bab 3 analisa dan perancangan sistem 1.1 analisa...
TRANSCRIPT

23
BAB 3
ANALISA DAN PERANCANGAN SISTEM
1.1 Analisa Masalah
Mesin pencari yang sudah ada dan banyak digunakan saat ini
memberikan hasil perolehan pencarian yang banyak (banyak dokumen yang
terambil), sehingga diperlukan waktu untuk menentukan hasil pencarian yang
relevan. Menentukan hasil yang relevan sesuai dengan keinginan user dengan
jumlah hasil pencarian yang banyak akan menyulitkan user. Selain itu,
dokumen yang tidak mengandung queri dari inputan user tidak akan
ditampilkan walaupun makna queri dari user dengan yang ada di dalam
dokumen sama. Sehingga memungkinkan banyaknya dokumen tidak relevan
yang terambil.
Penelitian ini tidak hanya menggunakan metode cosine similiarity
untuk mengukur kemiripan query dengan koleksi resensi buku, tetapi juga
menggunakan Wordnet untuk mengukur semantic similarity antar kata
(term).
1.2 Desain Sistem
Berikut adalah desain system pada penelitian ini, dimulai dari document
collecting, preprocessing yang meliputi Case Folding, Tokenizing, Filtering,
dan Stemming, kemudian dilakukan proses indeks term (kata). Hasil proses
indeks akan disimpan dalam file txt selanjutnya akan dilakukan proses hitung
similaritas antar dokumen dengan query serta mengukur keterkaitan makna
antar kata berdasarkan korpus WordNet, kemudian hasil tersebut ditampilkan
pada halaman hasil pencarian. Output yang dihasilkan adalah resensi buku
yang relevan dengan kata kunci yang diinputkan pengguna.

24
Gambar 0.1 Desain Sistem Sistem Pencari Resensi Buku
1.3 Data Penelitian
Data yang digunakan dalam penelitian ini merupakan data resensi buku
yang didapat dari hasil crawling secara manual terhadap website
buku.enggar.net, www.lensabuku.com, dan www.koran-jakarta.com. Data
yang dikumpulkan berjumlah 250 resensi buku. Data resensi buku disimpan
dalam bentuk korpus berformat .txt. Berikut contoh data resensi buku seperti
pada Tabel 3.1.
Tabel 0.1 Contoh Data Resensi Buku
Manajemen Diri yang Baik Bantu Raih Kesuksesan
Meraih kesuksesan dalam hidup merupakan cita-cita setiap manusia. Hanya,
setiap manusia memiliki jalan sukses masing-masing. Namun semua perlu
memiliki kemampuan manajemen diri yang baik. Pada banyak kesempatan,
manajemen diri akan membantu menyelesaikan banyak pekerjaan dalam waktu
terbatas.
Judul : Listful Thinking
Penulis : Paula Rizzo
Penerbit : Tiga Serangkai

25
Terbit : Cetakan 1, 2016
Tebal : 216 halaman
Meraih kesuksesan dalam hidup merupakan cita-cita setiap manusia. Hanya,
setiap manusia memiliki jalan sukses masing-masing. Namun semua perlu
memiliki kemampuan manajemen diri yang baik. Pada banyak kesempatan,
manajemen diri akan membantu menyelesaikan banyak pekerjaan dalam waktu
terbatas.
Namun tidak dipungkiri, sifat keterbatasan manusia khususnya dalam daya ingat
menjadikan penghalang, sehingga banyak agenda, tugas, dan pekerjaan
terlewatkan. Salah satu cara meminimalkan kekurangan tersebut orang perlu
membuat daftar tugas atau pekerjaan.
Daftar ini akan memaksimalkan manajemen, sehingga hidup lebih efektif dan
produktif. Buku ini menarasikan secara cermat dan menyeluruh cara membuat
daftar tugas yang baik serta efektif. Buku bersumber dari pengalaman penulis di
berbagai perjalanan karier mulai dari produser program kesehatan senior
FoxNews.com, Fox Channel, hingga pendirian situs ListProducer.com. Karier
Paula semakin sempurna kala meriah pemenang Emmy Award.
Manfaat paling nyata daftar tugas dan pekerjaan, menjauhkan dari rasa gelisah,
meningkatkan kekuatan otak, fokus, rasa percaya diri, dan sistematika pikiran
(hal 12). Selain itu, Dr Gail Mathews, profesor di Dominican University of
California, menuliskan target berkontribusi terhadap 33 persen keberhasilan.
Menurut Paula ada beberapa tahap membuat daftar tugas agar efektif. Misalnya,
diawali dengan menuliskan tugas atau pekerjaan sebagai pengingat saat lupa
tugas. Gunakan kalimat tindakan bukan keterangan saat membuat daftar.
Tulislah daftar secara bebas, tanpa terlalu risau dengan format atau urutan
tertentu. Tulis saja sesuai keinginan (hal 52).
Kemudian sistemkan daftar tersebut. Lalu dibagi dalam beberapa kategori seperti
pekerjaan, rumah, dan anak-anak. Pengklasifikasian ini untuk mencegah
kebingungan saat akan mengeksekusi tugas. Buatlah daftar berbeda untuk tuga

26
lain. Cara ini akan memudahkan memahami situasi. Buatlah prioritas, bisa
berdasarkan waktu tenggat atau pentingnya tugas tersebut (hal 54).
Lakukan evaluasi daftar kembali. Bisa jadi ada beberapa yang kurang penting
telah masuk daftar. Dalam membuat daftar tugas harus realistis sesuaikan dengan
kemampuan dan potensi diri. Jangan terlalu memaksakan kehendak. Realistis itu
tidak mudah. Jadikan daftar yang jelas dan spesifik. Ini akan membantu
mempermudah serta mengefisiensikan tugas.
Tentukan tenggat waktu dari setiap daftar tugas dan selalu ingatkan baik dengan
catatan kecil atau alarm. Letakkan catatan tugas di setiap tempat atau area yang
sering dikunjungi, sehingga selalu ingat tugas. Dengan begitu kita akan lebih
produktif memanfaatkan waktu dan tenaga (hal 59).
Buku ini menyajikan manajemen diri tidak hanya secara teoritis. Ada beragam
tips dan kisah pada setiap bab sehingga padu padan antara teori dan praktik.
Selain itu, metode ini sudah banyak diaplikasikan. Di antaranya, Marissa Mayer,
CEO Yahoo.
1.4 PreProcessing Data
Tahapan preprocessing yang digunakan dalam penelitian ini adalah
case folding, tokenizing, filtering, dan stemming. Skema sistem yang akan
dibangun sesuai dengan Gambar 3.1.
Gambar 0.2 Skema Preprocessing Data

27
1.4.1 Case Folding
Case Folding yaitu mengubah semua huruf dalam dokumen menjadi huruf
kecil. Karakter selain huruf akan dihilangkan dan dianggap delimiter.
Gambar 0.3 Skema Case Folding
1.4.2 Tokenizing
Tokenizing yaitu tahap pemotongan atau pemecahan kalimat berdasarkan
tiap kata yang menyusunnya.
Gambar 0.4 Skema Tokenizing
1.4.3 Filtering
Filtering yaitu tahap mengambil kata-kata penting dari hasil tahap
tokenizing. Filtering dapat dilakukan dengan menghilangkan stoplist atau stopword
(kata-kata yang tidak memiliki nilai deskriptif).
Gambar 0.5 Skema Filtering
Data yang dibutuhkan dalam proses menghilangkan Stop Word merupakan
data Stop word list. Stop word list berisi 758 kata bahasa Indonesia dan disimpan
ke dalam bentuk .txt. Data stopword list didapat dari site github.com/masdevid/ID-
Stopwords. Tabel 3.2 berikut merupakan contoh dari stop word list:

28
Tabel 0.2 Contoh Stop Word List
No Stop Word Lists
1 abstrak
2 abstraksi
3 ada
4 adalah
5 adanya
6 adapun
1.4.4 Stemming
Stemming yaitu sebuah proses untuk menemukan kata dasar dari sebuah
kata. Proses Stemming digunakan untuk mengubah term yang masih melekat dalam
term tersebut awalan, sisipan, dan akhiran. Proses stemming dilakukan dengan cara
menghilangkan semua imbuhan (affixes) baik yang terdiri dari awalan (prefixes),
sisipan (infixes), akhiran (suffixes) dan confixes (kombinasi dari awalan dan
akhiran) pada kata turunan. Stemming digunakan untuk mengganti bentuk dari
suatu kata menjadi kata dasar dari kata tersebut yang sesuai dengan struktur
morfologi bahasa Indonesia yang benar.
Gambar 0.6 Skema Stemming
Data yang dibutuhkan untuk proses stemming adalah data kata dasar. Data
kata dasar sudah tersedia bersama dengan library sastrawi. Data tersebut berisi
30.139 kata dasar berbahasa Indonesia dan disimpan dalam bentuk .txt. Tabel 3.3
berikut merupakan contoh data kata dasar:
Tabel 0.3 Contoh Kata Dasar
No Kata Dasar
1 aba
2 aba-aba

29
3 abad
4 abadi
5 abadiah
6 abah
1.5 Indexing
Setelah Tahap preprocessing, tahap selanjutnya yaitu pengindeksan
(indexing) untuk mempercepat proses pencarian. Term disimpan dalam dua file txt,
file yang menyimpan frekuensi term (file index) dan file yang menyimpan
document frekuensi dari term (file df). Tabel 3.4 merupakan contoh struktur file
yang menyimpan frekuensi term (file index).
Tabel 0.4 Contoh struktur file index
Term Nama document Frequency
Orang 5W1H.txt 2
Sukses 5W1H.txt 1
Bantu 5W1H.txt 4
hidup 5W1H.txt 8
Sedangkan struktur file yang menyimpan document frekuensi dari term (file df)
dapat dilihat pada Tabel 3.5 dibawah ini:
Tabel 0.5 Contoh Struktur File df
Term df
Orang 20
Sukses 15
Bantu 45
hidup 10
1.6 Term Weighting
Term wieighting yang digunakan dalam penelitian ini adalah TF-IDF atau
Term Frequency (TF) dan Inverse Document Frequency (IDF). TF-IDF merupakan
dasar dari skema pembobotan istilah yang paling populer di pemerolehan informasi.
Perhitungan term frequency (𝑡𝑓) dan Inverse Document Frequency (𝑖𝑑𝑓),
menggunakan persamaan (3) dan persamaan (4) pada bab 2.
30
Perhitungan 𝑖𝑑𝑓𝑖 digunakan untuk mengetahui banyaknya term yang dicari
(𝑑𝑓) yang muncul dalam dokumen lain yang ada pada korpus [1]. Berikut adalah
skema proses Term Weighting pada Gambar 3.6.:
Gambar 0.7 Skema Proses Term Weighting
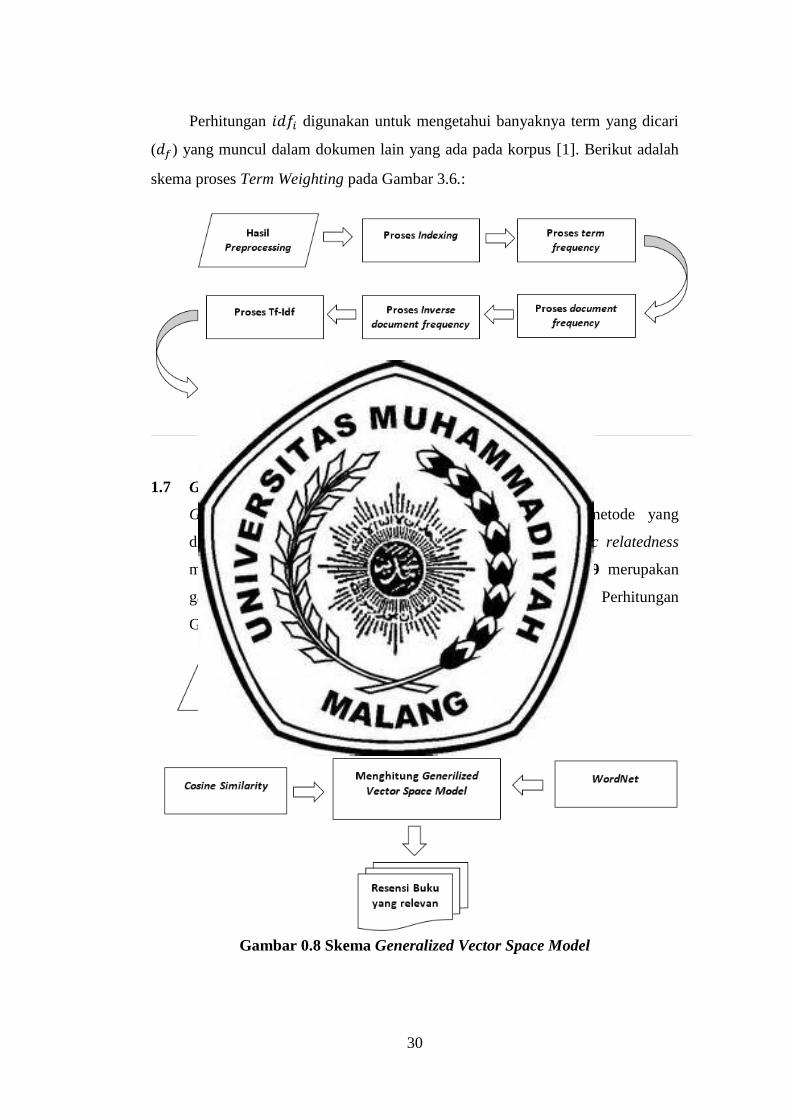
1.7 Generalized Vector Space Model (GVSM)
Generalized Vector Space Model (GVSM) merupakan metode yang
digunakan untuk menggabungkan hasil perhitungan semantic relatedness
menggunakan WOrdNet dan cosine similarity. Gambar 3.9 merupakan
gambar proses Generalized Vector Space Model (GVSM). Perhitungan
GVSM menggunakan persamaan (6) pada bab 2.
Gambar 0.8 Skema Generalized Vector Space Model

31
1.8 Perhitungan Cosine Similarity
Perhitungan cosine similarity dilakukan setelah proses pembobotan TF-IDF.
Cosine similarity berperan penting dalam perangkingan resensi buku berdasarkan
input query dari user. Perhitungan cosine similarity dapat menggunakan perumusan
(1) pada bab 2.
Gambar 0.9 Skema Proses Cosine Similarity
1.9 WordNet Bahasa
WordNet Bahasa digunakan dalam menghitung kemiripan semantik antar
term. Data WordNet Bahasa didapat dari http://wn-msa.sourceforge.net/.
Data yang digunakan hanya kategori bahasa dan Indonesia, serta goodness
yang digunakan Y (hand checked and good), O (automatic high quality
(good)) dan M (automatic medium quality (ok)). Sehingga jumlah data yang
didapat sebanyak 122.988 baris. Untuk menghitung kemiripan semantic
menggunakan perumusan semantic relatedness pada bab 2 persamaan (7),
(8), dan (9) berdasarkan situasi antar term terhadap WordNet Bahasa. Hasil
perhitungan tersebut akan berpengaruh pada resensi buku yang ditampilkan.
Berikut contoh data WordNet.
Tabel 0.6 Data WordNet Bahasa
00001740-a B O berdaya
00001740-a B O keahlian
00001740-a B O layak
00001740-a B O mahir
00001740-n B O hakikat
00001740-n B O keberadaan
00001740-n B O kewujudan

32
Dibawah ini merupakan skema WordNet Bahasa yang digunakan dalam
penelitian ini:
Gambar 0.10 Skema WordNet Bahasa
1.10 Perancangan Interface
1.10.1 Halaman Upload Resensi Buku
Halaman ini terdapat button untuk memilih dan mensubmit resensi buku.
Pada halaman ini juga terdapat 2 menu, jika user ingin berpindah halaman
ke menu yang lainnya

33
Gambar 0.11 Halaman Menu Resensi Buku
1.10.2 Halaman Preprocessing Buku
Halaman preprocessing resensi buku merupakan sebuah halaman proses
awal sebelum resensi buku siap untuk di index. Pada halaman ini terdapat
proses case folding, tokenizing, dan stopword removal. Pada halaman ini
juga terdapat button untuk menginputkan file yang akan diproses.
Gambar 0.12 Halaman proses Case Folding, Tokenizing, dan Stopword
Removal

34
Pada Gambar 3.9 merupakan halaman untuk hasil proses stopword removal
dan terdapat button untuk proses stemming.
Gambar 0.13 Halaman Hasil Stopword Removal dan proses Stemming
Pada Gambar 3.10 merupakan halaman untuk hasil proses stemming dan
terdapat button untuk menyimpan hasil preprocessing ke dalam format .txt.
dimana file tersebut akan digunakan untuk proses indexing.
Gambar 0.14 Halaman Hasil Stemming

35
1.10.3 Halaman Indexing Resensi Buku
Halaman ini terdapat button untuk memasukkan file. File tersebut akan
diindex dan disimpan ke dalam file .txt yang akan digunakan untuk
mempermudah dalam proses perhitungan cosine similarity.
Gambar 0.15 Halaman Indexing Resensi Buku
1.10.4 Halaman Pencarian Resensi Buku
Halaman pencarian resensi buku merupakan halaman utama. Pada halaman
ini terdapat proses akhir yaitu perhitungan cosine similarity, wordnet, dan
perangkingan.

36
Gambar 0.16 Halaman Pencarian Resensi Buku
1.11 Perancangan Pengujian
1.11.1 Evaluasi Precision dan Recall
Pengujian kemampuan system pada penelitian ini akan dilakukan dengan
menghitung nilai precision dan recall berdasarkan output resensi buku yang
dihasilkan. Pengujian ini dilakukan dengan menginputkan beberapa query
atau keyword pada system. Hasil jumlah dokumen yang relevan dari
keseluruhan resensi buku yang terambil ditentukan secara manual oleh user.
Dari hasil tersebut kemudian akan dihitung berapa nilai precision dan recall
dari query yang diinputkan.