhkan dana dari perusahaan lain Barings. Pada bulan Januari tahun
1995, Audit tahunan Coopers & Lybrand tentang Barings 'Singapura akun kantor dijemput
ketidaksesuaian dalam rekening, sehingga manajemen Barings 'tahu ada masalah tapi tidak
persis di mana itu berbaring atau ukurannya. Namun, Leeson berhasil menghindari pertanyaan
auditor. Sekitar saat yang sama, auditor SIMEX mengidentifikasi masalah dengan 88.888 akun.
Pada bulan Februari tahun 1995, Barings Securities sangat khawatir dengan peristiwa. Sampai
sampai Februari 1995, Posisi mungkin telah dipulihkan, tapi setelah itu pasar jatuh terus-
menerus dan kerugian dalam akun 88888 dipasang hampir secara eksponensial. Nasib Barings
'disegel dengan tidak adanya baik orang atau sistem dibutuhkan untuk menghentikan aliran
dana ke Singapura. Dengan itu waktu bank itu 'seperti saringan, bocor dana untuk Leeson
melalui berbagai lubang '. Tidak ada pemeriksaan yang dilakukan ketika uang itu ditransfer dari
satu bagian dari Barings yang lain. Karena ada risiko jelas adalah yang terlibat, pekerjaan itu
dialokasikan untuk pegawai junior. Juga karena tidak ada sistem yang ada untuk mendeteksi
penipuan kegiatan, itu diserahkan kepada individu untuk mengambil dan menafsirkan petunjuk.
Selalu ada kemungkinan bahwa hal yang mungkin salah. Tapi menerima bahwa kadang-
kadang gagal akan terjadi bukanlah hal yang sama seperti mengabaikannya. Juga tidak berarti
bahwa operasi tidak dapat atau tidak harus berusaha untuk meminimalkan kegagalan. Namun
tidak semua kegagalan sama-sama serius. beberapa kegagalan yang insidental dan mungkin
tidak diperhatikan; lain dapat menyebabkan bencana kegagalan. jadi organisasi perlu
membedakan antara kegagalan dan membayar tertentu perhatian untuk mereka yang adalah
kritis. Untuk melakukan hal ini kita perlu memahami mengapa sesuatu gagal dan dapat
mengukur Dampak dari kegagalan.

Mengapa Bisa Gagal
Kegagalan dalam operasi dapat terjadi karena berbagai alasan yang berbeda. Beberapa
memiliki sumber mereka dalam operasi karena desainnya secara keseluruhan sudah rusak atau
karena fasilitas (mesin, peralatan dan bangunan) atau staf gagal. Beberapa disebabkan oleh
kesalahan dalam materi atau informasi masukan untuk operasi. Beberapa disebabkan oleh
tindakan pelanggan. Dan beberapa, yang menerima meningkatkan perhatian, disebabkan oleh
gangguan lingkungan seperti serangan teroris.
Kegagalan desain - Pada tahap desain operasi mungkin terlihat baik-baik saja di atas
kertas; hanya ketika telah untuk mengatasi keadaan yang sebenarnya mungkin kekurangan
menjadi jelas. Beberapa kegagalan desain terjadi karena karakteristik permintaan itu diabaikan
atau salah perhitungan. Sebuah proses mungkin tidak mampu mengatasi dengan tuntutan
ditempatkan di atasnya. Mungkin tidak ada permintaan tak terduga ditempatkan pada operasi;
kesalahan sederhana dalam menerjemahkan persyaratan permintaan menjadi desain yang
memadai mungkin penyebabnya. Kegagalan-desain terkait lainnya terjadi karena keadaan yang
tak terduga. Misalnya, jalur produksi mungkin diinstal dengan asumsi ukuran produk tertentu,
tapi kemudian pasar menuntut ukuran yang lebih besar yang menyebabkan mesin untuk
kerusakan. Desain yang memadai termasuk mengidentifikasi berbagai situasi di mana operasi
harus kerja dan merancang sesuai.
Telah dipakai Kegagalan - Semua telah dipakai (Yaitu, mesin, Peralatan, Bangunan dan
perlengkapan) dari Operasi bertanggung jawab UNTUK telah dipakai Kegagalan ATAU
kerusakan. The 'breakdown' parsial mungkin Hanya, misalnya karpet Usang ATAU ditandai di
Hotel ATAU mesin Yang DAPAT Bekerja PADA Hanya Setengah nya Tingkat normal. ATAU,
jumlah DAPAT Menjadi penghentian Dan Tiba-Tiba Operasi. Either way, Adalah ITU Efek Dari
kerusakan Yang Penting. Beberapa kerusakan DAPAT membawa sebagian gede Operasi
Berhenti. Kegagalan berbaring mungkin memiliki Dampak Yang signifikan Hanya JIKA mereka
Terjadi PADA Saat Yang sama sebagai Kegagalan lainnya. Sebagai contoh, lihat Kasus Singkat
'Dua juta UNTUK Satu'.
Orang kegagalan - Orang kegagalan datang dalam dua jenis: kesalahan dan pelanggaran.
'Kesalahan' adalah kesalahan dalam penilaian; dengan melihat ke belakang, seseorang harus

melakukan sesuatu yang berbeda. untuk Misalnya, jika manajer toko olahraga gagal untuk
mengantisipasi peningkatan permintaan untuk bola selama Piala Dunia, toko akan kehabisan
stok. Ini adalah kesalahan penghakiman. 'Pelanggaran' adalah tindakan yang jelas bertentangan
dengan prosedur operasi didefinisikan. Sebagai contoh, operator mesin gagal untuk
membersihkan dan melumasi mesin dengan cara yang ditentukan. itu Operator telah
'melanggar' prosedur yang ditetapkan. Kedua kesalahan dan pelanggaran harus terjadi untuk
menghasilkan jenis kegagalan dijelaskan dalam kasus pendek 'Dua juta untuk satu'
Pemasok kegagalan - Setiap kegagalan dalam pengiriman atau kualitas barang dan jasa
dalam operasi dapat menyebabkan pemasok kegagalan. Kegagalan band muncul di konser akan
menyebabkan Seluruh acara untuk 'gagal'. Demikian pula, jika band tidak menunjukkan tetapi
terbukti menjadi bakat meragukan, yang Konser juga bisa dianggap sebagai kegagalan. Semakin
operasi bergantung pada pemasok bahan atau jasa, semakin bertanggung jawab untuk
kerusakan yang disebabkan oleh hilang atau input sub-standar.
Kegagalan Pelanggan - Tidak semua kegagalan yang (langsung) yang disebabkan oleh
operasi atau pemasoknya. Kegagalan pelanggan dapat hasil dari penyalahgunaan produk dan
layanan yang operasi telah dibuat. Misalnya, mesin cuci mungkin telah diproduksi secara efisien
dan gagal bebas cara, namun pelanggan yang membeli itu bisa membebani atau
menyalahgunakannya. itu pelanggan tidak 'selalu benar'. Kurangnya perhatian mereka,
ketidakmampuan atau kurangnya akal sehat bias menjadi penyebab kegagalan. Namun,
sebagian besar organisasi akan menerima bahwa mereka memiliki tanggung jawab untuk
mendidik dan melatih pelanggan dan untuk merancang produk dan layanan mereka sehingga
dapat meminimalkan kemungkinan kegagalan. Misalnya, urutan pertanyaan di mesin teller
otomatis dirancang oleh bank sedemikian rupa untuk membuat operasi mereka sebagai 'gagal
bebas' mungkin.
Gangguan terkait lingkungan kegagalan - gangguan Lingkungan mencakup semua
penyebab kegagalan yang berada di luar pengaruh langsung operasi ini. Sumber kegagalan
potensial telah meningkat ke dekat bagian atas agenda banyak perusahaan 'sejak 11 September
2001. Sebagai operasi menjadi semakin terintegrasi (dan semakin tergantung pada teknologi
yang terintegrasi seperti sebagai teknologi informasi), bisnis lebih menyadari peristiwa kritis

dan kerusakan yang mempunyai potensi untuk mengganggu normal kegiatan usaha dan bahkan
berhenti Seluruh perusahaan. Biasanya, bencana tersebut termasuk angin topan, banjir, petir,
suhu ekstrem, kebakaran, kejahatan korporasi, pencurian, penipuan, sabotase, terorisme,
ledakan bom, menakut-nakuti bom atau serangan keamanan lainnya dan kontaminasi produk
atau proses.
Kegagalan sebagai kesempatan
Meskipun kategorisasi kami gagal, asal dari semua kegagalan adalah beberapa jenis
Kegagalan manusia. Kegagalan mesin mungkin telah disebabkan oleh desain miskin seseorang
atas pemeliharaan, kegagalan pengiriman oleh kesalahan seseorang dalam mengelola jadwal
pasokan, dan pelanggan kesalahan oleh kegagalan seseorang untuk memberikan petunjuk yang
memadai. Kegagalan jarang hasil dari kebetulan acak; akar penyebab mereka biasanya gagal
manusia. Implikasi dari ini, pertama, bahwa kegagalan bisa sampai batas tertentu dikendalikan
dan kedua, bahwa organisasi dapat belajar dari kegagalan dan memodifikasi perilaku mereka
sesuai. Realisasi ini telah menyebabkan apa yang kadang-kadang disebut kegagalan sebagai
konsep peluang. Daripada mengidentifikasi 'Pelakunya' siapa yang bertanggung jawab dan
menyalahkan atas kegagalan, kegagalan dianggap sebagai kesempatan untuk memeriksa
mengapa mereka terjadi dan untuk dimasukkan ke dalam prosedur tempat yang
menghilangkan atau mengurangi kemungkinan mereka berulang. Ini diperlakukan lebih lanjut,
kemudian dalam bab ini, ketika kita meneliti kegagalan perencanaan '.
Mengukur Kegagalan
Ada tiga cara utama untuk mengukur kegagalan:
tingkat kegagalan - seberapa sering terjadi kegagalan;
keandalan - kemungkinan kegagalan terjadi;
ketersediaan - jumlah yang tersedia waktu operasi berguna.

'Kegagalan tingkat' dan 'kehandalan' berbagai cara untuk mengukur hal yang sama –
kecenderungan dari operasi, atau bagian dari operasi, gagal. Ketersediaan merupakan salah
satu ukuran dari konsekuensi dari kegagalan dalam operasi.
Tingkat Kegagalan
Tingkat kegagalan (FR) dihitung sebagai jumlah kegagalan selama periode waktu.
Sebagai contoh, keamanan bandara dapat diukur dengan jumlah pelanggaran keamanan per
tahun, dan tingkat kegagalan mesin dapat diukur dari segi jumlah kegagalan dibagi dengan
waktu operasi. Tingkat kegagalan dapat diukur baik sebagai persentase dari jumlah total produk
yang diuji atau sebagai jumlah kegagalan dari waktu ke waktu:
Kegagalan Dari Waktu Ke Waktu - Yang 'Bak Mandi' Kurva
Kegagalan, untuk sebagian besar operasi, merupakan fungsi dari waktu. Pada tahapan
yang berbeda selama kehidupan apapun, kemungkinan itu gagal akan berbeda. Probabilitas dari
listrik Lampu gagal relatif tinggi ketika pertama kali ditancapkan. Setiap cacat kecil dalam materi
dari mana filamen dibuat atau jalan lampu dirakit dapat menyebabkan lampu gagal. Jika lampu
bertahan tahap awal ini, masih bisa gagal pada setiap titik, tapi lagi itu bertahan, semakin besar
kemungkinan kegagalan menjadi. Sebagian bagian fisik dari berperilaku operasi dengan cara
yang sama. Kurva yang menggambarkan probabilitas kegagalan jenis ini disebut kurva bak
mandi. Ini terdiri dari tiga tahap yang berbeda:
yang 'bayi-kematian' atau 'awal kehidupan' tahap di mana kegagalan awal terjadi
disebabkan oleh cacat bagian atau penggunaan yang tidak benar;
'normal-hidup' panggung ketika tingkat kegagalan biasanya rendah dan cukup konstan,
dan disebabkan oleh faktor acak normal;

yang 'memakai-out' panggung ketika meningkat tingkat kegagalan sebagai bagian
mendekati akhir nya kehidupan kerja dan kegagalan disebabkan oleh penuaan dan
kerusakan bagian.
Gambar 19.2 mengilustrasikan tiga kurva bak mandi dengan karakteristik yang sedikit
berbeda. Kurva A menunjukkan bagian dari operasi yang memiliki kegagalan bayi-kematian
awal yang tinggi tetapi kemudian panjang, rendah-kegagalan, kehidupan normal diikuti oleh
kemungkinan secara bertahap meningkatkan kegagalan karena pendekatan wear-out. Curve B
memiliki sekitar kematian yang sama relatif bayi, normal-hidup dan tahap memakai-out. Ini
berbeda nyata, namun, dalam prediktabilitas dengan yang gagal terjadi. Kurva A menunjukkan
bagian dengan karakteristik kegagalan yang sangat diprediksi. Jika bertahan bayi mortalitas
(yaitu, melewati waktu x) sangat mungkin untuk bertahan hidup setidaknya sampai memakai-
out dimulai (pada waktu y). Namun, setelah waktu y peluang yang bertahan hidup dengan
cepat berkurang. Kurva B menunjukkan bagian yang jauh lebih dapat diprediksi. Perbedaan
antara tiga tahap kurang jelas, dengan bayi-kematian kegagalan mereda hanya perlahan-lahan
dan secara bertahap meningkatkan kesempatan dari memakai-out kegagalan. Namun, ada
contoh komponen penguat lebih lama dari hidup mereka diharapkan (lihat yang 'ringan
Leading' kasus pendek). Fasilitas dengan kurva kegagalan yang sama dengan yang ditunjukkan
dalam kurva B jauh lebih sulit untuk mempertahankan secara terencana, seperti yang akan kita
bahas nanti. Kegagalan operasi yang lebih mengandalkan sumber daya manusia dari pada
teknologi, seperti beberapa layanan, dapat mengikuti kurva yang agak berbeda, seperti yang
ditunjukkan pada kurva C dari Gambar 19.2. Mereka mungkin kurang rentan terhadap keausan
komponen-out tetapi lebih kepada staf puas, sebagai layanan, tanpa review dan regenerasi,
dapat menjadi membosankan dan berulang-ulang. Dalam kasus seperti itu ada awal tahap
reduksi kegagalan, setara dengan tahap bayi-kematian, seperti masalah dalam pelayanan
disetrika keluar. Hal ini dapat diikuti oleh periode panjang peningkatan kegagalan.

Keandalan
Keandalan mengukur kemampuan sistem, produk atau jasa untuk melakukan seperti
yang diharapkan lebih waktu. Pentingnya kegagalan tertentu sebagian ditentukan oleh efeknya
pada kinerja seluruh operasi atau sistem. Hal ini pada gilirannya tergantung pada cara di mana
bagian dari sistem yang bertanggung jawab untuk kegagalan yang terkait. Jika komponen dalam
suatu sistem yang semua saling tergantung, kegagalan dalam komponen individu akan
menyebabkan seluruh sistem gagal. Sebagai contoh, jika sistem saling memiliki komponen n
masing-masing dengan kehandalan mereka sendiri, Keandalan mengukur kemampuan sistem,
produk atau jasa untuk melakukan seperti yang diharapkan lebih waktu. Pentingnya kegagalan
tertentu sebagian ditentukan oleh efeknya pada kinerja seluruh operasi atau sistem. Hal ini
pada gilirannya tergantung pada cara di mana bagian dari sistem yang bertanggung jawab
untuk kegagalan yang terkait. Jika komponen dalam suatu sistem yang semua saling
tergantung, kegagalan dalam komponen individu akan menyebabkan seluruh sistem gagal.
Sebagai contoh, jika sistem saling memiliki komponen n masing-masing dengan kehandalan
mereka sendiri,

Jumlah komponen
Dalam contoh di atas, keandalan seluruh sistem hanya 0,8, meskipun keandalan dari
komponen individu secara signifikan lebih tinggi. Jika sistem telah dibuat komponen lebih,
kehandalan akan lebih rendah. Semakin saling bergantung komponen sistem memiliki, lebih
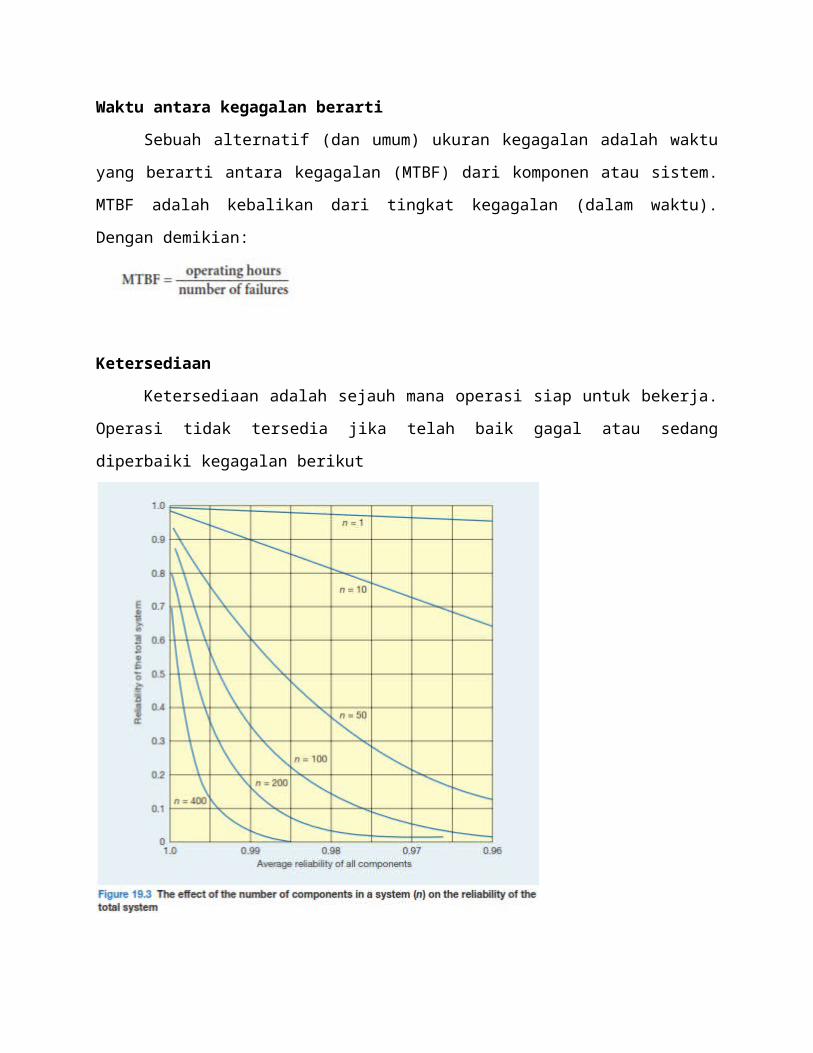
rendah kehandalan akan. Gambar 19.3 menunjukkan penurunan keandalan sistem sebagai
jumlah komponen dalam sistem meningkat. Untuk sistem yang terdiri dari komponen yang
masing-masing memiliki keandalan individu 0,99, dengan 10 komponen keandalan sistem telah
menyusut menjadi 0,9, dengan 50 komponen itu adalah di bawah 0,8, dengan 100 komponen
itu adalah di bawah 0,4 dan dengan 400 komponen itu turun di bawah 0.05. Dengan kata lain,
dengan sistem 400 komponen (tidak biasa dalam operasi otomatis besar), bahkan jika
keandalan dari setiap komponen individu adalah 99 persen, seluruh sistem akan bekerja kurang
dari 5 persen dari waktu.
Waktu antara kegagalan berarti
Sebuah alternatif (dan umum) ukuran kegagalan adalah waktu yang berarti antara
kegagalan (MTBF) dari komponen atau sistem. MTBF adalah kebalikan dari tingkat kegagalan
(dalam waktu). Dengan demikian:
Ketersediaan
Ketersediaan adalah sejauh mana operasi siap untuk bekerja. Operasi tidak tersedia jika
telah baik gagal atau sedang diperbaiki kegagalan berikut

Ada beberapa cara yang berbeda untuk mengukur ketersediaan tergantung pada berapa
banyak alasan untuk tidak beroperasi disertakan. Kurangnya ketersediaan karena pemeliharaan
yang direncanakan atau giliran dapat dimasukkan, misalnya. Namun, ketika 'ketersediaan'
sedang digunakan untuk menunjukkan waktu operasi tidak termasuk konsekuensi dari
kegagalan, itu dihitung sebagai berikut:
dimana:
MTBF = waktu yang berarti antara kegagalan operasi
MTTR = waktu yang berarti untuk memperbaiki, yang merupakan rata-rata waktu yang diambil
untuk memperbaiki operasi dari waktu itu gagal untuk waktu yang beroperasi lagi.

Pencegahan Kegagalan Dan Pemulihan
Dalam istilah praktis, manajer operasi memiliki tiga set kegiatan yang berhubungan
dengan kegagalan. itu pertama berkaitan dengan pemahaman apa kegagalan yang terjadi
dalam operasi dan mengapa mereka terjadi. Setelah sifat setiap kegagalan dipahami, manajer
operasi ini Tugas kedua adalah untuk menguji cara-cara baik mengurangi kemungkinan
kegagalan atau meminimalkan konsekuensi dari kegagalan. Tugas ketiga adalah untuk
merancang rencana dan prosedur yang membantu operasi untuk pulih dari kegagalan ketika
mereka terjadi. Yang pertama dari tugas-tugas ini, pada dasarnya, prasyarat untuk dua lainnya
(lihat Gambar 19.4). Sisa dari bab ini berkaitan dengan tiga tugas tersebut.
KEGAGALAN DETEKSI DAN ANALISIS
Mengingat bahwa kegagalan akan terjadi, manajer operasi harus terlebih dahulu
memiliki mekanisme di tempat yang memastikan bahwa mereka menyadari bahwa kegagalan
telah terjadi dan memiliki prosedur di tempat yang menganalisis kegagalan untuk mengetahui
akar penyebab nya.

Mekanisme Untuk Mendeteksi Kegagalan
Organisasi kadang-kadang mungkin tidak menyadari bahwa sistem telah gagal dan
dengan demikian kehilangan kesempatan baik untuk menempatkan hal yang benar untuk
pelanggan dan belajar dari pengalaman. Pelanggan tidak puas dengan makanan atau layanan di
restoran sangat mungkin 'orang dengan kaki mereka. Ketika pelanggan melakukan mengeluh
tentang produk atau layanan, situasinya mungkin ditangani, tetapi sistem tidak dapat diubah
untuk mencegah masalah tersebut terjadi lagi. Hal ini mungkin karena staf takut bahwa
menarik perhatian masalah dapat dilihat sebagai tanda kelemahan atau kurangnya
kemampuan, atau karena ada sistem identifikasi kegagalan tidak memadai, atau kurangnya
dukungan manajerial atau kepentingan dalam membuat perbaikan. banyak mekanisme yang
tersedia untuk mencari kegagalan dalam cara proaktif:
Dalam proses pemeriksaan. Karyawan memeriksa bahwa layanan ini dapat diterima
selama proses itu sendiri. Hal ini sering dilakukan di restoran, misalnya 'Apakah
semuanya baik-baik dengan Anda makan, Madam? "
Pemeriksaan diagnostik mesin. Sebuah mesin diuji dengan menempatkan melalui urutan
ditentukan kegiatan yang dirancang untuk mengekspos setiap kegagalan atau potensi
kegagalan. Prosedur servis komputer sering termasuk jenis dari periksa.
Point-of-keberangkatan wawancara. Di akhir layanan, staf dapat secara formal maupun
informal periksa bahwa layanan telah memuaskan dan mencoba untuk meminta
masalah serta pujian.
Survei telepon. Ini dapat digunakan untuk meminta pendapat tentang produk atau jasa.
Televisi perusahaan penyewaan, misalnya, mungkin memeriksa instalasi dan servis
peralatan dalam hal ini.
Kelompok fokus. Ini adalah kelompok pelanggan yang dibawa bersama-sama untuk
fokus pada beberapa aspek produk atau layanan. Ini dapat digunakan untuk
menemukan baik masalah tertentu atau sikap yang lebih umum terhadap produk atau
jasa.
Keluhan atau kartu umpan balik dan kuesioner. Ini digunakan oleh banyak organisasi
untuk meminta pandangan tentang produk dan layanan. Masalahnya di sini adalah

bahwa sangat sedikit orang cenderung untuk menyelesaikan mereka. Kuesioner dapat
menghasilkan respon sedikit lebih tinggi dari keluhan kartu, meskipun sulit untuk
mengidentifikasi keluhan individu tertentu
Analisis Kegagalan
Salah satu kegiatan penting bagi suatu organisasi ketika kegagalan telah terjadi adalah
untuk memahami mengapa hal itu terjadi. Kegiatan ini disebut analisis kegagalan. Ada banyak
teknik yang berbeda dan pendekatan yang digunakan untuk mengungkap akar penyebab
kegagalan. Beberapa dari mereka dijelaskan dalam bab sebelumnya. Lainnya adalah sebagai
berikut:
Penyelidikan kecelakaan. Bencana nasional berskala besar seperti tumpahan kapal
tanker minyak dan pesawat kecelakaan biasanya diselidiki menggunakan penyelidikan
kecelakaan, di mana khusus dilatih Staf menganalisis penyebab kecelakaan.
Kegagalan ketertelusuran. Beberapa bisnis (baik karena pilihan atau karena persyaratan
hukum) mengadopsi prosedur traceability untuk memastikan bahwa semua kegagalan
mereka (seperti yang terkontaminasi produk makanan) dapat dilacak. Setiap kegagalan
dapat ditelusuri kembali ke proses yang menghasilkan mereka, komponen dari mana
mereka diproduksi atau pemasok yang memberikan mereka.
Analisis keluhan. Keluhan (dan pujian) merupakan sumber potensial yang berharga bagi
mendeteksi akar penyebab kegagalan layanan pelanggan. Dua keuntungan utama dari
keluhan adalah bahwa mereka datang diminta dan juga mereka adalah sering sangat
potongan tepat waktu dari informasi yang dapat menunjukkan masalah cepat. Analisis
keluhan juga melibatkan pelacakan jumlah aktual dari keluhan dari waktu ke waktu,
yang dapat dengan sendirinya menjadi indikasi mengembangkan masalah. Fungsi utama
dari analisis keluhan melibatkan menganalisis 'isi' dari keluhan untuk memahami lebih
baik sifat kegagalan seperti yang dirasakan oleh pelanggan.
Analisis insiden kritis hanya memerlukan pelanggan untuk mengidentifikasi unsur-unsur
produk atau layanan yang mereka ditemukan baik sangat memuaskan atau tidak terlalu
memuaskan. Mereka diminta untuk menuliskan insiden yang memberi mereka menyebabkan
ketidakpuasan atau kepuasan. itu transkrip bukti anekdotal ini kemudian dianalisis secara rinci
faktor, sifat dan penyebab kepuasan dan ketidakpuasan. Penyebab ini kemudian dapat
dikategorikan dan dihubungkan dengan kemungkinan penyebab kegagalan. Ini adalah cara yang
populer untuk mengumpulkan informasi, terutama dalam operasi layanan. Teknik insiden kritis
(CIT) telah didefinisikan sebagai 'dasarnya prosedur untuk mengumpulkan tertentu penting
fakta tentang laku dalam situasi didefinisikan '. 4 Teknik ini telah diterapkan untuk banyak
industri layanan yang berbeda, termasuk hotel, bank dan maskapai penerbangan.
Modus Kegagalan Dan Analisis Efek
Tujuan dari modus kegagalan dan analisis efek (FMEA) adalah untuk mengidentifikasi
produk atau jasa fitur itu adalah kritis untuk berbagai jenis dari kegagalan. Ini adalah sarana
kegagalan mengidentifikasi sebelum terjadi dengan menyediakan 'checklist' prosedur yang
dibangun sekitar tiga pertanyaan kunci. Untuk setiap kemungkinan penyebab kegagalan:
Bagaimana kemungkinan bahwa kegagalan akan terjadi?
Apa yang akan konsekuensi dari kegagalan itu?
Berapa besar kemungkinan adalah kegagalan tersebut untuk dideteksi sebelum mempengaruhi
pelanggan?
Berdasarkan evaluasi kuantitatif dari tiga pertanyaan tersebut, sejumlah prioritas risiko
(RPN) adalah dihitung untuk setiap penyebab potensial kegagalan. Tindakan perbaikan,
bertujuan untuk mencegah kegagalan, kemudian diterapkan kepada mereka penyebab yang
RPN menunjukkan bahwa mereka menjamin prioritas. Ini pada dasarnya adalah proses tujuh
langkah:
Langkah 1 Mengidentifikasi semua bagian komponen dari produk atau jasa.
Langkah 2 Daftar semua cara yang mungkin di mana komponen bisa gagal (mode kegagalan).

Langkah 3 Mengidentifikasi kemungkinan efek kegagalan (down time, keselamatan, perbaikan
persyaratan
KASIH, efek pada pelanggan).
Langkah 4 Identifikasi semua kemungkinan penyebab kegagalan untuk setiap mode kegagalan.
Langkah 5 Menilai kemungkinan kegagalan, tingkat keparahan dampak kegagalan dan seperti-
yang lihood deteksi.
Langkah 6 Hitung RPN dengan mengalikan ketiga peringkat bersama-sama.
Langkah 7 Menghasut tindakan korektif yang akan meminimalkan kegagalan pada mode
kegagalan yang menunjukkan RPN tinggi.
Analisis Kesalahan-Pohon
Ini adalah prosedur logis yang dimulai dengan kegagalan atau potensi kegagalan dan
bekerja mundur untuk mengidentifikasi semua kemungkinan penyebab dan karena itu asal-usul
dari kegagalan itu. Kesalahan-pohon analisis terdiri dari cabang dihubungkan oleh dua jenis
node: node DAN dan ATAU node. Cabang-cabang bawah AND simpul semua harus terjadi untuk
acara di atas node untuk terjadi. Hanya salah satu cabang bawah OR simpul perlu terjadi untuk
acara di atas simpul terjadi. Gambar 19.5 menunjukkan pohon sederhana mengidentifikasi
kemungkinan alasan untuk hidangan panas yang disajikan dingin di sebuah restoran.

MENINGKATKAN KEANDALAN PROSES
Setelah pemahaman yang menyeluruh tentang penyebab dan dampak dari kegagalan
telah ditetapkan, tanggung jawab berikutnya manajer operasi adalah mencoba untuk
mencegah kegagalan yang terjadi di tempat pertama. Mereka dapat melakukan hal ini dalam
beberapa cara, seperti merancang keluar gagal poin di proses, membangun redundansi ke
dalam proses, 'gagal-safeing' beberapa kegiatan di proses, dan memelihara fasilitas fisik dalam
proses. Kami akan memeriksa masing-masing, tetapi terutama pemeliharaan fasilitas fisik
(peralatan, mesin dan bangunan) yang merupakan kegiatan penting dalam semua operasi.
Merancang Keluar Gagal Poin
Bab 4 dan 5 pada proses dan produk / layanan desain dan Bab 17 tentang perencanaan
kualitas dan kontrol prihatin dengan mengidentifikasi dan kemudian mengendalikan proses,
produk dan layanan karakteristik untuk mencoba untuk mencegah kegagalan terjadi.
Secara khusus, Bab 17 menggambarkan penggunaan kontrol proses charting mencoba untuk
mendeteksi ketika proses akan keluar dari kontrol sehingga tindakan yang bisa diambil sebelum

kegagalan terjadi. Pemetaan proses, dijelaskan dalam Bab 5, dapat digunakan untuk 'insinyur
keluar' potensi poin gagal dalam operasi.
Redundansi
Bangunan di redundansi untuk operasi berarti memiliki back-up sistem atau komponen
dalam kasus kegagalan. Hal ini dapat mahal dan umumnya digunakan ketika rinciannya bisa
memiliki dampak kritis. Ini berarti dua kali lipat atau bahkan tiga kali lipat beberapa bagian dari
proses atau sistem dalam kasus salah satu komponen gagal. Pembangkit listrik tenaga nuklir,
pesawat ruang angkasa dan rumah sakit semua memiliki sistem tambahan seandainya keadaan
darurat. Beberapa organisasi juga memiliki staf 'back-up' yang diadakan di cadangan kasus
seseorang tidak muncul untuk bekerja atau diadakan pada satu pekerjaan dan tidak dapat
melanjutkan ke yang berikutnya. Rem belakang pencahayaan set di bus dan truk berisi dua
lampu untuk mengurangi kemungkinan dari tidak menunjukkan lampu merah. Tubuh manusia
mengandung dua beberapa organ - ginjal dan mata, misalnya - yang keduanya digunakan dalam
'operasi normal' tapi tubuh dapat mengatasi kegagalan dalam salah satu dari mereka.
Keandalan komponen bersama-sama dengan back-up diberikan oleh jumlah dari keandalan
komponen asli dan kemungkinan bahwa back-up Komponen keduanya akan diperlukan dan
bekerja.
Gagal-Safeing
Konsep fail-safeing telah muncul sejak diperkenalkannya metode Jepang operasi
peningkatan. Disebut poka-yoke di Jepang (dari yokeru (untuk mencegah) dan poka (kesalahan
yang tidak disengaja)), ide ini didasarkan pada prinsip bahwa kesalahan manusia untuk

beberapa batas tak terelakkan. Yang penting adalah untuk mencegah mereka menjadi cacat.
Poka-belenggu yang alat sederhana (lebih murah) atau sistem yang dimasukkan ke dalam
proses untuk mencegah kesalahan operator yang sengaja mengakibatkan cacat. Khas poka-
belenggu yang seperti perangkat seperti:
Batas beralih pada mesin yang memungkinkan mesin untuk beroperasi hanya jika bagian
tersebut diposisikan benar
Pengukur ditempatkan pada mesin di mana bagian harus melewati untuk dimuat ke,
atau diambil dari, mesin - ukuran yang salah atau orientasi berhenti proses; counter
digital pada mesin untuk memastikan bahwa jumlah yang benar dari luka, melewati atau
lubang memiliki telah mesin;
Checklist yang harus diisi, baik dalam persiapan untuk, atau pada saat penyelesaian,
sebuah kegiatan
Berkas cahaya yang mengaktifkan alarm jika bagian diposisikan tidak benar.
Baru-baru ini, prinsip Fail-safeing telah diterapkan untuk operasi layanan. layanan poka-
belenggu dapat diklasifikasikan sebagai orang yang 'gagal-aman server' (pencipta layanan) dan
orang-orang yang 'gagal-aman pelanggan (penerima layanan). 5 Contoh failsafeing server
meliputi:
Kode warna tombol kasir untuk mencegah masuknya salah dalam operasi ritel;
McDonald yang mengambil jumlah yang tepat dari kentang goreng di kanan Orientasi
untuk ditempatkan di kemasan;
Nampan digunakan di rumah sakit dengan lekukan berbentuk ke setiap item yang
diperlukan untuk bedah Prosedur - item tidak kembali terjadi pada akhir prosedur
mungkin telah ditinggalkan di pasien;
Strip kertas ditempatkan putaran handuk bersih di hotel, penghapusan yang membantu
pembantu rumah tangga untuk mengatakan apakah handuk telah digunakan dan karena
itu perlu diganti.

Contoh Gagal-Safeing Pelanggan Meliputi:
Kunci pada pintu pesawat WC, yang harus berubah untuk mengaktifkan lampu pada;
Penyeranta di ATM untuk memastikan bahwa pelanggan menghapus kartu mereka;
Tinggi bar di hiburan naik untuk memastikan bahwa pelanggan tidak melebihi
batasan ukuran;
Menguraikan digambar di dinding pusat penitipan anak untuk menunjukkan di mana
mainan harus diganti pada akhir periode bermain;
Nampan berdiri strategis ditempatkan di restoran cepat saji untuk mengingatkan
pelanggan untuk membersihkan mereka tabel.
Pemeliharaan
Pemeliharaan adalah bagaimana organisasi mencoba untuk menghindari kegagalan
dengan merawat fasilitas fisik mereka. Ini adalah bagian penting dari kegiatan yang paling
operasi '. Dalam operasi seperti listrik stasiun, hotel, penerbangan dan kilang petrokimia,
kegiatan pemeliharaan akan memperhitungkan
proporsi yang signifikan dari manajemen operasi ini waktu, perhatian dan sumber daya.
keuntungan dari pemeliharaan yang signifikan, termasuk meningkatkan keamanan,
peningkatan kehandalan, tinggi kualitas (peralatan terpelihara lebih mungkin menyebabkan
kesalahan kualitas), operasi yang lebih rendah biaya (karena teknologi proses teratur dilayani
lebih efisien), rentang hidup lebih lama untuk teknologi proses dan lebih tinggi 'nilai akhir'
(karena fasilitas terawat umumnya mudah untuk membuang ke pasar kedua tangan).
Tiga Pendekatan Dasar Untuk Pemeliharaan
Dalam prakteknya kegiatan pemeliharaan organisasi akan terdiri dari beberapa
kombinasi dari tiga pendekatan dasar untuk perawatan fasilitas fisik. Ini dijalankan dengan
kerusakan (RTB), pemeliharaan preventif (PM) dan kondisi berbasis pemeliharaan (CBM).
Jalankan pemeliharaan rincian, seperti namanya, melibatkan memungkinkan fasilitas
untuk melanjutkan operasi sampai mereka gagal. Pekerjaan pemeliharaan dilakukan hanya
setelah kegagalan telah mengambil Tempat. Misalnya, televisi, peralatan mandi dan telepon di

tamu hotel kamar mungkin akan diperbaiki hanya jika mereka gagal. Hotel ini akan menyimpan
beberapa suku cadang dan staf yang tersedia untuk melakukan perbaikan bila diperlukan.
Kegagalan dalam keadaan ini adalah tidak bencana (meskipun mungkin menjengkelkan untuk
tamu) tidak begitu sering untuk membuat pemeriksaan rutin dari fasilitas yang sesuai.
Pemeliharaan preventif, upaya untuk menghilangkan atau mengurangi kemungkinan
kegagalan pelayanan (pembersihan, pelumas, mengganti dan memeriksa) fasilitas pada interval
direncanakan. untuk Misalnya, mesin pesawat penumpang diperiksa, dibersihkan dan
dikalibrasi menurut jadwal rutin setelah sejumlah set jam terbang. Mengambil pesawat dari
tugas rutin mereka untuk pemeliharaan preventif jelas merupakan pilihan yang mahal untuk
maskapai penerbangan apapun. konsekuensi dari Kegagalan sementara dalam pelayanan yang
jauh lebih serius, namun. Prinsipnya adalah juga diterapkan untuk fasilitas dengan konsekuensi
kurang bencana kegagalan. Pembersihan rutin dan pelumas mesin, bahkan lukisan periodik
bangunan, dapat dianggap perawatan preventif.
Kondisi berbasis pemeliharaan, upaya untuk melakukan perawatan hanya ketika fasilitas
memerlukannya. Misalnya, peralatan proses yang berkesinambungan, seperti yang digunakan
dalam lapisan fotografi kertas, dijalankan untuk waktu yang lama untuk mencapai pemanfaatan
tinggi yang diperlukan untuk hemat biaya produksi. Menghentikan mesin untuk mengubah,
katakanlah, bantalan ketika tidak sepenuhnya diperlukan untuk melakukannya akan
membawanya keluar dari tindakan untuk waktu yang lama dan mengurangi pemanfaatannya. di
sini pemeliharaan berdasarkan kondisi-mungkin melibatkan terus memantau getaran, untuk
misalnya, atau beberapa karakteristik lain dari garis itu. Hasil pemantauan ini maka akan
digunakan untuk memutuskan apakah garis harus dihentikan dan diganti bantalan.
Strategi Pemeliharaan Campuran
Setiap pendekatan ke fasilitas menjaga sesuai untuk situasi yang berbeda. RTB adalah
sering digunakan di mana perbaikan relatif mudah (sehingga konsekuensi dari kegagalan kecil),
di mana pemeliharaan rutin sangat mahal (membuat PM mahal), atau di mana kegagalan bukan
di semua diprediksi (sehingga tidak ada keuntungan dalam PM karena kegagalan hanya sebagai

kemungkinan untuk terjadi setelah memperbaiki seperti sebelumnya). PM digunakan di mana
biaya kegagalan yang tidak direncanakan tinggi (karena gangguan untuk normal operasi) dan
dimana kegagalan tidak benar-benar acak (sehingga pemeliharaan waktu bias direncanakan
sebelum kegagalan menjadi sangat mungkin). CBM digunakan di mana pemeliharaan Kegiatan
mahal, baik karena biaya penyediaan perawatan itu sendiri atau karena gangguan yang
kegiatan pemeliharaan menyebabkan untuk operasi.
Sebagian besar operasi mengadopsi campuran pendekatan ini. Bahkan mobil
menggunakan ketiga pendekatan (lihat Gambar 19.6). Lampu dan sekering biasanya diganti
hanya ketika mereka gagal, tapi bagian yang lebih mendasar dari mobil tidak harus lari ke
breakdown. Oli mesin tunduk pada pencegahan pemeliharaan di mobil biasa layanan, ketika
bagian lain dari mobil diperiksa dan diganti seperlunya. Akhirnya, sebagian besar pembalap juga
akan memantau kondisi mobil, mungkin informal oleh mendengarkan untuk mesin kebisingan
ketika mengemudi. Pemantauan lain mungkin dilakukan secara teratur, seperti mengukur
jumlah tapak pada ban.
Breakdown Terhadap Pemeliharaan Preventif

Sebagian besar operasi berencana pemeliharaan mereka untuk memasukkan tingkat
pemeliharaan preventif regular yang memberikan kesempatan yang cukup rendah tetapi
terbatas kerusakan. Biasanya semakin sering episode pemeliharaan preventif, yang kurang
adalah kemungkinan kerusakan. keseimbangan antara pemeliharaan preventif dan kerusakan
diatur untuk meminimalkan total biaya kerusakan. Pemeliharaan preventif jarang akan biaya
sedikit untuk memberikan tetapi akan menghasilkan tinggi kemungkinan (dan karena itu biaya)
pemeliharaan breakdown. Sebaliknya, sangat sering preventif pemeliharaan akan mahal untuk
memberikan tapi akan menurunkan biaya dari harus memberikan perawatan breakdown (lihat
Gambar 19.7a). Total biaya pemeliharaan muncul untuk meminimalkan pada tingkat 'optimal'
pemeliharaan preventif.
Ini representasi dari biaya pemeliharaan yang terkait, namun, meskipun secara konseptual
elegan, mungkin tidak mencerminkan realitas. Biaya penyediaan perawatan pencegahan
mungkin tidak meningkatkan begitu tajam seperti yang ditunjukkan pada Gambar 19.7 (a).
Kurva mengasumsikan bahwa itu dilakukan oleh set terpisah dari orang (staf pemeliharaan
terampil) yang waktunya dijadwalkan dan diperhitungkan secara terpisah dari 'operator'
fasilitas. Selanjutnya, setiap kali perawatan pencegahan Dibutuhkan Tempat, fasilitas tidak bisa
digunakan secara produktif. Inilah sebabnya mengapa kemiringan kurva meningkat karena

episode pemeliharaan mulai mengganggu kerja normal operasi. Di banyak operasi, namun,
setidaknya beberapa perawatan pencegahan dapat dilakukan oleh operator sendiri (yang
mengurangi biaya penyediaan itu) dan pada kali yang nyaman untuk operasi (yang
meminimalkan gangguan untuk operasi). Biaya kerusakan juga bisa menjadi lebih tinggi
daripada yang ditunjukkan pada Gambar 19.7 (a). Di sini Argumen ini mirip dengan yang
digunakan di Bab 2 untuk menggambarkan ketergantungan dan Bab 12 untuk menentukan
tingkat stok optimal (dan akan kembali dalam bab berikutnya ketika membahas biaya dari
kualitas). Kerusakan yang tidak direncanakan dapat melakukan lebih dari memerlukan
perbaikan dan menghentikan operasi; mereka dapat mengambil stabilitas dari operasi yang
mencegah mampu berbenah diri. Menempatkan dua ide-ide ini bersama-sama dan kurva
jumlah meminimalkan dan kurva biaya pemeliharaan terlihat lebih seperti Gambar 19.7 (b).
Penekanannya digeser lebih ke arah penggunaan perawatan pencegahan dari run-to-
breakdown maintenance.
Distribusi Kegagalan
Bentuk distribusi probabilitas kegagalan fasilitas juga akan berpengaruh pada manfaat
pemeliharaan preventif. Gambar 19.8 menunjukkan dua kurva probabilitas untuk dua mesin, A
dan B. Untuk mesin A, kemungkinan bahwa itu akan memecah sebelum waktu x adalah relatif
rendah. Mesin ini akan hampir selalu memecah antara kali x dan y.Ifpreventive pemeliharaan
adalah waktunya untuk terjadi sebelum titik x, itu bisa mengurangi kemungkinan breakdown
substansial. Mesin B, sementara itu, memiliki probabilitas yang relatif tinggi melanggar turun
setiap saat, meskipun lagi kemungkinan kerusakan meningkat setelah x.This waktu Artinya
menerapkan pemeliharaan pencegahan pada titik x (atau waktu lain) tidak dapat membawa
penurunan dramatis dalam kerusakan mungkin dengan mesin A. Implikasi dari ini adalah bahwa
pemeliharaan preventif lebih cenderung mengarah pada manfaat ketika periode tembus tinggi
yang cukup diprediksi. Ketika kerusakan terjadi secara relatif acak ada kurang keuntungan dari
pemeliharaan preventif karena memiliki sedikit efek pada kesempatan dari mesin mogok di
masa depan.
