tugas 5 0317-fahreza yozi-1612510832
TRANSCRIPT

Tugas 5
nama : Fahreza Yozinim : 1612510832mata kuliah : Rekayasa Webdosen : Andry sunandar, s.t. m.kom

1. Apa yang anda ketahui tentang Distributed Computing System.

Distributed Computing System
merupakan bidang ilmu komputer yang mempelajari sistem terdistribusi.Sebuah sistem terdistribusi terdiri dari beberapa komputer otonom yang berkomunikasi melalui jaringan komputer. Komputer yang saling berinteraksi untuk mencapai tujuan bersama. Suatu program komputer yang berjalan dalam sistem terdistribusi disebut program didistribusikan, dan didistribusikan pemrograman adalah proses menulis program tersebut. Distributed computing juga mengacu pada penggunaan sistem terdistribusi untuk memecahkan masalah komputasi. Dalam distributed computing, masalah dibagi menjadi banyak tugas, masing-masing yang diselesaikan oleh satu komputer

Sejarah Distributed Computing System
Sejarah mencatat Konferensi internasional tentang ParCo97 komputasi paralel (Parallel Computing 97) diadakan di Bonn, Jerman 19-22 September 1997. Konferensi pertama dalam seri ini dua tahunan diadakan pada tahun 1983 di Berlin. Selanjutnya konferensi diadakan di Leiden (Belanda), London (Inggris), Grenoble (Prancis) dan Gent (Belgia). Sejak awal tujuan dengan (Komputasi Paralel) konferensi parco adalah untuk mempromosikan penerapan komputer paralel untuk memecahkan masalah kehidupan nyata. Dalam kasus ParCo97 tonggak baru dicapai dalam bahwa lebih dari setengah dari makalah dan poster yang disajikan prihatin dengan aspek aplikasi. Fakta ini mencerminkan kedatangan usia komputasi paralel.
Sekitar 200 makalah yang disampaikan kepada Komite Program oleh penulis dari seluruh dunia. Program akhir terdiri dari empat makalah diundang, 71 kontribusi ilmiah / industri kertas dan 45 poster. Selain diskusi panel tentang Komputasi Paralel dan Evolusi Cyberspace diadakan. Penekanan praktis konferensi ini ditekankan oleh pameran industri di mana perusahaan menunjukkan perkembangan terbaru dalam peralatan pemrosesan paralel dan perangkat lunak. Pembicara dari perusahaan yang berpartisipasi mempresentasikan makalah dalam sesi industri di mana perkembangan baru dalam komputasi paralel dilaporkan.
Komputer paralel secara kasar dapat diklasifikasikan menurut tingkat di mana hardware mendukung paralelisme, dengan komputer multi-core dan multi-prosesor yang memiliki elemen pemrosesan ganda dalam satu mesin, sedangkan cluster, MPP, dan grid menggunakan beberapa komputer untuk bekerja pada hal yang sama tugas. Khusus arsitektur komputer paralel kadang-kadang digunakan bersama prosesor tradisional, untuk mempercepat tugas-tugas tertentu.

Sumber daya komputer (computer resource) dapat terdiri dari sebuah komputer dengan beberapa processor, atau beberapa komputer yang terhubung oleh sebuah jaringan, atau pun kombinasi antara keduanya. Processor mengakses data melalui shared memory. Beberapa supercomputer parallel processing system memiliki ratusan bahkan ribuan microprocessor. Dengan bantuan dari parallel processing, sejumlah komputasi dapat dijalankan dalam satu waktu, memangkas waktu yang dibutuhkan untuk menyelesaikan sebuah project. Parallel processing sangat berguna untuk project yang membutuhkan komputasi komplek, seperti weather modelling dan efek digital spesial (special effect digital). Dengan bantuan dari parallel processing, masalah yang sangat kompleks dapat terselesaikan dengan efektif dan lebih efisien. Parallel computing dapat secara efektif digunakan untuk tugas-tugas (task) yang melibatkan begitu banyak komputasi, untuk dapat dibagi menjadi task-task yang lebih kecil.Contoh sistem yang diterapkan pada obyek 3D yang besar dan rinci, interpretasi geometrik yang melekat seri membatasi kecepatan generasi gambar. Untuk mempercepat prosedur menafsirkan, sebuah Graphic Processing Unit (GPU) metode berbasis memanfaatkan Compute Arsitektur Unified Device (CUDA) yang diusulkan dalam tulisan ini. Pendekatan terfokus melibatkan dua tahap: pertama adalah scan sekuensial pada string yang dihasilkan negara dari derivasi dari L-sistem yang berjalan pada CPU, yang kedua adalah komputasi paralel pada GPU dengan CUDA. Simbol dalam string negara diinterpretasikan sebagai perintah penyu dan kura-kura primitif grafis yang menyatakan tergantung pada operasi perkalian matriks di scan sekuensial. Kemudian dengan posisi dan arah tercakup dalam penyu negara, garis (silinder) yang dihasilkan dan primitif grafik diubah menjadi sistem koordinat penyu menggunakan ribuan benang paralel dalam fase komputasi. Dibandingkan dengan metode lain, metode yang diusulkan lebih efisien.

2. Apa yang anda ketahui tentang Teori CAP (Consistency Availability and Partition tolerance) dan seberapa penting hal tersebut terhadap web application yang akan kita buat?

Teori CAP (Consistency Availability and Partition tolerance)
Tidak ada sistem terdistribusi aman dari kegagalan jaringan, sehingga partisi jaringan umumnya harus ditoleransi. Di hadapan partisi, satu kemudian ditinggalkan dengan dua pilihan: konsistensi atau ketersediaan. Ketika memilih konsistensi lebih ketersediaan, sistem akan kembali kesalahan atau waktu keluar jika informasi tertentu tidak dapat dijamin akan up to date karena partisi jaringan. Ketika memilih ketersediaan lebih konsistensi, sistem akan selalu memproses query dan mencoba untuk kembali versi terbaru yang tersedia dari informasi, bahkan jika tidak dapat menjamin itu up to date karena partisi jaringan.
Dengan tidak adanya kegagalan jaringan - yaitu, ketika sistem terdistribusi berjalan normal - baik ketersediaan dan konsistensi dapat dipenuhi.
CAP sering disalahpahami sebagai jika salah satu harus memilih untuk meninggalkan salah satu dari tiga jaminan setiap saat. Bahkan, pilihan ini benar-benar antara konsistensi dan ketersediaan ketika partisi hanya terjadi, tidak ada trade-off harus dibuat.
sistem database yang dirancang dengan jaminan ACID tradisional dalam pikiran seperti RDBMS memilih konsistensi lebih, sedangkan sistem yang dirancang di sekitar filosofi BASE, umum dalam gerakan NoSQL misalnya, memilih ketersediaan lebih konsistensi.
The PACELC Teorema dibangun di atas CAP dengan menyatakan bahwa bahkan dalam ketiadaan partisi, trade-off antara latency dan konsistensi terjadi.

Menurut Eric BrewerTeori tersebut bersangkutan dengan NoSql,karena NoSql didasarkan oleh Consistency, Availability,Partition-Tolerance (CAP). Consistency Availability (CA) berseberangan denganPartition-Tolerance dan berhubungan dengan replikasi. Consistency Partition-Tolerance (CP) berseberangan dengan Availability dalam penyimpanan data.Availability Partition-Tolerance (AP) dimana system mencapai kondisi eventualconsistency melalui replikasi dan verifikasi yang konsisten dalam node yang telahterbagi – bagi. Dalam basis data NoSQL, penerapan konsep tersebut diterjemahkandalam empat konsep dasar, yaitu Non-Relational, MapReduce, Schema Free, danHorizontal Scaling.

a) Non-RelationalKonsep Non-Relational dalam basis data NoSQL meliputi hirarki, graf, dan basis data berorientasi obyek. Penggunaan basis data non-relasional kembali merebak seiring bertambahnya aplikasi berbasis web yang menuntut skalabilitas tinggi.
b) MapReduceMapReduce merupakan mode pemrograman yang diadaptasi dari pemrograman fungsional yang diimplementasikan mengolah dataset yang besar. Tujuan dari MapReduce adalah merancang suatu abstraksi baru yang memungkinkanpengguna untuk membuat antarmuka pemrograman sederhana dan menyembunyikan detail yang rumit dari paralelisasi, fault-tolerance, distribusi data, dan load-balancing dalam pustaka pemrogramannya.
c) Schema-FreeNoSQL dan RDBMS mempunyai perbedaan dalam hal penerapan skema basis data. Dalam RDBMS, sebuah table didesain dengan peraturan skema yang ketat, sedangkan pada NoSQL tidak diharuskan memiliki table, kolom, primary key,foreign key, join, dan relasi. Dalam pengembangan RDBMS, developer/database administrator harus berhati – hati dalam menentukan bagaimana table saling berelasi dan field yang ada di dalam setiap tabel. Manfaat lain dalam penggunaan schema-free adalah penghematan dalam media penyimpanan. Model data schema free artinya setiap baris memungkinkan memiliki nilai sebanyak yang telah didefinisikan dalam tiap fields, dan tidak perlumenggunakan nilai yang memang tidak diperlukan. Kelemahan dalam schemafree adalah memunculkan lemahnya pendefinisian struktur yang memungkinkan terjadinya penggunaan basis data yang tidak konsisten.
d) Horizontal ScalingHorizontal Scaling memungkinkan basis data dijalankan pada beberapa server untuk meningkatkan kemampuan perangkat penyimpanan dan meningkatkan efisiensi waktu. Hal ini berarti memungkinkan dilakukannya penambahan server dalam satu jaringan dan user tidak sadar jika terdapat hardware yang diganti dari sisi server.

3. Jelaskan mengenai service discovery framework, dan berikan pembahasan singkat mengenai contoh discovery
framework seperti Eureka dan ZooKeeper !

Mengapa Gunakan Service Discovery?
Mari kita bayangkan bahwa Anda menulis beberapa kode yang memanggil layanan yang memiliki API SISA atau Thrift API. Dalam rangka untuk membuat permintaan, kode Anda perlu mengetahui lokasi jaringan (alamat IP dan port) dari contoh layanan. Dalam aplikasi tradisional yang berjalan pada perangkat keras fisik, lokasi jaringan contoh layanan relatif statis. Sebagai contoh, kode Anda dapat membaca lokasi jaringan dari file konfigurasi yang kadang-kadang diperbarui.
Dalam, berbasis cloud aplikasi microservices modern, bagaimanapun, ini adalah masalah yang jauh lebih sulit untuk memecahkan seperti yang ditunjukkan dalam diagram berikut.

contoh layanan telah ditetapkan secara dinamis lokasi jaringan. Selain itu, set contoh layanan perubahan dinamis karena autoscaling, kegagalan, dan upgrade. Akibatnya, kode klien Anda perlu menggunakan mekanisme penemuan layanan yang lebih rumit.
Ada dua pola penemuan layanan utama: client-side penemuan dan penemuan server-side. Mari kita pertama melihat penemuan client-side.

The Client Side Discovery Pattern‑Bila menggunakan penemuan sisi klien, klien bertanggung jawab untuk menentukan lokasi jaringan contoh layanan yang tersedia dan permintaan load balancing di antara mereka. Klien query registri layanan, yang merupakan database contoh layanan yang tersedia. Klien kemudian menggunakan algoritma load-balancing untuk memilih salah satu contoh layanan yang tersedia dan membuat permintaan.
Diagram berikut menunjukkan struktur dari pola ini.
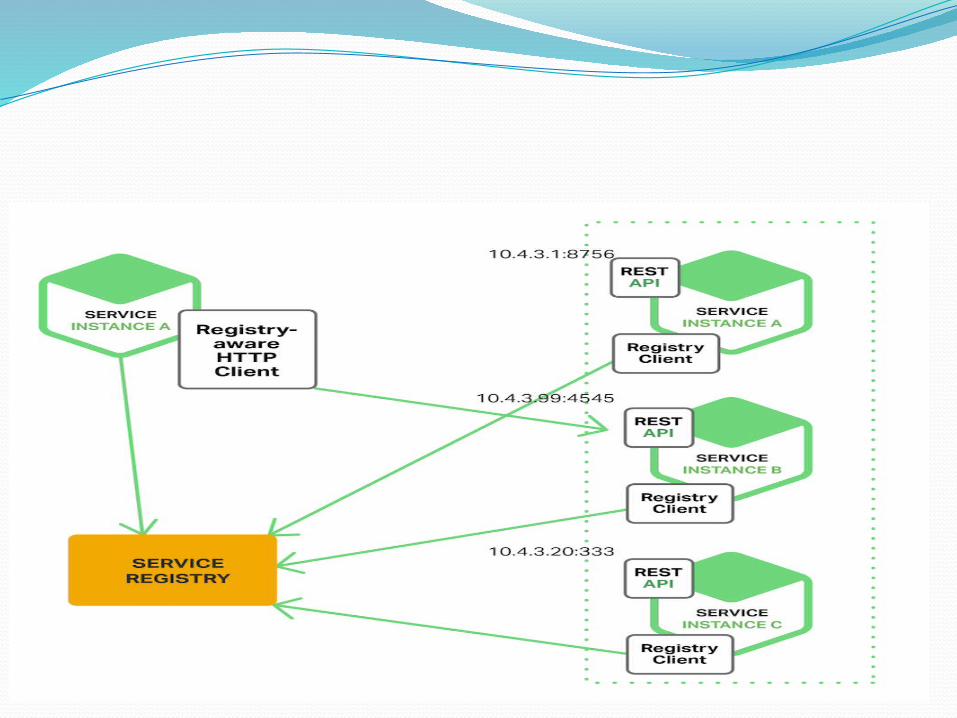

Lokasi jaringan contoh layanan terdaftar dengan registri layanan ketika itu dimulai. Hal ini dihapus dari registri layanan ketika misalnya berakhir. pendaftaran layanan contoh ini biasanya di-refresh secara berkala menggunakan mekanisme detak jantung.
Netflix OSS memberikan contoh yang bagus dari pola penemuan sisi klien. Netflix Eureka adalah registri layanan. Ini menyediakan API REST untuk mengelola pendaftaran layanan-contoh dan untuk query contoh yang tersedia. Netflix Ribbon adalah klien IPC yang bekerja dengan Eureka untuk memuat permintaan keseimbangan di contoh layanan yang tersedia. Kita akan membahas Eureka secara lebih mendalam nanti dalam artikel ini.
Pola Penemuan sisi klien memiliki berbagai kelebihan dan kekurangannya. Pola ini relatif mudah dan, kecuali untuk registri layanan, tidak ada bagian yang bergerak lainnya. Juga, karena klien tahu tentang contoh layanan yang tersedia, dapat membuat cerdas, keputusan load-balancing aplikasi khusus seperti menggunakan hashing konsisten. Salah satu kelemahan signifikan dari pola ini adalah bahwa hal itu pasangan klien dengan registri layanan. Anda harus menerapkan sisi klien penemuan layanan logika untuk setiap bahasa pemrograman dan kerangka kerja yang digunakan oleh klien layanan Anda.
Sekarang kita telah melihat penemuan client-side, mari kita lihat penemuan server-side.

Server-Side Penemuan PolaKlien membuat permintaan ke layanan melalui penyeimbang beban. Penyeimbang beban query registri
layanan dan rute setiap permintaan ke sebuah contoh layanan yang tersedia. Seperti penemuan sisi klien, contoh jasa didaftarkan dan dideregestrasi dengan registri layanan.
Pendekatan lain untuk penemuan layanan adalah pola penemuan server-side. Diagram berikut menunjukkan struktur dari pola ini.
Server-Side Penemuan Pola

Ringkasan Dalam aplikasi microservices, set menjalankan contoh layanan berubah secara dinamis. Contoh telah ditetapkan secara dinamis lokasi jaringan. Akibatnya, dalam rangka untuk klien untuk membuat permintaan untuk layanan itu harus menggunakan mekanisme pelayanan-penemuan.
Bagian penting dari penemuan layanan registri layanan. Registri layanan adalah database contoh layanan yang tersedia. Registri layanan menyediakan API manajemen dan API query. contoh layanan terdaftar dengan dan deregistrasi dari registri layanan menggunakan API manajemen. Permintaan API digunakan oleh komponen sistem untuk menemukan contoh layanan yang tersedia.
Ada dua pola layanan-penemuan utama: client-side penemuan dan penemuan layanan-side. Dalam sistem yang menggunakan layanan penemuan sisi klien, klien query registri layanan, pilih sebuah contoh yang tersedia, dan membuat permintaan. Dalam sistem yang menggunakan penemuan server-side, klien membuat permintaan melalui router, yang query registri layanan dan meneruskan permintaan ke sebuah contoh yang tersedia.
Ada dua cara utama yang contoh layanan terdaftar dengan dan deregistrasi dari registri layanan. Salah satu pilihan adalah untuk contoh layanan untuk mendaftarkan diri dengan registri layanan, pola pendaftaran mandiri. Pilihan lainnya adalah untuk beberapa komponen sistem lainnya untuk menangani pendaftaran dan deregistration atas nama layanan, pola pendaftaran pihak ketiga.
Dalam beberapa lingkungan deployment Anda perlu menyiapkan infrastruktur pelayanan-penemuan Anda sendiri menggunakan registri layanan seperti Netflix Eureka, etcd, atau Apache Zookeeper. Dalam lingkungan penyebaran lainnya, penemuan layanan dibangun di. Misalnya, Kubernetes dan Marathon menangani layanan misalnya pendaftaran dan deregistration. Mereka juga menjalankan proxy pada setiap cluster tuan rumah yang memainkan peran server-side penemuan router.