alva graceora nugroho 165314107 - usd
TRANSCRIPT

i
IMPLEMENTASI METODE ASOSIASI PADA DATA PEMINJAMAN
BUKU DI PERPUSTAKAAN UNIVERSITAS SANATA DHARMA
MENGGUNAKAN ALGORITMA FP-GROWTH
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Informatika
Alva Graceora Nugroho
165314107
PROGRAM STUDI INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2020
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

ii
IMPLEMENTATION OF ASSOCIATION METHOD ON THE
TRANSACTION DATA OF SANATA DHARMA UNIVERSITY
LIBRARY USING FP - GROWTH ALGORITHM
THESIS
As Partial Fullfillment of the Requirements
To Obtain the Sarjana Komputer Degree
in Informatics Study Program
Alva Graceora Nugroho
165314107
INFORMATICS STUDY PROGRAM
INFORMATICS DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
2020
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

v
HALAMAN PERSEMBAHAN
“Takut akan TUHAN adalah permulaan pengetahuan, tetapi orang bodoh menghina
hikmat dan didikan. Hai anakku, dengarkanlah didikan ayahmu, dan jangan menyia-
nyiakan ajaran ibumu”
Amsal 1:7-8
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

vii
ABSTRAK
Perpustakaan adalah sumber ilmu bagi tenaga edukasi, mahasiswa dan seluruh
akademisi di lingkungan kampus, antara lain di Universitas Sanata Dharma.
Perpustakaan Universitas Sanata Dharma mengelola buku-buku yang bermanfaat
untuk menunjang proses belajar mengajar berbagai program studi serta dilengkapi
dengan teknologi yang memadai seperti barcode, pembaca barcode, basis data, dan
lain-lain. Namun penggunaan teknologi pada Perpustakaan Universitas Sanata Dharma
belum secara optimal dapat memberikan manfaat bagi para penggunanya, antara lain
belum dapat memberikan rekomendasi buku-buku yang dapat dipinjam oleh tenaga
edukasi, mahasiswa dan seluruh akademisi sesuai dengan kebutuhannya.
Untuk dapat memberikan rekomendasi terhadap para pengguna perpustakaan
sesuai kebutuhannya, maka dapat digunakan pencarian keterkaitan peminjaman satu
buku dengan buku yang lain dengan menggunakan teknik pencarian aturan asosiasi
dalam penambangan data. Penelitian ini dimaksudkan untuk memberikan nilai lebih
dari penggunaan teknologi Perpustakaan Universitas Sanata Dharma dengan
menerapkan metode asosiasi dan algoritma FP-Growth. Dengan menerapkan metode
tersebut terhadap data peminjaman buku di tahun 2018, akan dapat diketahui pola
peminjaman buku pada tahun tersebut.
Penambangan aturan asosiasi dilakukan terhadap data peminjaman buku di
perpustakaan Universitas Sanata Dharma selama tahun 2018 sebanyak 78.779 data dan
33.917 transaksi. Penelitian ini menggunakan python dengan berbagai macam function
seperti PyQt5, mlxtend preprocessing, FPGrowth, dan Association_rule. Eksperimen
yang dilakukan pada penelitian ini adalah menguji data tiap bulan mulai dari bulan
Januari hingga bulan Desember dengan menggunakan rentang nilai minimum support
sebesar 0.1% hingga 0.3% dan rentang nilai minimum confidence sebesar 50% hingga
100%.
Berdasarkan penelitian yang telah dilakukan diperoleh nilai minimum support
tertinggi sebesar 0.3% dan nilai minimum confidence sebesar 100% pada bulan Januari
yang menghasilkan 1 aturan. Aturan asosiasi yang dihasilkan adalah “Pembelajaran
Terpadu: konsep dan penerapannya” → “Pembelajaran Tematik Terpadu” yang
merupakan aturan asosiasi yang kuat dengan nilai support sebesar 0.307%, nilai
confidence sebesar 100% , dan nilai lift ratio sebesar 118.3636.
Kata kunci : data mining, FP-Growth
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

viii
ABSTRACT
Libraries are a source of knowledge for education staff, students and all
academics on campus, including at Sanata Dharma University. The Sanata Dharma
University Library manages useful books to support the teaching and learning process
of various study programs and is equipped with adequate technology such as barcodes,
barcode readers, databases, and others. However, the use of technology in the Sanata
Dharma University Library has not been able to provide benefits to its users optimally,
including not being able to provide recommendations for books that can be borrowed
by education staff, students and all academics according to their needs.
To be able to provide recommendations to library users according to their
needs, association analysis was performed towards the data in finding relation between
one book to another in borrowing transaction. This study is intended to provide more
value than the use of Sanata Dharma University Library technology by applying the
association method and the FP-Growth algorithm. By implementing association
analysis and FP-Growth algorithm towards borrowing transaction data, it will be
possible to identify the pattern of borrowing.
Mining association rules were carried out on borrowing at the Sanata Dharma
University library during 2018 that consists of 78,779 data and 33,917 transactions.
This research uses python with various functions such as PyQt5, mlxtend
preprocessing, FPGrowth, and Association_rule. The experiment carried out in this
study was to test data every month from January to December using a minimum support
value range of 0.1% to 0.3% and a minimum confidence value range of 50% to 100%.
Based on the experiment, it can be found that the highest minimum support
value was 0.3% and the minimum confidence value was 100% in January which
resulted in 1 rule. The resulted association rule is “Pembelajaran Terpadu: konsep dan
penerapannya” → “Pembelajaran Tematik Terpadu”, which is a strong association rule
with a support value of 0.307%, a confidence value of 100%, and a lift ratio of
118.3636.
Keywords: data mining, FP-Growth
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xii
DAFTAR ISI
HALAMAN PERSETUJUAN ..................................................................................... iii
HALAMAN PENGESAHAN ...................................................................................... iv
HALAMAN PERSEMBAHAN ................................................................................... v
PERNYATAAN KEASLIAN KARYA ...................................................................... vi
ABSTRAK .................................................................................................................. vii
ABSTRACT ............................................................................................................... viii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI....................................... ix
KATA PENGANTAR .................................................................................................. x
DAFTAR ISI ............................................................................................................... xii
DAFTAR GAMBAR ................................................................................................. xiv
DAFTAR TABEL ....................................................................................................... xv
BAB I PENDAHULUAN ........................................................................................... 1
1.1 Latar Belakang .................................................................................................... 1
1.2 Rumusan Masalah ............................................................................................... 4
1.3 Tujuan ................................................................................................................. 4
1.4 Manfaat ............................................................................................................... 4
1.5 Batasan Masalah.................................................................................................. 5
1.6 Sistematika Penulisan ......................................................................................... 5
BAB II LANDASAN TEORI ...................................................................................... 7
2.1 Perpustakaan ....................................................................................................... 7
2.2 Data mining ......................................................................................................... 7
2.2.1 Pengelompokan Data mining ....................................................................... 8
2.3 Proses Penambangan Data ................................................................................ 10
2.4 Aturan Asosiasi ............................................................................................ 10
2.5 Algoritma FP-Growth ...................................................................................... 12
2.5.1 FP-Tree ....................................................................................................... 13
2.5.2 Frequent Itemset Generation dalam algoritma FP-Growth ....................... 16
BAB III METODOLOGI PENELITIAN .................................................................. 23
3.1 Gambaran Umum ......................................................................................... 23
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xiii
3.2 Bahan Riset/Data .......................................................................................... 23
3.3 Pre-processing .............................................................................................. 24
3.3.1 Data Cleaning........................................................................................ 25
3.3.2 Data Integration .................................................................................... 26
3.3.3 Data Selection........................................................................................ 26
3.3.4 Data Transformation ............................................................................. 26
3.4 Peralatan Penelitian ...................................................................................... 27
3.5 Algoritma FP-Growth .................................................................................. 27
BAB IV ANALISA DAN DESAIN SISTEM ............................................................ 30
4.1 Model Fungsi Sistem ........................................................................................ 30
4.1.1 Diagram Use Case ...................................................................................... 30
4.1.2 Narasi Use Case ......................................................................................... 31
4.2 Desain Antar Muka Pengguna .......................................................................... 36
BAB V IMPLEMENTASI DAN ANALISIS HASIL ................................................ 52
5.1 Implementasi Sistem ......................................................................................... 52
5.1.1 Tampilan Menu Utama .............................................................................. 52
5.1.2 Tampilan Output ........................................................................................ 53
5.1.3 Implementasi function dalam sistem .......................................................... 54
5.2 Hasil Pengujian ................................................................................................. 59
5.2.1 Uji Validasi ................................................................................................ 59
5.2.2 Uji Akurasi ................................................................................................. 76
5.3 Analisis Hasil Pengujian ................................................................................... 68
BAB VI PENUTUP .................................................................................................... 70
6.1 Simpulan ........................................................................................................... 70
6.2 Saran .................................................................................................................. 71
DAFTAR PUSTAKA ................................................................................................. 72
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xiv
DAFTAR GAMBAR
Gambar 2.1 Pembentukan Sebuah FP-Tree (Tan, 2005)……………………………14
Gambar 2.2 Penguraian masalah itemset generation ke dalam subproblem, dimana
setiap subproblem terdapat item yang berakhiran di e, d, c,b,dan a (Tan, 2005)...…17
Gambar 2.3. Contoh penerapan algoritma FP-Growth untuk mencari frequent
itemsets yang berakhir di e. (Tan, 2005)…………………………………………….19
Gambar 3.1 Data Asli………………………………………………………………..25
Gambar 3.2 Data cleaning judul buku……………………………………………….25
Gambar 3.3 Data cleaning mobile library USD……………………………………..26
Gambar 3. 4 Flowchart sistem………………………………………………………27
Gambar 3. 5 Flowchart Proses FP-Growth dan Aturan Asosiasi…………………...28
Gambar 4.1 Diagram Use Case...................................................................................30
Gambar 4.2 Desain Antarmuka dengan Pengguna…………………………………..36
Gambar 5.1 Tampilan Menu Utama ………………………………………………...53
Gambar 5.2 Tampilan Output ……………………………………………………….53
Gambar 5.3 Function yang digunakan……………………………………………….54
Gambar 5.4 Function mlx.preprocessing…………………………………………….54
Gambar 5.5 Function mlx.frequentspatterns...………………………………………55
Gambar 5.6 Function fpcommons……...…………………………………………….56
Gambar 5.7 Function fpgrowth…...………………………………………………….58
Gambar 5.8 Function association_rules.…....……………………………………….58
Gambar 5.9 Proses Pembentukan FP-Tree Data Sampel……………………………65
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xv
DAFTAR TABEL
Tabel 2.1. Daftar Item yang Sering Muncul dengan Akhirannya……….…………..18
Tabel 3.1 Jumlah Transaksi Tiap Bulan……………………………………………..24
Tabel 3.2 Nama Function yang Digunakan…………………...……………………..28
Tabel 4.1 Input File …......………………...………………………………………...31
Tabel 4.2 Input Nilai Minimum Support ……………………………………………32
Tabel 4.3 Input Nilai Minimum Confidence ……………...…………………………33
Tabel 4.4 Proses Aturan Asosiasi …………………………………………………...34
Tabel 4.5 Lihat Hasil Algoritma …………………………………………..………...34
Tabel 5.1 Contoh data………….. ...……...………………………………………….59
Tabel 5.2 Penyederhanaan Daftar Buku …………………………………………….62
Tabel 5.3 Item dan Count ……………………………………………………………62
Tabel 5.4 Item yang Memenuhi Minimum Support………………………………….63
Tabel 5.5 Frequent Itemset Data Sampel ..………………………………………….67
Tabel 5.6 Aturan Asosiasi Dari Data Sampel …..…………………………………...69
Tabel 5.7 Hasil Uji Validasi ………………………………………………………...74
Tabel 5.8 Perbandingan Jumlah Aturan Asosiasi Tiap Bulan dengan Variasi Nilai
Minsup dan Mincof ………………………………………………………………….76
Tabel 5.9 Hasil Aturan Asosiasi dengan Support dan Confidence Terbaik tiap Bulan ……78
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Perpustakaan merupakan suatu gudang ilmu yang terletak di setiap instansi
pendidikan maupun non pendidikan. Seperti apa yang dikatakan pepatah, perpustakaan
merupakan sebuah jantung dari institusi tersebut. Jika setiap sekolah atau kampus
mengandaikan perpustakaan merupakan sebuah jantung, berarti dalam arti yang
sesungguhnya pendidikan merupakan jantung dari sebuah negara. Perpustakaan
mempunyai peranan penting dalam meningkatkan kualitas mahasiswa juga menjadi
jembatan antara sumber ilmu dengan sumber daya manusia.
Dalam perkembangannya, manusia memanfaatkan teknologi untuk mempermudah
kepentingan kesehariannya. Teknologi sudah mempengaruhi di semua bidang, sama
hal nya di bidang pendidikan, seperti contoh kasus perpustakaan Universitas Sanata
Dharma. Salah satu contoh penggunaan teknologi di perpustakaan Sanata Dharma
adalah penggunaan basis data. Basis data tersebut berisi data transaksi peminjaman
buku di Perpustakaan Universitas Sanata Dharma. Namun data transaksi hanya
digunakan sebagai laporan akhir tahunan koleksi buku yang ada di perpustakaan.
Padahal jika diolah dengan baik maka akan mendapatkan informasi yang berharga.
Setiap mahasiswa, dosen, dan karyawan diperbolehkan untuk meminjam koleksi
dari perpustakaan dan harus mentaati sesuai peraturan tata cara meminjam buku.
Peminjaman yang dilakukan oleh stakeholder tersebut tercatat dengan baik ke dalam
sebuah basis data yang dikelola oleh bagian data perpustakaan tersebut. Namun mereka
belum menyediakan informasi mengenai saran buku kepada peminjam. Hal itu
dikarenakan belum adanya sumber daya manusia yang mengolah daftar peminjaman
buku menjadi informasi mengenai saran buku bagi peminjam. Saran buku sangat
penting bagi peminjam karena mempermudah peminjam dalam menentukan buku apa
saja yang dapat dipinjam sesuai dengan kebutuhannya. Saran buku juga penting bagi
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

2
pegawai perpustakaan karena bisa menentukan jumlah koleksi berdasarkan
keterpakaian yang kemungkinan besar dipinjam bersamaan oleh peminjam. Dengan
demikian, pegawai perpustakaan bisa mempersiapkan jumlah atau stok koleksi yang
sering dipinjam. Jika koleksi yang sering dipinjam habis maka dalam laporan akhir
tahun pegawai perpustakaan dapat memperbanyak jumlah koleksi berupa buku ataupun
dalam bentuk softcopy.
Data transaksi peminjaman buku di Perpustakaan Universitas Sanata Dharma
dapat diolah untuk mendapatkan saran buku dengan memanfaatkan data mining. Data
mining adalah sebuah teknik dalam bidang teknologi informasi yang bertujuan untuk
mengolah dan menganalisa kumpulan data dalam jumlah besar untuk menghasilkan
informasi yang berharga. Hal tersebut dapat dilakukan dengan cara mencari pola buku
yang sering dipinjam secara bersamaan oleh peminjam. Metode yang dapat digunakan
untuk menganalisis pola buku tersebut adalah Association rule mining.
Terdapat beberapa algoritma Association rule mining, diantaranya yaitu: algoritma
apriori dan algoritma Frequent Pattern-Growth (FP - Growth). Algoritma FP-Growth
(Frequent Pattern-Growth) merupakan metode yang membentuk struktur data compact
untuk meringkas transaksi basis data yang asli dan berfokus kepada FP – Growth dan
menghindari proses pembuatan kandidat yang tidak penting sehingga menghasilkan
hasil yang efisiens (Han, 2006). Karakteristik algoritma FP - Growth adalah struktur
data yang digunakan dalam tree yang disebut FP-Tree. Algoritma FP-Growth memiliki
beberapa kelebihan yaitu penggunaan memori yang lebih sedikit, dan proses pencarian
frequent itemset menjadi lebih cepat dan lebih efisien dibandingkan dengan algoritma
apriori karena tidak dilakukan pemindaian data transaksi secara berulang – ulang
(David, 2008).
Penelitian – penelitian terdahulu mengenai aturan asosiasi sudah menghasilkan
banyak hasil. Penulis mengutip empat penelitian sebelumnya yaitu: Pertama Analisis
Keranjang Belanja Menggunakan Metode FP - Growth pada Toko Grosir Pancaran
Bahagia oleh Yohanes Adi Purnomo Batlayeri (2019), penelitian dilakukan pada tahun
2019 menggunakan data transaksi toko Grosir Pancaran bahagia tahun 2017 dan 2018
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

3
menggunakan algoritma FP-Growth. Kesimpulan dari penelitian pertama adalah
dataset pada bulan Juli 2017 sampai Desember 2017 menghasilkan nilai minimum
support count sebesar 15 dan nilai minimum confidence sebesar 50% pada setiap
bulannya. Terdapat dataset yang tidak memiliki aturan asosiasi yaitu pada bulan Juli
2017 dan bulan Agustus 2017.
Penelitian kedua, Penerapan algoritma FP-Growth Untuk Menemukan Pola
Peminjaman Buku di Perpustakaan UIN Raden Fatah Palembang oleh Kadafi (2018).
Data yang digunakan adalah transaksi peminjaman buku pada tahun 2017. Kesimpulan
yang dihasilkan pada penelitian kedua adalah nilai minimum support dan confidence
mempengaruhi jumlah rule yang dihasilkan semakin tinggi rule tersebut maka rule
yang dihasilkan akan semakin akurat.
Penelitian ketiga, Implementasi Algoritma FP-Growth untuk Sistem Rekomendasi
Buku di Perpustakaan UKDW oleh Miraldi, dkk (2014). Data yang digunakan adalah
data transaksi peminjaman buku di perpustakaan UKDW. Kesimpulan yang dihasilkan
pada penelitian ketiga adalah algoritma FP-Growth dapat digunakan di dalam kasus
perekomendasian buku dan mendapatkan hasil keluaran berupa rekomendasi buku
yang terkait. Kesimpulan lain yang dihasilkan adalah tingkat keakuratan FP-Growth
dalam memberikan rekomendasi buku sebesar 60.78%.
Penelitian keempat, Analisis dan Implementasi Algoritma FP-Growth pada
Aplikasi SMART untuk Menentukan Market Basket Analysis pada Usaha Retail oleh
Larasati, dkk (2015). Data yang digunakan adalah data transaksi penjualan barang
retail. Kesimpulan yang dihasilkan pada penelitian keempat adalah rules yang
dihasilkan setiap bulan dengan nilai minimum support sebesar 0.002 dan minimum
confidence sebesar 0.5.
Berdasarkan permasalahan di atas penulis akan mengolah data peminjaman
buku di perpustakaan Universitas Sanata Dharma dengan menggunakan FP-Growth
untuk mencari pola buku yang sering dipinjam secara bersamaan guna membantu
peminjam dalam menentukan buku yang akan dipinjam sesuai dengan kebutuhannya.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

4
1.2 Rumusan Masalah
Berdasarkan permasalahan di atas masalah yang akan diselesaikan dalam
penelitian ini antara lain:
1. Bagaiman mengimplementasikan algoritma FP-Growth untuk menganalisis
pola peminjaman buku di perpustakaan?
2. Berapakah minimum support dan minimum confidence yang optimal untuk
mendapatkan aturan asosiasi yang kuat?
3. Seperti apakah aturan asosiasi kuat yang dihasilkan dan berapakah nilai support
dan confidence aturan kuat tersebut?
1.3 Tujuan
Tujuan dari penelitian ini antara lain:
1. Mengimplementasikan sistem analisis pola peminjaman buku dengan
menggunakan algoritma FP-Growth.
2. Menganalisis sistem untuk mendapatkan nilai minimum support dan minimum
confidence yang optimal untuk menghasilkan aturan asosiasi yang kuat.
3. Menganalisis sistem untuk mendapatkan aturan asosiasi yang kuat beserta nilai
support dan confidence nya.
1.4 Manfaat
Manfaat dalam penelitian ini adalah:
1. Bagi Penulis
Manfaat penelitian bagi penulis adalah membuat sistem yang menggunakan
aturan asosiasi dengan menggunakan algoritma FP-Growth.
2. Bagi Perpustakaan
Manfaat penelitian bagi perpustakaan adalah memudahkan pegawai
perpustakaan dalam menentukan ketersediaan koleksi.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

5
3. Bagi Peminjam
Aturan yang didapat melalui algoritma ini selanjutnya dapat dipergunakan
dalam sistem rekomendasi yang dapat dimanfaatkan oleh peminjam untuk
menentukan buku yang sesuai untuk dipinjam.
1.5 Batasan Masalah
Batasan masalah dalam penelitian ini adalah:
1. Data yang digunakan dalam penelitian ini adalah data transaksi peminjaman
buku di perpustakaan Universitas Sanata Dharma selama tahun 2018.
2. Algoritma yang digunakan adalah algoritma FP-Growth.
1.6 Sistematika Penulisan
Sistematika penulisan yang digunakan adalah:
1. BAB I PENDAHULUAN
Bab ini berisi tentang latar belakang, perumusan masalah, batasan masalah,
tujuan, dan sitematika penulisan.
2. BAB II LANDASAN TEORI
Bab ini berisi landasan teori yang akan digunakan dalam penelitian ini
antara lain pengertian perpustakaan, pengertian data mining,
pengelompokan data mining, pengertian asosiasi dan algoritma FP-
Growth.
3. BAB III METODOLOGI PENELITIAN
Bab ini berisi tentang penjelasan metodologi penelitian yang dibuat untuk
penerapan data mining serta penentuan analisis aosisasi menggunakan
algoritma FP-Growth.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

6
4. BAB IV ANALISA DAN DESAIN SISTEM
Bab ini berisi tentang analisa dan desain sistem untuk
mengimplementasikan metode asosiasi pada peminjaman buku di
perpustakaan menggunakan algoritma Growth.
5. BAB V IMPLEMENTASI DAN ANALISIS HASIL
Bab ini berisi tentang implementasi perancangan sistem dan analisis hasil
yang telah didapat dalam pengujian terhadap algoritma Growth.
6. BAB VI PENUTUP
Bab ini berisi tentang kesimpulan dari analisis hasil dan saran – saran yang
akan berguna untuk pengembangan penelitian ini ke depannya.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

7
BAB II
LANDASAN TEORI
2.1 Perpustakaan
Perpustakaan merupakan unit kerja dari suatu badan atau lembaga tertentu
yang mengelola bahan-bahan pustaka. Baik berupa buku maupun non buku yang
diatur secara sistematis menurut aturan tertentu sehingga dapat digunakan sebagai
sumber informasi (Suhendar, 2005). Perpustakaan adalah sekumpulan bahan
pustaka, baik yang tercetak maupun rekaman yang lainnya, pada suatu tempat
tertentu yang telah diatur sedemikian rupa untuk mempermudah pemustaka
mencari informasi yang diperlukannya dan yang tujuannya utamanya adalah untuk
melayani kebutuhan informasi masyarakat yang dilayaninnya dan bukan untuk
diperdagangkan” (Mudyana dan Royani dalam Sinaga, 2005).
2.2 Data mining
Pengertian data mining adalah proses menemukan pola yang menarik dan
pengetahuan dari data yang berjumlah besar (Han dan Kamber, 2011), Sedangkan
pengertian data mining kedua adalah suatu pencarian dan analisa dari jumlah data
yang sangat besar dan bertujuan untuk mencari arti dari pola dan aturan (Linoff
dan Berry, 2011). Lalu pengertian data mining ketiga adalah suatu proses ekstraksi
atau penggalian data yang belum diketahui sebelumnya, namun dapat dipahami
dan berguna dari basis data yang besar serta digunakan untuk membuat suatu
keputusan bisnis yang sangat penting (Connolly dan Begg, 2010). Dan menurut
pengertian data mining yang keempat adalah aktivitas yang menggambarkan
sebuah proses analisis yang terjadi secara iteratif pada basis data yang besar,
dengan tujuan mengekstrak informasi dan knowledge yang akurat dan berpotensial
berguna untuk knowledge workers yang berhubungan dengan pengambilan
keputusan dan pemecahan masalah (Vercellis, 2009). Dari beberapa teori yang
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

8
dijabarkan oleh para ahli di atas, bahwa data mining. Menurut beberapa pendapat
mengenai pengertian data mining, data mining sendiri itu adalah sebuah proses
untuk mengelola, menganalisa, dan menarik kesimpulan dari kumpulan data
menggunakan metode tertentu untuk meningkatkan nilai kegunaan dari data itu
sendiri.
2.2.1 Pengelompokan Data mining
Data mining dapat dikelompokkan menjadi beberapa kelompok, yaitu:
1. Deskripsi
Deskripsi bertujuan untuk mengidentifikasi pola yang muncul secara
berulang pada suatu data dan mengubah pola tersebut menjadi aturan
dan kriteria yang dapat mudah dimengerti oleh para ahli pada domain
aplikasinya. Aturan yang dihasilkan harus mudah dimengerti agar dapat
dengan efektif meningkatkan tingkat pengetahuan (knowledge) pada
sistem. Tugas deskriptif merupakan tugas data mining yang sering
dibutuhkan pada teknik postprocessing untuk melakukan validasi dan
menjelaskan hasil dari proses data mining. Postprocessing merupakan
proses yang digunakan untuk memastikan hanya hasil yang valid dan
berguna yang dapat digunakan oleh pihak yang berkepentingan.
2. Prediksi
Prediksi memiliki kemiripan dengan klasifikasi, akan tetapi data
diklasifikasikan berdasarkan perilaku atau nilai yang diperkirakan pada
masa yang akan datang. Contoh dari tugas prediksi misalnya untuk
memprediksikan adanya pengurangan jumlah pelanggan dalam waktu
dekat dan prediksi harga saham dalam tiga bulan yang akan datang.
3. Estimasi
Estimasi hampir sama dengan prediksi, kecuali variabel target estimasi
lebih ke arah numerik dari pada ke arah kategori. Model dibangun
menggunakan record lengkap yang menyediakan nilai dari variabel
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

9
target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya
estimasi nilai dari variabel target dibuat berdasarkan nilai variabel
prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik
pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, berat
badan, dan level sodium darah. Hubungan antara tekanan darah sistolik
dan nilai variabel prediksi dalam proses pembelajaran akan
menghasilkan model estimasi.
4. Klasifikasi
Klasifikasi merupakan proses menemukan sebuah model atau fungsi
yang mendeskripsikan dan membedakan data ke dalam kelas-kelas.
Klasifikasi melibatkan proses pemeriksaan karakteristik dari objek dan
memasukkan objek ke dalam salah satu kelas yang sudah didefinisikan
sebelumnya.
5. Clustering
Clustering merupakan pengelompokan data tanpa berdasarkan kelas
data tertentu ke dalam kelas objek yang sama. Sebuah kluster adalah
kumpulan record yang memiliki kemiripan suatu dengan yang lainnya
dan memiliki ketidakmiripan dengan record dalam kluster lain.
Tujuannya adalah untuk menghasilkan pengelompokan objek yang
mirip satu sama lain dalam kelompok-kelompok. Semakin besar
kemiripan objek dalam suatu cluster dan semakin besar perbedaan tiap
cluster maka kualitas analisis cluster semakin baik.
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang
muncul dalam suatu waktu. Dalam dunia bisnis lebih umum disebut
analisis keranjang belanja (market basket analisys). Tugas asosiasi
berusaha untuk mengungkap aturan untuk mengukur hubungan antara
dua atau lebih atribut.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

10
2.3 Proses Penambangan Data
Langkah- langkah dalam penambangan data atau yang lebih dikenal dengan
istilah KDD (knowledge discovery in databases). Knowledge discovery in
databases (KDD) adalah keseluruhan proses non-trivial untuk mencari dan
mengidentifikasi pola (pattern) dalam data. Pola yang ditemukan bersifat sah,
baru, dapat bermanfaat dan dapat dimengerti. Menurut Jiawei, Kamber (2012)
tahapan KDD adalah sebagai berikut.
1. Data cleaning untuk membersihkan data dari gangguan dan data yang tidak
konsisten
2. Data integration untuk menggabungkan beberapa sumber data yang tersedia
3. Data selection untuk memilih data yang relevan untuk dianalisa yang berasal
dari basis data.
4. Data transformation untuk mentransformasikan dan mengkonsolidasikan
data ke dalam bentuk yang sesuai untuk penambangan dengan melakukan
operasi ringkasan atau agregasi.
5. Data mining adalah proses penting di mana data diolah dengan metode untuk
mengekstrak pola data.
6. Pattern evaluation untuk mengidentifikasi pola yang benar-benar menarik
yang mewakili pengetahuan berdasarkan ukuran ketertarikan.
7. Knowledge presentation adalah teknik visualisasi dan representasi
pengetahuan digunakan untuk menyajikan pengetahuan yang ditambang
kepada pengguna.
2.4 Aturan Asosiasi
Analisis asosiasi adalah teknik data mining untuk menemukan aturan
asosiatif antara suatu kombinasi item (Kusrini & Lutfi, 2009). Analisis asosiasi
berguna untuk menemukan hubungan penting yang tersembunyi diantara set data
yang sangat besar (Prasetyo, 2012).
Tujuan umum penjual yang berkaitan dengan asosiasi adalah untuk
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

11
mengidentifikasi item yang dibeli bersama-sama. Informasi ini dapat digunakan
untuk meningkatkan susunan barang-barang dalam sebuah toko atau susunan
halaman katalog (Hernawati, 2013).
Dalam asosiasi terdapat dua hal penting yang berpengaruh besar terhadap
aturan yang dibentuknya, yaitu support dan confidence. Perhitungan nilai support
dan confidence dapat dilakukan sebagai berikut (Kusrini, dan Emha 2009):
a. Analisa pola frekuensi
Support merupakan perbandingan dari transaksi dalam basisdata yang
berisi semua item dalam itemset.
Mencari Nilai support sebuah item diperoleh dengan menggunakan
rumus berikut:
Nilai support 2 item diperoleh dengan rumus:
𝑆𝑢𝑝𝑝𝑜𝑟𝑡 (𝐴) =Jumlah transaksi yang mengandung A
Total Transaksi (2.1)
b. Pembentukan aturan asosiasi
Confidence merupakan seberapa sering item-item dalam B muncul
dalam transaksi yang berisi Perhitungan aturan asosiasi confidence
menggunakan rumus:
𝐶𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒 (𝐴, 𝐵) =Jumlah transaksi yang mengandung A dan B
Transaksi Mengandung A (2.2)
c. Pembentukan Lift Ratio
Lift ratio adalah satuan ukuran untuk mengetahui kekuatan aturan
asosiasi yang telah terbentuk. Ukuran lift ratio berada pada kisaran
nilai 0 sampai tak hingga (Han dan Kamber, 2012). Adapun
keterangannya adalah sebagai berikut:
• Jika lift ratio = 1, maka antara item A dan B saling independent.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

12
Sehingga tidak ada hubungan keeratan antara A dan B
• Jika lift ratio > 1, maka antara item A dan B memiliki hubungan
korelasi yang positif, di mana kejadian satu menyiratkan terjadinya
kejadian yang lain.
• Jika lift ratio < 1, maka antara item A dan B memiliki korelasi yang
negatif, terjadinya suatu kemungkinan mengarah pada ketiadaan
yang lain.
Nilai lift ratio dikatakan baik ketika nilai lift ratio > 1. Pada nilai ini
proses transaksi dikatakan memiliki korelasi positif karena keadaan
keeratan antar item saling positif dan dapat diartikan di mana
kejadian satu menyiratkan kejadian yang lainnya (Han dan Kamber,
2012). Dapat disimpulkan semakin besar lift ratio maka semakin kuat
aturan asosiasi yang dihasilkan. Untuk mengetahui lift ratio
digunakan rumus sebagai berikut (Tan, 2005):
𝐿𝑖𝑓𝑡 𝑅𝑎𝑡𝑖𝑜 = 𝑐 (𝐴𝐵)
𝑠(𝐵) (2.3)
di mana :
𝑐 (𝐴𝐵) : nilai confidence transaksi yang memiliki item A dan B
𝑠(𝐵) : nilai support transaksi yang memiliki item B
A : transaksi yang memiliki item A
B : transaksi yang memiliki item B
2.5 Algoritma FP-Growth
Algoritma FP-Growth merupakan salah satu algoritma penambangan data yang
menggunakan teknik aturan asosiasi. Algoritma FP-Growth adalah algoritma yang
tidak memakai paradigma generated - and – test seperti yang dilakukan oleh algoritma
apriori. Algoritma FP-Growth mengkodekan sebuah data set menggunakan struktur
data yang biasa disebut FP-Tree (Tan, 2005). Algoritma FP-Growth lebih efisien untuk
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

13
menentukan frequent pattern baik dalam data yang berjumlah kecil maupun besar.
Algoritma ini sebagai penyempurnaan dari algoritma apriori dalam hal waktu saat
proses data dan jumlah data yang dapat diolah (Han, 2006). Langkah – langkah dalam
algoritma FP – Growth adalah Pertama menghitung setiap count pada item dalam
transaksi. Kedua adalah pembentukan FP – Tree. Setelah tahap pembangunan FP-Tree
dari sekumpulan data transaksi, akan diterapkan algoritma FP-Growth untuk mencari
frequent itemset yang signifikan. Algoritma FP-Growth dibagi menjadi tiga langkah
utama (David, 2008), yaitu :
1. Tahap pembangkitan conditional pattern base
Conditional pattern base merupakan subdatabase yang berisi prefix path
(lintasan prefix) dan suffix pattern (pola akhiran). Pembangkitan conditional
pattern base didapatkan melalui FP-Tree yang telah dibangun sebelumnya.
2. Tahap pembangkitan conditional FP-Tree
Pada tahap ini, support count dari setiap item pada setiap conditional pattern
base dijumlahkan, lalu setiap item yang memiliki jumlah support count lebih
besar sama dengan minimum support count akan dibangkitkan dengan
conditional FP-Tree.
3. Tahap pencarian frequent itemset
Apabila conditional FP-Tree merupakan lintasan tunggal (single path), maka
didapatkan frequent itemset dengan melakukan kombinasi item untuk setiap
conditional FP-Tree. Jika bukan lintasan tunggal, maka dilakukan
pembangkitan FP-Growth secara rekursif.
2.5.1 FP-Tree
Dalam algoritma FP-Growth dikenal pula dengan istilah FP-Tree
(Frequent Pattern Tree) yaitu sebuah struktur seperti pohon prefix yang
digunakan untuk mendesain struktur frequent pattern mining secara efisien.
Setiap node pada pohon diisi dengan 1 item dan di setiap anak dari node
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

14
tersebut merepresentasikan item yang berbeda dengan item yang ada pada
induk. Setiap node menyimpan informasi pendukung dari isi item di dalam
path dan root hingga ke node. Sebuah root dalam FP-Tree diinisialisasikan
dengan nilai null. Dengan menggunakan FP-Tree, algoritma FP-Growth dapat
langsung mengekstrak frequent itemset.
Gambar 2.1 Pembentukan Sebuah FP-Tree (Tan, 2005)
Pada gambar 2.1 menunjukkan data transaksi yang berisi sepuluh transaksi
dan lima item. Struktur FP-Tree membaca mulai dari transaksi pertama,
kedua, ketiga hingga transaksi terakhir. Setiap node dalam tree berisi label
item bersama dengan counter dan pemetaan sesuai dengan rute dalam
transaksi. Pada awalnya FP-Tree berisi root yang bernilai null, langkah
berikut nya dalam pembentukan FP-Tree adalah sebagai berikut:
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

15
1. Tahap pertama adalah memindai dataset sebanyak 1 kali untuk
menemukan support count pada setiap item. Item yang jarang muncul
akan dieliminasi. Item yang sering muncul akan diurutkan (sort) dari
count yang bejumlah besar ke count yang bejumlah kecil (decreasing
support). Pada gambar 2.1 dapat dilihat item yang memiliki count
terbanyak adalah a, diikuti oleh item b,c, dan e.
2. Tahap kedua adalah membangun FP-Tree baru setelah membaca
transaksi pertama, {a,b}, kemudian membuat node dengan label sebagai
a dan b. Sebuah jalur terbentuk dari null a b. Setiap node di jalur
tersebut memiliki bobot frekuensi yang bernilai 1. Pembentukan FP-
Tree transaksi pertama dapat dilihat pada gambar 2.1 point (i).
3. Tahap ketiga adalah membaca transaksi kedua {b,c,d}, kemudian
membuat node baru untuk item b,c,d. Sebuah jalur baru terbentuk untuk
menghubungkan node nullbc d. Setiap node di jalur tersebut
memiliki bobot frekuensi yang bernilai 1. Pembentukan FP-Tree
transaksi kedua dapat dilihat pada gambar 2.1 point (ii).
4. Tahap keempat adalah membaca transaksi ketiga, {a,,c,d,e}, kemudian
terlihat memiliki awalan yang sama dengan transaksi pertama yaitu {a}.
Kemudian, jalur untuk transaksi ketiga adalah null a c d e.
Karena item {a} tumpang tindih jalur dengan {a,b}, maka jumlah
frekuensi untuk node a bertambah menjadi dua. Sementara untuk node
{c,d,e} jumlah frekuensi nya adalah satu. Pembentukan FP-Tree
transaksi ketiga dapat dilihat pada gambar 2.1 point (iii).
5. Proses ini dilanjutkan sampai setiap transaksi terpetakan ke satu
transaksi dari jalur yang diberikan di FP-Tree. Pembentukan FP-Tree
sampai transaksi terakhir dapat dilihat pada gambar 2.1 point (iv).
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

16
2.5.2 Frequent Itemset Generation dalam algoritma FP-Growth
Algoritma FP-Growth adalah algoritma yang membentuk
frequent itemset dari sebuah FP-Tree dengan cara mengekplorasi tree
di bottom-up. Dapat dilihat pada gambar 2.1, item terakhir pada frequent
itemset adalah item e, kemudian diikuti oleh item d,c,b, dan berakhir di
item a. Bottom-up digunakan untuk mencari frequent itemset yang
berakhiran dengan item tertentu yang setara dengan basis suffix. Setiap
transaksi akan terpetakan ke dalam jalur FP-Tree. Sebagai contoh
adalah item e, jalur yang diperiksa hanyalah jalur yang mengandung
node e. Jalur ini bisa diakses dengan cepat dengan memakai pointer
yang berkaitan dengan node e. Berikut merupakan contoh setiap jalur
yang diekstraksi ditunjukkan pada gambar 2.2.
Gambar 2.2 Penguraian masalah itemset generation ke dalam
subproblem, dimana setiap subproblem terdapat item yang
berakhiran di e, d, c,b,dan a (Tan, 2005)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

17
Setelah memvisualisasikan penguraian dengan menggunakan gambar
dalam bentuk tree kemudian mendata setiap subfix dan mencatatnya ke
dalam frequent itemsets. Daftar frequent itemsets setiap node
ditunjukkan pada tabel 2.1
Tabel 2.1. Daftar item yang sering muncul dengan akhirannya.
Setelah melakukan pencarian frequent itemsets yang berakhiran
dengan e, maka algoritma akan melakukan proses untuk mencari
itemset yang berakhir dengan node d, dengan cara memproses
jalur yang berasosiasi dengan node d. Jalur yang sesuai dapat
dilihat pada gambar 2.2 point (b). Proses dilanjutkan sampai
semua jalur tersambung atau saling berasosiasi dengan nodes c,
b dan berakhir di a, kemudian dilakukan pemrosesan
selanjutnya. Jalur untuk item-item ini ditunjukkan pada gambar
2.2 point (c), (d), dan (e).
Algoritma FP-Growth mencari semua frequent itemsets dengan
suffix tertentu dengan strategi divide and conquer atau membagi
dan menggabungkan untuk melakukan pembagian dari satu
masalah menjadi beberapa subproblem yang lebih kecil.
Suffix Frequent Itemsets
e {e}, {d,e}, {a,d,e}, {c,e},{a,e}
d {d}, {c,d}, {b,c,d}, {a,c,d}, {b,d}, {a,b,d}, {a,d}
c {c}, {b,c}, {a,b,c}, {a,c}
b {b}, {a,b}
a {a}
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

18
Sebagai contoh, pencarian semua frequent itemsets yang
berakhiran di e. Untuk melakukan hal itu kita harus memeriksa
apakah itemset{e} adalah frequent dirinya sendiri. Jika dia
adalah frequent, maka kita pertimbangkan untuk subproblem
mencari itemsets yang berakhiran dengan de, kemudian diikuti
dengan ce,be, dan ae. Selanjutnya setiap subproblem ini
diuraikan menjadi subproblem yang lebih kecil. Dengan
menguraikan subproblem menjadi lebih kecil, maka semua
itemsets yang sering berakhiran e dapat ditemukan. Pendekatan
divide and conquer ini adalah cara utama yang dipakai algoritma
FP-Growth.
Gambar 2.3. Contoh penerapan algoritma FP-Growth
untuk mencari frequent itemsets yang berakhir di e. (Tan,
2005)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

19
Berikut adalah tahapan untuk menyelesaikan subproblems,
untuk mencari frequent itemsets yang berakhiran dengan e.
Ilustrasi dapat dilihat pada gambar 2.3.
1. Langkah pertama, kumpulkan semua jalur yang mengandung
node e. Ini disebut sebagai awalan, maka dari itu dipanggil
sebagai jalur prefix seperti ditunjukkan pada gambar 2.3(a).
2. Dari jalur prefix yang ditunjukan pada gambar 2.3(a), support
count untuk e didapatkan dengan cara menambahkan support
count yang terasosiasi dengan node e. Misalnya support count
adalah sebesar 2, {e} dinyatakan karena merupakan itemset
yang sering muncul dan memiliki nilai support count sebesar 3.
3. Item {e} sering muncul, maka subproblem harus diselesaikan
oleh algoritma untuk menemukan itemset yang berakhiran
dengan de,ce,be dan ae. Awal jalur harus dikonversi lebih
dahulu menjadi conditional FP-Tree sebelum melakukan
penyelesaian subproblem. Secara structural ini mirip dengan
FP-Tree tetapi digunakan untuk mencari frequent itemsets yang
berakhiran tertentu.
Cara memperoleh conditional FP-Tree adalah sebagai berikut :
a) Tahap pertama, support count sepanjang jalur prefix
harus diperbarui, karena beberapa perhitungan dalan
transaksi tidak termasuk di item e. Pada gambar 2.2 (a),
null b:2c:2e:1, jalur paling kanan, transaksi{b,c}
tidak terkandung item e. Sepanjang jalur awal, count harus
menyesuaikan ke 1 untuk menampilkan jumlah transaksi
yang sebenarnya yang terkandung {b, c, e}.
b) Melakukan pemotongan pada jalur awal dengan cara
menghapus node e. Penghapusan node dilakukan karena
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

20
support count dalam jalur awalan telah perbarui untuk
menunjukkan transaksi yang mengandung hanya node e
dan subproblem untuk itemset yang ditemukan sering
muncul dan berakhiran de, ce, be dan ae.
c) Support count yang telah diperbarui pada frefix path,
dimana memungkinkan beberapa item tidak lagi sering
muncul. Sebagai contoh, node b, memiliki support count
sama dengan 1 dan hanya muncul sekali yang
menandakan hanya ada satu transaksi yang berisi b dan e.
Item b dapat diabaikan dengan aman dari analisis
selanjutkan, karena semua item yang berakhiran be jarang
muncul.
4. Conditional FP-Tree digunakan pada FP-Growth untuk
menyelesaikan subproblem penentuan frequent itemset dengan
akhiran de, ce, dan ae. Prefix path untuk d dikumpulkan dari
conditional FP-Tree pada e (Gambar 2.3(c)) untuk menemukan
itemset yang sering muncul berakhiran. Dengan menambahkan
jumlah frekuensi yang berasosiasi dengan node d, maka akan
didapatkan support count untuk {d,e}. Sejak support count sama
dengan 2, {d, e} dideklarasikan sebagai frequent itemset.Tahap
selanjutnya, algoritma membangun conditional FP-Tree untuk
de dengan menggunakan pendekatan yang dijelaskan pada tahap
ketiga. Setelah support count diperbarui dan melakukan
penghapusan item yang jarang muncul (c) yang ditunjukkan
pada gambar 2.3 (d) conditional FP-Tree untuk de. Sejak
conditional FP-Tree hanya mengandung satu item a, yang mana
support dengan minimum support, algoritma melakukan ekstrasi
frequent itemset {a,d,e} dan bergerak ke subproblem
selanjutnya yang menhasilkan frequent itemset yang berakhiran
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

21
ce. Setelah prefix path untuk c diproses, ditemukan {c, e} yang
sering muncul. Algoritma akan memproses untuk
menyelesaikan subprogram selanjuntya dan menemukan {a, e}
yang menjadi frequent itemset satu-satunya yang tersisa.
Ilustrasi tadi menjelaskan pendekatan divide and conguer yang
dipakai algoritma FP-Growth. Pada tahap rekursif, conditional FP-
Tree dibentuk dengan cara memperbarui jumlah frekuensi di
sepanjang prefix path dan semua item yang jarang muncul akan
dihapus. Jumlah yang berasosiasi dengan node memperbolehkan
algoritma untuk menunjukan perhitungan support ketika
menghasilkan common suffix itemsets.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

23
BAB III
METODOLOGI PENELITIAN
Pada bab ini berisi tentang metodologi penelitian tugas akhir yang
digunakan, di bab ini juga berisi bagaimana mendapatkan data, cara mengolah
data, spesifikasi hardware dan software yang digunakan, cara pengujian, desain
antarmuka dengan pengguna, dan analisis fungsi sistem.
3.1 Gambaran Umum
Penelitian ini memiliki tujuan untuk menemukan aturan asosiasi
berupa pola buku yang sering dipinjam secara bersamaan oleh
peminjam. Aturan asosiasi tersebut digunakan untuk mencari pola buku
yang sering dipinjam secara bersamaan guna membantu peminjam
dalam menentukan buku yang akan dipinjam sesuai dengan
kebutuhannya
3.2 Bahan Riset/Data
Data yang digunakan dalam penelitian ini adalah data peminjaman
buku di perpustakaan Universitas Sanata Dharma selama tahun 2018
sebanyak 78.779 data dan 33.917 transaksi. Atribut yang dipakai dari
data sebanyak dua yaitu id transaksi dan judul buku. Bentuk dari data
yang digunakan penulis berupa excel. Penulis mendapatkan data dari
bagian akademik di perpustakaan Sanata Dharma Mrican. Dalam
penelitian ini, data akan diproses dalam jangka waktu setiap bulan.
Untuk melihat jumlah transaksi tiap bulan dapat dilihat pada tabel 3.1.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
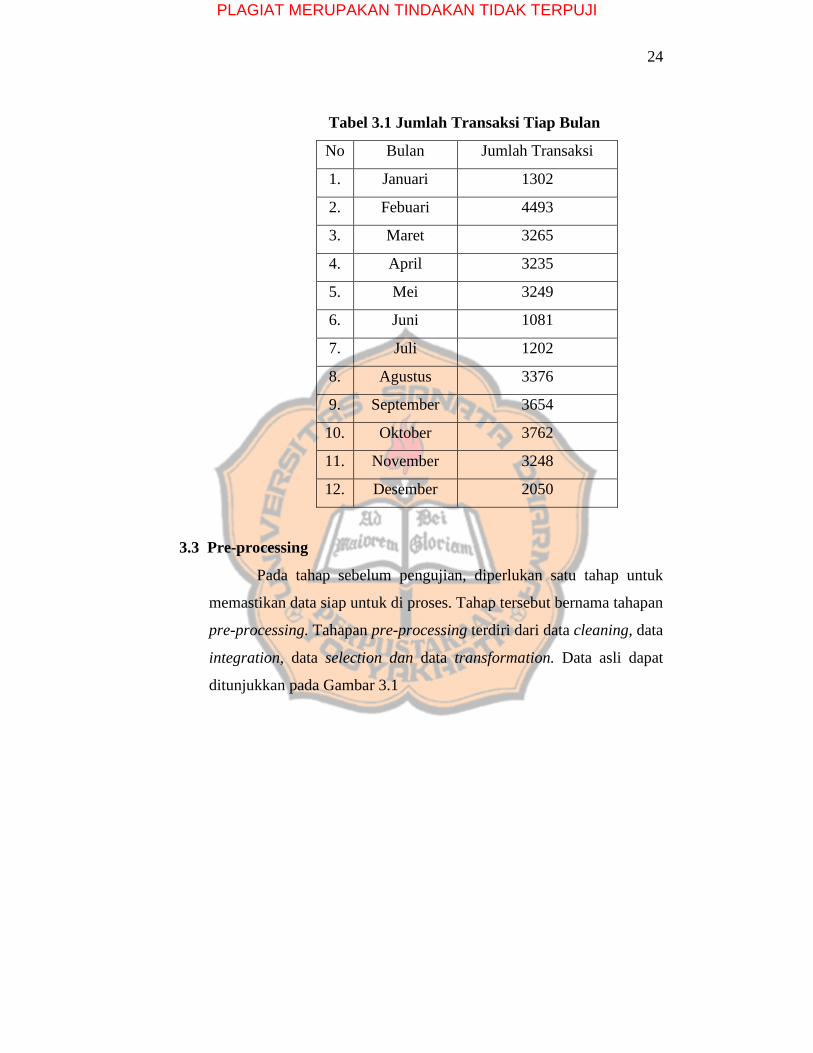
24
Tabel 3.1 Jumlah Transaksi Tiap Bulan
No Bulan Jumlah Transaksi
1. Januari 1302
2. Febuari 4493
3. Maret 3265
4. April 3235
5. Mei 3249
6. Juni 1081
7. Juli 1202
8. Agustus 3376
9. September 3654
10. Oktober 3762
11. November 3248
12. Desember 2050
3.3 Pre-processing
Pada tahap sebelum pengujian, diperlukan satu tahap untuk
memastikan data siap untuk di proses. Tahap tersebut bernama tahapan
pre-processing. Tahapan pre-processing terdiri dari data cleaning, data
integration, data selection dan data transformation. Data asli dapat
ditunjukkan pada Gambar 3.1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

25
Gambar 3.1 Data Asli
3.3.1 Data Cleaning
Pada tahapan ini beberapa data perlu dibersihkan karena tidak
sesuai dengan kriteria. Beberapa kriteria data yang perlu
dibersihkan adalah sebagai berikut:
1. Transaksi yang memiliki judul buku kosong.
2. Transaksi dengan peminjam bernama Mobile Library
USD.
Proses data cleaning dapat ditunjukkan pada gambar 3.2 dan
gambar 3.3.
Gambar 3.2 Data cleaning judul buku
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

26
Gambar 3.3 Data cleaning mobile library USD
3.3.2 Data Integration
Data transaksi peminjaman buku perpustakaan diperoleh dari
satu sumber dan sebanyak satu file excel yang berisi transaksi
peminjaman buku selama satu tahun pada tahun 2018.
Sehingga tidak diperlukan tahap data integration.
3.3.3 Data Selection
Pada data asli transaksi peminjaman buku di perpustakaan
terdapat 7 atribut yaitu no barcode, judul buku, tanggal pinjam,
tanggal perpanjangan, tanggal kembali, nomor anggota, dan
nama. Atribut yang digunakan oleh sistem untuk menganalisis
aturan asosiasi pada transaksi peminjaman atau penambangan
data hanya 2 atribut yaitu ID Transaksi dan judul buku.
ID Transaksi diperoleh dari proses pengolahan yaitu jika buku
yang dipinjam masih dalam satu nama peminjam yang sama
dan tanggal pinjam yang sama menjadi satu transaksi, Jika
nama peminjam dan tanggal pinjam berbeda sudah menjadi
transaksi yang baru.
3.3.4 Data Transformation
Tahapan ini adalah hasil dari data selection. Atribut yang telah
terpilih yaitu id transaksi dan judul buku ditampung sistem
dalam bentuk array untuk proses penambangan data.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

27
3.4 Peralatan Penelitian
Alat yang digunakan dalam penelitian ini adalah
1. Laptop dengan spesifikasi:
- Prosesor intel core i5 7200u
- Memory 4 GB
2. Software dengan spesifikasi:
- Windows 10 Home Single Language 64 bit
- Phytom.
3.5 Algoritma FP-Growth
Terdapat beberapa tahapan dari sistem yang akan dibangun, sebagai
berikut:
1. Tahap pertama dari sistem yang dibangun adalah membaca data
masukan yang berupa file bertipe .xls atau .xlsx
2. Selanjutnya, menginputkan nilai minimum support dan minimum
confidence.
3. Proses pembentukan aturan asosiasi yang sesuai dengan nilai
minimum support dan nilai minimum confidence.
4. Tahap terakhir dari sistem yang dibangun adalah menampilkan hasil
aturan asosiasi.
Tahapan dari sistem yang dibangun dapat digambarkan pada gambar 3.4.
Gambar 3. 4 Flowchart sistem
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

28
Pada proses perhitungan menggunakan algoritma FP-Growth terdapat
beberapa langkah penting yang harus diperhatikan yaitu:
1. Perhitungan count pada setiap item.
2. Pembentukan FP-Tree.
3. Pembuatan Conditional Pattern Base.
4. Pembuatan Conditional FP-Tree.
5. Pembuatan Frequent Itemset.
Tahapan proses FP-Growth dapat digambarkan dalam flowchart pada
Gambar 3.5
Gambar 3. 5 Flowchart Proses FP-Growth dan Aturan Asosiasi
Pada tahapan proses FP-Growth dan aturan asosiasi menggunakan
beberapa function. Function yang digunakan dapat dilihat pada tabel
3.2:
Tabel 3.2 Nama Function yang Digunakan
No Proses Nama Function
1. Menghitung count pada setiap item FPGrowth
2. Membentuk FP-Tree FPcommons
3. Membuat Conditional Pattern Base FPGrowth
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
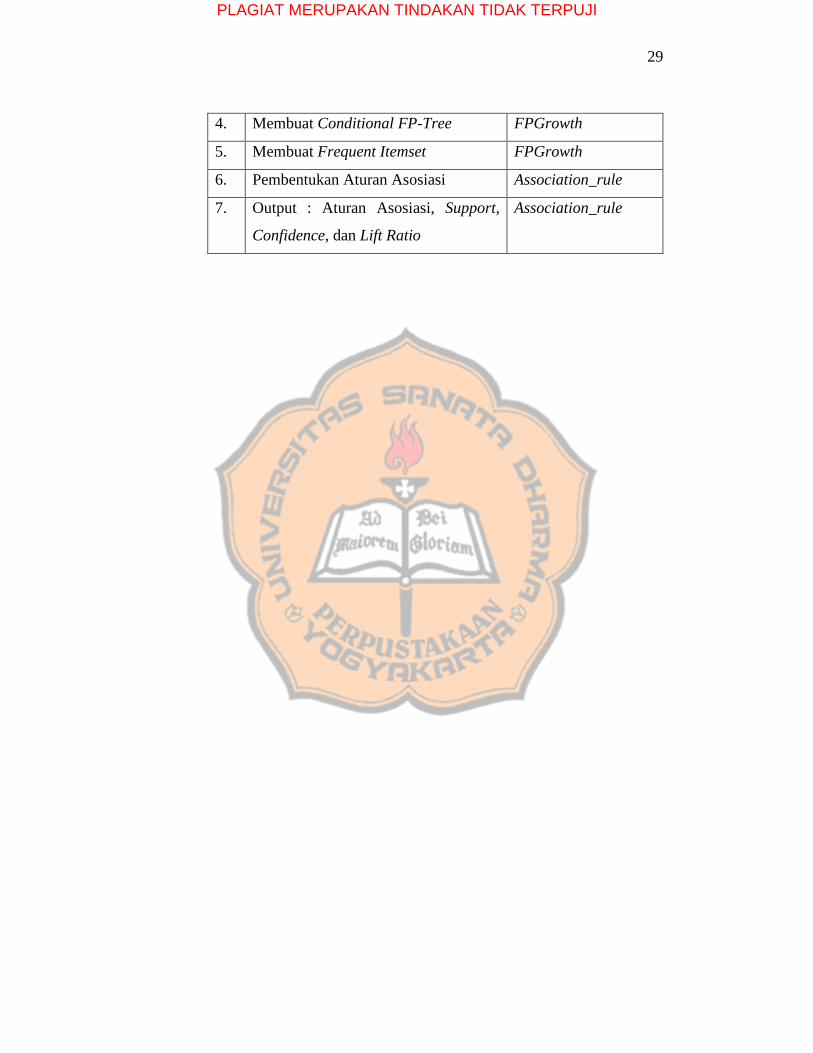
29
4. Membuat Conditional FP-Tree FPGrowth
5. Membuat Frequent Itemset FPGrowth
6. Pembentukan Aturan Asosiasi Association_rule
7. Output : Aturan Asosiasi, Support,
Confidence, dan Lift Ratio
Association_rule
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

30
BAB IV
ANALISA DAN DESAIN SISTEM
4.1 Model Fungsi Sistem
4.1.1 Diagram Use Case
Diagram Use Case adalah diagram yang digunakan untuk
mendokumentasikan dan menjelaskan interaksi antara pengguna
dengan sistem. Sistem ini terdapat satu pengguna atau actor yang
dapat menginput file data transaksi peminjaman buku. Proses
selanjutnya adalah menginput nilai minimum support dan minimum
confidence. Langkah berikutnya adalah mengklik tombol proses
untuk melakukan proses penghitungan menggunakan algoritma
FP-Growth. Pengguna dapat melihat hasil dari penghitungan
berupa rule. Diagram use case yang digunakan dapat dilihat pada
Gambar 4.1.
Gambar 4.1 Diagram Use Case
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

31
4.1.2 Narasi Use Case
Narasi use case adalah penjelasan dari setiap use case dari Gambar
4.1.
Tabel 4.1 Input File
Input File
Nama Usecase Input Data Transaksi Peminjaman Buku
Id Usecase 001
Aktor Pengguna
Deskripsi Pengguna dapat melakukan input file data transaksi
belanja dalam bentuk excel dengan tipe .csv dengan
menekan tombol “Cari File”.
Kondisi Awal Pengguna masuk dalam sistem.
Kondisi Akhir Setelah file diinputkan maka sistem akan menyimpan
data transaksi peminjaman buku yang telah dipilih.
Typical Course Aksi Pengguna Reaksi Sistem
LANGKAH 1:
Menekan tombol “Cari
File”.
LANGKAH 2:
Menampilkan kotak
dialog dari direktori
pc/laptop pengguna untuk
memilih file.
LANGKAH 3:
Memilih file data bertipe
.csv atau .csv
LANGKAH 4:
Menyimpan file data
transaksi belanja
Alternate Course -
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

32
Tabel 4.2 Input Nilai Minimum Support
Input nilai minimum support
Nama Usecase Input Nilai Minimum Support
Id Usecase 002
Aktor Pengguna
Deskripsi Pengguna dapat melakukan input nilai minimum
support sesuai dengan nilai yang diinginkan.
Kondisi Awal Nilai minimum support belum terisi.
Kondisi Akhir Setelah nilai minimum support dimasukkan maka
sistem akan menampilkan nilai minimum support.
Typical Course Aksi Pengguna Reaksi Sistem
LANGKAH 1:
Mengklik ke text field
minimum support.
LANGKAH 2:
Memasukkan nilai
minimum support.
LANGKAH 3:
Menampilkan persentase
dari nilai minimum
support.
Alternate Course -
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
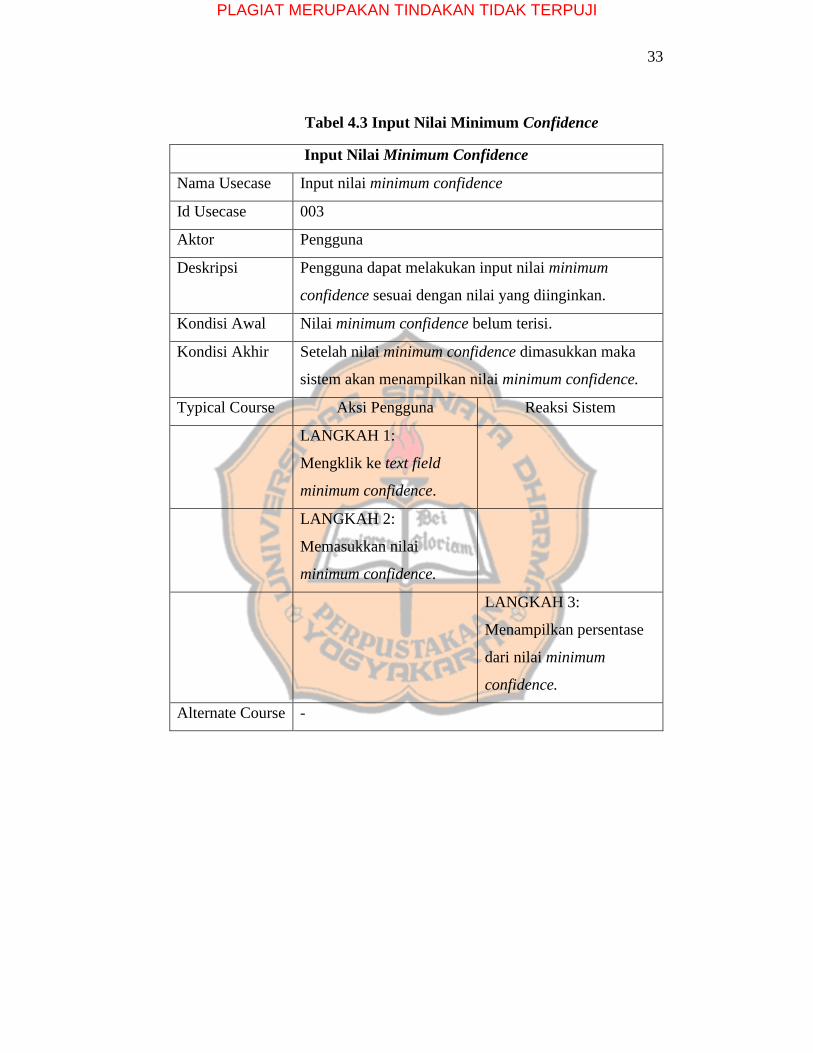
33
Tabel 4.3 Input Nilai Minimum Confidence
Input Nilai Minimum Confidence
Nama Usecase Input nilai minimum confidence
Id Usecase 003
Aktor Pengguna
Deskripsi Pengguna dapat melakukan input nilai minimum
confidence sesuai dengan nilai yang diinginkan.
Kondisi Awal Nilai minimum confidence belum terisi.
Kondisi Akhir Setelah nilai minimum confidence dimasukkan maka
sistem akan menampilkan nilai minimum confidence.
Typical Course Aksi Pengguna Reaksi Sistem
LANGKAH 1:
Mengklik ke text field
minimum confidence.
LANGKAH 2:
Memasukkan nilai
minimum confidence.
LANGKAH 3:
Menampilkan persentase
dari nilai minimum
confidence.
Alternate Course -
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
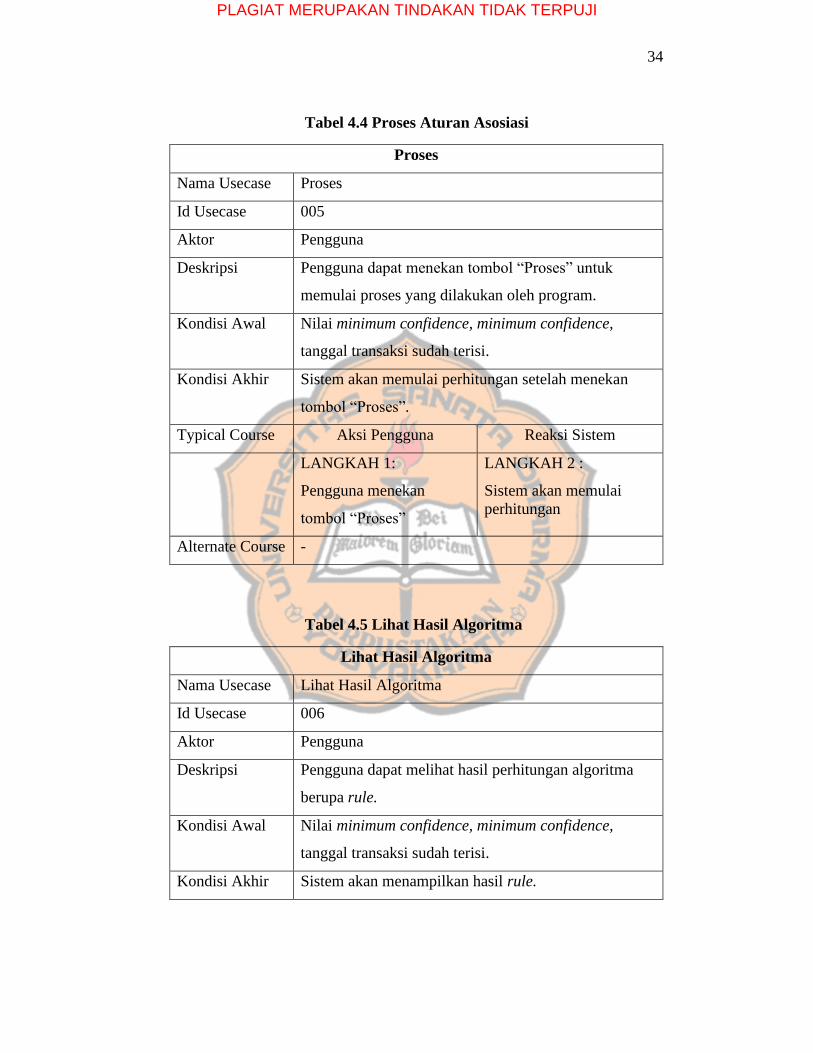
34
Tabel 4.4 Proses Aturan Asosiasi
Proses
Nama Usecase Proses
Id Usecase 005
Aktor Pengguna
Deskripsi Pengguna dapat menekan tombol “Proses” untuk
memulai proses yang dilakukan oleh program.
Kondisi Awal Nilai minimum confidence, minimum confidence,
tanggal transaksi sudah terisi.
Kondisi Akhir Sistem akan memulai perhitungan setelah menekan
tombol “Proses”.
Typical Course Aksi Pengguna Reaksi Sistem
LANGKAH 1:
Pengguna menekan
tombol “Proses”
LANGKAH 2 :
Sistem akan memulai
perhitungan
Alternate Course -
Tabel 4.5 Lihat Hasil Algoritma
Lihat Hasil Algoritma
Nama Usecase Lihat Hasil Algoritma
Id Usecase 006
Aktor Pengguna
Deskripsi Pengguna dapat melihat hasil perhitungan algoritma
berupa rule.
Kondisi Awal Nilai minimum confidence, minimum confidence,
tanggal transaksi sudah terisi.
Kondisi Akhir Sistem akan menampilkan hasil rule.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

35
Typical Course Aksi Pengguna Reaksi Sistem
LANGKAH 2 :
Sistem akan menampilkan
hasil rule dari perhitungan
algoritma.
Alternate Course -
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

36
4.2 Desain Antar Muka Pengguna
Gambar 4.2 Desain Antarmuka dengan Pengguna
Keterangan:
1. Header – Menampilkan judul.
2. Cari File – Tombol yang digunakan untuk memasukkan file.
3. Tabel Dataset – Menampilkan dataset peminjaman perpustakaan.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

37
4. Minimum support – Memasukkan nilai minimal support yang akan
dicari.
5. Minimum confidence - Memasukkan nilai minimal confidence yang
akan dicari.
6. Proses – Tombol untuk menghitung asosiasi data.
7. Aturan asosiasi – Menampilkan hasil dari pengujian data yang telah
dihitung
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

52
BAB V
IMPLEMENTASI DAN ANALISIS HASIL
5.1 Implementasi Sistem
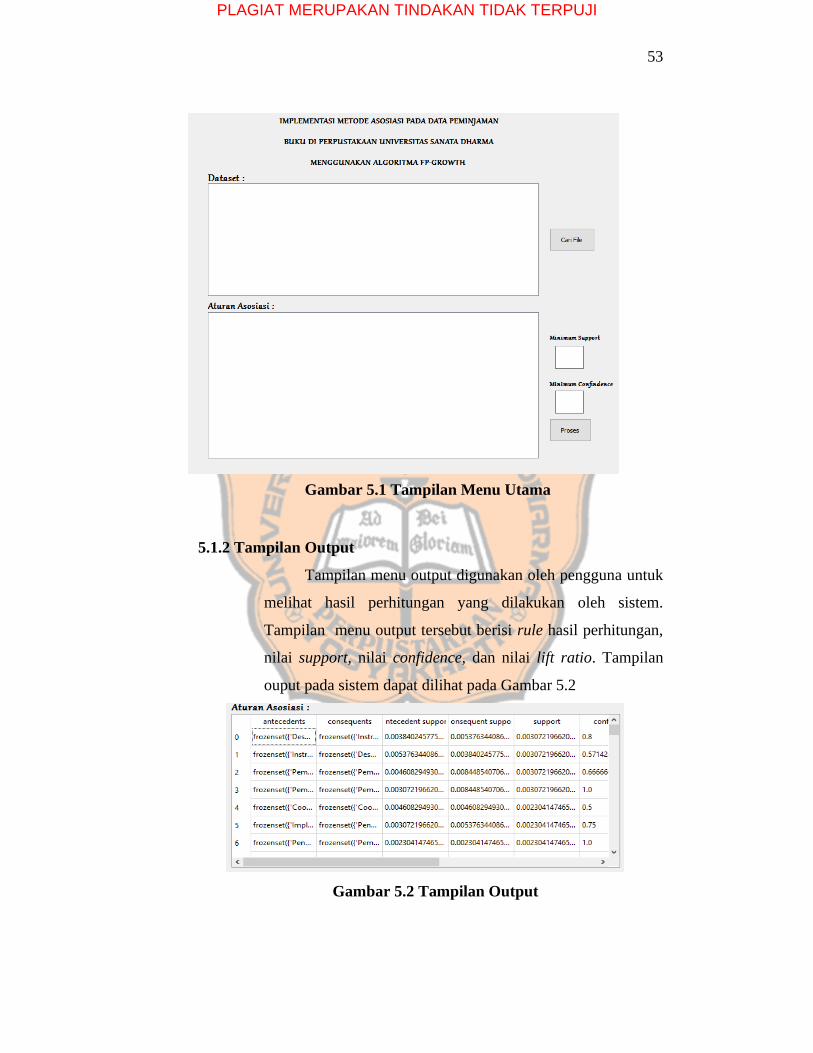
5.1.1 Tampilan Menu Utama
Tampilan menu utama merupakan halaman awal pada
program. Pada tampilan utama terdapat tampilan dataset,
tombol cari file, tampilan hasil aturan asosiasi, menu inputan
minimum support, menu inputan minimum confidence, dan
tombol proses. Tampilan dataset merupakan tampilan isi file
yang akan diproses. Tombol cari file merupakan tombol yang
berguna untuk memilih file dari direktori yang akan diproses
oleh sistem. Tampilan hasil aturan asosiasi merupakan tampilan
aturan hasil asosiasi yang telah diproses oleh sistem. Menu
inputan minimum support merupakan inputan yang paling
minimum untuk support (ukuran yang menunjukkan persentase
suatu item kombinasi dari keseluruhan transaksi). Sedangkan
menu minimum confidence (ukuran yang menunjukkan item-
item yang paling sering muncul dalam keseluruhan transaksi).
Tampilan menu utama pada sistem dapat dilihat pada
Gambar 5.1.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
53
Gambar 5.1 Tampilan Menu Utama
5.1.2 Tampilan Output
Tampilan menu output digunakan oleh pengguna untuk
melihat hasil perhitungan yang dilakukan oleh sistem.
Tampilan menu output tersebut berisi rule hasil perhitungan,
nilai support, nilai confidence, dan nilai lift ratio. Tampilan
ouput pada sistem dapat dilihat pada Gambar 5.2
Gambar 5.2 Tampilan Output
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

54
5.1.3 Implementasi function dalam sistem
Dalam proses FP-Growth dan aturan asosiasi terdapat beberapa tahapan
yang menggunakan function. Berikut penggalan program terkait
pemanggilan function:
5.1.3.1. Function yang digunakan
Penggalan program pertama berupa semua function yang
digunakan di dalam program. Tampilan penggalan
program pertama dapat dilihat pada Gambar 5.3.
Gambar 5.3 Function yang digunakan
5.1.3.2. Function mlx.preprocessing
Penggalan program kedua berupa function
mlx.preprocessing yang berfungsi untuk melakukan pre-
processing data sebelum diproses oleh sistem. Tampilan
penggalan program kedua dapat dilihat pada Gambar 5.4.
Gambar 5.4 Function mlx.preprocessing
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
55
5.1.3.3. Function mlx.frequentspatterns
Penggalan program ketiga berupa function
mlx.frequentspatterns yang berfungsi untuk memeilih
algoritma asosiasi yang digunakan dalam penelitian.
Tampilan penggalan program ketiga dapat dilihat pada
Gambar 5.5.
Gambar 5.5 Function mlx.frequentspatterns
5.1.3.4. Function fpcommons
Penggalan program keempat berupa function fpcommons
yang berfungsi untuk pembuatan FP-Tree sesuai dengan
data transaksi. Tampilan penggalan program ketiga dapat
dilihat pada Gambar 5.6.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
56
Gambar 5.6 Function fpcommons
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

57
5.1.3.5. Function fpgrowth
Penggalan program kelima berupa function fpgrowth yang
berfungsi untuk melakukan tahapan – tahapan penting
seperti pembentukan conditional pattern base, conditional
fp-tree dan pembentukan frequent itemset. Tampilan
penggalan program ketiga dapat dilihat pada Gambar 5.7.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

58
Gambar 5.7 Function fpgrowth
5.1.3.6. Function association_rules
Penggalan program keenam berupa function
association_rules yang berfungsi untuk melakukan
perhitungan data untuk menampilkan nilai support,
confidence, dan lift ratio dari aturan yang telah terbentuk.
Tampilan penggalan program keenam dapat dilihat pada
Gambar 5.8.
Gambar 5.8 Function association_rules
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

59
5.2 Hasil Pengujian
5.2.1 Uji Validasi
Pengujian validasi program dilakukan untuk menguji
apakah program yang sudah dibuat sesuai dengan fungsi-fungsi
terhadap keperluan yang sudah dirancang. Dalam penelitian
ini, program diuji apakah dapat digunakan untuk menghasilkan
aturan asosiasi sesuai metode “analisis keranjang belanja”
dengan menggunakan uji validasi manual dan uji validasi
program.
Pada pengujian ini menggunakan sampel data sebanyak
10 transaksi. Hasil uji validasi menggunakan perhitungan
manual.
5.2.1.1 Perhitungan Manual
Pada perhitungan manual, penulis melakukan langkah-
langkah sebagai berikut:
a. Menghitung count pada setiap item.
Pada tahap pertama, dilakukan pencarian count untuk
setiap buku pada data transaksi peminjaman buku. Sebagai
contoh, terdapat data sampel pengujian peminjaman buku
yang ditunjukkan pada Tabel 5.1.
Tabel 5.1 Contoh Data
id_tr buku 1 Language and gender
1 An introduction to sociolinguistics
(2nd Edition) 1 Sociolinguistics
1 Sociolinguistics : a resource book
for students
1 Discussing language
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
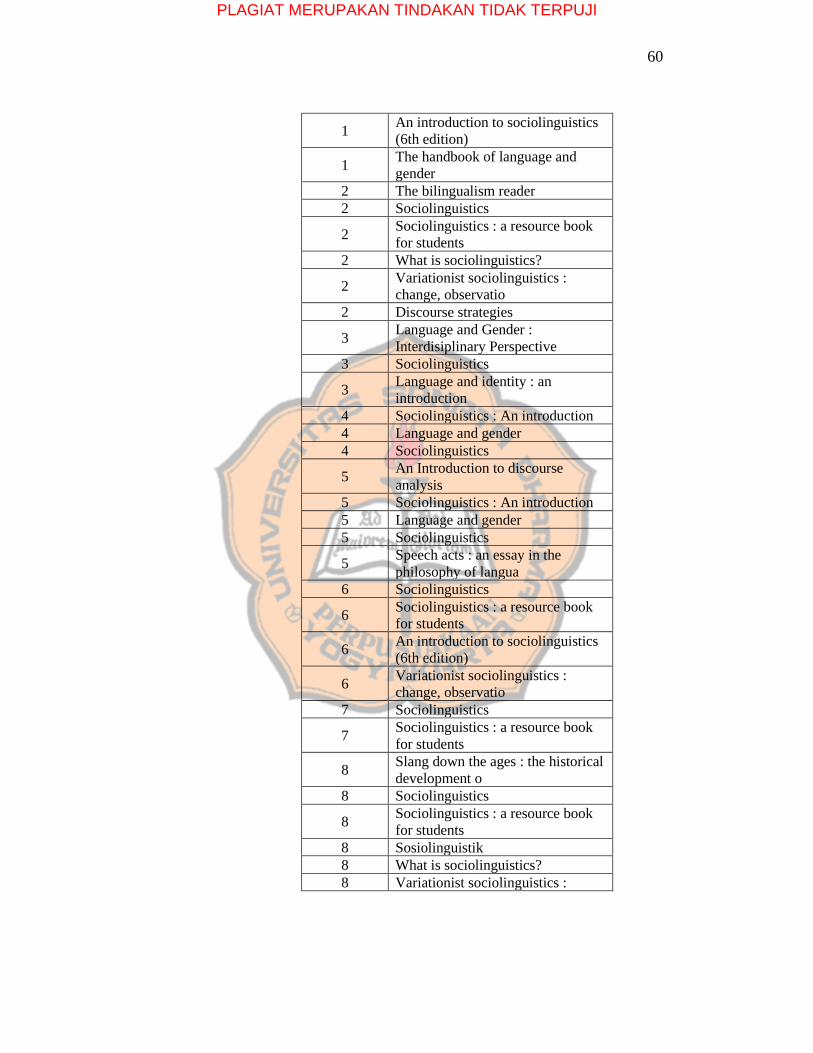
60
1 An introduction to sociolinguistics
(6th edition)
1 The handbook of language and
gender 2 The bilingualism reader 2 Sociolinguistics
2 Sociolinguistics : a resource book
for students 2 What is sociolinguistics?
2 Variationist sociolinguistics :
change, observatio 2 Discourse strategies
3 Language and Gender :
Interdisiplinary Perspective 3 Sociolinguistics
3 Language and identity : an
introduction 4 Sociolinguistics : An introduction 4 Language and gender 4 Sociolinguistics
5 An Introduction to discourse
analysis 5 Sociolinguistics : An introduction 5 Language and gender 5 Sociolinguistics
5 Speech acts : an essay in the
philosophy of langua 6 Sociolinguistics
6 Sociolinguistics : a resource book
for students
6 An introduction to sociolinguistics
(6th edition)
6 Variationist sociolinguistics :
change, observatio 7 Sociolinguistics
7 Sociolinguistics : a resource book
for students
8 Slang down the ages : the historical
development o 8 Sociolinguistics
8 Sociolinguistics : a resource book
for students 8 Sosiolinguistik 8 What is sociolinguistics? 8 Variationist sociolinguistics :
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

61
change, observatio
8 Global English slang :
methodologies and perspecti 9 The bilingualism reader 9 Bilingualism [1996]
9 An introduction to sociolinguistics
(6th edition) 9 Discourse strategies 10 The bilingualism reader 10 An introduction to bilingualism 10 Bilingualism [1996]
Untuk mempermudah dalam proses perhitungan, setiap
judul buku ditransformasi menjadi kode angka, sebagai
berikut:
1 = Language and gender
2 = An introduction to sociolinguistics (2nd Edition)
3 = Sociolinguistics
4 = Sociolinguistics : a resource book for students
5 = Discussing language
6 = An introduction to sociolinguistics (6th edition)
7 = The handbook of language and gender
8 = The bilingualism reader
9 = What is sociolinguistics?
10 = Variationist sociolinguistics : change, observation
11 = Discourse strategies
12 = Language and Gender : Interdisiplinary Perspective
13 = Language and identity : an introduction
14 = Sociolinguistics : An introduction
15 = An Introduction to discourse analysis
16 = Speech acts : an essay in the philosophy of langua
17 = Slang down the ages : the historical development o
18 = Bilingualism [1996]
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

62
19 = An introduction to bilingualism
Berdasarkan keterangan di atas dapat dijelaskan secara
lebih singkat melalui Tabel 5.2
Tabel 5.2 Penyederhanaan Daftar Buku
T id Daftar Buku
T1 1,2,3,4,5,6,7
T2 8,3,4,9,10,11
T3 12,3,13
T4 14,1,3
T5 15,14,1,3,16
T6 3,4,6,10
T7 3,4
T8 17,3,4,9,10
T9 8,18,6,11
T10 8,18,19
Tabel 5.3 menunjukkan nilai support count dari setiap itemset. Untuk
menuju ke tahap berikutnya ditentukan nilai minimum support sebesar
2. Dari tabel 5.3, jika item yang memiliki nilai support count dibawah 2
maka akan dihapus.
Tabel 5.3 Item dan Count
Item Count
1 3
2 1
3 8
4 5
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
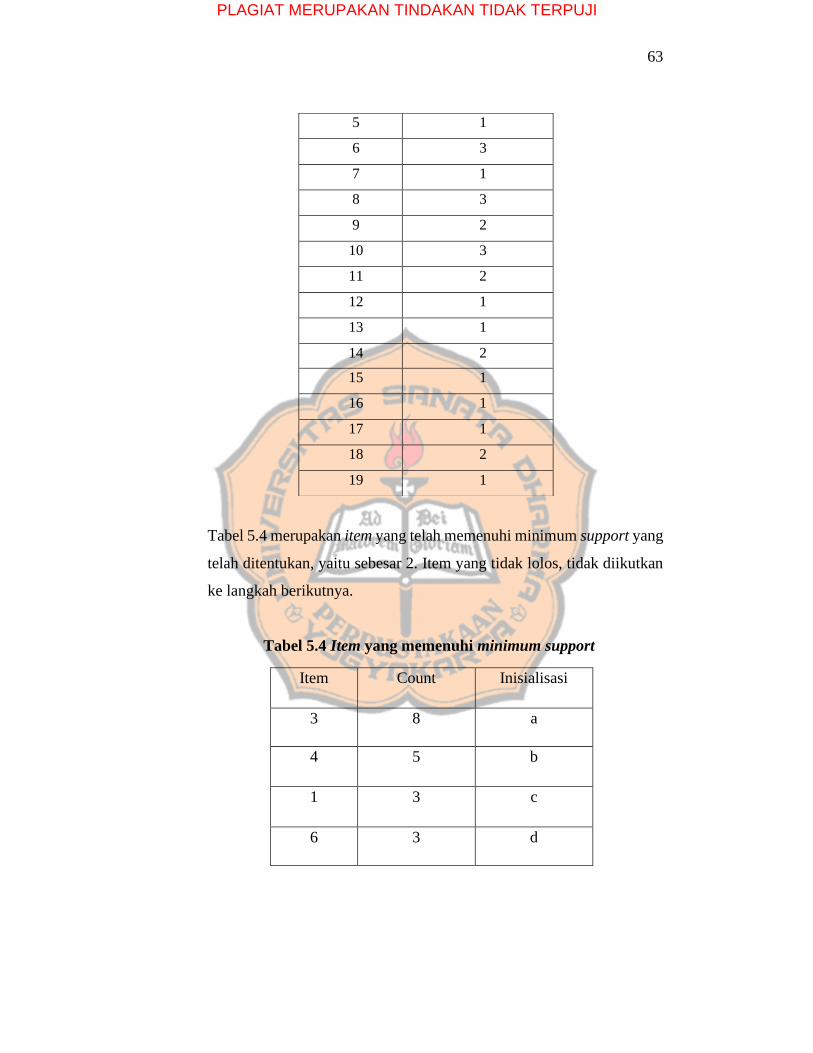
63
Tabel 5.4 merupakan item yang telah memenuhi minimum support yang
telah ditentukan, yaitu sebesar 2. Item yang tidak lolos, tidak diikutkan
ke langkah berikutnya.
Tabel 5.4 Item yang memenuhi minimum support
Item Count Inisialisasi
3 8 a
4 5 b
1 3 c
6 3 d
5 1
6 3
7 1
8 3
9 2
10 3
11 2
12 1
13 1
14 2
15 1
16 1
17 1
18 2
19 1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
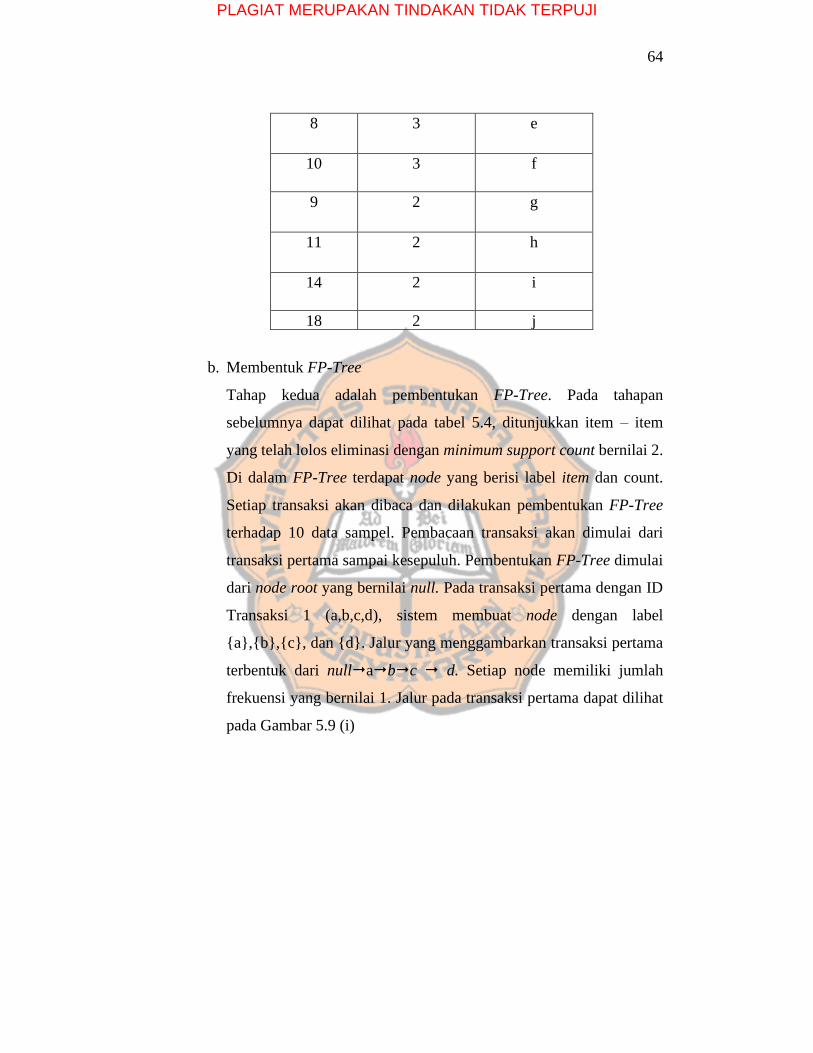
64
8 3 e
10 3 f
9 2 g
11 2 h
14 2 i
18 2 j
b. Membentuk FP-Tree
Tahap kedua adalah pembentukan FP-Tree. Pada tahapan
sebelumnya dapat dilihat pada tabel 5.4, ditunjukkan item – item
yang telah lolos eliminasi dengan minimum support count bernilai 2.
Di dalam FP-Tree terdapat node yang berisi label item dan count.
Setiap transaksi akan dibaca dan dilakukan pembentukan FP-Tree
terhadap 10 data sampel. Pembacaan transaksi akan dimulai dari
transaksi pertama sampai kesepuluh. Pembentukan FP-Tree dimulai
dari node root yang bernilai null. Pada transaksi pertama dengan ID
Transaksi 1 (a,b,c,d), sistem membuat node dengan label
{a},{b},{c}, dan {d}. Jalur yang menggambarkan transaksi pertama
terbentuk dari nullabc d. Setiap node memiliki jumlah
frekuensi yang bernilai 1. Jalur pada transaksi pertama dapat dilihat
pada Gambar 5.9 (i)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
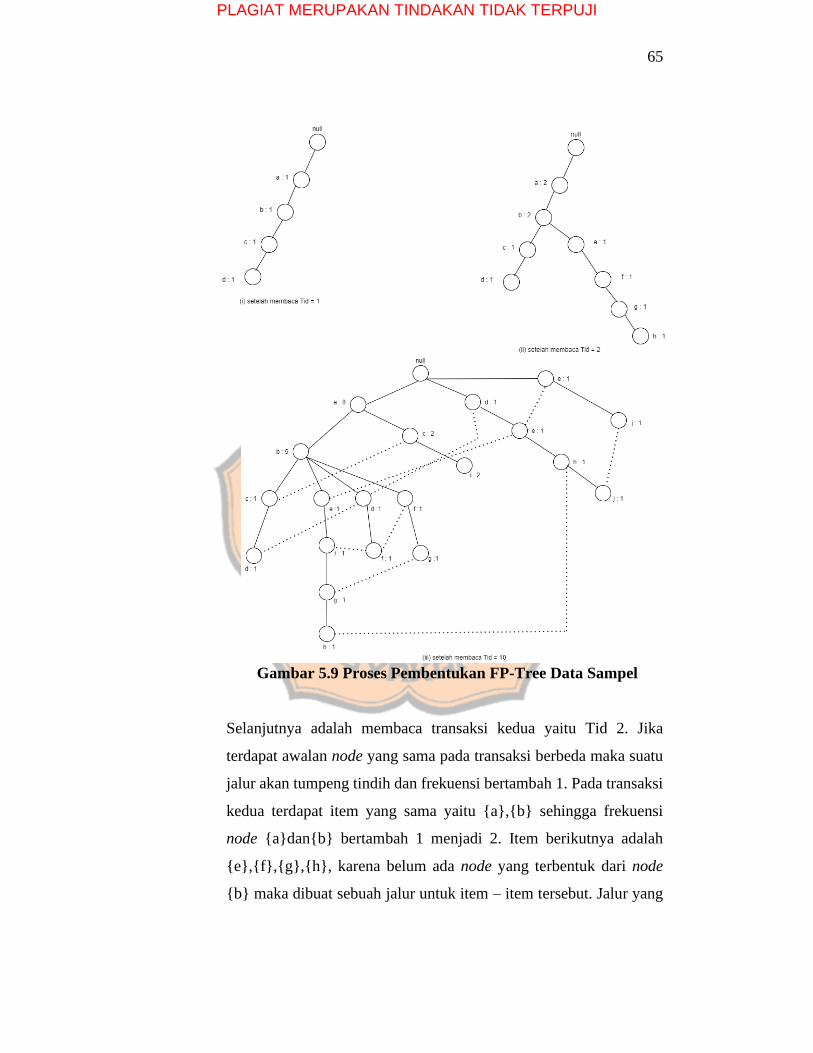
65
Gambar 5.9 Proses Pembentukan FP-Tree Data Sampel
Selanjutnya adalah membaca transaksi kedua yaitu Tid 2. Jika
terdapat awalan node yang sama pada transaksi berbeda maka suatu
jalur akan tumpeng tindih dan frekuensi bertambah 1. Pada transaksi
kedua terdapat item yang sama yaitu {a},{b} sehingga frekuensi
node {a}dan{b} bertambah 1 menjadi 2. Item berikutnya adalah
{e},{f},{g},{h}, karena belum ada node yang terbentuk dari node
{b} maka dibuat sebuah jalur untuk item – item tersebut. Jalur yang
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

66
menggambarkan transaksi kedua terbentuk dari nullabe
fgh. Jalur pada transaksi kedua dapat dilihat pada Gambar 5.9 (ii)
Proses pembentukan FP-Tree dilakukan sampai transaksi terkahir
yaitu Tid 10. Pembentukan FP-Tree yang sudah membaca seluruh
transaksi dapat dilihat pada Gambar 5.9 (iii).
Dalam proses pembentukan FP-Tree, jika terdapat awalan node yang
sama pada transaksi yang sebelumnya atau yang sudah terdapat node
nya maka suatu jalur akan tumpeng tindih dan jumlah frekuensi
bertambah 1 terhadap node tersebut. Jika awalan node berbeda akan
terbentuk jalur baru dari root dengan frekuensi bernilai 1. Garis putus
– putus pada Gambar 5.9 (iii) menunjukkan node yang memiliki label
yang sama.
c. Pembentukan Conditional Pattern Base, Conditional FP-Tree dan
Frequent Itemset
Tahapan berikutnya adalah pembentukan Conditional Pattern Base,
Conditional FP-Tree dan Frequent Itemset dari FP-Tree yang telah
terbentuk dengan menjelajah tree yang telah terbentuk secara
bottom-up. Penulis mengambil contoh node dengan akhiran {j}.
Langkah berikutnya adalah melakukan pengecekan terhadap
frekuensi kemunculan node {j}. Dapat dilihat jalur yang memiliki
akhiran node {j} yaitu {e:1} dan {deh:1} sehingga node tersebut
menjadi conditional pattern base. Langkah berikutnya adalah
melakukan pengecekan terhadap count dari conditional pattern base.
Dalam jalur ini terdapat node {e} yang memiliki frekuensi
kemunculan sebanyak 2 kali bersama dengan node {j} pada tree yang
sudah dipetakan.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
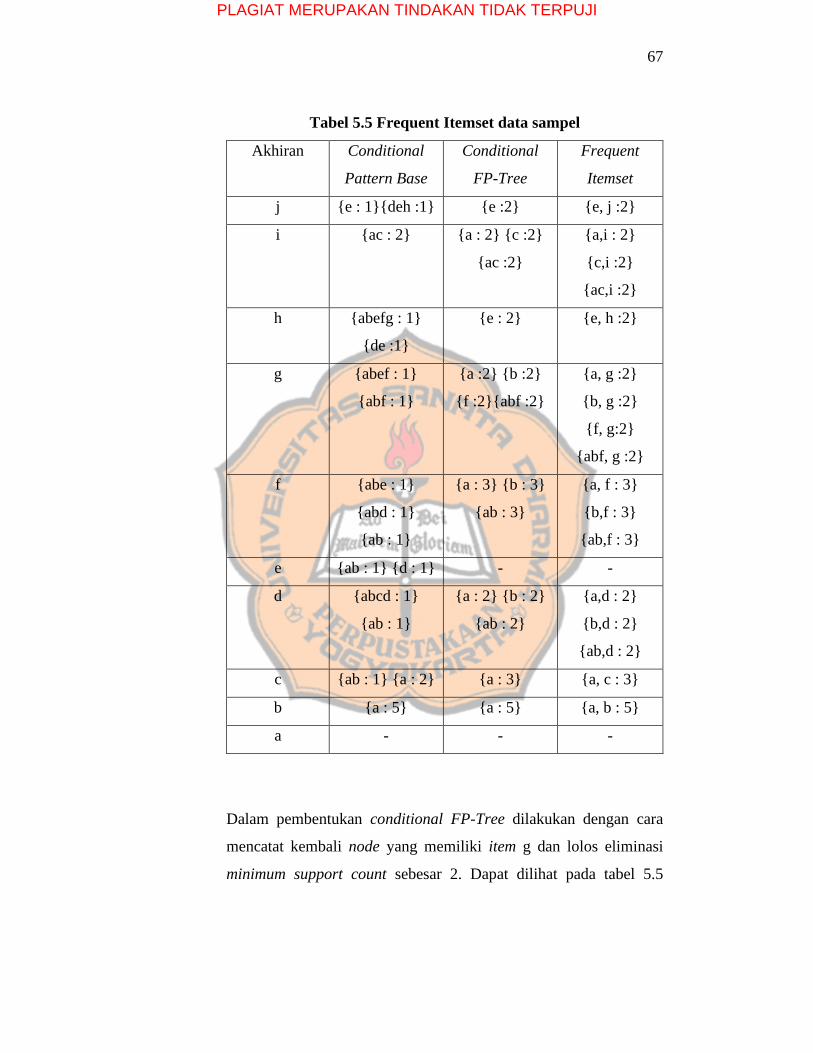
67
Tabel 5.5 Frequent Itemset data sampel
Akhiran Conditional
Pattern Base
Conditional
FP-Tree
Frequent
Itemset
j {e : 1}{deh :1} {e :2} {e, j :2}
i {ac : 2} {a : 2} {c :2}
{ac :2}
{a,i : 2}
{c,i :2}
{ac,i :2}
h {abefg : 1}
{de :1}
{e : 2} {e, h :2}
g {abef : 1}
{abf : 1}
{a :2} {b :2}
{f :2}{abf :2}
{a, g :2}
{b, g :2}
{f, g:2}
{abf, g :2}
f {abe : 1}
{abd : 1}
{ab : 1}
{a : 3} {b : 3}
{ab : 3}
{a, f : 3}
{b,f : 3}
{ab,f : 3}
e {ab : 1} {d : 1} - -
d {abcd : 1}
{ab : 1}
{a : 2} {b : 2}
{ab : 2}
{a,d : 2}
{b,d : 2}
{ab,d : 2}
c {ab : 1} {a : 2} {a : 3} {a, c : 3}
b {a : 5} {a : 5} {a, b : 5}
a - - -
Dalam pembentukan conditional FP-Tree dilakukan dengan cara
mencatat kembali node yang memiliki item g dan lolos eliminasi
minimum support count sebesar 2. Dapat dilihat pada tabel 5.5
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

68
conditional FP-Tree dengan akhiran node {j} adalah {e : 2}. Node
{d} dan {h} dieliminasi karena memiliki minimum support count
dibawah 2. Tahap ini juga bisa disebut tahap pemetaan karena
memetakan semua node. Sebagai contoh node dengan akhiran {i}.
Dapat dilihat pada Tabel 5., jalur yang memiliki atau diakhiri node
{i} adalah {ac} dengan count sebanyak 2. Proses pembentukan
conditional FP-Tree dengan jalur {ac} dipetakan menjadi {a},{c},
dan {ac}.
Tahapan berikutnya adalah pembentukan frequent itemset. Node
yang berada di conditional FP-Tree ditambahkan dengan node yang
sesuai akhirannya. Contohnya adalah {e, j : 2}. Proses pembentukan
frequent itemset dapat dilihat pada tabel 3.7. Tahapan ini berlanjut
sampai semua jalur yang diakhiri atau dilewati node
{i},{h},{g},{f},{e},{d},{c},{b},{a} diproses.
5.2.1.2 Aturan Asosiasi
Hasil dari frequent itemset algoritma FP-Growth akan diproses
untuk membentuk aturan asosiasi. Dapat dilihat pada Tabel 5.4
penulis menentukan nilai minimum support count sebesar 2 dan
nilai minimum confidence sebesar 50%. Aturan asosiasi yang
tidak memenuhi nilai minimum support count dan nilai
minimum confidence akan di eliminasi. Hasil aturan asosiasi
dapat ditunjukkan pada Tabel 5.6.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
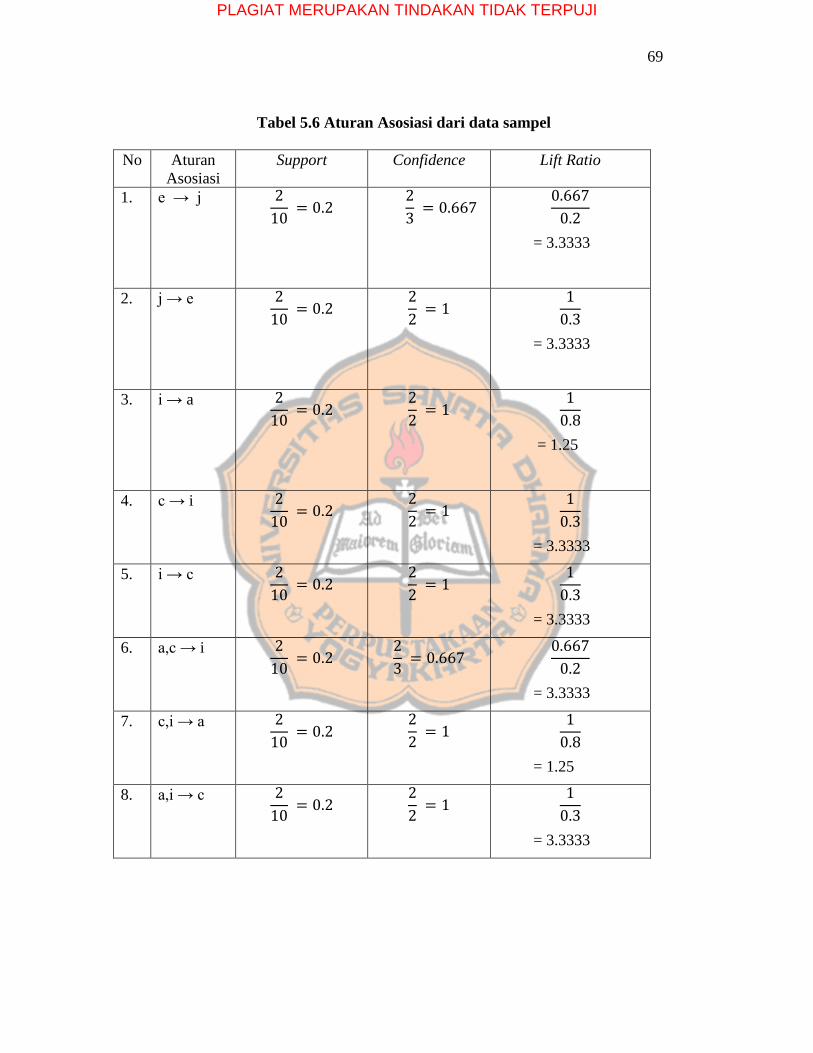
69
Tabel 5.6 Aturan Asosiasi dari data sampel
No Aturan
Asosiasi
Support Confidence Lift Ratio
1. e → j 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.3333
2. j → e 2
10 = 0.2
2
2 = 1
1
0.3
= 3.3333
3. i → a 2
10 = 0.2
2
2 = 1
1
0.8
= 1.25
4. c → i 2
10 = 0.2
2
2 = 1
1
0.3
= 3.3333
5. i → c 2
10 = 0.2
2
2 = 1
1
0.3
= 3.3333
6. a,c → i 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.3333
7. c,i → a 2
10 = 0.2
2
2 = 1
1
0.8
= 1.25
8. a,i → c 2
10 = 0.2
2
2 = 1
1
0.3
= 3.3333
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
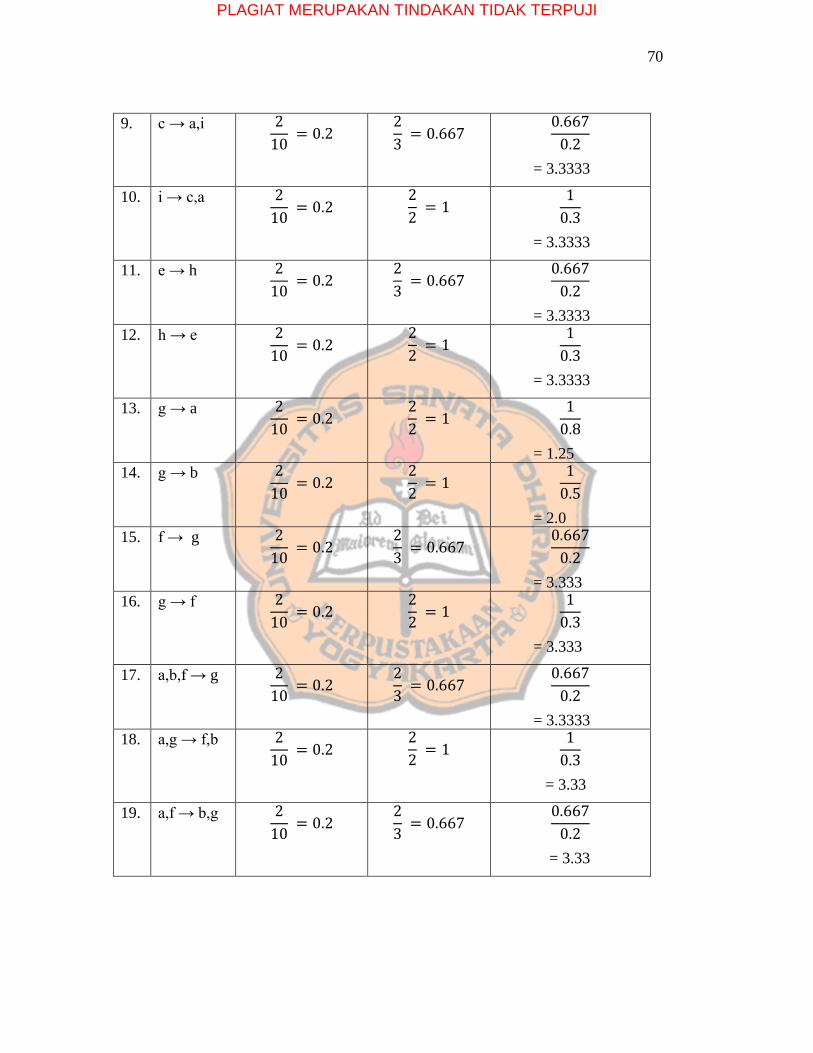
70
9. c → a,i 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.3333
10. i → c,a 2
10 = 0.2
2
2 = 1
1
0.3
= 3.3333
11. e → h 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.3333
12. h → e 2
10 = 0.2
2
2 = 1
1
0.3
= 3.3333
13. g → a 2
10 = 0.2
2
2 = 1
1
0.8
= 1.25
14. g → b 2
10 = 0.2
2
2 = 1
1
0.5
= 2.0
15. f → g 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.333
16. g → f 2
10 = 0.2
2
2 = 1
1
0.3
= 3.333
17. a,b,f → g 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.3333
18. a,g → f,b 2
10 = 0.2
2
2 = 1
1
0.3
= 3.33
19. a,f → b,g 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.33
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
71
20. f,b,g → a 2
10 = 0.2
2
2 = 1
1
0.8
= 1.25
21. a,f,g → b 2
10 = 0.2
2
2 = 1
1
0.5
= 2
22. f,b → a,g 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.333
23. b,g →a,f 2
10 = 0.2
2
2 = 1
1
0.3
= 3.33
24. f,g → a,b 2
10 = 0.2
2
2 = 1
1
0.5
= 2
25. f → a,b,g 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.33
26. g → a,f,b 2
10 = 0.2
2
2 = 1
1
0.3
= 3.33
27. a,b,g → f 2
10 = 0.2
2
2 = 1
1
0.3
= 3.33
28. f → a,g 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.33
29. g → a,b 2
10 = 0.2
2
2 = 1
1
0.5
= 2
30. b,g →a 2
10 = 0.2
2
2 = 1
1
0.8
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
72
= 1.25
31. f → a 3
10 = 0.3
2
2 = 1
1
0.8
= 1.25
32. f → b 3
10 = 0.3
2
2 = 1
1
0.5
= 2.0
33. f → a,b 3
10 = 0.3
2
2 = 1
1
0.4
= 2.0
34. b → a,f 3
10 = 0.3
3
5 = 0.6
0.6
0.3
= 2
35. f,b → a 3
10 = 0.3
3
3 = 1
1
0.8
= 1.25
36. a,f → b 3
10 = 0.3
3
3 = 1
1
0.5
= 2
37. a,b →f 3
10 = 0.3
3
5 = 0.6
0.6
0.3
= 2
38. b → f 3
10 = 0.3
3
5 = 0.6
0.6
0.3
= 2
39. f,b → g 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.3333
40. b,g → f 2
10 = 0.2
2
2 = 1
1
0.3
= 3.3333
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
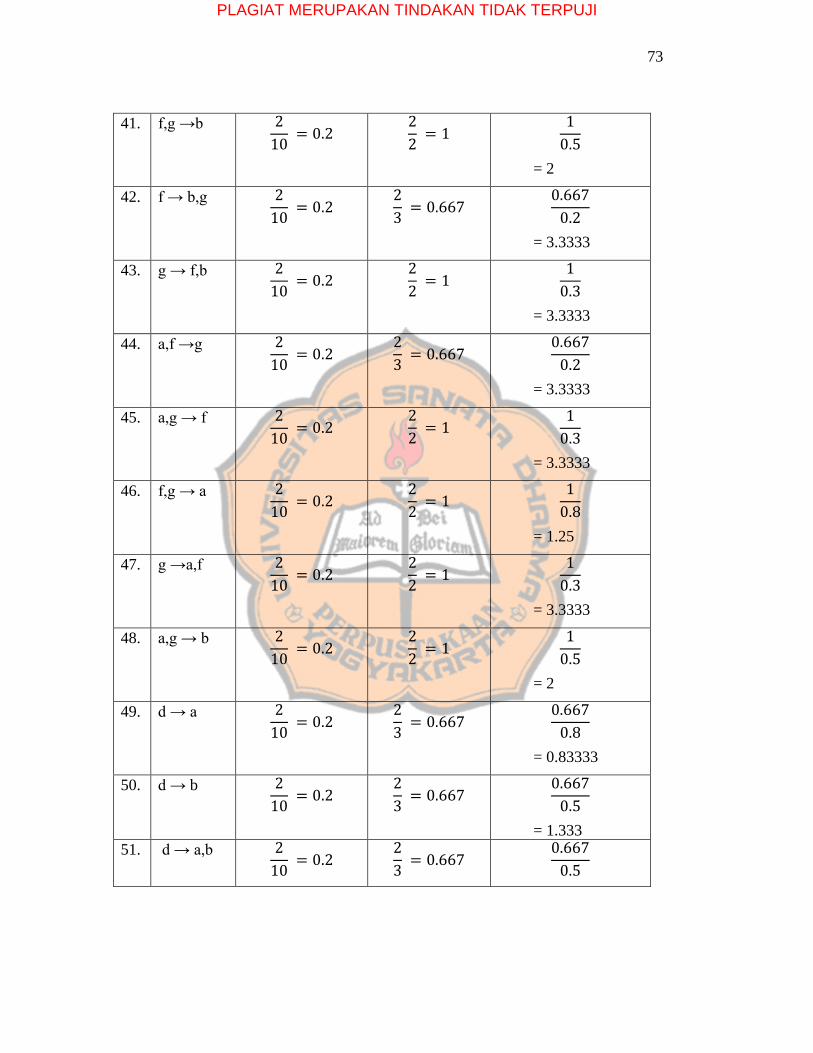
73
41. f,g →b 2
10 = 0.2
2
2 = 1
1
0.5
= 2
42. f → b,g 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.3333
43. g → f,b 2
10 = 0.2
2
2 = 1
1
0.3
= 3.3333
44. a,f →g 2
10 = 0.2
2
3 = 0.667
0.667
0.2
= 3.3333
45. a,g → f 2
10 = 0.2
2
2 = 1
1
0.3
= 3.3333
46. f,g → a 2
10 = 0.2
2
2 = 1
1
0.8
= 1.25
47. g →a,f 2
10 = 0.2
2
2 = 1
1
0.3
= 3.3333
48. a,g → b 2
10 = 0.2
2
2 = 1
1
0.5
= 2
49. d → a 2
10 = 0.2
2
3 = 0.667
0.667
0.8
= 0.83333
50. d → b 2
10 = 0.2
2
3 = 0.667
0.667
0.5
= 1.333
51. d → a,b 2
10 = 0.2
2
3 = 0.667
0.667
0.5
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
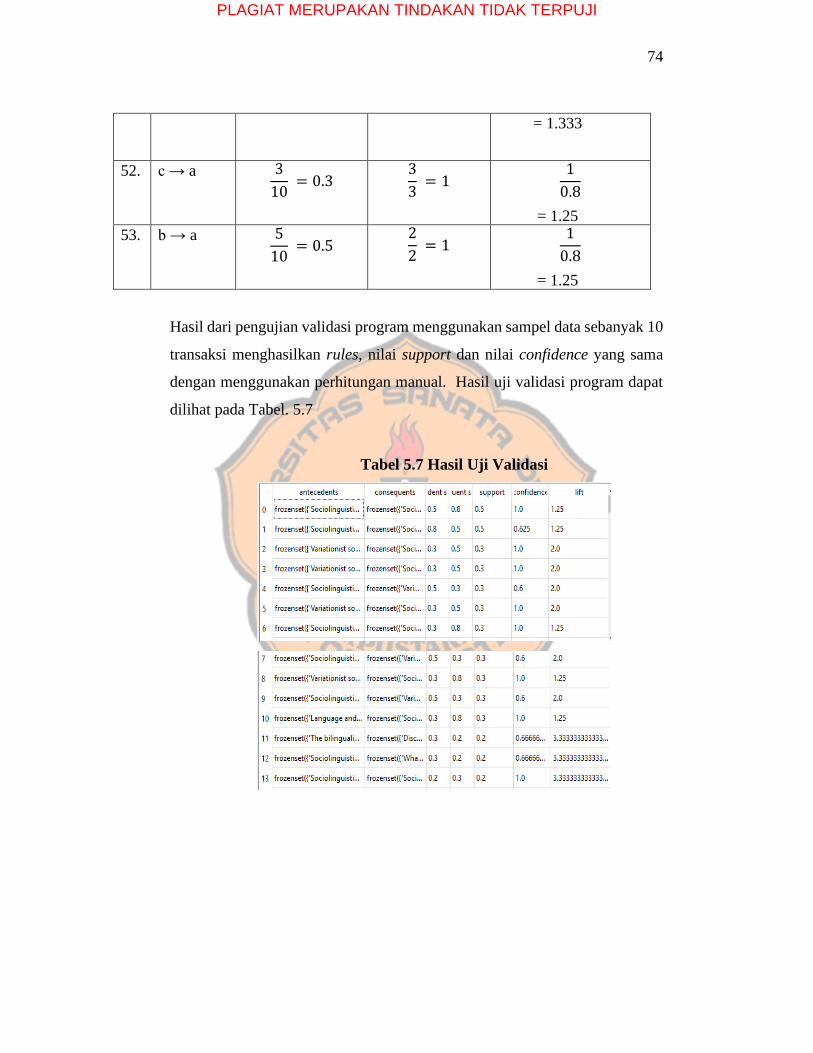
74
= 1.333
52. c → a 3
10 = 0.3
3
3 = 1
1
0.8
= 1.25
53. b → a 5
10 = 0.5
2
2 = 1
1
0.8
= 1.25
Hasil dari pengujian validasi program menggunakan sampel data sebanyak 10
transaksi menghasilkan rules, nilai support dan nilai confidence yang sama
dengan menggunakan perhitungan manual. Hasil uji validasi program dapat
dilihat pada Tabel. 5.7
Tabel 5.7 Hasil Uji Validasi
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

75
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
76
5.2.2 Uji Akurasi
Pengujian akurasi merupakan pengujian sistem
menggunakan dataset tiap bulan untuk melihat rule, nilai
support, nilai confidence, dan nilai lift ratio yang dihasilkan.
Uji akurasi pada penelitian ini dilakukan dengan menggunakan
data set tiap bulan untuk menghasilkan aturan asosiasi. Pada
penelitian ini dilakukan uji akurasi terhadap 78.779 data dan
33.917 transaksi yang dihasilkan pada bulan Januari sampai
dengan bulan Desember 2018.
Perbandingan hasil uji akurasi dari Januari tahun 2018
sampai dengan Desember 2018 dapat dilihat pada Tabel 5.8.
Tabel 5.8 Perbandingan Jumlah Aturan Asosiasi Tiap Bulan
dengan Variasi Nilai Minsup dan Mincof
Minsup Mincof Jumlah Aturan Asosiasi
Jan Feb Mar Apr Mei Jun Agt Sep Okt Des
0.1 % 50% 355 1 4 6 4 265 10 2 6 17
60% 310 0 1 5 4 256 8 2 4 16
70% 197 0 1 2 2 193 7 2 2 14
80% 191 0 1 2 1 193 6 2 2 7
90% 190 0 1 1 1 193 4 2 1 7
100% 190 0 1 1 1 193 4 2 1 7
0.2 % 50% 31 0 0 0 0 5 2 0 0 0
60% 19 0 0 0 0 5 1 0 0 0
70% 15 0 0 0 0 4 1 0 0 0
80% 9 0 0 0 0 4 0 0 0 0
90% 8 0 0 0 0 4 0 0 0 0
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
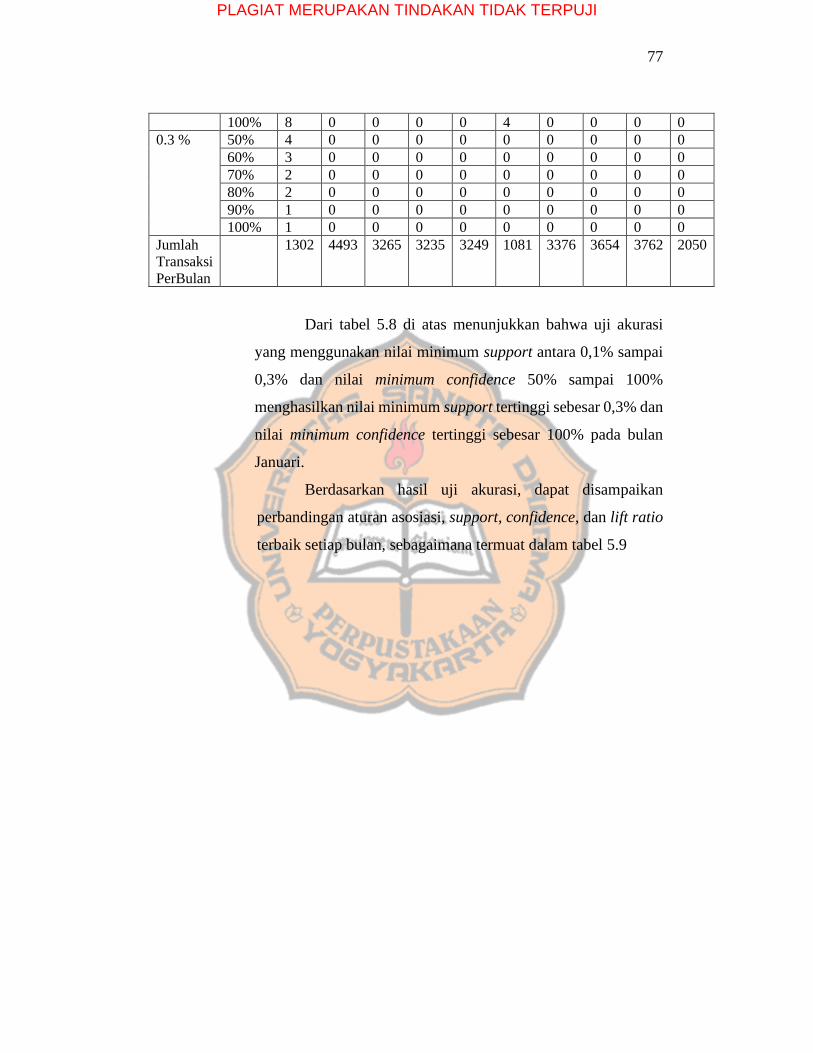
77
100% 8 0 0 0 0 4 0 0 0 0
0.3 % 50% 4 0 0 0 0 0 0 0 0 0
60% 3 0 0 0 0 0 0 0 0 0
70% 2 0 0 0 0 0 0 0 0 0
80% 2 0 0 0 0 0 0 0 0 0
90% 1 0 0 0 0 0 0 0 0 0
100% 1 0 0 0 0 0 0 0 0 0
Jumlah
Transaksi
PerBulan
1302 4493 3265 3235 3249 1081 3376 3654 3762 2050
Dari tabel 5.8 di atas menunjukkan bahwa uji akurasi
yang menggunakan nilai minimum support antara 0,1% sampai
0,3% dan nilai minimum confidence 50% sampai 100%
menghasilkan nilai minimum support tertinggi sebesar 0,3% dan
nilai minimum confidence tertinggi sebesar 100% pada bulan
Januari.
Berdasarkan hasil uji akurasi, dapat disampaikan
perbandingan aturan asosiasi, support, confidence, dan lift ratio
terbaik setiap bulan, sebagaimana termuat dalam tabel 5.9
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
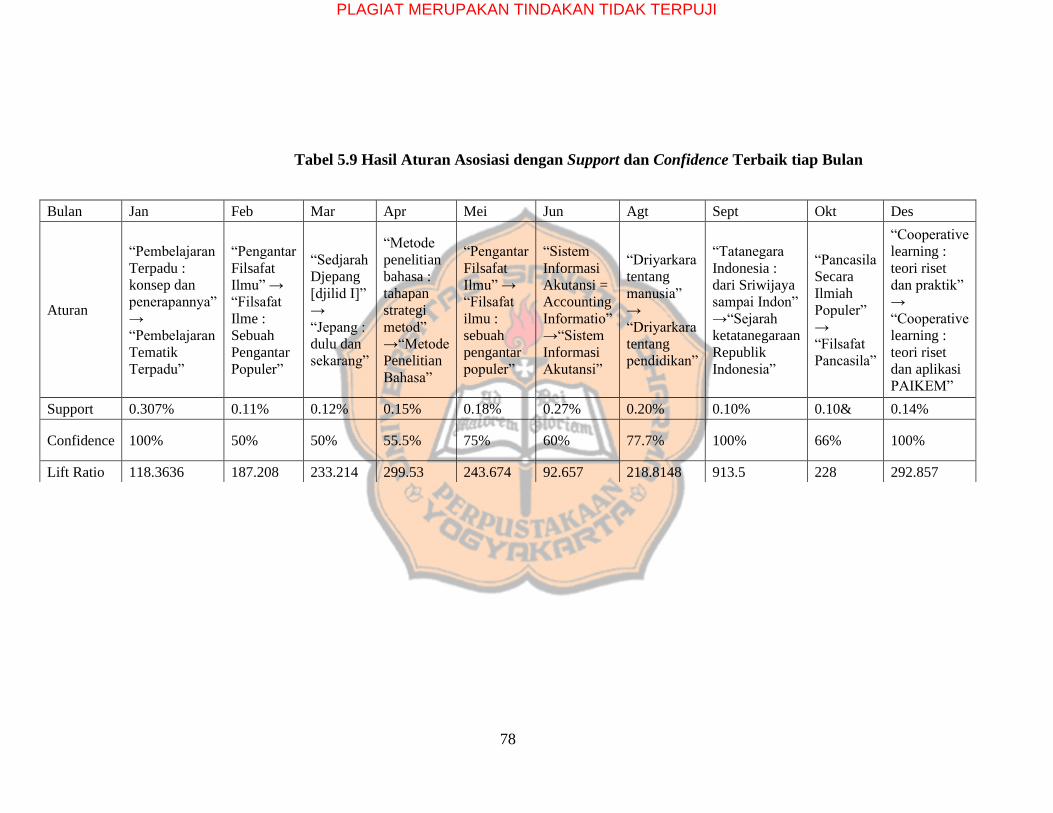
78
Tabel 5.9 Hasil Aturan Asosiasi dengan Support dan Confidence Terbaik tiap Bulan
Bulan Jan Feb Mar Apr Mei Jun Agt Sept Okt Des
Aturan
“Pembelajaran
Terpadu :
konsep dan
penerapannya”
→
“Pembelajaran
Tematik
Terpadu”
“Pengantar
Filsafat
Ilmu” →
“Filsafat
Ilme :
Sebuah
Pengantar
Populer”
“Sedjarah
Djepang
[djilid I]”
→
“Jepang :
dulu dan
sekarang”
“Metode
penelitian
bahasa :
tahapan
strategi
metod”
→“Metode
Penelitian
Bahasa”
“Pengantar
Filsafat
Ilmu” →
“Filsafat
ilmu :
sebuah
pengantar
populer”
“Sistem
Informasi
Akutansi =
Accounting
Informatio”
→“Sistem
Informasi
Akutansi”
“Driyarkara
tentang
manusia”
→
“Driyarkara
tentang
pendidikan”
“Tatanegara
Indonesia :
dari Sriwijaya
sampai Indon”
→“Sejarah
ketatanegaraan
Republik
Indonesia”
“Pancasila
Secara
Ilmiah
Populer”
→
“Filsafat
Pancasila”
“Cooperative
learning :
teori riset
dan praktik”
→
“Cooperative
learning :
teori riset
dan aplikasi
PAIKEM”
Support 0.307% 0.11% 0.12% 0.15% 0.18% 0.27% 0.20% 0.10% 0.10& 0.14%
Confidence 100% 50% 50% 55.5% 75% 60% 77.7% 100% 66% 100%
Lift Ratio 118.3636 187.208 233.214 299.53 243.674 92.657 218.8148 913.5 228 292.857
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

68
Berdasarkan tabel 5.9 di atas, maka hasil penelitian
menunjukkan bahwa pengujian pada bulan Juli dan November
tidak menemukan aturan asosiasi. Selain itu, buku dengan judul
: “Pembelajaran Terpadu: konsep dan penerapannya” →
“Pembelajaran tematik terpadu” mempunyai nilai support dan
confidence tertinggi, yaitu 0.307% dan 100% serta nilai lift ratio
sebesar 118.3636.
5.3 Analisis Hasil Pengujian
Berdasarkan hasil pengujian yang telah dilakukan di atas, maka telah
diperoleh hasil uji bahwa dengan menggunakan nilai minimum support
antara 0.1% sampai 0.3% dan nilai minimum confidence 50% sampai 100%
menghasilkan nilai minimum support tertinggi sebesar 0.3% dan nilai
minimum confidence tertinggi sebesar 100% pada bulan Januari. Selain itu
hasil penelitian menunjukkan bahwa buku dengan judul: “Pembelajaran
Terpadu: konsep dan penerapannya” → “Pembelajaran tematik terpadu”
mempunyai nilai support dan confidence tertinggi, yaitu 0.307% dan 100%
serta nilai lift ratio sebesar 118.3636.
Berkenaan dengan hasil pengujian aturan sosialisasi terbaik setiap bulan
yang memuat support, confidence dan lift ratio, dapat dimaknai bahwa
semakin besar support maka persentase rule tersebut terhadap keseluruhan
transaksi akan semakin besar. Apabila nilai confidence semakin besar, maka
antara antisendent dan consequent semakin sering dipinjam secara
bersamaan. Sedangkan apabila data menunjukkan semakin besar lift ratio,
maka aturan asosiasi tersebut akan semakin kuat sehingga memberikan
rekomendasi alternatif terhadap buku sejenis yang dibutuhkan.
Hasil pengujian di atas menunjukkan bahwa penelitian telah
menghasilkan aturan asosiasi sesuai tujuan penelitian yang dapat
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

69
dipergunakan bagi pengelola perpustakaan maupun pengguna perpustakaan
untuk diimplementasikan. Bagi pengelola perpustakaan, hasil pengujian
akan memberikan informasi bahwa buku yang mempunyai support,
confidence, dan lift ratio tertinggi:
1. Menjadi buku-buku yang perlu diperbanyak stok-nya, dan di stok secara
bersamaan sesuai dengan hasil aturan asosiasi karena sangat dibutuhkan
oleh pengguna;
2. Peletakannya pada rak buku perlu didekatkan karena buku-buku
tersebut dapat menjadi alternatif bagi para pengguna seandainya salah satu
buku telah kehabisan stok untuk dipinjamkan.
3. Menjadi saran rekomendasi peminjaman bagi pengguna seandainya
stok buku yang akan dipinjamkan telah habis.
Sedangkan bagi pengguna perpustakaan, maka buku yang mempunyai
support, confidence, dan lift ratio tertinggi akan memberikan informasi
mengenai alternatif buku yang dapat dipinjam apabila judul buku yang akan
dipinjam stok-nya telah habis.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

70
BAB VI
PENUTUP
6.1 Simpulan
Hasil penelitian sistem implementasi metode asosiasi pada data
peminjaman buku di perpustakaan Universitas Sanata Dharma
menggunakan algoritma FP-Growth menghasilkan kesimpulan sebagai
berikut:
1. Algoritma FP-Growth dapat diterapkan untuk menemukan
aturan asosiasi pada data transaksi peminjaman buku di
perpustakaan Universitas Sanata Dharma berdasarkan hasil
penelitian yang menyatakan bahwa nilai minimum support antara
0.1% sampai 0.3% dan nilai minimum confidence 50% sampai
100% menghasilkan nilai minimum support tertinggi sebesar 0.3%
dan nilai minimum confidence tertinggi sebesar 100% pada bulan
Januari, serta buku dengan judul : “Pembelajaran Terpadu:
konsep dan penerapannya” → “Pembelajaran tematik terpadu”
mempunyai nilai support dan confidence tertinggi, yaitu 0.307%
dan 100% serta nilai lift ratio sebesar 118.3636.
2. Nilai minimum support dan minimum confidence yang optimal
untuk mendapatkan aturan asosiasi yang kuat adalah sebesar 0.3%
dan 100%.
3. Aturan asosiasi pada buku “Pembelajaran Terpadu: konsep dan
penerapannya” → “Pembelajaran Tematik Terpadu” merupakan
aturan asosiasi yang kuat dengan nilai support sebesar 0.307% ,
nilai confidence sebesar 100% , dan nilai lift ratio sebesar
118.3636.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

71
6.2 Saran
Penelitian sistem implementasi metode asosiasi pada data peminjaman
buku di perpustakaan Universitas Sanata Dharma menggunakan algoritma
FP-Growth ini memberikan saran untuk pengembangan penelitian di masa
mendatang, yaitu:
1. Penelitian dengan menggunakan algoritma FP-Growth sistem dapat
dikembangkan lebih lanjut untuk memberikan rekomendasi buku
bagi jenjang umur tertentu, jenis kelamin tertentu, atau jenjang
pendidikan tertentu di Perpustakaan Universitas Sanata Dharma
dengan menambahkan data-data terkait usia, jenis kelamin, dan
tingkatan pendidikan dalam penelitian.
2. Untuk penelitian berikutnya dapat dikembangkan dengan
menggunakan algoritma yang dapat menangani data jarang (sparse)
sehingga dapat menemukan aturan yang lebih banyak.
3. Hasil penelitian algoritma FP-Growth sistem agar dapat
diimplementasikan pada Perpustakaan Universitas Sanata Dharma
untuk merekomendasikan:
a. Stok buku-buku sangat dibutuhkan oleh pengguna;
b. Peletakan buku-buku yang dapat menjadi alternatif
pinjaman pengguna dengan meletakkannya secara
berdekatan.
c. Memudahkan peminjam menentukan buku sesuai dengan
kebutuhannya.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

72
DAFTAR PUSTAKA
Batlayeri, Yohanes Adi Purnomo. 2019. Analisis Keranjang Belanja
Menggunakan Metode FP-Growth pada Toko Grosir Pancaran Bahagia.
Program Studi Teknik Informatika Fakultas Sains dan Teknologi
Universitas Sanata Dharma Yogyakarta.
Berry, M.J. & Linoff, G.S. 2004. Data mining Techniques for Marketing, Sales
and Customer Relationship Management. Second Edition. USA: Wiley
Publishing, Inc
Connolly, Thomas and Begg, Carolyn, 2010, Database Systems: A Practical
Approach to Design, Implementation, and Management, Fifth Edition.
Pearson Education, Boston.
Enykawati, E. S. E., 2015. Penerapan Data Mining pada Perusahaan Ritail
Pakaian untuk Memprediksi Ketersediaan Jenis Barang dengan
Menggunakan Algoritma FP-Growth. Program Studi Teknik Informatika
Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
Jiawei Han, Micheline Kamber, Jian Pei. 2012. Data Mining : Concepts and
Techniques 3rd Edition
Kadafi, Muhammad. 2018. Penerapan Algoritma FP - Growth Untuk
Menemukan Pola Peminjaman Buku di Perpustakaan UIN Raden Fatah
Palembang. Program Studi Sistem Informasi UIN Raden Fatah Palembang.
Kusrini dan Luthfi, R.T., 2009, Algoritma Data Mining, Yogyakarta, Andi
Offset
Larasita, D.P. Muhammad Nasrun. Umar Ali Ahmad. 2018. Analisis dan
Implementasi Algoritma FP-Growth pada Aplikasi SMART untuk
Menentukan Market Basket Analysis pada Usaha Retail (Studi Kasus :
PT.X) Vol. 2 (01):749-755
Mudyana dan Royani (dalam Sinaga 2005:16). .(http://pengertian-
pengertianinfo.blogspot.co.id/2015/05/pengertian-dan-fungsi-
perpustakaan.html). (Diakses 27 Oktober 2019)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

73
Prasetyo, Eko. 2012. Data mining Konsep dan Aplikasi Menggunakan Matlab.
Yogyakarta : Andi Yogyakarta.
Rachmat, Antonius dkk. 2014. Implementasi Algoritma FP-Growth untuk
Sitem Rekomendasi Buku di Perpustakaan UKDW. Vol. 10 No. 1.
Samuel, David 2008. Penerapan Struktur FP Tree dan Algoritma FP-Growth
dalam Optimasi Penentuan Frequent Itemset. Institut Teknologi Bandung
Suhendar, Yusuf. 2005. Pedoman Penyelenggaraan Perpustakaan Sekolah.
Jakarta: Prenada Media group
Tan, Pang Ning. 2005. Introduction to Data Mining 1st ed. Addison Wesley,
New York
Vercellis, Carlo. 2009. Business Intilligence : Data mining and optimization for
decision making. Chichester : John Willey & Son.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI