2.1. data mining - bina nusantara | library &...
TRANSCRIPT

3
BAB II DASAR TEORI
2.1. Data mining
Data mining adalah teknik menganalisis data dan menemukan pola-pola tersembunyi baik secara
otomatis maupun semi-otomatis. Saat ini database mengumpulkan dan menyimpan data dalam
jumlah yang sangat besar. Data ini berasal dari berbagai aplikasi bisnis seperti core banking,
kredit sistem, Customer Information System, Human Resourse Sistem yang saling terintegrasi.
Hasil pengumpulan data ini adalah bahwa organisasi telah menjadi kaya akan data namun
knowledge yang dapat didapatkan sedikit. Pengumpulan data telah menjadi begitu luas dan
meningkat begitu cepat dalam ukuran yang besar.
Tujuan utama dari data mining adalah untuk mengekstrak pola dari data pada database,
meningkatkan nilai intrinsik kemudian mentransfer data untuk menghasilkan knowledge. Data
mining banyak memberikan nilai bisnis bagi perusahaan.
Berikut beberapa alasan data mining menjadi penting saat ini:
• Data yang tersedia sangat besar:
Selama dekade terakhir, harga hardware, terutama hard disk, telah menurun
drastis. Bersama dengan ini, perusahaan telah menyimpan data yang sangat besar melalui
banyak aplikasi. Dengan semua data ini untuk mengeksplorasi, perusahaan menginginkan
dapat menemukan pola dan informasi yang tersembunyi sehingga dapat membantu
mengarahkan strategi bisnis perusahaan manjadi lebih baik.

4
• Meningkatkan kompetisi:
Kompetisi yang tinggi sebagai dampak dari modernisasi pasar dan distribusi seperti
Internet dan telekomunikasi. Perusahaan-perusahaan di seluruh dunia menghadapi
persaingan, dan kunci untuk keberhasilan bisnis adalah kemampuan untuk
mempertahankan pelanggan dan memperoleh pelanggan baru. Data mining adalah
teknologi yang memungkinkan perusahaan untuk menganalisis faktor-faktor yang
mempengaruhi masalah ini.
• Technology yang telah siap:
Teknologi Data mining yang sebelumnya hanya ada dalam wilayah akademis, tapi
sekarang banyak dari teknologi tersebut telah matang dan siap diterapkan dalam
industri. Algoritma yang lebih akurat,lebih efisien dan dapat menangani data yang
semakin rumit. Selain itu pemrograman aplikasi antarmuka data mining (API) telah
distandarisasi, yang akan memungkinkan para pengembang untuk membangun aplikasi
data mining yang lebih baik. Data mining dapat digunakan untuk memecahkan ratusan
masalah bisnis.
Berdasarkan sifat masalah kita dapat mengelompokkan teknik – teknik data mining menjadi:
• Klasifikasi
Klasifikasi adalah salah satu pekerjaan yang paling populer dalam data mining. Masalah
bisnis seperti analisis acak, manajemen risiko dan penargetan iklan yang biasanya
melibatkan klasifikasi. Klasifikasi mengacu pada kasus ke kategori berdasarkan prediksi
atribut. Setiap kasus berisi satu set atribut, salah satunya adalah atribut kelas (prediksi
atribut). Proses memerlukan menemukan sebuah model yang menggambarkan atribut

5
kelas sebagai fungsi masukan atribut. Dalam Rencana College Dataset sebelumnya
dijelaskan, kelas adalah Rencana College atribut dengan dua bagian: Ya dan No. Untuk
melatih model klasifikasi, perlu mengetahui nilai kelas dari masukan kasus kedalam
pelatihan Dataset, yang biasanya adalah data historis. Algoritma Data mining
membutuhkan target untuk belajar berbeda dengan algoritma supervised. Beberapa
algoritma klasifikasi adalah decision trees, neural network, and Naïve Bayes.
• Clustering
Clustering juga disebut segementasi. Hal ini digunakan untuk mengidentifikasi kelompok
secara umum yang didasarkan pada seperangkat atribut
Gambar 1.3 menampilkan dataset pelanggan sederhana yang mengandung dua atribut:
usia dan pendapatan. Para kelompok-kelompok algoritma clustering yang Dataset
menjadi tiga segmen didasarkan pada kedua atribut.
Cluster 1 berisi populasi yang lebih muda dengan pendapatan rendah.
Cluster 2 berisi setengah baya pelanggan dengan pendapatan yang lebih tinggi.
Cluster 3 adalah kelompok individu senior dengan pendapatan yang relatif rendah.
Clustering adalah proses unsupervised data mining. Tidak ada satu atribut yang
digunakan untuk memandu proses pelatihan. Semua masukan atribut diperlakukan
sama. Kebanyakan algoritma Clustering membangun model melalui sejumlah iterasi dan
berhenti ketika model terpenuhi, yakni ketika batas-batas segmen telah stabil.

6
Umur
penghasilan
cluster 1
cluster 3
cluster 2
Clustering
Gambar 2.1. Clustering
• Asosiasi
Asosiasi adalah proses populer lain dari data mining. Asosiasi ini juga disebut analisis
keranjang pasar (market basket analysis). Jenis problem bisnis dari asosiasi adalah untuk
menganalisis suatu tebel transaksi penjualan dan mengidentifikasi produk-produk mana
yang sering terjual besamaan pada saat perbelanjaan. Penggunaan yang umum asosiasi
adalah untuk mengidentifikasi set item yang umum dan aturan untuk tujuan cross-
selling.
Dalam hal asosiasi, setiap produk, atau lebih umum, setiap atribut / nilai pasangan
dianggap item. Tugas asosiasi memiliki dua tujuan: untuk mencari sering itemsets yang
sering muncul dan untuk mencari aturan asosiasi.

7
Kebanyakan jenis algoritma asosiasi menemukan itemsets yang sering dengan
memindai (scanning). Dataset beberapa kali. Frekuensi ambang batas (dukungan)
didefinisikan oleh pengguna sebelum memproses model. Sebagai contoh, support = 2%
berarti bahwa model menganalisa hanya item yang muncul sekurang-kurangnya 2% dari
shopping cart. Afrequent itemset mungkin terlihat seperti (Product = "Pepsi", Product =
"Chips", Product = "Juice"). Masing-masing memiliki jumlah itemset, yang merupakan
jumlah item yang dikandungnya.Jumlah itemset dalam hal ini adalah 3.
Selain mengidentifikasi itemsets yang sering (frequent itemsets) berdasarkan support,
sebagian besar jenis algoritma asosiasi juga menemukan aturan. Aturan asosiasi
mempunyai bentuk A, B => C dengan probabilitas, di mana A, B, C adalah semua item
set yang sering. Probabilitas ini juga disebut sebagai confidence dalam literatur data
mining. Probabilitas adalah ambang nilai (threshold) bahwa kebutuhan pengguna untuk
menentukan sebelum pelatihan sebuah model asosiasi. Sebagai contoh, berikut ini adalah
aturan khas: Product = "Pepsi", Product = "Chip" => Product = "Juice" dengan
probabilitas 80%. Penafsiran aturan ini sangatlah mudah. Jika seorang pelanggan
membeli Pepsi dan keripik, ada 80% kesempatan bahwa ia mungkin juga membeli
jus. Gambar 1.4 menampilkan pola produk asosiasi . Setiap simpul dalam gambar
mewakili suatu produk, masing-masing tepi mewakili hubungan. Arah tepi mewakili
arah prediksi. Sebagai contoh, tepi dari Susu ke Keju menunjukkan bahwa mereka
yang membeli susu mungkin juga membeli keju.

8
2.2. Siklus Proyek Data Mining
Berikut siklus data mining. langkah-langkah apa yang menantang, siapa saja yang harus terlibat
dalam proyek data mining akan dijelaskan setiap langkah nya sebagai berikut
Step 1: Data Collection
Langkah pertama dalam data mining biasanya pengumpulan data (data collection). Data Bisnis
disimpan dalam banyak sistem dalam perusahaan. Sebagai contoh, ada ratusan OLTP database
dan lebih dari 70 gudang data (datawarehouse) di dalam Microsoft. Langkah pertama adalah
untuk menarik data yang relevan ke suatu database atau data mart di mana analisis data
diterapkan. Sebagai contoh, jika ingin menganalisis aliran klik Web dan perusahaan memiliki
selusin Web server, langkah pertama adalah men-download Web log data dari masing-masing
web server.
Kadang-kadang mungkin akan beruntung. Gudang data dari subjek yang akan dianalisis sudah
ada. Namun, data dalam gudang data tidak cukup kaya. Kita masih perlu untuk mengumpulkan
data dari sumber lain. Anggaplah bahwa ada gudang data klik yang berisi semua klik dari Situs
web perusahaan. Anda memiliki informasi dasar tentang pola navigasi pelanggan. Namun,
karena tidak banyak informasi demografis tentang pengunjung web Anda, Anda mungkin perlu
untuk membeli atau mengumpulkan beberapa demografis data dari sumber lain dalam rangka
membangun model yang lebih akurat. Setelah data yang dikumpulkan, Anda dapat mengambil
sampel data untuk mengurangi volume Dataset pelatihan. Dalam banyak kasus, pola-pola yang
terkandung dalam 50.000 pelanggan adalah sama seperti dalam 1 juta pelanggan.

9
Step 2: Data Cleaning and Transformation
Pembersihan dan transformasi data adalah langkah dalam data mining yang paling memerlukan
sumber daya yang intensif. Tujuan dari pembersihan data adalah untuk menghilangkan noise dan
informasi yang tidak relevan dari Dataset. Tujuan transformasi data adalah untuk memodifikasi
sumber data ke format yang berbeda dalam hal jenis dan nilai data.
Ada berbagai teknik yang dapat diterapkan untuk pembersihan dan transformasi data,termasuk:
• Transformasi tipe data: Ini adalah transformasi data yang paling sederhana. Contohnya
mengubah tipe kolom yang Boolean ke tipe integer. Alasan untuk mengubah ini adalah
bahwa beberapa algoritma data mining berperforma lebih baik pada integer data,
sementara yang lain lebih baik pada data Boolean.
• Continuous kolom transform: Untuk data kontinu seperti pendapatan dan umur, yang
khas adalah membagi data. Sebagai contoh, Anda mungkin ingin membagi Usia ke lima
kelompok standar usia kelompok. Selain dari pembagian data , teknik normalisasi
populer untuk mengubah data kontinu. Normalisasi memetakan semua numerik nilai ke
angka antara 0 dan 1 (atau -1 untuk 1) untuk memastikan bahwa besar angka tidak
mendominasi nomor yang lebih kecil selama analisis.
• Pengelompokan: Kadang-kadang terdapat terlalu banyak nilai-nilai yang berbeda untuk
diskrit kolom. Diperlukan kelompok nilai-nilai ini ke dalam beberapa kelompok untuk
mengurangi kompleksitas model. Sebagai contoh, kolom Profesi mungkin memiliki
puluhan nilai-nilai yang berbeda seperti Software Engineer, Telecom Engineer,
Mechanical Engineer, Konsultan, dan seterusnya. Anda dapat mengelompokkan berbagai
profesi engineering dengan menggunakan nilai tunggal: Engineer. Pengelompokan juga

10
membuat model lebih mudah untuk menafsirkannya.
• Agregasi: Agregasi adalah transformasi penting lain. Misalkan bahwa ada tabel yang
berisi detail catatan panggilan telepon (CDR) untuk setiap pelanggan, dan tujuan Anda
adalah melakukan segmen pelanggan berdasarkan penggunaan telepon bulanan. Karena
informasi CDR terlalu rinci untuk model, Anda perlu untuk menggabungkan semua
panggilan ke beberapa atribut yang diturunkan seperti jumlah panggilan dan rata-rata
lama panggilan. Atribut yang diturunkan ini di kemudian hari dapat digunakan dalam
model.
Penanganan Nilai yang hilang: Hampir semua dataset mengandung nilai-nilai yang hilang. Ada
sejumlah penyebab data hilang. Sebagai contoh, Anda mungkin memiliki dua tabel pelanggan
yang berasal dari dua OLTP database. Penggabungan tabel ini dapat menghasilkan nilai-nilai
yang hilang, karena definisi tabel tidak tepat sama. Dalam contoh lain, tabel demografis
pelanggan Anda mungkin memiliki kolom untuk usia. Tetapi pelanggan tidak selalu seperti
untuk memberikan informasi ini selama pendaftaran. Anda mungkin memiliki tabel penutupan
harian nilai untuk saham MSFT. Karena pasar saham ditutup pada akhir pekan,akan ada nilai
null untuk tanggal tersebut dalam tabel. Addressing hilang nilai-nilai adalah masalah
penting. Ada beberapa cara untuk menangani masalah ini. Anda dapat mengganti nilai yang
hilang dengan yang paling popular nilai (konstan). Jika Anda tidak tahu usia pelanggan, Anda
dapat menggantinya dengan usia rata-rata dari semua pelanggan. Ketika record memiliki terlalu
banyak nilai hilang, Anda dapat dengan mudah menghapusnya. Untuk kasus yang lebih lanjut,
Anda dapat membangun model data mining yang menggunakan kasus yang lengkap, dan

11
kemudian menerapkan model untuk memprediksi nilai yang paling mungkin untuk setiap kasus
hilang.
Menghapus outliers: Outliers adalah kasus abnormal dalam dataset. Kasus Abnormal yang
mempengaruhi kualitas sebuah model. Sebagai contoh, anggaplah bahwa Anda ingin
membangun model segmentasi pelanggan berdasarkan penggunaan pelanggan telepon (durasi
rata-rata, total jumlah panggilan, faktur bulanan, panggilan internasional, dan sebagainya) Ada
beberapa pelanggan (0,5%) yang berperilaku sangat berbeda.Beberapa dari pelanggan ini hidup
di atas kapal dan menggunakan roaming. Sepanjang jika kita termasuk kasus yang abnormal
dalam model, Anda mungkin berakhir dengan menciptakan sebuah model dengan mayoritas
pelanggan dalam satu segmen dan beberapa lainnya yang sangat kecil yang hanya berisi segmen
outliers tersebut. Cara terbaik untuk mengatasi adalah menghapus outliers sebelum analisis.
Anda dapat menghapus outliers didasarkan pada atribut individu untuk Misalnya, menghapus
0,5% pelanggan dengan pendapatan tertinggi atau terendah. Kamu dapat menghapus outliers
berdasarkan himpunan atribut. Dalam kasus ini, Anda dapat menggunakan algoritma
clustering. Banyak algoritma clustering, termasuk Microsoft Clustering, outliers kelompok
menjadi beberapa kelompok tertentu. Ada banyak data lain-pembersihan dan transformasi teknik,
dan ada banyak utilitas yang tersedia di pasar. SQL Server Integration Services (SSIS)
menyediakan satu set transformasi yang meliputi sebagian besar tugas-tugas yang tercantum di
sini.

12
Step 3: Model Building
Setelah data dibersihkan dan variabel telah di transformasikan, kita dapat mulai membangun
model. Sebelum membangun suatu model, kita perlu memahami tujuan proyek pertambangan
data dan jenis data tugas pertambangan. Apakah proyek ini klasifikasi tugas, tugas asosiasi atau
tugas segmentasi? Pada tahap ini, kita perlu untuk bekerjasama dengan analis bisnis dengan
domain pengetahuan. Misalnya jika kita menambang telekomunikasi data, kita harus
bekerjasama dengan orang-orang pemasaran yang memahami bisnis telekomunikasi.
Membangun Model adalah inti dari data mining, meskipun tidak memerlukan banyak waktu dan
sumber daya-intensif sebagai mana transformasi data. Sekali setelah memahami jenis pekerjaan
data mining, akan relatif mudah untuk memilih algoritma yang tepat. Untuk setiap pekerjaan data
mining, ada beberapa algoritma yang cocok. Dalam banyak kasus, Anda tidak akan tahu
algoritma mana yang paling cocok untuk data sebelum model pelatihan. Akurasi dari algoritma
tergantung pada sifat dari data seperti jumlah bagian dari atribut yang dapat diprediksi, distribusi
nilai setiap atribut, hubungan antara atribut, dan seterusnya. Sebagai contoh, jika hubungan di
antara semua masukan atribut dan atribut yang diprediksi linier, algoritma decision tree akan
menjadi pilihan yang sangat baik. Jika hubungan antara atribut lebih rumit, maka algoritma
jaringan saraf harus dipertimbangkan.Pendekatan yang benar adalah untuk membangun beberapa
model yang menggunakan algoritma yang berbeda dan kemudian membandingkan keakuratan
model ini menggunakan beberapa alat, seperti chart yang digambarkan pada langkah
berikutnya. Bahkan untuk algoritma yang sama, Anda mungkin perlu untuk membangun

13
berbagai model yang menggunakan pengaturan parameter yang berbeda dalam rangka
menyempurnakan akurasi model.
Step 4: Model Assessment
Dalam membangun sebuah model, kita membangun serangkaian model yang menggunakan
algoritma yang berbeda dan pengaturan parameter. Jadi apa model yang terbaik dalam hal
keakuratan? Bagaimana Anda mengevaluasi model ini? Ada beberapa tool yang terkenal untuk
mengevaluasi ualitas model. Yang paling terkenal adalah lift chart. menggunakan model yang
dilatih untuk memprediksi nilai-nilai pengujian Dataset. Berdasarkan perkiraan nilai dan
probabilitas, itu menampilkan model grafis dalam tabel.
Dalam tahap penilaian model, anda tidak hanya menggunakan alat-alat untuk
mengevaluasi akurasi model tetapi Anda juga perlu membicarakan arti dari pola yang ditemukan
dengan analis bisnis. Sebagai contoh, jika Anda membangun sebuah model asosiasi di dataset,
Anda mungkin menemukan aturan seperti Hubungan = Suami => Gender = Laki-laki dengan
100% confidence. Meskipun aturan ini berlaku, itu tidak mengandung nilai bisnis. Hal ini sangat
penting untuk bekerja dengan analis bisnis yang memiliki domain pengetahuan yang tepat untuk
memvalidasi penemuan.Kadang-kadang model tidak berisi pola berguna. Hal ini mungkin terjadi
karena beberapa alasan. Salah satunya adalah bahwa data benar-benar acak. Walaupun
mungkin memiliki data acak, dalam banyak kasus, dataset nyata memang mengandung informasi
yang kaya. Alasan kedua, yang lebih mungkin, adalah bahwa himpunan variabel dalam model
bukan yang terbaik untuk digunakan. Anda mungkin perlu mengulang data-pembersihan
dan langkah transformasi dalam rangka untuk memperoleh variabel yang lebih berarti. Data

14
mining adalah proses siklus; biasanya memerlukan beberapa iterasi untuk menemukan model
yang tepat.
Step 5: Reporting
Pelaporan adalah delivery channel yang penting untuk penemuan dalam data mining. Dalam
banyak organisasi, tujuan data mining adalah memberikan laporan kepada eksekutif
pemasaran. Kebanyakan alat data mining memiliki fitur pelaporan yang memungkinkan
pengguna untuk menghasilkan laporan standar dari mining model dengan output teks atau grafik.
Ada dua jenis laporan: laporan tentang temuan (pola) dan laporan tentang prediksi atau ramalan.
Step 6: Prediction (Scoring)
Dalam banyak proyek-data mining, menemukan pola hanya setengah dari pekerjaan. Tujuannya
final adalah untuk menggunakan model ini untuk prediksi. Prediksi ini juga disebut penilaian
(scoring) dalam terminology data mining. Untuk memberikan prediksi, kita perlu memiliki
model yang terlatih dan satu set kasus baru. Pertimbangkan skenario perbankan di mana Anda
telah membangun sebuah model tentang evaluasi risiko pinjaman. Setiap hari ada ribuan
pinjaman baru aplikasi. Anda dapat menggunakan model evaluasi risiko untuk memperkirakan
potensi risiko untuk masing-masing aplikasi pinjaman.
Step 7: Application Integration
Embedding data mining ke dalam aplikasi bisnis adalah tentang menerapkan kecerdasan ke
bisnis, yaitu menutup analisis menjadi siklus. Menurut Gartner Penelitian, dalam beberapa tahun

15
ke depan, semakin banyak aplikasi bisnis akan embed data mining komponen sebagai nilai
tambah. Sebagai contoh, aplikasi CRM mungkin memiliki fitur data mining kelompok pelanggan
menjadi beberapa segmen. ERP aplikasi mungkin memiliki fitur data mining untuk meramalkan
produksi. toko buku online pelanggan dapat memberikan real-time rekomendasi buku.
Mengintegrasikan fitur data mining, khususnya real-time komponen prediksi ke dalam aplikasi
merupakan salah satu langkah penting dalam proyek data mining. Ini langkah kunci untuk
membawa data mining ke dalam penggunaan massal.
Step 8: Model Management
Merupakan tantangan untuk mempertahankan status model data mining. Setiap model data
mining memiliki siklus. Dalam beberapa bisnis, pola yang relatif stabil dan model sering tidak
memerlukan pelatihan ulang. Tetapi dalam banyak pola bisnis sering bervariasi. Sebagai contoh,
di toko buku online, buku-buku baru muncul setiap hari. Ini berarti bahwa aturan asosiasi baru
muncul setiap hari. Durasi model data mining terbatas. Versi baru dari model sering harus
diciptakan. Akhirnya menentukan akurasi model dan menciptakan versi baru. Model harus
dicapai dengan menggunakan proses otomatis. Seperti setiap data, data mining model juga
memiliki masalah keamanan. Data mining Model mengandung pola. Banyak dari pola ini adalah
ringkasan dari data yang sensitif. Kita perlu untuk mempertahankan membaca, menulis, dan hak
prediksi untuk profil pengguna yang berbeda.Data mining Model harus diperlakukan sebagai
warga negara kelas pertama dalam database dimana administrator dapat menetapkan dan
mencabut hak akses pengguna model ini.
Berikut ini adalah beberapa bidang atau area dimana data mining dapat berperan:
• Menghasilkan rekomendasi

16
Seperti pada kasus amazon.com, data mining digunakan untuk menghasilkan
rekomendasi mengenai produk – produk kepada customer yang sedang membeli
barang.Data tersebut dihasilkan dari analisa terhadap perilaku pembelian customer -
customernya
• Pendeteksian anomaly
Data mining dapat diterapkan untuk mendeteksi adanya anomaly transaksi pada
perusahaan credit card, sehingga dapat mengurangi tingkat penyalahgunaan kartu kredit
dari customernya
• Manajemen resiko
Teknik data mining dapat membantu bank dalam membuat suatu keputusan apakah
permintaan kredit yang diajukan nasabah dapat diterima atau tidak.
• Segementasi customer
Dengan data mining kita dapat menganalisa mengenai perilaku dan profil dari customer
perusahaan, sehingga dapat dihasilkan kelompok – kelompok customer kita berdasarkan
profil tersebut, dimana pengelompokkan ini akan membantu marketing dalam
melancarkan strategi marketing yang tepat sesuai dengan kelompok – kelompok tersebut
2.3. Neural Network
Hecht-Nielsend (1988) mendefinisikan Artificial Neural Network (ANN), atau
diterjemahkan menjadi jaringan saraf tiruan, adalah suatu struktur pemroses informasi yang
terdistribusi dan bekerja secara paralel, yang terdiri atas elemen pemroses (yang memiliki
memori lokal dan beroperasi dengan informasi lokal) yang diinterkoneksi bersama dengan alur
sinyal searah yang disebut koneksi. Setiap elemen pemroses memiliki koneksi keluaran tunggal
yang bercabang (fan out) ke sejumlah koneksi kolateral yang diinginkan (setiap koneksi

17
membawa sinyal yang sama dari keluaran elemen pemroses tersebut). Keluaran dari elemen
pemroses tersebut dapat merupakan sebarang jenis persamaan matematis yang diinginkan.
Seluruh proses yang berlangsung pada setiap elemen pemroses harus benar-benar dilakukan
secara lokal, yaitu keluaran hanya bergantung pada nilai masukan pada saat itu yang diperoleh
melalui koneksi dan nilai yang tersimpan dalam memori lokal. Sebuah ANN adalah sebuah
prosesor yang terdistribusi paralel dan mempuyai kecenderungan untuk menyimpan pengetahuan
yang didapatkannya dari pengalaman dan membuatnya tetap tersedia untuk digunakan (Haykins,
1994).
Tidak ada dua otak manusia yang sama, setiap otak selalu berbeda. Beda dalam
ketajaman, ukuran, dan pengorganisasiannya. Salah satu cara untuk memahami bagaimana otak
bekerja adalah dengan mengumpulkan informasi dari sebanyak mungkin scan otak manusia dan
membuatnya menjadi suatu peta. Hal tersebut merupakan upaya untuk menemukan cara kerja
otak manusia. Peta otak manusia diharapkan dapat menjelaskan misteri mengenai bagaimana
otak mengendalikan setiap tindakan manusia, mulai dari penggunaan bahasa hingga gerakan.
Walaupun demikian kepastian cara kerja otak manusia masih merupakan suatu misteri. Berikut
adalah aspek-aspek yang hingga saat ini telah berhasil ditemukan dalam otak manusia.
a. Tiap bagian pada otak manusia memiliki alamat, dalam bentuk formula kimia, dan
sistem saraf manusia berusaha untuk mendapatkan alamat yang cocok untuk setiap
akson (saraf penghubung) yang dibentuk.
b. Melalui pembelajaran, pengalaman dan interaksi antara sistem maka struktur dari
otak itu sendiri akan mengatur fungsi-fungsi dari setiap bagiannya.
c. Axon-axon pada daerah yang berdekatan akan berkembang dan mempunyai bentuk
fisik mirip, sehingga terkelompok dengan arsitektur tertentu pada otak.

18
d. Axon berdasarkan arsitekturnya bertumbuh dalam urutan waktu, dan terhubung pada
struktur otak yang berkembang dengan urutan waktu yang sama.
e. Berdasarkan keempat aspek tersebut di atas dapat ditarik suatu kesimpulan bahwa
otak tidak seluruhnya terbentuk oleh proses genetis. Terdapat proses lain yang ikut
membentuk fungsi dari bagian-bagian otak, yang pada akhirnya menentukan
bagaimana suatu informasi diproses oleh otak.
Elemen yang paling mendasar dari jaringan saraf adalah sel saraf. Sel-sel saraf inilah
membentuk bagian kesadaran manusia yang meliputi beberapa kemampuan umum. Pada
dasarnya sel saraf biologi menerima input dari sumber yang lain dan mengkombinasikannya
dengan beberapa cara, melaksanakan suatu operasi yang non-linear untuk mendapatkan hasil dan
kemudian mengeluarkan outputnya.
Dalam tubuh manusia terdapat banyak variasi tipe dasar sel saraf, sehingga proses
berpikir manusia menjadi sulit untuk direplikasi secara elektrik. Sekalipun demikian, semua sel
saraf alami mempunyai empat komponen dasar yang sama. Keempat komponen dasar ini dikenal
berdasarkan nama biologinya yaitu dendrit, soma, akson, dan sinapsis.
Gambar 2.2. Saraf yang disederhanakan

19
Dendrit merupakan suatu perluasan dari soma yang menyerupai rambut dan bertindak sebagai
saluran input. Dendrit menerima rangsangan berupa sinyal elektrokimiawi dari sel saraf lainnya.
Soma dalam hal ini kemudian memproses input menjadi sebuah output berupa sinyal yang
kemudian dikirim ke sel saraf lainnya melalui akson lalu kemudian sinapsis. Konsep dasar
semacam inilah yang ingin dicoba para ahli dalam menciptakan ANN.
Penelitian terbaru memberikan bukti lebih lanjut bahwa sel saraf biologi mempunyai
struktur yang lebih kompleks dan lebih canggih daripada sel saraf buatan. Ilmu biologi
menyediakan suatu pemahaman yang lebih baik tentang sel saraf sehingga memberikan
keuntungan kepada para perancang jaringan untuk dapat terus meningkatkan sistem ANN yang
ada berdasarkan pada pemahaman terhadap otak biologi.
Implementasi Sel Saraf
Implementasi ANN dapat dilakukan dengan berbagai cara yang berbeda. Sebelum
melihat ANN sebagai satu kesatuan jaringan, konsep mengenai sel saraf buatan harus terlebih
dahulu dipahami. Langkah pertama yang harus dilakukan adalah memberikan definisi terhadap
sel saraf yang terdapat dalam suatu ANN. Definisi matematika yang paling umum untuk
menggambarkan hal ini dapat dilihat pada (2.1).
(2.1)
Dimana:
x = sel saraf yang dijadikan obyek perhitungan.
x0, x1, x2, ... xi = nilai sinyal yang diterima dari sel saraf input i.
w0, w1, w2, ... wi = nilai beban yang menyatakan besarnya pengaruh input i.

20
y(x) = output kepada sel saraf selanjutnya.
g(x) = fungsi aktivasi, menyatakan seberapa besar output yang dihasilkan.
Dalam sel saraf sebenarnya, fungsi aktivasi g seharusnya hanyalah suatu threshold sederhana
yang mengembalikan nilai 0 atau 1. Dalam implementasinya, fungsi aktivasi g bernilai antara 0
sampai 1 atau -1 sampai 1 tergantung pada fungsi aktivasi yang digunakan. Sedangkan nilai
input dan beban boleh saja berupa bilangan riil, walau pun seringkali digunakan nilai-nilai kecil
yang mendekati 0.
Gambar 2.3. Contoh sel saraf buatan
Berikut ini adalah beberapa jenis fungsi aktivasi yang dapat digunakan.
(2.2)
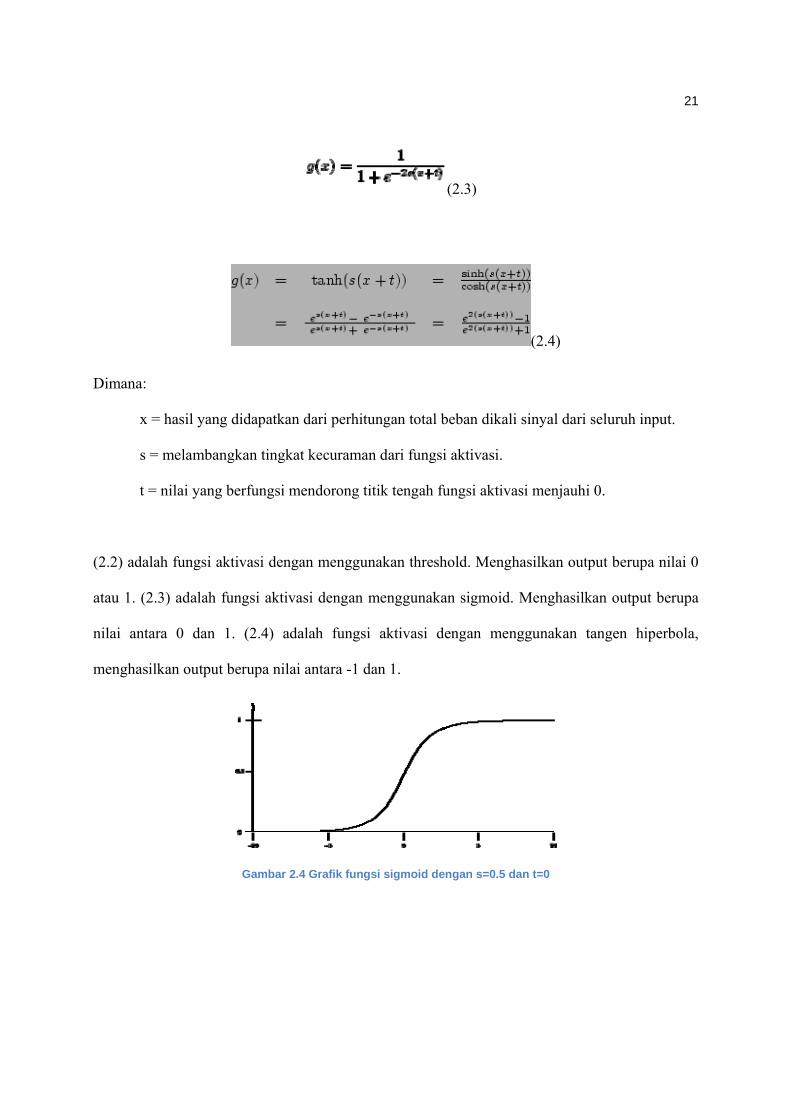
21
(2.3)
(2.4)
Dimana:
x = hasil yang didapatkan dari perhitungan total beban dikali sinyal dari seluruh input.
s = melambangkan tingkat kecuraman dari fungsi aktivasi.
t = nilai yang berfungsi mendorong titik tengah fungsi aktivasi menjauhi 0.
(2.2) adalah fungsi aktivasi dengan menggunakan threshold. Menghasilkan output berupa nilai 0
atau 1. (2.3) adalah fungsi aktivasi dengan menggunakan sigmoid. Menghasilkan output berupa
nilai antara 0 dan 1. (2.4) adalah fungsi aktivasi dengan menggunakan tangen hiperbola,
menghasilkan output berupa nilai antara -1 dan 1.
Gambar 2.4 Grafik fungsi sigmoid dengan s=0.5 dan t=0

22
Parameter t dapat dipandang sebagai nilai sinyal yang dibutuhkan untuk melakukan aktivasi
terhadap sel saraf. Parameter t dan beban merupakan parameter yang disesuaikan nilainya pada
saat pembelajaran.
Implementasi ANN
Jenis ANN yang paling dikenal adalah ANN multilayer feedforward. Sel-sel saraf
diurutkan berdasarkan pada layer-layer, diawali oleh layer input dan diakhiri dengan layer output
sedangkan di antaranya terdapat layer hidden. Hubungan dalam ANN jenis ini terjadi hanya satu
arah, dari layer input ke layer hidden pertama lalu ke layer hidden kedua dan seterusnya. Jenis
ANN ini bukan merupakan satu-satunya, namun jenis ANN ini adalah yang paling mudah untuk
dipelajari.
input layer hidden layer output layer
ANN Feedforward satu hidden layer
Gambar 2.5. ANN feedforward dengan satu layer hidden

23
Fase pada ANN feedfoforward terbagi atas dua, yaitu fase pembelajaran dan fase
eksekusi. Pada fase pembelajaran, ANN feedforward dilatih dengan menggunakan konsep
supervised learning, dimana nilai dari beban-beban yang terdapat pada setiap sel saraf
disesuaikan untuk dapat melakukan klasifikasi. Pada tahap klasifikasi, nilai input diberikan
kepada layer input untuk kemudian dipropagasikan ke layer output untuk mendapatkan hasil
akhirnya.
Seperti yang telah disebutkan sebelumnya bahwa parameter t dan beban akan mengalami
penyesuaian selama masa pembelajaran untuk memberikan hasil yang sesuai. Namun, untuk
menghitung parameter t tersebut akan dibutuhkan rumus tambahan yang mempersulit
perhitungan. Karenanya, untuk menyederhanakan perhitungan, hanyalah nilai beban yang
disesuaikan, sedangkan nilai t diganti dengan satu sel saraf yang disebut sebagai sel saraf bias
pada setiap layer. Sel saraf bias ini selalu memiliki nilai sinyal sebelum dikalikan dengan beban
sama dengan 1. (2.5) adalah rumus matematika sel saraf yang telah dimodifikasi setelah
ditambahkannya sel saraf bias.
(2.5)
Menambahkan sel saraf bias menyebabkan tidak diperlukannya lagi parameter t dalam fungsi
aktivasi. (2.6) adalah bentuk fungsi aktivasi sigmoid setelah parameter t dibuang.
(2.6)

24
input layer hidden layer output layer
biasbias
ANN Feedforward
Gambar 2.6. ANN Feedforward dengan menggunakan sel saraf bias
Pembelajaran ANN
Pada saat pembelajaran dilakukan terhadap suatu ANN, sekumpulan data yang telah lebih
dahulu diketahui jenis atau kelasnya diberikan sebagai input terhadap ANN tersebut. Kemudian,
beban-beban yang terdapat dalam ANN disesuaikan sedemikian rupa sehingga dapat
memberikan output yang sama seperti yang ada pada data pembelajaran. Di sisi lain, ANN
tersebut tetap harus dapat menangani data lain di luar data pembelajaran dengan benar. Apabila
ANN tesebut mampu menangani data pembelajaran dengan benar, namun gagal dalam
menangani data lainnya, maka dapat dikatakan bahwa ANN tersebut overfit.

25
Teknik pembelajaran ANN feedforward yang paling banyak dikenal adalah algoritma
back-propagation. Berikut adalah langkah-langkah yang terjadi dalam proses pembelajaran
menggunakan back-propagation.
1. Satu kelompok data dimasukkan sebagai input dari ANN.
2. Input tersebut dipropagasikan melewai ANN sehingga diperoleh output.
3. Output yang dihasilkan dihitung tingkat kesalahannya.
4. Apabila tingkat kesalahan masih terlalu tinggi, nilai dari tingkat kesalahan
dipropagasi balik untuk menyesuaikan beban-beban pada setiap sel saraf. Sebaliknya,
apabila tingkat kesalahan sudah cukup kecil, algoritma ini selesai sampai di sini
(langkah 5 tidak dilakukan).
5. Ulang lagi proses dengan menggunakan data yang sama dari langkah 1.
Dalam praktiknya, input dipropagasikan dengan menggunakan rumus (2.5) dan (2.6)
hingga akhirnya didapatkan output dari ANN. Kemudian, nilai kesalahan pada setiap sel saraf
dihitung dengan mengunakan rumus (2.7).
(2.7)
Dimana:
k = salah satu sel saraf yang terdapat pada layer output.
y = nilai output yang dihasilkan oleh sel saraf tersebut.
d = nilai output yang diharapkan.
e = nilai kesalahan dari output yang diberikan.
Nilai kesalahan tersebut kemudian digunakan untuk menghitung (2.8). Rumus ini hanya berlaku
pada layer output saja.

26
(2.8)
Dimana:
δ = sinyal kesalahan yang diperoleh.
Fungsi g’ merupakan turunan dari fungsi aktivasi yang digunakan sebelumnya. Dengan
menggunakan (2.9) sinyal kesalahan pada layer sebelumnya dapat dihitung.
(2.9)
Dimana:
K = jumlah sel saraf pada layer ini.
η = sebuah konstanta yang menyatakan jarak penyesuaian beban.
Kemudian, nilai penyesuaian beban dihitung dengan menggunakan rumus (2.10).
(2.10)
Dan beban disesuaikan dengan menggunakan rumus (2.11).
(2.11)
Kemudian, algoritma back-propagation akan mempropagasikan kembali input yang sama, dan
melihat apakah nilai kesalahan masih melebihi yang diharapkan. Proses ini akan terus berulang
hingga akhirnya nilai kesalahan sudah memuaskan kondisi tertentu.
Back-propagation memiliki kelemahan tersendiri. Salah satunya adalah batasan yang nilai
penyesuaian beban yang dapat dilakukan pada setiap iterasi, menyebabkan diperlukan proses
iterasi yang lebih banyak. Sudah ada beberapa teknik yang mampu memecahkan masalah ini.
Walau pun ANN feedforward dan back-propagation bukan jenis ANN yang terbaik, tapi
kombinasi ini merupakan sistem ANN yang paling mudah dipahami sehingga seringkali

27
digunakan sebagai contoh implementasi sistem ANN sebagai salah satu sistem pengenalan pola.
Hingga saat ini, sudah banyak teori-teori ANN yang lebih maju yang telah dikembangkan dan
memiliki performa yang dapat melebihi ANN baik dalam hal pembelajaran mau pun klasifikasi.
2.4. Decision Tree
Konsep dari decision tree adalah mengubah data menjadi decision tree yang akan menghasilkan
rule
Gambar 2.7. Decision tree
Dimana dalam penentuan node dari masing – masing atribut data di dalam decision tree
dilakukan dengan mengukur nilai entropy dari semua atribut data, dan yang dipilih adalah yang
memiliki nilai entropy yang paling kecil ,pengukuran dilakukan sampai dengan node yang paling
akhir
2.5. Data Mining Extensions to SQL (DMX)
DMX merupakan suatu query yang digunakan untuk membuat dan memanipulasi model – model
data mining pada SQL Server, Berikut ini adalah contoh – contoh sintak query DMX yang jika
dilihat secara sepintas mirip dengan query pada T-SQL.
Create Mining Structure
Syntax: CREATE [SESSION] MINING STRUCTURE <structure> ( [(<column definition list>)] ) [(<parameter list>)] Contoh penggunaan :

28
CREATE MINING STRUCTURE [New Mailing] ( CustomerKey LONG KEY, Gender TEXT DISCRETE, [Number Cars Owned] LONG DISCRETE, [Bike Buyer] LONG DISCRETE )
Atau
CREATE MINING STRUCTURE [People3] ( [CustID] LONG KEY, [Name] TEXT DISCRETE, [Gender] TEXT DISCRETE, [Age] LONG CONTINUOUS, [AgeDisc] LONG DISCRETIZED(EQUAL AREAS,3), [CarMake] TEXT DISCRETE, [CarModel] TEXT DISCRETE, [Purchases] TABLE ( [Product] TEXT KEY, [Quantity] LONG CONTINUOUS, [OnSale] BOOLEAN DISCRETE ) , [Movie Ratings] TABLE ( [Movie] TEXT KEY, [Rating] LONG CONTINUOUS ) )
Alter Mining Structure
Contoh penggunaan : ALTER MINING STRUCTURE [People3] ADD MINING MODEL [PredictPurchases-Trees] ( [CustID], [Gender], [Age], [Purchases] PREDICT ( [Product] ) ) USING Microsoft Decision Trees
Insert Into Mining Contoh penggunaan :
INSERT INTO MINING STRUCTURE [People1] ([CustID], [Name], [Gender], [Age], [CarMake],[CarModel]) OPENQUERY(Chapter3Data,

29
’SELECT [Key], Name, Gender, Age, CarMake, CarModel FROM People’)
Select Statement
Contoh penggunaan: // (a) Select all cases SELECT * FROM MINING STRUCTURE People3.CASES // (b) Select cases as a flat rowset SELECT FLATTENED * FROM MINING STRUCTURE People3.CASES // (c) Select only test cases SELECT * FROM MINING STRUCTURE People3.CASES WHERE IsTestCase()
2.6. Kredit Pengertian kredit menurut undang-undang No. 7 Tahun 1992 tentang Perbankan adalah :
penyediaan uang atau tagihan yang dapat dipersamakan dengan itu, berdasarkan persetujuan
kesepakatan pinjam meminjam antara bank dengan pihak lain yang mewajibkan pihak
meminjam untuk melunasi hutangnya setelah jangka waktu tertentu dengan jumlah bunga,
imbalan atau pembagian hasil keuntungan.
2.6.1. Manajemen Kredit Oleh dunia usaha (termasuk usaha kecil) perlu memperhatikan beberapa hal yaitu:
1. Jumlah Pengajuan Kredit harus sesuai dengan kebutuhan (jika jumlah kredit yang diminta
berlebihan akan terbebani bunga yang cukup besar)
2. Penggunaan kredit sesuai dengan tujuan pengembangan usaha
3. Kredit yang diterima ditatausahakan sebaik mungkin sehingga jadwal angsuran dan
pelunasan dapat terpenuhi.

30
2.6.2. Analisa Kredit
Tujuan utama analisis premohonan kredit adalah untuk memperoleh keyakinan apakah nasabah
mempunyai kemauan dan kemampuan memenuhi kewajibannya kepada bank secara tertib, baik
pembayaran pokok pinjaman maupun bunganya, sesuai dengan kesepakatan dengan bank.hal-hal
yang perlu diperhatikan dalam penyelesaian kredit nasabah, terlebih dahulu harus
terpenuhinya Prinsip 6 C’s Analysis, yaitu sebagai berikut:
1. Character
Character adalah keadaan watak dari nasabah, baik dalam kehidupan pribadi maupun dalam
lingkungan usaha. Kegunaan dari penilaian terhadap karakter ini adalah untuk mengetahui
sampai sejauh mana kemauan nasabah untuk memenuhi kewajibannya (willingness to pay)
sesuai dengan perjanjian yang telah ditetapkan.
Sebagai alat untuk memperoleh gambaran tentang karakter dari calon nasabah tersebut, dapat
ditempuh melalui upaya antara lain:
a. Meneliti riwayat hidup calon nasabah;
b. Meneliti reputasi calon nasabah tersebut di lingkungan usahanya;
c. Meminta bank to bank information (Sistem Informasi Debitur);
d. Mencari informasi kepada asosiasi-asosiasi usaha dimana calon nasabah berada;
e. Mencari informasi apakah calon nasabah suka berjudi;
f. Mencari informasi apakah calon nasabah memiliki hobi berfoya-foya.
2. Capital
Capital adalah jumlah dana/modal sendiri yang dimiliki oleh calon nasabah. Semakin besar
modal sendiri dalam perusahaan, tentu semakin tinggi kesungguhan calon nasabah dalam

31
menjalankan usahanya dan bank akan merasa lebih yakin dalam memberikan kredit. Modal
sendiri juga diperlukan bank sebagai alat kesungguhan dan tangung jawab nasabah dalam
menjalankan usahanya karena ikut menanngung resiko terhadap gagalnya usaha.dalam praktik,
kemampuan capital ini dimanifestasikan dalam bentuk kewajiban untuk menyediakan self-
financing, yang sebaiknya jumlahnya lebih besar daripada kredit yang dimintakan kepada bank.
3. Capacity
Capacity adalah kemampuan yang dimiliki calon nasabah dalam menjalankan usahanya guna
memperoleh laba yang diharapkan. Kegunaan dari penilaian ini adalah untuk mengetahui sampai
sejauh mana calon nasabah mampu untuk mengembalikan atau melunasi utang-utangnya secara
tepat waktu dari usaha yang diperolehnya.
Pengukuran capacity tersebut dapat dilakukan melalui berbagai pendekatan berikut ini:
a. Pendekatan historis, yaitu menilai past performance, apakah menunjukkan perkembangan
dari waktu ke waktu.
b. Pendekatan finansial, yaitu menilai latar belakang pendidikan para pengurus
c. Pendekatan yuridis, yaitu secara yuridis apakah calon nasabah mempunyai kapasitas untuk
mewakili badan usaha yang diwakilinya untuk mengadakan perjanjian kredit dengan bank.
d. Pendekatan manajerial, yaitu menilai sejauh mana kemampuan dan keterampilan nasabah
melaksanakan fungsi-fungsi manajemen dalam memimpin perusahaan.
e. Pendekatan teknis, yaitu untuk menilai sejauh mana kemampuan calon nasabah mengelola
faktor-faktor produksi seperti tenaga kerja, sumber bahan baku, peralatan-peralatan , administrasi
dan keuangan, industrial relation sampai pada kemampuan merebut pasar.
4. Collateral

32
Collateral adalah barang-barang yang diserahkan nasabah sebagai agunan terhadap kredit yang
diterimanya. Collateral tersebut harus dinilai oleh bank untuk mengetahui sejauh mana resiko
kewajiban finansial nasabah kepada bank. Pada hakikatnya bentuk collateral tidak hanya
berbentuk kebendaan tetapi juga collateral yang tidak berwujud seperti jaminan
pribadi (borgtocht), letter of guarantee, letter of comfort, rekomendasi dan avalis.
5. Condition of Economy
Condition of Economy, yaitu situasi dan kondisi politik , sosial, ekonomi , budaya yeng
mempengaruhi keadaan perekonomian pada suatu saat yang kemungkinannya memengaruhi
kelancaran perusahaan calon debitur. Untuk mendapat gambaran mengenai hal tersebut, perlu
diadakan penelitian mengenai hal-hal antara lain:
a. Keadaan konjungtur
b. Peraturan-peraturan pemerintah
c. Situasi, politik dan perekonomian dunia
d. Keadaan lain yang memengaruhi pemasaran
6. Constraint
Constraint adalah batasan dan hambatan yang tidak memungkinkan suatu bisnis untuk
dilaksankan pada tempat tertentu, misalnya pendirian suatu usaha pompa bensin yang
disekitarnya banyak bengkel las atau pembakaran batu bata.
Dari keenam prinsip diatas, yang paling perlu mendapatkan perhatian account officer adalah
character, dan apabila prinsip ini tidak terpenuhi, prinsip lainnya tidak berarti. Dengan perkataan
lain, permohonannya harus ditolak.

33
2.6.3. Kredit Bermasalah
Sumber-sumber penyebab terjadinya kegagalan pengembalian kredit oleh nasabah atau penyebab
terjadinya kredit bermasalah pada bank dapat dikemukakan sebagai berikut:
1. Self Dealing
Self dealing terjadi karena adanya interest tertentu dari pejabat pemberi kredit terhadap
permohonan yang diajukan nasabah, berupa pemberian kredit yang tidak layak atas dasar yang
kurang sehat terhadap nasabahnya dengan harapan mendapatkan kompensasi berupa pemberian
imbalan dari nasabah.
2. Anxiety for Income
Pendapatan yang diperoleh melalui kegiatan perkreditan merupakan sumber pendapatan utama
sebagian besar bank sehingga ambisi ataupun nafsu yang berlebihan untuk memperoleh laba
bank melalui penerimaan bunga kredit sering menimbulkan pertimbangan yang tidak sehat
dalam pemberian kredit.
3. Compromise of Credit Principles
Pelanggaran prinsip-prinsip kredit oleh pimpinan bank yang menyetujui pemberian kredit yang
mengandung risiko yang potensial menjadi kredit yang bermasalah.
4. Incomplete Credit Information
Terbatasnya informasi seperti data keuangan dan laporan usaha, disamping informasi lainnya
seperti penggunaan kredit, perencanaan, ataupun keterangan mengenai sumber pelunasan
kembali kredit.

34
5. Failure to Obtain or Enforce Liquidation Agreements
Sikap ragu-ragu dalam menentukan tindakan terhadap suatu kewajiban yang telah diperjanjikan,
meskipun nasabah mampu dan wajib membayarnya, juga merupakan penyebab timbulnya kredit-
kredit yang tidak sehat dan mengakibatkan kredit bermasalah bagi bank.
6. Complacency
Sikap memudahkan suatu masalah dalam proses kredit akan mengakibatkan terjadinya kegagalan
atas pelunasan kembali kredit yang diberikan
7. Lack of Supervising
Karena kurangnya pengawasan yang efektif dan berkesinambungan setelah pemberian kredit,
kondisi kredit berkembang menjadi kerugian karena nasabah tidak memenuhi kewajibannya
dengan baik.
8. Technical Incompetence
Tidak adanya kemampuan teknis dalam menganalisis permohonan kredit dari aspek keuangan
meupun aspek lainnya akan berakibat kegagalan dalam operasi perkreditan suatu bank. Para
pejabat kredit harus senantiasan meningkatkan pengetahuan dan kemampuan yang berkaitan
dengan tugasnya dan jangan memberikan kredit kepada usaha atau sektor yang tidak dikenal
dengan baik.
9. Poor Selection of Risks
Risiko tersebut dapat dijelaskan dibawah ini:
a. Pejabat kredit mampu mendeteksi kemampuan nasabah dalam membiayai usahanya,
selain yang diperoleh dari bank.
b. Pejabat kredit harus mampu menghitung berapa kebutuhan nasabah yang sesungguhnya.

35
c. Pejabat kredit harus mampu menghitung nilai taksasi jaminan yang mengcover kredit
yang diberikan
d. Pejabat kredit harus mampu memperhitungkan kemungkinan risiko yang dihadapi dengan
pemberian kredit dan mengetahui sumber pelunasan.
e. Pejabat kredit harus mampu mendeteksi risiko pemberian kredit yang mungkin secara
kemampuan cukup baik, tetapi dari sisi moral kurang menguntungkan bagi bank.
f. Pejabat kredit harus mampu mendeteksi kualitas jaminan yang akan menimbulkan
masalah di kemudian hari.
10. Overlending
Overlending adalah pemberian kredit yang besarnya melampaui batas kemampuanpelunasan
kredit oleh nasabah.
11. Competition
Competition merupakan risiko persaingan yang kurang sehat antar bank yang memperebutkan
nasabah yang berakibat pemberian kredit yang tidak sehat.
Kolektibilitas Kredit
Kualitas Aktiva Produktif dalam bentuk Kredit menurut PBI No. 8/19/PBI/2006 ditetapkan
dalam 4 (empat) golongan, yaitu Lancar, Kurang Lancar, Diragukan dan Macet. Penilaian
terhadap Aktiva Produktif sebagaimana dimaksud dilakukan berdasarkan ketepatan membayar
dan/atau kemampuan membayar kewajiban oleh Debitur.
Aktiva Produktif dalam bentuk Kredit diklasifikasikan menjadi 3 (tiga) jenis sebagai berikut:

36
a. Kredit dengan angsuran, diluar Kredit Pemilikan Rumah (KPR), dengan masa angsuran:
1) kurang dari 1 (satu) bulan, atau
2) 1 (satu) bulan atau lebih.
b. Kredit dengan angsuran, untuk Kredit Pemilikan Rumah; dan
c. Kredit tanpa angsuran. (DL)
Kualitas Kredit diluar KPR dengan masa angsuran kurang dari 1 (satu) bulan ditetapkan
sebagai berikut:
1. Lancar yaitu 0-1 bln dan tdk jth tempo
2. Kurang Lancar yaitu tunggakan > 1-3 bln dan/atau Jth tempo <= 1 bln.
3. Diragukan tunggakan > 3–6 bln dan/atau Jth tempo >1 - <= 2 bln
4. Macet yaitu tunggakan >6 bln dan/atau Jth tempo > 2 bln