rules untuk prediksi kewirausahaan theory of planned …
TRANSCRIPT

KERJA PRAKTIK – KI141330
Pembentukan Rules untuk Prediksi Kewirausahaan Mahasiswa berdasarkan Theory of Planned Behavior Gedung Departemen Teknik Informatika Jl. Teknik Kimia, Kampus Institut Teknologi Sepuluh Nopember Surabaya, Jalan Raya ITS, Sukolilo Surabaya 60111, Indonesia Periode: 1 Juni 2020 – 28 Agustus 2020
Oleh:
Ifta Jihan Nabila 05111740000034
Pembimbing Jurusan Diana Purwitasari, S.Kom., M.Sc. Pembimbing Lapangan Nova Rijati DEPARTEMEN TEKNIK INFORMATIKA Fakultas Teknologi Elektro dan Informatika Cerdas Institut Teknologi Sepuluh Nopember Surabaya 2020

ii
ii
[Halaman ini sengaja dikosongkan]

iii
iii
KERJA PRAKTIK – KI141330
Pembentukan Rules untuk Prediksi Kewirausahaan Mahasiswa berdasarkan Theory of Planned Behavior Gedung Departemen Teknik Informatika Jl. Teknik Kimia, Kampus Institut Teknologi Sepuluh Nopember Surabaya, Jalan Raya ITS, Sukolilo Surabaya 60111, Indonesia Periode: 1 Juni 2020 – 28 Agustus 2020
Oleh:
Ifta Jihan Nabila 05111740000034
Pembimbing Jurusan Diana Purwitasari, S.Kom., M.Sc. Pembimbing Lapangan Nova Rijati DEPARTEMEN TEKNIK INFORMATIKA Fakultas Teknologi Elektro dan Informatika Cerdas Institut Teknologi Sepuluh Nopember Surabaya 2020

iv
iv
[Halaman ini sengaja dikosongkan]

v
v
LEMBAR PENGESAHAN
KERJA PRAKTIK
Pembentukan Rules untuk Prediksi Kewirausahaan Mahasiswa
berdasarkan Theory of Planned Behavior
Oleh:
Ifta Jihan Nabila 05111740000034
Disetujui oleh Pembimbing Kerja Praktik:
1. Diana Purwitasari, S.Kom., M.Sc.
NIP. 197804102003122001
(Pembimbing Departemen)
2. Nova Rijati Ssi, M.Kom
Universitas Dian Nuswantoro
(Pembimbing Lapangan)

vi
vi
[Halaman ini sengaja dikosongkan]

vii
vii
Pembentukan Rules untuk Prediksi Kewirausahaan Mahasiswa
berdasarkan Theory of Planned Behavior
Nama Mahasiswa : Ifta Jihan Nabila
NRP : 05111740000034
Departemen : Teknik Informatika FTEIC-ITS
Pembimbing Jurusan : Diana Purwitasari, S.Kom., M.Sc.
ABSTRAK
Potensi kewirausahaan mahasiswa yang diidentifikasi secara
akurat dan dikelola secara optimal akan memberikan kontribusi yang
cukup signifikan pada pembangunan sosial dan ekonomi suatu bangsa.
Populasi mahasiswa berwirausaha yang sangat sedikit mengakibatkan
kondisi ketidakseimbangan kelas data yang berdampak pada
ketidakakuratan kinerja machine learning.
Pada penelitian ini mengusulkan sebuah teknik preprocessing
menggunakan kombinasi teknik sampling SMOTE-NC+IHT dengan
teknik seleksi atribut Information Gain untuk mengoptimalkan
pemanfaatan database perguruan tinggi nasional sehingga
menghasilkan dataset seimbang yang layak untuk teknik machine
learning.
Berdasarkan evaluasi hasil eksperimen, sebuah model yang
mengintegrasikan teknik sampling SMOTE-NC+IHT, metode
clustering K-Means dengan algoritma pembentukan rule J48 dapat
membangkitkan ruleset berdasarkan Theory of Planned Behavior
(TPB) dengan kinerja prediksi yang efektif.
Kata kunci: pembentukan rule, prediksi kewirausahaan

viii
viii
KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha
Esa karena atas berkat limpahan rahmat dan lindungan-Nya penulis
dapat melaksanakan salah satu kewajiban sebagai mahasiswa Teknik
Informatika ITS yaitu Kerja Praktik (KP).
Penulis menyadari masih terdapat banyak kekurangan baik
dalam pelaksanaan kerja praktik maupun penyusunan buku laporan
ini, namun kami berharap buku laporan ini dapat menambah wawasan
pembaca dan dapat menjadi sumber referensi. Penulis mengharapkan
kritik dan saran yang membangun untuk kesempurnaan penulisan
buku laporan ini.
Melalui laporan ini penulis juga ingin menyampaikan rasa
terima kasih kepada kepada orang-orang yang telah membantu dalam
pelaksanaan kerja praktik hingga penyusunan laporan Kerja praktik
baik secara lngsung maupun tidak langsung. Orang-orang tersebut
antara lain adalah:
1. Orang tua penulis,
2. Ibu Diana Purwitasari, S.Kom., M.Sc. selaku dosen
pembimbing kerja praktik yang telah membimbing penulis
selama kerja praktik berlangsung.
3. Bapak Ary Mazharuddin Shiddiqi, S.Kom., M.Comp.Sc.,
Ph.D selaku koordinator Kerja Praktik.
4. Ibu Nova Rijati selaku pembimbing lapangan selama kerja
praktik yang telah memberikan bimbingan serta ilmunya
kepada penulis.
Surabaya, Oktober 2020
Penulis

ix
ix
[Halaman ini sengaja dikosongkan]

x
x
DAFTAR ISI
ABSTRAK................................................................................... VII
KATA PENGANTAR ................................................................... VIII
DAFTAR ISI .................................................................................. X
DAFTAR TABEL .......................................................................... XII
DAFTAR GAMBAR .................................................................... XIII
BAB I PENDAHULUAN ...................................................................1 LATAR BELAKANG ....................................................................... 1 TUJUAN .................................................................................... 2 MANFAAT ................................................................................. 2 RUMUSAN PERMASALAHAN ......................................................... 2 LOKASI DAN WAKTU KERJA PRAKTIK .............................................. 3 METODOLOGI KERJA PRAKTIK ...................................................... 3 SISTEMATIKA LAPORAN ............................................................... 4
BAB II TINJAUAN PUSTAKA ...........................................................7 2.1 JUPYTER NOTEBOOK ................................................................... 7 2.2 ORANGE ................................................................................... 7 2.3 WEKA ..................................................................................... 7 2.4 THEORY OF PLANNED BEHAVIOR ................................................... 7 2.5 TEKNIK SAMPLING ...................................................................... 8 2.5.1 OVERSAMPLING ......................................................................... 8 2.5.2 UNDERSAMPLING ....................................................................... 9 2.6 K-MEANS CLUSTERING ................................................................ 9

xi
xi
2.7 ALGORITMA PEMBUATAN RULES ................................................ 10 2.7.1 RULE-BASED CLASSIFIER ............................................................. 10 2.7.2 DECISION TREE ........................................................................ 11
BAB III METODOLOGI PENELITIAN ............................................... 13 3.1 DATA ..................................................................................... 13 3.2 LANGKAH ANALISIS .................................................................. 15
BAB IV HASIL DAN PEMBAHASAN ............................................... 18 4.1 PRA-PROSES DATA ................................................................... 18
4.1.1 Penghapusan Kolom ................................................ 18 4.1.2 Pengisian Missing Values ........................................ 18 4.1.3 Penghapusan Data Tidak Relevan........................... 19 4.1.4 Pelabelan (Diskritisasi) ............................................ 19
4.2 CLUSTERING ............................................................................ 21 4.3 PENANGANAN DATA TIDAK SEIMBANG ....................................... 23 4.4 SELEKSI FITUR.......................................................................... 26 4.5 VERIFIKASI TEKNIK SAMPLING DAN KLASIFIKASI ........................... 27 4.6 PEMBUATAN RULES ................................................................. 28 4.7 VALIDASI MODEL ..................................................................... 33
BAB V KESIMPULAN DAN SARAN ................................................ 37
DAFTAR PUSTAKA ...................................................................... 38
BIODATA PENULIS ...................................................................... 40

xii
xii
DAFTAR TABEL
Tabel 1. Nama Kolom pada Data ..................................................... 13 Tabel 2. Diskritisasi .......................................................................... 19 Tabel 3. Skenario Clustering ............................................................ 21 Tabel 4. Hasil Undersampling .......................................................... 24 Tabel 5. Rata-Rata AUC tiap Skenario ............................................ 27 Tabel 6. Hasil Ujicoba Skenario Kedua ........................................... 31 Tabel 7. Rules Prediksi untuk Data 01 ............................................. 32 Tabel 8. Rules Prediksi untuk Data 02 ............................................. 33 Tabel 9. Performa Rules Prediksi untuk Data 01 ............................. 34 Tabel 10. Performa Rules Prediksi untuk Data 02 ........................... 35

xiii
xiii
DAFTAR GAMBAR
Gambar 1. 4 Cluster Terbentuk ........................................................ 22 Gambar 2. Perbandingan Metode Sampling ..................................... 25 Gambar 3. Perbandingan Performa Algoritma dari 3 Skenario ........ 29

xiv
xiv
[Halaman ini sengaja dikosongkan]

1
1
BAB I
PENDAHULUAN
Latar Belakang
Agar dapat mengenali potensi dan mengembangkan
minat kewirausahaan mahasiswa secara optimal, pemangku
kepentingan perlu memahami dan mempunyai pengetahuan
tentang faktor-faktor yang berpengaruh terhadap minat
kewirausahaan mahasiswa. Salah satu pendekatan yang
cocok untuk memahami perilaku kewirausahaan adalah
Theory of Planned Behavior (TPB). Penelitian perilaku
kewirausahaan di kalangan mahasiswa menunjukkan bahwa
variabel yang ada pada TPB yang disertai dengan
pendidikan kewirausahaan memberikan pengaruh yang
positif dan signifikan terhadap peningkatan minat
kewirausahaan mahasiswa yang pada akhirnya mampu
membentuk sikap kewirausahaan. Faktor lain yang
mempengaruhi jiwa kewirausahaan adalah sikap dan
karakteristik individu.
Dengan menumbuhkan minat
kewirausahaan, diharapkan potensi kewirausahaan
mahasiswa berkembang secara optimal sehingga
berkontribusi pada pembangunan sosial dan ekonomi suatu
bangsa.

2
2
Tujuan
Tujuan dalam pelaksanaan kerja praktik kali ini yaitu
sebagai berikut:
Mempelajari pengaruh proses akademik yang dinamis
terhadap minat kewirausahaan
Pembentukan algoritma pembangkit aturan untuk
memprediksi potensi kewirausahaan mahasiswa
Pembentukan aturan pada data yang tidak seimbang yang
diperoleh dari database akademik
Melakukan komparasi untuk menentukan algoritma
pembangkit aturan terbaik
Manfaat
Berikut manfaat yang diperoleh melalui kerja praktik:
Dapat memudahkan perguruan tinggi untuk menentukan
potensi kewirausahaan dari tiap mahasiswa
Dapat memudahkan perguruan tinggi dalam memberikan
pembekalan tentang wirausaha kepada mahasiswa secara
efektif dan efisien
Rumusan Permasalahan
Berikut rumusan masalah dalam pelaksanaan kerja
praktik:
Bagaimana menerapkan metode clustering pada data
yang tidak seimbang?

3
3
Bagaimana menentukan algoritma pembangkit aturan
terbaik untuk prediksi potensi wirausaha?
Lokasi dan Waktu Kerja Praktik
Kerja praktik kali ini dilaksanakan pada waktu dan
tempat sebagai berikut:
Lokasi : Gedung Departemen Teknik Informatika
Alamat : Jl. Teknik Kimia, Kampus Institut Teknologi
Sepuluh Nopember Surabaya, Jalan Raya
ITS, Sukolilo Surabaya 60111, Indonesia
Waktu : 1 Juni 2020 – 28 Agustus 2020
Metodologi Kerja Praktik
1.6.1 Perumusan Masalah
Untuk mengetahui bagaimana penanganan data yang
tidak seimbang serta dilakukannya teknik clustering dan
menentukan algoritma terbaik untuk membuat aturan
prediksi potensi wirausaha mahasiswa. Penjelasan oleh
pembimbing lapangan kerja praktik kali ini menghasilkan
beberapa catatan mengenai gambaran secara garis besar
tentang metode yang harus dilakukan untuk mengolah data
dan menerapkan beberapa algoritma pembangkit aturan.
Setelah itu dilakukan diskusi lebih lanjut untuk memberikan
referensi terkait metode yang akan diterapkan.

4
4
1.6.2 Studi Literatur
Pada tahap ini, setelah menentukan metode yang akan
diterapkan, bahasa pemrograman sampai dengan teknologi
beserta tools tambahan yang digunakan, dilakukan studi
literatur lanjut mengenai bagaimana penggunaannya dalam
menerapkan metode-metode tersebut.
Bahasa pemrograman yang digunakan yaitu Python
dengan menggunakan Jupyter Notebook untuk pembuatan
codenya. Beberapa library juga digunakan untuk
menjalankan beberapa metode seperti numpy, pandas,
imblearn, dan sklearn. Tools lain yang digunakan yaitu
Orange dan WEKA.
1.6.3 Metodologi Penelitian
Tahap ini dilakukan untuk menyiapkan atau mengolah
data sebelum dilakukannya teknik clustering. Praproses
data dilakukan dengan mengolah data seperti seleksi fitur
serta pengisian missing values. Penanganan data yang tidak
seimbang juga diterapkan menggunakan library imblearn.
Sistematika Laporan
Laporan kerja praktik ini terdiri dari 5 bab dengan
rincian sebagai berikut:

5
5
1. Bab I: Pendahuluan
Bab ini berisi tentang latar belakang masalah, tujuan,
manfaat, rumusan masalah, lokasi dan waktu kerja praktik,
metodologi, dan sistematika laporan.
2. Bab II: Tinjauan Pustaka
Dalam bab ini dibahas mengenai konsep-konsep
pembuatan model, dasar teori, teknologi yang dipakai dalam
pembuatan model.
3. Bab III: Metodologi Penelitian
Bab ini membahas mengenai metode penelitian yang
akan dilakukan.
4. Bab IV: Hasil dan Pembahasan
Dalam bab ini akan dibahas tentang proses serta hasil
dari penerapan metode serta pembahasan analisa yang
dilakukan terhadap hasil yang terbentuk.
7. Bab V: Kesimpulan dan Saran
Bab ini berisi tentang kesimpulan dan saran yang
didapatkan selama kerja praktik.

6
6
[Halaman ini sengaja dikosongkan]

7
7
BAB II
TINJAUAN PUSTAKA
2.1 Jupyter Notebook
Jupyter Notebook merupakan aplikasi web open-source
yang memungkinkan pengguna untuk membuat dan berbagi
dokumen yang berisi live code, persamaan, visualisasi, dan
teks naratif.
2.2 Orange
Orange Data Mining merupakan platform Data
Analytics, yang mengedepankan Visual Programming (Free
Coding), dan dibuat oleh tim dari University of Ljubljana
dan Jožef Stefan Institute pada tahun 1996.
2.3 WEKA
WEKA merupakan perangkat lunak open-source untuk
machine learning yang telah dicoba dan diuji yang dapat
diakses melalui antarmuka pengguna grafis, aplikasi
terminal standar, atau API Java.
2.4 Theory of Planned Behavior
Theory of Planned Behavior (TPB) yang merupakan
pengembangan dari Theory of Reasoned Action (TRA)
(Ajzen dalam Jogiyanto, 2007). Jogiyanto (2007)
Mengembangkan teori ini dengan menambahkan konstruk
yang belum ada di TRA. Konstruk ini di sebut dengan
kontrol perilaku persepsian (perceived behavioral control).

8
8
Konstruk ini ditambahkan di TPB untuk mengontrol
perilaku individual yang dibatasi oleh kekurangan-
kekurangannya dan keterbatasan-keterbatasan dari
kekurangan sumber-sumber daya yang digunakan untuk
melekukan perilakunya (Hsu and Chiu 2002).
2.5 Teknik Sampling
2.5.1 Oversampling
Oversampling merupakan suatu teknik untuk
mengatasi ketidakseimbangan kelas pada dataset.
Oversampling dilakukan dengan menggandakan
sampel atau menambah data sintesis baru dari kelas
minoritas. Metode yang digunakan dalam penelitian
ini adalah SMOTE-NC dari library imblearn.
SMOTE merupakan teknik yang berdasarkan
tetangga terdekat yang dihitung berdasarkan
Euclidean Distance antara titik data di ruang fitur.
SMOTE-NC digunakan untuk tipe fitur Nominal dan
Kontinu, yang berguna untuk membuat data sintetis
untuk fitur kategorikal dan kuantitatif dalam
kumpulan data. SMOTE-NC sedikit mengubah cara
sampel baru dihasilkan dengan melakukan sesuatu
yang spesifik untuk fitur kategorikal. Kategori sampel
yang baru ditentukan dengan memilih kategori yang
paling sering muncul dari tetangga terdekat yang ada
selama pembuatan.

9
9
2.5.2 Undersampling
Undersampling adalah proses membuang
sebagian data dari kelas mayoritas, sehingga jumlah
kelas mayoritas mendekati kelas minoritas. Metode
yang digunakan dalam penelitian ini adalah Cluster
Centroids, Condensed Nearest Neighbour, Edited
Nearest Neighbours, Repeated Edited Nearest
Neighbours, AllKNN, Instance Hardness Threshold,
Near Miss, One Sided Selection, Random Under
Sampling, dan Tomek Links. Metode-metode
undersampling tersebut terdapat di dokumentasi
library imblearn.
2.6 K-Means Clustering
K-Means Clustering adalah suatu metode penganalisaan
data atau metode Data Mining yang melakukan proses
pemodelan tanpa supervisi (unsupervised) dan merupakan
salah satu metode yang melakukan pengelompokan data
dengan sistem partisi. Metode K-Means Clustering
bertujuan untuk meminimalisasikan objective function yang
diset dalam proses clustering dengan cara meminimalkan
variasi antar data yang ada di dalam suatu cluster dan
memaksimalkan variasi dengan data yang ada di cluster
lainnya.
Algoritma untuk melakukan K-Means clustering adalah
sebagai berikut:

10
10
1. Tentukan berapa banyak cluster k dari dataset yang
akan dibagi.
2. Tetapkan secara acak data k menjadi pusat awal lokasi
cluster.
3. Untuk masing-masing data, temukan cluster centroid
terdekat. Dengan demikian, masing-masing cluster
centroid memiliki sebuah subset dari dataset,
sehingga mewakili bagian dari dataset. Oleh karena
itu, telah terbentuk cluster k: C1, C2, C3, …, Ck.
4. Untuk masing-masing cluster k, temukan center dari
area cluster, dan perbarui lokasi dari masing-masing
cluster centroid ke nilai baru dari center area cluster.
5. Ulangi langkah ke-3 dan ke-5 hingga data-data pada
tiap cluster menjadi terpusat atau selesai.
2.7 Algoritma Pembuatan Rules
2.7.1 Rule-based classifier
Rule-based classifier hanyalah jenis
pengklasifikasi lain yang membuat keputusan kelas
bergantung dengan menggunakan berbagai aturan
"if..else". Kondisi yang digunakan dengan "IF"
disebut anteseden dan kelas yang diprediksi dari
setiap aturan disebut konsekuen. Pada penelitian ini
algoritma yang digunakan yaitu PART, OneR dan
RIPPER yang telah disediakan pada tools WEKA.

11
11
2.7.2 Decision Tree
Decision Tree adalah salah satu algoritma
supervised pada machine learning. Algoritma ini
dapat digunakan untuk masalah regresi dan
klasifikasi - namun, sebagian besar digunakan untuk
masalah klasifikasi. Decision Tree mengikuti
sekumpulan kondisi if-else untuk
memvisualisasikan data dan mengklasifikasikannya
sesuai dengan kondisi. Pada penelitian ini algoritma
yang digunakan yaitu J48 dan REPTree yang telah
disediakan pada tools WEKA.

12
12
[Halaman ini sengaja dikosongkan]

13
13
BAB III
METODOLOGI PENELITIAN
Pada bab ini membahas tentang metode apa saja yang
dilakukan dalam melakukan penelitian.
3.1 Data
Data yang digunakan adalah daftar mahasiswa
Universitas Dian Nuswantoro Tahun Angkatan 2009 hingga
2014. Data ini berasal dari database pendidikan tinggi
Indonesia yang disediakan oleh Kementerian Riset,
Teknologi, dan Pendidikan Tinggi Indonesia. Data ini
memiliki jumlah baris sebanyak 350 data dan 33 kolom
dengan detil nama kolom dapat dilihat pada Tabel 1. Serta
dari 350 data, terdapat 27 mahasiswa yang menjadi
Entrepreneur. Tabel 1. Nama Kolom pada Data
No Kolom No Kolom No Kolom
1 No 12 IPK (A6) 23 IPS 3
2 NIM 13 B.Indo (A7) 24 IPS 4
3 Nama 14 B.Inggris (A8) 25 IPS 5
4 Prodi 15 Met.Penel (A9) 26 IPS 6
5 Saintek/Soshum 16 Etika Profesi
(A10) 27 IPS 7
6 SEX 17 Bimb. Karir
(A11) 28 IPS 8

14
14
7 Status Beasiswa
(A1) 18
Kewirausahaan
(A12) 29 IPS 9
8 Status Aktivis
(A2) 19
Status Ink.
Bisnis (A13) 30 IPS 10
9 Jalur Masuk (A3) 20 Status PKM
(A14) 31 IPS 11
10 Pekerjaan Ortu
(A4) 21 IPS 1 32 IPS 12
11 Penghasilan Ortu
(A5) 22 IPS 2 33
Lama
Studi
Data tersebut memiliki 14 kolom yang merupakan unsur
variabel TPB. Untuk kolom A1-A3 merupakan unsur
Attitude (Att). Sedangkan kolom A4-A6 merupakan unsur
Subjective Norms (SN). Dan untuk unsur Perceived
Behavioral Control (PBC) ada pada kolom A7-A14.
Kolom-kolom yang ada pada dataset memberikan
gambaran yang mendekati proses pendidikan di suatu
perguruan tinggi. Sejumlah 3 kolom yaitu A1, A2 dan A3
mendiskripsikan sikap-sikap yang mempengaruhi aktivitas
entrepreneurial, relevan dengan variabel Att. Sejumlah 9
(64%) kolom yaitu A4 sampai dengan A12 mendiskripsikan
proses belajar di perguruan tinggi, relevan dengan variabel
SN. Sejumlah 2 (14%) kolom yaitu A13 dan A14
mendeskripsikan aktivitas mahasiswa dalam kegiatan-

15
15
kegiatan kewirausahaan yang terprogram dan difasilitasi
pihak perguruan tinggi, relevan dengan variabel PBC.
3.2 Langkah Analisis
Langkah analisis yang dilakukan pada penelitian ini
adalah sebagai berikut:
1. Melakukan pra proses data:
Penghapusan kolom yang tidak perlu digunakan
Pengisian missing values
Melakukan penghapusan data pada data yang tidak
relevan
Melakukan pelabelan (diskritisasi) terhadap value
pada beberapa kolom dengan bobot yang telah
ditentukan
2. Melakukan teknik clustering menggunakan metode K-
Means dengan beberapa skenario menggunakan
kombinasi fitur sebagai berikut:
Semua fitur yang merupakan unsur TPB (A1-A14)
Fitur Attitude (Att)
Fitur Subjective Norms (SN)
Fitur Perceived Behavioral Control (PBC)
Fitur Attitude (Att) dan Perceived Behavioral Control
(PBC)
Fitur Subjective Norms (SN) dan Perceived
Behavioral Control (PBC)

16
16
Fitur Attitude (Att) dan Subjective Norms (SN)
3. Melakukan penanganan data yang tidak seimbang
meggunakan beberapa metode dari library imblearn
4. Melakukan seleksi fitur dengan menggunakan Orange
5. Melakukan verifikasi teknik sampling dengan berbagai
metode klasifikasi menggunakan Orange dengan
beberapa skenario sebagai berikut:
Semua fitur yang merupakan unsur TPB (A1-A14)
(Data 01)
5 fitur terbaik hasil seleksi fitur (Data 02)
5 fitur terbaik tanpa fitur #1 dari hasil seleksi fitur
(Data 03)
6. Membuat rules untuk prediksi menggunakan WEKA dari
beberapa dataset sebagai berikut :
Semua fitur yang merupakan unsur TPB (A1-A14)
(Data 01)
5 fitur terbaik hasil seleksi fitur (Data 02)
5 fitur terbaik tanpa fitur #1 dari hasil seleksi fitur
(Data 03)
Penambahan fitur A14 pada Data 03 (Data 04)
Penambahan fitur A2 pada Data 03 (Data 05)
7. Melakukan validasi pada model yang terbentuk
berdasarkan nilai coverage dan accuracy.

17
17
[Halaman ini sengaja dikosongkan]

18
18
BAB IV
HASIL DAN PEMBAHASAN
Pada bab ini membahas tentang hasil dari implementasi
yang telah dilakukan berdasarkan langkah analisis yang telah
ditentukan.
4.1 Pra-proses Data
4.1.1 Penghapusan Kolom
Tahap pertama yang dilakukan pada pra-proses
yaitu penghapusan kolom yang tidak perlu
digunakan untuk langkah selanjutnya. Berikut ini
daftar kolom yang akan dihapus :
NIM
Nama
Saintek/Soshum
SEX
IPS 8
IPS 9
IPS 10
IPS 11
IPS 12
4.1.2 Pengisian Missing Values
Terdapat beberapa missing values pada kolom
IPS 1 hingga IPS 7 pada dataset. Pengisian missing
values dilakukan dengan cara menghitung rata-rata
IPS pada Prodi mahasiswa yang bersangkutan
tersebut.

19
19
4.1.3 Penghapusan Data Tidak Relevan
Penghapusan data dilakukan pada data yang tidak
relevan, yakni data mahasiswa yang memiliki lama
studi di bawah 7 semester. Jumlah data pada dataset
setelah dilakukannya penghapusan yaitu sebanyak
277 baris.
4.1.4 Pelabelan (Diskritisasi)
Tahap pra-proses terakhir sebelum dilakukan
clustering adalah diskritisasi. Pelabelan bertujuan
untuk mengonversi nilai string yang ada pada kolom
menjadi nilai diskrit agar memudahkan dalam proses
clustering. Tabel 2 menunjukkan nilai diskrit/bobot
untuk setiap value yang ada pada kolom yang
memiliki unsur TPB.
Tabel 2. Diskritisasi
TP
B
Va
ria
bel
Kode Kriteria Diskritisasi
. A
ttit
ud
e
A1 Status Beasiswa
Scholarship (Sch) 1
Non-scholarship
(NonSch)
0.5
A2 Status Aktivis Activists (Act) 1
Non-activists (NonAct) 0.5
A3 Jalur Masuk Non-reguler (NR) 1
AVG > 7.0 (AVG) 0.8

20
20
TP
B
Va
ria
bel
Kode Kriteria Diskritisasi
Regular Test (RT) 0.6
Transfer (T) 0.4
Moving (M) 0.2
Su
bje
ctiv
e N
orm
s
A4 Pekerjaan Ortu
Entrepreneur (Entre) 1
Non-entrepreneur
(NonEntre)
0.5
A5 Penghasilan
Ortu
> 10 million (P1) 1
7 – 10 million (P2) 0.8
5 – 7 million (P3) 0.6
3 – 5 million (P4) 0.4
< 3 million (P5) 0.2
A6 IPK
Cumlaude (C) 1
Highly Satisfactory (HS) 0.75
Satisfying (S) 0.5
Good (G) 0.25
Nilai Mata Kuliah
A7 B.Indo A
B
C
D
E
1
0.8
0.6
0.4
0.2
A8 B.Inggris
A9 Met. Penel
A10 Etika Profesi
A11 Bimb. Karir
A12 Kewirausahaan
Per
ceiv
ed
Beh
avio
ral
Co
ntr
ol
A13 Status Ink.
Bisnis
member 1
non member 0.5
A14 Status PKM
Excellent (E) 1
Funded (F) 0.67
Proposing (P) 0.33

21
21
4.2 Clustering
Clustering dilakukan dengan menggunakan metode K-
Means. K-Means akan diterapkan pada dataset yang
menggunakan kolom dengan unsur TPB saja, yaitu kolom
dengan kode A1 hingga A14. Clustering dilakukan dengan
menggunakan 7 skenario dengan k-cluster yaitu 4. Tabel 3
menunjukkan skenario yang dipakai beserta silhouette score
yang diperoleh.
Tabel 3. Skenario Clustering
Skenario Fitur Score
1 Semua Fitur (A1-A14) 0.144
2 Attitude 0.69
3 SN 0.2
4 PBC 0.946
5 Attitude + PBC 0.4038
6 SN + PBC 0.173
7 Attitude + SN 0.16
Dapat dilihat bahwa clustering menggunakan semua
fitur (skenario 1) ternyata memiliki silhouette score
terendah (0.14), dengan kata lain skenario ini menghasilkan
pengelompokan data yang buruk, sehingga kurang layak
digunakan sebagai dataset eksperimen selanjutnya.
Sedangkan clustering pada skenario 4 (fitur PBC) dan
skenario 2 (fitur Attitude) berturut-turut memiliki silhouette

22
22
score 0.95 dan 0.65. Karena jumlah fitur pada skenario 4
dan 2 terlalu sedikit, maka fitur atau kombinasi fitur yang
terpilih sebagai dataset eksperimen selanjutnya adalah
skenario 5 (fitur Attitude+PBC) yang memiliki silhouette
score = 0.40 sehingga cukup layak sebagai dataset
eksperimen selanjutnya.
Setelah menentukan skenario untuk kombinasi fitur,
dilakukan eksperimen kedua untuk menentukan k terbaik
pada metode K-Means. Eksperimen dilakukan dengan
menggunakan nilai k = 2 hingga k = 6 untuk melihat
pembentukan cluster terbaik berdasarkan konsistensi
pengelompokan data serta melihat sebaran anggota cluster.
Berdasarkan eksperimen, dengan melihat silhouette score
dan sebaran data mahasiswa entrepreneur, clustering terbaik
dicapai untuk nilai k=4.
Gambar 1. 4 Cluster Terbentuk

23
23
Gambar 1 menunjukkan data setelah dilakukan
clustering menggunakan metode K-Means dengan k = 4.
Dari 4 cluster data yang terbentuk, data entrepreneur
sebagian besar tersebar pada C1 (10 mahasiswa) dan C3 (12
mahasiswa) serta sebagian kecil sisanya berada di C2 (4
mahasiswa) dan C4 (1 mahasiswa).
4.3 Penanganan Data Tidak Seimbang
Tahap selanjutnya yaitu untuk menyeimbangkan data
dengan teknik sampling untuk mencapai rasio yang
diinginkan antara kelas Entrepreneur dan Not-Entrepreneur
yaitu 1:2. Dari proses clustering sebelumnya, dapat dilihat
bahwa C1 dan C3 memiliki data entrepreneur yang lebih
banyak dibandingkan dengan C2 dan C4. Sehingga akan
dilakukan tahap menghasilkan data sintesis baru untuk
cluster data entrepreneur pada C1 dan C3.
Penghasilan data sintesis dilakukan dengan teknik
oversampling menggunakan metode SMOTE-NC yang
akan menghasilkan 30 data entrepreneur baru untuk C1 dan
28 data entrepreneur baru untuk C3. Sehingga data
entrepreneur pada C1 dan C3 masing-masing terdapat 40
data. Dataset yang ada sekarang memiliki jumlah 335 data
dengan komposisi Entrepreneur sebanyak 85 data dan Not-
Entrepreneur sebanyak 250 data (1:2.9).

24
24
Rasio pada kelas Status Entrepreneur belum mencapai
perbandingan 1:2, sehingga tahap selanjutnya yaitu
dilakukan teknik undersampling. Undersampling dilakukan
terhadap data Not-Entrepreneur dengan menggunakan 10
teknik undersampling dari library imblearn. Tabel 4
menunjukkan hasil ujicoba menggunakan 10 metode dan
rasio yang didapat.
Tabel 4. Hasil Undersampling
Metode undersampling yang berhasil menurunkan
jumlah data not-entrepreneur sehingga mencapai ratio 1:2
terhadap data entrepreneur adalah dengan menggunakan
metode CC, ENN, IHT, NM, dan RUS, dengan sebaran 4
cluster data yang seimbang seperti pada Gambar 2.
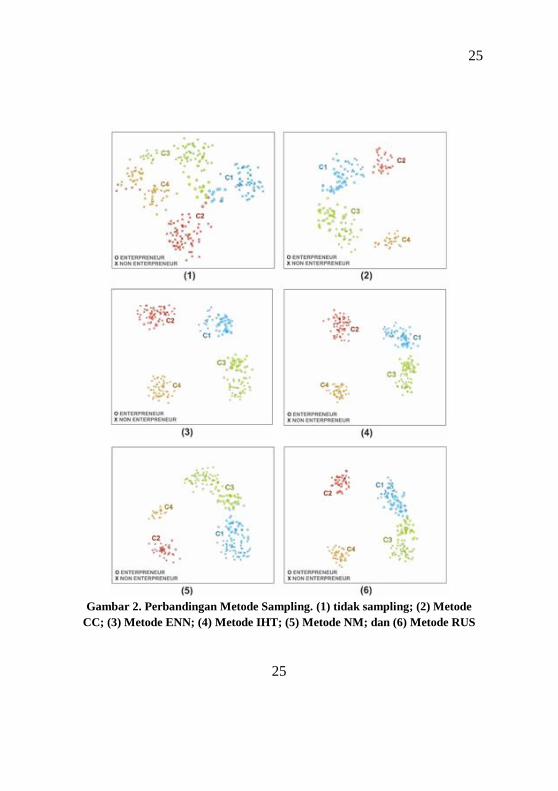
25
25
Gambar 2. Perbandingan Metode Sampling. (1) tidak sampling; (2) Metode
CC; (3) Metode ENN; (4) Metode IHT; (5) Metode NM; dan (6) Metode RUS

26
26
Gambar 2 menunjukkan cluster yang terbentuk pada saat
sebelum sampling dan setelah dilakukan sampling. Secara
visual, hasil dua teknik sampling mampu menghasilkan 4
cluster yang benar-benar terpisah satu dengan lainnya, yaitu
dengan metode IHT (Gambar 2 (4)) dan ENN (Gambar 2
(3)). Sedangkan teknik sampling yang lain menghasilkan
cluster yang masih terdapat banyak data yang terpisah dan
dekat dengan cluster selain clusternya.
4.4 Seleksi Fitur
Proses seleksi fitur yang dilakukan menggunakan tools
Orange pada dataset bertujuan untuk mengetahui fitur-fitur
terpenting pada variabel-variabel TPB yang mempengaruhi
status kewirausahaan mahasiswa (entrepreneur/not-
entrepreneur) yang nantinya digunakan sebagai
pertimbangan dalam penentuan rules terbaik.
Digunakan metode Information Gain pada Orange untuk
membantu dalam melakukan perankingan untuk fitur A1
hingga A14. Didapatkan 5 fitur tertinggi yaitu Etika Profesi
(A10), Status Ink. Bisnis (A13), Bimb. Karir (A11), Jalur
Masuk (A3), dan IPK (A6). Lima fitur terserbut
menunjukkan bahwa semua unsur variabel TPB, yaitu Att
(A3); SN (A6, A10, A11); dan PBC (A13) mempunyai
pengaruh yang signifikan terhadap status kewirausahaan
mahasiswa.

27
27
4.5 Verifikasi Teknik Sampling dan Klasifikasi
Setelah dilakukan proses seleksi fitur, maka tahap
selanjutnya yaitu untuk melakukan ujicoba ke dalam
beberapa metode klasifikasi k-NN (k=5), Decision Tree,
SVM, Random Forest, MLP, Naive Bayes, dan Logistic
Regression.
Pada tahap ini dilakukan klasifikasi dengan
menggunakan beberapa skenario yaitu:
Semua fitur yang merupakan unsur TPB (A1-A14) (Data
01)
5 fitur terbaik hasil seleksi fitur (Data 02)
5 fitur terbaik tanpa fitur #1 dari hasil seleksi fitur (Data
03)
Tabel 5. Rata-Rata AUC tiap Skenario
Data 01 Data 02 Data 03
CC 0.92 0.78 0.78
ENN 0.96 0.86 0.86
IHT 0.96 0.86 0.86
NM 0.94 0.78 0.79
RUS 0.95 0.83 0.84
Untuk setiap skenario dataset dilakukan klasifikasi
menggunakan 7 metode klasifikasi dimana setiap metode
dilakukan Stratified Cross Validation dengan 10 folds.

28
28
Tabel 5 menunjukkan hasil dari ujicoba klasifikasi untuk
ketiga skenario dengan berbagai metode undersampling
yaitu CC, ENN, IHT, NM, dan RUS. Hasil pada Tabel 5
yaitu rata-rata AUC dari 7 metode klasifikasi yang
dilakukan.
Dari 3 skenario dataset tersebut, dapat dilihat bahwa 2
teknik sampling menggunakan SMOTE-NC+IHT dan
SMOTE-NC+ENN konsisten menghasilkan nilai rata-rata
AUC tertinggi pada 3 skenario tersebut.
4.6 Pembuatan Rules
Setelah menentukan teknik sampling yang paling sesuai
untuk dilanjutkan ke tahap selanjutnya, maka eksperimen
dilanjutkan dengan pembuatan rules. Pada tahapan kali ini,
5 algoritma pembuatan rules yang digunakan yaitu PART,
OneR, RIPPER, J48, dan REPTree menggunakan tools
WEKA.
Pembuatan rules ini akan dijalankan di 5 dataset yang
berbeda, yaitu:
Semua fitur yang merupakan unsur TPB (A1-A14) (Data
01)
5 fitur terbaik hasil seleksi fitur (Data 02)
5 fitur terbaik tanpa fitur #1 dari hasil seleksi fitur (Data
03)
Penambahan fitur A14 pada Data 03 (Data 04)

29
29
Penambahan fitur A2 pada Data 03 (Data 05)
Eksperimen pembuatan rules ini dilakukan dalam 3
skenario. Skenario pertama untuk dataset original (tidak
menggunakan teknik sampling), skenario kedua untuk
dataset yang disampling dengan metode SMOTE-NC+IHT
sedangkan skenario ketiga untuk dataset yang disampling
dengan metode SMOTE-NC+ENN.
Gambar 3. Perbandingan Performa Algoritma dari 3 Skenario

30
30
Gambar 3 menunjukkan hasil ujicoba rata-rata performa
algoritma pembuatan rules untuk pada ketiga skenario
tersebut.
Berdasarkan perbandingan kinerja algoritma pembuatan
rules pada tiga skenario, dapat dilihat bahwa pada Gambar
3 (2) memiliki performa yang baik pada berbagai kriteria
kinerja yang ditunjukkan dengan nilai rata-rata yang relatif
tinggi pada accuracy, precision, recall, F-measure, G-mean
dan AUC dengan disertai nilai RMSE yang relatif rendah.
Dari ketiga skenario tersebut, skenario kedua memiliki
kinerja yang konsisten.
Setelah didapatkan skenario yang terbaik, Tabel 6
menunjukkan hasil performa menggunakan 5 metode
pembuatan rules. Hasil terbaik didapatkan dengan
menggunakan algoritma J48 dikarenakan kinerjanya yang
stabil dengan nilai rata-rata pada semua aspek kinerja yang
relatif lebih baik serta hasil yang lebih konsisten pada semua
jenis dataset dibanding dengan algoritma yang lain. Akurasi
terbaik dengan menggunakan algoritma J48 pada skenario
kedua dicapai pada Data 01 dan Data 02 dengan akurasi
masing-masing 90% dan 89.6%.
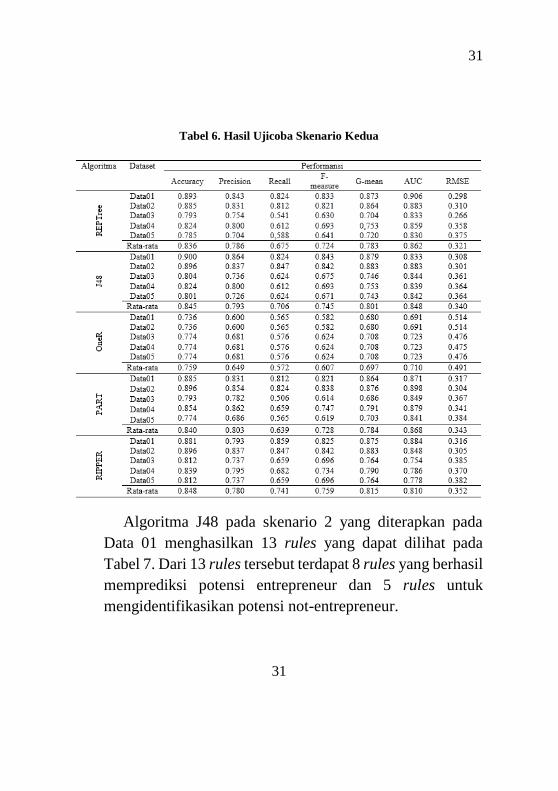
31
31
Tabel 6. Hasil Ujicoba Skenario Kedua
Algoritma J48 pada skenario 2 yang diterapkan pada
Data 01 menghasilkan 13 rules yang dapat dilihat pada
Tabel 7. Dari 13 rules tersebut terdapat 8 rules yang berhasil
memprediksi potensi entrepreneur dan 5 rules untuk
mengidentifikasikan potensi not-entrepreneur.

32
32
Tabel 7. Rules Prediksi untuk Data 01
Sedangkan untuk algoritma J48 pada skenario 2 yang
diterapkan pada Data 02 menghasilkan 4 rules yang dapat
dilihat pada Tabel 8. Dari keempat rules tersebut, terdapat 2
rules untuk memprediksi potensi entrepreneur dan 2 rules
untuk mengidentifikasikan potensi not-entrepreneur.

33
33
Tabel 8. Rules Prediksi untuk Data 02
4.7 Validasi Model
Rules yang terbentuk akan divalidasi menggunakan nilai
coverage dan accuracy. Tabel 9 menunjukkan bahwa
algoritma J48 pada skenario 2 menggunakan Data 01
berhasil memprediksi 30.26% data masuk ke potensi
entrepreneur, dan memprediksi 69.74% data masuk ke
potensi not-entrepreneur.
Dan untuk prediksi potensi entrepreneur, rata-rata
akurasi seluruh rules adalah 95.49%. Hasil prediksi potensi
not-entreprenueur memiliki rata-rata akurasi seluruh rules
adalah 97. 95%. Rule R1 memiliki akurasi 95.87%. Yang
berarti, dari 121 data not-entrepreneur ada 116 data
(95.87%) yang berhasil benar diprediksi sebagai not-
entrepreneur. Sedangkan untuk Rule R2 memiliki akurasi
100%, artinya 22 data di Rule R2 berhasil diprediksi
seluruhnya sebagai potensi entrepreneur. Nilai coverage
dan akurasi dari masing-masing rules dapat dilihat pada
Tabel 9.

34
34
Tabel 9. Performa Rules Prediksi untuk Data 01
Sedangkan untuk eksperimen pada Data 02, Tabel 10
menunjukkan bahwa eksperimen ini berhasil memprediksi
32.95% data masuk ke potensi entrepreneur, dan
memprediksi 67.65% data masuk ke potensi not-
entrepreneur. Untuk akurasi rata-rata seluruh rules yang
dapat memprediksi potensi entrepreneur adalah 87.65%,
sedangkan rata-rata akurasi prediksi non-entrepreneur
adalah 90.53%.
Potensi Rule Coverage Akurasi
Entrepreneur
R2 8.43% 100.00%
R3 4.21% 100.00%
R4 1.53% 75.00%
R8 3.45% 88.89%
R9 5.36% 100.00%
R11 0.77% 100.00%
R12 1.53% 100.00%
R13 4.98% 100.00%
Not-
Entrepreneur
R1 46.36% 95.87%
R5 1.53% 100.00%
R6 18.77% 93.88%
R7 1.15% 100.00%
R10 1.93% 100.00%

35
35
Tabel 10. Performa Rules Prediksi untuk Data 02
Algoritma J48 pada Data 01 mampu membuat ruleset
dengan tingkat akurasi prediksi yang lebih tinggi juga
mengandung potensi error data pada masing-masing rule
prediksi status entrepreneur yang lebih besar. Sedangkan
untuk Data 02, meskipun menghasilkan tingkat akurasi
prediksi yang lebih rendah, namun juga mengandung
potensi error data pada masing-masing rule prediksi status
entrepreneur lebih rendah juga.
Potensi Rule Coverage Akurasi
Entrepreneur
R2 7.66% 95.00%
R4 25.29% 80.30%
Not-
Entrepreneur
R1 46.36% 95.87%
R3 20.69% 85.19%

36
36
[Halaman ini sengaja dikosongkan]

37
37
BAB V
KESIMPULAN DAN SARAN
Kesimpulan yang didapat dari hasil analisis ujicoba pada
penelitian ini dapat dijabarkan sebagai berikut:
Pada permasalahan dataset dengan unsur variabel TPB
yang tidak seimbang, dari eksperimen yang telah
dilakukan menggunakan beberapa skenario
menunjukkan bahwa teknik sampling SMOTE-NC+IHT
dan SMOTE-NC+ENN merupakan teknik sampling
yang paling optimal.
Untuk pembuatan ruleset, algoritma J48 pada dataset 14
fitur dengan akurasi 97.95% dan pada dataset 5 fitur
dengan akurasi 90.53% menghasilkan ruleset dengan
tingkat kinerja yang paling optimal.
Perbedaan kinerja pada 2 ruleset tersebut tidak terlalu
signifikan, sehingga model dapat dikatakan cukup
adaptif meskipun diterapkan pada dataset yang berbeda.
Saran yang dapat dilakukan untuk penelitian selanjutnya
yaitu untuk menggunakan data yang memiliki fitur yang lebih
banyak dan jumlah data yang lebih banyak, sehingga dapat
memanfaatkan penggunaan big data pada penelitian ini.

38
38
DAFTAR PUSTAKA
[1] Jupyter.org. (2019). Project Jupyter. [online] Available at:
https://jupyter.org/ [Accessed 1 Nov. 2020].
[2] Ljubljana, B.L., University of (n.d.). Documentation.
[online] orange.biolab.si. Available at:
https://orange.biolab.si/docs/ [Accessed 1 Nov. 2020].
[3] Data, D. (2019). Membuat Model Image Classification tanpa
Skill Programming dengan Orange Data Mining. [online]
Medium. Available at:
https://medium.com/@danau.data/membuat-model-image-
classification-tanpa-skill-programming-dengan-orange-data-
mining-3fdf5344be31 [Accessed 1 Nov. 2020].
[4] Waikato.ac.nz. (2019). Weka 3 - Data Mining with Open
Source Machine Learning Software in Java. [online] Available
at: https://www.cs.waikato.ac.nz/ml/weka/ [Accessed 1 Nov.
2020].
[5] idtesis.com. (2018). Teori Lengkap tentang Theory Planned
Behaviour (TPB) menurut Para Ahli dan Contoh Tesis Theory
Planned Behaviour (TPB) – Jasa Pembuatan Skripsi dan Tesis
0852.25.88.77.47 (WA). [online] Available at:
https://idtesis.com/teori-lengkap-tentang-theory-planned-
behaviour-tpb-menurut-para-ahli-dan-contoh-tesis-theory-
planned-behaviour-tpb/ [Accessed 1 Nov. 2020].

39
39
[6] Aguilar, F. (2019). SMOTE-NC in ML Categorization
Models fo Imbalanced Datasets. [online] Medium. Available at:
https://medium.com/analytics-vidhya/smote-nc-in-ml-
categorization-models-fo-imbalanced-datasets-8adbdcf08c25
[Accessed 1 Nov. 2020].
[7] imbalanced-learn.readthedocs.io. (n.d.). Welcome to
imbalanced-learn documentation! — imbalanced-learn 0.5.0
documentation. [online] Available at: https://imbalanced-
learn.readthedocs.io/en/stable/index.html [Accessed 1 Nov.
2020].
[8] GeeksforGeeks. (2020). Rule-Based Classifier - Machine
Learning. [online] Available at:
https://www.geeksforgeeks.org/rule-based-classifier-machine-
learning/ [Accessed 1 Nov. 2020].
[9] Towards AI (2020). Decision Trees Explained With a
Practical Example. [online] Towards AI. Available at:
https://towardsai.net/p/programming/decision-trees-explained-
with-a-practical-example-fe47872d3b53 [Accessed 1 Nov.
2020].

40
40
BIODATA PENULIS
Ifta Jihan Nabila, lahir pada tanggal 26
Juni 1999 di Kendal. Penulis
merupakan mahasiswa yang sedang
menempuh studi di Departemen
Informatika Institut Teknologi
Sepuluh Nopember (ITS). Penulis aktif
dalam berorganisasi yaitu pada
Himpunan Mahasiswa Teknik
Computer-Informatika (HMTC) tahun 2020 sebagai Bendahara.
Selain sedang aktif dalam Himpunan, penulis juga merupakan
peserta Virtual Exchange Asia University tahun 2020.