statistik & probabilitas -...
TRANSCRIPT

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 1
PENDAHULUAN
1. Statistik
Dalam perkembangan ilmu pengetahuan dan teknologi, statistik tidak hanya kumpulan
angka-angka dalam tabel atau grafik seperti dulu. Statistik telah berkembang sesuai dengan
tuntutan ilmu pengetahuan sekarang ini. Statistik dapat digunakan dalam segala bidang ilmu
pengetahuan. Sehingga pengertian statistik pun berkembang menjadi:
Statistik merupakan cabang dari ilmu matematika yang mempelajari cara (metode)
pengumpulan, penyajian, analisa, interpretasi dan penarikan kesimpulan dari sekelompok data
yang disusun, dalam bentuk angka. (Hifni, 1990)
Bidang statistik berkaitan dengan pengumpulan, penyajian, analisis, dan penggunaan
data untuk membuat keputusan dan memecahkan masalah. Karena banyak aspek praktek
rekayasa melibatkan pekerjaan yang berhubungan dengan data, pengetahuan tentang statistik
penting bagi insinyur dari bidang apapun. Secara khusus, teknik statistik dapat mempermudah
kerja dalam merancang produk dan sistem baru, meningkatkan kualitas desain yang sudah ada,
dan merancang, mengembangkan, dan meningkatkan proses produksi.
Metode statistik digunakan untuk membantu kita menggambarkan dan memahami
variabilitas. Variabilitas berarti, bahwa pada setiap pengamatan dari suatu sistem atau
fenomena, tidak akan menghasilkan hasil yang sama persis. Kita semua menghadapi variabilitas
dalam kehidupan kita sehari-hari, dan statistik dapat memberikan kita cara yang tepat untuk
memasukkan variabilitas tersebut ke dalam proses pengambilan keputusan. Misal, jarak yang
dapat ditempuh suatu mobil untuk tiap liter bensin. Apakah selalu sama? Tentu saja tidak,
faktanya jarak tersebut bervariasi. Variabilitas ini bergantung pada banyak faktor seperti kondisi
jalan, cuaca, kondisi mobil, dll. Faktor-faktor inilah yang menggambarkan sumber dari
variabilitas sistem tersebut. Statistik memberi kita kerangka untuk menjelaskan variabilitas ini
dan untuk mempelajari tentang sumber variabilitas mana yang paling penting atau yang
memiliki dampak terbesar pada sistem tersebut.
2. Probabilitas
Probabilitas biasa digunakan untuk menggambarkan pemikiran terhadap beberapa
masalah atau dalil yang kebenarannya tidak menentu. Masalah tersebut biasanya dalam bentuk
“Apakah peristiwa tertentu akan terjadi?” Sedangkan pemikiran dalam bentuk ”Seberapa
yakinkah kita bahwa peristiwa tersebut akan terjadi?” Keyakinan (kepastian) yang kita adopsi

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 2
tersebut dapat digambarkan dalam bentuk ukuran numerik, antara 0 dan 1, yang kita sebut
probabilitas. Semakin tinggi nilai probabilitas dari suatu peristiwa, semakin yakin kita bahwa
peristiwa tersebut akan terjadi.
Jadi, probabilitas dalam pengertiannya adalah ukuran atau nilai dari kemungkinan suatu
peristiwa acak akan terjadi. (Wikipedia)
Teori matematika tentang probabilitas memberi kita alat dasar untuk membangun dan
menganalisa model matematika untuk fenomena acak. Dalam mempelajari fenomena acak, kita
berhadapan dengan percobaan yang hasilnya tidak dapat diprediksi sebelumnya.
Dalam sains dan teknologi, fenomena acak menggambarkan berbagai macam situasi.
Pada umumnya, mereka dapat dikelompokkan menjadi dua kelas yang besar. Kelas yang
pertama berhubungan dengan fenomena fisik atau alam yang melibatkan ketidakpastian.
Ketidakpastian masuk ke dalam rumusan masalah melalui kompleksitas, kurangnya pemahaman
kita tentang semua sebab dan akibat masalah tersebut, dan kurangnya informasi. Misalnya,
prakiraan cuaca. Informasi yang diperoleh dari satelit cuaca dan informasi meteorologi lainnya
tidak cukup untuk membuat prediksi cuaca tersebut bisa diandalkan 100 persen. Oleh karena
itu, laporan cuaca di radio dan televisi dibuat berdasarkan probabilitas.
Kelas kedua mempelajari model probabilistik yang menyangkut variabilitas. Misalnya,
masalah dalam kepadatan lalu lintas dimana seseorang ingin mengetahui jumlah kendaraan
melintasi titik tertentu di jalan dalam interval waktu tertentu. Jumlah ini bervariasi tak terduga
untuk interval satu dan interval lain, dan variabilitas ini mencerminkan variabel perilaku
pengemudi yang melekat dalam masalah ini. Sifat ini memaksa kita untuk mengadopsi sudut
pandang probabilistik, dan teori probabilitas menyediakan alat yang tepat untuk menganalisis
masalah jenis ini.
Dapat dikatakan bahwa variabilitas dan ketidakpastian ada dalam setiap pemodelan
untuk semua fenomena nyata, dan wajar bila melihat pemodelan dan analisis probabilitas
menempati posisi sentral dalam perkembangan berbagai topik ilmu dalam sains dan teknologi.

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 3
POPULASI, SAMPEL DAN DATA
1. Populasi
Populasi adalah keseluruhan objek yang akan/ingin diteliti. Populasi ini sering juga
disebut Universe. Anggota populasi dapat berupa benda hidup maupun benda mati, dimana
sifat-sifat yang ada padanya dapat diukur atau diamati. Populasi yang tidak pernah diketahui
dengan pasti jumlahnya disebut "Populasi Infinit" atau tak terbatas, dan populasi yang
jumlahnya diketahui dengan pasti (populasi yang dapat diberi nomor identifikasi), misalnya
murid sekolah, jumlah karyawan tetap pabrik, dll disebut "Populasi Finit".
2. Sampel
Sampel adalah bagian dari populasi yang menjadi objek penelitian (sampel sendiri
secara harfiah berarti contoh). Hasil pengukuran atau karakteristik dari sampel disebut
"statistik" yaitu X untuk harga rata-rata hitung dan S atau SD untuk simpangan baku.
Alasan perlunya pengambilan sampel adalah sebagai berikut :
Keterbatasan waktu, tenaga dan biaya.
Lebih cepat dan lebih mudah.
Memberi informasi yang lebih banyak dan dalam.
Dapat ditangani lebih teliti.
Pengambilan sampel kadang-kadang merupakan satu-satunya jalan yang harus dipilih,
(tidak mungkin untuk mempelajari seluruh populasi) misalnya:
Meneliti air laut di Indonesia
Mencicipi rasa makanan di dapur
Mencicipi durian yang hendak dibeli
Dalam prakteknya, berikut jenis (teknik) pemilihan sampel yang paling banyak
digunakan oleh peneliti:
a) Sampel Random (Random Sampling)
Cara ini dapat digunakan apabila dari populasi dianggap semua unsur yang terdapat
dalam populasi tersebut memiliki probabilitas yang sama untuk terpilih. Contohnya
pengambilan adukan campuran baja untuk dibuat sampel kubus.
b) Sampel Sistematis (Systematic Sampling)
Sebuah sampel dianggap sistematis, apabila proses pengambilannya dilakukan
secara sistematis dari populasinya. Contohnya apabila kita ingin menyelidiki lapisan tanah,

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 4
dimana sampel-sampel yang kita ambil pada kedalaman-kedalaman tertentu, maka secara
teoritis apabila pengambilan dilakukan beberapa tempat maka pada kedalaman yang
mempunyai lapisan yang sama, dapat kita hubungkan dengan garis, dan ini merupakan
proyeksi perkiraan lapisan tanah berdasarkan hasil dari data yang kita peroleh.
c) Sampel Luas / Kelompok (Cluster Sampling)
Pengambilan sampel dilakukan terhadap sampling unit, dimana sampling unitnya
terdiri dari satu kelompok (cluster). Tiap item (individu) di dalam kelompok yang terpilih
akan diambil sebagai sampel. Cara ini dipakai bila populasi dapat dibagi dalam kelompok-
kelompok dan setiap karakteristik yang dipelajari ada dalam setiap kelompok. Misalnya ingin
meneliti gambaran karakteristik (umur, suku, pendidikan dan pekerjaan) orang tua
mahasiswa FT Universitas Brawijaya. Mahasiswa FT-UB dibagi dalam 6 kelompok (I s/d VI).
Pilih secara random salah satu tingkat (misal kelompok II). Maka orang tua semua mahasiswa
yang berada pada tingkat II diambil sebagai sampel (Cluster).
d) Sampel Bertingkat (Multi Stage Sampling)
Pengambilan sampel bertingkat dapat dilakukan, apabila populasi dapat terbagi
dalam tingkatan-tingkatan, sehingga pengambilan sampel disesuaikan dengan jumlah tiap
tingkatan. Contohnya bila kita mengajukan pendapat umum, maka sampel dibagi atas
beberapa tingkatan umum, atau kita ingin menyelidiki pengeluaran rata-rata dari penduduk
kita dapat menggolongkan pada tingkat penghasilan dan sebagainya.
e) Sampel Kuota (Quota Sampling)
Pengambilan sampel hanya berdasarkan pertimbangan peneliti saja, hanya
disini besar dan kriteria sampel telah ditentukan lebih dahulu. Misalnya Sampel yang akan di
ambil berjumlah 100 orang dengan perincian 50 laki dan 50 perempuan yang berumur 15-40
tahun. Cara ini dipergunakan kalau peneliti mengenal betul daerah dan situasi daerah
dimana penelitian akan dilakukan.
3. Data
Dalam statistika dikenal beberapa jenis data. Data dapat berupa angka dapat pula
bukan berupa angka. Data berupa angka disebut data kuantitatif dan data yang bukan angka
disebut data kualitatif.
Berdasarkan nilainya dikenal dua jenis data kuantitatif yaitu data diskrit yang diperoleh
dari hasil perhitungan dan data continue yang diperoleh dari hasil pengukuran. Menurut
sumbernya data dibedakan menjadi dua jenis yaitu data interen adalah data yang bersumber

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 5
dari dalam suatu instansi atau lembaga pemilik data dan data eksteren yaitu data yang
diperoleh dari luar.
Data eksteren dibagi menjadi dua jenis yaitu data primer dan data sekunder. Data
primer adalah data yang langsung dikumpulkan oleh orang yang berkepentingan dengan data
tersebut dan data sekunder adalah data yang tidak secara langsung dikumpulkan oleh orang
yang berkepentingan dengan data tersebut.
Data bisa disajikan dalam bentuk tabel atau grafik.
a) Tabel Statistika
Ada beberapa macam tabel yang kita kenal dalam tabel statistika, yang fungsinya
bukan hanya mempermudah pada pengolah data saja, tetapi tabel dapat berfungsi sebagai
alat bantu komunikasi dan sumber informasi bagi pembacanya. Tabel-tabel tersebut secara
umum dapat dibagi dalam
Tabel Referensi
Tabel referensi ini biasanya disusun secara khusus dan terinci guna kepentingan
referensi. Contohnya tabel dibawah ini yang merupakan tabel referensi kekuatan pipa
baja
Tabel Iktisar
Merupakan bentuk penyajian beberapa data, hasil dari pengumpulan atau pengukuran
sebelumnya dari kelompok jenis data tertentu sehingga seseorang secara langsung
dapat membandingkan antara data yang satu dengan data lainnya.
Tabel Umum
Bentuk penyajian data yang dikumpulkan dari bermacam-macam jenis data, yang
dituliskan dalam suatu monogram. Biasanya informasi ini dikumpulkan berdasarkan
sensus, sehingga setiap saat data itu akan berubah sesuai dengan perkembangan.
Contoh:

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 6
Tabel Distribusi
Bentuk penataan data, yang dibuat oleh pengolahan data berdasarkan hasil-hasil data
yang diperoleh oleh peneliti tersebut, yang bertujuan untuk memperoleh gambaran
karakteristik dari data yang akan diolahnya. Contoh:
b) Grafik
Grafik adalah cara penyampaian informasi bagi pembacanya. Penyajian data dengan
grafik dianggap lebih komunikatif karena dalam waktu singkat dapat diketahui karakteristik
dari data yang disajikan.
Grafik Garis
Grafik garis atau diagram garis dipakai untuk menggambarkan data berkala. Grafik garis
dapat berupa grafik garis tunggal maupun grafik garis berganda. Contoh grafik garis
tunggal dan ganda:

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 7
Grafik Batang
Grafik batang pada dasarnya sama fugsinya dengan grafik garis yaitu untuk
menggambarkan data berkala. Grafik batang juga terdiri dari grafik batang tunggal dan
grafik batang ganda. Contoh grafik batang tunggal dan ganda:
Grafik Lingkaran
Grafik lingkaran menunjukkan hubungan bagian informasi yang satu dengan yang lain
terhadap total seluruh informasi. Biasanya bagian-bagian informasi digambarkan dalam
Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 8
bentuk proporsi atau presentase dimana lingkaran menggambarkan seluruh total
kejadian. Contoh grafik lingkaran:
Histogram
Penyajian data dengan histogram diperlukan suatu batas tepi kelas, sehingga masing-
masing kelas dapat berhimpit menjadi satu batas. Contoh histogram:
Poligon
Jika pada penggambaran histogram diperlukan batas tepi, maka untuk menggambarkan
poligon data yang diperlukan hanya titik tengah dan frekuensi saja. Hanya saja
tambahan dua batas lagi, yaitu pada awal dan akhir dari garis poligon, dilanjutkan
setebal interval dari masing-masing kelas yang ada. Contoh poligon:

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 9
TENDENSI SENTRAL
Ukuran rata-rata dalam statistik banyak ragamnya. Dalam penelitian pendidikan hanya tiga
macam ukuran rata-rata yang sering digunakan yaitu, mean atau rata-rata hitung, median dan mode.
1. Mean
Rata-rata hitung atau arithmetic mean atau sering disebut dengan istilah mean saja
merupakan metode yang paling banyak digunakan untuk menggambarkan ukuran tendensi
sentral. Mean dihitung dengan menjumlahkan semua nilai data pengamatan kemudian dibagi
dengan banyaknya data. Definisi tersebut dapat di nyatakan dengan persamaan berikut:
Sampel:
Populasi:
Keterangan:
∑ = lambang penjumlahan semua gugus data pengamatan
n = banyaknya sampel data
N = banyaknya data populasi
= nilai rata-rata sampel
μ = nilai rata-rata populasi
Mean dilambangkan dengan (dibaca “x-bar”) jika kumpulan data ini merupakan
contoh (sampel) dari populasi, sedangkan jika semua data berasal dari opulasi, mean
dilambangkan dengan μ (huruf kecil Yunani mu).
Sampel statistik biasanya dilambangkan dengan huruf Inggris, , sementara parameter-
parameter populasi biasanya dilambangkan dengan huruf Yunani, misalnya μ
a) Rata-rata hitung (Mean) untuk data tunggal
Contoh 1:
Hitunglah nilai rata-rata dari nilai ujian matematika kelas 3 SMU berikut ini:
2; 4; 5; 6; 6; 7; 7; 7; 8; 9
Jawab:
Nilai rata-rata dari data yang sudah dikelompokkan bisa dihitung dengan menggunakan
formula berikut:

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 10
Keterangan:
∑ = lambang penjumlahan semua gugus data pengamatan
fi = frekuensi data ke-i
n = banyaknya sampel data
= nilai rata-rata sampel
Contoh 2:
Berapa rata-rata hitung pada tabel frekuensi berikut:
xi fi
70 5
69 6
45 3
80 1
56 1
Catatan: Tabel frekuensi pada tabel di atas merupakan tabel frekuensi untuk data tunggal,
bukan tabel frekuensi dari data yang sudah dikelompokkan berdasarkan selang/kelas
tertentu.
Jawab:
xi fi fixi
70 5 350
69 6 414
45 3 135
80 1 80
56 1 56
Jumlah 16 1035

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 11
b) Mean dari data distribusi Frekuensi atau dari gabungan:
Distribusi Frekuensi
Rata-rata hitung dari data yang sudah disusun dalam bentuk tabel distribusi frekuensi dapat
ditentukan dengan menggunakan formula yang sama dengan formula untuk menghitung
nilai rata-rata dari data yang sudah dikelompokkan, yaitu:
Keterangan:
∑ = lambang penjumlahan semua gugus data pengamatan
fi = frekuensi data ke-i
= nilai rata-rata sampel
Contoh 3:
Tabel berikut ini adalah nilai ujian statistik 80 mahasiswa yang sudah disusun dalam tabel
frekuensi. Berbeda dengan contoh 2, pada contoh ke-3 ini, tabel distribusi frekuensi dibuat
dari data yang sudah dikelompokkan berdasarkan selang/kelas tertentu (banyak kelas = 7
dan panjang kelas = 10).
Kelas ke- Nilai Ujian fi
1 31 – 40 2
2 41 – 50 3
3 51 – 60 5
4 61 – 70 13
5 71 – 80 24
6 81 – 90 21
7 91 – 100 12
Jumlah 80
Jawab:
Buat daftar tabel berikut, tentukan nilai pewakilnya (xi) dan hitung fixi.
Kelas ke- Nilai Ujian fi xi fixi
1 31 – 40 2 35.5 71.0
2 41 – 50 3 45.5 136.5

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 12
3 51 – 60 5 55.5 277.5
4 61 – 70 13 65.5 851.5
5 71 – 80 24 75.5 1812.0
6 81 – 90 21 85.5 1795.5
7 91 – 100 12 95.5 1146.0
Jumlah 80 6090.0
Catatan: Pendekatan perhitungan nilai rata-rata hitung dengan menggunakan distribusi
frekuensi kurang akurat dibandingkan dengan cara perhitungan rata-rata hitung dengan
menggunakan data aktualnya. Pendekatan ini seharusnya hanya digunakan apabila tidak
memungkinkan untuk menghitung nilai rata-rata hitung dari sumber data aslinya.
Rata-rata Gabungan atau rata-rata terboboti (Weighted Mean)
Rata-rata gabungan (disebut juga grand mean, pooled mean, atau rata-rata umum) adalah
cara yang tepat untuk menggabungkan rata-rata hitung dari beberapa sampel.
2. Median
Median dari n pengukuran atau pengamatan x1, x2 ,…, xn adalah nilai pengamatan yang
terletak di tengah gugus data setelah data tersebut diurutkan. Apabila banyaknya pengamatan
(n) ganjil, median terletak tepat ditengah gugus data, sedangkan bila n genap, median diperoleh
dengan cara interpolasi yaitu rata-rata dari dua data yang berada di tengah gugus data. Dengan
demikian, median membagi himpunan pengamatan menjadi dua bagian yang sama besar, 50%
dari pengamatan terletak di bawah median dan 50% lagi terletak di atas median.
Median sering dilambangkan dengan (dibaca “x-tilde”) apabila sumber datanya
berasal dari sampel (dibaca “μ-tilde”) untuk median populasi. Median tidak dipengaruhi oleh
nilai-nilai aktual dari pengamatan melainkan pada posisi mereka.

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 13
Prosedur untuk menentukan nilai median, pertama urutkan data terlebih dahulu,
kemudian ikuti salah satu prosedur berikut ini:
Banyak data ganjil → mediannya adalah nilai yang berada tepat di tengah gugus data
Banyak data genap → mediannya adalah rata-rata dari dua nilai data yang berada di
tengah gugus data
a) Median data tunggal:
Untuk menentukan median dari data tunggal, terlebih dulu kita harus mengetahui
letak/posisi median tersebut. Posisi median dapat ditentukan dengan menggunakan formula
berikut:
dimana
n= banyaknya data pengamatan.
Median apabila n ganjil
Contoh 4:
Hitunglah median dari nilai ujian matematika kelas 3 SMU berikut ini:
8; 4; 5; 6; 7; 6; 7; 7; 2; 9; 10
Jawab:
data: 8; 4; 5; 6; 7; 6; 7; 7; 2; 9; 10
setelah diurutkan: 2; 4; 5; 6; 6; 7; 7; 7; 8; 9; 10
banyaknya data (n) = 11
posisi Me = ½ (11+1) = 6
jadi Median = 7 (data yang terletak pada urutan ke-6)
Nilai Ujian 2 4 5 6 6 7 7 7 8 9 10
Urutan data ke- 1 2 3 4 5 6 7 8 9 10 11
↑
Median apabila n genap:
Contoh 6:
Hitunglah median dari nilai ujian matematika kelas 3 SMU berikut ini:
8; 4; 5; 6; 7; 6; 7; 7; 2; 9

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 14
Jawab:
data: 8; 4; 5; 6; 7; 6; 7; 7; 2; 9
setelah diurutkan: 2; 4; 5; 6; 6; 7; 7; 7; 8; 9
banyaknya data (n) = 10
posisi Me = ½ (10+1) = 5.5
Data tengahnya: 6 dan 7
jadi Median = ½ (6+7) = 6.5 (rata-rata dari 2 data yang terletak pada urutan ke-5 dan
ke-6)
Nilai Ujian 2 4 5 6 6 7 7 7 8 9
Urutan data ke- 1 2 3 4 5 6 7 8 9 10
↑
b) Median dalam distribusi frekuensi
Formula untuk menentukan median dari tabel distribusi frekuensi adalah sebagai
berikut:
b = batas bawah kelas median dari kelas selang yang mengandung unsur atau memuat nilai
median
p = panjang kelas median
n = ukuran sampel/banyak data
f = frekuensi kelas median
F = Jumlah semua frekuensi dengan tanda kelas lebih kecil dari kelas median (∑fi)
Contoh 6:
Tentukan nilai median dari tabel distribusi frekuensi pada Contoh 3 di atas!
Jawab:
Kelas ke- Nilai Ujian fi fkum
1 31 – 40 2 2
2 41 – 50 3 5
3 51 – 60 5 10

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 15
4 61 – 70 13 23
5 71 – 80 24 47 ←letak kelas median
6 81 – 90 21 68
7 91 – 100 12 80
8 Jumlah 80
Letak kelas median: Setengah dari seluruh data = 40, terletak pada kelas ke-5 (nilai ujian
71-80)
b = 70.5, p = 10
n = 80, f = 24
f = 24 (frekuensi kelas median)
F = 2 + 3 + 5 + 13 = 23
3. Mode
Mode adalah data yang paling sering muncul/terjadi. Untuk menentukan modus,
pertama susun data dalam urutan meningkat atau sebaliknya, kemudian hitung frekuensinya.
Nilai yang frekuensinya paling besar (sering muncul) adalah modus. Modus digunakan baik
untuk tipe data numerik atau pun data kategoris. Beberapa kemungkinan tentang modus suatu
gugus data:
Apabila pada sekumpulan data terdapat dua mode, maka gugus data tersebut dikatakan
bimodal.
Apabila pada sekumpulan data terdapat lebih dari dua mode, maka gugus data tersebut
dikatakan multimodal.
Apabila pada sekumpulan data tidak terdapat mode, maka gugus data tersebut
dikatakan tidak mempunyai modus.
Meskipun suatu gugus data mungkin saja tidak memiliki modus, namun pada suatu
distribusi data kontinyu, modus dapat ditentukan secara analitis.
Untuk gugus data yang distribusinya simetris, nilai mean, median dan modus semuanya
sama.
Untuk distribusi miring ke kiri (negatively skewed): mean < median < modus
untuk distribusi miring ke kanan (positively skewed): terjadi hal yang sebaliknya, yaitu
mean > median > modus.

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 16
Hubungan antara ketiga ukuran tendensi sentral untuk data yang tidak berdistribusi normal,
namun hampir simetris dapat didekati dengan menggunakan rumus empiris berikut:
Mean – Mode = 3 (Mean – Median)
a) Modus Data Tunggal
Contoh: 8:
Berapa modus dari nilai ujian matematika kelas 3 SMU berikut ini:
2, 4, 5, 6, 6, 7, 7, 7, 8, 9
2, 4, 6, 6, 6, 7, 7, 7, 8, 9
2, 4, 6, 6, 6, 7, 8, 8, 8, 9
2, 4, 5, 5, 6, 7, 7, 8, 8, 9
1, 2, 3, 4, 5, 6, 7, 8, 9, 10
Jawab:
2, 4, 5, 6, 6, 7, 7, 7, 8, 9→ Nilai yang sering muncul adalah angka 7 (frekuensi terbanyak =
3), sehingga Modus (M) = 7
2, 4, 6, 6, 6, 7, 7, 7, 8, 9→ Nilai yang sering muncul adalah angka 6 dan 7 (masing-masing
muncul 3 kali), sehingga Modusnya ada dua, yaitu 6 dan 7. Gugus data tersebut dikatakan
bimodal karena mempunyai dua modus. Karena ke-2 mode tersebut nilainya berurutan,
mode sering dihitung dengan menghitung nilai rata-rata keduanya, ½ (6+7) = 6.5.
2, 4, 6, 6, 6, 7, 8, 8, 8, 9→ Nilai yang sering muncul adalah angka 6 dan 8 (masing-masing
muncul 3 kali), sehingga Modusnya ada dua, yaitu 6 dan 8. Gugus data tersebut dikatakan
bimodal karena mempunyai dua modus. Nilai mode tunggal tidak dapat dihitung karena
ke-2 mode tersebut tidak berurutan.
2, 4, 5, 5, 6, 7, 7, 8, 8, 9→ Nilai yang sering muncul adalah angka 5, 6 dan 7 (masing-
masing muncul 2 kali), sehingga Modusnya ada tiga, yaitu 5, 6 dan 7. Gugus data tersebut
dikatakan multimodal karena modusnya lebih dari dua.

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 17
1, 2, 3, 4, 5, 6, 7, 8, 9, 10 → Pada gugus data tersebut, semua frekuensi data sama,
masing-masing muncul satu kali, sehingga gugus data tersebut dikatakan tidak
mempunyai modusnya
b) Mode dalam Distribusi Frekuensi:
dimana:
Mo = modal = kelas yang memuat modus
b = batas bawah kelas modal
p = panjang kelas modal
bmo = frekuensi dari kelas yang memuat modus (yang nilainya tertinggi)
b1= bmo – bmo-1 = frekuensi kelas modal – frekuensi kelas sebelumnya
b2 = bmo – bmo+1 = frekuensi kelas modal – frekuensi kelas sesudahnya
Contoh:
Tentukan nilai median dari tabel distribusi frekuensi pada Contoh 3 di atas!
Jawab:
Kelas ke- Nilai Ujian fi
1 31 – 40 2
2 41 – 50 3
3 51 – 60 5
4 61 – 70 13
→ b1 = (24 – 13) = 11
5 71 – 80 24 ← kelas modal (frekuensinya paling besar)
→ b2 =(24 – 21) =3
6 81 – 90 21
7 91 – 100 12
8 Jumlah 80
Kelas modul =kelas ke-5
b = 71-0.5 = 70.5; b1 = 24 -13 = 11; b2 = 24 – 21 = 3
p = 10

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 18
4. Varian dan Standar Deviasi
Salah satu ukuran variabilitas (measure of dispersion) yang paling sering digunakan jika
data yang diukur berskala interval adalah varians. Varians didefinisikan sebagai rata-rata dari
skor penyimpangan kuadrat. Untuk mencari varians, dibedakan antara varians populasi yang
dilambangkan dengan (σ2) dengan varians sample yang dilambangkan dengan (s2).
Untuk varians populasi, dapat dicari dengan rumus:
Dimana:
µ = rata-rata populasi
N = total jumlah populasi
Adapun varians untuk sample dapat dicari dengan rumus yang sama namun
mengurangkan N dengan 1 sebagai berikut:
Dimana :
s = rata-rata sample
n = jumlah sampel yang digunakan
Untuk lebih memperjelas, baiklah kita coba dengan menghitung varians untuk populasi
jika kita memiliki data pengukuran tentang nilai 5 siswa pada mata pelajaran matematika
sebagai berikut:
7; 7; 9; 8; 6
Untuk menghitung varians dari data di atas maka kita harus mencari dahulu berapa
mean (rata-rata) dari. Dengan rata-rata 6,9 maka kita tinggal memasukkan data di atas sebagai
berikut:
Dengan varian sebesar 1,3 maka untuk mencari standar deviasi kita tinggal mengakar
kuadratkan 1,3 yang akan menghasilkan 1,14. Karena varian adalah ukuran keberagaman data,

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 19
maka semakin besar angkat varians maka semakin beragamlah data yang kita miliki dan
semakin kecil nilai varians maka semakin homogenlah data yang kita miliki.
Nah, jika seandainya nilai varians yang kita miliki ternyata adalah 0, maka dapat
disimpulkan bahwa dalam populasi atau sampel yang kita miliki tidak terdapat variabilitas.
Keadaan demikian dapat terjadi jika sekor untuk setiap sampel/populasi adalah sama.
Selain rumus di atas, kita juga dapat menggunakan rumus-rumus lain untuk mencari
varians. Pada dasarnya, pemilihan rumus yang digunakan tergantung pengguna yang merasakan
rumus manakah yang paling mudah digunakan. Rumus-rumus yang lain tersebut diantaranya
adalah:
Untuk varians sampel:

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 20
UKURAN POSISI
1. Quartil (Q)
Suatu nilai yang membagi data dalam kelompok maisng-masing 25%, sehingga
kelompok data akan terbagi menjadi 4 bagian. Kelompok data terbagi menjadi 3 bagian yaitu:
Q1 : Quartil bawah
Q2: Quartil tengah
Q3: Quartil atas
Perhitungan Quartil:
Dimana:
LQi = batas tepi bawah nilai kelas Quartil ke i
Qi = Quartil ke i (i = 1;2;3)
n = jumlah data
i = nomor quartil ke i
∑fQi = jumlah frekuensi sebelum kelas quartil
fQi = frekuensi kelas kuartil
c = interval kelas
2. Quentil (q)
Quentil membagi data menjadi 5 bagian masing-masing 20% dari tabel data. Maka
jumlah sekelompok data mempunyai 4 Quentil yaitu q1, q2, q3, dan q4.
Perhitungan Quensil:
Dimana:
Lqi = batas tepi bawah nilai kelas Quensil ke i
qi = Qensil ke i (i = 1;2;3;4)
n = jumlah data
i = nomor quensil ke i
∑fqi = jumlah frekuensi sebelum kelas quensil

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 21
fqi = frekuensi kelas quensil
c = interval kelas
3. Desil (d)
Desil membagi sekelompok data menjadi 10 bagian, sehingga masing-masing bagian
10%. Berarti sekelompok data mempunyai 9 desil d1, d2,d3,......d9.
Perhitungan Desil:
Dimana:
Ldi = batas tepi bawah nilai kelas desil ke i
di = desil ke i (i = 1;2;3;4;5;6;7;8;9)
n = jumlah data
i = nomor desil ke i
∑fdi = jumlah frekuensi sebelum kelas desil
fdi = frekuensi kelas desil
c = interval kelas
4. Persentil (p)
Persentil membagi sederetan data menjadi 100 bagian yang masing-masing bagian 1%.
Berarti sekelompok data mempunyai 99 persentil, yaitu p1, p2, p3.......p99.
Perhitungan Persentil:
Dimana:
Lpi = batas tepi bawah nilai kelas persentil ke i
pi = desil ke i (i = 1;2;3;4;......99)
n = jumlah data
i = nomor desil ke i
∑fpi = jumlah frekuensi sebelum kelas desil
fpi = frekuensi kelas desil
c = interval kelas

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 22
PROBABILITAS
Konsep probabilitas (peluang) mulanya berkembang dari judi, namun demikian dalam
perkembangannya mempunyai peranan penting dalam ilmu pengetahuan dan kehidupan sehari-hari.
Menurut BJ Randel: Probabilitas diartikan sebagai suatu nilai yang dipergunakan untuk mengukur
tingkat peluang terjadinya kejadian yang random
Suatu proses disebut random, bila hasil proses tersebut tidak dapat ditentukan sebelumnya
dengan pasti, dan terjadinyapun tidak dapat ditentukan dengan pasti. Sehingga nilai peluang
tersebut hanya dapat dipakai sebagai ukuran untuk memprediksi peluang yang akan terjadi dalam
suatu kejadian. (Hifni, 1990)
1. Nilai Peluang
Apabila suatu event (E) dapat terjadi sebanyak h kali sejumlah n cara peluang yang sama,
maka peluang event tersebut dapat terjadi atau tidak dapat ditulis:
Jika Pr(E) ditulis dengan simbol p (dapat terjadi/succeed) dan Pr(bukan E) disimbolkan q
(gagal/failure) maka p+q=1
Contoh: bila sebuah dadu dilempar, berapa peluang muncul mata dadu 5?
Jawab : Dadu memiliki 6 sisi, dan masing-masing sisi tertulis nilai 1-6. Maka tiap pelemparan
tiap sisi menpunyai nilai peluang yang sama. Berarti ada 6 cara untuk muncul. Harapan
munculnya mata dadu 5 adalah 1 dari 6 kejadian tersebut maka peluangnya adalah
p=1/6 dan peluang tidak munculnya angka 5 adalah q=1-1/6=5/6.
2. Analisa Kombinatorial
a) Permutasi
Permutasi r unsur yang diambil dari n unsur yang berlainan ialah penempatan r
unsur tersebut dalam suatu urutan (r>n).
b) Kombinasi
Jika permutasi unsur-unsur tersebut disusun tidak mempermasalahkan urutan maka
pada kombinasi, urutan pasangan dipermasalahkan.

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 23
Persamaan permutasi dan kombinasi:
3. Distribusi Kemungkinan
Apabila nilai kemungkinan menggambarkan nilai dari suatu kejadian, maka seluruh nilai
kejadian dapat digambarkan dengan distribusi tersebut.
Dalam berbagai peristiwa probabilitas yang bersifat independen dan dependen akan
mengalamai kesulitan dalam penghitungan jika frekuensi percobaannya cukup banyak (bekali-
kali). Apalagi untuk peristiwa yang bersifat independen dengan frekuensi percobaan yang tidak
terhingga (tidak terbatas). Untuk menjawab permasalahan tersebut, maka digunakan Distribusi
Kemungkinan untuk penyelesaian secara sederhana. Untuk membahas distribusi kemungkinan,
terlebih dahulu harus dapat membedakan antara Variabel Diskrit dengan Variabel Kontinyu.
Variabel Diskrit merupakan variabel yang mempunyai angka-angka bulat. Misalnya
jumlah mahasiswa sebanyak 60 orang, dia pergi ke Jakarta sebanyak 4 kali dan lain-lain. Dalam
variabel diskrit berlaku ketentuan X > 5 tidak sama X >= 5. Sedangkan yang dimaksud dengan
Variabel Kontinyu adalah suatu variabel yang mempunyai nilai berkesinambungan
(antara variabel satu dengan variabel selanjutnya tidak mempunyai jarak). Misalnya panjang
jalan itu 25,73 km, perusahaan itu sudah berusia 5 tahun, 8 bulan, 25 hari. Dalam variabel
kontinyu berlaku ketentuan X > 5 sama dengan X >= 5. Dengan demikian variabel kontinyu
dapat dikatakan mempunyai nilai yang kecilnya tidak terhingga dan besarnya juga tidak
terhingga.Dalam bab ini pembahasan distribusi kemungkinan lebih difokuskan pada :
a) Variabel Diskrit :
Peristiwa Dependen : Distribusi Hipergeometris.
Peristiwa Independen : Distribusi Binomial, Distribusi Multinomial dan Distribusi
Poisson.
b) Variabel Kontinyu :
Peristiwa Independen : Distribusi Normal

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 24
4. Distribusi Hipergeometris
Distribusi Hipergeometris digunakan untuk menghitung probabilitas dari peristiwa yang
bersifat dependen (bersyarat) dan variabelnya bersifat diskrit. Rumus yang digunakan : P(x1, x2,
…, xi) = (n1Cx1.n2Cx2 … niCxi)/(nCx); dimana x1, x2, … xi : banyaknya peristiwa yang diharapkan
terjadi dari setiap peristiwa; n1, n2, …ni : banyaknya seluruh frekuensi yang dapat terjadi dari
setiap peristiwa; n = n1 + n2 + … + ni; dan x = x1 + x2 + … + xi.
Contoh :
Sebuah kotak berisi 10 bola, yang terdiri 4 bola warna merah dan 6 bola warna hitam. Jika
diambil sebanyak 3 bola secara berturut-turut (tanpa dikembalikan) berapa probabilitas
terambil bola 2 warna merah dan 1 warna hitam.
Jawab :
X1 = kejadian bola warna merah
X2 = kejadian bola warna hitam
P(2 ; 1) = ((4C2).(6C1))/(10C3) = 36/120 = 0,3
5. Distribusi Binomial
Distribusi Binomial digunakan untuk menghitung peristiwa-peristiwa yang bersifat independen
dengan variabel yang bersifat diskrit. Rumus yang digunakan adalah :

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 25
REGRESI
Regresi adalah metode statistika yang digunakan untuk membentuk model hubungan antara
variabel terikat (dependen; respon; Y) dengan satu atau lebih variabel bebas (independen, prediktor,
X). Apabila banyaknya variabel bebas hanya ada satu, disebut sebagai regresi linier sederhana,
sedangkan apabila terdapat lebih dari 1 variabel bebas, disebut sebagai regresi linier berganda.
Analisis regresi setidak-tidaknya memiliki 3 kegunaan, yaitu untuk tujuan deskripsi dari
fenomena data atau kasus yang sedang diteliti, untuk tujuan kontrol, serta untuk tujuan prediksi.
Regresi mampu mendeskripsikan fenomena data melalui terbentuknya suatu model hubungan yang
bersifatnya numerik. Regresi juga dapat digunakan untuk melakukan pengendalian (kontrol)
terhadap suatu kasus atau hal-hal yang sedang diamati melalui penggunaan model regresi yang
diperoleh. Selain itu, model regresi juga dapat dimanfaatkan untuk melakukan prediksi untuk
variabel terikat.
Namun, yang perlu diingat, prediksi di dalam konsep regresi hanya boleh dilakukan di dalam
rentang data dari variabel-variabel bebas yang digunakan untuk membentuk model regresi tersebut.
Misal, suatu model regresi diperoleh dengan mempergunakan data variabel bebas yang memiliki
rentang antara 5 s.d. 25, maka prediksi hanya boleh dilakukan bila suatu nilai yang digunakan
sebagai input untuk variabel X berada di dalam rentang tersebut. Konsep ini disebut sebagai
interpolasi.
1. Regresi Linear
Regresi Linear digunakan untuk menentukan fungsi linier yang paling sesuai dengan
kumpulan titik data (xn,yn) yang diketahui.
Untuk mendapatkan fungsi linier y=mx+c, dicari nilai m dan c
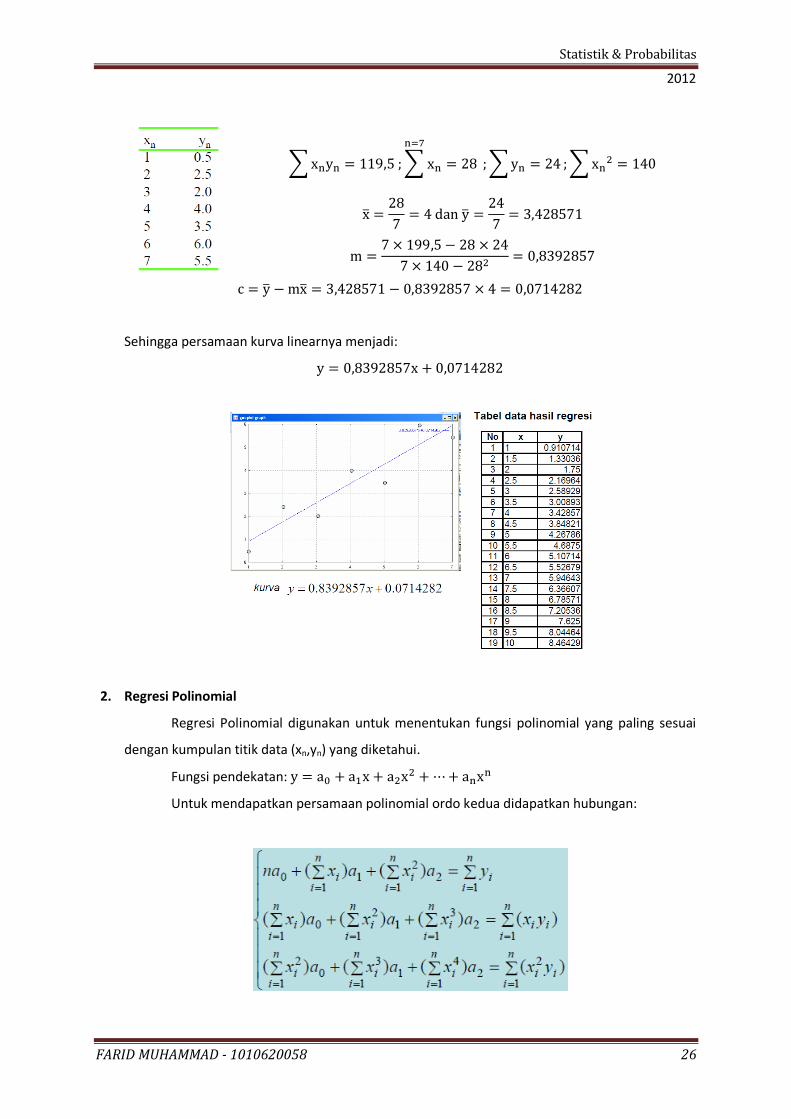
Contoh penyelesaian analisis regresi linear:
Carilah persamaan kurva linier jika diketahui data untuk x dan y sebagai berikut:
Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 26
Sehingga persamaan kurva linearnya menjadi:
2. Regresi Polinomial
Regresi Polinomial digunakan untuk menentukan fungsi polinomial yang paling sesuai
dengan kumpulan titik data (xn,yn) yang diketahui.
Fungsi pendekatan:
Untuk mendapatkan persamaan polinomial ordo kedua didapatkan hubungan:
Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 27
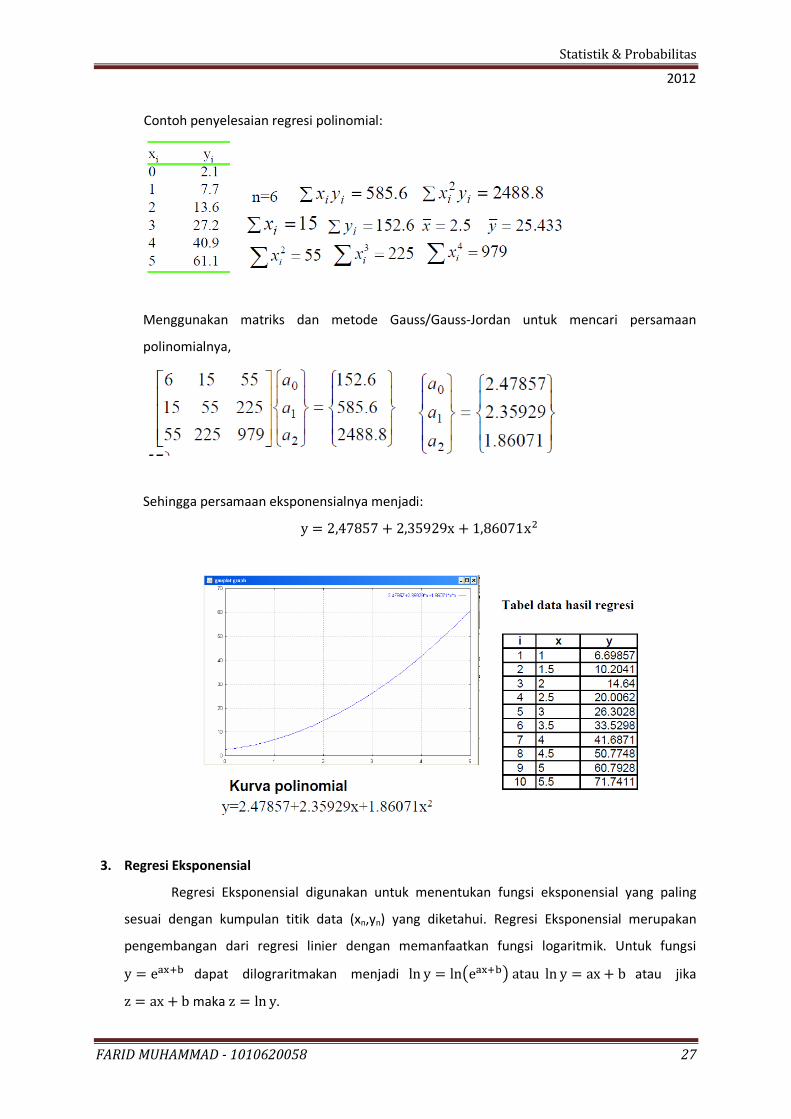
Contoh penyelesaian regresi polinomial:
Menggunakan matriks dan metode Gauss/Gauss-Jordan untuk mencari persamaan
polinomialnya,
Sehingga persamaan eksponensialnya menjadi:
3. Regresi Eksponensial
Regresi Eksponensial digunakan untuk menentukan fungsi eksponensial yang paling
sesuai dengan kumpulan titik data (xn,yn) yang diketahui. Regresi Eksponensial merupakan
pengembangan dari regresi linier dengan memanfaatkan fungsi logaritmik. Untuk fungsi
dapat dilograritmakan menjadi atau jika
maka .
Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 28
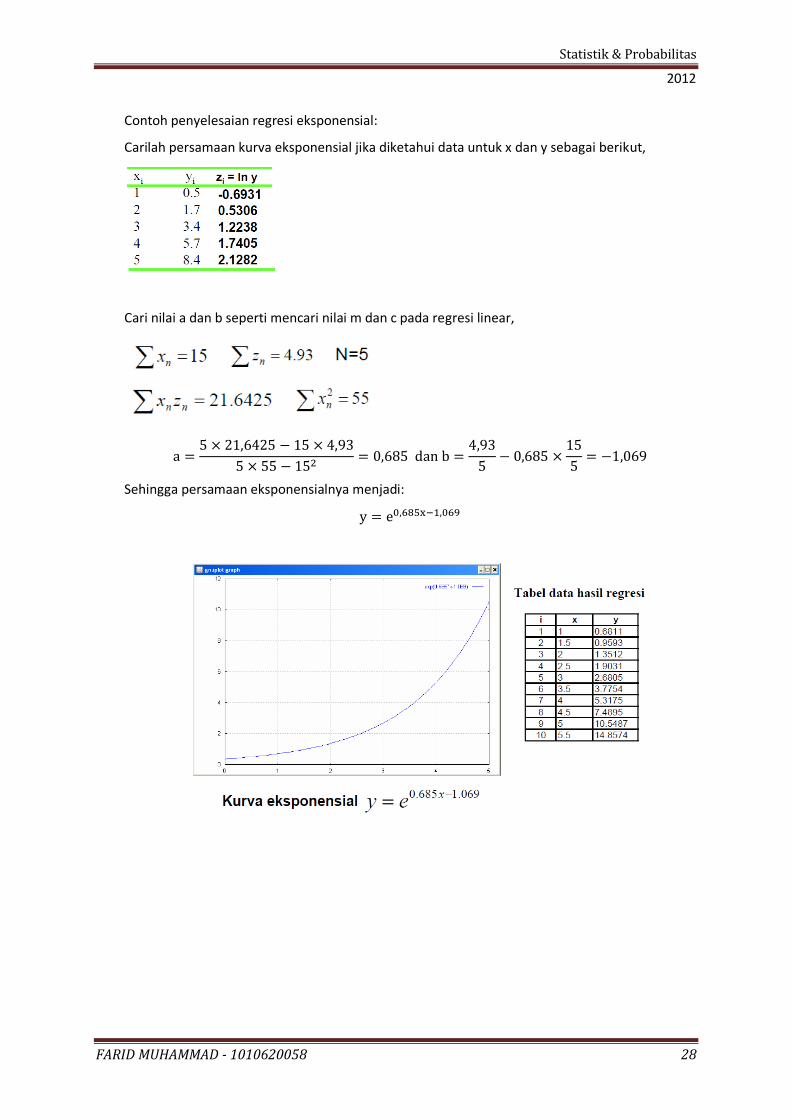
Contoh penyelesaian regresi eksponensial:
Carilah persamaan kurva eksponensial jika diketahui data untuk x dan y sebagai berikut,
Cari nilai a dan b seperti mencari nilai m dan c pada regresi linear,
Sehingga persamaan eksponensialnya menjadi:

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 29
PENGUJIAN HIPOTESIS
1. Hipotesis
Hipotesis statistik adalah pernyataan atau dugaan mengenai satu atau lebih populasi.
Pengujian hipotesis berhubungan dengan penerimaan atau penolakan suatu hipotesis. Kebenaran
(benar atau salahnya ) suatu hipotesis tidak akan pernah diketahui dengan pasti, kecuali kita
memeriksa seluruh populasi. (Memeriksa seluruh populasi? Apa mungkin?) Lalu apa yang kita
lakukan, jika kita tidak mungkin memeriksa seluruh populasi untuk memastikan kebenaran suatu
hipotesis? Kita dapat mengambil contoh acak, dan menggunakan informasi (atau bukti) dari
contoh itu untuk menerima atau menolak suatu hipotesis.
Penerimaan suatu hipotesis terjadi karena tidak cukup bukti untuk menolak hipotesis
tersebut dan bukan karena hipotesis itu benar. Sedangkan penolakan suatu hipotesis terjadi
karena tidak cukup bukti untuk menerima hipotesis tersebut dan bukan karena hipotesis itu salah.
Landasan penerimaan dan penolakan hipotesis seperti ini, yang menyebabkan para statistikawan
atau peneliti mengawali pekerjaan dengan terlebih dahulu membuat hipotesis yang diharapkan
ditolak, tetapi dapat membuktikan bahwa pendapatnya dapat diterima.
Hipotesis dibedakan menjadi dua macam yaitu Hipotesis Nol (H0) yang menyatakan
hipotesis yang diuji dan Hipotesis Alternatif (H1). H0 harus berupa satu nilai parameter dari suatu
populasi (rata-rata atau varians). H1 bisa merupakan beberapa kemungkinan nilai parameter.
2. Kesalahan
Kesalahan jenis 1: suatu kesalahan bila menolak H0 yang benar (seharusnyaditerima), tingkat
kesalahan ini dinyatakan dalam α.
Kesalahan jenis2: suatu kesalahan bila menerima H0 yang salah (seharusnyaditolak), tingkat
kesalahan ini dinyatakan dalamβ.
Biasanya tingkat kesalahan yang diambil dinamakan dengan tingkat signifikasi yaitu
antara 1% sampai dengan 5%. Suatu hipotesa dikatakan terbukti dengan tingkat kesalahan 1%
Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 30
bila dilakukan pada 100 kali pengambilan sample dari populasi yang sama hanya mendapatkan
satu kesimpulan yang salah.
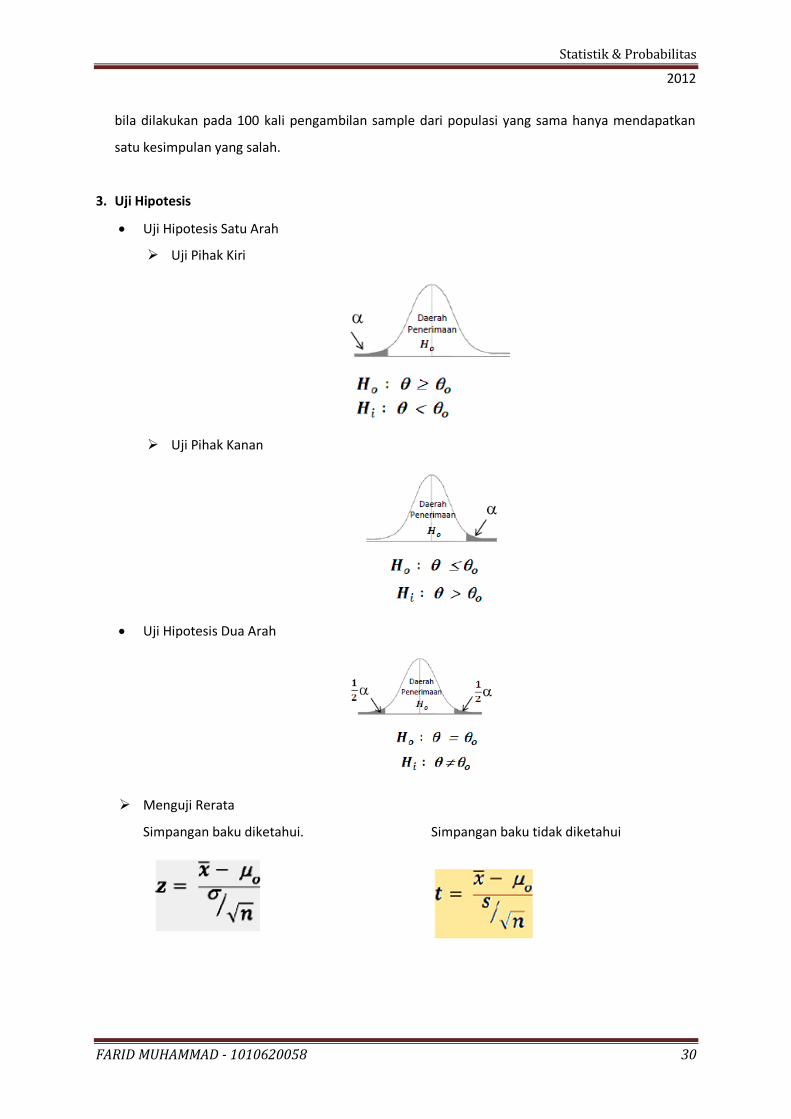
3. Uji Hipotesis
Uji Hipotesis Satu Arah
Uji Pihak Kiri
Uji Pihak Kanan
Uji Hipotesis Dua Arah
Menguji Rerata
Simpangan baku diketahui. Simpangan baku tidak diketahui

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 31
4. Ilustrasi Kasus
Pengusaha lampu pijar A mengatakan bahwa lampunya memiliki masa pakai 800 jam. Akhir-akhir
ini timbul dugaan bahwa masa pakai lampu itu berubah. Untuk menentukan hal ini, dilakukan
penyelidikan dengan menguji 50 lampu, ternyata reratanya 792 jam. Dari pengalaman, diketahui
bahwa simpangan baku masa hidup lampu 60 jam.
a. Selidikilah dengan taraf nyata 0,05, apakah kualitas lampu itu telah berubah atau belum.
b. Bagaimana dengan taraf nyata 0,01?
Jawab:

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 32
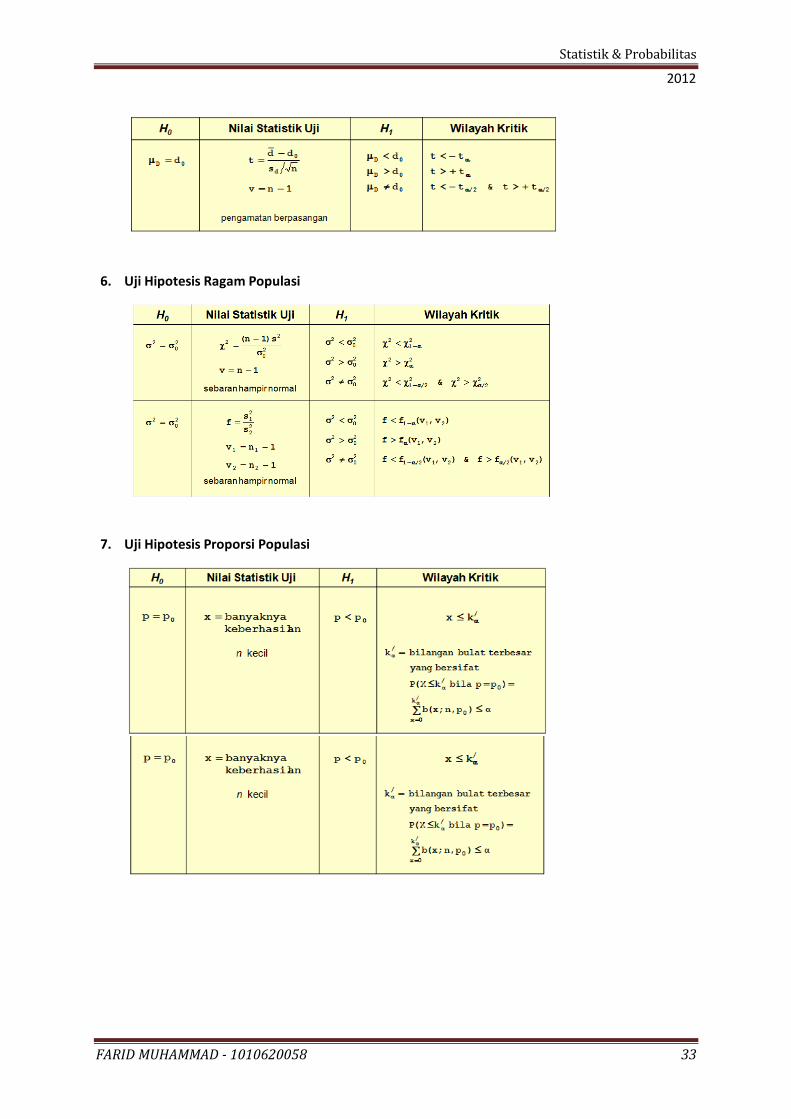
5. Uji Hipotesis Nilai Tengah Populasi
Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 33
6. Uji Hipotesis Ragam Populasi
7. Uji Hipotesis Proporsi Populasi

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 34

Statistik & Probabilitas 2012
FARID MUHAMMAD - 1010620058 35
DAFTAR PUSTAKA
Anonymous. 2011. “Ukuran Pemusatan Data: Mean, Median & Mode”. http://www.smartstat.info/
statistika/ statisika-deskriptif/ukuran-pemusatan-data-mean-median-mode.html (diakses
pada tanggal 14 Maret 2012)
Basuki, Achmad. 2006. “Statistik dan Probabilitas: Uji Hipotesa”. Surabaya: PENS-ITS
Hifni. 1990. “Metode Statistika”. Malang: Kopma Unibraw
Kurniawan, Deni. 2008. “Regresi Linier”. http://ineddeni.wordpress.com (diakses pada tanggal 20
April 2012)
Manado, Djunaidi. 2010. “Varian dan Standar Deviasi” http://statistikpendidikanii.blogspot.com/
2010/07/varian-dan-standar-deviasi.html (diakses pada tanggal 14 Maret 2012)
Montgomery, Douglas & Runger, George. 2003. “Applied Statistics and Probability for Engineers”.
New York: John Wiley & Sons Inc.
Nasution, Rozaini. 2003. “Teknik Sampling”. Medan: USU Digital Library
Nurtama, Budi; Suyatma, Nugraha Edhi. _____. “Uji Hipotesis”. Bogor: IPB
Pramono, Supriyoko. ____. “Modul Kuliah Statistik & Probabilitas”. http://sangiang.files.wordpress.
com /2008/11/stat_pro_modul_1.doc (diakses pada tanggal 6 Maret 2012)
Santoso, Slamet. 2009. “Distribusi Kemungkinan”. http://ssantoso.blogspot.com/2009/03/materi-iv-
distribusi-kemungkinan-1.html (diakses pada tanggal 28 Maret 2012)
Soong, T.T. 2004. “Fundamentals of Probability and Statistics for Engineers”. New York: John Wiley &
Sons Inc.
Wikipedia. 2012. “Probability”. http://en.wikipedia.org/wiki/Probability (diakses pada tanggal 26
Februari 2012)