sistem pengumpulan data publikasi ilmiah
TRANSCRIPT

SISTEM PENGUMPULAN DATA PUBLIKASI ILMIAH
MENGGUNAKAN METODE WEB CRAWLING
SKRIPSI
NANA NERINA NASUTION
101402025
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
2020
UNIVERSITAS SUMATERA UTARA

SISTEM PENGUMPULAN DATA PUBLIKASI ILMIAH
MENGGUNAKAN METODE WEB CRAWLING
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah
Sarjana Teknologi Informasi
NANA NERINA NASUTION
101402025
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
2020
UNIVERSITAS SUMATERA UTARA

i
UNIVERSITAS SUMATERA UTARA

ii
PERNYATAAN
SISTEM PENGUMPULAN DATA PUBLIKASI ILMIAH MENGGUNAKAN
METODE WEB CRAWLING
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa
kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, 14 Januari 2020
Nana Nerina Nasution
101402025
UNIVERSITAS SUMATERA UTARA

iii
UCAPAN TERIMA KASIH
Syukur Alhamdulillah senantiasa penulis panjatkan kehadirat Allah SWT, karena
atas rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan skripsi ini
sebagai syarat kelulusan dan memperoleh gelar Sarjana dari Program Studi
Teknologi Informasi Universitas Sumatera Utara.
Banyak rasa terima kasih yang ingin penulis ucapkan kepada seluruh pihak
yang turut serta terlibat dalam masa perkuliahan dan masa pengerjaan skripsi ini:
1. Penulis mengucapkan terima kasih kepada orangtua penulis, Zulkarnaen Nasution
dan Askaria Br Sembiring , atas perhatian dan juga kasih sayangnya. Juga bagi
saudara-saudara penulis yang selalu memberikan dukungan moral maupun materil
kepada penulis.
2. Penulis mengucapkan terima kasih kepada Ibu Sarah Purnamawati, ST., M.Sc selaku
dosen pembimbing pertama dan kepada Bapak Ainul Hizriadi S.Kom., M.Comp.SC
selaku dosen pembimbing kedua. Terima kasih telah meluangkan waktu, ide dan
tenaganya untuk membimbing penulis baik dalam pembuatan program maupun
dalam penulisan skripsi.
3. Penulis mengucapkan terima kasih kepada Bapakl Dr. Sawaluddin, M.IT selaku
dosen pembanding pertama dan Ibu Dr. Erna Budhiarti Nababan, M.IT selaku dosen
pembanding kedua yang telah memberikan kritik dan saran yang bermanfaat.
4. Penulis mengucapkan terima kasih kepada Dekan, Wakil Dekan, Ketua Program
Studi Teknologi Informasi, Sekretaris Program Studi Teknologi Informasi, seluruh
dosen dan staff di Program Studi Teknologi Informasi USU yang telah mengajar,
membimbing dan membantu penulis selama proses perkuliahan dan proses
pengerjaan skripsi.
5. Penulis mengucapkan terima kasih kepada teman-teman angkatan 2010 yang telah
menemani, memotivasi penulis, memberikan kritik dan saran yang baik selama
proses perkuliahan maupun dalam masa pengerjaan skripsi, terkhusus bagi Patricia
M Panjaitan, Reza Taqyuddin, Afifudin, Andry Endang, Andrew Handoko, Andreas
T. S. Manulang, Filbert Nicholas, Aaron Maslim, Noviyanti Tri M. Sagala,
Halimatusadiah, Amelia Febrina dan Jhon Wesley Napitupulu.
UNIVERSITAS SUMATERA UTARA

iv
6. Penulis mengucapkan terima kasih kepada sahabat terbaik penulis Christine S., Rena
Tarigan, Rismawaty Sinuhaji, Dini Dwi Aulia, Santa Nova Sari Pinem, Muhammad
Iqbal R Siregar, Rona Simbolon, Grup Indomie, Grup Girls Power.
7. Terima kasih penulis ucapkan untuk semua pihak yang telah terlibat dalam
pengumpulan data maupun pengujian sistem.
Kiranya kalian semua selalu dalam rahmat dan hidayah-Nya.
UNIVERSITAS SUMATERA UTARA

v
ABSTRAK
Jumlah publikasi Ilmiah merupakan salah satu indikator kontribusi sebuah perguruan
tinggi terhadap ilmu pengetahuan dan masyarakat. Tanpa adanya publikasi ilmiah,
hasil-hasil penelitian yang dilakukan oleh perguruan tinggi tidak akan dapat diketahui
khalayak umum sehingga tidak akan mampu menyelesaikan permasalahan di
masyarakat. Kementerian Riset, Teknologi dan Pendidikan Tinggi (Kemenristek)
belum lama ini menggelar Science and Technology Index Award (SINTA) untuk
mengapresiasi perguruan tinggi yang mampu mendorong peningkatan publikasi dan
jurnal ilmiah. Data publikasi yang disimpan ke SINTA tentu saja sangat berguna bagi
Universitas. Akan tetapi, beberapa Universitas cukup kesulitan mengumpulkan data
publikasi dari civitas akademika secara manual, dan untuk mendapatkan data detail
dari SINTA memerlukan akses khusus ke dalam system untuk dapat mengambil data
langsung dari database. Dalam pengumpulan data SINTA, authors diwajibkan untuk
melakukan update data Scopus ID dan Google Scholar ID. Untuk itu diperlukan
sebuah cara agar data publikasi yang ada di SINTA dapat ditarik kedalam dashboard
lokal Universitas untuk dapat dikelola lebih lanjut dan menjadi bahan pertimbangan
pembuat kebijakan di Universitas. Metode Web Crawling dapat digunakan untuk
mengotomasi pencarian dan ekstraksi data di dalam Website. Penelitian ini
menggunakan sumber data publikasi SINTA dengan afiliasi Universitas Sumatera
Utara.
Kata kunci: Web Crawling, Data Scraping, Publikasi Ilmiah, Universitas, SINTA.
UNIVERSITAS SUMATERA UTARA

vi
SCIENTIFIC PUBLICATION DATA COLLECTING SYSTEM USING
WEB CRAWLING TECHNIQUE
ABSTRACT
The number of scientific publications is one indicator of a university's contribution to
science and society. Without scientific publications, the results of research conducted
by universities will not be known to the general public so that they will not be able to
solve problems in society. The Ministry of Research, Technology and Higher
Education (Kemenristek) recently held a Science and Technology Index Award
(SINTA) to appreciate universities that are able to encourage the improvement of
scientific publications and journals. Publication data saved to SINTA is of course very
useful for universities. Therefore, some universities have difficulty in collecting
publication data from the academic community manually, and to obtain detailed data
from SINTA requires special access to the system to be able to retrieve data directly
from the database. For this reason, a method is needed so that publication data in
SINTA can be drawn into the local dashboard of the university to be managed further
and become the material for consideration of policy makers at the university. Web
crawling methods can be used to automate the search and extraction of data on the
website. This study uses the publication data source from SINTA with the affiliation of
the Universitas Sumatera Utara.
Keywords : Web Crawling, Data Scraping, Scientific Publication, Universitas,
SINTA.
UNIVERSITAS SUMATERA UTARA

vii
DAFTAR ISI
PERSETUJUAN Error! Bookmark not defined.
PERNYATAAN ii
UCAPAN TERIMA KASIH iii
ABSTRAK v
ABSTRACT vi
DAFTAR ISI vii
DAFTAR GAMBAR ix
DAFTAR TABEL x
BAB 1 1
1.1 Latar Belakang 1
1.2 Rumusan Masalah 2
1.3 Tujuan Penelitian 3
1.4 Batasan Masalah 3
1.5 Manfaat Penelitian 3
1.6 Metode Penelitian 3
1.7 Sistematika Penulisan 4
BAB 2 6
2.1 Publikasi Ilmiah 6
2.1.1 Publikasi Ilmiah dan Perguruan Tinggi 6
2.1.2 Jurnal Online 7
2.1.3 Indeksasi dan Ranking 7
2.1.4 SINTA (Science and Technology Index) 7
2.2 Document Object Model 8
2.2.1 Struktur DOM 8
2.2.2 XPath dan Css Selector 10
2.3 Crawling and Scraping 11
2.3.3 Metode Crawler Web 12
2.3.4 Metode Scraping 13
2.4 Penelitian Terdahulu 14
UNIVERSITAS SUMATERA UTARA

viii
BAB 3 15
3.1 Sumber Data 15
3.2 Arsitektur Umum Sistem 16
3.2.1 Web Crawling 17
3.2.2 Web Scraping 19
3.2.3 Ekstraksi setiap Data 22
3.3 Perancangan Halaman Crawling Data Publikasi Ilmiah 24
BAB 4 25
4.1 Implementasi Sistem 25
4.1.2 Konfigurasi Perangkat Lunak 25
4.2 Implementasi Perancangan Antar Muka 26
4.3 Pengujian Sistem 27
4.3.1 Pengujian Pengambilan Data Scopus 27
5.1 Kesimpulan 35
5.2 Saran 35
DAFTAR PUSTAKA 36
UNIVERSITAS SUMATERA UTARA

ix
DAFTAR GAMBAR
Gambar 2. 1 Halaman Depan Website SINTA 8
Gambar 2. 2 Contoh sederhana Struktur Halaman Web 9
Gambar 2. 3 Model Tree DOM 10
Gambar 2. 4 Contoh Penerapan CSS Selector 11
Gambar 2. 5 Struktur Umum Web Crawler 13
Gambar 3. 1 Halaman Dokumen Scopus dari Afiliasi USU di SINTA 16
Gambar 3. 2 Arsitektur Umum Aplikasi 16
Gambar 3. 3 Struktur Pola Pagination pada halaman 17
Gambar 3. 4 Pseudocode Crawling Halaman 18
Gambar 3. 5 Struktur DOM data Publikasi 19
Gambar 3. 6 Struktur HTML dari data Publikasi 20
Gambar 3. 7 Snippet Code dari Ekstraksi data Scopus 22
Gambar 3. 8 Contoh Data hasil Scraping 23
Gambar 3. 9 Mockup Halaman Crawling Data 24
Gambar 4. 1 Implementasi Halaman Crawling 27
Gambar 4. 2 Pengujian Automatic Crawling and Scraping data Scopus 28
Gambar 4. 3 Tabel Request Scraping dengan Request Data connection failed 30
Gambar 4. 4 Tabel Request Scraping dengan Range 5 halaman per Request 31
Gambar 4. 5 Tabel Request Scraping dengan Range 10 halaman per Request 32
Gambar 4.6 Tabel Request Scraping dengan Range 15 halaman per Request 32
Gambar 4.7 Tabel Request Scraping dengan Range 20 halaman per Request 33
Gambar 4. 8 Hasil Crawling dan Scraping Data Scopus 34
UNIVERSITAS SUMATERA UTARA

x
DAFTAR TABEL
Tabel2 . 1 Penelitian Terdahulu 14
Tabel 3. 1 Struktur dan Posisi Data yang akan di Scraping 21
Tabel 4. 1 Tabel Spesifikasi Perangkat Keras 25
Tabel 4. 2 Tabel Spesifikasi Perangkat Lunak 26
Tabel 4. 3 Tabel Pengujian Scraping data Scopus 28
UNIVERSITAS SUMATERA UTARA

1
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Publikasi ilmiah merupakan salah satu faktor bagi perguruan tinggi untuk dapat
memberikan dampak positif bagi ilmu pengetahuan dan masyarakat. Civitas
akademika di perguruan tinggi dituntut untuk dapat membuat publikasi ilmiah yang
dapat bermanfaat bagi pemecahan masalah di masyarakat.
Upaya yang harus dilakukan perguruan tinggi sehingga mampu meningkatkan
kualitasnya adalah sumber daya manusia harus selalu memberikan konstribusi yang
bermanfaat bagi masyarakat. Salah satu upaya yang harus dilakukan sivitas akademika
di perguruan tinggi adalah melakukan publikasi ilmiah yang mampu memberikan
manfaat bagi setiap publik yang membacanya. Hal ini telah dilakukan oleh berbagai
perguruan tinggi besar di dunia yang dirilis oleh Quacquarelli Symonds (QS) World
University Ranking seperti: University of Oxford (Inggris), California Institute of
Technology (Amerika Serikat), Stanford University (Amerika Serikat), University of
Cambridge (Amerika Serikat), dan Massachusetts Institute of Technology (Amerika
Serikat) (Symonds, 2015). Akan tetapi, di Indonesia masih mengalami kendala besar
karena publikasi yang telah dihasilkan masih sangat rendah apabila dibandingkan
dengan negara tetangga seperti: Malaysia, Thailand, Singapura (Shahjahan & Kezar,
2013).
Open Science adalah gerakan yang bertujuan untuk membuat penelitian ilmiah,
data, dan penyebaran dapat diakses oleh semua tingkatan masyarakat yang
membutuhkannya. Di benua Eropa, gerakan ini lebih umum disebut Open Science.
Untuk mengembangkan pengetahuan dan penelitian yang bersifat “Open Science”,
salah satu upaya yang dilakukan adalah sivitas akademika di perguruan tinggi harus
memiliki strategi yang mampu untuk meningkatkan publikasi ilmiah yang telah
dimiliki (Salam, Akhyar, Tayeb, & Niswaty, 2017).
Kesulitan dalam mengumpulkan data publikasi di sebuah Universitas
menyebabkan kesulitan bagi para pemangku kepentingan dan pimpinan dalam
membuat roadmap penelitian dan publikasi. SINTA yang merupakan basis data
UNIVERSITAS SUMATERA UTARA

2
sentral bagi publikasi yang dibuat oleh Kemenristekdikti mewajibkan seluruh dosen
atau peneliti di Indonesia untuk melakukan pendataan publikasi mereka ke dalam
sistem. Data yang telah dikumpulkan oleh sistem SINTA tidak ditampilkan secara
detail dan apabila Universitas membutuhkan data tersebut, maka harus mempunyai
izin akses khusus yang diberikan oleh Kementerian.
Untuk meningkatkan nilai Ranking Universitas, proses sinkronisasi publikasi
oleh author sangat diperlukan karena dalam sistem SINTA, yang dapat melakukan
sinkronisasi hanya user (author) pribadi dan manager di Universitas yang telah
diberikan hak akses.
Berdasarkan permasalahan di atas, maka dibutuhkanlah sebuah metode untuk
dapat melakukan ekstraksi data detail berupa authors dan detail publikasi yang
terdapat dari sistem SINTA untuk dapat dipergunakan dalam dashboard local
Universitas sehingga dapat menunjang pengambilan keputusan bagi pimpinan di
Universitas tersebut.
1.2 Rumusan Masalah
Pengumpulan data publikasi yang realtime sulit dilakukan secara manual. Data
publikasi dari sebuah Universitas dibutuhkan oleh pimpinan untuk dapat membuat
arah kebiajakan terkait penelitian dan publikasi. Data publikasi tersebut haruslah
berasal dari sumber data yang telah tervalidasi dan dapat diandalkan. Pengumpulan
data publikasi terkini dari Kementerian Riset perlu dilakukan namun, untuk
mendapatkan data secara langsung dibutuhkan hak akses khusus ke dalam sistem.
Untuk mengatasi permasalahan tersebut, dibutuhkanlah sebuah metode agar dapat
melakukan ekstraksi data yang ditampilkan pada website SINTA sehingga dapat
disajikan secara baik untuk keperluan pimpinan di Universitas.
UNIVERSITAS SUMATERA UTARA

3
1.3 Tujuan Penelitian
Penelitian ini bertujuan untuk mendapatkan data publikasi ilmiah terindeks Scopus
dari website SINTA dengan menerapkan metode Web Crawling.
1.4 Batasan Masalah
Agar penelitian ini sesuai dengan tujuan penelitian, maka masalah yang ada dalam
penelitian ini akan dibatasi oleh hal-hal berikut :
1. Data publikasi yang akan diambil berasal dari website SINTA.
2. Data utama publikasi yang akan di-crawling merupakan data milik
afiliasi Universitas Sumatera Utara.
3. Sample crawling hanya pada publikasi Scopus
1.5 Manfaat Penelitian
Manfaat yang dapat diperoleh dari penelitian ini adalah :
1. Membantu Universitas untuk mendapatkan data publikasi yang detail.
2. Membuat model bagi kebutuhan penelitian selanjutnya untuk
mempermudah pengumpulan data.
3. Menjadi referensi dalam pengembangan sistem crawling, sehingga
dapat dijadikan bank data di program studi.
1.6 Metode Penelitian
Tahapan-tahapan yang dilakukan pada penelitian ini adalah :
1. Studi Literatur
Tahap ini dilaksanakan untuk mengumpulkan dan mempelajari
informasi yang diperoleh dari buku, jurnal dan berbagai sumber
referensi lain yang berkaitan dengan publikasi, Web Crawling dan
scraping, dan sistem SINTA.
2. Identifikasi Masalah
Pada tahap ini dilakukan analisa terhadap masalah yang sering dihadapi
terkait data publikasi di Universitas.
UNIVERSITAS SUMATERA UTARA

4
3. Perancangan Sistem
Tahap ini menjelaskan mengenai perancangan sistem untuk
menyelesaikan permasalahan yang sesuai hasil yang didapatkan dalam
tahap analisis.
4. Implementasi dan Pengujian
Pada tahap ini dilakukan implementasi perancangan ke program,
kemudian dilakukan pengujian terhadap hasil yang didapatkan melalui
implementasi metode Web Scraping
5. Analisis dan Pengambilan Kesimpulan
Pada tahap ini dilakukan pengujian pengambilan data dari sumber
website SINTA dengan menggunakan Web Crawling.
1.7 Sistematika Penulisan
Tugas akhir ini disusun dalam lima bab dengan sistematika penulisan sebagai
berikut:
Bab 1 : Pendahuluan
Bab pendahuluan ini berisi tentang hal-hal yang mendasari
dilakukannya penelitian serta pengidentifikasian masalah penelitian.
Bagian-bagian yang terdapat dalam bab pendahuluan ini meliputi latar
belakang masalah, perumusan masalah, batasan masalah, tujuan
penelitian, dan manfaat penelitian.
Bab 2 : Landasan Teori
Pada bab tinjauan pustaka menguraikan landasan teori, penelitian
terdahulu, kerangka pikir dan hipotesis yang diperoleh dari acuan yang
mendasari dalam melakukan kegiatan penelitian pada tugas akhir ini.
Bab 3 : Analisis dan Perancangan
Bab ini membahas analisis dan perancangan, dimulai dari analisis
terhadap permasalahan yang ada, dan penyelesaian. Pada bab ini
dijabarkan tentang arsitektur umum, proses yang dilakukan serta
tahapan pada metode yang digunakan.
UNIVERSITAS SUMATERA UTARA

5
Bab 4 : Implementasi dan Pengujian
Pada bab ini membahas tentang implementasi sistem dan hasil
pengujian terhadap aplikasi yang telah dibangun.
Bab 5 : Kesimpulan dan Saran
Bab ini berisi tentang kesimpulan hasil penelitian dan saran-saran yang
berkaitan dengan penelitian selanjutnya.
UNIVERSITAS SUMATERA UTARA

6
BAB 2
LANDASAN TEORI
Bab ini akan membahas tentang teori-teori pendukung dan penelitian sebelumnya
yang berhubungan dengan publikasi ilmiah, struktur DOM (Document Object Model)
Web Crawling dan Scraping mengenai publikasi ilmiah di Indonesia.
2.1 Publikasi Ilmiah
2.1.1 Publikasi Ilmiah dan Perguruan Tinggi
Perguruan tinggi adalah wadah yang mampu mencetak sumber daya manusia yang
berkualitas sehingga mampu untuk meningkatkan kualitas suatu negara. Sumber daya
manusia baik dari mahasiswa, alumni, tenaga pendidik maupun tenaga kependidikan
merupakan cerminan dari perguruan tinggi yang berkualitas. Oleh karena itu, elemen-
elemen tersebut memiliki keterkaitan yang sangat erat.
Kontribusi bermanfaat kepada masyarakat merupakan salah satu upaya untuk
dapat meningkatkatkan kualitas sumber daya manusia. Salah satu upaya yang
dilakukan oleh sivitas akademika adalah melakukan publikasi ilmiah yang dapat
memberikan manfaat untuk publik. Hal ini telah jauh diterapkan oleh perguruan
tinggi besar di dunia yang dirilis oleh Quacquarelli Symonds (QS) World University
Ranking seperti: University of Oxford (Inggris), California Institute of Technology
(Amerika Serikat), Stanford University (Amerika Serikat), University of Cambridge
(Amerika Serikat), dan Massachusetts Institute of Technology (Amerika Serikat)
(Symonds, 2015). Akan tetapi, Indonesia masih mengalami kendala karena publikasi
yang dihasilkan dari perguruan tinggi masih sangat rendah. Jika dibandingkan dengan
negara asean seperti: Thailand, Malaysia dan Singapura jumlah publikasi ilmiah di
Indonesia masih jauh tertinggal (Shahjahan & Kezar, 2013).
Salah satu upaya yang dilakukan adalah sivitas akademika di perguruan tinggi
harus memiliki strategi yang mampu untuk meningkatkan publikasi ilmiah (Salam,
Akhyar, Tayeb, & Niswaty, 2017). Sivitas akademika yang paling berperan dalam
pengembangan publikasi di perguruan tinggi adalah dosen dan mahasiswa
(Mopangga, 2014).
UNIVERSITAS SUMATERA UTARA

7
2.1.2 Jurnal Online
Menurut Bill Cope, Angus Philips dan lainnya pada buku “The Future of the
Academic Journal”, terdapat trend yang semakin berkembang terkait jurnal online
yang mana memberikan penghematan biaya produksi pada institusi dan jurnal
publisher. Pada masa sekarang ini hampr 100% jurnal yang telah dipublikasi di dunia
secara online. Publikasi online pada jurnal mengindikasikan bahwa artikel dapat
tersedia pada tingkatan produksi yang berbeda dan tidak perlu ditunggu untuk
menyelesaikan sebuah journal issue sebelum sebuah artikel (Cope & Phillips, 2009).
2.1.3 Indeksasi dan Ranking
QS Stars adalah sistem peringkat Universitas. Universitas yang berpartisipasi
dievaluasi dalam berbagai kategori, menerima peringkat Bintang dari lima untuk
setiap kategori, serta peringkat keseluruhan. Tujuannya adalah untuk membantu para
calon mahasiswa mendapatkan gambaran mendalam tentang kekuatan Universitas-
Universitas yang berbeda - yang mencakup segala sesuatu mulai dari penelitian dan
hasil kerja, hingga tanggung jawab sosial dan inklusivitas (Sumber:
https://www.topuniversities.com).
Salah satu parameter dalam pemeringkatan Perguruan Tinggi di Indonesia
adalah jumlah publikasi ilmiah yang telah dipublikasi dan terdaftar dalam database
sitasi literatur ilmiah yang dimiliki oleh Elsevier yaitu Scopus. Scopus diperkenalkan
ke dunia pada tahun 2004. Scopus bersaing dengan Web of Science (WOS) yang
diterbitkan oleh Thomson Reuters menjadi pusat data terbesar di dunia. WOS terbit
terlebih dahulu dibandingkan dengan Scopus. Meskipun begitu, Scopus lebih diminati
dan melingkupi lebih banyak jurnal (20% lebih banyak) jika dibandingkan dengan
WOS. Scopus dan pusat data lainnya merupakan mesin pencari artikel ilmiah dan
jurnal. Database atau pusat data artikel ilmiah yang lainnya meliputi : Ebsco,
ProQuest, SpringerLink, Wiley, Web of Science, Doaj, Doab, dan lain-lain
(Chadegani, et al., 2013).
2.1.4 SINTA (Science and Technology Index)
Jumlah penduduk di negara kita relatif lebih banyak dari pada beberapa negara
tetangga, namun dalam kenyataannya jumlah publikasi di negara kita masih kalah
dengan negara-negara tetangga. Mengutip informasi dari Ristekdikti bahwa salah satu
UNIVERSITAS SUMATERA UTARA

8
penyebabnya adalah minimnya publikasi internasional para peneliti kita. SINTA
(Science and Technology Index) merupakan portal yang berisi tentang pengukuran
kinerja Ilmu Pengetahuan dan Teknologi yang meliputi antara lain kinerja peneliti,
penulis, author, kinerja jurnal dan kinerja institusi Iptek. Berdasarkan inilah maka
untuk meningkatkan jumlah publikasi ilmiah, pemerintah dalam hal ini Kementerian
Riset, Teknologi dan Pendidikan Tinggi (Kemenristekdikti) membangun Science and
Technology Index yang diberi nama SINTA (Ministry of Research, 2007).
Gambar 2. 1 Halaman Depan Website SINTA
(Sumber : http://sinta2.ristekdikti.go.id/ )
2.2 Document Object Model
Document Object Model (DOM) adalah antarmuka pemrograman untuk dokumen
HTML dan XML. Ini mewakili halaman sehingga program dapat mengubah struktur
dokumen, gaya, dan konten. DOM mewakili dokumen sebagai simpul dan objek.
Dengan begitu, bahasa pemrograman dapat terhubung ke halaman.
2.2.1 Struktur DOM
Dynamic HTML adalah istilah yang digunakan oleh beberapa vendor untuk
menggambarkan kombinasi HTML, style sheet, dan skrip yang memungkinkan
dokumen dianimasikan. W3C telah menerima beberapa pengajuan dari perusahaan
anggota tentang cara model objek dokumen HTML harus diekspos ke skrip. Kiriman
UNIVERSITAS SUMATERA UTARA

9
ini tidak mengusulkan tag HTML baru atau teknologi style sheet. Kegiatan DOM
W3C bekerja keras untuk memastikan solusi netral yang dapat digunakan untuk
interoperable dan scripting disetujui.
Dengan Model Objek Dokumen (DOM), pemrogram dapat membangun
dokumen, menavigasi struktur mereka, dan menambahkan, memodifikasi, atau
menghapus elemen dan konten. Apa pun yang ditemukan dalam dokumen HTML atau
XML dapat diakses, diubah, dihapus, atau ditambahkan menggunakan Model Objek
Dokumen, dengan beberapa pengecualian - khususnya, Antarmuka DOM untuk subset
internal dan eksternal XML belum ditentukan.
DOM adalah API pemrograman untuk dokumen. Ini didasarkan pada struktur
objek yang sangat mirip dengan struktur dokumen yang dimodelkannya. Misalnya,
pertimbangkan tabel ini, yang diambil dari dokumen HTML, contoh :
Gambar 2. 2 Contoh sederhana Struktur Halaman Web.
Dalam DOM, dokumen memiliki struktur logis yang sangat mirip pohon yang
dapat berisi lebih dari satu pohon. Setiap dokumen berisi nol atau satu node doctype,
satu simpul elemen root, dan nol atau lebih komentar atau instruksi pemrosesan;
elemen root berfungsi sebagai root dari elemen tree untuk dokumen. Namun, DOM
tidak menentukan bahwa dokumen harus diimplementasikan sebagai pohon, juga tidak
menentukan bagaimana hubungan antara objek diimplementasikan. DOM adalah
model logis yang dapat diimplementasikan dengan cara apa pun yang nyaman. Dalam
hal menggunakan model struktur istilah untuk menggambarkan representasi seperti
pohon dari dokumen. Salah satu sifat penting dari model struktur DOM adalah
UNIVERSITAS SUMATERA UTARA

10
isomorfisme structural dimana jika ada dua implementasi DOM digunakan untuk
membuat representasi dari dokumen yang sama, mereka akan membuat model struktur
yang sama, sesuai dengan Kumpulan Informasi XML (Wood, et al., 1998).
Sebuah XML Schema mendefinisikan sebuah dokumen yang memiliki sintaks
yang valid dan tidak formal. Sementara halaman web (HTML) memiliki struktur yang
sama dengan XML namun sintak yang digunakan telah didefinisikan menurut standar
W3C (World Wide Web Consortium), sehingga halaman website standar dapat
direpresentasikan dengan tree model object yang menggambarkan data semantik yang
terstruktur penyusun sebuah halaman website.
Gambar 2. 3 Model Tree DOM (Sumber: www.w3schools.com)
2.2.2 XPath dan Css Selector
XPath 3.1 adalah bahasa ekspresi yang memungkinkan pemrosesan nilai yang
sesuai dengan model data yang didefinisikan dalam [XQuery dan XPath Data Model
(XDM) 3.1]. Nama bahasa berasal dari fitur yang paling khas, ekspresi jalur, yang
menyediakan cara pengalamatan hierarkis dari node dalam pohon XML. Selain
memodelkan struktur pohon XML, model data juga mencakup nilai atom, item fungsi,
dan urutan. Versi XPath ini mendukung JSON dan juga XML, menambahkan peta dan
array ke model data dan mendukungnya dengan ekspresi baru dalam bahasa dan
fungsi-fungsi baru di [Fungsi dan Operator XQuery dan XPath 3.1]. Ini adalah fitur
baru yang paling penting di XPath 3.1 (Wood, et al., 1998).
UNIVERSITAS SUMATERA UTARA

11
Tujuan utama XPath adalah untuk mengatasi node pohon XML dan pohon
JSON. XPath mendapatkan namanya dari penggunaan notasi jalur untuk menavigasi
melalui struktur hierarki dokumen XML. XPath menggunakan sintaksis non-XML
yang ringkas untuk memfasilitasi penggunaan XPath dalam nilai atribut URI dan
XML. XPath 3.1 menambahkan sintaksis yang serupa untuk menavigasi pohon JSON.
Sementara CSS Selector merupakan bentuk dari metadata DOM objek yang
menjelaskan style tertentu yang diterapkan pada objek dom tersebut. Mesin rendering
browser melihat melalui CSS & HTML kemudian mencocokkan penyeleksi ke objek
DOM yang sesuai dan kemudian menerapkan gaya CSS ke objek DOM yang
diberikan.
Gambar 2. 4 Contoh Penerapan CSS Selector (Sumber : Granneman, 2018 )
2.3 Crawling and Scraping
Web scraping atau disebut juga dengan web harvesting atau web data extraction
adalah sebuah teknik program komputer untuk melakukan ekstraksi informasi dari
sebuah halaman website. Web Scraping tidak dapat dimasukkan dalam bidang data
mining karena data mining menyiratkan upaya untuk memahami pola semantik atau
tren dari sejumlah besar data yang telah diperoleh. Aplikasi web scraping (juga
disebut intelligent, automated, or autonomous agents) hanya fokus pada cara
memperoleh data melalui pengambilan dan ekstraksi data dengan ukuran data yang
bervariasi (Taqyuddin, Rahmat, Nababan, & Purnamawati, 2017).
UNIVERSITAS SUMATERA UTARA

12
2.3.3 Metode Crawler Web
Halaman Web berisi sejumlah besar informasi tentang berbagai hal dan topik. Berbeda
dengan koleksi tradisional seperti perpustakaan, halaman web tidak memiliki struktur
konten yang diatur secara terpusat. Data di halaman web ini dapat diunduh
menggunakan crawler web. Crawler web adalah perangkat lunak untuk mengunduh
halaman dari Web secara otomatis (Mitchell, 2015).
Crawler web adalah metode penting untuk mengumpulkan data dan mengikuti
perkembangan Internet yang sangat pesat. Crawler web juga bisa disebut sebagai
masalah pencarian grafik (graph) karena web dianggap sebagai graph yang besar yang
direpresentasikan sebagai kumpulan node. Crawler web dapat digunakan di berbagai
bidang, yaitu salah satu yang paling menonjol adalah mengindeks satu set halaman
yang besar dan memungkinkan orang lain untuk mencari indeks ini. Crawler web
hanya mengirim permintaan untuk dokumen di server web dari sekumpulan lokasi
yang sudah ada (Singh, Singh, & Varnica, 2014). Secara umum, tahapan yang
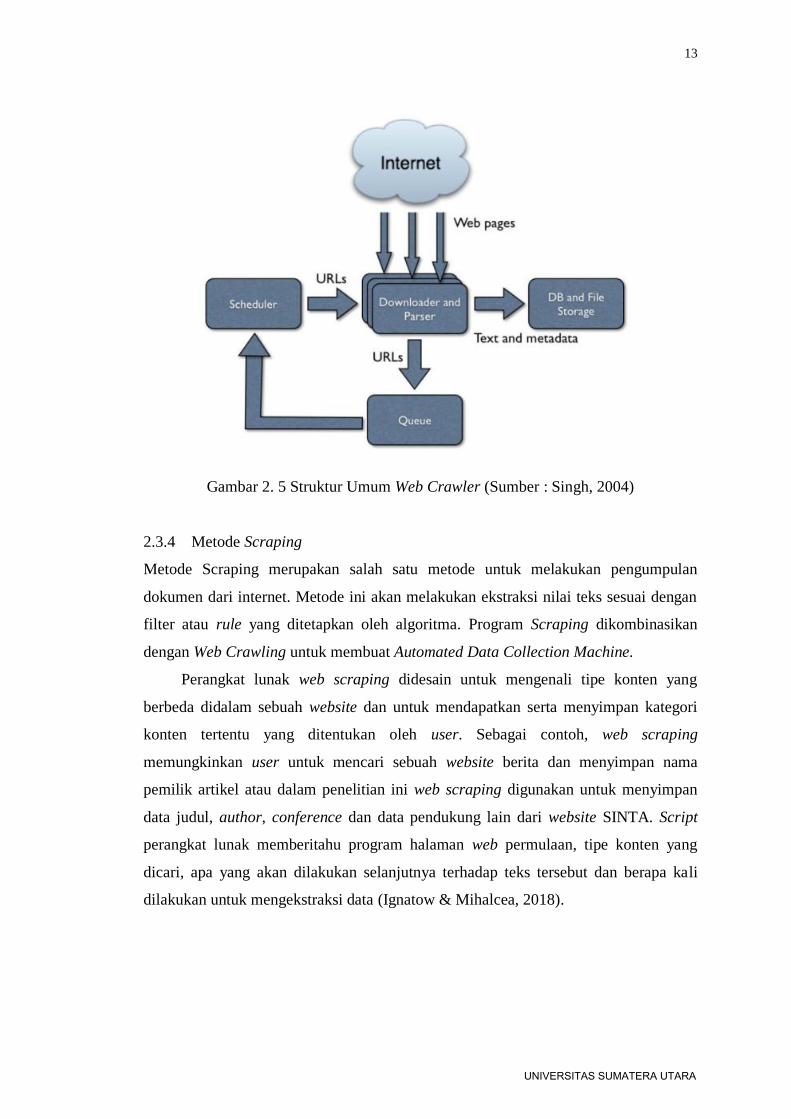
dilakukan oleh crawler adalah sebagai berikut :
a. Web Crawler membuat list URL untuk diproses. List ini diperoleh dari hasil
inisialisasi URL secara manual yang nantinya akan melakukan perulangan
untuk membentuk kumpulan URL yang lebih besar.
b. Crawler mengambil URL dari dalam list dan menandainya. Biasanya url
diekstraksi dari hasil regular expression (Regex) terhadap link, contoh : <a
href=”….” >. Dengan menggunakan struktur DOM, system melakukan
ekstraksi nilai href dari link tersebut.
c. Memeriksa file robot dan juga membaca header halaman untuk melihat
apakah ada instruksi pengecualian. Beberapa halaman web tidak
menginginkannya halaman diarsipkan oleh mesin pencari.
d. Unduh seluruh halaman lalu ekstrak semua tautan dari halaman (situs web
tambahan dan alamat halaman) dan tambahkan ke antrian yang disebutkan
di atas untuk diunduh nanti.
e. Ekstrak semua kata & simpan ke basis data yang terkait dengan halaman
ini, dan simpan urutan kata.
f. Simpan ringkasan halaman dan perbarui yang terakhir tanggal diproses
untuk halaman sehingga sistem tahu kapan harus memeriksa ulang halaman
di tahap selanjutnya.
UNIVERSITAS SUMATERA UTARA
13
Gambar 2. 5 Struktur Umum Web Crawler (Sumber : Singh, 2004)
2.3.4 Metode Scraping
Metode Scraping merupakan salah satu metode untuk melakukan pengumpulan
dokumen dari internet. Metode ini akan melakukan ekstraksi nilai teks sesuai dengan
filter atau rule yang ditetapkan oleh algoritma. Program Scraping dikombinasikan
dengan Web Crawling untuk membuat Automated Data Collection Machine.
Perangkat lunak web scraping didesain untuk mengenali tipe konten yang
berbeda didalam sebuah website dan untuk mendapatkan serta menyimpan kategori
konten tertentu yang ditentukan oleh user. Sebagai contoh, web scraping
memungkinkan user untuk mencari sebuah website berita dan menyimpan nama
pemilik artikel atau dalam penelitian ini web scraping digunakan untuk menyimpan
data judul, author, conference dan data pendukung lain dari website SINTA. Script
perangkat lunak memberitahu program halaman web permulaan, tipe konten yang
dicari, apa yang akan dilakukan selanjutnya terhadap teks tersebut dan berapa kali
dilakukan untuk mengekstraksi data (Ignatow & Mihalcea, 2018).
UNIVERSITAS SUMATERA UTARA

14
2.4 Penelitian Terdahulu
Penelitian yang dibuat penulis mengambil beberapa sumber penelitian terdahulu
sebagai referensi.
Tabel 2. 1 Penelitian Terdahulu
No. Peneliti Tahun Keterangan
1 (Turland M. , 2010) 2010 Penelitian Turland menggunakan
penerapan Web Scraping pada
pemrograman PHP
2 (Ahmat, Abdillah, &
Suryayusra, 2014)
2014 Penelitian ini menjelaskan struktur dan
pseudocode langkah penererapan teknik
Web Scraping
3 (Vargiu & Urru, 2013) 2013 Penelitian ini melakukan implementasi
teknik Web Scraping untuk mendapatkan
data yang ditampilkan melalui jejaring
sosial.
4 (Gilbert., Sanchez-
Marre., & Sevilla.,
2012)
2012 Tenik mengklasifikasi dengan
menggunakan multi-label prediction pada
polusi udara untuk mendapatkan prediksi
5 Margaret, P; ,
Purnamawati S;
Rahmat, RF
2018 Penelitian ini menggunakan Teknik web
scraping untuk dapat mengambil
historical data dari website
wunderground.com dan mengekstraksinya
ke dalam bentuk JSON.
UNIVERSITAS SUMATERA UTARA

15
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Bab ini secara garis besar membahas analisis metode Automated Web Crawling and
Scrapping pada sistem dan tahap-tahap yang dilakukan dalam perancangan sistem
yang akan dibangun sehingga menghasilkan informasi data publikasi
3.1 Sumber Data
Untuk melakukan pengumpulan data yang valid, sumber data yang digunakan
dalam penelitian ini adalah data publikasi Universitas Sumatera Utara dari url
http://sinta2.ristekdikti.go.id/affiliations/detail?id=441&view=overview. Data SINTA
itu sendiri telah diverifikasi sehingga 90% data yang ditampilkan merupakan data
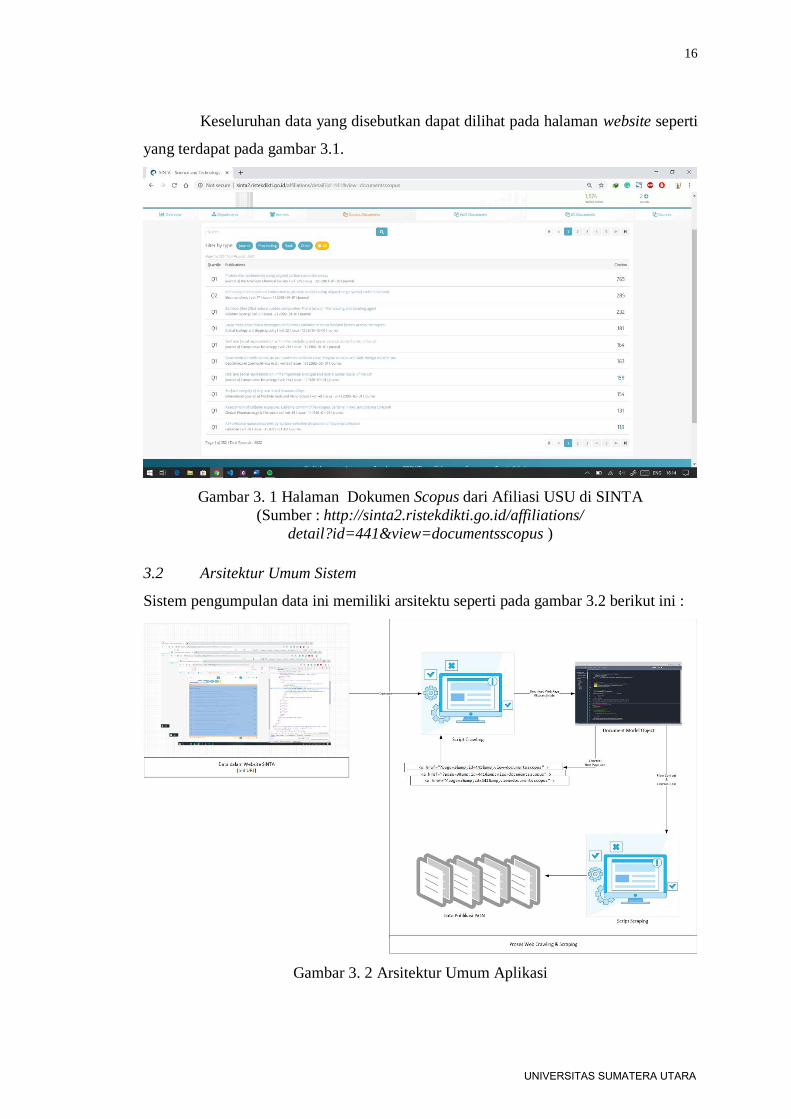
yang valid. Data parameter pada website ini yang akan diambil adalah document
Scopus yang terdapat pada tab #scopus, pada halaman ini terdapat tabel yang memuat
data dokumen scopus yaitu :
1. Kelompok Quartil
2. Judul Dokumen
3. Nama Jurnal
4. Jumlah Sitasi
5. Author (Commented)
6. Author profile Links (Commented)
UNIVERSITAS SUMATERA UTARA
16
Keseluruhan data yang disebutkan dapat dilihat pada halaman website seperti
yang terdapat pada gambar 3.1.
Gambar 3. 1 Halaman Dokumen Scopus dari Afiliasi USU di SINTA
(Sumber : http://sinta2.ristekdikti.go.id/affiliations/
detail?id=441&view=documentsscopus )
3.2 Arsitektur Umum Sistem
Sistem pengumpulan data ini memiliki arsitektu seperti pada gambar 3.2 berikut ini :
Gambar 3. 2 Arsitektur Umum Aplikasi
UNIVERSITAS SUMATERA UTARA

17
Arsitektur umum pada gambar 3.2 memiliki beberapa tahapan dalam menjalankan
seluruh proses yang ada baik dari input, proses utama hingga menghasilkan output
data berupa JSON. Proses-proses tersebut dijabarkan pada poin-poin berikut ini :
3.2.1 Web Crawling
Teknik Web Crawling dilakukan untuk menelusuri tautan yang teradapat di website
SINTA. Proses ini dimulai dengan menginisialisasi starting url:
http://sinta2.ristekdikti.go.id/affiliations/detail/?id=441&view=documentsscopus.
Pembedahan struktur data semantik (DOM) pada website ataupun dokumen dilakukan
untuk mendapatkan nilai halaman selanjutnya dari tautan yang ada di halaman.
Saat halaman web mulai diinisialisasi, program akan mengekstrak DOM map
dari halaman web yang dapat ditelusuri dan difilter. Pada tahapan crawling ini, Objek
dari DOM yang telah diunduh oleh script, difilter hanya menampilkan link dari
paging halaman data. Pada gambar 3.3, kita perlu memperhatikan pola dari struktur
halaman web yang akan kita crawling. Pada gambar tampak bahwa tautan untuk
menuju halaman pagination berada pada class .uk-pagination, di object element list
<li></li>
Gambar 3. 3 Struktur Pola Pagination pada halaman.
Apabila kita telusuri secara manual, model pagination dihalaman ini tidak
berubah jumlahnya, dalam hal ini terdapat 9 element list pada halaman, dimana untuk
next page berada pada array index ke 7. Setiap kita melakukan klik halaman
UNIVERSITAS SUMATERA UTARA

18
selanjutnya, label dan value href dari pagination akan berubah. Hal ini memungkinkan
kita untuk dapat melakukan ekstraksi value next page dari halaman. Value ini dapat
kita simpan ke dalam variable untuk dapat diproses dalam iterasi selanjutnya.
Langkah langkah pada pseudocode dapat dijelaskan sebagai berikut :
Penjelasan dari pseudocode pada gambar 3.4 adalah sebagai berikut :
1. GetDOMinPage akan melakukan process pengambilan DOM Object dari
halaman web dengan url string yang telah ditentukan. Dalam hal ini, halaman
web didapatkan dari starting url yang akan diproses pada fungsi getNextPage()
2. Fungsi getNextPage() akan memproses url yang didapatkan, lalu melakukan
pengecekan apakah alamat url tersebut valid atau tidak.
3. Jika Halaman valid, maka script akan melakukan komunikasi dengan Halaman
web yang dituju untuk mengecek apakah script crawling mendapakan akses
untuk memproses halaman web dari domain tersebut.
4. Jika diperbolehkan, maka script akan mengunduh halaman web dari url tadi
dan melakukan parsing halaman menjadi Struktur Document Object Model.
GetDOMinPage(getNextPage(‘url’))
Function getNextPage(startUrl)
check_is_valid_url(startUrl)
doCommunicationWithWebsite();
if(allowed)
downloadPage()
data = parseIntoDOMStructure()
return false
filterPagination()
paging = findXPath(‘.uk-pagination > ul > li’)
checkIfPagingExist[7]
extractLinkValue()
else
return false
nextPage = linkValue()
return nextPage()
end
Gambar 3. 4 Pseudocode Crawling Halaman
UNIVERSITAS SUMATERA UTARA

19
5. Data DOM yang telah diparsing kemudian difilter untuk mendapatkan nilai
pagination dari halaman web tersebut. Dalam hal ini, filter dilakukan dengan
Xpath element class .uk-pagination > ul > li dimana pada setiap li terdapat
tautan yang berisi link untuk ke halaman tertentu, ditunjukkan gambar 3.3.
6. Cek apakah list ke 7 mempunyai isi, jika tidak maka script telah mencapai ke
ujung halaman dan program akan dihentikan.
7. Ekstrak nilai dari link di list ke 7 untuk dipassing ke variable yang akan
diproses pada iterasi berikutnya.
3.2.2 Web Scraping
Proses selanjutnya adalah melakukan scraping data dari halaman website untuk dapat
disimpan ke dalam data lokal. Pada gambar 3.5, data publikasi Scopus pada website
Sinta terdapat pada tabel. Di setiap halaman pagination, tabel tersebut hanya
menampilkan 10 baris data publikasi saja.
Gambar 3. 5 Struktur DOM data Publikasi ( Sumber : http://sinta2.ristekdikti.go.id/
affiliations/ detail?id=441&view=documentsscopus)
UNIVERSITAS SUMATERA UTARA

20
Gambar 3. 6 Struktur HTML dari data Publikasi (Sumber :
http://sinta2.ristekdikti.go.id/affiliations/detail?
id=441&view=documentsscopus)
Pada gambar 3.6 terlihat struktur dari data publikasi dalam format html. Data tersebut
terdapat pada setiap baris tabel yang ditandai dalam class .uk-table. Posisi data text
tersebut muncul dengan pola yang sama yakni berada didalam tabel dengan class uk-
tabel dengan child object tbody lalu subchild tr > td.
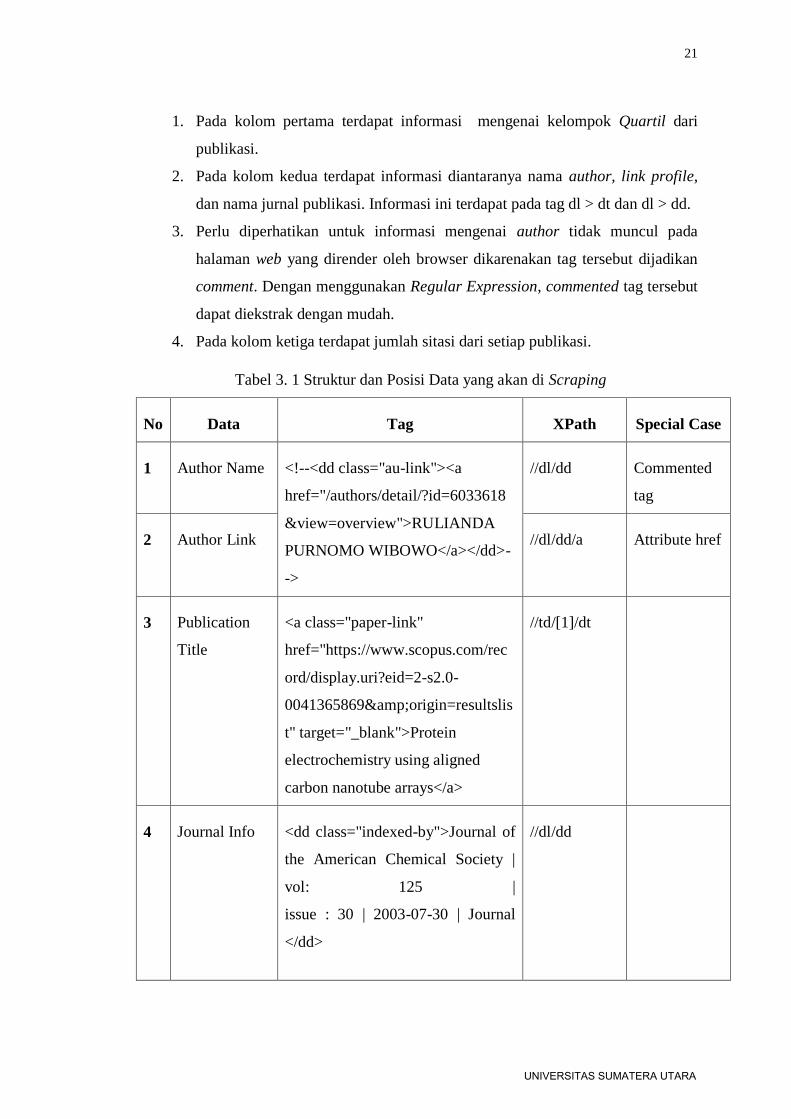
Didalam setiap baris (tr) table terdapat 3 kolom (td) dimana masing-masing td
memiliki konten text, seperti :
UNIVERSITAS SUMATERA UTARA
21
1. Pada kolom pertama terdapat informasi mengenai kelompok Quartil dari
publikasi.
2. Pada kolom kedua terdapat informasi diantaranya nama author, link profile,
dan nama jurnal publikasi. Informasi ini terdapat pada tag dl > dt dan dl > dd.
3. Perlu diperhatikan untuk informasi mengenai author tidak muncul pada
halaman web yang dirender oleh browser dikarenakan tag tersebut dijadikan
comment. Dengan menggunakan Regular Expression, commented tag tersebut
dapat diekstrak dengan mudah.
4. Pada kolom ketiga terdapat jumlah sitasi dari setiap publikasi.
Tabel 3. 1 Struktur dan Posisi Data yang akan di Scraping
No Data Tag XPath Special Case
1 Author Name <!--<dd class="au-link"><a
href="/authors/detail/?id=6033618
&view=overview">RULIANDA
PURNOMO WIBOWO</a></dd>-
->
//dl/dd Commented
tag
2 Author Link //dl/dd/a Attribute href
3 Publication
Title
<a class="paper-link"
href="https://www.scopus.com/rec
ord/display.uri?eid=2-s2.0-
0041365869&origin=resultslis
t" target="_blank">Protein
electrochemistry using aligned
carbon nanotube arrays</a>
//td/[1]/dt
4 Journal Info <dd class="indexed-by">Journal of
the American Chemical Society |
vol: 125 |
issue : 30 | 2003-07-30 | Journal
</dd>
//dl/dd
UNIVERSITAS SUMATERA UTARA

22
Tabel 3. 1 Struktur dan Posisi Data yang akan di Scraping (Lanjutan)
No Data Tag Xpath Special Case
4 Quartil <td class="index-val uk-text-
center">Q1</td>
//td[0]
5 Citation <td class="index-val uk-text-
center">765</td>
//td[2]
3.2.3 Ekstraksi setiap Data
Setelah pola dari konten yang akan di-scraping telah kita tentukan seperti pada tabel
3.1, selanjutnya adalah melakukan ekstraksi. Ekstraksi data dilakukan dengan
memfilter node Xpath seperti pada gambar 3.7
Gambar 3. 7 Snippet Code dari Ekstraksi data Scopus
Pada gambar 3.7, fungsi akan menerima parameter dari DOM halaman website yang
telah didownload kemudian dilakukan filter node untuk mendapatkan baris-baris data.
Setelah baris data difilter, kemudian dilakukan iterasi untuk mendapatkan data
authors, title, journal, quartil dan cite dengan melakukan filter XPath kembali sesuai
dengan pola struktur yang telah ditentukan sebelumnya. Data tersebut kemudian akan
UNIVERSITAS SUMATERA UTARA
23
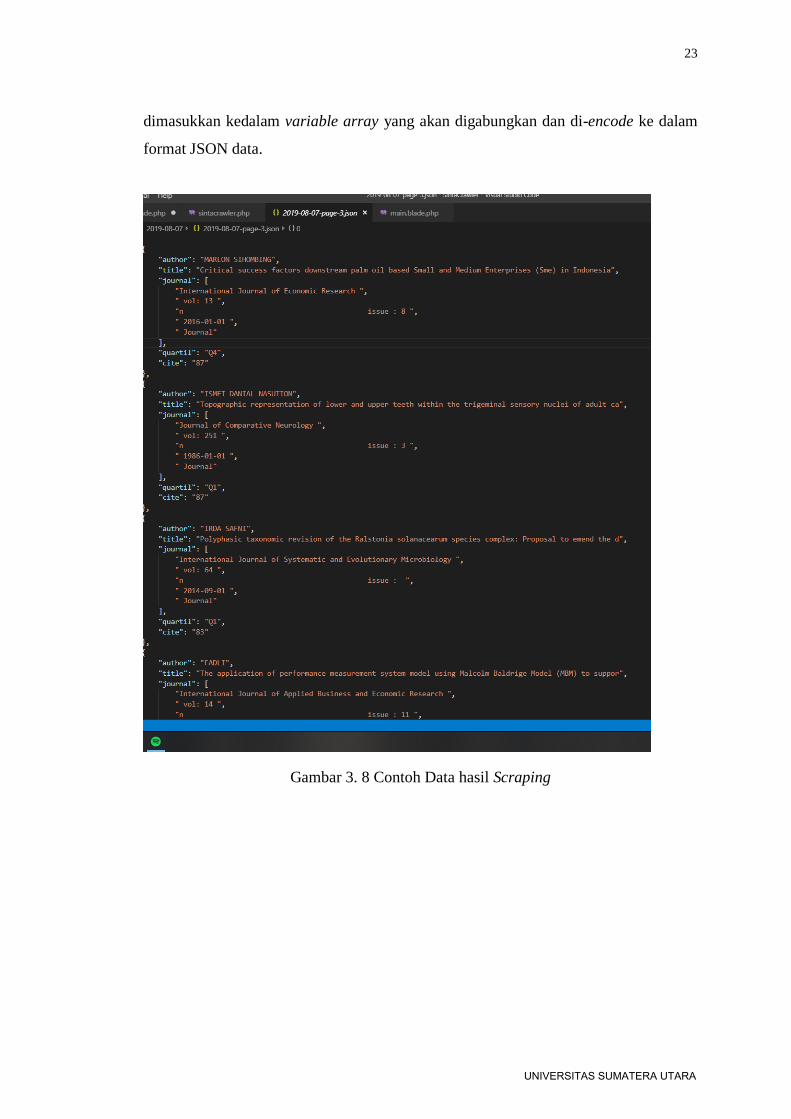
dimasukkan kedalam variable array yang akan digabungkan dan di-encode ke dalam
format JSON data.
Gambar 3. 8 Contoh Data hasil Scraping
UNIVERSITAS SUMATERA UTARA

24
3.3 Perancangan Halaman Crawling Data Publikasi Ilmiah
Halaman ini terdiri dari beberapa blok area yaitu blok area untuk console log proses
crawling dan scraping, content menu untuk melakukan crawling dan content menu
untuk melakukan auto sync profile serta blok footer untuk navigasi lainnya seperti
pada gambar 3.9
Gambar 3. 9 Mockup Halaman Crawling Data
UNIVERSITAS SUMATERA UTARA

25
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Setelah melakukan analisis dan perancangan sistem selanjutnya dilakukan
implementasi. Pada bab ini akan membahas tentang hasil yang diperoleh setelah
melakukan implementasi.
4.1 Implementasi Sistem
Dalam penelitian ini, penerapan metode Web Crawling dan Scraping dilakukan
dengan menggunakan bahasa pemograman PHP dan framework Laravel.
4.1.1 Konfigurasi Perangkat Keras.
Spesifikasi perangkat keras yang digunakan untuk membangun sistem ini dan agar
pengujian dapat berjalan dengan baik dapat dilihat pada tabel 4.1.
Tabel 4. 1 Tabel Spesifikasi Perangkat Keras.
No. Jenis Komponen Komponen yang digunakan
1. CPU Intel Core i7 (Min Intel Core i3)
2. Kartu Grafis Nvidia GeForce
3. Storage 500GB harddisk
4. Network 10/100Mbps Ethernet
.
4.1.2 Konfigurasi Perangkat Lunak
Konfigurasi Perangkat Lunak yang digunakan pada penelitian ini, baik saat
proses implementasi maupun pengujian dapat dilihat pada tabel 4.2.
UNIVERSITAS SUMATERA UTARA

26
Tabel 4. 2 Tabel Spesifikasi Perangkat Lunak
No. Jenis Software Software yang digunakan
1. Sistem Operasi Microsoft® Windows 10 Pro 64bit
2. Laravel Framework Laravel min versi 5.5
3. Browser Min. Chrome v42
4. IDE Visual Studio Code
5. Library Symfony/DOMCrawler , Goutte dan
GuzzleHttp
4.2 Implementasi Perancangan Antar Muka
Berikut akan dijelaskan tampilan dari aplikasi yang dibangun. Pada aplikasi ini,
hanya memiliki satu tampilan utama, yaitu tampilan menu untuk melakukan
crawling data publikasi Scopus di halaman SINTA. Dibangun dengan menggunakan
bahasa pemograman php dan didukung dengan Javascript pada framework Laravel
dengan memanfaatkan View Blade standar dari Laravel, untuk navigasi dan interaksi
sistem menggunakan ajax dan juga JQuery. Gambar 4.1 merupakan hasil
implementasi dari perancangan yang telah dilakukan :
UNIVERSITAS SUMATERA UTARA

27
Gambar 4. 1 Implementasi Halaman Crawling
4.3 Pengujian Sistem
Tahapan pengujian sistem adalah tahapan dimana serangkaian langkah y a n g
d i l a k u k a n untuk melihat apakah sistem yang dibangun sudah berjalan
dengan baik dan respon dari sistem terhadap kesalahan yang dilakukan oleh
pengguna dapat ditanggulangi secara baik atau tidak. Pada pengujian kali ini,
dilakukan beberapa tahapan berikut :
4.3.1 Pengujian Pengambilan Data Scopus
Data publikasi yang digunakan pada penelitian ini merupakan data yang dihasilkan
dari metode crawling dan scraping pada website SINTA. Proses scraping dimulai
dengan menjalankan langkah-langkah berikut :
UNIVERSITAS SUMATERA UTARA
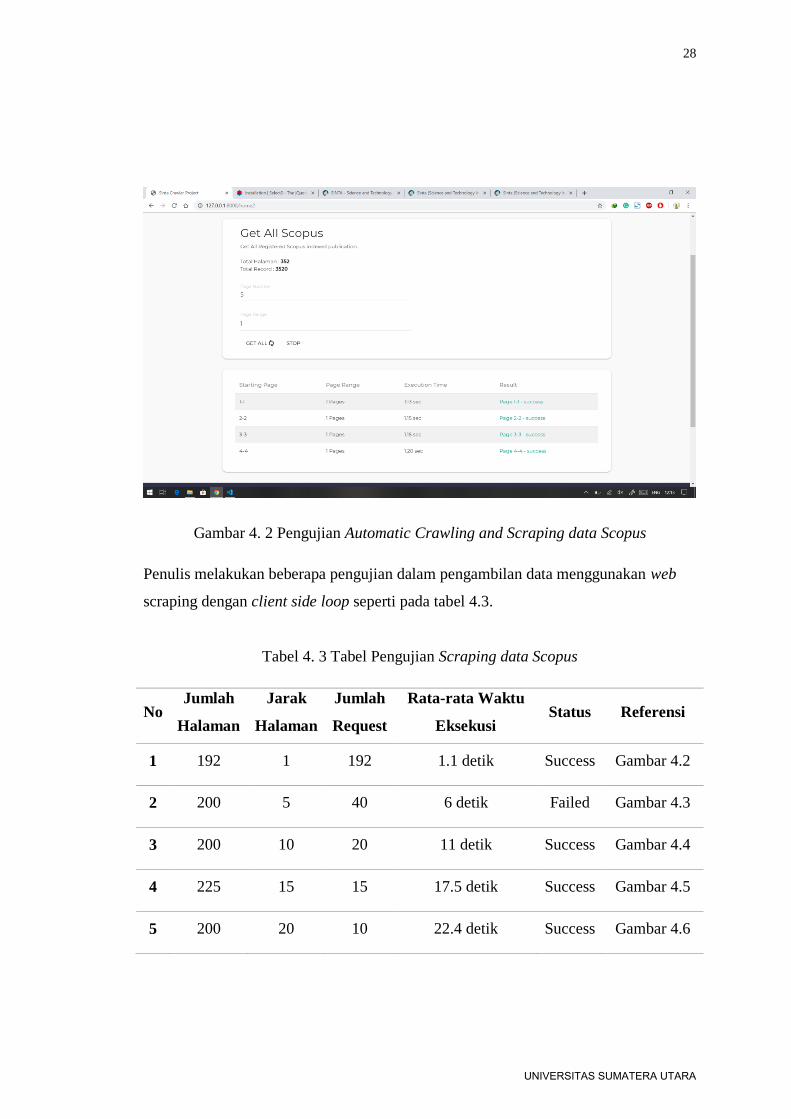
28
Gambar 4. 2 Pengujian Automatic Crawling and Scraping data Scopus
Penulis melakukan beberapa pengujian dalam pengambilan data menggunakan web
scraping dengan client side loop seperti pada tabel 4.3.
Tabel 4. 3 Tabel Pengujian Scraping data Scopus
No Jumlah
Halaman
Jarak
Halaman
Jumlah
Request
Rata-rata Waktu
Eksekusi Status Referensi
1 192 1 192 1.1 detik Success Gambar 4.2
2 200 5 40 6 detik Failed Gambar 4.3
3 200 10 20 11 detik Success Gambar 4.4
4 225 15 15 17.5 detik Success Gambar 4.5
5 200 20 10 22.4 detik Success Gambar 4.6
UNIVERSITAS SUMATERA UTARA

29
Tabel 4. 3 Tabel Pengujian Scraping data Scopus (Lanjutan)
No Jumlah
Halaman
Jarak
Halaman
Jumlah
Request
Rata-rata Waktu
Eksekusi Status Referensi
6 240 30 8 30.7 detik Success -
7 315 35 9 35.8 detik Success -
8 300 50 6 44.1 detik Success -
9 300 100 3 70.3 detik Success -
10 300 300 1 124.6 detik Success -
Dari hasil pengujian di tabel 4.3, dengan menerapkan metode scraping website untuk
mengumpulkan data secara otomatis sangat memungkinkan dan juga sangat mudah.
Akan tetapi, semakin banyak request yang dikirimkan server menyebabkan
kemungkinan mengalami kegagalan akan tinggi seiring dengan tingginya latency
konektivitas di setiap request. Maka dalam melakukan scraping perlu diperhatikan :
1. Reliabity jaringan antara server scraper dengan server tujuan. Apabila jaringan
kurang baik, maka kemungkinan request timeout akan semakin besar.
2. Pengaturan penjadwalan request ajax di client yang tidak diatur dengan baik
menyebabkan beban request ajax ke server menjadi banyak, sehingga apabila
ada ajax request yang belum selesai, akan dinyatakan pending dan dilanjutkan
ke request berikutnya. Hal ini berdampak pada beban server scraper sehingga
program menjadi hang dan server tidak dapat melanjutkan pemrosesan
request.
3. Banyaknya perulangan dan komunikasi dengan server meningkatkan level
kegagalan dalam melakukan scraping.
UNIVERSITAS SUMATERA UTARA

30
Gambar 4. 3 Tabel Request Scraping dengan Request Data connection failed.
Pada gambar 4.3 menunjukkan kegagalan saat melakuakan request. Hal ini
disebabkan waktu pengambilan data dilakukan pada siang hari, yang bisa disebabkan
kemungkinan terkendala masalah jaringan, atau bisa juga disebabkan SINTA pada
saat sedang banyak diakses.
UNIVERSITAS SUMATERA UTARA
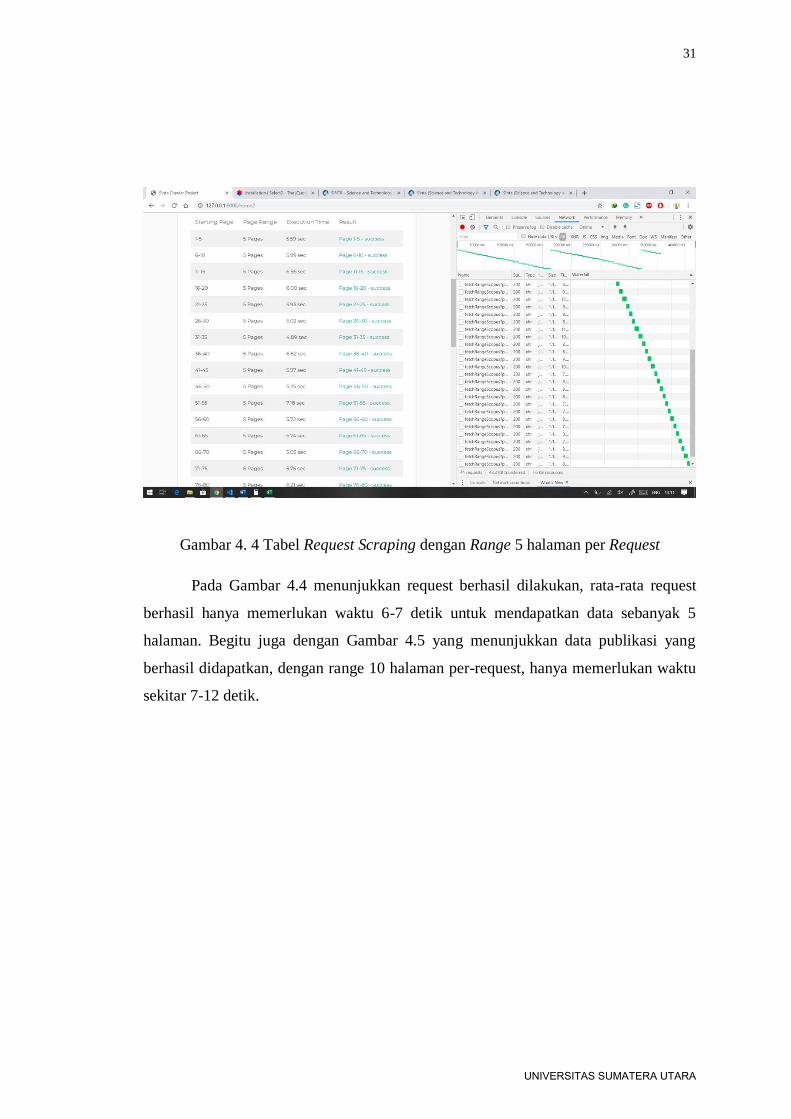
31
Gambar 4. 4 Tabel Request Scraping dengan Range 5 halaman per Request
Pada Gambar 4.4 menunjukkan request berhasil dilakukan, rata-rata request
berhasil hanya memerlukan waktu 6-7 detik untuk mendapatkan data sebanyak 5
halaman. Begitu juga dengan Gambar 4.5 yang menunjukkan data publikasi yang
berhasil didapatkan, dengan range 10 halaman per-request, hanya memerlukan waktu
sekitar 7-12 detik.
UNIVERSITAS SUMATERA UTARA
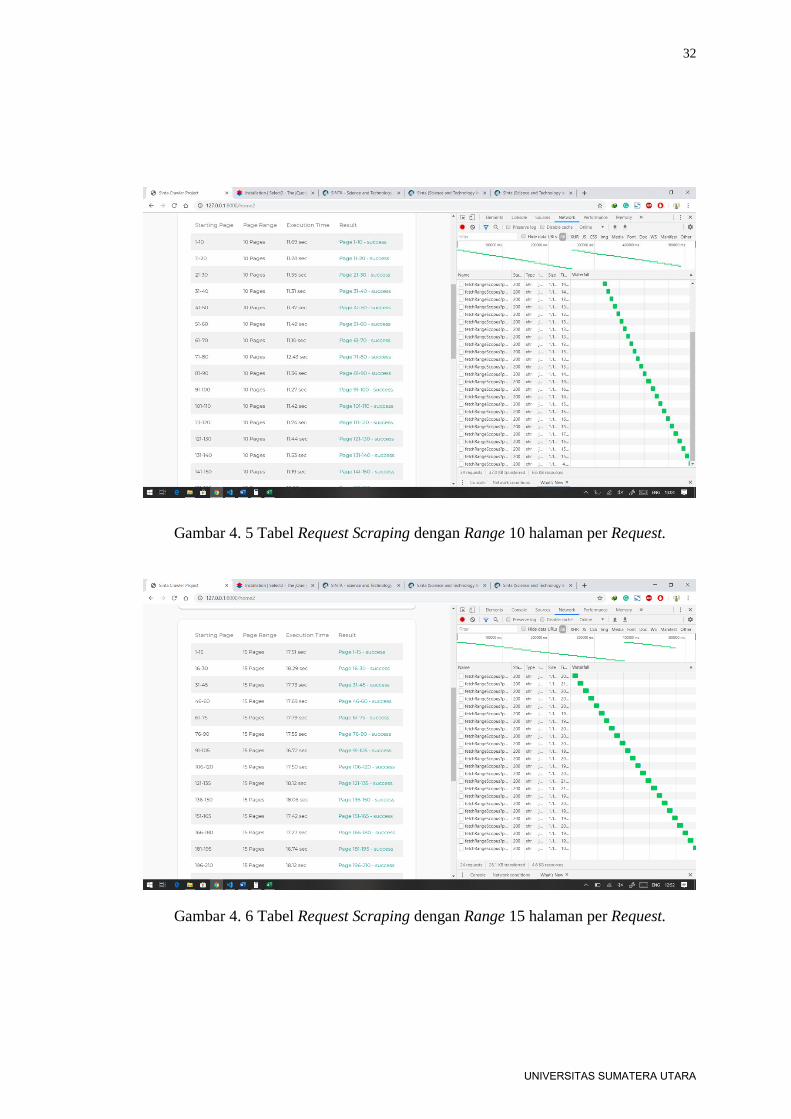
32
Gambar 4. 5 Tabel Request Scraping dengan Range 10 halaman per Request.
Gambar 4. 6 Tabel Request Scraping dengan Range 15 halaman per Request.
UNIVERSITAS SUMATERA UTARA

33
Gambar 4.7 Tabel Request Scraping dengan Range 20 halaman per Request.
Dari beberapa pengujian untuk Crawling data, hasil dari crawling tersebut kemudian
disimpan dalam file json sesuai dengan halaman yang direquest seperti pada gambar
4.7.
UNIVERSITAS SUMATERA UTARA

34
Gambar 4. 8 Hasil Crawling dan Scraping Data Scopus.
Hasil didapatkan dan disatukan dalam sebuah folder yang diberi nama sesuia dengan
tanggal akses yang dilakukan. Jumlah publikasi yang berada dalam satu folder sesuai
dengan range saat melakukan request pada halaman Crawling. Seperti dilihat pada
Gambar 4.8 hasil request disimpan pada folder 29 08- 10-page-8.json, yang mana saat
melakukan request, range yang diberikan adalah 1.
UNIVERSITAS SUMATERA UTARA

35
BAB 5
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Metode web crawler sering digunakan untuk mencari data dari halaman web yang
sangat besar dengan menganalisa hubungan graph antar link halaman untuk
menelusuri sebuah domain web. Metode web crawler biasa digabungkan dengan
metode scraping untuk melakukan ekstraksi data. Pada penelitian ini, algoritma web
crawling dan scraping telah berhasil diimplementasikan. Percobaan telah dilakukan
sebanyak 10 kali pada hari yang berbeda. dari 10 kali percobaan hanya 1 kali web
crawler berhenti dikarenakan koneksi ke server SINTA yang mengalami gangguan.
Kesembilan percobaan yang dilakukan pada malam hari untuk menghindari koneksi
jaringan tidak stabil dan juga SINTA tidak sedang banyak diakses.
5.2 Saran
Beberapa saran yang dapat menjadi pertimbangan dalam penelitian selanjutnya ialah:
1. Untuk menerapkan system crawling sebaiknya dilakukan dengan
Multithreading untuk mempercepat proses secara parallel
2. Data yang sudah dikumpulkan dari penelitian ini lebih baik divisualisasikan
pada penelitian lanjutan.
3. Error handling diimplementasikan agar pada saat koneksi terputus, sistem
akan mengulangi request yang sama tanpa harus mendapatkan trigger manual
dari user.
UNIVERSITAS SUMATERA UTARA

36
DAFTAR PUSTAKA
Ahmat, J., Abdillah, L., & Suryayusra. 2014. Penerapan Teknik Web Scraping Pada
Mesin Pencari Artikel Ilmiah. Jurnal Sistem Informasi (SISFO), 159-164.
Bannayan, M., & Hoogenboom, G. 2008. Weather analogue: A tool for real-time
prediction of daily weather data realizations based on a modified k-nearest
neighbor approach. Environmental Modelling & Software, 703-713.
Chadegani, A. A., Salehi, H., Yunus, M. M., Farhadi, H., Fooladi, M., Farhadi, M., &
Ebrahim, N. A. 2013. A Comparison between Two Main Academic Literature
Collections:. Asian Social Science, 18-26.
Cope, B., & Phillips, A. 2009. The Future of the Academic Journal. London: Chandos
Publishing.
Coumou, D., & Rahmstorf, S. 2012. A decade of weather extremes. Potsdam Institute
for Climate Impact Research, 1-6.
Cover, T., & Hart, P. 1967. Nearest neighbor pattern classification. IEEE
Transactions on Information Theory, 21-27.
Gilbert., K., Sanchez-Marre., M., & Sevilla., B. 2012. Tools for Environmental Data
Mining and Intelligent Decision Support. International Congress on
Environmental Modelling and Software. Canada.
Griffiths, G. M., Chambers, L., & Hayloc, M. 2005. Change in mean temperature as a
predictor of extreme temperature change in the Asia–Pacific region.
International Journal of Climatology, 1301-1330.
Hegerl, G. 2006. Climate change detection and attribution: beyond mean temperature
signals. Journal of Climate , 5058-5077.
Ignatow, G., & Mihalcea, R. 2018. An Introduction to Text Mining. Texas: Sage
Publication.
Kedia, P. 2016. LOCALISED WEATHER MONITORING SYSTEM. International
Journal of Engineering Research and General Science Volume 4, Issue 2,, 315
- 322.
Keller, J. M., Gray, M. R., & Givens, A. J. 1985. A Fuzzy K-Nearest Neighbor
Algorithm. IEEE TRANSACTIONS ON SYSTEMS, MAN, AND
CYBERNETICS, 580-585.
UNIVERSITAS SUMATERA UTARA

37
Koduvely, M. 2015. Learning Bayessian Model With R. United Kingdom: Packt
Publisher.
Liao, Z., Peng, Y., & Liang, X. &. 2012. A Web Based Visual Analytics System for
Air Quality Monitoring Data. 22nd International Conference on
Geoinformatics, 1-6.
Ministry of Research, T. a. 2007 January 02. SINTA (Science and Technology Index).
Retrieved from Sinta FAQ: https://sinta2.ristekdikti.go.id/home/faq
Mitchell, R. 2015. Web Scraping with Python : Collecting Data From The Modern
Web. California: O'reilly.
R. Scott Granneman & Jans Carton. 2005. CSS Building Blocks : Selector.
Salam, R., Akhyar, M., Tayeb, A., & Niswaty, R. 2017. Peningkatan Kualitas
Publikasi Ilmiah Mahasiswa dalam Menunjang. Jurnal Office, 61-65.
Shahjahan, R. A., & Kezar, A. J. 2013. Beyond the “National Container”: Addressing
Methodological Nationalism in Higher Education Research. Educational
Researcher, 20-29.
Sharif, M., & Burn, D. H. 2006. Simulating climate change scenarios using an
improved K-nearest neighbor model. Journal of hydrology, 179-196.
Singh, A. M., Singh, B. J., & Varnica. 2014. Web Crawler: Extracting the Web Data.
International Journal of Computer Trends and Technology (IJCTT), 132-137.
Sinta Dikti, http://sinta2.ristekdikti.go.id/ affiliations/detail?id=441&view
=documentsscopus. Diakses tanggal 1 Agustus 2019.
Susmitha, P., & Bala, G. 2014. Design and Implementation of Weather Monitoring
and Controlling System. International journal of Computer applications, 97.
Taqyuddin, R., Rahmat, R. F., Nababan, E. B., & Purnamawati, S. 2017. Klasifikasi
Kualitas Udara Menggunakan Naive Bayes Classifier Pada Sistem
Terdistribusi Raspberry Pi Cluster Server. Medan: Universitas Sumatera
Utara.
Turland, M. 2010. Php|architect's Guide to Web Scraping. Marco Tabini &
Associates, Inc.
UNIVERSITAS SUMATERA UTARA

38
Turland, M. 2010. Php|architect's Guide to Web Scraping with PHP. United States:
php|architect press.
Vargiu, E., & Urru, M. 2013. Exploiting web scraping in a collaborative
filteringbased. Artificial Intelligence Research, 44-54.
Wood, L., Hors, A., Apparao, V., Byrne, S., Champion, M., Isaacs, S., & Jacobs, I.
1998. Document object model (dom) level 1 specification. W3C
recommendation 1.
UNIVERSITAS SUMATERA UTARA