klasifikasi kategori dan identifikasi topik pada artikel...
TRANSCRIPT

Klasifikasi Kategori dan Identifikasi Topik pada Artikel Berita Berbahasa Indonesia
Tugas Akhir KI91391
Dosen Pembimbing:Dr. Agus Zainal Arifin, S. Kom, M. Kom
Penyusun:Aini Rachmania
51071000771

Pendahuluan
2

Latar Belakang Berita Laporan mengenai fakta atau ide terbaru yang benar,dan atau
penting bagi sebagian besar khalayak, melalui media berkala seperti surat kabar, radio, televisi, atau media online internet. (Siti, 2009)
Aliran informasi yang dinamis (Bracewell, 2009)
Karakter berita: Jumlah data besar Satu berita dengan berita lainnya berbeda Topik baru terus muncul
Dibutuhkan: Klasifikasi berita untuk memudahkan navigasi berita
3

4

Algoritma yang Umumnya Digunakan
5
Support Vector Machine Dapat diimplementasikan secara mudah (Nugroho, 2003) Sulit dipakai dalam problem berskala besar (Nugroho, 2003) Proses pembelajaran lambat (Bracewell, 2009) Harus dilatih ulang pada saat terjadi penambahan data (Princea, 2010)
Naive Bayesian Hasilnya cukup baik untuk sebagian kasus Ukuran vektor fitur yang dibutuhkan cukup besar (Johanes, 2006) Fitur – fitur data training harus disimpan (Bracewell, 2009)

Algoritma yang Digunakan
6
Topic Analysis
Diusulkan oleh David B. Bracewell, Jiajun Yan, Fuji Ren dan Shingo Kuroiwa pada tahun 2009 pada paper yang berjudul “Category Classification and Topic Discovery of Japanese and English News Articles”
Tidak memerlukan online training
Membagi proses menjadi dua tahap: klasifikasi kategori dan identifikasi topik

Hirarki BeritaEdukasi
Beasiswa
Ujian Nasional
SNMPTN
Sertifikasi Guru
Pendidikan Agama
Bisnis & Ekonomi
Investasi
Saham
Praktik Dumping
Pajak
7

Permasalahan Bagaimana membangun aplikasi yang mampu menglasifikasikan
kategori berita tanpa harus melakukan online training Bagaimana membangun sebuah aplikasi yang dapat
mengidentifikasi topik dari sebuah berita yang ada
Tujuan Membuat sebuah aplikasi yang dapat menglasifikasikan berita ke
kategori yang sesuai dan menemukan topik dari berita tersebut
8

Gambaran umum aplikasi
9

Corpus Dokumen
Berita Training
Kategori
Topik
Klasifikasi Kategori
Identifikasi Topik10
Perhitungan Likelihood
Perhitungan Threshold
Seleksi Kategori
Perhitungan CosSim
Seleksi t dengan CosSim terbesar
Perhitungan threshold
Seleksi topik menggunakant
hreshold
DataBase Dokumen
Berita
DataBase Kamus dan
Stoplist
Database Kata Kunci
Preprocess
Ekstraksi Kata Kunci

Training
11
Case Folding
Filtering
Eliminasi Stopword
Stemming
Weighting
Keywords Extraction

Klasifikasi Kategori
12
Pengambilan Kata Kunci pada
Database
Perhitungan Likelihood
Perhitungan Rata –rata dan standard
Deviasi
Seleksi kategori

Identifikasi Topik
13
Perhitungan CosSim
Seleksi CosSim
Terbesar
Perhitungan Threshold
Seleksi Topik

Contoh CorpusSelasa, 19 April 2011
KOMPETISI
UI Juara Kompetisi Bisnis di Paris
DEPOK, KOMPAS.com - Tim Universitas Indonesia (UI) berhasil menjadi juaradunia setelah mengalahkan tujuh negara lainnya, yaitu Algeria, China,Czech Republic, Portugal, Romania, Rusia, dan Amerika Serikat di ajangkompetisi bisnis internasional tingkat mahasiswa Trust by Danone diParis, Perancis, 4-6 April 2011. Para finalis diwajibkan berperan sebagaijajaran direksi untuk membuat perencanaan strategis di suatu negara danmempresentasikan solusi mereka dalam bahasa Inggris di hadapan dewanjuri. -- Vishnu Juwono Tim UI terdiri dari Ekky Gompa, Ivan Cahyadi,Shanty Debora, Stevenlie Satryaputra dari FEUI dan Chandra Satria Mudadari FTUI. Kelimanya tergabung dalam tim Jayawijaya yang mempresentasikanWay in Doing Business melalui media video kreatif dan sebuah objek padababak International Final. Mereka juga diuji secara ketat dalam memahamifilosofi bisnis yang tidak hanya mengejar profit tetapi juga kontribusiterhadap lingkungan dan sosial.Adapun kompetisi simulasi bisnis initerdiri dari empat babak, yaitu seleksi CV, Trust Day, Country Final, danInternational Final.
14

Klasifikasi Kategori (Offline)
15

Identifikasi Topik (Offline)
16

Thresholding topik
17Uji Coba

Identifikasi kata (Filtering)
Eliminasi Stopwords Penghilangan kata – kata yang dianggap tidak berkontribusi banyak pada isi dokumen (Yates dan Neto, 1999) Jenis kata yang termasuk stoplist adalah: Kata depan Kata ganti Kata hubung Kata sandang
“ “\t\n\r\f\’\”\\1234567890!@#$%^&*()_+-{}|[]:;<,>.?/`~
18

StemmingTerms Frekuensi
Fira 1gemar 1memasak 1masakannya 1lezat 1
Terms FrekuensiFira 1gemar 1masak 2lezat 1
sebelum stemming
sesudah stemming
19

Confix Stripping Stemmer
[ DP + [ DP + [ DP ] ] ] Kata-Dasar [ [+DS] [+PP] [+P] ]
Formula Kata berimbuhan :
[ DP + [ DP + [ DP ] ] ] Kata-Dasar [ [+DS] [+PP] [+P] ]//// / /Alur stemming-1 :
[ DP + [ DP + [ DP ] ] ] Kata-Dasar [ [+DS] [+PP] [+P] ]//// / /Alur stemming-2 :
DP = Derivation Prefix (awalan “me-”, “be-”, “pe-”, “te-”, “di-”, “ke-”, “se-”)
DS = Derivation Suffix (akhiran “-i”, “-kan”, “-an”)
PP = Possesive Pronoun (kata ganti kepunyaan “-ku”, “-mu”, “-nya”)
P = Partikel (“-kah”, “-lah”, “-tah”, “-pun”)
Keterangan:
20
Weighting
=
jijij df
Ntfw 2log.
Pada setiap term, diberikan pembobotan TF-IDF :
Keterangan:wij = bobot term j pada dokumen itfij = frekuensi kemunculan term j pada dokumen iN = jumlah keseluruhan dokumen yang diprosesdfj = jumlah dokumen yang memiliki term j
Terms FrekuensiFira 1gemar 1
masak 2lezat 1
21

Ekstraksi kata kunci Setiap dokumen yang telah selesai distemming diambil
keseluruhan termsnya Terms dokumen diberi bobot menggunakan TFIDF 10-15 terms terbaik diambil dan dikumpulkan menjadi kata
kunci untuk kategori dan topik
22
Perhitungan Likelihood
cj = kategori
A = artikel
k = keywords
23
Kata Kunci Dokumen
Uji c1 c2 c3 c4 c5 c6 c7 c8 c9
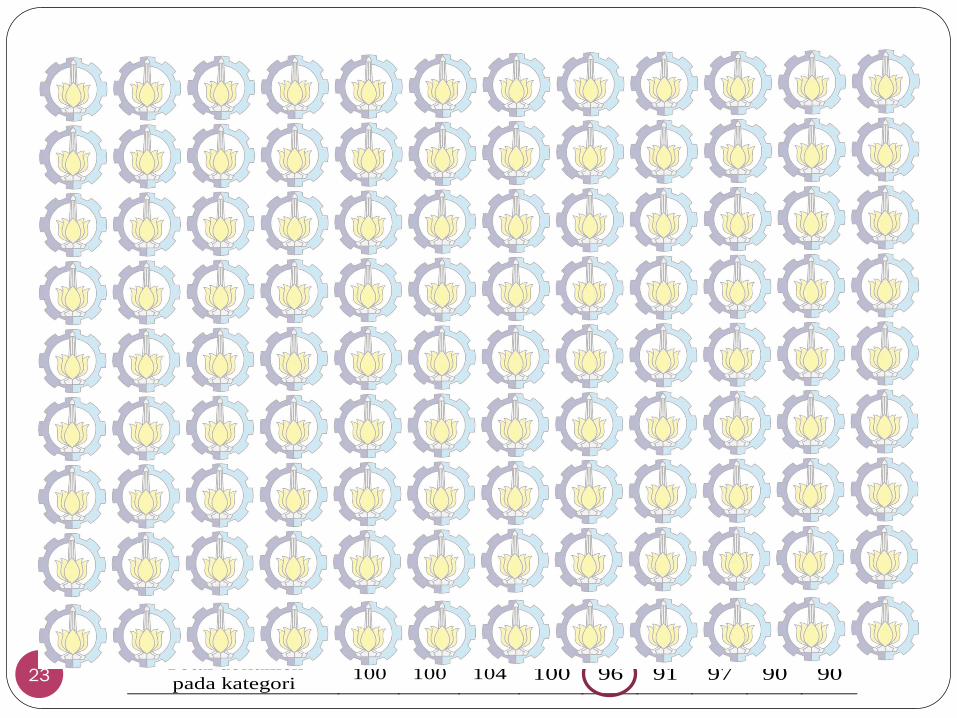
k1 saham 0 0 0 0 3 0 0 0 0 k2 TBK 0 0 0 0 1 0 0 0 0 k3 mega 0 0 0 0 0 1 0 0 0 k4 top 0 0 0 0 0 0 0 0 0 k5 IHSG 0 0 0 0 2 0 0 0 0 k6 sektor 0 1 1 0 3 1 0 0 0 k7 indeks 0 0 0 0 2 0 0 0 0 k8 naik 0 0 1 0 4 0 1 0 0 k9 persen 0 1 0 0 6 3 0 3 1 k10 peringkat 0 0 0 0 0 0 0 2 0
Total dokumen pada kategori 100 100 104 100 96 91 97 90 90

Perhitungan Likelihood (lanjutan)
24
Kata Kunci P(kata kunci | kategori) log2(P) P* log2(P) saham 0,03125 -1,50515 -0,0470359 tbk 0,01041 -1,98227 -0,0206487 mega 0 0 0 top 0 0 0 ihsg 0,02083 -1,68124 -0,0350259 sektor 0,03125 -1,50515 -0,0470359 indeks 0,02083 -1,68124 -0,0350259 naik 0,04167 -1,38021 -0,0575088 persen 0,0625 -1,20411 -0,0752575 peringkat 0 0 0 saham 0,03125 -1,50515 -0,0470359 Nilai Likelihood 0,317538551

Perhitungan ThresholdL = likelihood seluruh kategori yang ada
li = likelihood untuk kategori i
25
Likelihood-Mean (Likelihood – Mean)2 Likelihood1 - Mean -0,068489938 0,004690872 Likelihood2 – Mean -0,028489938 0,000811677 Likelihood3 – Mean -0,029700835 0,00088214 Likelihood4 – Mean -0,068489938 0,004690872 Likelihood5 – Mean 0,249048614 0,062025212 Likelihood6 – Mean -0,046776132 0,002188007 Likelihood7 – Mean 0,023420427 0,000548516 Likelihood8 – Mean -0,048007755 0,002304745 Likelihood9 - Mean 0,017485493 0,000305742
Mean 0,068489938 Sum 0,078447781 |L| 9 Sum / |L| 0,00871642 Standard Deviasi 0,09336177 Threshold 0,161851708
Algoritma Identifikasi Topik1. Transformasikan kata kunci dokumen dan topik ke dalam vector-
space model yang sama
2. rumus:
ti = topik ke-i
A = artikel
26
Topik Kurs 5
Dollar 10
Saham 3
Kurs 5
Dollar 10
Saham 3
Valuta 0
Artikel Valuta 2
Kurs 3
Dollar 7
Kurs 3
Dollar 7
Saham 0
Valuta 2

3. Hitung nilai NewTSim menggunakan rumus:
4. Bandingkan CosSim topik awal dengan kedua threshold:(i) CosSim(tc,A) > 0.1 AND CosSim(tc,A) > NewTSim(tc,A)
(ii) NumTopics > 10 CosSim(tc,A) AND > (2 × StdDev(AllTopicSims) +Mean(AllTopicSims))
5. Bila topik awal memenuhi kedua threshold, maka topik awal ditetapkan.Bila topik awal memenuhi <= 1 threshold, masukkan topik baru.
27

Uji Coba Perangkat Lunak
28

Uji Coba Aplikasi Tujuan:
Pencarian parameter optimal: Jumlah Kata Kunci Nilai threshold topik Performa Parser (tambahan)
Dokumen Testing:
29
Kategori Jumlah Dokumen Nasional 10 Regional 11
Internasional 11 Metropolitan 10
Bisnis dan Ekonomi 11 Olahraga 11
Sains dan Teknologi 11 Edukasi 10
Pariwisata 10 Total 95

Uji Coba Kata Kunci
30
Jumlah kata kunci yang diambil : 5, 10, 15, 20
Diujikan pada dua kondisi: offline dan online

Uji Coba Kata Kunci (lanjutan)
31
Hasil uji coba offline :
Keyword = 5 Keyword = 10 Keyword = 15 Keyword = 20
Precision Precision Precision Precision
Kategori
Bisnis & Ekonomi 0,667 0,571 0,933 0,929
Edukasi 0,588 0,467 0,600 0,733
Internasional 0,286 0,563 0,563 0,563
Metropolitan 0,214 0,154 0,231 0,231
Nasional 0,952 0,947 0,947 1,000
Olahraga 0,846 0,923 1,000 1,000
Pariwisata 1,000 0,933 0,933 1,000
Regional 1,000 1,000 1,000 1,000
Sains & Teknologi 0,818 1,000 0,909 1,000

Uji Coba Kata Kunci (lanjutan)
32
Hasil uji coba offline :
Keyword = 5 Keyword = 10 Keyword = 15 Keyword = 20
Recall Recall Recall Recall Kategori Bisnis & Ekonomi 0,667 0,727 0,737 0,765
Edukasi 0,909 0,875 0,900 0,917
Internasional 1,000 1,000 0,900 1,000
Metropolitan 0,429 0,400 0,500 0,600
Nasional 0,952 0,947 0,947 0,950
Olahraga 1,000 1,000 1,000 1,000
Pariwisata 0,400 0,389 0,452 0,467
Regional 0,348 0,390 0,390 0,390
Sains & Teknologi 0,643 0,733 0,769 0,786

Uji Coba Kata Kunci (lanjutan)
33
Hasil uji coba offline :
90.00%
90.50%
91.00%
91.50%
92.00%
92.50%
93.00%
93.50%
94.00%
94.50%
5 10 15 20
Rata - Rata Akurasi
Rata - Rata Akurasi
K ATA KUNCI YANG DIEKSTRAKSI
AKURASI

Uji Coba Kata Kunci (lanjutan)
34
Hasil Uji Coba Online
91.80%
92.00%
92.20%
92.40%
92.60%
92.80%
93.00%
93.20%
93.40%
93.60%
93.80%
94.00%
5 10 15 20
Rata - Rata Akurasi
Rata - Rata Akurasi
K ATA KUNCI YANG DIEKSTRAKSI
AKURASI

Uji Coba parameter threshold
35
Pada identifikasi topik, parameter nilai ambang CosSimditentukan 0,1
Jumlah kta kunci yang diambil 20
Nilai threshold diuji coba pada nilai 0.1, 0.2, 0.3, dan 0.4

Hasil Uji Coba Identifikasi Topik
36
92.00%
93.00%
94.00%
95.00%
96.00%
97.00%
98.00%
0.1 0.2 0.3 0.4
Akurasi
Akurasi
AKURASI
T H R E S H O L D

Uji Coba Parser
37
Menemukan kesalahan – kesalahan pada parser
Hasil uji coba:
Tipe Kesalahan Contoh Kasus Kesalahan Seharusnya
Pembacaan karakter HTML 2.0
> > — — " ̎ ldquo; “
Dokumen tidak terunduh sempurna
Dokumen hanya terunduh hingga
pertengahan berita
Dokumen terunduh secara lengkap
hingga akhir berita

Evaluasi
38
Performa aplikasi meningkat seiring bertambahnya kata kunci yang diekstraksi
Jumlah kata kunci yang dapat menghasilkan nilai akurasi optimal adalah 20
Akurasi tertinggi klasifikasi offline: 93,82%
Akurasi tertinggi klasifikasi online: 93,84%
Akurasi tertinggi identifikasi topik : 97,26%
Parameter nilai threshold klasifikasi optimal adalah 0,3

Simpulan dan Saran
39

Kesimpulan
40
Algoritma terbukti mampu melakukan klasifikasi kategori dan identifikasi topik dokumen berita berbahasa Indonesia dengan akurasi 93,84%
Performa algoritma berkaitan erat dengan jumlah kata kunci yang diambil pada saat ekstraksi kata kunci

Saran
41
Riset lebih dalam untuk algoritma ekstraksi kata kunci
Riset untuk mengurangi waktu running time
Ground truth kategori sebaiknya saling lepas
Riset lebih dalam untuk parser

42
Terima Kasih