prihandoko, mit, phd universitas guandarma pengantar data
TRANSCRIPT

Pengantar Data Mining
Prihandoko, MIT, PhDUniversitas Guandarma

Latar Belakang
• Setiap detik TB data dihasilkan oleh perangkat dan aplikasi berikut ini:• Perangkat mobile • Camera digital• Dokumen web (250 juta webpage)• Status facebook (lebih 1 milyar pengguna)• Tweets (300 juta pengguna)• Transaksi digital (Walmart 20jt transaksi/hari)• Sensor (IoT)• Query, browsing (1,5 milyar pengguna google)
• Harga penyimpanan digital (digital storage) semakin murah

https://www.allaccess.com/merge/archive/31294/infographic-what-happens-in-an-internet-minute

Data Riwayat Perilaku
Pengguna
• Ponsel saat ini merekam banyak informasi tentang perilaku pengguna• GPS merekam posisi• Kamera menghasilkan gambar• Komunikasi melalui telepon dan SMS• Teks melalui pembaruan status
facebook• Amazon mengumpulkan semua barang
yang anda jelajahi, barang yang ditempatkan di keranjang Anda, membaca ulasan dari pembeli, dst.

Data Riwayat Perilaku
Pengguna
• Google dan Bing merekam semua aktivitas penelusuran anda melalui aplikasi. Mereka juga merekam pertanyaan yang anda tanyakan, halaman yang anda lihat, dan klik yang anda lakukan.• Data dikumpulkan untuk jutaan
pengguna setiap hari

Kompleksitas & Konektifitas Data
• Data yang dihasilkan beragam dan kompleks (teks, gambar, suara, video)• Dari perangkat mobile diperoleh beragam
data yang saling terkoneksi: lokasi perangkat, informasi kontak, tempat cek-in, opini twitter, status facebook, query di google

Apa yang dimaksud Data ?Tid Refund Marital
Status Taxable Income Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes 10
Field/Atribut/Kolom à 5 field
Baris/Record/Objek à 10 baris
Data = kumpulan dari objek yang memiliki atributSize/ukuran tabel = jumlah objek/barisDimensi = jumlah atribut

Data DokumenSetiap dokumen menjadi vector. Term adalah gabungan dari vector. Setiap term adalah komponen dari atribut. Nilai setiap komponen adalah berapa kali istilah yang sesuai terjadi dalam dokumen.Representasi bag-of-words - tanpa urutan.
Document 1
season
timeout
lost
win
game
score
ball
play
coach
team
Document 2
Document 3
3 0 5 0 2 6 0 2 0 2
0
0
7 0 2 1 0 0 3 0 0
1 0 0 1 2 2 0 3 0

Data Transaksi
• Setiap transaksi berisi sejumlah item (set of item)• Sekumpulan item dapat
direpresentasikan sebagai binary vector• Sebuah dokumen juga dapat
direpresentasikan dengan sekumpulan kata (set of words).
ID Nama
1 Roti, Kopi, Susu
2 Coklat, Roti
3 Coklat, Kopi, Gula, Susu
4 Coklat, Roti, Gula, Susu
5 Kopi, Gula, Susu

Tipe Data
• Data numerik: Setiap objek adalah titik dalam ruang multidimensi• Data kategori: Setiap objek adalah
vektor dari nilai kategori• Set data: Setiap objek adalah
seperangkat nilai (dengan atau tanpa jumlah). • Objek berurutan: Setiap objek adalah
urutan nilai yang diurutkan.• Data Grafik

Urgensi Data
• Jika anda adalah pemilik sebuah supermarket dan anda telah mengumpulkan jutaan data transaksi, maka informasi apa yang akan Anda ekstrak darinya dan bagaimana Anda menggunakannya?• Penempatan produk di rak• Menentukan jumlah stok
inventori• Mengetahui perilaku pembeli
ID Nama
1 Roti, Kopi, Susu
2 Coklat, Roti
3 Coklat, Kopi, Gula, Susu
4 Coklat, Roti, Gula, Susu
5 Kopi, Gula, Susu

Mengapa Data Mining?
Aspek bisnis/komersialData telah menjadi keunggulan kompetitif utama perusahaan saat iniContoh: Facebook, Google, AmazonMampu mengekstraksi informasi bermanfaat dari data adalah kunci untuk mengeksploitasinya secara komersial.
Aspek ilmiahPara ilmuwan berada pada posisi yang belum pernah terjadi sebelumnya di mana mereka dapat mengumpulkan informasi sebesar terabytes (TB)Contoh: Data sensor, data astronomi, data jaringan sosial, data genIlmuwan membutuhkan alat untuk menganalisis data tersebut untuk mendapatkan pemahaman yang lebih baik tentang fenomena di dunia ini dan untuk mengembangkan ilmu pengetahuan
Mengapa Data Mining?
• "The success of companies like Google, Facebook, Amazon, and Netflix, not to mention Wall Street firms and industries from manufacturing and retail to healthcare, is increasingly driven by better tools for extracting meaning from very large quantities of data. 'Data Scientist' is now the hottest job title in Silicon Valley." – Tim O'Reilly

Definisi Data Mining
• "Data mining adalah analisis dari sekumpulan data pengamatan (dalam jumlah besar) untuk menemukan hubunganyang tidak terduga dan untuk meringkas data dalam cara-cara baru yang dapat dimengerti dan berguna bagi analis data" (Hand, Mannila, Smyth)
• "Data mining adalah penemuan model untuk data" (Rajaraman, Ullman)• Model yang menjelaskan
data (mis., satu fungsi)• Model yang memprediksi
data masa depan.• Model yang meringkas data• Model mengekstrak fitur
yang paling menonjol dari data.

Metode Data Mining
1. Frequent item sets and Association Rules extraction
2. Clustering3. Classification4. Ranking 5. Exploratory analysis
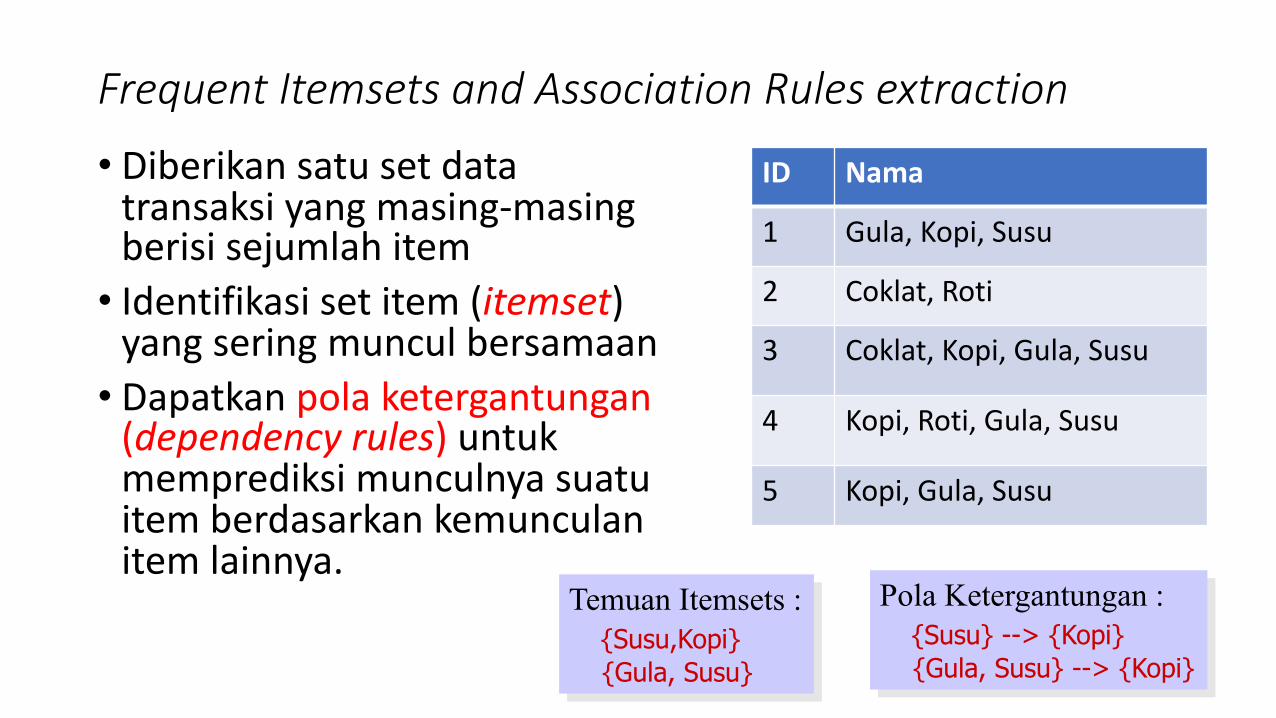
Frequent Itemsets and Association Rules extraction
• Diberikan satu set data transaksi yang masing-masing berisi sejumlah item• Identifikasi set item (itemset)
yang sering muncul bersamaan• Dapatkan pola ketergantungan
(dependency rules) untuk memprediksi munculnya suatu item berdasarkan kemunculan item lainnya.
ID Nama
1 Gula, Kopi, Susu
2 Coklat, Roti
3 Coklat, Kopi, Gula, Susu
4 Kopi, Roti, Gula, Susu
5 Kopi, Gula, Susu
Temuan Itemsets :{Susu,Kopi}{Gula, Susu}
Pola Ketergantungan :{Susu} --> {Kopi}{Gula, Susu} --> {Kopi}

Penerapan Frequent Itemsets and Association Rules
• Text Mining: menemukan frasa yang saling terkait dalam teks• Berapa banyak dokumen yang mengandung
frasa ”classification", " data mining" dan "algoritma"
• Recommendation System:• Pengguna yang membeli barang ini sering
membeli barang ini juga• Pengguna yang menonton film IP Man, juga
menonton film Kung Fu Panda.

Clustering
Jika diberikan sekumpulan titik data, masing-masing memiliki sejumlah atribut, dan kesamaan ukuran (similarity measure) di antara mereka, maka kita dapat menemukan cluster sehingga:• Titik data dalam satu cluster
memiliki similaritas tinggi satu dengan lain.• Titik data dalam kelompok cluster
berbeda memiliki similaritas yang rendah
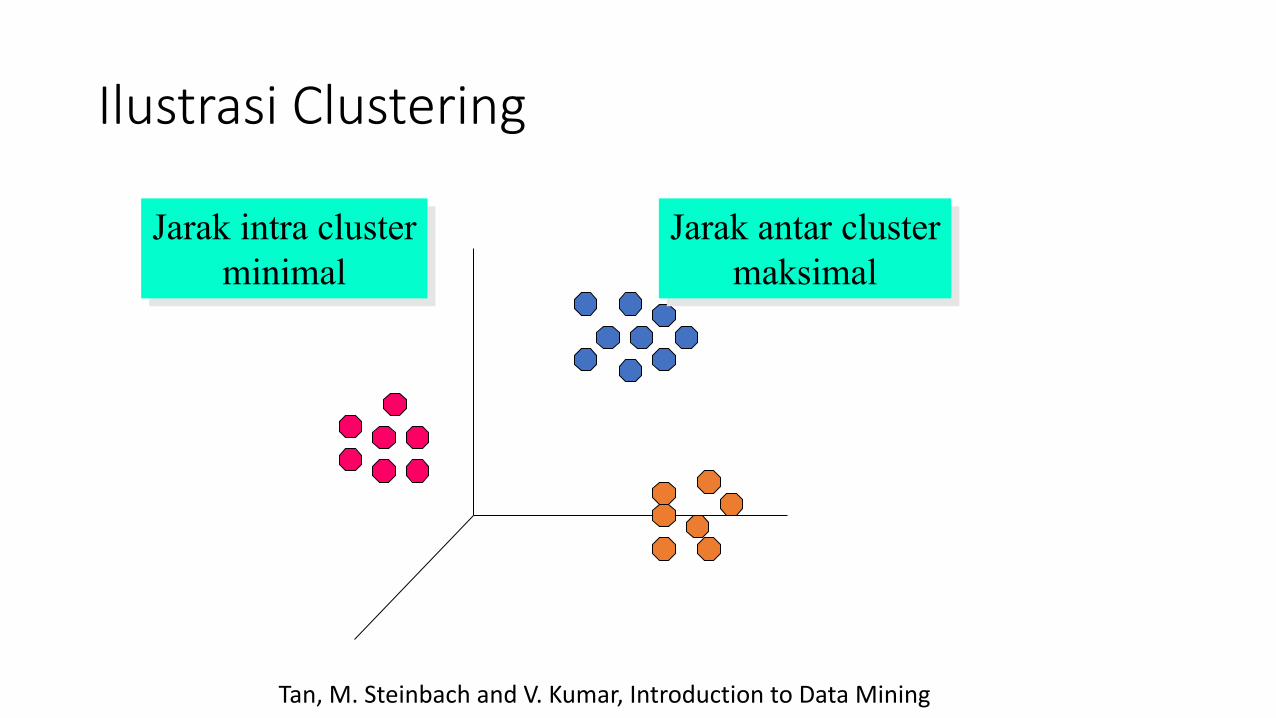
Ilustrasi Clustering
Jarak intra clusterminimal
Jarak antar clustermaksimal
Tan, M. Steinbach and V. Kumar, Introduction to Data Mining

Classification
• Jika terdapat sekumpulan data/record (data training)• Setiap record berisi sekumpulan atribut,
salah satu atributnya adalah kelas.• Temukan model untuk atribut kelas sebagai
fungsi dari nilai atribut lainnya.• Selain data training, kita perlu data tes yang
akan digunakan untuk menentukan keakuratan model. • Set data yang diberikan dibagi menjadi data
training dan data tes, dengan data training yang digunakan untuk membangun model dan data tes yang digunakan untuk memvalidasinya.
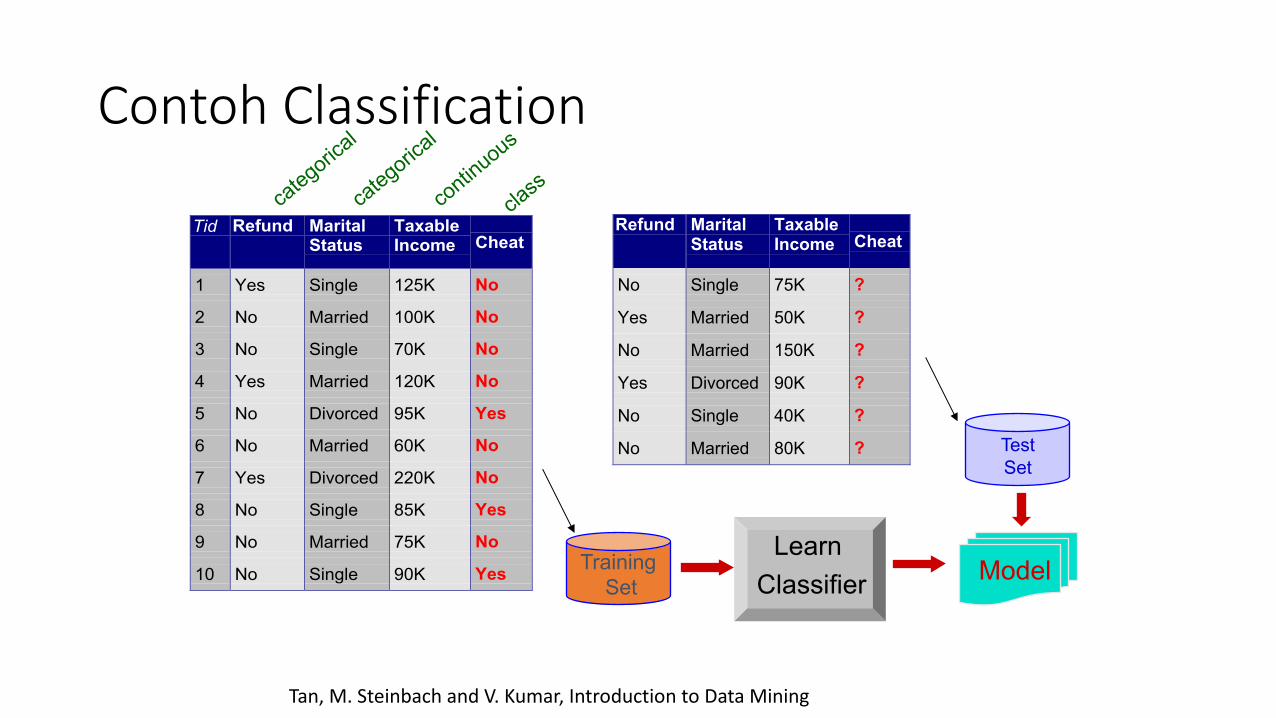
Contoh Classification
Tid Refund MaritalStatus
TaxableIncome Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes10
categorical
categorical
continuous
class
Refund MaritalStatus
TaxableIncome Cheat
No Single 75K ?
Yes Married 50K ?
No Married 150K ?
Yes Divorced 90K ?
No Single 40K ?
No Married 80K ?10
TestSet
Training Set
ModelLearn
Classifier
Tan, M. Steinbach and V. Kumar, Introduction to Data Mining

Penerapan Classification (1)
• Prediksi Klik Iklan• Sasaran: Memprediksi jika pengguna yang mengunjungi
halaman web akan mengklik iklan yang ditampilkan. Gunakan untuk menargetkan pengguna dengan probabilitas klik tinggi.
• Pendekatan:• Kumpulkan data untuk pengguna selama periode waktu
tertentu dan rekam siapa yang mengklik dan siapa yang tidak. Informasi {klik, tanpa klik} membentuk atribut kelas.• Gunakan riwayat pengguna (halaman web yang
diramban, query yang dikeluarkan) sebagai fitur.• Pelajari model classifier dan uji pada pengguna baru.

Penerapan Classification (2)
• Mendeteksi Penipuan• Sasaran: Memprediksi kasus penipuan dalam transaksi
kartu kredit.• Pendekatan:• Gunakan transaksi kartu kredit dan informasi pada
pemegang akunnya sebagai atribut.• Kapan seorang pelanggan membeli, apa yang dia beli,
seberapa sering dia membayar tepat waktu, dll• Beri label transaksi masa lalu sebagai penipuan atau
transaksi wajar. Ini membentuk atribut kelas.• Pelajari model untuk kelas transaksi.• Gunakan model ini untuk mendeteksi penipuan dengan
mengamati transaksi kartu kredit di akun.

Network Data Analysis for Ranking
• Link Analysis Ranking : Jika terdapat sekumpulan halaman web yang saling terhubung satu sama lain, peringkathalaman (pages) akan ditentukan berdasarkan otoritas(authoritativeness) dalam grafik• Sebuah halaman mendapatkan otoritas
jika dirujuk oleh halaman lain.

Analisis Eksploratori (Exploratory Analysis)
• Memahami data sebagai fenomena fisik, dan menggambarkannya dengan metrik sederhana, misalnya:• Seberapa sering orang mengulangi query yang sama?• Apakah teman di facebook juga teman di twitter?
• Tantangannya adalah bagaimana menemukan metrik yang tepat dan mengajukan pertanyaan yang tepat• Analisis ini akan membantu pemahaman kita tentang dunia, dan
dapat digunakan untuk membangun model atas fenomena yang kita amati.
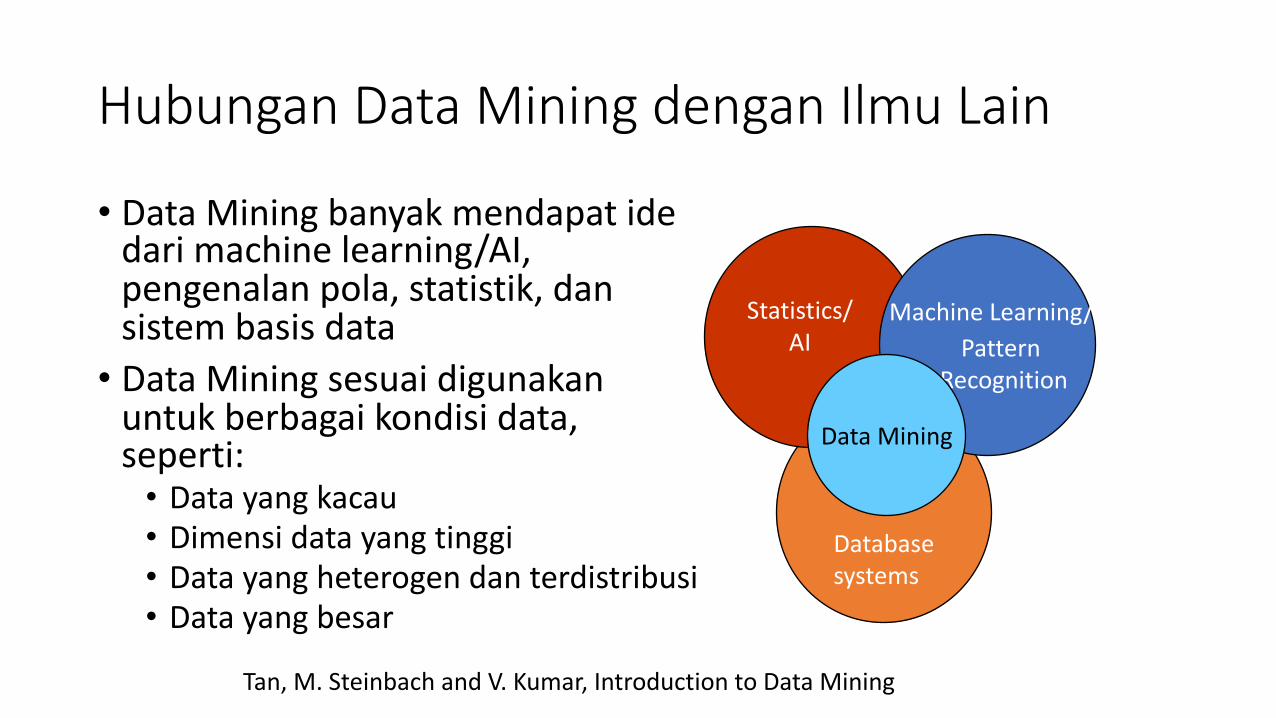
Hubungan Data Mining dengan Ilmu Lain
• Data Mining banyak mendapat ide dari machine learning/AI, pengenalan pola, statistik, dan sistem basis data• Data Mining sesuai digunakan
untuk berbagai kondisi data, seperti:• Data yang kacau• Dimensi data yang tinggi• Data yang heterogen dan terdistribusi• Data yang besar
Machine Learning/Pattern
Recognition
Statistics/AI
Data Mining
Database systems
Tan, M. Steinbach and V. Kumar, Introduction to Data Mining
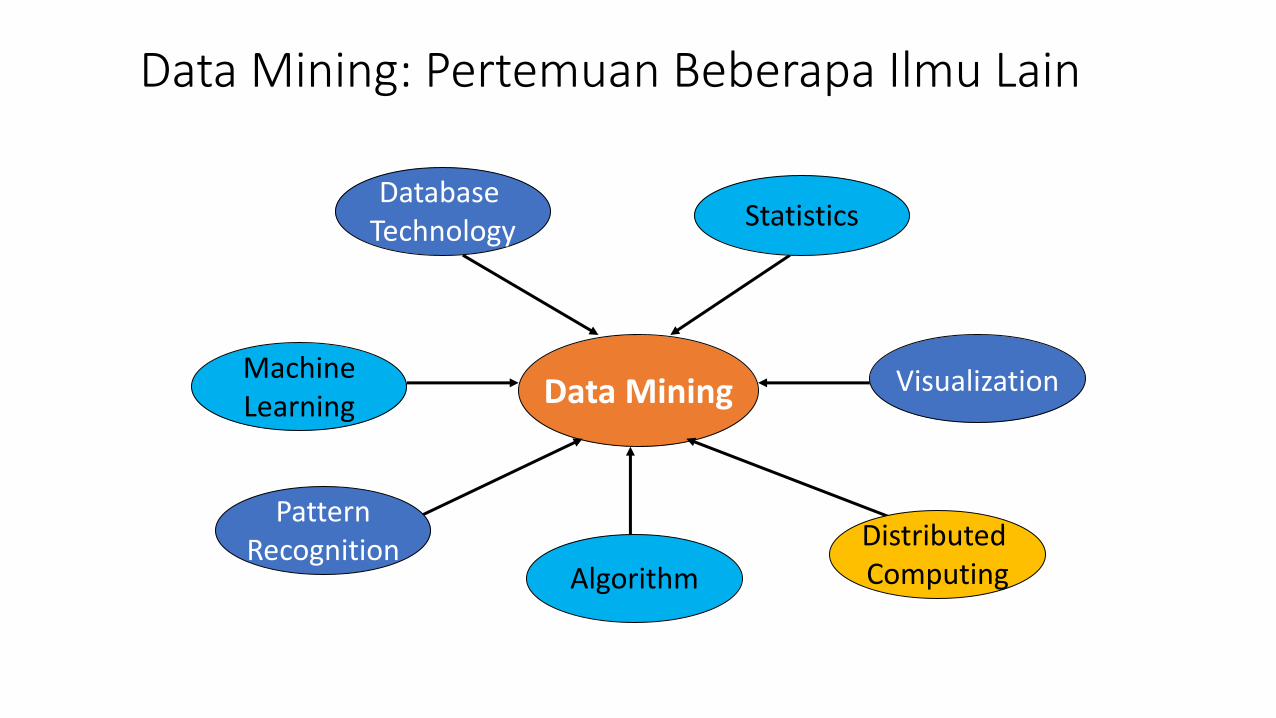
Data Mining: Pertemuan Beberapa Ilmu Lain
Data Mining
Database Technology Statistics
MachineLearning
PatternRecognition
AlgorithmDistributed Computing
Visualization

Resume
• "Data mining adalah analisis dari sekumpulan data pengamatan (dalam jumlah besar) untuk menemukan hubungan yang tidak terduga dan untuk meringkas data dalam cara-cara baru yang dapat dimengerti dan berguna bagi analis data" (Hand, Mannila, Smyth)
Teknik Data Mining:• Frequent item sets and
Association Rules extraction• Clustering• Classification• Ranking • Exploratory analysis

Daftar Pustaka
• “Data Mining: Concepts and Techniques”, by Jiawei Han and Micheline Kamber.• “Introduction to Data Mining” by Tan, Steinbach, Kumar.• http://www.cs.uoi.gr/~tsap/teaching/2013-cs059/index-en.html