bab v learning (tugas ai lamris pandiangan 03081004080)
TRANSCRIPT

5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 1/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
BAB V
Learning
Terdapat 3 metode learning yang akan dibahas yaitu decision tree learning, jaringan
syaraf tiruan , dan algoritma genetika.
Sebagai contoh perthatikan data peneriamaan pegawai dibawah ini. Terdapat 11 orang
pelamar kerja dengan 3 parameter : IPK , hasil tes psikologis , dan hasil tes wawancara.
Didapat sebuah tabel data penerimaan pegawai (Tabel 5-1).
Pelamar IPK Psikologi Wawancara Diterima
P1 Bagus Tinggi Baik Ya
P2 Bagus Sedang Baik YaP3 Bagus Sedang Buruk Ya
P4 Bagus Rendah Buruk Tidak
P5 Cukup Tinggi Baik Ya
P6 Cukup Sedang Baik Ya
P7 Cukup Sedang Buruk Ya
P8 Cukup Rendah Buruk Tidak
P9 Kurang Tinggi Baik Ya
P10 Kurang Sedang Buruk Tidak
P11 Kurang Rendah Baik Ya
5.1 Decision Tree Learning
Decision tree learning adalah salah satu metode yang menemukan fungsi-fungsi
pendekatan yang bernilai diskrit dan tahan terhadap data-data yang terdapat kesalahan (noisy
data) serta mampu mempelajari ekspresi-ekspresi discjunctive (ekspresi OR).
Iterative Dychotomizer version 3 (ID3) adalah jenis Decision tree learning yang popular.
5.1.1 Entropy
Entropy digunakan sebagai suatu parameter untuk mengukur heterogenitas
(keberagaman) dari suatu kumpulan sampel data. Entropy dirumuskan sebagai berikut :
∑ (5.1)
Dimana c adalah jumlah nilai yang ada pada atribut target (jumlah kelas klasifikasi).
Sedangkan pi menyatakan jumlah sampel untuk kelas i.
Pada data tabel 5-1, jumlah kelas 2, yaitu ‘Ya’ atau ‘Tidak’ (c = 2). Jumlah sampel
untuk kelas 1 (‘Ya’) adalah 8 dan jumlah sampel untuk kelas 2 (‘Tidak’) adalah 3. Dengan
demikian entropy untuk kumpulan sampel data S tabel 5-1 adalah:

5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 2/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
5.1.2 Information Gain
Information Gain merupakan ukuran efektivitas suatu atribut dalam
mengklasifikasikan data. Secara matematis information gain dari suatu atribut A, sebagai
berikut :
∑ (5.3)
Dimana :A : Atribut
V : menyatakan nilai yang mungkin untuk atribut A
Values(A) : himpunan nilai yang mungkin untuk Atribut A
|Sv| : jumlah sampel untuk nilai v
|S| : jumlah seluruh sampel data
Entropy(Sv) : entropy untuk sampel yang memiliki nilai v
Pada tabel 5-1, atribut diterima = ‘Ya’ dikatakan positif (+) dan atribut diterima =
‘Tidak’ dikatakan sebagai negative (-). Didapat :
Values(IPK) = Bagus, Cukup, Kurang)
S = [8+, 3-], |S| = 1
SBagus = [3+, 1-], |SBagus| = 4
SCukup = [3+, 1-], |SCukup| = 4
SKurang = [2+, 1-], |SKurang| = 3
Selanjutnya didapat nilai-nilai entropy :
Entropy(S) = -(8/11)log2(8/11)-(3/11)log2(3/11)
= 0,8454 (5.4)
Entropy(SBagus) =-(3/4)log2(3/4)-(1/4)log2(1/4)
= 0,8113 (5.5)
Entropy(SCukup) =-(3/4)log2(3/4)-(1/4)log2(1/4)
= 0,8113 (5.6)
Entropy(SKurang) =-(2/3)log2(2/3)-(1/3)log2(1/3)
= 0,9183 (5.7)

5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 3/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
()
()
5.1.3 Algoritma ID3
ID3 adalah algoritma decision tree learning (algoritma pembelajaran pohon keputusan)
yang melakukan pencarian secara menyeluruh (greedy) pada semua kemungkinan pohon
keputusan.
Rekursi level o iterasi ke-1
Untuk menemukan atribut yang merupakan the best classifier dan diletakkan sebagaiRoot, diperlukan menghitung information gain untuk dua atribut yang lain, yaitu Psikologi
dan Wawancara.
Dari tabel 5-1 dan dengan cara yang sama pada proses penghitungan Gain (S,IPK), kita
dapatkan Gain (S,Psikologi):
Values(Psikologi) = Tinggi, Sedang, Rendah
S = [8+, 3-], |S| = 11
STinggi = [3+, 0-] |STinggi| = 3,Entropy(STinggi) = 0
SSedang = [4+, 1-] |SSedang| = 5,Entropy(SSedang) = 0,7219SRendah = [1+, 2-] |SRendah| = 3,Entropy(SRendah) = 0,9183
∑
()
Dari tabel 5-1 dan dengan cara yang sama, didapatkan Gain(S,Wawancara):
Values(Psikologi) = Tinggi, Sedang, Rendah
S = [8+, 3-], |S| = 11
SBaik = [6+, 0-] |SBaik | = 6, Entropy(SBaik ) = 0
SBuruk = [2+, 3-] |SBuruk | = 5, Entropy(SBuruk ) = 0,9710
∑

5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 4/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
Dari tiga nilai information gain di atas, Gain (S,Wawancara) adalah yg terbesar,
sehingga wawancara adalah atribut yang merupakan the best classifier dan harus diletakkansebagai Root. Pada tahap ini diperoleh struktur pohon pada gambar 5-2 berikut ini.
Gambar 5-2 : Pohon keputusan yang dihasilkan pada rekursi level 0 iterasi ke -1
Rekursi level 1 iterasi ke-1
Memanggil fungsi ID3 dengan KumpulanSampel berupa SampelBaik = [6+, 0-],
AtributTarger = ‘Diterima’ dan Kumpulan Atribut = {IPK, Psikologi}.
Gambar 5-3 : Pohon keputusan yang dihasilkan pada rekursi level 1 iterasi ke-1
Rekursi level 0 iterasi ke-2
Pada rekursi level 0 iterasi ke-1, sudah dilakukan pengecekan untuk atribut
‘wawancara’ dengan nilai ‘Baik’.Selanjutnya dilakukan pengecekan untuk atribut
‘wawancara’ dengan nilai ‘Buruk’.
Gambar 5-4 : Pohon keputusan pada rekursi level 0 iterasi ke-2
Rekursi level 1 iterasi ke-2
Memanggil fungsi ID3 dengan Kumpulan Sampel berupa SampelBuruk = [2+, 3-],
AtributTarget = ‘Diterima’, dan KumpulanAtribut = {IPK, Psikologi}.
Values(IPK) = Bagus, Cukup, Kurang
S = SampelBuruk = [2+, 3-], |S| = 5
SBagus = [1+, 1-], |SBagus| = 2

5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 5/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
SCukup = [1+, 1-], |SCukup| = 2
SKurang = [0+, 1-], |SKurang| = 1
Selanjutnya, nilai-nilai entropy untuk S, SBagus, SCukup, SKurang, dan information gain untuk IPKadalah:
Entropy(S) = -(2/5)log2(2/5)-(3/5)log2(3/5)
= 0,9710
Entropy(SBagus) =-(1/2)log2(1/2)-(1/2)log2(1/2)
= 1
Entropy(SCukup) =-(1/2)log2(1/2)-(1/2)log2(1/2)
= 1
Entropy(SKurang) =-(0)log2(0)-(1)log2(1)
= 0
()
()
Values(Psikologi) = Tinggi, Sedang, Rendah
S = SampelBuruk = [2+, 3-], |S| = 5, Entropy(S) = 0,9710
STinggi = [0+, 0-] |STinggi| = 0,Entropy(STinggi) = 0
SSedang = [2+, 1-] |SSedang| = 3,Entropy(SSedang) = 0,9183
SRendah = [0+, 2-] |SRendah| = 2,Entropy(SRendah) = 0
∑
()
Dari dua nilai information gain di atas, Gain(S,Psikologi) adalah yang terbesar.
Sehingga Psikologi adalah atribut yang merupakan the best classifier dan harus diletakkan
sebagai simpul di bawah simpul ‘Wawancara’ pada cabang nilai ‘Buruk’.
Pada tahap ini, diperoleh pohon keputusan pada gambar di bawah ini.

5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 6/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
Gambar 5-5 : Pohon keputusan yang dihasilkan pada rekursi level 1 iterasi ke-2
Rekursil level 2 iterasi ke-1
Memanggil fungsi ID3 dengan kumpulan sampel berupa SampelSedang = [2+, 1-],AtributTarget = ‘Diterima’, dan KumpulanAtribut = {IPK}. Sehingga diperoleh pohon
gambar 5-6 di bawah ini.
Gambar 5-6 : Pohon keputusan yang dihasilkan pada rekursi level 2 iterasi ke-1
Rekursi level 3 iterasi ke-1
Memanggil fungsi ID3 dengan kumpulan sampel berupa SampelBagus = [1+,0-],
AtributTarget = ‘Diterima’ dan KumpulanAtribut = {}. Sehingga dihasilkan pohon pada
gambar di bawah ini. Selanjutnya proses akan kembali ke rekursi level 2 untuk iterasi ke-2.
Gambar 5-7 : Pohon keputusan yang dihasilkan pada rekursi level 3 iterasi ke-1

5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 7/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
Rekursi level 2 iterasi ke-2
Pada rekursi level 2 iterasi ke-1, sudah dilakukan pengecekan atribut IPK untuk nilai
‘Bagus’.Selanjutnya pengecekan dilakukan pada atribut IPK untuk nilai’Cukup’.Sehinggadiperoleh pohon pada gambar 5-8 di bawah ini.
Gambar 5-8 : Pohon keputusan yang dihasilkan pada rekursi level 2 iterasi ke-2
Rekursi level 3 iterasi ke-2
Memanggil fungsi ID3 dengan KumpulanSampel berupa SampelCukup = [1+, 0-],
AtributTarget = ‘Diterima’, dan KumpulanAtribut = {}. Sehingga dihasilkan pohon pada
gambar 5-9 di bawah ini. Selanjutnya proses akan kembali ke rekursi level 2 untuk iterasi ke-
3.
Gambar 5-9 : Pohon keputusan yang dihasilkan pada rekursi level 3 iterasi ke-2
Rekursi level 2 iterasi ke-3
Pada rekursi level 2 iterasi ke-1 dan ke-2, sudah dilakukan pengecekanatribut IPK
untuk nilai ‘Bagus’ dan ‘Cukup’.Selanjutnya, pengecekan dilakukan pada atribut IPK untuk nilai ‘Kurang’.Pada tahap ini diper oleh gambar di bawah ini.

5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 8/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
Gambar 5-10 : Pohon keputusan yang dihasilkan pada rekursi level 2 iterasi ke-3
Rekursi level 3 Iterasi ke-3
Memanggil fungsi ID3 dengan KumpulanSampel berupa SampelKurang = [0+, 1-],
AtributTarget = ‘Diterima’, dan KumpulanAtribut = {}. Sehingga dihasilkan pohon pada
gambar 5-11 di bawah ini.Selanjutnya, proses akan kembali ke rekursi level 1 untuk iterasi
ke-3.
Gambar 5-11 : Pohon keputusan yang dihasilkan pada rekursi level 3 iterasi ke-3
Rekursi level 1 iterasi ke-3
Pada rekursi level ini diperoleh pohon pada gambar 5-12 di bawah ini.

5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 9/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
Gambar 5-12 : Pohon keputusan yang dihasilkan pada rekursi level 1 iterasi ke-3
Rekursi level 2 iterasi ke-4
Memanggil fungsi ID3 dengan kumpulan sampel berupa SampelRendah = [0+, 2-],
AtributTarget = ‘Diterima’, dan KumpulanAtribut = {IPK}. Proses selesai dan
mengembalikan pohon keputusan pada gambar 5-13 di bawah ini :
Gambar 5-13 : Pohon keputusan akhir yang dihasilkan oleh fungsi ID3.
Ilustrasi langkah-langkah algoritma ID3 di atas menunjukkan bahwa ID3 melakukan
strategi pencarian hill-climbing : dimulai dari pohon kosong, kemudian secara progresif
berusaha menemukan sebuah pohon keputusan yang mengklasifikasikan sampel-sampel data
secara akurat tanpa kesalahan. Dengan demikian, persamaan 5.10 ini bisa menggantikan
pohon keputusan tersebut dalam mengklasifikasikan sampel data ke dalam kelas ‘Ya’ dan
‘Tidak’.
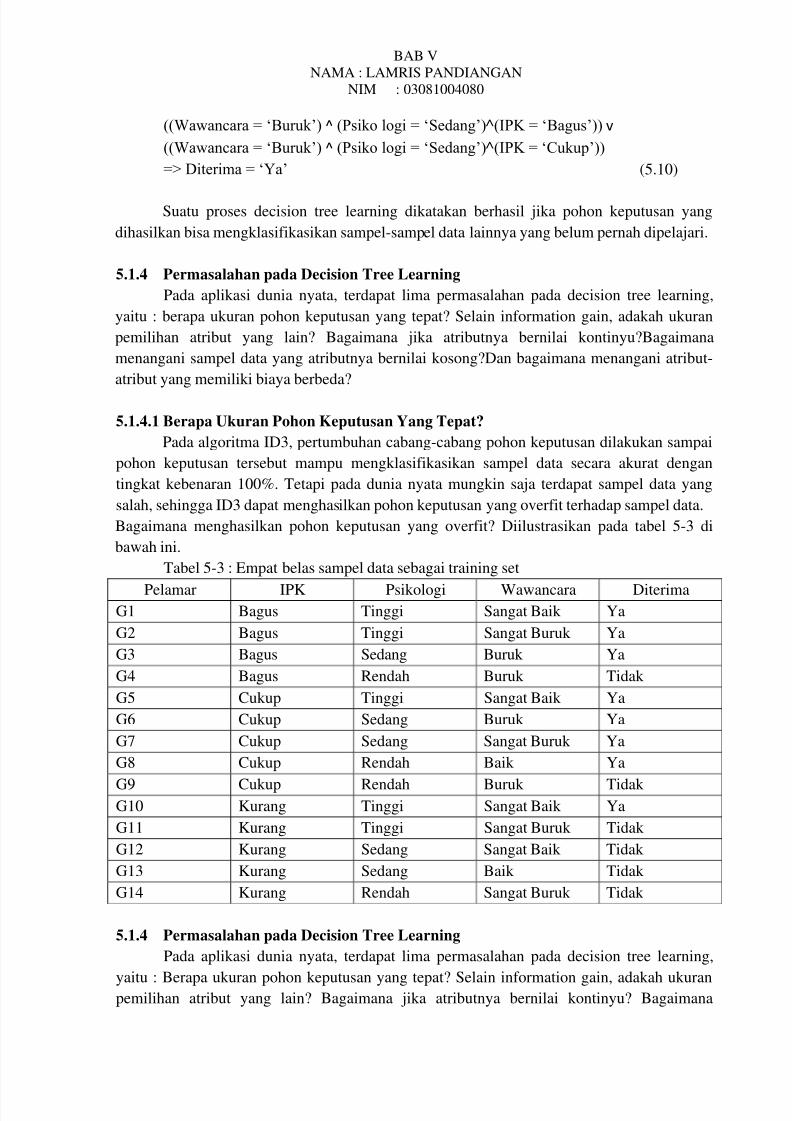
(Wawancara = ‘Baik’) v
5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 10/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
((Wawancara = ‘Buruk’) ^ (Psiko logi = ‘Sedang’)˄(IPK = ‘Bagus’)) v
((Wawancara = ‘Buruk’) ^ (Psiko logi = ‘Sedang’)˄(IPK = ‘Cukup’))
=> Diterima = ‘Ya’ (5.10)
Suatu proses decision tree learning dikatakan berhasil jika pohon keputusan yang
dihasilkan bisa mengklasifikasikan sampel-sampel data lainnya yang belum pernah dipelajari.
5.1.4 Permasalahan pada Decision Tree Learning
Pada aplikasi dunia nyata, terdapat lima permasalahan pada decision tree learning,
yaitu : berapa ukuran pohon keputusan yang tepat? Selain information gain, adakah ukuran
pemilihan atribut yang lain? Bagaimana jika atributnya bernilai kontinyu?Bagaimana
menangani sampel data yang atributnya bernilai kosong?Dan bagaimana menangani atribut-
atribut yang memiliki biaya berbeda?
5.1.4.1 Berapa Ukuran Pohon Keputusan Yang Tepat?
Pada algoritma ID3, pertumbuhan cabang-cabang pohon keputusan dilakukan sampai
pohon keputusan tersebut mampu mengklasifikasikan sampel data secara akurat dengan
tingkat kebenaran 100%. Tetapi pada dunia nyata mungkin saja terdapat sampel data yang
salah, sehingga ID3 dapat menghasilkan pohon keputusan yang overfit terhadap sampel data.
Bagaimana menghasilkan pohon keputusan yang overfit? Diilustrasikan pada tabel 5-3 di
bawah ini.
Tabel 5-3 : Empat belas sampel data sebagai training set
Pelamar IPK Psikologi Wawancara DiterimaG1 Bagus Tinggi Sangat Baik Ya
G2 Bagus Tinggi Sangat Buruk Ya
G3 Bagus Sedang Buruk Ya
G4 Bagus Rendah Buruk Tidak
G5 Cukup Tinggi Sangat Baik Ya
G6 Cukup Sedang Buruk Ya
G7 Cukup Sedang Sangat Buruk Ya
G8 Cukup Rendah Baik Ya
G9 Cukup Rendah Buruk Tidak G10 Kurang Tinggi Sangat Baik Ya
G11 Kurang Tinggi Sangat Buruk Tidak
G12 Kurang Sedang Sangat Baik Tidak
G13 Kurang Sedang Baik Tidak
G14 Kurang Rendah Sangat Buruk Tidak
5.1.4 Permasalahan pada Decision Tree Learning
Pada aplikasi dunia nyata, terdapat lima permasalahan pada decision tree learning,
yaitu : Berapa ukuran pohon keputusan yang tepat? Selain information gain, adakah ukuranpemilihan atribut yang lain? Bagaimana jika atributnya bernilai kontinyu? Bagaimana

5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 11/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
menangani sampel data yang atributnya bernilai kosong? Dan bagaimana menangani atribut-
atribut yang memiliki biaya berbeda?
5.1.4.1 Berapa ukuran pohon keputusan yang tepat ?Pada algoritma ID3, pertumbuhan cabang-cabang pohon keputusan dilakukan sampai
pohon keputusan tersebut mampu mengklasifikasikan sampel data secara akurat dengan
tingkat kebenaran 100 %. Tetapi, pada permasalahan dunia nyata, mungkin saja terdapat
sampel-sampel data yang salah (noise), sehingga ID3 dapat menghasilkan pohon keputusan
yang overfit terhadap sampel data. Pohon keputusan yang overfit atau ‘terlalu ngepres
(sempit)’ bisa diartikan sebagai pohon keputusan yang akurat untuk sebagian besar data latih,
sedangkan untuk sampel-sampel data uji yang belum pernah dipelajari (unseen data), pohon
keputusan tersebut banyak mengalami kegagalan dalam mengklasifikasikannya.
Bagaimana ID3 bisa menghasilkan pohon keputusan yang overfit? Untuk
mengilustrasikan hal ini, misalkan data ‘Penerimaan Pegawai’ pada tabel 5-1 kita ubah
sehingga atribut Wawancara memiliki 4 nilai: Sangat Baik, Baik, Buruk, dan Sangat Buruk.
Sehingga jumlah kemungkinan sampel data adalah 3 x 3 x 4 = 36.
Tabel 5-3: Empat belas sampel data sebagai Training Set
Pelamar IPK Psikologi Wawancara Diterima
G1 Bagus Tinggi Sangar Baik Ya
G2 Bagus Tinggi Sangat Buruk Ya
G3 Bagus Sedang Buruk Ya
G4 Bagus Rendah Buruk Tidak
G5 Cukup Tinggi Sangat Baik Ya
G6 Cukup Sedang Buruk Ya
G7 Cukup Sedang Sangat Buruk Ya
G8 Cukup Rendah Baik Ya
G9 Cukup Rendah Buruk Tidak
G10 Kurang Tinggi Sangat Baik Ya
G11 Kurang Tinggi Sangat Buruk Tidak
G12 Kurang Sedang Sangat Baik Tidak
G13 Kurang Sedang Baik Tidak
G14 Kurang Rendah Sangat Buruk Tidak
Reduced Error Pruning (REP)
Sebelum proses pembangunan pohon keputusan dan proses pruning, sampel data yang
ada dibagi menjadi tiga bagian :
1. Training set
2. Validation set

5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 12/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
3. Test set
REP berusaha memangkas simpul-simpul pada pohon keputusan sehingga bisa
menurunkan error pada validation set. Ide dasar dari REP afalah mengevaluasi setiap simpul
pada pohon keputusan untuk kemudian dipilih simpul yang bisa dipangkas.
Rule Post-Pruning (RPP)
1. Dengan menggunakan sampel-sampel data pada training set, bangun pohon keputusan
yang paling sesuai. Biarkan overfitting terjadi
2. Ubah pohon keputusan yang dihasilkan menjadi sekumpulan aturan, dimana satu
aturan merepresentasikan satu jalur pohon dari simpul akar sampai simpul daun.
3. Pangkas setiap aturan dengan cara menghilangkan setiap prekondisi yang membuat
akurasi perkiraan dari aturan tersebut menjadi lebih baik.
4. Urutkan aturan-aturan hasil pemangkasan berdasarkan akurasi perkiraannya. Pilih
aturan-aturan hasil pemangkasan berdasarkan urutan tersebut.
5.1.4.2 Bagaimana jika atributnya bernilai kontinyu ?
Cara paling mudah untuk menyelesaikan kasus adalah mengubah nilai-nilai kontinyu
menjadi nilai-nilai diskrit dengan cara mempartisi nilai kontinyu ke dalam interval-interval
bernilai diskrit. Oleh karena itu, kita harus mengubah nilai – nilai kontinyu menjadi nilai-nilai
diskrit misalkan , 11 nilai kontinyu kita ubah menjadi 3 nilai diskrit berbeda dengan interval :
‘Bagus’ = [3,00; 4,00], ‘Cukup’ = [2,75;3,00), dan ‘Kurang’ = [0,00; 2,75).
5.1.4.3 Selain informasi gain, adakah ukuran pemilihan atribut yang lain ?
Informasi gain akan mengalami masalah ketika ada atribut yang memiliki nilai sangat
bervariasi. Sebagai contoh, perhatikan tabel 5-6 di bawah ini. Pada kasus tersebut, atribut
Kelahiran memiliki nilai yang bervarisi. Dari 11 sampel data, atribut Kelahiran memiliki 11
nilai berbeda sehingga entropy untuk masing-masing nilai tersebut adalah 0 (nol). Oleh karena
itu, information gain untuk IPK adalah sama dengan Gains(S,IPK) = Entropy(S) – 0 =
Entropy(S). Dalam hal ini, Entropy (S) adalah entropy untuk 11 data tersebut berdasarkan
keputusan, Diterima = ‘Ya’ atau ‘Tidak’, yaitu :
Entropy(S) = -(8/11)log2(8/11)-(3/11)log2(3/11)
= 0,8454
5.1.4.4 Bagaimana menangani sampel data yang atributnya bernilai kosong ?
Suatu strategi paling mudah yang biasa digunakan adalah dengan memberikan nilai
yang paling sering muncul. Cara lainnya yang agak rumit adalah dengan memberikan suatu
probabilitas pada setiap nilai.
5.1.4.5 Bagaimana menangani atribut-atribut yang memiliki biaya berbeda ?

5/14/2018 Bab v Learning (Tugas Ai Lamris Pandiangan 03081004080) - slidepdf.com
http://slidepdf.com/reader/full/bab-v-learning-tugas-ai-lamris-pandiangan-03081004080 13/13
BAB V
NAMA : LAMRIS PANDIANGAN
NIM : 03081004080
Terkadang kita menghadapi masalah dimana masing-masing atribut memiliki biaya
yang berbeda-beda untuk mendapatkannya. Pada data penerimaan pegawai, misalkan biaya
melaksanakan tes Psikologi empat kali lebih mahal dibandingkan biaya tes wawancara.