tugas individu 2_struktur data dan algoritma ii_m0513019
TRANSCRIPT

Tugas Individu (2) SDA II
Aplikasi String Matching menggunakan algoritma Brute force, KMP (Knuth-
Morris-Pratt) dan Byore-Moore.
Sifat Tugas : Individu
Batas pengumpulan : 12 Desember 2014
Arsip pengumpulan : - CD yang berisi Report (Laporan), Source Code.
- Laporan (Hardcopy)
Bangun sebuah aplikasi untuk pencocokan string (String Matching) dengan menggunakan 3
algoritma yaitu Brute Force, KMP (Knuth-Morris-Pratt) dan Byore-Moore. Aplikasi yang dibangun
memiliki spesifikasi sbb:
• Input berupa T (Teks) dari file eksternal misal file dengan format .txt dll, selain itu juga
input P (Pattern) yakni string yang akan dicari.
• Output dari aplikasi adalah hasil status dari pencocokan string apakah berhasil atau tidak,
jika berhasil program akan menampilkan posisi/lokasi awal dari P (pattern) di T (Teks).
• Selain itu, aplikasi juga harus menampilkan hasil running time dari ketiga algoritma
tersebut.
• Aplikasi menyediakan pilihan untuk mengulangi input T (Teks) maupun P(Pattern) yang
berbeda.
• Aplikasi yang dibuat harus berbasis grafis (GUI).
Format Laporan :
Halaman Cover
Bab 1: Pendahuluan
Bab 2: Dasar teori
Bab 3: Analisis & Rancangan Aplikasi.
Bab 4: Hasil & Pembahasan. Bab ini berisi:
Bab 5: Kesimpulan dan saran (hasil yang dicapai, saran pengembangan).
Tuliskan juga referensi (buku, web, paper), yang dipakai/diacu di dalam Daftar Referensi.
Penilaian :
1. Kebenaran program (50%) : program mampu berjalan sesuai dengan requirement system
yang sudah ditentukan.
2. Laporan (35%)
3. Interface, feature-feature program, dan unsur kreativitas (15%)
Lain – lain : 1. Anda dapat menambahkan fitur fungsional lain untuk menunjang program yang anda buat
(unsur kreatifitas).
2. Program harus modular dan mengandung komentar yang jelas.
3. Mahasiswa harus membuat program sendiri, tetapi belajar dari contoh-contoh program tidak
dilarang (tidak boleh mengkopi source code dari program orang lain).
4. Pengumpulan paling lambat adalah tanggal 12 Desember 2014. Keterlambatan akan
mengurangi nilai.
5. Tugas disimpan di dalam folder TI2_NIM. Isi folder ada dua yakni laporan dan source
program Folder ini disimpan dalam bentuk CD untuk dikumpulkan bersama berkas laporan.
-selamat mengerjakan-

LAPORAN TUGAS INDIVIDU
STRUKTUR DATA DAN ALGORITMA
STRING MATCHING
DISUSUN OLEH:
FEMBI REKRISNA GRANDEA PUTRA
M0513019
JURUSAN INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SEBELAS MARET
SURAKARTA
DESEMBER 2014

BAB I
PENDAHULUAN
Algoritma pencarian string atau sering disebut juga pencocokan string adalah
algoritma untuk melakukan pencarian semua kemunculan string pendek pattern[0..n-1] yang
disebut pattern di string yang lebih panjang teks[0..m-1] yang disebut teks.
Pencocokkan string merupakan permasalahan paling sederhana dari semua
permasalahan string lainnya, dan dianggap sebagai bagian dari pemrosesan data,
pengkompresian data, analisis leksikal, dan temu balik informasi. Teknik untuk
menyelesaikan permasalahan pencocokkan string biasanya akan menghasilkan implikas i
langsung ke aplikasi string lainnya.
Algoritma-algoritma pencocokkan string dapat diklasifikasikan menjadi tiga bagian
menurut arah pencariannya.
Tiga kategori itu adalah:
Dari arah yang paling alami, dari kiri ke kanan, yang merupakan arah untuk
membaca, algoritma yang termasuk kategori ini adalah:
1. Algoritma Brute Force
2. Algoritma dari Morris dan Pratt, yang kemudian dikembangkan oleh Knuth,
Morris, dan Pratt
Dari kanan ke kiri, arah yang biasanya menghasilkan hasil terbaik secara praktikal,
contohnya adalah:
1. Algoritma dari Boyer dan Moore, yang kemudian banyak dikembangkan,
menjadi Algoritma turbo Boyer-Moore, Algoritma tuned Boyer-Moore, dan
Algoritma Zhu-Takaoka;
Dan kategori terakhir, dari arah yang ditentukan secara spesifik oleh algoritma
tersebut, arah ini menghasilkan hasil terbaik secara teoritis, algoritma yang termasuk
kategori ini adalah:
1. Algoritma Colussi
2. Algoritma Crochemore-Perrin

BAB II
DASAR TEORI
Algoritma brute force merupakan algoritma pencocokan string yang ditulis tanpa
memikirkan peningkatan performa. Algoritma ini sangat jarang dipakai dalam praktik,
namun berguna dalam studi pembanding dan studi-studi lainnya.
Secara sistematis, langkah- langkah yang dilakukan algoritma brute force pada saat
mencocokkan string adalah:
1. Algoritma brute force mulai mencocokkan pattern pada awal teks.
2. Dari kiri ke kanan, algoritma ini akan mencocokkan karakter per karakter pattern
dengan karakter di teks yang bersesuaian, sampai salah satu kondisi berikut
dipenuhi:
1. Karakter di pattern dan di teks yang dibandingkan tidak cocok (mismatch).
2. Semua karakter di pattern cocok. Kemudian algoritma akan memberitahukan
penemuan di posisi ini.
3. Algoritma kemudian terus menggeser pattern sebesar satu ke kanan, dan mengulangi
langkah ke-2 sampai pattern berada di ujung teks.
Berikut adalah Algoritma brute force yang sedang bekerja mencari string:
Algoritma Knuth-Morris-Pratt adalah salah satu algoritma pencarian string,
dikembangkan secara terpisah oleh Donald E. Knuth pada tahun 1967 dan James H. Morris
bersama Vaughan R. Pratt pada tahun 1966, namun keduanya mempublikasikannya secara
bersamaan pada tahun 1977.

Jika kita melihat algoritma brute force lebih mendalam, kita mengetahui bahwa
dengan mengingat beberapa perbandingan yang dilakukan sebelumnya kita dapat
meningkatkan besar pergeseran yang dilakukan. Hal ini akan menghemat perbandingan,
yang selanjutnya akan meningkatkan kecepatan pencarian.
Perhitungan penggeseran pada algoritma ini adalah sebagai berikut, bila terjadi
ketidakcocokkan pada saat pattern sejajar dengan teks[i..i+n-1], kita bisa menganggap
ketidakcocokan pertama terjadi di antara teks[i+j] dan pattern[j], dengan 0 < j < n. Berarti,
teks[i..i+j-1] = pattern[0..j-1] dan a=teks[i+j] tidak sama dengan b=pattern[j]. Ketika kita
menggeser, sangat beralasan bila ada sebuah awalan v dari pattern akan sama dengan
sebagian akhiran u dari sebagian teks. Sehingga kita bisa menggeser pattern agar awalan v
tersebut sejajar dengan akhiran dari u.
Dengan kata lain, pencocokkan string akan berjalan secara efisien bila kita
mempunyai tabel yang menentukan berapa panjang kita seharusnya menggeser seandainya
terdeteksi ketidakcocokkan di karakter ke-j dari pattern. Tabel itu harus memuat next[j]
yang merupakan posisi karakter pattern[j] setelah digeser, sehingga kita bisa menggeser
pattern sebesar j-next[j] relatif terhadap teks.
Secara sistematis, langkah-langkah yang dilakukan algoritma Knuth-Morris-Pratt
pada saat mencocokkan string:
1. Algoritma Knuth-Morris-Pratt mulai mencocokkan pattern pada awal teks.
2. Dari kiri ke kanan, algoritma ini akan mencocokkan karakter per karakter pattern
dengan karakter di teks yang bersesuaian, sampai salah satu kondisi berikut
dipenuhi:
1. Karakter di pattern dan di teks yang dibandingkan tidak cocok (mismatch).
2. Semua karakter di pattern cocok. Kemudian algoritma akan memberitahukan
penemuan di posisi ini.
3. Algoritma kemudian menggeser pattern berdasarkan tabel next, lalu mengulangi
langkah 2 sampai pattern berada di ujung teks.
Algoritma Boyer-Moore adalah salah satu algoritma pencarian string,
dipublikasikan oleh Robert S. Boyer, dan J. Strother Moore pada tahun 1977.
Algoritma ini dianggap sebagai algoritma yang paling efisien pada aplikasi umum.
Tidak seperti algoritma pencarian string yang ditemukan sebelumnya, algoritma Boyer-
Moore mulai mencocokkan karakter dari sebelah kanan pattern. Ide di balik algoritma ini
adalah bahwa dengan memulai pencocokan karakter dari kanan, dan bukan dari kiri, maka
akan lebih banyak informasi yang didapat.
Misalnya ada sebuah usaha pencocokan yang terjadi pada teks[i..i+n-1], dan anggap
ketidakcocokan pertama terjadi di antara teks[i+j] dan pattern[j], dengan 0 < j < n. Berarti,
teks[i+j+1..i+n-1] = pattern[j+1..n-1] dan a=teks[i+j] tidak sama dengan b=pattern[j] . Jika
u adalah akhiran dari pattern sebelum b dan v adalah sebuah awalan dari pattern, maka
penggeseran-penggeseran yang mungkin adalah:
Penggeseran good-suffix yang terdiri dari menyejajarkan potongan teks[i+j+1..i+n-
1] = pattern[j+1..n-1] dengan kemunculannya paling kanan di pattern yang didahului oleh

karakter yang berbeda dengan pattern[j]. Jika tidak ada potongan seperti itu, maka algoritma
akan menyejajarkan akhiran v dari teks[i+j+1..i+n-1] dengan awalan dari pattern yang sama.
Penggeseran bad-character yang terdiri dari menyejajarkan teks[i+j] dengan
kemunculan paling kanan karakter tersebut di pattern. Bila karakter tersebut tidak ada di
pattern, maka pattern akan disejajarkan dengan teks[i+n+1].
Secara sistematis, langkah-langkah yang dilakukan algoritma Boyer-Moore pada
saat mencocokkan string adalah:
1. Algoritma Boyer-Moore mulai mencocokkan pattern pada awal teks.
2. Dari kanan ke kiri, algoritma ini akan mencocokkan karakter per karakter pattern
dengan karakter di teks yang bersesuaian, sampai salah satu kondisi berikut
dipenuhi:
1. Karakter di pattern dan di teks yang dibandingkan tidak cocok (mismatch).
2. Semua karakter di pattern cocok. Kemudian algoritma akan memberitahukan
penemuan di posisi ini.
3. Algoritma kemudian menggeser pattern dengan memaksimalkan nilai penggeseran
good-suffix dan penggeseran bad-character, lalu mengulangi langkah 2 sampai
pattern berada di ujung teks.

BAB III
ANALISIS DAN RANCANGAN APLIKASI
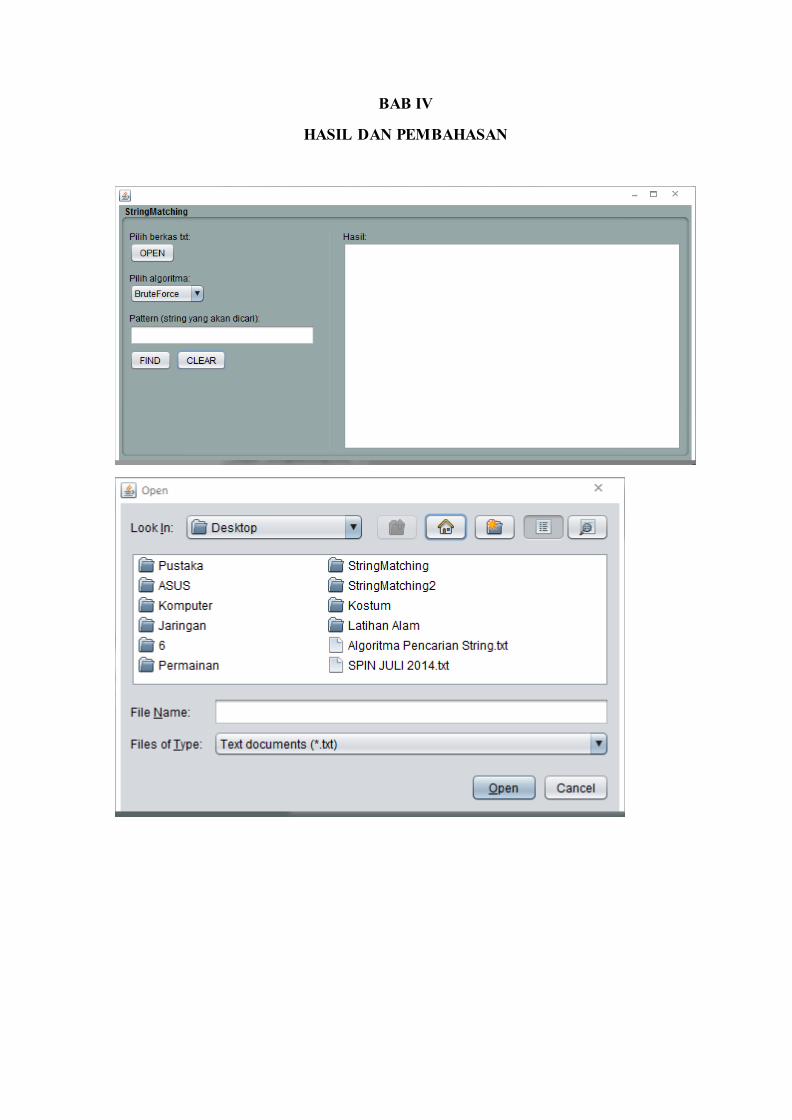
Program ini dibuat dengan berbasis antarmuka pengguna grafis (GUI). Proses yang
pertama kali dilakukan adalah membuka berkas berekstensi TXT (dokumen teks). Dengan
menekan tombol “open”, maka akan memanggil fungsi OpenActionPerformed yang berada
pada kelas StringMatching. Setelah berkas dipilih dan dibuka, program akan mendapatkan
nama berkas tersebut untuk ditampilkan dalam program di samping tombol “open”. Jika
berkas yang dipilih tidak dapat dibuka atau menimbulkan masalah saat diakses, program
akan melakukan pengecualian dan memunculkan pesan “problem accessing file”. Jika
pengguna memilih untuk membatalkan pembukaan berkas, program akan menampilkan
pesan “File access cancelled by user.”
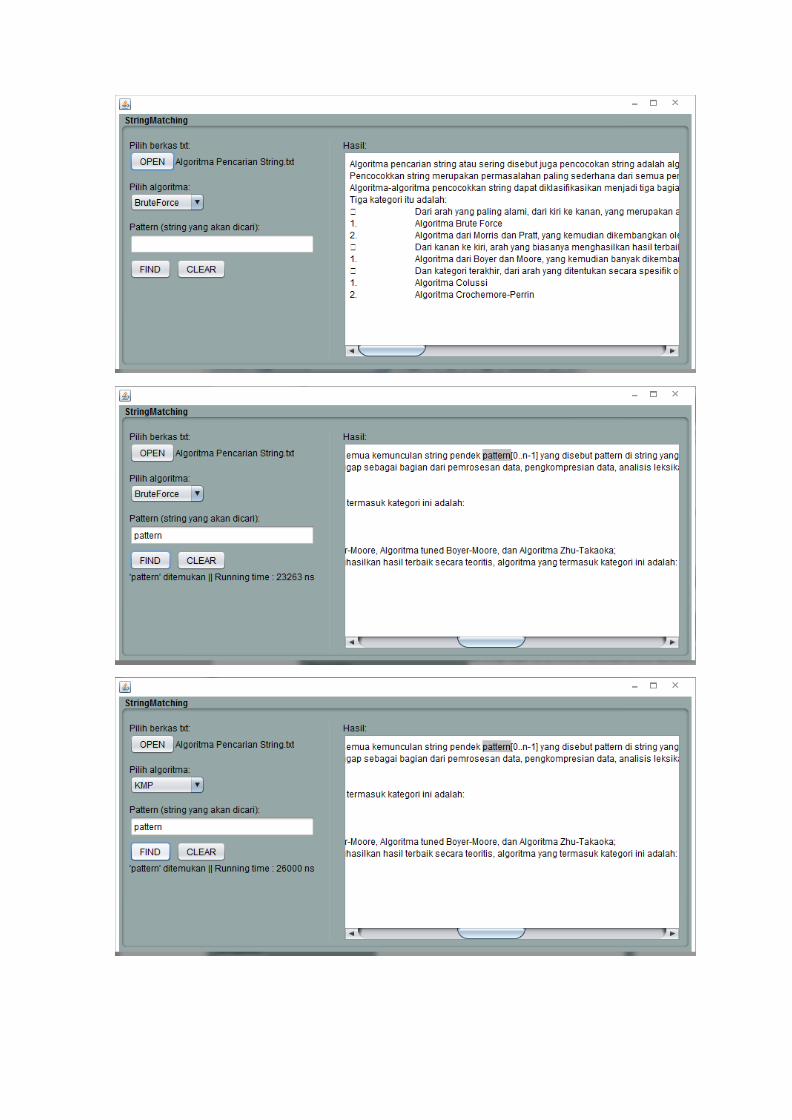
Setelah berkas dibuka, pengguna diminta untuk memilih algoritma yang akan
dipakai, yaitu Brute Force, Knuth-Morris-Pratt, atau Boyer-Moore, dengan default-nya
adalah Brute Force. Selanjutnya adalah pengisian pattern atau string yang ingin dicari oleh
pengguna. Bergantung kepada algoritma yang telah dipilih, setelah tombol “find” ditekan,
maka program akan memanggil kelas dari masing-masing algoritma untuk melakukan
proses pencocokan string.
Jika pengguna memilih Brute Force ataupun tidak mengubah pilihan algoritma
default, program akan memanggil kelas BruteForce. Algoritma ini akan mencocokkan
karakter pertama dari pattern tersebut satu persatu dengan setiap karakter teks yang ada pada
berkas dimulai dari kiri. Jika karakter pertama itu cocok, akan dilanjutkan dengan karakter
selanjutnya. Jika terdapat ketidakcocokan, program akan mencari bagian teks selanjutnya
yang cocok dengan karakter pertama hingga keseluruhan pattern cocok dengan bagian teks
tersebut.
Jika pengguna memilih algoritma Knuth-Morris-Pratt, program akan memanggil
kelas KMP. Dengan menggunakan algoritma ini, program akan mencocokkan karakter
pertama dari pattern yang diberikan oleh pengguna dengan teks dari berkas dimulai dari kiri.
Saat terjadi ketidakcocokan, program akan langsung mengulangi pencocokan karakter
pertama dengan bagian teks selanjutnya berdasarkan tabel KMP, sehingga tidak perlu lagi
mencocokkan satu persatu setiap bagian teks.
Jika pengguna memilih algoritma Boyer-Moore, program akan memanggil kelas
BoyerMoore. Pada algoritma ini, program akan mencocokkan karakter dari pattern dengan
teks dari berkas dimulai dari kanan. Algoritma ini akan memisahkan pattern menjadi prefix
dan suffix tertentu untuk memudahkan dalam pencocokan string.
Setelah salah satu dari ketiga proses pencocokan string di atas sukses, maka program
akan menampilkan pesan bahwa pattern tersebut ditemukan beserta running time-nya.
Pattern yang dicari dalam teks tersebut akan disorot dalam warna abu-abu. Jika program
tidak dapat menemukan pattern yang ingin dicari, program akan menampilkan pesan bahwa
pattern tersebut tidak ditemukan. Selanjutnya pengguna dapat mengulangi pencarian
terhadap teks dari berkas lain dengan menekan tombol “clear” ataupun keluar dari program
dengan menutupnya.
BAB IV
HASIL DAN PEMBAHASAN
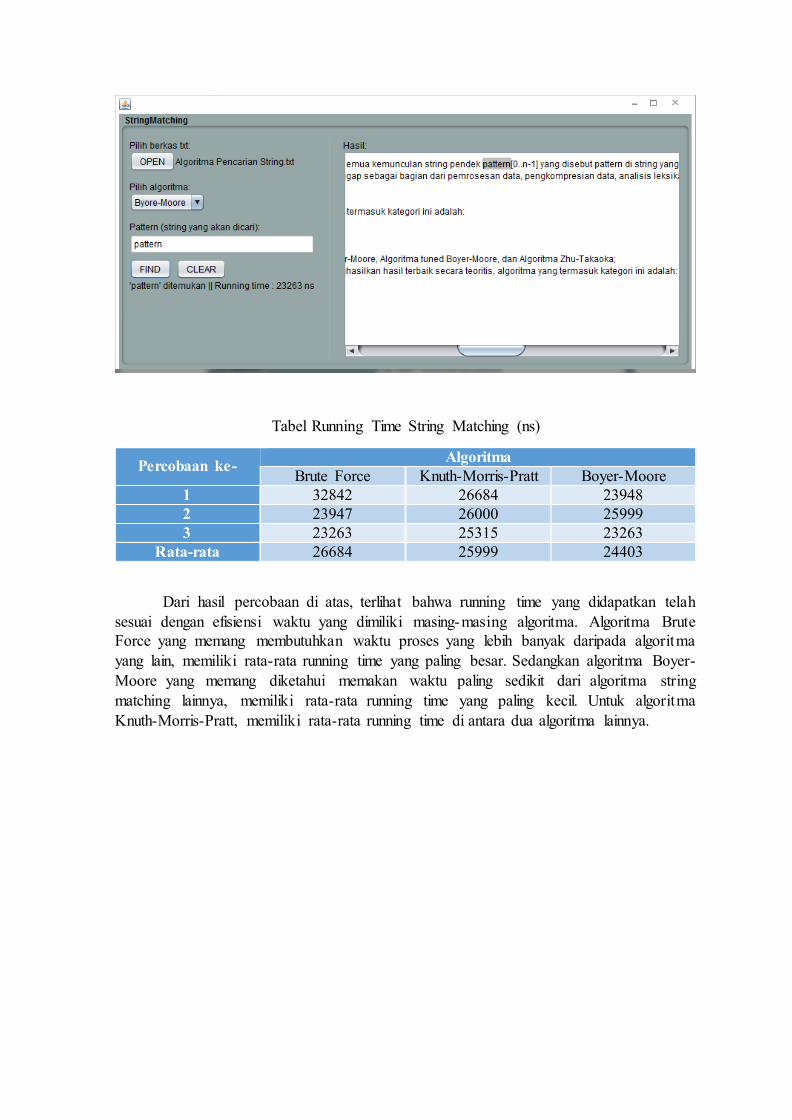
Tabel Running Time String Matching (ns)
Percobaan ke- Algoritma
Brute Force Knuth-Morris-Pratt Boyer-Moore
1 32842 26684 23948
2 23947 26000 25999
3 23263 25315 23263
Rata-rata 26684 25999 24403
Dari hasil percobaan di atas, terlihat bahwa running time yang didapatkan telah
sesuai dengan efisiensi waktu yang dimiliki masing-masing algoritma. Algoritma Brute
Force yang memang membutuhkan waktu proses yang lebih banyak daripada algoritma
yang lain, memiliki rata-rata running time yang paling besar. Sedangkan algoritma Boyer-
Moore yang memang diketahui memakan waktu paling sedikit dari algoritma string
matching lainnya, memiliki rata-rata running time yang paling kecil. Untuk algoritma
Knuth-Morris-Pratt, memiliki rata-rata running time di antara dua algoritma lainnya.

BAB V
KESIMPULAN DAN SARAN
Dari pembahasan sebelumnya, dapat disimpulkan bahwa algoritma Brute Force
memiliki running time yang paling besar dan kurang efisien, dikarenakan prosesnya yang
harus mencocokkan karakter satu persatu. Sedangkan algoritma Boyer-Moore merupakan
algoritma yang paling efisien dikarenakan running time-nya paling kecil dan proses
pencocokannya dilakukan dari kanan dan menggunakan prefix dan suffix dari pattern,
berbeda dengan algoritma lainnya.
Untuk ke depannya, penulis berharap agar program ini dapat dikembangkan lagi,
yaitu dengan menampilkan pattern lain yang cocok dengan teks, jika ditemukan banyak
pattern yang sama di dalam teks. Karena program ini masih belum dapat menampilkan lebih
dari satu pattern yang cocok dan hanya dapat menampilkan satu pattern yang cocok yang
pertama kali ditemukan.

DAFTAR REFERENSI
Algoritma pencarian string - Wikipedia bahasa Indonesia, ensiklopedia bebas
http://id.wikipedia.org/wiki/Algoritma_pencarian_string diakses pada tanggal 10
Desember 2014.
Algoritma Knuth-Morris-Pratt - Wikipedia bahasa Indonesia, ensiklopedia bebas
http://id.wikipedia.org/wiki/Algoritma_Knuth-Morris-Pratt diakses pada tanggal 11
Desember 2014.
Algoritma Boyer-Moore - Wikipedia bahasa Indonesia, ensiklopedia bebas
http://id.wikipedia.org/wiki/Algoritma_Boyer-Moore diakses pada tanggal 11
Desember 2014.