bab iv bandel - rayvel.files.wordpress.com · data perhitungan manual untuk membuat tabel harus...
TRANSCRIPT
IV-1
BAB IV
PEMBAHASAN DAN ANALISIS
4.1. Studi Kasus Modul Distribusi Frekuensi
Perusahaan tempat tidur sedang melakukan penelitian terhadap
beberapa orang yang sedang memilih tempat tidur. Statistik penilaian tinggi
badan seseorang yang diukur. Jumlah data terhadap pria dan wanita dengan
kriteria tinggi sampai pendek maka dapatlah data-data yang dapat diolah
untuk membuat sebuah tempat tidur yang berkualitas sehingga dapat
menyenangkan pemiliknya. Data yang telah terkumpul terdapat yaitu 30
buah data tinggi badan dengan tabel sebagai berikut: Tabel 4.1. Data Simulasi Distribusi Frekuensi
No Gender Tinggi Badan (cm) No Gender Tinggi Badan (cm)
1 Wanita 155 16 Pria 185
2 Pria 173 17 Pria 175
3 Pria 179 18 Pria 163
4 Wanita 151 19 Pria 180
5 Wanita 156 20 Wanita 171
6 Pria 177 21 Wanita 170
7 Pria 183 22 Pria 169
8 Wanita 176 23 Wanita 174
9 Pria 189 24 Wanita 169
10 Wanita 167 25 Wanita 173
IV-2
Tabel 4.1. Data Simulasi Distribusi Frekuensi (Lanjutan)
No Gender Tinggi Badan (cm) No Gender Tinggi Badan (cm)
11 Wanita 172 26 Wanita 166
12 Pria 170 27 Wanita 170
13 Wanita 162 28 Pria 185
14 Pria 179 29 Pria 179
15 Pria 182 30 Pria 183
Data telah diperoleh dan agar mempermudah pengusaha tempat tidur
tersebut sehingga seorang peneliti membuat beberapa kriteria, yaitu:
a. Buatlah tabel perhitungan untuk data di atas ?
b. Buatlah grafik dari data diatas dengan grafik statistika ?
4.1.1 Perhitungan Manual Modul Distribusi Frekuensi
Berdasarkan data yang telah diobservasi dan dicantumkan dalam
tabel, maka di bawah ini adalah hasil dari pengolahan data dengan
menggunakan perhitungan manual.
a. Tabel Perhitungan
Data perhitungan manual untuk membuat tabel harus mengikuti
procedure pengolahan data dengan urutannya adalah urutan data,
jangkauan, banyaknya kelas, dan panjang interval kelas. Urutan data adalah
mengurutkan data dari yang terkecil sampai yang terbesar. Hasilnya adalah
sebagai berikut:
151 155 156 162 163 166 167 169 169 170
170 170 171 172 173 173 174 175 176 177
179 179 179 180 182 183 183 185 185 189

IV-3
Jangkauan adalah nilai data terbesar dikurangkan dengan data terkecil,
jangkauan sering juga disebut range. Hasilnya adalah sebagai berikut:
Range = data terbesar – data terkecil
= 198 - 151
= 38
Banyaknya kelas adalah jumlah banyaknya kelas yang ada dalam tabel
data. Hasilnya adalah sebagai berikut:
K = 1 + 3,3 log n
K = 1 + 3,3 log 30
K = 1 + (3,3 . 1,477)
K = 1 + 4,875
K = 5,875 dibulatkan 6
Panjang interval kelas adalah Merupakan jarak dari sebuah kelas yang
terletak antara tepi atas kelas dan tepi bawah kelas. Hasilnya adalah sebagai
berikut:
638
I
KRangeI
I = 6,3333 dibulatkan 7 Tabel 4.2. Hasil Perhitungan Manual Distribusi Frekuensi
No Interval Kelas Turus Frekuensi Tepi Interval
Kelas
Titik
Tengah
1 151 – 157 III 3 150,5 – 157,5 154
2 158 – 164 II 2 157,5 – 164,5 161
3 165 – 172 IIIII IIII 9 164,5 – 172,5 168
4 173 – 179 IIIII IIII 9 172,5 – 179,5 176

IV-4
Tabel 4.2. Hasil Perhitungan Manual Distribusi Frekuensi (Lanjutan)
No Interval Kelas Turus Frekuensi Tepi Interval
Kelas
Titik
Tengah
5 180 – 186 IIIII I 6 179,5 – 186,5 183
6 187 – 193 I 1 186,5 – 193,5 190
Jml 30
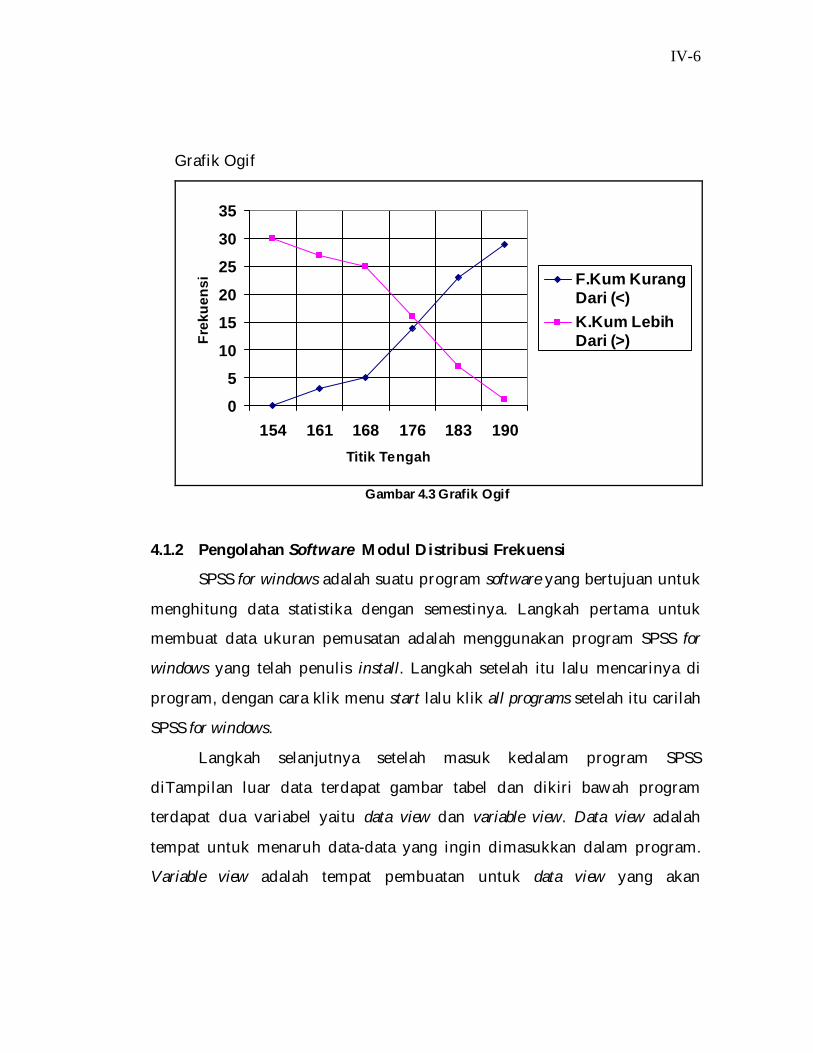
Tabel 4.3. Hasil Perhitungan Manual Kumulatif Distribusi Frekuensi
Frekuensi Kumulatif Kurang Dari Frekuensi Kumulatif Lebih Dari
0 30
3 27
5 25
14 16
23 7
29 1
30 0
b. Grafik Perhitungan
Grafik yang berupa gambar pada umumnya lebih mudah diambil
kesimpulannya secara cepat dari pada tabel, itulah sebabnya maka sering kali
data disajikan dalam bentuk grafik. Grafik statistik memiliki berbagai macam
bentuk tetapi yang dipakai biasanya hanya tiga yaitu histogram, poligon, dan
ogif.

IV-5
Grafik Histogram
0
2
4
6
8
10
150,5 157,5 164,5 172,5 179,5 186,5
Tepi Interval Kelas
Frek
uens
i
Gambar 4.1 Grafik Histogram
Grafik Poligon
0
2
4
6
8
10
154 161 168 176 183 190
Titik Tengah
Frek
uens
i
Gambar 4.2 Grafik Poligon
IV-6
Grafik Ogif
0
5
10
15
20
25
30
35
154 161 168 176 183 190Titik Tengah
Frek
uens
i F.Kum KurangDari (<)K.Kum LebihDari (>)
Gambar 4.3 Grafik Ogif
4.1.2 Pengolahan Software Modul Distribusi Frekuensi
SPSS for windows adalah suatu program software yang bertujuan untuk
menghitung data statistika dengan semestinya. Langkah pertama untuk
membuat data ukuran pemusatan adalah menggunakan program SPSS for
windows yang telah penulis install. Langkah setelah itu lalu mencarinya di
program, dengan cara klik menu start lalu klik all programs setelah itu carilah
SPSS for windows.
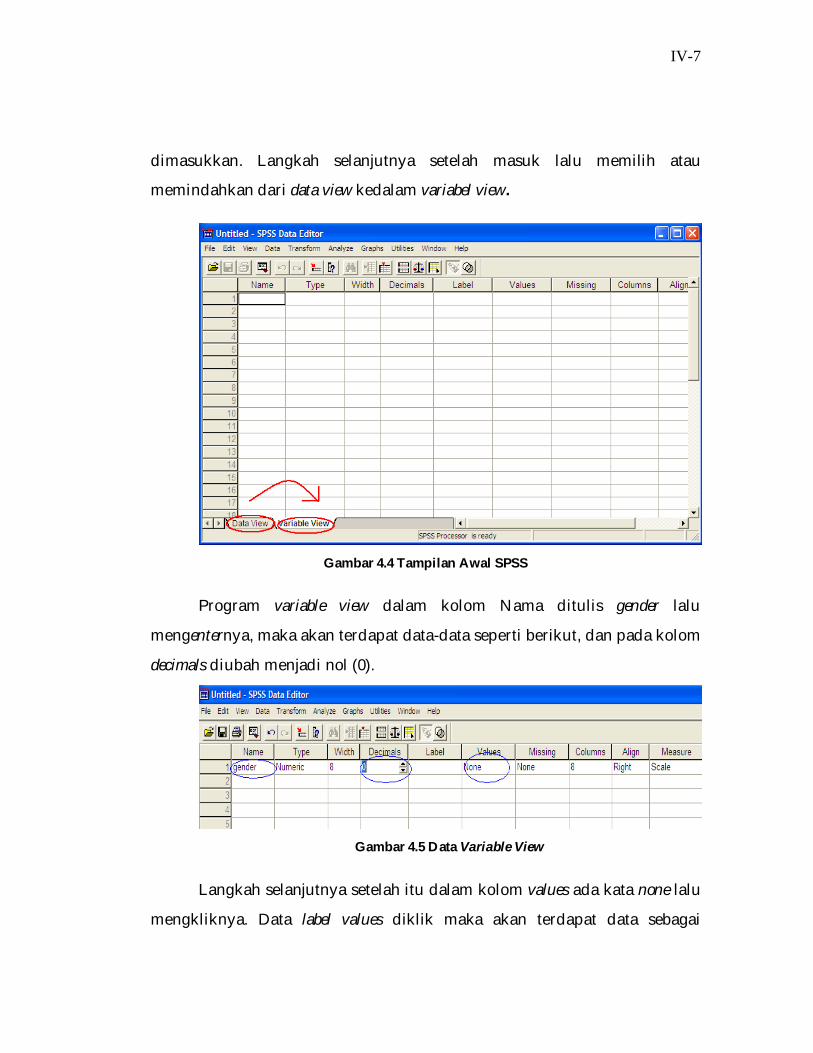
Langkah selanjutnya setelah masuk kedalam program SPSS
diTampilan luar data terdapat gambar tabel dan dikiri bawah program
terdapat dua variabel yaitu data view dan variable view. Data view adalah
tempat untuk menaruh data-data yang ingin dimasukkan dalam program.
Variable view adalah tempat pembuatan untuk data view yang akan
IV-7
dimasukkan. Langkah selanjutnya setelah masuk lalu memilih atau
memindahkan dari data view kedalam variabel view.
Gambar 4.4 Tampilan Awal SPSS
Program variable view dalam kolom Nama ditulis gender lalu
mengenternya, maka akan terdapat data-data seperti berikut, dan pada kolom
decimals diubah menjadi nol (0).
Gambar 4.5 Data Variable View
Langkah selanjutnya setelah itu dalam kolom values ada kata none lalu
mengkliknya. Data label values diklik maka akan terdapat data sebagai

IV-8
berikut, dalam kolom value ditulis angka 1 dan 2, lalu dalam kolom value label
ditulis pria dan wanita, setelah selesai lalu add lalu klik OK.
Gambar 4.6 Kolom Value Label
Berikutnya setelah data tertulis maka dalam kolom values akan
berubah dari none, setelah itu di baris 2 dikolom nama ditulis t.badan lalu
mengenternya setelah itu pada kolom decimals diubah menjadi 0.
Gambar 4.7 Data Variable View
Langkah selanjutnya setelah program data telah tersusun dengan
sesuai lalu kembalikan lagi dari variable view menuju data view.
Langkah selanjutnya dalam data diew maka akan berubah variablenya
dalam kolom pertama tertulis gender dan dalam kolom kedua tertulis t.badan,
setelah data tertera maka dalam kolom gender ditulis pria dan wanita dengan
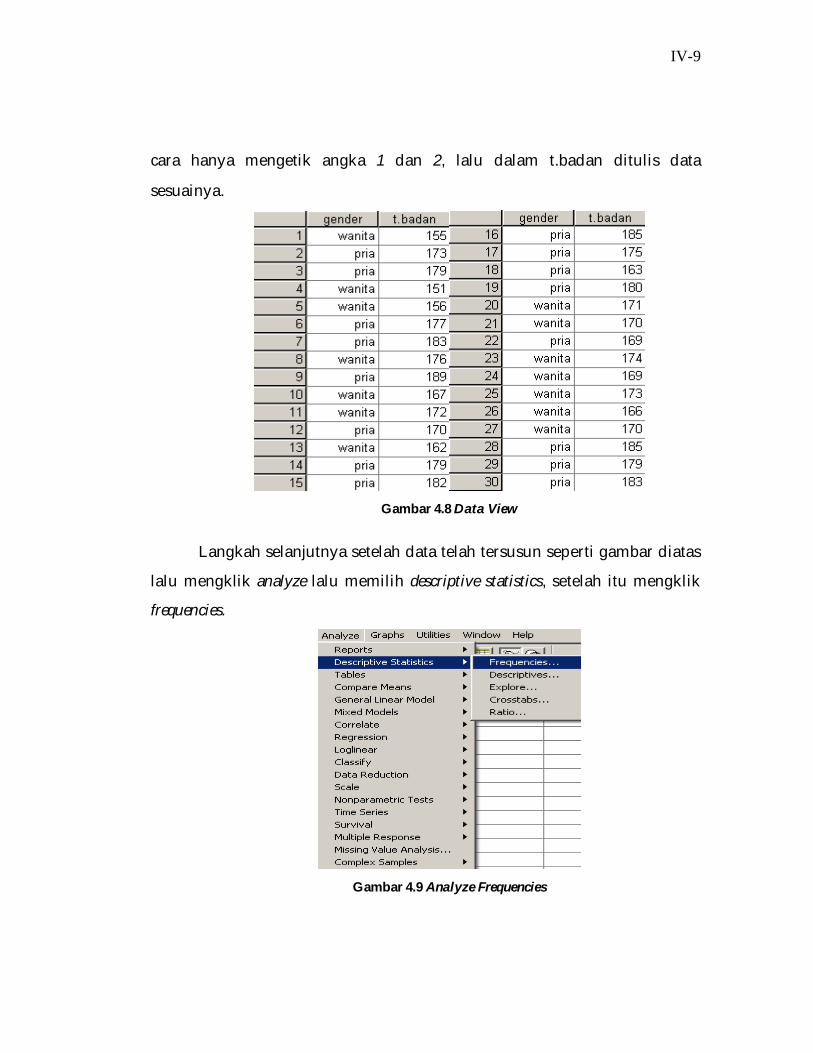
IV-9
cara hanya mengetik angka 1 dan 2, lalu dalam t.badan ditulis data
sesuainya.
Gambar 4.8 Data View
Langkah selanjutnya setelah data telah tersusun seperti gambar diatas
lalu mengklik analyze lalu memilih descriptive statistics, setelah itu mengklik
frequencies.
Gambar 4.9 Analyze Frequencies

IV-10
Langkah selanjutnya setelah mengeklik maka akan terdapat tabel
seperti gambar berikut, dalam kolom itu lalu pindahkan t.badan menuju
variable(s) dengan memindahnya, lalu setelah itu mengklik tombol statistics
dan tombol charts.
Gambar 4.10 Kolom Frequencies
Langkah selanjutnya setelah dalam tabel frequencies setelah mengeklik
tombol statistics maka akan terdapat tabel seperti dibawah ini dalam tabel
tersebut pada kanan bawah pada kolom distribution ada data yaitu skewness
dan kurtosis keduanya lalu diklik, setelah itu lalu mengklik continue.
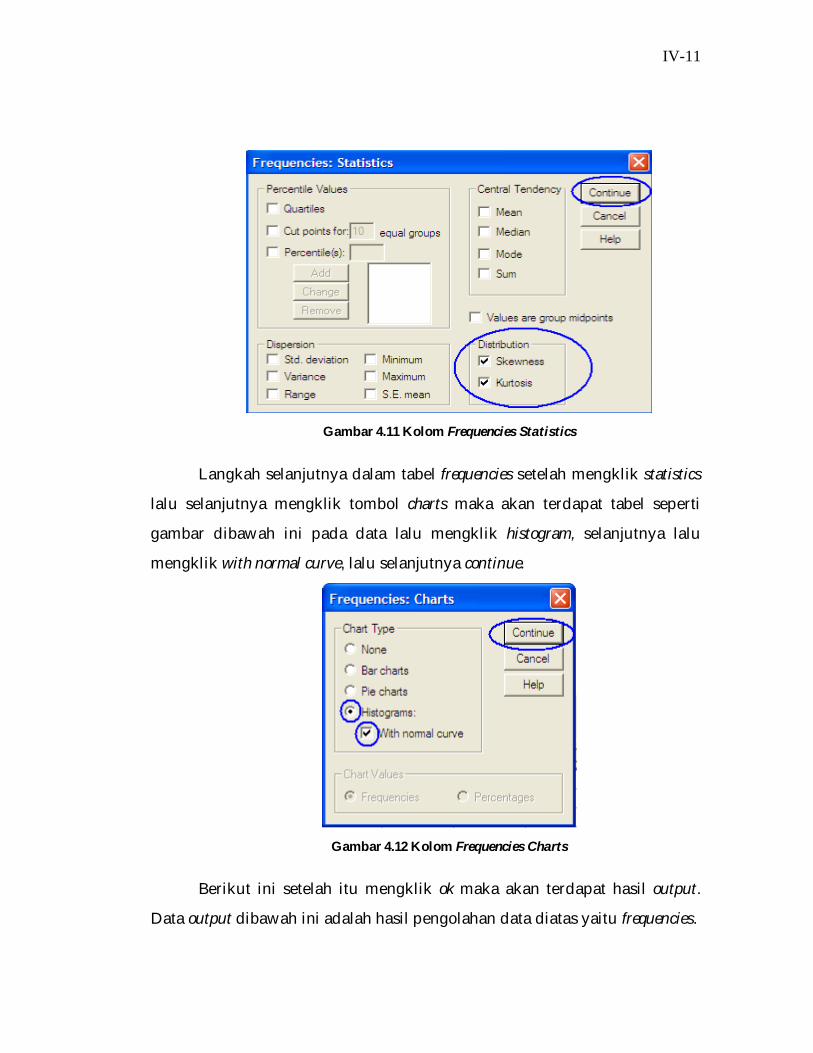
IV-11
Gambar 4.11 Kolom Frequencies Statistics
Langkah selanjutnya dalam tabel frequencies setelah mengklik statistics
lalu selanjutnya mengklik tombol charts maka akan terdapat tabel seperti
gambar dibawah ini pada data lalu mengklik histogram, selanjutnya lalu
mengklik with normal curve, lalu selanjutnya continue.
Gambar 4.12 Kolom Frequencies Charts
Berikut ini setelah itu mengklik ok maka akan terdapat hasil output.
Data output dibawah ini adalah hasil pengolahan data diatas yaitu frequencies.
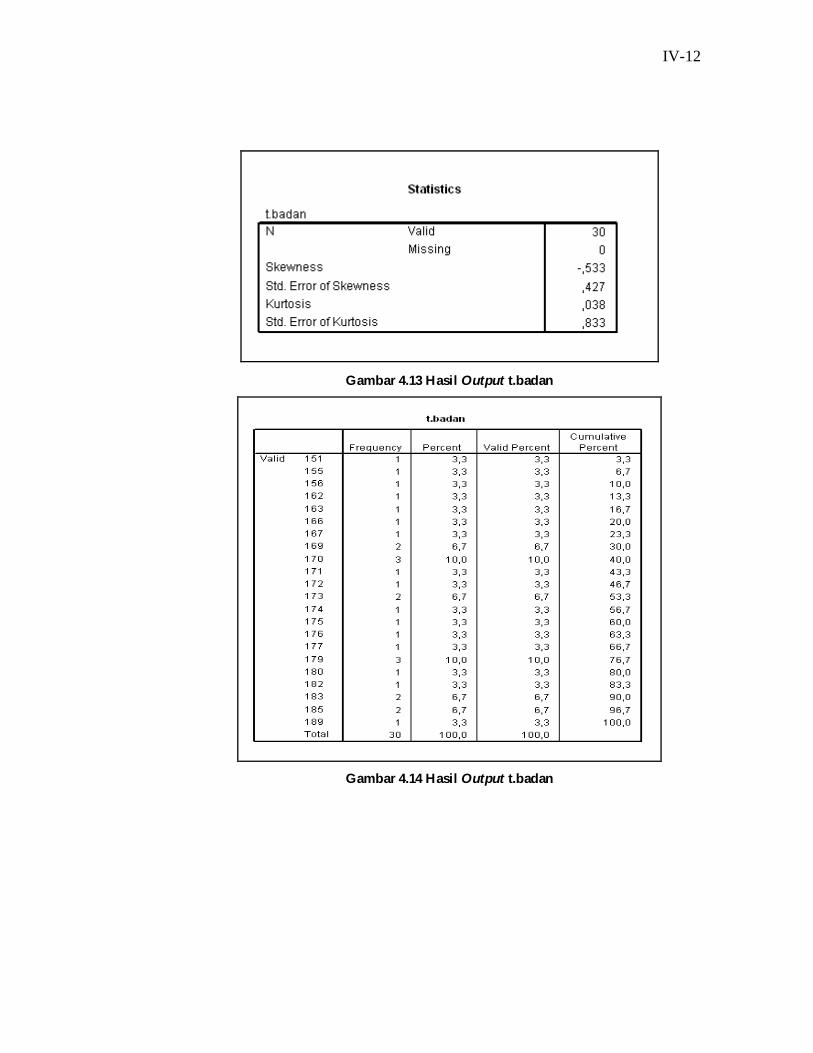
IV-12
Gambar 4.13 Hasil Output t.badan
Gambar 4.14 Hasil Output t.badan
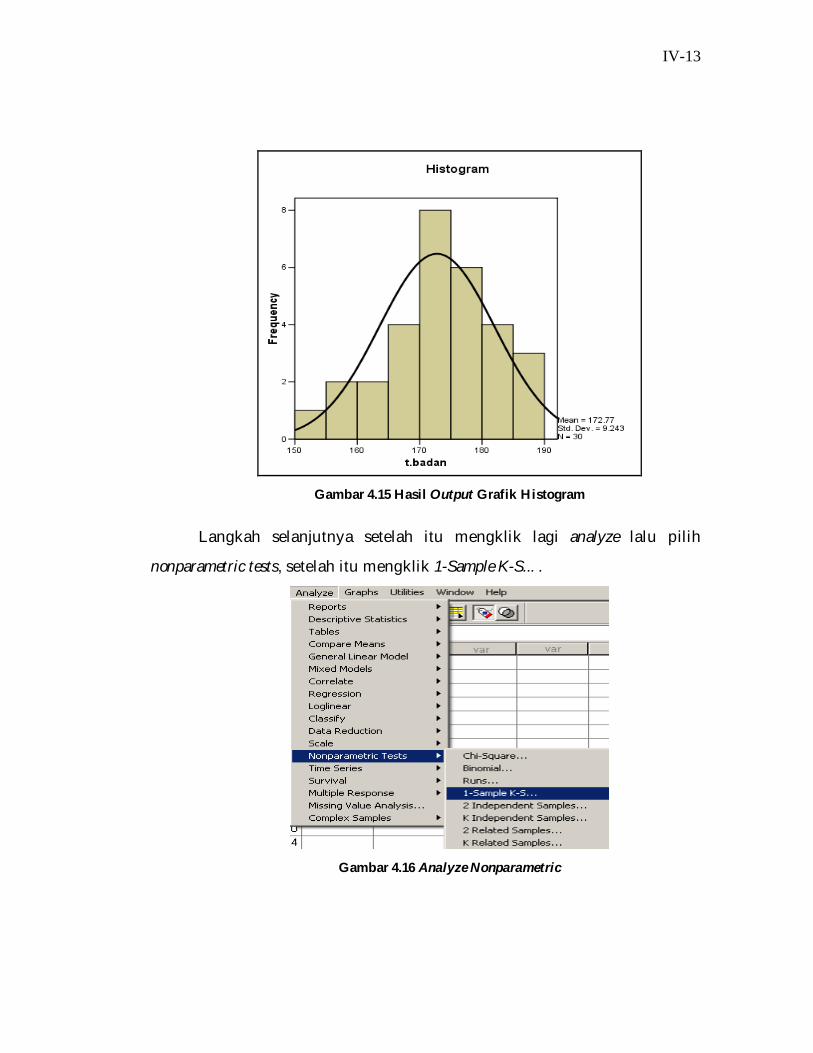
IV-13
Gambar 4.15 Hasil Output Grafik Histogram
Langkah selanjutnya setelah itu mengklik lagi analyze lalu pilih
nonparametric tests, setelah itu mengklik 1-Sample K-S... .
Gambar 4.16 Analyze Nonparametric

IV-14
Maka akan terdapat tabel seperti dibawah ini dalam tabel tersebut lalu
pindahkan Gender dan t.badan menuju test variable list, lalu setelah itu
dibawahnya dalam kolom test distribution klik normal, lalu menuju tombol
Option.
Gambar 4.17 Kolom One Sample Kolmogorov
Langkah selanjutnya mengeklik tombol option maka akan terdapat
tabel seperti dibawah ini pada kolom statistics lalu pilih kata descriptive, pada
kolom missing values lalu pilih kata exclude cases test-by-test, lalu mengklik
continue.
Gambar 4.18 Kolom Option
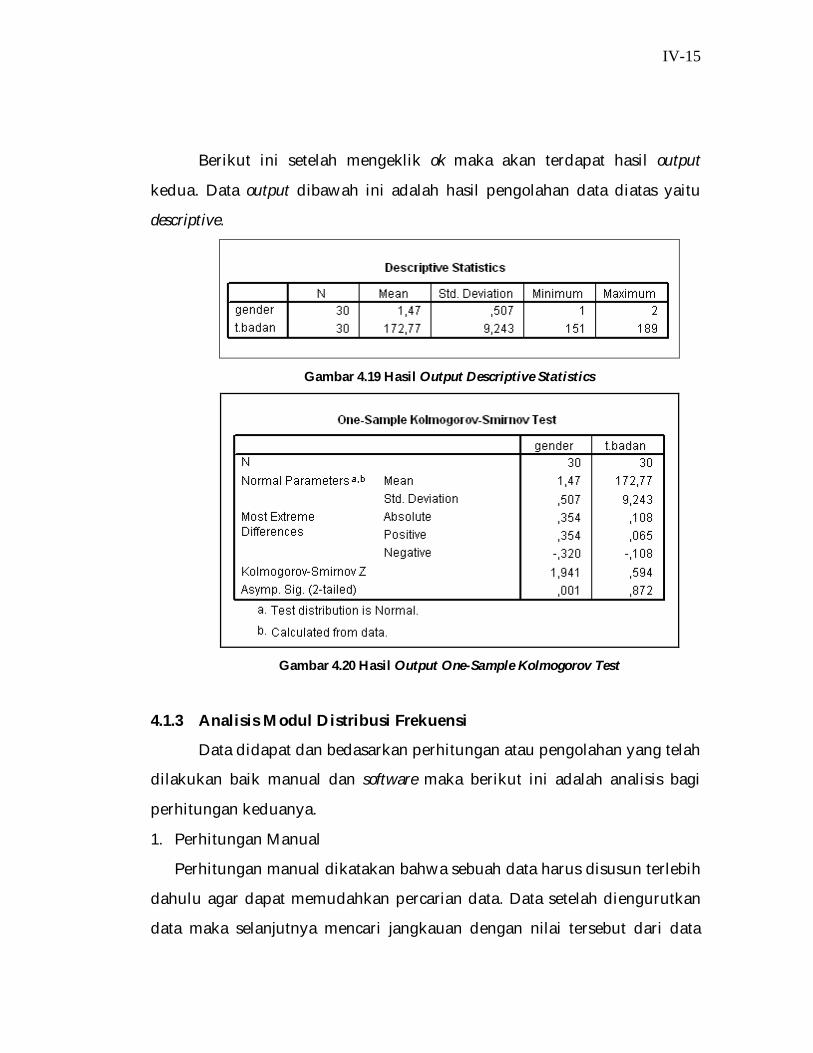
IV-15
Berikut ini setelah mengeklik ok maka akan terdapat hasil output
kedua. Data output dibawah ini adalah hasil pengolahan data diatas yaitu
descriptive.
Gambar 4.19 Hasil Output Descriptive Statistics
Gambar 4.20 Hasil Output One-Sample Kolmogorov Test
4.1.3 Analisis Modul Distribusi Frekuensi
Data didapat dan bedasarkan perhitungan atau pengolahan yang telah
dilakukan baik manual dan software maka berikut ini adalah analisis bagi
perhitungan keduanya.
1. Perhitungan Manual
Perhitungan manual dikatakan bahwa sebuah data harus disusun terlebih
dahulu agar dapat memudahkan percarian data. Data setelah diengurutkan
data maka selanjutnya mencari jangkauan dengan nilai tersebut dari data

IV-16
yang telah tersusun hanya menggunakan dua nilai yaitu data yang terkecil
dan data yang terbesar dengan hasil jangkauan adalah 38.
Jumlah kelas didapatkan setelah mengurutkan data dan mendapatkan
jangkauan setelah itu dapat mencari jumlah kelas, dengan kegunaan untuk
memasukkan data tunggal menjadi lebih teratur dengan kelompok-kelompok
kelas. Jumlah kelas didapat dengan cara log n dikalikan dengan 3,3 dan
ditambahkan dengan 1, dengan hasil jumlah kelas adalah 5,875 dibulatkan 6.
Interval kelas didapat setelah data tersusun, jangkauan, dan banyaknya
kelas telah terhitung. Interval kelas merupakan jarak dari sebuah kelas yang
terletak antara tepi atas kelas dan tepi bawah kelas. Interval kelas didapat
dengan dengan cara pembagian antara jangkauan dengan jumlah kelas,
dengan hasil interval kelas adalah 6,333 dibulatkan 7.
Tepi interval kelas untuk kelas pertama adalah 150,5 - 157,5. Tepi interval
kelas tersebut didapat setelah mencari interval kelas dan mendapatkannya
dengan cara batas bawah kiri kelas dikurangkan dengan 0,5, lalu batas atas
kanan kelas ditambahkan 0,5.
Titik tengah untuk kelas pertama adalah 154. Titik tengah bergantung
pada keakuratan data, sehingga untuk mencari titik tengah tersebut didapat
dengan cara batas atas kelas ditambah batas bawah kelas, selanjutnya dibagi
dengan 2.
Membuat grafik histogram digunakan data interval kelas sebagai
penunjuk yang mana tepi bawah kelas dan tepi atas kelas, grafik histogram
digunakan interval kelas dengan menggunakan frekuensi untuk menunjang
tinggi grafik batangnya. Membuat grafik pologon digunakan data titik
tengah yang sebagai penentu data titik barada ditengah-tengah interval kelas,
grafik poligon berbentuk grafik garis dengan menggunakan titik tengah dan

IV-17
frekuensi sebagai titik garis. Membuat grafik ogif digunakan data frekuensi
kumulatif kurang dari dan frekuensi kumulatif lebih dari, grafik ogif
memiliki data tengah atau titik pertemuan antara kurva kurang dari dan
lebih dari. Nilai titik tengah grafik ogif berarti jenis barang yang sesuai atau
tinggi badan yang ideal untuk membuat suatu tempat tidur. Garis yang
berada diatas titik tengah berarti jenis barang yang dipesan untuk beberapa
tinggi badan.
2. Pengolahan Software
Pengolahan software untuk output pertama dalam data statistik terdapat
pada gambar 4.13 dan paragraf dengan kriteria adalah sebagai berikut:
N adalah jumlah data yang diinput. N Valid adalah jumlah data yang telah
terpakai yaitu 30, berarti terdapat 30 data yang terpakai. N Missing adalah
jumlah data yang tidak terpakai atau yang lolos yaitu 0, berarti data semua
terpakai.
Skewness adalah untuk melihat kemencengan data jika dibuat dalam
bentuk kurva, sehingga kemencengan atau skewness data tersebut yaitu -
0,533. Std.Error of Skewwness adalah standar kesalahan pada kemencengan,
berarti standar kesalahannya yaitu 0,427.
Kurtosis adalah untuk melihat keruncingan data jika dibuat dalam bentuk
kurva, sehingga keruncingan atau kurtosis data tersebut yaitu 0,038. Std.Error
of Kurtosis adalah standar kesalahan pada keruncingan, berarti standar
kesalahannya yaitu 0,833.
Pengolahan software untuk output pertama dalam data tinggi.badan
terdapat pada gambar 4.14 dan paragraf dengan kriteria adalah sebagai
berikut:

IV-18
Frequency adalah jumlah data dalam bentuk tunggal yang telah tersusun
dalam Valid 30, dan missing berada dalam system yaitu 0 jadi Total yaitu 30.
Percent adalah data frekuensi yang disusun dalam %, dengan cara
frekuensi dibagi dengan jumlah data, selanjutnya dikalikan dengan 100%.
Contoh pada tinggi 151 cm dengan frekuensi 1 sehingga percentnya adalah
3,3%.
Valid Percent adalah data frekuensi yang disusun dalam %, sama dengan
percent, tetapi tidak terdapat data yang hilang. Contoh pada tinggi 151 cm
dengan frekuensi 1 sehingga percentnya adalah 3,3%.
Cumulative Percent adalah penunjuk dari setiap bagian frekuensi yang
sesuai dengan kumulatif kurang dari (<). Contoh data ke-2 adalah 6,7. Data
tersebut didapat dari penjumlahan antara data pertama dengan kedua, dan
seterusnya sampai data ke 30.
Pengolahan software untuk output pertama dalam grafik histogram
terdapat pada gambar 4.15 dan paragraf dengan kriteria adalah sebagai
berikut:
Grafik terdapat garis kurva normal, apabila garis kurva normal berada
diatas grafik histogram maka tinggi badan yang tidak sesuai dengan
keinginan untuk dibuat sebuah tempat tidur. Garis kurva normal berada
didalam grafik histogram maka tinggi badan tersebut sesuai untuk dibuat
dalam sebuah tempat tidur.
Data kurva normal yang telah tersusun dengan data yang sesuai dengan
tabel yang telah tersusun dengan mean yaitu 87,67, Std.Dev yaitu 15,67, dan
N yaitu 30.

IV-19
Pengolahan software untuk output kedua dalam descriptive statistics
terdapat pada gambar 4.19 dan paragraf dengan kriteria adalah sebagai
berikut:
N adalah jumlah data yang diinput. gender dan t.badan sama yaitu 30.
Mean adalah nilai rata-rata hitung. Rata–rata hitung adalah nilai yang di
peroleh dengan menjumlahkan semua nilai data dan membaginya dengan
jumlah data. Berarti rata-rata dalam gender yaitu 1,47 dan rata-rata dalam
t.badan yaitu 172.77.
Std. deviation yaitu standar normal dalam menentukan ukuran dalam
suatu data. Standar deviasi didapat dari titik tengah suatu kelas dikurangkan
dengan rata-rata hitung, selanjutnya dijumlahkan dan lalu dibagi dengan
banyaknya data. Standar deviasi dalam gender yaitu 0,507 dan dalam
tinggi.badan yaitu 9,243.
Minimum adalah data yang paling terkecil yaitu 151, sedangkan gendernya
yaitu 1 atau pria. Maxsimum adalah data yang paling besar yaitu 189,
sedangkan gendernya yaitu 2 atau wanita.
Pengolahan software untuk output kedua dalam one sample kolmogorov-
smirnov test terdapat pada gambar 4.20 dan paragraf dengan kriteria adalah
sebagai berikut:
Most Exstreme adalah data yang menunjukkan situasi besar. Absolute
adalah nilai yang menunjukkan situasi, dalam gender yaitu 0,354 dan dalam
t.badan yaitu 0,108. Situasi yang besar pada data diatas adalah tinggi badan
yang terlalu jauh atau tinggi, sehingga data menunjukkan situasi yang paling
tinggi untuk dibuat tempat tidur.
Differences positif adalah data yang menunjukkan hasil yang baik, dalam
gender yaitu 0,354 dan dalam t.badan yaitu 0,065. Tinggi badan yang ideal

IV-20
untuk dibuat tempat tidur adalah 0,065. Defferences negatife adalah data yang
kurang baik dipakai, dalam gender yaitu -0,320 dan dalam t.badan yaitu -
0,108, sehingga angka tersebut kurang tepat untuk dibuat tempat tidur.
Kolmogorov-Smirnov Z adalah data yang telah tersusun dengan distribisi
normal dan calculator data, dalam gender yaitu 1,941 dan dalam t.badan yaitu
0,594. Asymp.sig.(2-tailed) adalah data yang lebih besar 0,05 maka nilai
terpenuhi, jika nilai lebih kecil 0,05 maka tidak dapat dipenuhi, dalam gender
yaitu 0,001 maka dalam t.badan yaitu 0,872 dapat terpenuhi sehingga sebuah
tempat tidur dapat dibuatnya.
3. Perbandingan Antara Perhitungan Manual dan Pengolahan Software
Bagian N data dalam perhitungan manual data yang digunakan adalah
30, sedangkan dalam pengolahan software data yang digunakan juga 30. Data
tersebut sesuai disebabkan data yang diteliti adalah 30.
Bagian frekuensi dalam perhitungan manual data yang diberikan telah
dijadikan dalam data berkelompok dan frekuensi yang didapat telah
memenuhi kriteria kelompok yaitu menggunakan pencarian jangkauan,
banyaknya kelas, dan interval kelas. Pengolahan software data yang diberikan
dalam data tunggal. Sehingga frekuensi yang akurat berada dalam data
tunggal.
Bagian kumulatif, data kumulatif dalam perhitungan manual data yang
telah disusun adalah data berkelompok dengan frekuensi tertentu dan
menggunakan data kumulatif kurang dari dan lebih dari, sedangkan dalam
pengolahan software adalah data tunggal dan pada software data yang didapat
telah berbentuk persen. Sehingga kumulatif yang tepat dan akurat berada
dalam pengolahan software.
IV-21
Grafik histogram, grafik histogram dalam perhitungan manual
menggunakan tepi interval kelas dengan frekuensi data berkelompok yang
didapat, sedangkan dalam pengolahan software menggunakan mean, dan
standar deviasi dengan frekuensi data berkelompok yang diproses, dengan
menggunakan garis normal yaitu garis apabila berada dibawah grafik berarti
jenis barang yang baik dipakai, sedangkan untuk garis yang berada diatas
grafik berarti jenis barang yang tidak baik untuk dibuat karena jenis barang
yang dibuat terdapat cacatnya. Sehingga grafik histogram yang akurat adalah
menggunakan pengolahan software.
4.2. Studi Kasus Modul Ukuran Pemusatan
Disebuah perusahaan yang bergerak di bidang tekstil di daerah jawa
barat ingin membuat kerah kemeja dengan model terbaru dan trendi, untuk
semua kalangan baik pria maupun wanita. Perusahaan ini untuk
memprediksikan pasar ingin mengadakan suatu pengamatan untuk
mengukur lingkar leher. Perusahaan ini membutuhkan 30 sempel dalam
pengukuran tersebut. Data yang telah diukur yaitu sebagai berikut:
Tabel 4.4. Data Simulasi Ukuran Pemusatan
No Gender Lingkar Leher (cm) No Gender Lingkar Leher (cm)
1 Pria 30 16 wanita 27
2 Pria 31 17 wanita 25
3 Pria 33 18 wanita 28
4 Pria 30 19 wanita 26
5 Pria 35 20 Pria 33
6 pria 34 21 wanita 25
7 wanita 29 22 Pria 27

IV-22
Tabel 4.4. Data Simulasi Ukuran Pemusatan (Lanjutan)
No Gender Lingkar Leher (cm) No Gender Lingkar Leher (cm)
8 Pria 30 23 Pria 26
9 wanita 25 24 Pria 31
10 Pria 32 25 Pria 30
11 Pria 33 26 Pria 31
12 Pria 31 27 wanita 28
13 Pria 30 28 wanita 27
14 Pria 34 29 wanita 26
15 Pria 34 30 Pria 34
Data diatas agar memudahkan penelitian yang lebih lanjut maka
perusahaan tersebut akan melakukan perhitungan dengan kriterianya, yaitu:
a. Rata-rata hitung, ukur (geometrik), dan (harmonik)?
b. Median ?
c. Modus ?
d. Kuartil ?
e. Desil 5 dan 7 ?
f. Persentil 25, 50, 70, 75, 95 ?
4.2.1 Perhitungan Manual Modul Ukuran Pemusatan
Bedasarkan data yang telah diobservasi dan dicantumkan dalam tabel,
maka dibawah ini adalah hasil dari pengolahan data dengan menggunakan
perhitungan manual. Urutkan data adalah mengurutkan data dari yang
terkecil sampai yang terbesar. Hasilnya adalah sebagai berikut:

IV-23
25 25 25 26 26 26 27 27 27 28
28 29 30 30 30 30 30 31 31 31
31 32 33 33 33 34 34 34 35 35
Jangkauan adalah nilai data terbesar dikurangkan dengan data
terkecil, jangkauan sering juga disebut range. Hasilnya adalah sebagai
berikut:
Range = data terbesar – data terkecil
= 35 – 25
= 10
Banyaknya Kelas (K) adalah jumlah banyaknya kelas yang ada dalam
tabel data. Hasilnya adalah sebagai berikut:
K = 1 + 3,3 log n
K = 1 + 3,3 log 30
K = 1 + (3,3 . 1,477)
K = 1 + 4,875
K = 5,875 dibulatkan 6
Panjang Interval Kelas (I) adalah Merupakan jarak dari sebuah kelas
yang terletak antara tepi atas kelas dan tepi bawah kelas. Hasilnya adalah
sebagai berikut:
I = Range / K
I = 10 / 6
I = 1.667 dibulatkan 2

IV-24
Tabel 4.5. Hasil Perhitungan Manual Ukuran Pemusatan
No Interval Kelas Tepi Interval
Kelas
Frekuensi
(Fi)
Titik
Tengah
(Xi)
Frek *
T.Tgh
(FiXi)
1 25 – 26 24,5 – 26,5 5 25,5 127,5
2 27 – 28 26,5 – 28,5 5 27,5 137,5
3 29 - 30 28,5 – 30,5 7 29,5 206,5
4 31 – 32 30,5 – 32,5 5 31,5 157,5
5 33 – 34 32,5 – 34,5 6 33,5 201
6 35 - 36 34,5 – 36,5 2 35,5 71
Jml 30 901
Tabel 4.6. Hasil Perhitungan Manual Ukuran Pemusatan
Log Xi Fi * Log Xi Fi / Xi FK
1,4065 7,0325 0,1961 5
1,4393 7,1965 0,1818 10
1,4698 10,2886 0,2373 17
1,4983 7,4915 0,1587 22
1,5250 9,1500 0,1791 28
1,5502 3,1004 0,0563 30
44,2595 1,0093
a. Rata-Rata Hitung, Ukur (Geometrik), dan Harmonik
Rata-rata hitung adalah rata–rata hitung adalah nilai yang di peroleh
dengan jumlahkan semua nilai data dan membaginya dengan jumlah data,

IV-25
dengan demikian rata–rata hitung menunjukan pusat niali data dan
merupakan nilai yang dapat mewakili dari keterputusan data.
∑FiXi =901
∑Fi = 30
i
ii
FXF
X.
30901
X
0333,30X
Rata-rata ukur (geometrik) adalah banyak nilai data yang satu sama lain
saling berkelipatan sehingga perbandingan tiap dua data yang berurutan
tetap atau hampir tetap.
∑FiLogXi = 44,2595
∑Fi = 30
i
ii
FXF
AntiGlog.
log
302595,44logAntiG
4753,1logAntiG
8751,29G
Rata-rata harmonik adalah proses mencari nilai rata-rata dengan cara
menjumlahkan data dibagi dengan jumlah satu persetiap data.
∑Fi = 30
∑Fi / Xi = 1,0093
i
i
i
XFF
RH

IV-26
0093,130
RH
7236,29RH
b. Median
Median adalah nilai yang berada ditengah–tengah data setelah data di
urutkan.
Letak kelas median = ( ½ ) * n
= ( ½ ) * 30 = 15
Kelas median = 29 - 30
LB = 29 – 0,5 = 28,5
FK = 10
F.medium = 7
I = 2
i.f
FK -n 21
LB Md
2.7
10 - 15 28,5 Md
42,15,28 Md
92,29Md
c. Modus
Modus adalah nilai dari kelompok tersebut yang mempunyai frekuensi
tertinggi.
Kelas modus = 29 - 30
LB = 29 – 0,5 = 28,5
Fa = 7 – 5 = 2
Fb = 7 – 5 = 2

IV-27
I = 2
i.d d
d LB Mo
21
1
2.22
2 28,5 Mo
128,5 Mo
29,5 Mo
d. Kuartil
Kuartil adalah ukuran letak yang membagi data yang telah di urutkan
atau data yang berkelompok menjadi 4 bagian yang sama besar masing
masing 25%.
Kuartil 1 adalah data dibagi menjadi sama rata ¼.
Letak kelas kuartil1 = ( ¼ ) * n = ( ¼ ) * 30 = 7,5
Kelas kuartil 1 = 27 – 28
LB = 27 – 0,5 = 26,5
FK = 5
FQ1 = 5
I = 2
CiFQ
FKnLBQ .
)41(
11
2.5
55,75,261 Q
5,27115,261

IV-28
Kuartil 3 adalah data dibagi menjadi ¾.
Letak kelas kuartil3 = ( ¾ ) * n = ( ¾ ) * 30 = 22,5
Kelas kuartil 3 = 33 – 34
LB = 33 – 0,5 = 32,5
FK = 22
FQ3 = 6
I = 2
CiFQ
FKnLBQ .
)43(
33
2.6
225,225,323 Q
6667,3231667,05,323
e. Desil 5 dan 7
Desil adalah nilai atau angka yang membagi data dalam 10 bagian yang
sama, setelah disusun dalam data yang terkecil sampai yang terbesar atau
sebaliknya.
Desil 5
Letak kelas desil 5 = ( i * n ) / 10 = ( 5 * 30 ) / 10 = 15
Kelas desil 5 = 29 - 30
LB = 29 – 0,5 = 28,5
FK = 10
F.desil = 7
I = 2
i.fD
FK - 10in
LB D55

IV-29
2.7
10 - 15 28,5 D5
42,15,285 D
92,295 D
Desil 7
Letak kelas desil 7 = ( i * n ) / 10 = ( 7 * 30 ) / 10 = 21
Kelas desil 7 = 31 – 32
LB = 31 – 0,5 = 30,5
FK = 17
F.D7 = 5
I = 2
i.fD
FK - 10in
LB D77
2.5
17-2130,5 D7
1,3276,15,307
DD
f. Persentil 25, 50, 70, 75, dan 95
Persentil adalah nilai atau angka yang membagi data dalam 100 bagian
yang sama, setelah disusun dalam data yang terkecil sampai yang terbesar
atau sebaliknya.
Persentil 25
Letak kelas persentil 25 = ( I * n ) / 100 = ( 25 * 30 ) / 100 = 7,5
Kelas persentil 25 = 27 – 28
LB = 27 – 0,5 = 26,5
FK = 5

IV-30
FP25 = 5
I = 2
CiFP
FKin
LBP .10025
25
2.5
55,75,2625
P
5,2715,26
25
25
PP
Persentil 50
Letak kelas persentil 50 = ( I * n ) / 100 = ( 50 * 30 ) / 100 = 15
Kelas persentil 50 = 29 - 30
LB = 29 – 0,5 = 28,5
FK = 10
F.P50 = 7
I = 2
CiFP
FKin
LBP .10050
50
2.710 - 15 28,5 P50
42,15,2850 P
92,2950 P
Persentil 70
Letak kelas persentil 70 = ( I * n ) / 100 = ( 70 * 30 ) / 100 = 21
Kelas persentil 70 = 31 – 32
LB = 31 - 0,5 = 30,5
FK = 17

IV-31
F.P70 = 5
I = 2
CiFP
FKin
LBP .10070
70
2.5
17215,3070
P
1,326,15,30
70
70
PP
Persentil 75
Letak kelas persentil 75 = ( I * n ) / 100 = ( 75 * 30 ) / 100 = 22,5
Kelas persentil 75 = 33 – 34
LB = 33 – 0,5 = 32,5
FK = 22
F.P75 = 6
I = 2
CiFP
FKin
LBP .10075
75
2.6
225,225,3275
P
6667,321667,05,32
75
75
PP
Persentil 95
Letak kelas persentil 95 = ( I * n ) / 100 = ( 95 * 30 ) / 100 = 28,5
Kelas persentil 95 = 35 - 36
LB = 35 – 0,5 = 34,5
FK = 28

IV-32
F.P95 = 2
I = 2
CiFP
FKin
LBP .100100
95
2.2
285,285,3495
P
355,05,34
95
95
PP
4.2.2 Pengolahan Software Modul Ukuran Pemusatan
SPSS for windows adalah suatu program software yang bertujuan untuk
menghitung data statistika dengan semestinya. Langkah pertama untuk
membuat data ukuran pemusatan adalah menggunakan program SPSS for
windows yang telah penulis install. Langkah setelah itu lalu mencarinya di
program, dengan cara klik menu start lalu klik all programs setelah itu carilah
SPSS for windows.
Langkah selanjutnya setelah masuk kedalam program SPSS
diTampilan luar data terdapat gambar tabel dan dikiri bawah program
terdapat dua variabel yaitu data view dan variable view. Data view adalah
tempat untuk menaruh data-data yang ingin dimasukkan dalam program.
Variable view adalah tempat pembuatan untuk data view yang akan
dimasukkan. Langkah selanjutnya setelah masuk lalu memilih atau
memindahkan dari data view kedalam variabel view.

IV-33
Gambar 4.21 Tampilan Awal SPSS
Program variable view dalam kolom nama ditulis gender lalu
mengenternya, maka akan terdapat data-data seperti berikut, dan pada kolom
decimals diubah menjadi nol (0).
Gambar 4.22 Data Variable View
Langkah selanjutnya setelah itu dalam kolom values ada kata none lalu
mengkliknya. Data label values diklik maka akan terdapat data sebagai
berikut, dalam kolom value ditulis angka 1 dan 2, lalu dalam kolom value label
ditulis pria dan wanita, setelah selesai lalu add lalu klik OK.
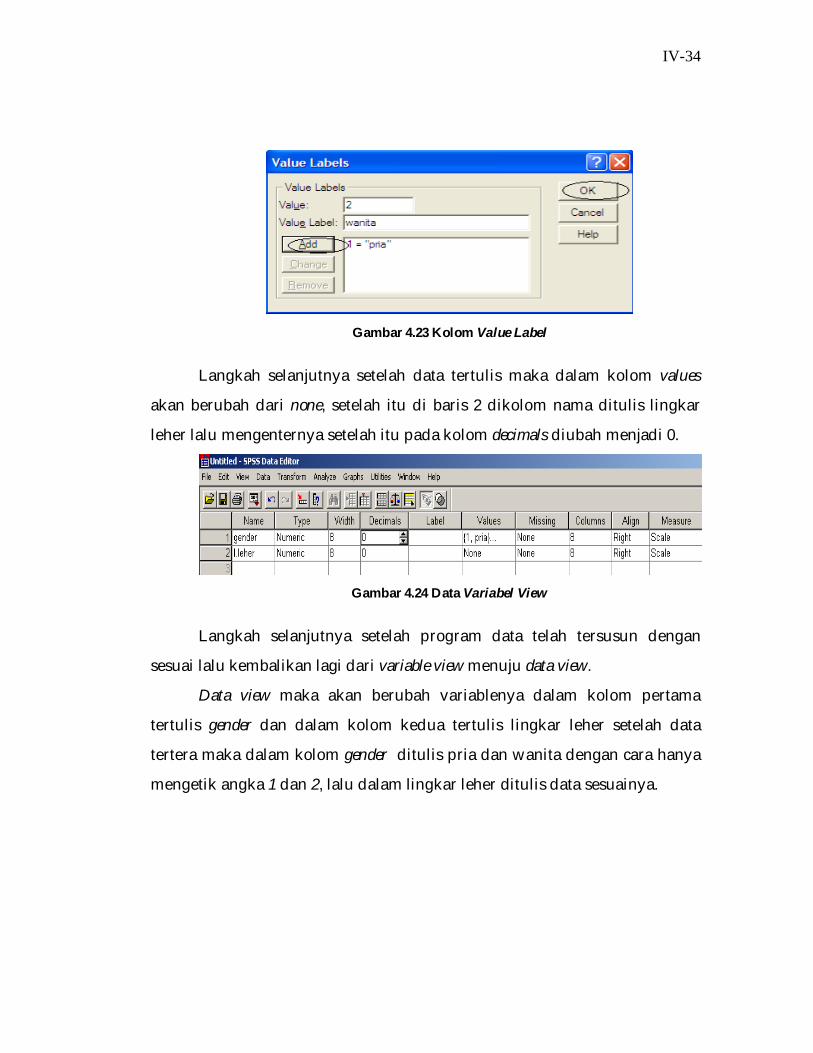
IV-34
Gambar 4.23 Kolom Value Label
Langkah selanjutnya setelah data tertulis maka dalam kolom values
akan berubah dari none, setelah itu di baris 2 dikolom nama ditulis lingkar
leher lalu mengenternya setelah itu pada kolom decimals diubah menjadi 0.
Gambar 4.24 Data Variabel View
Langkah selanjutnya setelah program data telah tersusun dengan
sesuai lalu kembalikan lagi dari variable view menuju data view.
Data view maka akan berubah variablenya dalam kolom pertama
tertulis gender dan dalam kolom kedua tertulis lingkar leher setelah data
tertera maka dalam kolom gender ditulis pria dan wanita dengan cara hanya
mengetik angka 1 dan 2, lalu dalam lingkar leher ditulis data sesuainya.

IV-35
Gambar 4.25 Data View
Langkah selanjutnya setelah data telah tersusun pada gambar diatas
lalu klik analyze lalu memilih compare means, setelah itu klik means… .
Gambar 4.26 Analyze Means
Langkah selanjutnya setelah mengeklik maka akan terdapat tabel
seperti gambar berikut, dalam tabel tersebut terdapat beberapa kolom.
Caranya pindahkan gender menuju ke independent list, setelah itu lalu
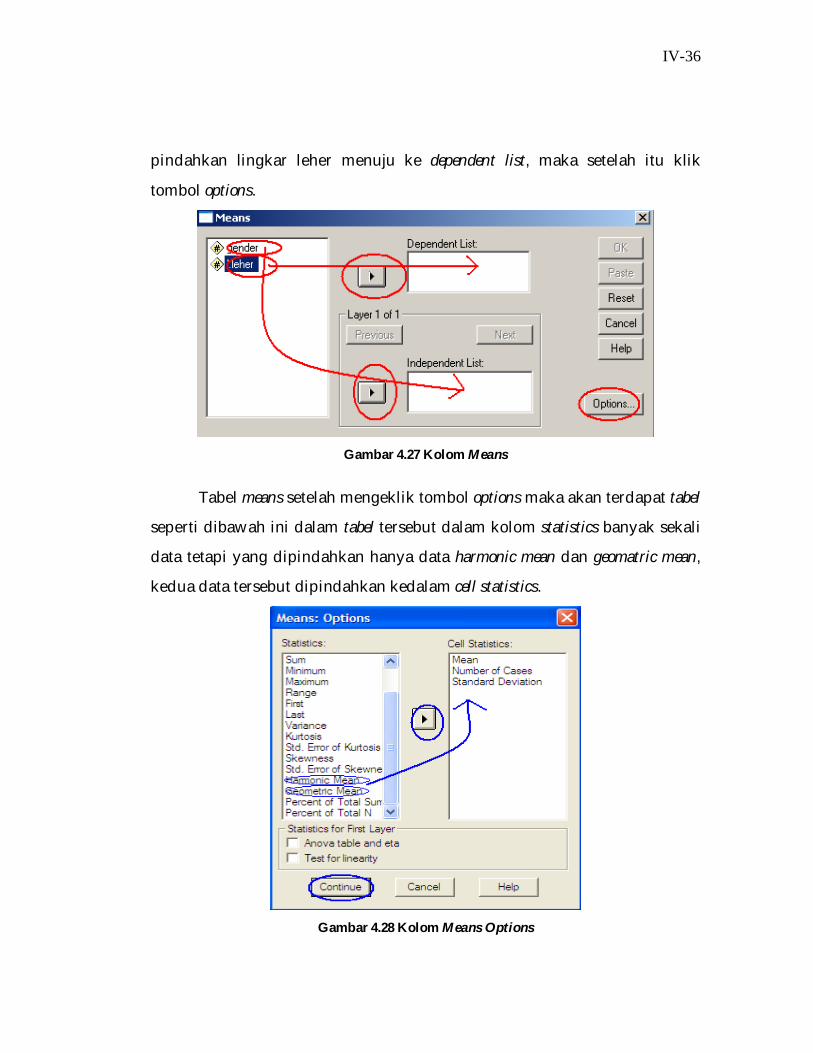
IV-36
pindahkan lingkar leher menuju ke dependent list, maka setelah itu klik
tombol options.
Gambar 4.27 Kolom Means
Tabel means setelah mengeklik tombol options maka akan terdapat tabel
seperti dibawah ini dalam tabel tersebut dalam kolom statistics banyak sekali
data tetapi yang dipindahkan hanya data harmonic mean dan geomatric mean,
kedua data tersebut dipindahkan kedalam cell statistics.
Gambar 4.28 Kolom Means Options
IV-37
Berikut ini setelah itu mengeklik Ok maka akan terdapat hasil Output.
Data output dibawah ini adalah hasil pengolahan data diatas yaitu means.
Gambar 4.29 Hasil Output Case Processing Summary
Gambar 4.30 Hasil Output Report
Langkah kedua setelah mendapatkan hasil output pertama adalah
seperti berikut, lalu klik analyze lalu memilih descriptive statistics, setelah itu
klik frequencies.

IV-38
Gambar 4.31 Analyze Frequencies
Langkah selanjutnya setelah mengeklik maka akan terdapat tabel
seperti gambar berikut, dalam kolom itu pindahkan lingkar leher menuju
variable (s), setelah itu mengklik tombol statistics.
Gambar 4.32 Kolom Frequecies
Tabel frequencies setelah mengeklik tombol statistics maka akan
terdapat tabel seperti dibawah ini pada kolom percentile values terdapat
banyak data tetapi yang dipilih adalah quartiles dan percentile (s) dengan

IV-39
mengekliknya, pada bagian percentile (s) menulis data yaitu 25, 50, 70, 75, dan
95. lalu klik add.
Langkah selanjutnya setelah itu disampingnya ada kolom data central
tendency pada kolom tersebut hanya mengeklik data mean, median, dan mode,
lalu mengklik continue.
Gambar 4.33 Kolom Frequencies Statistics
Berikut ini setelah itu mengklik ok maka akan terdapat hasil output.
Data output dibawah ini adalah hasil pengolahan data diatas yaitu frequencies.

IV-40
\ Gambar 4.34 Hasil Output Means Statistics
Gambar 4.35 Hasil Output Frequencies
4.2.3 Analisis Modul Ukuran Pemusatan
Data didapat dan bedasarkan perhitungan atau pengolahan yang telah
dilakukan baik manual dan software maka berikut ini adalah analisis bagi
perhitungan keduanya.

IV-41
1. Perhitungan Manual
Hal yang perlu diperhatikan dalam perhitungan manual ukuran
pemusatan adalah mengurutkan data dari yang terkecil samapai yang
terbesar setelah itu
Menghitung rata-rata hitung dimana rata-rata hitung disini adalah
30,0333 dimana hasil ini didapat dari frekuensi titik tengah dan frekuensi
disini frekuensi titik tengah didapat dari frekunsi dikali dengan titik tengah.
Rata-rata harmonik adalah banyaknya nilai data yang satu sama lainya saling
berkelipatan sehingga perbandingan tiap dau data yang berurutan tetap
dalam perhitungan manual didapat rata-rata geometrik sebesar 29,8751
dimana hasil ini didapat dari jumlah Fi log ix dibagi jumlah if dimana
jumlah .if iXlog sudah ada dalam tabel tinggal dibagi dengan n.
Perhitungan manual juga menghitung median di mana hasil pengukuran
median di sini mendapat hasil 29,92 dimana letak kelas mediannya 15 dan
LBnya 28,5 dan frekuensinya 10 dan frekuensi medium 7 dan intervalnya
adalah 1 maka dapat di hitung dengan rumus yang sudah ada tinggal
memasukan data yang sudah di cari sebelumnya.
Menghitung modus adalah dengan mencari data yang sering. Percobaan
yang sudah di lakukan mendapat hasil 29,5 dimana hasil ini di capai dengan
menentukan batas bawah atau kelas dimana modus berada, frekuensi kelas
modus dengan kelas sebelumnya, frekuensi kelas modus dengan kelas
sesudahnya dan besarnya interval setelah semua sudah didapat hasilnya
tinggal memasukan rumus yang sudah ada.
Perhitungan selanjutnya menghitung kuartil dimana kuartil adalah
ukuran letak yang membagi data yang telah di urutkan atau data yang
berkelompok menjadi 4 bagian yang sama besar masing masing 25%. Hasil

IV-42
dalam perhitungan ini adalah 27,5 dimana untuk mendapatkan hasil ini yang
pertama dilakukan mencari letak kelas interval tepi kelas dimana kuartil 1
berada, Frekuensi komulatif sebelum kelas kuartil, FQ1 Frekuensi pada kelas
kuartil dan besarnya interval, setelah semua sudah didapat hasilnya tinggal
memasukan rumus yang sudah ada. Kuartil 2 dan kuartil 3 hampir semuanya
sama yang membedakanya adalah letak kelas kuartilnya, Frekuensi
kumulatif sebelum kelas kuartil, FQ1 Frekuensi pada kelas kuartil.
Desil disini adalah membagi data menjadi 10 bagian yang sama misalnya
D1, D2, ....., D9, artinya setiap bagian mempunyai jumlah observasi yang
sama.dalam perhitungan di sini menggunakan D5 dimana mendapat hasil
perhitungan sebesar 29,92, untuk mendapatkan hasil tersebut yang dilakukan
adalah mencari letak kelas desil dari D5, Frekuensi komulatif sebelum kelas
desil, Frekuensi pada kelas desil dan besarnya interval, Setelah semua sudah
didapat hasilnya tinggal memasukan rumus yang sudah ada. Desil
selanjutnya hampir semuanya sama hanya dalam letak desil Frekuensi
komulatif sebelum kelas desil, Frekuensi pada kelas desil yang berbeda.
Pesentil hampir sama dengan desil hanya pembagian di dalam persentil
100 sedangkan desil 10. Perhitungan yang ada disini mendapatkan hasil
persentil 75 adalah 32,6667 disini hasil tersebut dicapai dari mencari letak
persentil dari P75, Frekuensi komulatif sebelum kelas persentil, Frekuensi
pada kelas persentil dan besarnya interval, Setelah semua sudah didapat
hasilnya tinggal memasukan rumus yang sudah ada. Persentil 25, 50,70 dan
95 selanjutnya hampir semuanya sama hanya dalam letak desil Frekuensi
komulatif sebelum kelas desil, Frekuensi pada kelas desil yang berbeda.

IV-43
2. Pengolahan Software
Pengolahan software untuk output pertama dalam data means terdapat
pada gambar 4.29 dan 4.30 dan paragraf dengan kriteria adalah sebagai
berikut:
Perhitungan software menggunakan SPSS 12 untuk mengetahui data yang
ingin di ukur. Hasil output untuk means adalah sebagai berikut. Included disini
adalah data yang sudah di masukan kedalam SPSS 12 dan n disini adalah
jumlah data yang di masukan 30 benar apa tidak. Excluded disini tidak ada
data yang tidak masuk dalam SPSS 12 jadi bisa dikatakan sukses, Sedangkan
total adalah jumlah dari included dan excluded. Mean adalah nilai rata-rata
disini mean pria adalah 31,45 maksudnya rata-rata dari pria dari 30 sampel
dan mean disini adalah 26,60 maksudnya nilai rata-rata dari 30 sampel yang
di ambil. Standar deviation disini standar dari pria adalah 2,373 sedangkan
standar deviation wanita adalah 1,430 maksud standar deviation disini standar
normal antara pria dan wanita dari 30 sampel. Harmonik mean dari pria dan
wanita sangat berbeda di kerenakan data pria dan wanita berbeda.
Geometrik mean adalah banyaknya nilai rata-rata dengan cara menjumlahkan
data di bagi dengan jumlah satu persetiap data. Pria geometriknya adalah
31,36 dan wanita 26,67. Total di sini adalah jumlah dari data pria di
tambahkan dengan hasil data wanita.
Pengolahan software untuk output kedua dalam data statistics terdapat
pada gambar 4.34 dan paragraf dengan kriteria adalah sebagai berikut:
Statistics untuk lingkar leher N adalah valid 30 maksudnya data yang di
masukan ada 30 dan missing 0 karena tidak ada data yang tidak valid
sehingga missing 0. Mean disini 29,83 maksudnya adalah nilai rata-rata dari
30 sampel. Median disini 30.00 adalah nilai tengah dari data 30 sampel dan

IV-44
mode 30 adalah data yang sering muncul dari 30 sampel. Persentil 25 disini
27,00. persentil 50 di sini bernilai 30,00 hasil ini didapat dari perhitungan data
tungal,persentil 70 disini bernilai 31,70 hasil ini didapat dari perhitungan
data tunggal persentil 70 sama dengan perhitungan desil 7. Persentil 73
bernilai 33,00 hasil ini didapat dari perhitungan data tunggal persentil 75
sama dengan perhitungan kuartil 3. Persentil 95 bernilai 34,45 maksudnya
nilai ini hasil dari perhitungan dari data tunggal menggunakann SPSS.
Pengolahan software untuk output kedua dalam data lingkar leher terdapat
pada gambar 4.35 dan paragraf dengan kriteria adalah sebagai berikut:
Frekuensi dari hasil output ini adalah data dimana data valid 30 yang
masuk frekuensi disini adalah 3 karena data 25 ada 3. Menghitung percent
dengan cara frekuensi dikali 3,3 sehingga persentnya menjadi 10,0, semuanya
frekuensi di kalikan 3,3. Mencari cumulative percent dengan menambahkan
dari data valid persent ke bawah, sehingga samapai data yang terakhir. Total
hanya menjumlahkan data dari pertama hingga terakhir.
3. Perbandingan Antara Perhitungan Manual dan Pengolahan Software
Perhitungan yang dilakukan antara manual dan software hampir semua
memilki persamaan yang membedakannya adalah angka di belakang
komanya saja dalam perhitungan manual.
Bagian N data dalam perhitungan manual data yang digunakan adalah
30, sedangkan dalam pengolahan software data yang digunakan juga 30. Data
tersebut sesuai disebabkan data yang diteliti adalah 30.
Data rata-rata hitung dalam perhitungan manual adalah 30,0333 dan
dalam pengolahan software adalah 29,83. Data tersebut dikatakan sama hanya
saja perbedaan pembulatan dan pengolahan data, untuk data perhitungan

IV-45
manual digunakan data berkelompok sedangkan pengolahan software
menggunakan data tunggal.
Data rata-rata harmonik dalam perhitungan manual adalah 29,7236 dan
dalam pengolahan software adalah 29,51. Data tersebut dikatakan sama hanya
saja perbedaan pembulatan, untuk perhitungan manual data yang didapat
menggunakan perhitungan kelompok sedangkan untuk pengolahan software
data yang didapat telah memasuki pembulatan yang sesuai.
Data rata-rata geometrik dalam perhitungan manual adalah 29,8751 dan
dalam pengolahan software adalah 29,67. Data tersebut dikatakan sama hanya
saja perbedaan pembulatan, untuk perhitungan manual data yang didapat
menggunakan perhitungan kelompok sedangkan untuk pengolahan software
data yang didapat telah memasuki pembulatan yang sesuai.
Data median dalam perhitungan manual adalah 29,92 dan dalam
pengolahan software adalah 30,00. Data tersebut telah sesuai hanya perbedaan
pembulatan saja, dalam perhitungan manual data menggunakan rumus
berkelompok sedangkan untuk pengolahan software menggunakan data
tunggal yang menggunakan persen.
Data modus dalam perhitungan manual adalah 29,5 dan dalam
pengolahan software adalah 30. Data tersebut telah sesuai hanya perbedaan
pembulatan saja, dalam perhitungan manual data menggunakan rumus
berkelompok sedangkan untuk pengolahan software menggunakan data
tunggal yang menggunakan persen.
Data persentil untuk 25, 50, 70, 75 dan 95 untuk perhitungan manual dan
pengolahan software tidak terlalu jauh dalam pembulatan. Data tersebut,
dalam perhitungan manual data menggunakan rumus berkelompok
IV-46
sedangkan untuk pengolahan software menggunakan data tunggal yang
menggunakan persen.
4.3. Studi Kasus Modul Ukuran Penyebaran
PT. Radja Martha ingin memproduksi topi pantai untuk acara festival
bulan purnama. Data akan diambil sebanyak 30 orang dengan 15 pria dan 15
wanita. Maka dilakukan survey dengan hasil data dibawah ini: Tabel 4.7. Data Simulasi Ukuran Penyebaran
No Gender Lingkar Kepala
(cm)
N
o Gender
Lingkar Kepala
(cm)
1 Pria 52 16 Wanita 51
2 Pria 52 17 Pria 49
3 Wanita 47 18 Pria 47
4 Wanita 48 19 Pria 50
5 Wanita 50 20 Wanita 52
6 Pria 47 21 Wanita 48
7 Wanita 49 22 Wanita 51
8 Pria 50 23 Pria 50
9 Pria 50 24 Wanita 49
10 Wanita 51 25 Wanita 52
11 Pria 51 26 Pria 51
12 Pria 52 27 Pria 48
13 Pria 49 28 Wanita 50
14 Wanita 50 29 Pria 52
15 Wanita 50 30 Wanita 52

IV-47
Berdasarkan data pengamatan diatas maka akan dicari nilai dari:
a. Rentang ?
b. Kuartil pertama dan kuartil ketiga ?
c. Rentang antar kuartil ?
d. Simpangan rata-rata ?
e. Simpangan baku ?
f. Koefisiensi Variansi ?
g. Z-score ?
4.3.1 Perhitungan Manual Modul Ukuran Penyebaran
Perhitungan manual akan dicari nilai dari data pria dan dari data
wanita yang dilakukan secara terpisah.
1. Data Pria
Data pria adalah data tunggal untuk data pria saja. Data tersebut akan
dicari rentang, kuartil, rentang antar kuartil, simpangan rata-rata, simpangan
baku, dan koefisien variansi. Hasilnya adalah sebagai berikut: Tabel 4.8. Hasil Perhitungan Manual Data Pria Ukuran Penyebaran
No Gender Lingkar Kepala (cm) X XXi 2)( XXi
1 Pria 47 50 3 9
2 Pria 47 50 3 9
3 Pria 48 50 2 4
4 Pria 49 50 1 1
5 Pria 49 50 1 1
6 Pria 50 50 0 0
7 Pria 50 50 0 0

IV-48
Tabel 4.8. Hasil Perhitungan Manual Data Pria Ukuran Penyebaran (Lanjutan)
No Gender Lingkar Kepala (cm) X XXi 2)( XXi
8 Pria 50 50 0 0
9 Pria 50 50 0 0
10 Pria 51 50 1 1
11 Pria 51 50 1 1
12 Pria 52 50 2 4
13 Pria 52 50 2 4
14 Pria 52 50 2 4
15 Pria 52 50 2 4
Jumlah 750 20 42
a. Rentang = data terbesar – data terkecil
= 52-47
= 5
Kelas = 1 + 3,3 log n I = Rentang/Kelas
= 1 + 3,3 log 15 = 5/5
= 1 + 3,88 = 1
= 4,88 atau sama dengan 5
b. Rumus Qi =
41-ke Data n
Q1 =
41151-ke Data Q3 =
41153-ke Data
=
416-ke Data =
448-ke Data
= Data ke - 4 = Data ke-12
= 49 = 52

IV-49
c. Rentang Antar Kuartil
H = Q3 – Q1
= 52 – 49
= 3
d. Simpangan Rata-rata
n
xix
n
i 1
15525252525151505050504949484747
x
15750
50
SR = 1
n
xxi
115
4.50522.50514.50502.504950482.5047
14
4)2(2.14.02.122.3
14
)8(20226
1420
= 1,4285
e. Varians
1
2
2
nxxi
S

IV-50
= 115
4.)5052(2.50514.)5050(2.504950482.5047 222222
= 14
4.)2(2.14.)0(2.122.3 222222
14
4).2(2.14.02.142.9
14
)8(202418
1442
3
Simpangan baku
S = 2S
= 3
=1,73205
f. Koefisiensi Variansi
KV = %100XS
= %10050
73205,1
= %46,3
2. Data Wanita
Data wanita adalah data tunggal untuk data wanita saja. Data tersebut
akan dicari rentang, kuartil, rentang antar kuartil, simpangan rata-rata,
simpangan baku, dan koefisien variansi. Hasilnya adalah sebagai berikut:

IV-51
Tabel 4.9. Hasil Perhitungan Manual Data Wanita Ukuran Penyebaran
No Gender Lingkar Kepala(cm) X XXi 2)( XXi
1 Wanita 47 50 3 9
2 Wanita 48 50 2 4
3 Wanita 48 50 2 4
4 Wanita 49 50 1 1
5 Wanita 49 50 1 1
6 Wanita 50 50 0 0
7 Wanita 50 50 0 0
8 Wanita 50 50 0 0
9 Wanita 50 50 0 0
10 Wanita 51 50 1 1
11 Wanita 51 50 1 1
12 Wanita 51 50 1 1
13 Wanita 52 50 2 4
14 Wanita 52 50 2 4
15 Wanita 52 50 2 4
Jumlah 750 18 34
a. Rentang = data terbesar – data terkecil
= 52-47
= 5
Kelas = 1 + 3,3 log n I = Rentang/Kelas
= 1 + 3,3 log 15 = 5/5
= 1 + 3,88 = 1
= 4,88 atau sama dengan 5

IV-52
b. Rumus Qi =
41-ke Data n
Q1 =
41151-ke Data Q3 =
41153-ke Data
=
416-ke Data =
448-ke Data
= Data ke - 4 = Data ke-12
= 49 = 51
c. Rentang Antar Kuartil
H = Q3 – Q1
= 51 – 49
= 2
d. Simpangan Rata-rata
n
xix
n
i 1
15525252515151505050504949484847
x
15750
50
SR = 1
n
xxi
115
3.50523.50514.50502.50492.50485047
14
3)2(3.14.02.12.23

IV-53
14
)6(30243
1418
= 1,285
e. Varians
1
2
2
nxxi
S
= 115
3.)5052(3.50514.)5050(2.50492.50485047 222222
= 14
3.)2(3.14.)0(2.12.23 222222
14
3).4(3.14.02.12.49
14
)12(30289
1434
2 ,429
Simpangan baku
S = 2S
= 429,2
=1,5585
f. Koefisiensi Variansi
KV = %100XS
= %100505585,1
= %12,3
IV-54
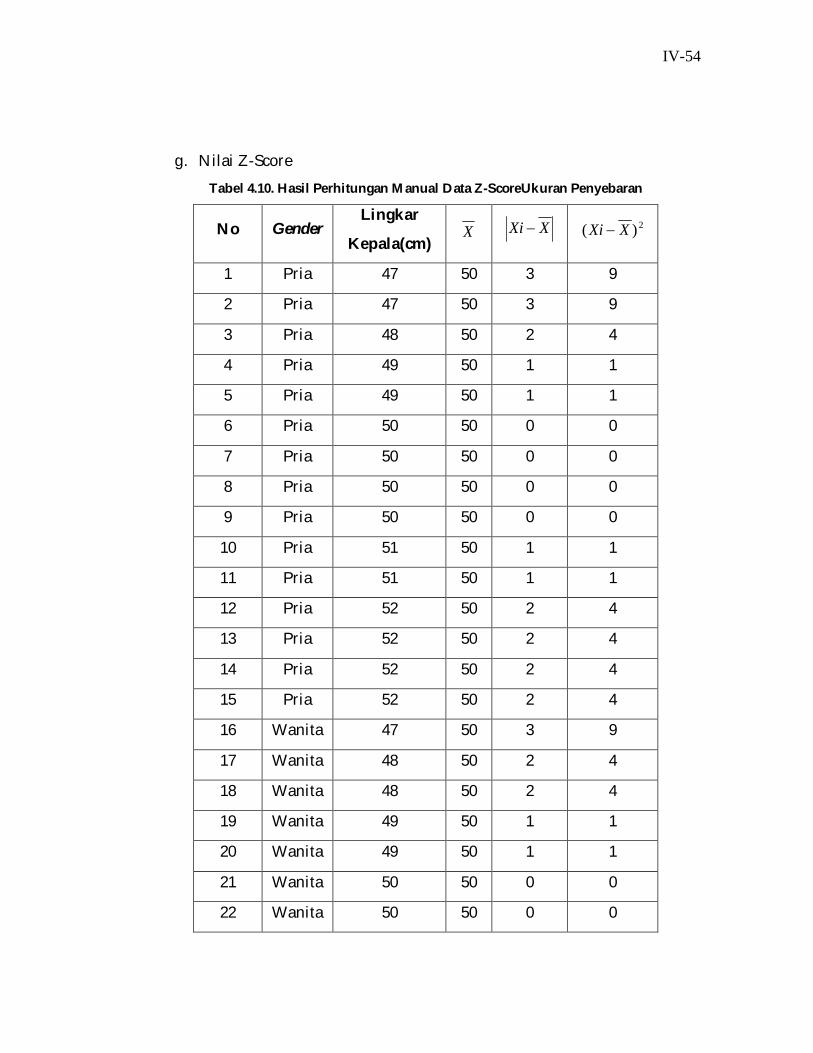
g. Nilai Z-Score Tabel 4.10. Hasil Perhitungan Manual Data Z-ScoreUkuran Penyebaran
No Gender Lingkar
Kepala(cm) X XXi 2)( XXi
1 Pria 47 50 3 9
2 Pria 47 50 3 9
3 Pria 48 50 2 4
4 Pria 49 50 1 1
5 Pria 49 50 1 1
6 Pria 50 50 0 0
7 Pria 50 50 0 0
8 Pria 50 50 0 0
9 Pria 50 50 0 0
10 Pria 51 50 1 1
11 Pria 51 50 1 1
12 Pria 52 50 2 4
13 Pria 52 50 2 4
14 Pria 52 50 2 4
15 Pria 52 50 2 4
16 Wanita 47 50 3 9
17 Wanita 48 50 2 4
18 Wanita 48 50 2 4
19 Wanita 49 50 1 1
20 Wanita 49 50 1 1
21 Wanita 50 50 0 0
22 Wanita 50 50 0 0
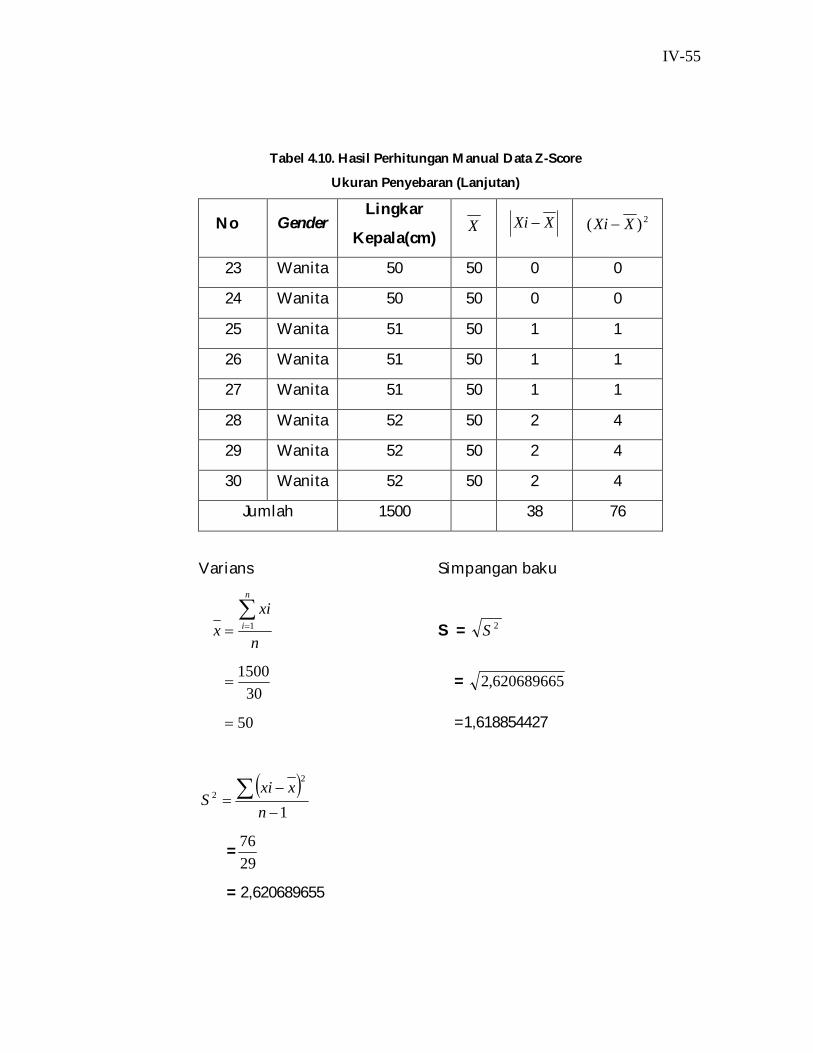
IV-55
Tabel 4.10. Hasil Perhitungan Manual Data Z-Score
Ukuran Penyebaran (Lanjutan)
No Gender Lingkar
Kepala(cm) X XXi 2)( XXi
23 Wanita 50 50 0 0
24 Wanita 50 50 0 0
25 Wanita 51 50 1 1
26 Wanita 51 50 1 1
27 Wanita 51 50 1 1
28 Wanita 52 50 2 4
29 Wanita 52 50 2 4
30 Wanita 52 50 2 4
Jumlah 1500 38 76
Varians Simpangan baku
n
xix
n
i 1 S = 2S
30
1500 = 620689665,2
50 =1,618854427
1
2
2
nxxi
S
=2976
= 2,620689655

IV-56
Z-Score
sxxZ
85316,1618854427,1
3618854427,1
504711
sxxZ
61772,0618854427,1
1618854427,1
504955
sxx
Z
23544,1618854427,1
2618854427,1
50521515
sxx
Z
61772,0618854427,1
1618854427,1
50512525
sxx
Z
23544,1618854427,1
2618854427,1
50523030
sxx
Z
4.3.2 Pengolahan Software Modul Ukuran Penyebaran
Pertama pilih program MiniTab 14 untuk mempermudah proses
perhitungan data ukuran penyebaran. Tampilan awal MiniTab 14 ialah
sebagai berikut.
Gambar 4.36 Tampilan Awal MiniTab 14

IV-57
Langkah kedua masuk ke program MiniTab 14 dan akan muncul
tampilan seperti dibawah ini. Tuliskan gender pada kolom C1, l.kepala pada
kolom C2 dan z-score pada kolom C3 lalu masukan data yang telah diambil
melalui hasil survey pada saat pengambilan data.
Gambar 4.37 Data Input
Langkah ketiga ialah klik stat pilih Basic Statistics lalu pilih Display
Descriptive Statistics, di bawah ini adalah langkah tampilan software.
Gambar 4.38 Basic Statistics
IV-58
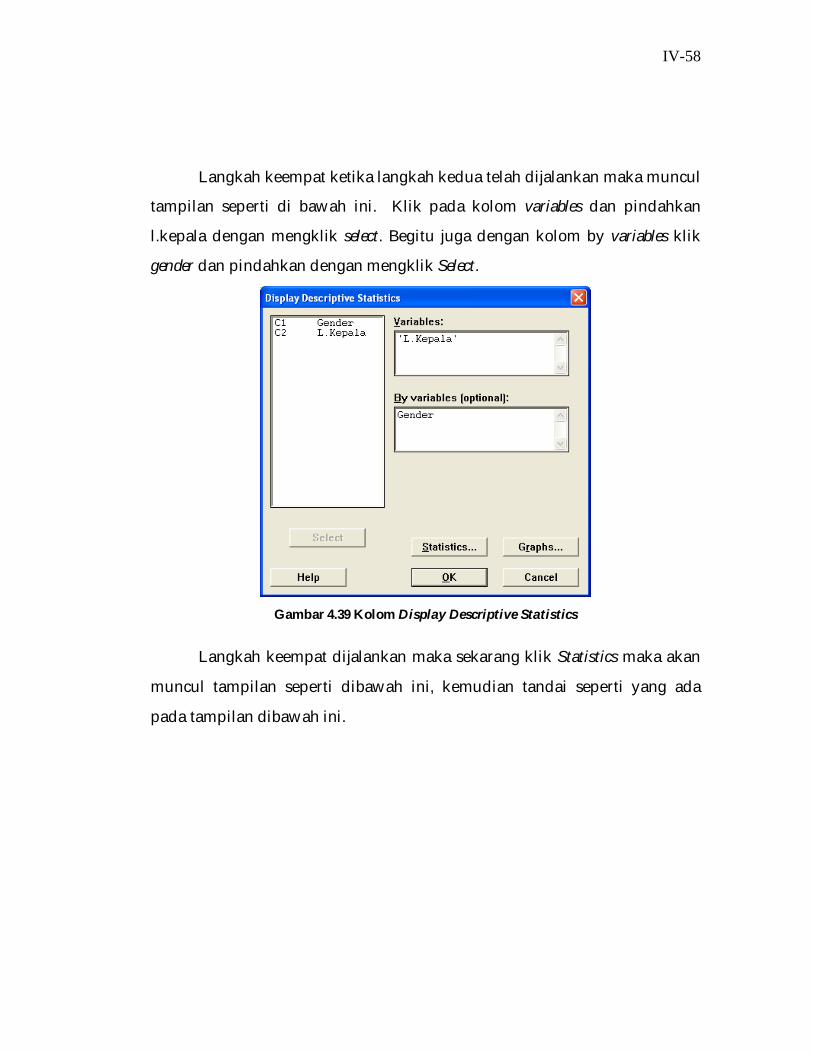
Langkah keempat ketika langkah kedua telah dijalankan maka muncul
tampilan seperti di bawah ini. Klik pada kolom variables dan pindahkan
l.kepala dengan mengklik select. Begitu juga dengan kolom by variables klik
gender dan pindahkan dengan mengklik Select.
Gambar 4.39 Kolom Display Descriptive Statistics
Langkah keempat dijalankan maka sekarang klik Statistics maka akan
muncul tampilan seperti dibawah ini, kemudian tandai seperti yang ada
pada tampilan dibawah ini.
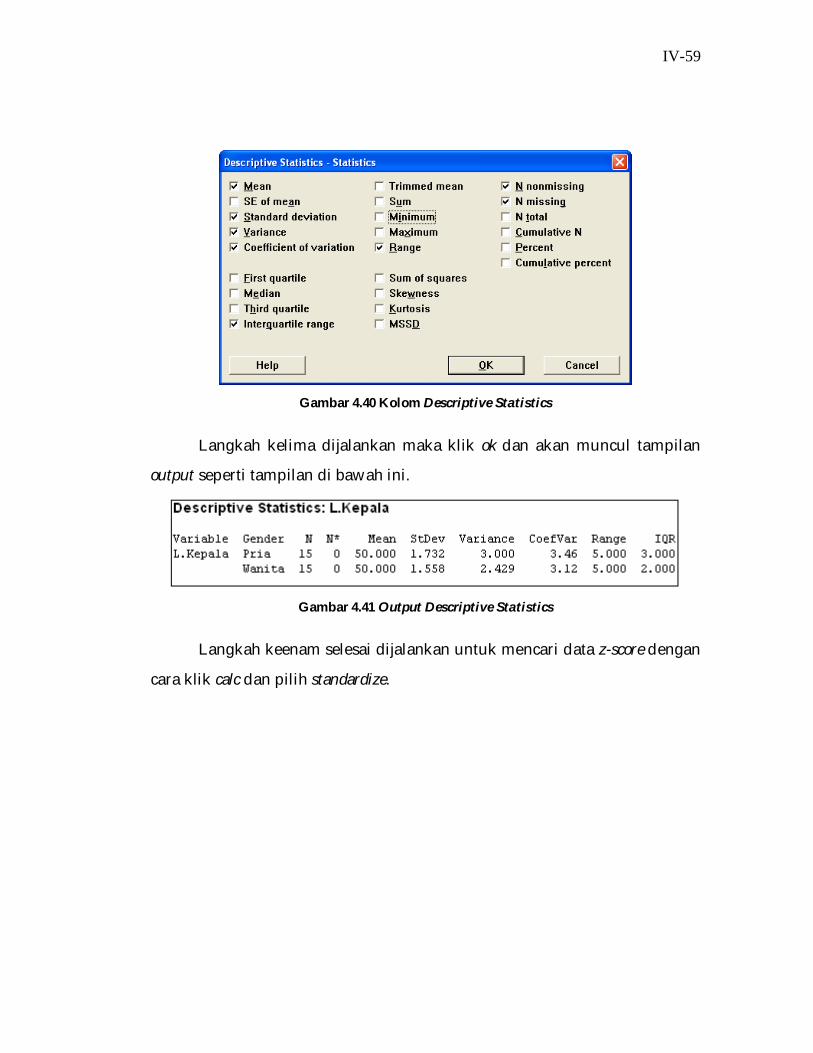
IV-59
Gambar 4.40 Kolom Descriptive Statistics
Langkah kelima dijalankan maka klik ok dan akan muncul tampilan
output seperti tampilan di bawah ini.
Gambar 4.41 Output Descriptive Statistics
Langkah keenam selesai dijalankan untuk mencari data z-score dengan
cara klik calc dan pilih standardize.
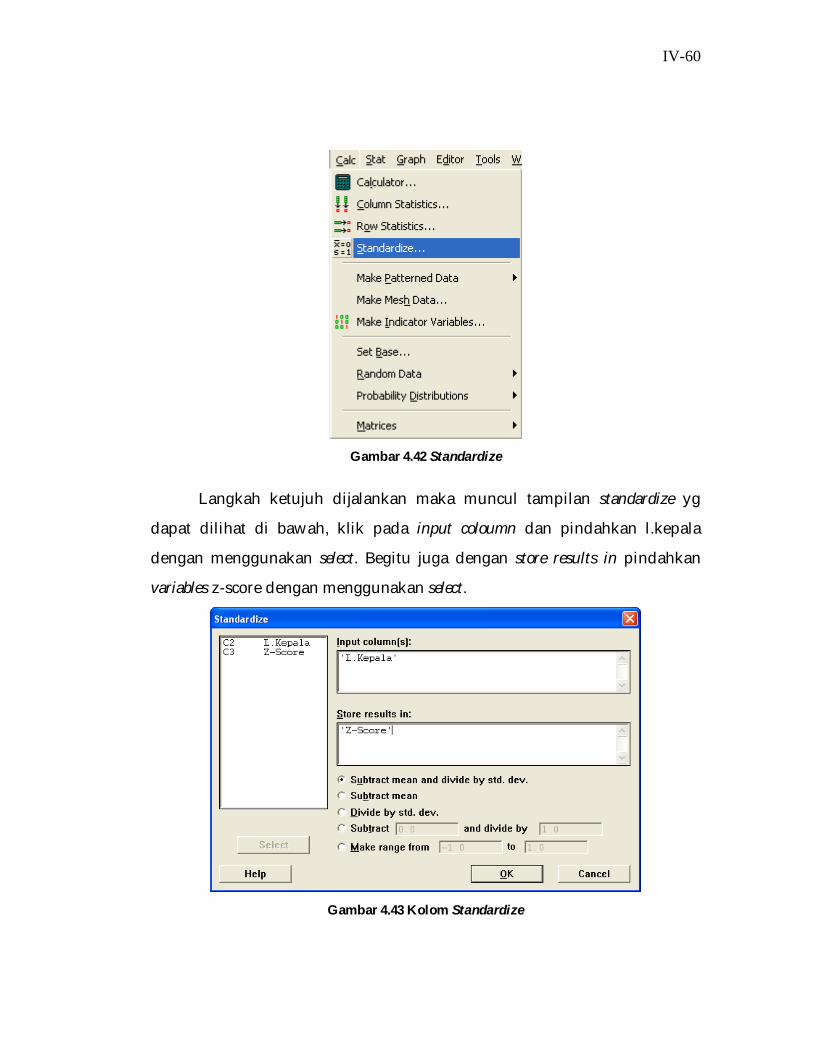
IV-60
Gambar 4.42 Standardize
Langkah ketujuh dijalankan maka muncul tampilan standardize yg
dapat dilihat di bawah, klik pada input coloumn dan pindahkan l.kepala
dengan menggunakan select. Begitu juga dengan store results in pindahkan
variables z-score dengan menggunakan select.
Gambar 4.43 Kolom Standardize

IV-61
Langkah setelah selesai menjalankan semua perintah pada langkah di
atas kemudian klik ok dan muncul hasil perhitungan software pada kolom z-
score yang dapat dilihat di bawah ini.
Gambar 4.44 Output Standardize
4.3.3 Analisis Modul Ukuran Penyebaran
Data didapat bedasarkan perhitungan dan pengolahan yang telah
dilakukan baik manual dan software maka berikut ini adalah analisis bagi
perhitungan untuk data pria, data wanita dan nilai Z-score.
1. Perhitungan Manual
Perhitungan manual dilakukan terpisah dengan mencari nilai dari data
pria masing-masing dan nilai dari data wanita masing-masing.
a. Data Pria
Nilai rentang pada data pria adalah 5 yang merupakan pengurangan
dari nilai terbesar pada data pria dikurang dengan nilai terkecil dari
data pria. Banyak kelas pada data pria adalah 4,88 yang dibulatkan
menjadi 5 merupakan nilai dari 1 ditambah 3,3 log banyak data pria.
Interval kelas pada data pria ialah 1 merupakan pembagian dari

IV-62
rentang dengan banyak kelas yang berarti perhitungan yang
digunakan adalah data tunggal karena interval kelasnya 1. Kuartil
pertama pada data data pria adalah data keempat yakni 49 dan kuartil
ketiga pada data pria adalah data kedua belas yakni 52. Rentang antar
kuartil pada data pria adalah 3 yang merupakan pengurangan dari
kuartil ketiga dengan kuartil pertama. Rata-rata pada data pria adalah
50 merupakan keseluruhan nilai jumlah data pria dibagi dengan
banyaknya data pria. Simpangan rata-rata pada data pria adalah
1,4285 merupakan keseluruhan jumlah nilai mutlak dari pengurangan
setiap data pria dengan nilai rata-rata yang dibagi dengan jumlah
data dikurangi satu. Varians pada data pria adalah 3 merupakan
penjumlahan dari setiap data pria dikurangi dengan nilai rata-rata
yang dikuadratkan kemudian dibagi jumlah data pada pria dikurang
1. Simpangan baku pada data pria adalah 1,73205 merupakan akar
dari nilai varians. Koefisiensi variansi pada data pria adalah 3,46%
merupakan nilai dari simpangan baku dibagi dengan rata-rata dikali
100%.
b. Data Wanita
Nilai rentang pada data wanita adalah 5 yang merupakan
pengurangan dari nilai terbesar pada data wanita dikurang dengan
nilai terkecil dari data wanita. Banyak kelas pada data wanita adalah
4,88 yang dibulatkan menjadi 5 merupakan nilai dari 1 ditambah 3,3
log banyak data wanita. Interval kelas pada data wanita ialah 1
merupakan pembagian dari rentang dengan banyak kelas yang berarti
perhitungan yang digunakan adalah data tunggal karena interval
kelasnya 1. Kuartil pertama pada data data wanita adalah data

IV-63
keempat yakni 49 dan kuartil ketiga pada data wanita adalah data
kedua belas yakni 51. Rentang antar kuartil pada data wanita adalah 2
yang merupakan pengurangan dari kuartil ketiga dengan kuartil
pertama. Rata-rata pada data wanita adalah 50 merupakan
keseluruhan nilai jumlah data wanita dibagi dengan banyaknya data
wanita.Simpangan rata-rata pada data wanita adalah 1,285 merupakan
keseluruhan jumlah nilai mutlak dari pengurangan setiap data wanita
dengan nilai rata-rata yang dibagi dengan jumlah data dikurangi satu.
Varians pada data wanita adalah 2,429 merupakan penjumlahan dari
setiap data wanita dikurangi dengan nilai rata-rata yang dikuadratkan
kemudian dibagi jumlah data pada wanita dikurang 1.Simpangan
baku pada data wanita adalah 1,5585 merupakan akar dari nilai
varians. Koefisiensi variansi pada data wanita adalah 3,12%
merupakan nilai dari simpangan baku dibagi dengan rata-rata dikali
100%.
c. Nilai Z-score
Nilai Z-score digunakan dengan mencari nilai simpangan baku dari
keseluruhan data dan juga nilai rata-rata dari keseluruhan data
dimana jumlah data adalah 30. Rata-rata dari keseluruhan data ialah
50 yang merupakan nilai dari keseluruhan jumlah data dibagi dengan
banyak data. Varians untuk keseluruhan data adalah 2,620689655
merupakan jumlah keseluruhan dari setiap data dikurangi dengan
nilai rata-rata kemudian dibagi dengan jumlah data dikurangi dengan
1. Simpangan baku untuk keseluruhan data adalah 1,618854427
merupakan hasil akar dari varians Nilai z-score untuk data kelima

IV-64
adalah –0,61772 yang merupakan nilai dari data kelima dikurangi
dengan nilai rata-rata kemudian dibagi dengan simpangan baku.
2. Pengolahan Software
Pengolahan software modul ukuran penyebaran akan dicari untuk data
pada data wanita dan nilai z-score. Pengolahan software digunakan untuk
mempermudah perhitungan data-data yang berkaitan dengan statistika.
a. Data Pria
Lihat gambar 4.41 untuk data pria dimana terdapat gender untuk
menentukan jenis kelamin untuk pria. Nilai N adalah 15 merupakan
jumlah data pria kemudian N* adalah 0 merupakan jumlah data yang
hilang. Nilai mean adalah 50 yang merupakan nilai rata-rata dari data
pria. Nilai stdev adalah 1,732 merupakan simpangan baku pada data
pria. Nilai variance adalah 3,000 yang merupakan nilai varians dari
data pria. Nilai coefvar adalah 3,46 yang merupakan nilai koefisiensi
variansi pada data pria. Nilai range adalah 5.000 yang merupakan
nilai rentang dari data pria. Nilai IQR adalah 3,000 yang merupakan
nilai rentang antar kuartil pada data pria.
b. Data Wanita
Lihat gambar 4.41 untuk data wanita dimana terdapat gender ntuk
menentukan jenis kelamin untuk wanita. Nilai N adalah 15
merupakan jumlah data wanita kemudian N* adalah 0 merupakan
jumlah data yang hilang. Nilai mean adalah 50 yang merupakan nilai
rata-rata dari data wanita. Nilai stdev adalah 1,558 merupakan
simpangan baku pada data wanita. Nilai variance adalah 2,429 yang
merupakan nilai varians dari data wanita. Nilai coefvar adalah 3,12
yang merupakan nilai koefisiensi variansi pada data wanita. Nilai

IV-65
range adalah 5.000 yang merupakan nilai rentang dari data wanita.
Nilai IQR adalah 2,000 yang merupakan nilai rentang antar kuartil
pada data pria.
c. Nilai Z-score
Lihat gambar 4.44 untuk melihat nilai Z-score dimana nilai Z-score
untuk data pertama adalah –1,85316 untuk data kelima -0,61772 untuk
data kesepuluh 0,61772 untuk data kelima belas 1,23544 untuk data
kedua puluh -0,61772 untuk data kedua puluh lima 0,61772 dan untuk
data ketiga puluh 1,23544 dan seterusnya untuk data lainnya.
3. Perbandingan Antara Perhitungan Manual dan Pengolahan Software
Perbandingan digunakan untuk membuktikan hasil perhitungan
menggunakan perhitungan manual dengna menggunakan pengolahan
software terdapat perbedaan yang signifikan atau tidak.
a. Data Pria
Nilai rentang pada data pria adalah 5 sama dengan pada pengolahan
software yang merupakan pengurangan dari nilai terbesar pada data
pria dikurang dengan nilai terkecil dari data pria. Banyak kelas pada
data pria adalah 4,88 yang dibulatkan menjadi 5 sama dengan pada
pengolahan software merupakan nilai dari 1 ditambah 3,3 log banyak
data pria. Interval kelas pada data pria ialah 1 merupakan pembagian
dari rentang dengan banyak kelas yang berarti perhitungan yang
digunakan adalah data tunggal karena interval kelasnya 1. Kuartil
pertama pada data data pria adalah data keempat yakni 49 dan kuartil
ketiga pada data pria adalah data kedua belas yakni 52. Rentang antar
kuartil pada data pria adalah 3 sama dengan pengolahan software yang
merupakan pengurangan dari kuartil ketiga dengan kuartil pertama.

IV-66
Rentang semi antar kuartil pada data pria adalah 1,5 yang merupakan
setengah dari rentang antar kuartil. Rata-rata pada data pria adalah 50
sama dengan pengolahan software merupakan keseluruhan nilai
jumlah data pria dibagi dengan banyaknya data pria. Simpangan rata-
rata pada data pria adalah 1,4285 merupakan keseluruhan jumlah nilai
mutlak dari pengurangan setiap data pria dengan nilai rata-rata yang
dibagi dengan jumlah data dikurangi satu. Varians pada data pria
adalah 3 sama dengan pengolahan menggunakan software yang
merupakan penjumlahan dari setiap data pria dikurangi dengan nilai
rata-rata yang dikuadratkan kemudian dibagi jumlah data pada pria
dikurang 1. Simpangan baku pada data pria adalah 1,73205 berbeda
dengan pengolahan software yaitu 1,732 yang berbeda pembulatan
angka dibelakang koma dan merupakan akar dari nilai varians.
Koefisiensi variansi ada data pria adalah 3,46% sama dengan
pengolahan software merupakan nilai dari simpangan baku dibagi
dengan rata-rata dikali 100%.
b. Data Wanita
Nilai rentang pada data wanita adalah 5 sama dengan pengolahan
software yang merupakan pengurangan dari nilai terbesar pada data
wanita dikurang dengan nilai terkecil dari data wanita.Banyak kelas
pada data wanita adalah 4,88 yang dibulatkan menjadi 5 sama dengan
pengolahan software merupakan nilai dari 1 ditambah 3,3 log banyak
data wanita. Interval kelas pada data wanita ialah 1 merupakan
pembagian dari rentang dengan banyak kelas yang berarti
perhitungan yang digunakan adalah data tunggal karena interval
kelasnya 1. Kuartil pertama pada data data wanita adalah data

IV-67
keempat yakni 49 dan kuartil ketiga pada data wanita adalah data
kedua belas yakni 51. Rentang antar kuartil pada data wanita adalah 2
sama dengan pengolahan yang merupakan pengurangan dari kuartil
ketiga dengan kuartil pertama. Rata-rata pada data wanita adalah 50
sama dengan pengolahan software merupakan keseluruhan nilai
jumlah data wanita dibagi dengan banyaknya data wanita.
Simpangan rata-rata pada data wanita adalah 1,285 merupakan
keseluruhan jumlah nilai mutlak dari pengurangan setiap data wanita
dengan nilai rata-rata yang dibagi dengan jumlah data dikurangi satu.
Varians pada data wanita adalah 2,429 sama dengan pengolahan
software merupakan penjumlahan dari setiap data wanita
dikurangi dengan nilai rata-rata yang dikuadratkan kemudian dibagi
jumlah data pada wanita dikurang 1.Simpangan baku pada data
wanita adalah 1,5585 berbeda dengan pengolahan software 1,558 yang
berbeda adalah pembulatan angka dibelakang koma merupakan akar
dari nilai varians. Koefisiensi variansi pada data wanita adalah 3,12%
sama dengan pengolahan software merupakan nilai dari simpangan
baku dibagi dengan rata-rata dikali 100%.
c. Nilai Z-score
Nlai z-score untuk data pertama adalah –1,85316 sama dengan
pengolahan menggunakan software. Nilai z-score untuk data kelima
adalah -0,61772 sama dengan pengolahan menggunakan sofware. Nilai
z-score untuk data kelima belas adalah 1,23544 sama dengan
pengolahan menggunakan software. Nilai z-score untuk data kedua
puluh lima adalah 0,61772 sama dengan pengolahan menggunakan
IV-68
software. Nilai z-score untuk data ketiga puluh adalah 1,23544 sama
dengan pengolahan menggunakan software.
4.4. Studi Kasus Modul Probabilitas
Seorang mahasiswa ingin belajar menjahit untuk memasang kancing
pada kemeja, dengan berbagai warna kancing yang berbeda. Mahasiswa
tersebut membeli kancing disebuah pasar dengan jumlah 52 buah kancing,
kancing tersebut yang akan dijahit pada kemeja, dengan 4 warna, yaitu:
1. Kancing kemeja berwarna merah (berbentuk bulat lempeng).
2. Kancing kemeja bewarna kuning (berbentuk bulat lempeng).
3. Kancing kemeja bewarna putih (berbentuk bulat lempeng).
4. Kancing kemeja bewarna biru (berbentuk bulat lempeng).
Pengambilan 4 buah kancing tersebut lalu dicarilah perhitungannya
dengan pengembalian, perhitungan terdapat pada tabel dibawah ini:
Tabel 4.11. DataSimulasi Probabilitas
X 2
Merah
2
Kuning
2
Putih
2 Merah
dan
2 Putih
2 Merah
dan
2 Kuning
2 Kuning
dan
2 Putih
1 0 1 1 0 0 1
2 0 1 0 0 0 0
3 0 0 0 0 0 0
4 0 0 1 1 0 0
5 0 0 0 0 1 0
6 0 0 0 0 1 0
7 0 0 0 1 0 0
8 0 0 0 0 0 0

IV-69
Tabel 4.11. DataSimulasi Probabilitas (Lanjutan)
X 2
Merah
2
Kuning
2
Putih
2 Merah
dan
2 Putih
2 Merah
dan
2 Kuning
2 Kuning
dan
2 Putih
9 1 1 0 1 0 1
10 0 0 1 0 1 0
11 1 0 0 0 0 0
12 0 1 0 0 0 0
13 0 0 0 0 0 0
14 0 0 0 1 0 0
15 0 1 0 0 0 0
16 0 0 0 1 0 1
17 0 0 1 1 1 1
18 0 0 1 0 1 1
19 0 0 0 0 0 0
20 0 0 0 0 0 0
21 0 0 0 0 0 0
22 0 1 1 1 0 0
23 0 1 0 1 1 0
24 1 0 0 0 1 1
25 0 0 1 0 0 1
26 0 0 0 0 0 0
27 0 1 1 0 0 0
28 1 0 0 0 0 0
29 0 0 0 1 1 0
30 1 0 1 1 0 0

IV-70
Diketahui : 0 = Gagal 1 = Sukses.
Pengambilan data diatas dilakukan sesuai dengan judul percobaan
dengan data dikembalian. Setelah melakukan simulasi data diatas dan
sesuaikan dengan menggunakan tabel, langkah berikutnya adalah sebagai
berikut:
1. Tentukan frekuensi harapan ?
2. Tentukan frekuensi nisbi ?
3. Soal-soal probabilitas ?
4.4.1 Perhitungan Manual Modul Probabilitas
Bedasarkan data yang telah diobservasi dan dicantumkan dalam tabel,
maka di bawah ini adalah hasil dari pengolahan data dengan menggunakan
perhitungan manual.
1. Frekuensi Harapan
Frekuensi harapan adalah peluang terambilnya sebuah kancing dalam
pengambilan acak. Pengambilan acak dengan dikembalikan kembali
ketempat pengambilan. Hasilnya adalah sebagai berikut:
a. 2 Kancing Merah
n(A) = 2
n(B) = 13
n(total) = 30
2 merah = )()()( totaln
BnAn
= 30132
= 4,6154

IV-71
b. 2 Kancing Kuning
n(A) = 2
n(B) = 13
n(total) = 30
2 kuning = )()()( totaln
BnAn
= 30132
= 4,6154
c. 2 Kancing Putih
n(A) = 2
n(B) = 13
n(total) = 30
2 putih = )()()( totaln
BnAn
= 30132
= 4,6154
d. 2 Kancing Merah dan Kancing Putih
2 merah
n(A) = 2
n(B) = 13
n(total) = 30
2 putih
n(A) = 2
n(B) = 13
n(total) = 30

IV-72
2 merah & putih = )()()(
)()( totaln
BnAn
BnAn
= 30132
132
= 9,2293
e. 2 Kancing Merah dan 2 Kancing Kuning
2 merah
n(A) = 2
n(B) = 13
n(total) = 30
2 kuning
n(A) = 2
n(B) = 13
n(total) = 30
2 merah & kuning = )()()(
)()( totaln
BnAn
BnAn
= 30132
132
= 9,2293
f. 2 Kancing Kuning dan 2 Kancing Putih
2 kuning
n(A) = 2
n(B) = 13
n(total) = 30
2 putih
n(A) = 2
n(B) = 13

IV-73
n(total) = 30
2 kuning & putih = )()()(
)()( totaln
BnAn
BnAn
= 30132
132
=9,2293
2. Frekuensi Nisbi
Frekuensi nisbi adalah keberhasilan mengambilnya kancing dalam
pengambilan acak suatu percobaan, dengan keberhasilannya menggunakan
data persen. Hasilnya adalah sebagai berikut:
a. 2 Kancing Merah
0 = 25
1 = 5
2 merah = %100)(
)(
totalnberhasiln
= %100305
= 16,66%
b. 2 Kancing Kuning
0 = 22
1 = 8
2 kuning = %100)(
)(
totalnberhasiln
= %100308
= 26,66%

IV-74
c. 2 Kancing Putih
0 = 21
1 = 9
2 putih = %100)(
)(
totalnberhasiln
= %100309
= 30%
d. 2 Kancing Merah dan Kancing Putih
0 = 20
1 = 10
2 merah & putih = %100)(
)(
totalnberhasiln
= %1003010
= 33,33%
e. 2 Kancing Merah dan 2 Kancing Kuning
0 = 22
1 = 8
2 merah & kuning = %100)(
)(
totalnberhasiln
= %100308
= 26,66%
g. 2 Kancing Kuning dan 2 Kancing Putih
0 = 23
1 = 7

IV-75
2 kuning & putih = %100)(
)(
totalnberhasiln
= %100307
= 23,33%
3. Soal Probabilitas
a. Berapa banyak susunan huruf yang dapat dibentuk dari kata KEIKO
HANA ?
Jawab
Soal tersebut di atas penyusunan elemen dengan unsur yang sama
dimana jumlah unsur : 9. Unsur yang sama (k) : 2, (A) :4
jumlah susunan yang terjadi:
560.7!4!.2
!9!!.
!
p
p
AKnp
Analisis:
Dari hasil percobaan tersebut diatas telah dihitung dengan
perhitungan manual yang didapat adalah apabila terdapat unsur yang
sama pada kata KIEKO HANA maka dapat hitung dengan
menngunakan permutasi sederhana sehingga susunan kata yang
dapat dibentuk dari kata KIEKO HANA sebanyak 7,560.
Kesimpulan:
Dari hasil percobaan yang telah dihitung dengan menggunaka
perhitungan manual bahwa dapat disimpulkan bahwa, apabila

IV-76
terdapat jenis percobaan diatas dapat diselesaikan dengan cara
permutasi sederhana
b. Didalam suatu ruangan terdapat 9 orang siswa kelas 3 smp mereka
ingin duduk mengitari meja bundar, ada beberapa cara yang
dipermutasikan jika mereka ingin duduk mengitari meja tersebut.
Jawab
Jumlah susunan yang berbeda sesuai permutasi siklik diketahui (n-1!)
n=(9-1!) =8!
=40320.
Analisis:
Percobaan tersebut diatas merupakan jenis soal yang dapat dihitung
menggunakan permutasi Siklis dimana jumlah seluruh elemen yaitu 9.
dengan menggunakan rumus permutasi siklik dapat diperoleh hasil
dengan cara (9-1)! Yang hasilnya adalah 40320. hasil dari perhitungan
tersebut merupakan banyak cara untuk menduduki kursi yang
bermeja bundar.
Kesimpulan:
Probabilitas terdapat sub bab permutasi siklik apabila terdapat soal
seprti diatas maka dapat selesaikan menggunakan rumus permutasi
siklik.
c. 3 dari 9 siswa yang akan mengikuti olimpiade olah raga dalam bidang
karate di gor pajajaran kota Bogor,bila salah satu siswa yang terpilih
adalah keanz, hitunglah probabilitas keanz yang terpilih dari 3 siswa ?
Jawab
Banyaknya siswa yang terpilih dari 322560)!39(!3
!993
c

IV-77
Analisis:
Terdapat 3 dari 9 siswa yang akan mengikuti olimpiade olahraga.
Untuk mengetahui probabilitas terpilihnya siswa bernama Keanz.
Dapat menggunakan kombinasi, dipilih kombinasi karena untuk
mencari banyaknya siswa terpilih tidak diperlukan untuk
memperhatikan urutan oleh karena itu 3 dari 9 siswa probabilitas
Keanz terpilih sebanyak 322560.
Kesimpulan:
Soal tersebut diatas disellesaikan dengan menggunakan kombinasi
karena tipe soal tersebut tidak diperhatikan urutannya.
d. Terdapat 5 orang dari kalangan kumpulan remaja disebuah karang
taruna. Mereka sedang mengadakan pertemuan untuk membahas
dana untuk bakti sosial tingkat RW. Apabila mereka semua ingin
berjabat tangan untuk mempererat silah turahmi antara mereka.
Berapa banyak jabat tangan yang terjadi pada saat itu ?
jawab
20256
12025
)!25(!525
P
P
P
Analisis:
Terdapat 5 orang dari kalangan remaja. Kelima orang tersebut
memiliki sepasang tangan yang akan digunakan untuk bersalaman
dengan remaja yang lain. Dan cara yang didapat dari banyaknya
berjabat tagan dari 5 orang tersebut sebanyak 20 kali.

IV-78
Kesimpulan:
Soal tersebut diatas menggunakan permutasi dikarenakan dalam
melakukan jabat tangan antar remaja karang taruna tersebut sangat
diperhatikan urutannya.
e. Berapa banyak cara untuk menyusun angka 5555 apabila terdapat
angka yang berulang dan hitung juga cara yang dengan angka yang
tidak ber ulang ?
Jawab
Angka berulang = 5.5.5.5 = 625
Angka tidak berulang = 5.4.3.2 = 120
Analisa:
Terdapat 4 susunan angka yang akan disusun secara berulang dan
telah didapat hasilnya sebanyak 625 cara. Sedangkan angka yang tidak
berulang didapat hasilnya 120 cara.
Kesimpulan:
Soal tersebut diatas merupakan jenis dari contoh soal permutasi.
Dikarenakan urutan penyusunannya sangat diperhatikan.
4.4.2 Analisis Modul Probabilitas
Berdasarkan percoaan perhitungan manual yang telah di uji cobakan
pada sebuah kancing, maka mendapatkan hasil sebagai berikut:
Frekuensi harapan untuk 2 kancing merah adalah 4,6153, begitu juga
dengan 2 kancing kuning adalah 4,6153 selanjutnya untuk 2 kancing putih
adalah 4,6153, Sedangkan untuk 2 kancing yang berbeda yaitu 2 kancing
merah dan 2 kancing putih adalah 9,2293 begitu juga sama dengan 2 kancing
IV-79
merah dan 2 kancing kuning menghasilkan hasil yang serupa yaitu 9,2293
begitu juga sama dengan 2 kancing kuning dan 2 kancing putih yaitu 9,2293.
Frekuensi harapan 2 kancing merah, 2 kancing kuning, dan 2 kancing
putih sama karena mencari banyaknya kejadian adalah 2 dan ruang
sampelnya adalah 13.
Berarti pada jenis kancing tersebut hanya mencari 2 warna saja dan
jumlah seluruh jenis warnanya adalah 13, lalu dikalikan dengan banyaknya
percobaan.
Contoh : merah.
: Jumlah seluruh jenis warna merah ada 13.
Tetapi yang dicari hanya 2 buah saja.
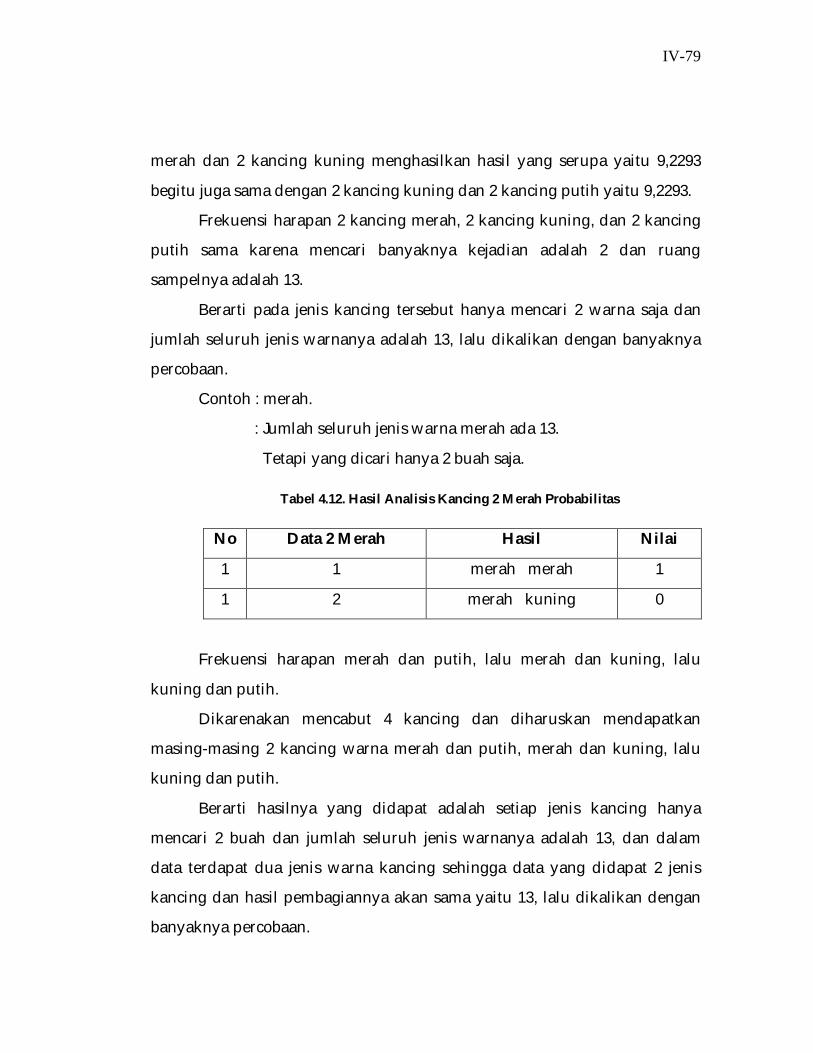
Tabel 4.12. Hasil Analisis Kancing 2 Merah Probabilitas
No Data 2 Merah Hasil Nilai
1 1 merah merah 1
1 2 merah kuning 0
Frekuensi harapan merah dan putih, lalu merah dan kuning, lalu
kuning dan putih.
Dikarenakan mencabut 4 kancing dan diharuskan mendapatkan
masing-masing 2 kancing warna merah dan putih, merah dan kuning, lalu
kuning dan putih.
Berarti hasilnya yang didapat adalah setiap jenis kancing hanya
mencari 2 buah dan jumlah seluruh jenis warnanya adalah 13, dan dalam
data terdapat dua jenis warna kancing sehingga data yang didapat 2 jenis
kancing dan hasil pembagiannya akan sama yaitu 13, lalu dikalikan dengan
banyaknya percobaan.

IV-80
Contoh : merah.
: jumlah seluruh jenis merah ada 13.
: Tetapi yang dicari hanya 2 buah saja.
: putih.
: jumlah seluruh jenis putih ada 13.
: Tetapi yang dicari hanya 2 buah saja.
: sehingga totalnya ada 4 kancing yang didapat. Tabel 4.13. Hasil Analisis Kancing 2 Merah dan Putih Probabilitas
No Data 2 Merah dan Putih Hasil Nilai
1 1 merah merah putih putih 1
1 2 merah putih putih putih 0
Frekuensi nisbi data 2 merah yaitu 16,66%.
Frekuensi nisbi data 2 kuning yaitu 26,66%.
Frekuensi nisbi data 2 putih yaitu 30%.
Frekuensi nisbi data 2 merah dan putih yaitu 33,33%.
Frekuensi nisbi data 2 merah dan kuning yaitu26,66%.
Frekuensi nisbi data 2 kuning dan putih yaitu 23,33%.
Frekuensi nisbi hasilnya yaitu menggunakan keberhasilan
mendapatkan hasil yang diinginkan yaitu angka 1, dan hasil berhasilnya
akan dibagi dengan total semua data, lalu dikalikan dengan 100%.
4.5. Studi Kasus Modul Distribusi Hipergeometrik
Seorang anak ingin pergi ke pasar bersama teman-tamannya untuk
membeli kaos bola, lalu dia meminta uang kepada ibunya. Anak tersebut
mencari kaos bola dengan warna-warna yang berbeda. Lalu mereka pergi ke
sebuah toko yang memiliki kaos bola dengan berbagai macam warna.

IV-81
Didalam toko tersebut terdapat 90 kaos bola dengan 3 warna yang berbeda
yaitu merah 30 buah, hitam 30 buah, dan biru 30 buah. Anak tersebut ingin
mengambil 6 kaos bola berwarna biru tanpa pengembalian. Seperti contoh
pada tabel dibawah ini:
Tabel 4.14. Data Simulasi Distribusi Hipergeometrik
No X Turus Frekuensi
1 0 - 0
2 1 IIII 4
3 2 IIIII 5
4 3 IIII 4
5 4 II 2
6 5 - 0
7 6 - 0
Jml 15
Ternyata mendapatkan baju bewarna biru 6 buah sangatlah susah.
Sehingga apa yang terjadi apabila:
a. Berapakan peluang kalau kurang dari 4 kaos bola biru yang didapatkan
anak tersebut ? (x < 4)
b. Apakah yang terjadi kalau lebih dari 4 kaos bola biru yang didapatkan
anak tersebut ? (x > 4)
c. Berapakan peluang apabila paling banyak 4 kaos bola biru yang
didapatkan anak tersebut ? (x ≤ 4)
d. Apakah yang terjadi apabila minimal 4 kaos bola biru yang didapatkan
anak tersebut ? (x ≥ 4)

IV-82
e. Berapakah peluang antara 1 sampai 5 kaos bola biru yang didapatkan
anak tersebut ? (1 < x < 5)
f. Berapakah peluang 1 sampai 5 kaos bola biru yang didapatkan anak
tersebut ? (1 ≤ x ≤ 5)
4.5.1 Perhitungan Manual Modul Distribusi Hipergeometrik
Bedasarkan data yang telah diobservasi dan dicantumkan dalam tabel,
maka dibawah ini adalah hasil dari pengolahan data dengan menggunakan
perhitungan manual, adapun langkahnya sebagai berikut:
Nn
kNxn
kx
CCC
knNxp),,;(
N = 90
n = 6
K = 30 ( Biru )
906
309006
300)30,6,90;0(
CCCp
→ 90
6
606
300)30,6,90;0(C
CCp
= 0,08041
906
309016
301)30,6,90;1(
CCCp
→ 90
6
605
301)30,6,90;1(C
CCp
= 0,26316
906
309026
302)30,6,90;2(
CCCp
→ 90
6
604
302)30,6,90;2(C
CCp
= 0,34069
906
309036
303)30,6,90;3(
CCCp
→ 90
6
603
303)30,6,90;3(C
CCp
= 0,22314

IV-83
906
309046
304)30,6,90;4(
CCCp
→ 90
6
602
304)30,6,90;4(C
CCp
= 0,07791
906
309056
305)30,6,90;5(
CCCp
→ 90
6
601
305)30,6,90;5(C
CCp
= 0,01373
906
309066
306)30,6,90;6(
CCCp
→ 90
6
600
306)30,6,90;6(C
CCp
= 0,000954
Tabel 4.15. Hasil Perhitungan Manual Distribusi Hipergeometrik
No X P (x;N,n,k)
1 0 0,08041
2 1 0,26316
3 2 0,34069
4 3 0,22314
5 4 0,07791
6 5 0,01373
7 6 0,000954
a. Peluang Kurang dari 4 Kaos Bola Biru
x < 4
P (x < 4) = [P(0) + P (1) + P (2) + P (3)]
= (0,08041 + 0,26316 + 0,34069 + 0,22314)
= 0,90740

IV-84
b. Peluang Lebih dari 4 Kaos Bola Biru
x > 4
P (x > 4) = [ 1 – (P ( x ≤ 4 ))]
= [ 1 – (P(0) + P (1) + P (2) + P (3) + P (4))]
= [ 1 – (0,08041 + 0,26316 + 0,34069 + 0,22314 + 0,07791)]
= [ 1 – (0,98531)]
= 0,01469
c. Peluang Paling Banyak 4 Kaos Bola Biru
x ≤ 4
P (x ≤ 4) = [ P(0) + P (1) + P (2) + P (3) + P(4)]
= (0,08041 + 0,26316 + 0,34069 + 0,22314 + 0,07791)
= 0,98531
d. Peluang Minimal 4 Kaos Bola Biru
x ≥ 4
P (x ≥ 4) = [ 1 – (P ( x < 4 ))]
= [ 1 – (P(0) + P (1) + P (2) + P(3))]
= [ 1 – (0,08041 + 0,26316 + 0,34069 + 0,22314)]
= [ 1 – (0,9074)]
= 0,09260
e. Peluang Antara 1 sampai 5 Kaos Bola Biru
1 < x < 5
P (1 < x < 5) = [ P(2) + P (3) + P (4)]
= (0,34069 + 0,22314 + 0,07791)
= 0,64174
f. Peluang 1 sampai 5 Kaos Bola Biru
1 ≤ x ≤ 5
P (1 ≤ x ≤ 5) = [ P(1) + P (2) + P (3) + P (4) + P (5)]

IV-85
= (0,26316 + 0,34069 + 0,22314 + 0,07791 + 0,01373)
= 0,91863
4.5.2 Pengolahan Software Modul Distribusi Hipergeometrik
Minitab adalah suatu program software yang bertujuan untuk
menghitung data statistika dengan semestinya. Langkah pertama untuk
membuat data ukuran penyebaran adalah menggunakan program minitab
yang telah menginstallnya, setelah itu lalu mencarinya di program, dengan
cara klik menu start lalu klik all program setelah itu carilah minitab.
Setelah memasuki minitab maka akan terdapat tampilan seperti
dibawah ini, pada tampilan terdapat dua kolom data yaitu session dan
worksheet 1 ***. Workshett 1 *** adalah tempat memasukkan data-data yang
diinput dalam program. Session adalah hasil output data yang telah masukkan
kedalamnya dalam kolom worksheet 1 ***, setelah masuk lalu masukkan data
di dalam worksheet 1 ***.
Gambar 4.45 Tampilan Awal MiniTab 14
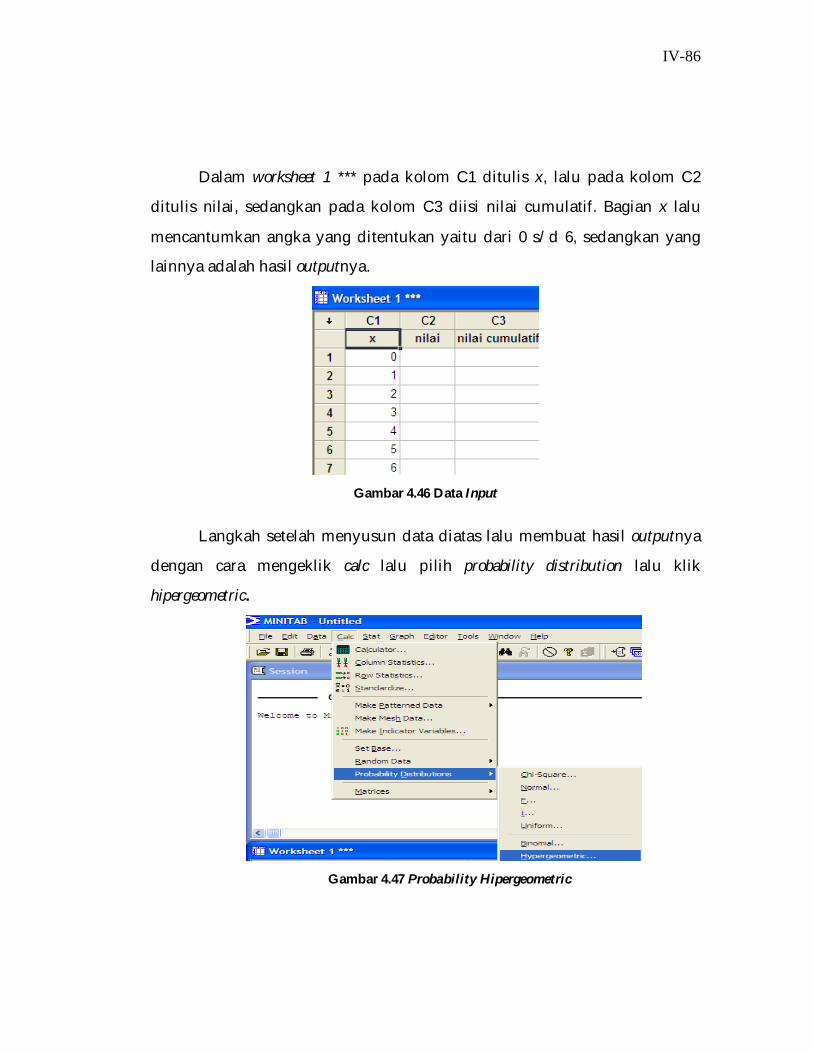
IV-86
Dalam worksheet 1 *** pada kolom C1 ditulis x, lalu pada kolom C2
ditulis nilai, sedangkan pada kolom C3 diisi nilai cumulatif. Bagian x lalu
mencantumkan angka yang ditentukan yaitu dari 0 s/d 6, sedangkan yang
lainnya adalah hasil outputnya.
Gambar 4.46 Data Input
Langkah setelah menyusun data diatas lalu membuat hasil outputnya
dengan cara mengeklik calc lalu pilih probability distribution lalu klik
hipergeometric.
Gambar 4.47 Probability Hipergeometric

IV-87
Langkah selanjutnya mengeklik maka akan terdapat tabel seperti
gambar berikut, dalam tabel tersebut terdapat beberapa kolom. Caranya
adalah memilih probability lalu mengekliknya. Berikutnya itu dalam
Population size (N) menulis angka 90, menunjukkan banyaknya data atau
element. Successes in population (M) menulis angka 30, menunjukkan jumlah
sukses dalam N. Sample size (n) ditulis angka 6, menunjukkan jumlah data
pengambilan. Berikutnya setelah itu pada input column masukkan C1 x, lalu
pada C2 nilai pindahkan kedalam kolom optional storage, lalu pilih ok maka
akan terdapat hasil outputnya.
Gambar 4.48 Kolom Hipergeometric Distribution
X adalah banyaknya keberhasilan dalam perubahan acak x, yaitu dari
x = 0 sampai x = 6.
nilai adalah distribusi hipergeometricnya yaitu perubahan acak x yang
menyatakan banyaknya keberhasilan dalam contoh acak ukuran n, dengan x
= 0 hasilnya 0,080409 dan x = 6 hasilnya 0,000945.

IV-88
Hasil outputnya dari data yang telah melalui proses pemograman
adalah seperti gambar dibawah ini:
Gambar 4.49 Hasil Output Probability Hipergeometric
Cara untuk mendapatkan cumulative distribusi hipergeometricnya
atau cumulative probability adalah sebagai berikut, yaitu sama dengan cara
probability yaitu dengan cara mengeklik calc lalu pilih probability distribution
lalu klik hipergeometric. Berikutnya lalu yang dipilih adalah cumulative
probability, sedangkan pada optional storage diisi C3 nilai cumulative, lalu pilih
ok maka akan terdapat hasil outputnya.
Gambar 4.50 Kolom Hipergeometrik Distribution

IV-89
Hasil outputnya dari data yang telah melalui proses pemograman
adalah seperti gambar dibawah ini:
Gambar 4.51 Hasil Output Nilai Cumulatif
4.5.3 Analisis Modul Distribusi Hipergeometrik
Modul yang kelima adalah distribusi hipergeometik, dan penyusun
akan menganalisis menjadi tiga bagian. Pertama untuk analisis pada
perhitungan manualnya, kedua menganalisis pengolahan software kemudian
yang terakhir membandingkan hasil kedua perhitungan tersebut. Adapun
analisis yang telah dibuat sebagai berikut:
1. Perhitungan Manual
Mencari peluang terambilnya kaos bola sebanyak 0 sampai dengan 6,
untuk peluang terambilnya kaos bola biru sebanyak 0 adalah 0,08041,
peluang terambilnya kaos bola biru sebanyak 1 adalah 0,26316, peluang
terambilnya kaos bola biru sebanyak 2 adalah 0,34069, peluang terambilnya
kaos bola biru sebanyak 3 adalah 0,22314, peluang terambilnya kaos bola biru
sebanyak 4 adalah 0,07791, peluang terambilnya kaos bola biru sebanyak 5
adalah 0,01373, dan yang terakhir untuk peluang terambilnya kaos bola biru
sebanyak 6 adalah 0,000954.

IV-90
Peluang kaos bola biru yang terambil kurang dari 4 adalah hasil
penjumlahan dari peluang terambilnya kaos bola biru sebanyak 0 ditambah
sampai dengan peluang terambilnya kaos bola biru sebanyak 3, dengan hasil
0,90740. Berikutnya peluang terambilnya kaos bola lebih dari 4 yang
berwarna biru adalah hasil pengurangan 1 dikurang penjumlahan peluang 0
ditambah sampai dengan peluang terambilnya 4, dengan hasil 0,01469.
Peluang kaos bola dengan warna biru yang diambil paling banyak 4
adalah hasil penjumlahan peluang 0 ditambah sampai dengan peluang 4,
dengan hasil 0,98531. Berikutnya untuk peluang terambilnya kaos bola biru
yang diambil paling sedikit 4 adalah hasil pengurangan 1 dikurang hasil
penjumlahan antara peluang 0 ditambah sampai dengan peluang 3, dengan
hasil 0,09260.
Peluang terambilnya baju kaos bola antara 1 sampai 5 adalah hasil
penjumlahan antara peluang 2 ditambah sampai dengan peluang 4, dengan
hasil 0,64174. Berikutnya untuk peluang terambilnya kaos bola biru sebanyak
1 sampai 5 adalah hasil penjumlahan peluang 1 ditambah sampai dengan
peluang 5, dengan hasil 0,91863.
2. Pengolahan Software
Hasil output untuk pengolahan software pada distribusi hipergeometrik
adalah seperti gambar 4.60, yang terdapat hasil nilai dan nila kumulatifnya.
Banyaknya jumlah kaos bola yang diambil dilambangkan dengan huruf X
yaitu, 0 sampai dengan 6. Nilai yang terdapat pada tabel diatas adalah
peluang terambilnya kaos bola yang berwarna biru, untuk jumlah kaos bola
sebanyak 0 hasilnya adalah 0,080409, untuk jumlah kaos bola sebanyak 1
hasilnya adalah 0,263157, dan seterusnya. Berikutnya untuk nilai kumulatif
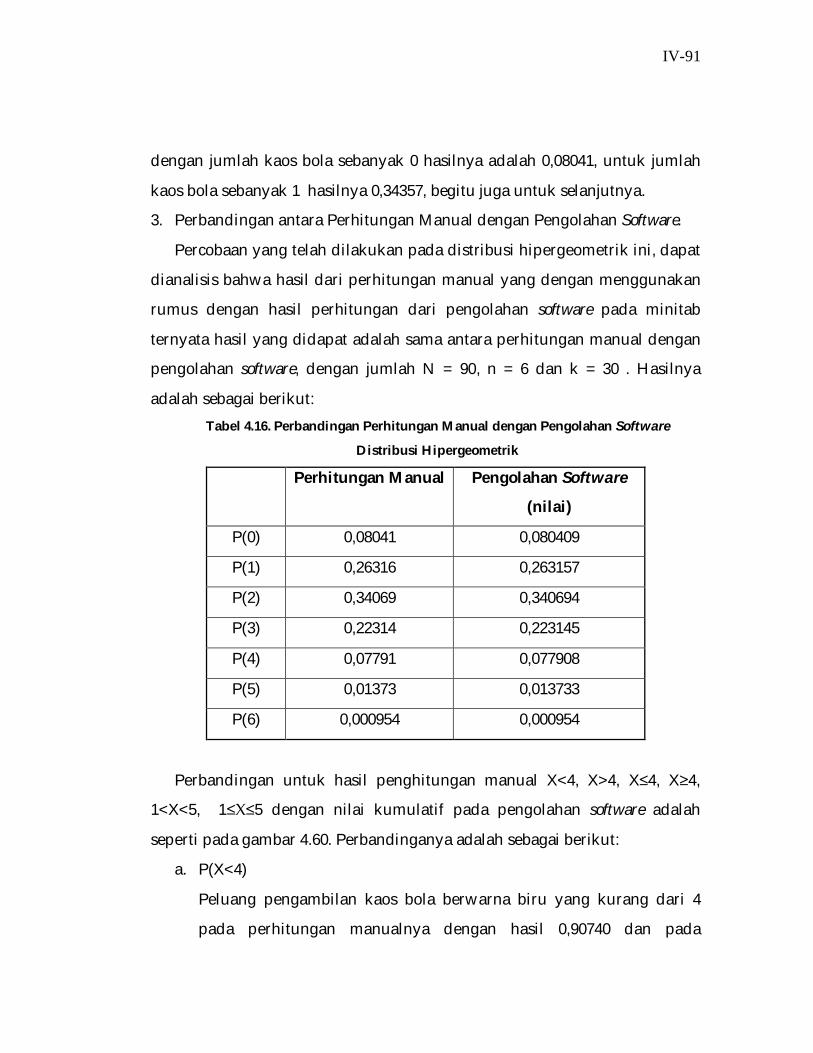
IV-91
dengan jumlah kaos bola sebanyak 0 hasilnya adalah 0,08041, untuk jumlah
kaos bola sebanyak 1 hasilnya 0,34357, begitu juga untuk selanjutnya.
3. Perbandingan antara Perhitungan Manual dengan Pengolahan Software.
Percobaan yang telah dilakukan pada distribusi hipergeometrik ini, dapat
dianalisis bahwa hasil dari perhitungan manual yang dengan menggunakan
rumus dengan hasil perhitungan dari pengolahan software pada minitab
ternyata hasil yang didapat adalah sama antara perhitungan manual dengan
pengolahan software, dengan jumlah N = 90, n = 6 dan k = 30 . Hasilnya
adalah sebagai berikut: Tabel 4.16. Perbandingan Perhitungan Manual dengan Pengolahan Software
Distribusi Hipergeometrik
Perhitungan Manual Pengolahan Software
(nilai)
P(0) 0,08041 0,080409
P(1) 0,26316 0,263157
P(2) 0,34069 0,340694
P(3) 0,22314 0,223145
P(4) 0,07791 0,077908
P(5) 0,01373 0,013733
P(6) 0,000954 0,000954
Perbandingan untuk hasil penghitungan manual X<4, X>4, X≤4, X≥4,
1<X<5, 1≤X≤5 dengan nilai kumulatif pada pengolahan software adalah
seperti pada gambar 4.60. Perbandinganya adalah sebagai berikut:
a. P(X<4)
Peluang pengambilan kaos bola berwarna biru yang kurang dari 4
pada perhitungan manualnya dengan hasil 0,90740 dan pada

IV-92
pengolahan software hasilnya adalah 0,90471 yang diambil dari
banyaknya kaos bola yang dilambangkan X dengan jumlah kaos bola 3
pada kolom nilai kumulatif, jadi untuk perbandingan kedua
perhitungan peluang terambilnya kaos bola biru kurang dari 4
tersebut hanya berbeda sedikit yaitu 0,00001.
b. P(X>4)
Peluang pengambilan kaos bola berwarna biru yang lebih dari 4 pada
perhitungan manualnya dengan hasil 0,01469 dan pada pengolahan
software di kolom nilai cumulatif hasilnya adalah sebagai berikut:
1 – P(X=4) =1 – 0,98531
= 0,01469.
Maksudnya untuk menghitung peluang yang lebih besar, maka harus
1 dikurang dengan jumlah x pada nilai kumulatif. Nilai x lebih dari 4
sama dengan nilai pada kolom kelima di tabel nilai kumulatif.
c. P(X≤4)
Peluang pengambilan kaos bola berwarna biru paling banyak 4 pada
perhitungan manualnya dengan hasil 0,98531 dan pada pengolahan
software di kolom nilai cumulatif hasilnya adalah P(X=4) = 0,98531. jadi
perbandingan kedua hitungan tersebut adalah sama.
d. P(X≥4)
Peluang pengambilan kaos bola berwarna biru yang paling sedikit 4
pada perhitungan manualnya dengan hasil 0,09260 dan pada
pengolahan software di kolom nilai cumulatif hasilnya adalah sebagai
berikut:
1 – P(X=3) =1–0,90741
=0,09259.

IV-93
Maksudnya untuk menghitung peluang yang lebih besar dari, maka
harus 1 dikurang dengan jumlah x pada nilai kumulatif. Tabel nilai
kumulatif diatas, nilai x yang lebih besar dari 4 sama dengan nilai
yang keempat pada tabel nilai kumulatif tersebut.
e. P(1<X<5)
Peluang pengambilan kaos bola berwarna biru antara 1 sampai 5 pada
perhitungan manualnya dengan hasil 0,64174 dan pada pengolahan
software di kolom nilai hasilnya adalah
P(X=2)+P(X=3)+P(X=4) =0,340694 + 0,223145 + 0,077908
= 0,641747.
Maksudnya untuk menghitung peluang antara 1 sampai 5, harus
menjumlahkan nilai yang lebih besar dari 1 dan lebih kecil dari 5.
Berarti dijumlahkan nilai kedua, ketiga dan keempat, berarti pada
tabel nilai diatas menjumlahkan nilai tabel ke tiga, empat, dan kelima.
f. P(1≤X≤5)
Peluang pengambilan kaos bola berwarna biru 1 sampai 5 pada
perhitungan manualnya dengan hasil 0,91863 dan pada pengolahan
software di kolom nilai hasilnya adalah:
P(X=1)+P(X=2)+P(X=3)+P(X=4)+P(X=5)
= 0,263157+0,340694+0,223145+0,077908 + 0,013733
= 0,918637.
Maksudnya untuk menghitung peluang x lebih besar sama dengan 1
dan x lebih lebih kecil sama dengan 5, harus menjumlahkan nilai
pertama sampai dengan nilai ke lima. Berarti pada tabel nilai diatas
menjumlahkan nilai ke dua, tiga, empat, lima, dan ke enam.

IV-94
4.6. Studi Kasus Modul Distribusi Normal
Untuk mengetahui waktu yang dibutuhkan untuk membuat suatu
produk kerajinan soap flower di suatu tempat pembuatan di suatu rumah
maka dilakukan uji coba terhadap 30 orang sebagai sample dengan data
sebagai berikut dengan waktu standar 25 menit/orang: Tabel 4.17. Data Simulasi Distribusi Normal
Orang Ke- Waktu(menit) Orang Ke- Waktu(menit)
1. 23,90 16. 22,55 2. 27,48 17. 27,30 3. 23,59 18. 23,45 4. 20,46 19. 26,27 5. 25,31 20. 28,31 6. 23,49 21. 20,34 7. 27,85 22. 20,31 8. 27,41 23. 28,40 9. 21,40 24. 24,45
10. 28,49 25. 23,35 11. 21,31 26. 25,37 12. 22,52 27. 26,35 13. 27,40 28. 22,90 14. 27,30 29. 22,36 15. 28,39 30. 28,21
Dari data tersebut tentukanlah : a. Berapakah rata-rata waktu untuk membuat suatu produk dari seluruh
produk tersebut ?
b. Berapakah standar deviasi atau simpangan baku dari keseluruhan
waktu yang dibutuhkan ?
c. Apakah yang terjadi apabila waktu yang dipakai lebih dari 26 menit ?
d. Apakah yang terjadi apabila waktu yang dipakai kurang dari 23 menit ?

IV-95
e. Apakah yang terjadi apabila waktu yang dipakai antara 24 menit dan 28
menit ?
4.6.1 Perhitungan Manual Modul Distribusi Normal
Berdasarkan studi kasus dari materi distribusi normal serta tujuan
yang ingin di capai, maka berikut ini adalah perhitungan yang dilakukan
untuk menjawab tujuan yang ada.
XZ
a. Rata-rata waktu untuk membuat suatu produk dari seluruh produk
tersebut.
n
X i
30
22,746
= 24,8740
b. Standar deviasi atau simpangan baku dari keseluruhan waktu yang
dibutuhkan Tabel 4.18. Hasil Perhitungan Manual Standar Deviasi Distribusi Normal
NO Xi ( Xi – µ ) ( Xi – µ )² NO Xi ( Xi – µ ) ( Xi – µ )²
1 23,90 -0.9740 0,9487 16 22,55 -2.3240 5.4010
2 27,48 2.6060 6.7912 17 27,30 2.4260 5.8855
3 23,59 -1.2840 1.6487 18 23,45 -1.4240 2.0278
4 20,46 -4,4140 19.4843 19 26,27 1.3960 1.9488
5 25,31 0.4360 0.1901 20 28,31 3.4360 11.8061

IV-96
Tabel 4.18. Hasil Perhitungan Manual Standar Deviasi Distribusi Normal (Lanjutan)
6 23,49 -1.3840 1.9155 21 20,34 -4.5340 20.5572
7 27,85 2.9760 8.8566 22 20,31 -4.5640 20.8301
8 27,41 2.5360 6.4313 23 28,40 3.5260 12.4327
9 21,40 -3.4740 12.0687 24 24,45 -0.4240 0.1798
10 28,49 3.6160 13.0755 25 23,35 -1.5240 2.3226
11 21,31 -3.5640 12.7021 26 25,37 0.4960 0.2460
12 22,52 -2.3540 5.5413 27 26,35 1.4760 2.1786
13 27,40 2.5260 6.3807 28 22,90 -1.9740 3.8967
14 27,30 2.4260 5.8855 29 22,36 -2.5140 6.3202
15 28,39 3.5160 12.3623 30 28,21 3.3360 11.1289
Jumlah 746,22 221.4445
1)(
)(2
2
nXX
Ragam i
294445,221)( 2 Ragam
= 7,6360
Simpangan baku (σ) = 6360,7
= 2,7633
c. Waktu yang dibutuhkan lebih dari 28 menit.
P (x > 26)
Z26 = 26 – 24,8740
2,7633
= 0,40 » 0,6554
P (x > 26) = 1 – (P ( Z ≤ 0,40))

IV-97
= 1 – 0,6554 = 0,3446
d. Waktu yang dibutuhkan kurang dari 23 menit.
P (x < 23)
7633,28740,242323
Z
= - 0,68 » 0,2483
P (x < 23) = (P ( Z < -0,68))
= 0,2483
e. Waktu yang dibutuhkan antara 24 menit dan 28 menit.
P (24 < x < 28)
Z24 = 24 – 24,8740
2,7633
= -0,31 » 0,3783
Z28 = 28 – 24,8740
2,7633
= 1,13 » 0,8708
P (24 < x < 28) = P (- 0,31 < Z < 1,13)
= P (0,3783 < Z < 0,8708)
= 0,8708 – 0,3783
= 0,4925
4.6.2 Pengolahan Software Modul Distribusi Normal
Minitab adalah suatu program software yang bertujuan untuk
menghitung data statistika dengan semestinya. Langkah pertama untuk
membuat data distribusi normal adalah menggunakan program minitab yang
telah di install. Setelah itu hanya mencarinya di program, dengan cara klik
menu start lalu klik all program setelah itu carilah minitab 14.

IV-98
Setelah memasuki minitab maka akan terdapat tampilan seperti
dibawah ini, pada tampilan terdapat dua kolom data yaitu session dan
worksheet 1 ***. Workshett 1 *** adalah tempat memasukkan data-data yang
diinput dalam program. Session adalah hasil output data yang telah
dimasukkan kedalamnya dalam kolom worksheet 1 ***. Setelah masuk yang
harus dilakukan adalah masukkan data di dalam worksheet 1 ***.
Gambar 4.52 Tampilan Awal MiniTab 14
Langkah selanjutnya ketika program Minitab14 telah tampil, ketik
pada lembar kerja yang telah tersedia yaitu pada kolom C1 dengan kalimat
Orang Ke, dan C2 dengan kalimat Waktu. Selanjutnya masukkan data yang
telah di dapat dalam simulasi sebelumnya pada lembar kerja yang telah
disediakan. Tampilannya akan seperti gambar berikut ini :
IV-99
Gambar 4.53 Data Input
Setelah menyusun data diatas lalu membuat hasil outputnya dengan
cara mengeklik calc lalu pilih probability distribution lalu klik normal.
Gambar 4.54 Probability Distribusi Normal
Setelah tampil kotak dialog Normal Distribution, lakukan langkah-
langkah selanjutnya, yaitu klik Cumulative probability, isi Mean dengan angka
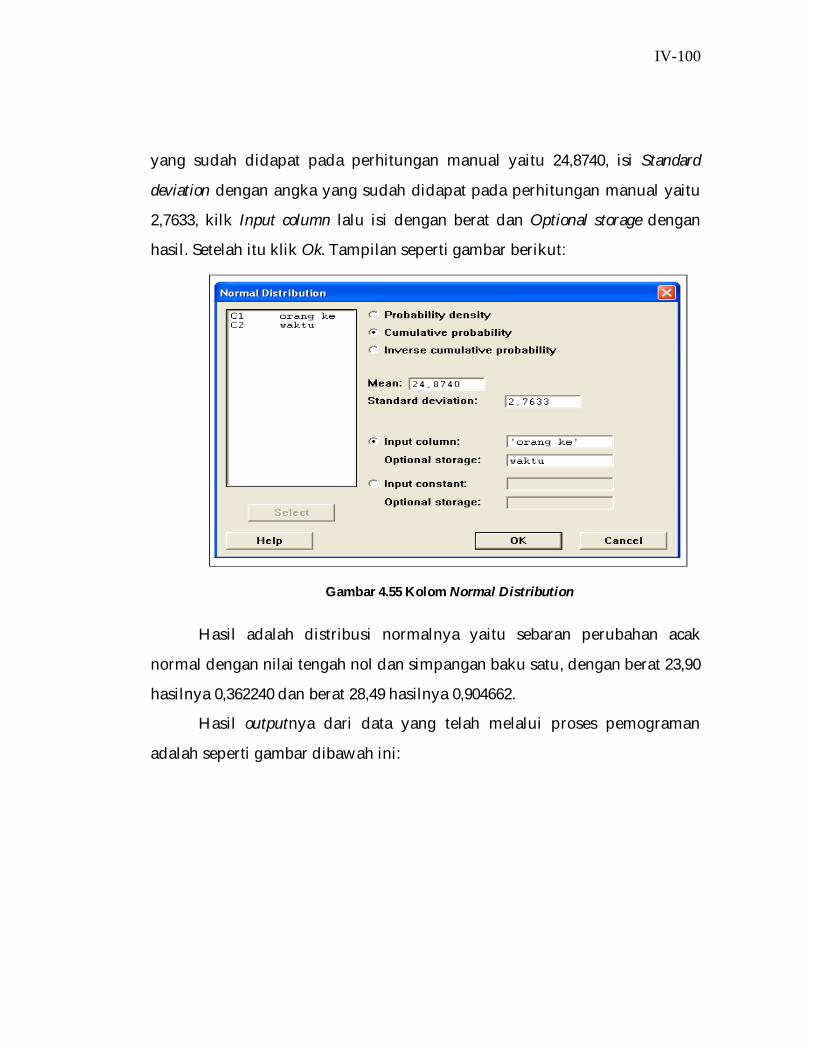
IV-100
yang sudah didapat pada perhitungan manual yaitu 24,8740, isi Standard
deviation dengan angka yang sudah didapat pada perhitungan manual yaitu
2,7633, kilk Input column lalu isi dengan berat dan Optional storage dengan
hasil. Setelah itu klik Ok. Tampilan seperti gambar berikut:
Gambar 4.55 Kolom Normal Distribution
Hasil adalah distribusi normalnya yaitu sebaran perubahan acak
normal dengan nilai tengah nol dan simpangan baku satu, dengan berat 23,90
hasilnya 0,362240 dan berat 28,49 hasilnya 0,904662.
Hasil outputnya dari data yang telah melalui proses pemograman
adalah seperti gambar dibawah ini:

IV-101
Gambar 4.56 Hasil Output Normal Cumulative
Membuat kurva distribisi normalnya yaitu dengan cara pilih graph
lalu pilih histogram setelah itu maka akan ada terdapat tabel.
Gambar 4.57 Graph Histogram
Setelah mengklik maka akan terdapat tabel seperti gambar berikut,
dalam table tersebut terdapat beberapa kolom. Yang dipilih adalah kolom
with fit. Lalu pilih ok.
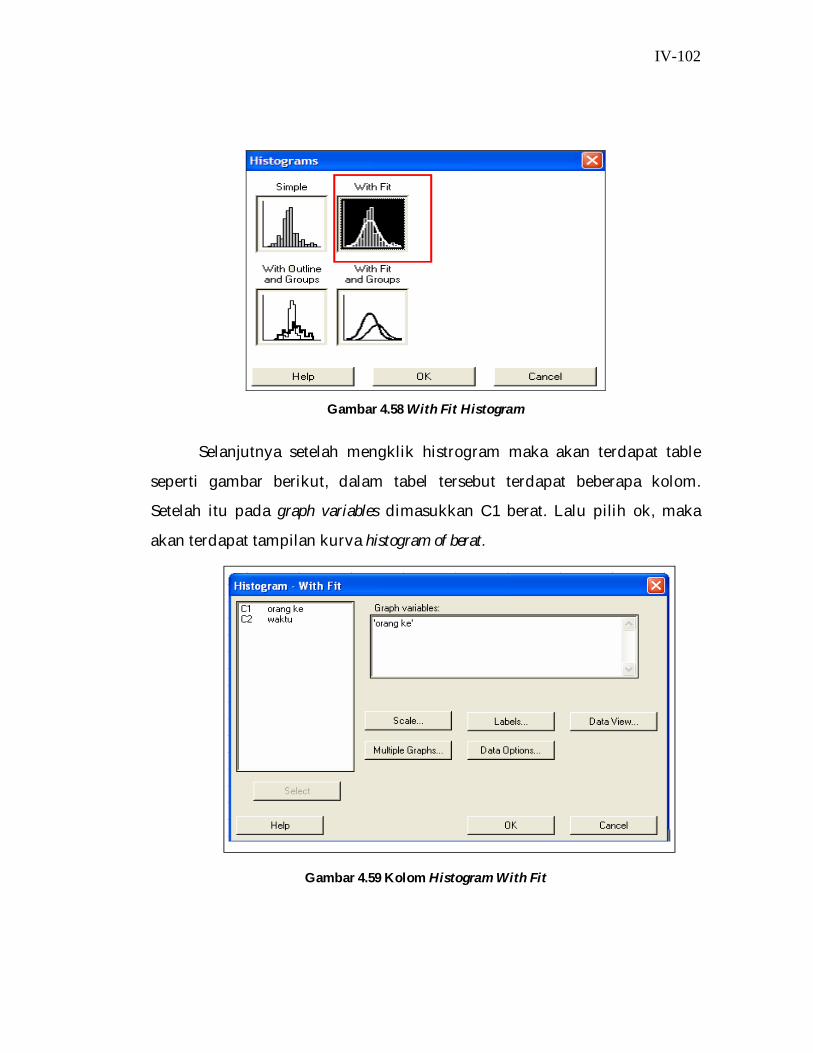
IV-102
Gambar 4.58 With Fit Histogram
Selanjutnya setelah mengklik histrogram maka akan terdapat table
seperti gambar berikut, dalam tabel tersebut terdapat beberapa kolom.
Setelah itu pada graph variables dimasukkan C1 berat. Lalu pilih ok, maka
akan terdapat tampilan kurva histogram of berat.
Gambar 4.59 Kolom Histogram With Fit

IV-103
Hasil dari kurva normal setelah memasukkan data untuk diprogram
adalah seperti gambar dibawah ini:
Gambar 4.60 Hasil Output Grafik Histogram
4.6.3 Analisis Modul Distribusi
Setelah data didapat dan berdasarkan perhitungan atau pengolahan
yang telah dilakukan baik manual dan software maka berikut ini adalah
analisis bagi perhitungan keduanya.
1. Perhitungan Manual
Perhitungan manual sebuah data harus dicari beberapa kuncinya terlebih
dahulu untuk membuat hasil distribusi normalnya. Didapat beberapa hasil
perhitungan yaitu sebagai berikut :
Mean adalah nilai rata- rata hitung atau jumlah semua data yang dibagi
rata dengan banyaknya data, dengan hasilnya adalah 24,8740. Dengan kata
lain didapat bahwa rata-rata tersebut tidak terlalu jauh dengan datanya.

IV-104
Standar deviasi adalah standar normal dalam perhitungan data rata-rata,
dari data (Xi–μ) ² dengan Xi adalah data tunggalnya dan µ adalah rata-
ratanya kemudian kedua data tersebut dibagi dengan banyaknya data yang
dikurang satu. Dengan hasilnya adalah 2,7633.
Untuk x > 26 pada perhitungan manual hasilnya adalah 0,3446. Bahwa
data x > 26 adalah data pengurangan satu. Berarti peluang mendapatkan satu
produk setiap orang dengan waktunya lebih dari 26 adalah 0,3%. Dikatakan
bahwa peluang tersebut kecil dan mendapatkan waktu tersebut sulit.
Untuk x < 23 pada perhitungan manual hasilnya adalah 0,2483. Bahwa
data x < 23 adalah data penjumlahan dari x = 0 sampai dengan x = 22. Berarti
peluang mendapatkan satu produk setiap orang dengan waktunya kurang
dari 23 adalah 0,2%. Dikatakan bahwa peluang tersebut tidak terbaca dan
mendapatkan waktu tersebut diragukan mendapatkannya.
Untuk 24 < x < 28 pada perhitungan manual hasilnya adalah 0,4925.
Bahwa data 23 < x < 28 adalah data penjumlahan antara x = 23 sampai
dengan x = 28. Berarti peluang mandapatkan satu produk setiap orang
dengan waktunya antara 23 dan 28 adalah 49,2%. Dikatakan bahwa peluang
tersebut sangat besar dan mendapatkan waktu tersebut pasti, dikarenakan
peluang tersebut tidak jauh dari 100%.
2. Pengolahan Software
Berdasarkan gambar 4.62, waktu tercepat dalam pembuatan produk soap
flower terdapat pada orang ke- 22, dimana waktu yang dicapai adalah 20,31
menit dengan rata-rata 0,049303. Waktu yang dicapai jauh lebih cepat dari
waktu standar, yaitu 25 menit. Berarti semakin cepat waktu yang dicapai,
produksi bisa semakin bisa ditingkatkan. Untuk waktu terlama terdapat pada
orang ke- 10, dimana waktu yang dicapai adalah 28,49 menit dengan rata-rata

IV-105
0,904662. waktu yang dicapai jauh lebih lambat dari waktu standar. Berarti
semakin lambat waktu yang dicapai, produksi kemungkinan sedikit
terhambat.
Berdasarkan gambar 4.66 dari grafik yang ada, garis kurva yang
melengkung merupakan kurva normal. Histogram yang berada diatas kurva
normal dianggap data invalid atau tidak berlaku. Bisa dipakai, tetapi masih
kurang baik untuk digunakan. Untuk histogram yang berada di bawah kurva
normal dianggap valid atau berlaku. Sangat baik untuk digunakan sebagai
gambaran produksi suatu barang. Kurva normal hanya mempunyai satu
jenis kurva, tidak melenceng ke kiri ataupun kanan, dan bentuknya landai,
dikenal kurva lonceng.
3. Perbandingan Antara Perhitungan Manual dan Pengolahan Software
Setelah diteliti dengan seksama, dikatakan bahwa data pengolahan
software hampir sama dengan perhitungan manual. Hal ini dikarenakan
ketidakakuratan dari perhitungannya yang menggunakan kalkulator (alat
bantu hitung) dan dikarenakan pula oleh pembulatan desimal pada
perhitungan manual yang telah disesuaikan dengan keinginan sehingga hasil
dari pembulatannya terbatas.
Untuk x > 26
Artinya adalah untuk menghitung peluang normal dalam waktu yang dicari
lebih 26 menit.
Pada perhitungan manual hasilnya adalah 0,3446.
Pada perhitungan software hasilnya adalah 1 – 0,693288 = 0,3067 pada waktu
ke- 26,27 menit.
Untuk x < 23

IV-106
Artinya adalah untuk menghitung peluang normal dalam waktu yang dicari
kurang dari 23 menit.
Pada perhitungan manual hasilnya adalah 0,2483.
Pada perhitungan software hasilnya adalah 0,237501 pada waktu ke- 22,90
menit.
Untuk 24 < X < 28
Artinya adalah untuk menghitung peluang normal dalam waktu yang dicari
antara 24 menit dan 28 menit.
Pada perhitungan manual hasilnya adalah 0,4925
Pada perhitungan software hasilnya adalah = (23,90 – 27,85)
= (0,362240 – 0,859254)
= 0,859254 – 0,362240
= 0,4970