prediksi berita palsu menggunakan metode …
TRANSCRIPT

PREDIKSI BERITA PALSU MENGGUNAKAN METODE
CONVOLUTION NEURAL NETWORK
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Informatika
Oleh:
Hieronimus Fredy Morgan
175314080
PROGRAM STUDI INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2021
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

ii
FAKE NEWS PREDICTION USING THE CONVOLUTION NEURAL
NETWORK METHOD
THESIS
Present as Partial Fulfillment of The Requirements
to Obtain Sarjana Komputer Degree
in Informatics Study Program
Created by:
Hieronimus Fredy Morgan
175314080
INFORMATICS STUDY PROGRAM
INFORMATICS DEPARTMENT
FACULTY OF SCIENCE OF TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
2021
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

v
HALAMAN PERSEMBAHAN
SEBAB BAGI ALLAH TIDAK ADA YANG
MUSTAHIL
~LUKAS 1:37~
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

viii
ABSTRAK
Suatu berita dapat dengan mudah diakses melalui berbagai media, baik
media cetak maupun media elektronik. Tingkat persebaran berita melalui media
cetak dan media elektronik sangat berbeda. Persebaran berita di media elektronik
sangatlah tinggi karena berita tersebut sangat mudah diakses oleh masyarakat
umum, khususnya melalui media sosial. Kemudahan mengakses berita
menyebabkan munculnya banyak berita palsu.
Berita palsu bukan sekedar misleading alias menyesatkan. Informasi yang
dimuat pada berita palsu juga tidak memiliki landasan faktual, namun disajikan
seolah-olah sebagai serangkaian fakta atau suatu kebenaran. Oleh sebab itu, peneliti
mencoba melakukan prediksi berita palsu dengan mengklasifikasi berita. Penelitian
ini bertujuan untuk mengetahui prediksi berita menggunakan pendekatan
Convolution Neural Network serta akurasi dari pendekatan Convolution Neural
Network.
Pada penelitian ini terdiri dari tiga tahapan. Tahapan pertama adalah
preprocessing yang terdiri dari case folding, stemming, tokenizing, stopwords
removal, punctuation removal. Tahapan kedua adalah ekstraksi ciri dengan
menghitung term frequency dan invers document frequency. Tahapan ketiga yaitu
melakukan klasifikasi berita dengan pendekatan Convolution Neural Network.
Hasil yang diperoleh dengan pendekatan Convolution Neural Network
menggunakan 12-Layers mendapatkan hasil yang optimal, dengan akurasi rata –
rata sebesar 0.8507.
Kata kunci: Convolution Neural Network, Term Frequency, Invers Document
Frequency, klasifikasi.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

ix
ABSTRACT
News can be easily accessed through various media, such as print media and
electronic media. The level of news spreading through print media and electronic
media is very different. The spread of news in electronic media is very high because
the news is very easily accessible to the public, especially through social media.
The ease of accessing news led to the emergence of many fake news.
Fake news is not just something that is misleading. The information
contained in fake news also does not have a factual basis, but it is presented as if it
were a fact or a truth. Therefore, the writer tries to predict fake news by classifying
the news. This study aims to determine news predictions using the Convolution
Neural Network approach and the accuracy of the Convolution Neural Network
approach.
This research consists of three stages. The first stage is preprocessing which
consists of case folding, stemming, tokenizing, stopwords removal, and punctuation
removal. The second stage is feature extraction by calculating term frequency and
inverse document frequency. The third stage is classifying the news with the
Convolution Neural Network approach. The results obtained with the Convolution
Neural Network approach using 12-Layers get optimal results with an average
accuracy of 0.8507.
Keywords: Convolution Neural Network, Term Frequency, Invers Document
Frequency, classification.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

x
KATA PENGANTAR
Puji dan syukur penulis panjatakan kepada Tuhan Yang Maha Esa atas
rahmat dan karunia-Nya, sehingga penulis dapat menyelesaikan tugas akhir dengan
judul “Prediksi Berita Palsu Menggunakan Metode Convolution Neural Network”
dengan baik dan tepat waktu. Tugas akhir ini merupakan salah satu persyaratan
yang wajib untuk ditempuh sebagai syarat akademik untuk memperoleh gelar
sarjana komputer program studi Informatika Universitas Sanata Dharma
Yogyakarta.
Selama proses penelitian, penulis mendapat banyak dukungan dari berbagai
pihak sehingga sudah sepantasnya penulis menyampaikan terima kasih kepada:
1. Romo Dr. Cyprianus Kuntoro Adi, S.J. M.A., M.Sc. selaku dosen
pembimbing tugas akhir yang telah bersedia memberikan arahan, masukan,
waktu serta motivasi kepada penulis selama menyelesaikan skripsi.
2. Bapak Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D. selaku dekan Fakultas
Sains dan Teknologi.
3. Seluruh dosen Informatika Universitas Sanata Dharma yang telah mendidik
dan memberikan ilmu pengetahuan kepada penulis yang digunakan sebagai
bekal untuk menyelesaikan tugas akhir ini.
4. Keluarga tercinta, Papah Damianus Barus, Mamah Sesila Tity Suziana,
Kakak ATM Berjalan Yesica Fridiani Claudia Dasti, dan Adik
menggemaskan Gaudentius Aracello Fagan yang selalu memberikan
dukungan dan doa sehingga membuat penulis semakin semangat dalam
mengerjakan serta menyelesaikan tugas akhir ini.
5. Saudara Gabriel Ryan Prima, Atanasius Ivan Noel Rio Aji, Yudistira Prama
Putra, Edrick Hernando, Albertus Ivan Adhyatma Maheswara, Nivea Galuh
Iswarin yang selalu bisa diajak diskusi masalah tugas akhir
6. Bernadetta Astrid Widyasari yang selalu memberikan semangat, dukungan,
makanan, dan waktunya agar penulis selalu semangat untuk menyelesaikan
skripsi ini
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xii
DAFTAR ISI
HALAMAN PERSETUJUAN PEMBIMBING ....................................................... iii
HALAMAN PENGESAHAN .................................................................................. iv
HALAMAN PERSEMBAHAN ................................................................................ v
PERNYATAAN KEASLIAN KARYA ................................................................... vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH .... vii
ABSTRAK .............................................................................................................. viii
ABSTRACT .............................................................................................................. ix
KATA PENGANTAR ............................................................................................... x
DAFTAR ISI ............................................................................................................ xii
DAFTAR GAMBAR .............................................................................................. xvi
DAFTAR TABEL ................................................................................................... xix
BAB I PENDAHULUAN ......................................................................................... 1
1.1. Latar Belakang............................................................................... 1
1.2. Rumusan Masalah ......................................................................... 3
1.3. Tujuan Penelitian ........................................................................... 3
1.4. Manfaat Penelitian ......................................................................... 3
1.5. Batasan Masalah ............................................................................ 4
1.6. Sistematika Penelitian ................................................................... 4
BAB II LANDASAN TEORI ................................................................................... 6
2.1 Berita ............................................................................................. 6
2.2 Berita Palsu .................................................................................... 7
2.3 Information Retrieval .................................................................... 8
2.4 Natural Language Processing ..................................................... 10
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xiii
2.4.1 Case Folding ............................................................... 11
2.4.2 Stemming ..................................................................... 11
2.4.3 Tokenizing ................................................................... 12
2.4.4 Stopwords Removal ..................................................... 12
2.4.5 Normalization ............................................................. 13
2.4.6 Punctuation Removal .................................................. 13
2.5 Feature Extraction....................................................................... 14
2.5.1. Model Boolean ............................................................ 14
2.5.2. Model Ruang Vektor ................................................... 14
2.5.3. Model Probabilistik ..................................................... 19
2.6 Machine Learning ....................................................................... 22
2.7 Jaringan Syaraf Tiruan ................................................................ 23
2.7.1. Komponen Neural Network ........................................ 24
2.7.2. Arsitektur Neural Network .......................................... 26
2.7.3. Fungsi Aktivasi ........................................................... 28
2.8 Deep Learning ............................................................................. 31
2.9 Convolution Neural Network ....................................................... 32
2.9.1. Embedding Layer ........................................................ 33
2.9.2. Convolution Layer ...................................................... 34
2.9.3. Operasi Pooling ........................................................... 37
2.9.4. Fully Connected Layer ................................................ 38
2.9.5. Softmax Classifier ....................................................... 38
2.10 Word Embedding......................................................................... 41
2.11 Pengukuran Performa .................................................................. 44
BAB III METODE PENELITIAN .......................................................................... 47
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xiv
3.1. Deskripsi Data ............................................................................. 47
3.2. Kebutuhan Perangkat Hardware dan Software ............................ 47
3.3. Perancangan Sistem ..................................................................... 48
3.3.1. Preprocessing .............................................................. 48
3.3.2. Feature Extraction ....................................................... 55
3.3.3. Klasifikasi ................................................................... 59
3.3.4. Convolution Neural Network ...................................... 60
3.3.5. Pengukuran Performa .................................................. 66
3.3.6. Prediksi ....................................................................... 68
3.4. Cara Pengujian............................................................................. 69
3.5. Desain User Interface .................................................................. 70
3.5.1. Input GUI .................................................................... 70
3.5.2. Output GUI ................................................................. 70
BAB IV HASIL DAN ANALISIS ......................................................................... 71
4.1. Data.............................................................................................. 71
4.2. Implementasi Preprocessing ........................................................ 73
4.2.1. Case Folding ............................................................... 73
4.2.2. Stemming .................................................................... 74
4.2.3. Tokenizing .................................................................. 76
4.2.4. Stopwords Removal .................................................... 78
4.2.5. Punctuation Removal .................................................. 80
4.3. Implementasi Pembagian Data .................................................... 82
4.4. Implementasi Feature Extraction ................................................. 83
4.4.1. TF - IDF ...................................................................... 83
4.5. Implementasi Convolution Neural Network ............................... 85
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xv
4.6. Implementasi Pengukuran Performa ........................................... 90
4.7. Hasil Penelitian ............................................................................ 92
4.7.1. Skenario Pertama ........................................................ 92
4.7.2. Skenario Kedua ........................................................... 95
4.7.3. Skenario Ketiga ........................................................... 98
4.7.4. Skenario Keempat ..................................................... 100
4.7.5. Skenario Kelima ........................................................ 103
4.8. Implementasi GUI ..................................................................... 106
BAB V KESIMPULAN DAN SARAN ............................................................... 109
5.1. Kesimpulan ................................................................................ 109
5.2. Saran .......................................................................................... 109
DAFTAR PUSTAKA ............................................................................................ 109
LAMPIRAN ........................................................................................................... 111
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xvi
DAFTAR GAMBAR
Gambar 2. 1 Contoh Sederhana Model Ruang Vektor (Zhai & Massung, 2016) . 15
Gambar 2. 2 Ranking Dokumen Model Ruang Vektor (Zhai & Massung, 2016) 16
Gambar 2. 3 Term Frequency (Zhai & Massung, 2016) ....................................... 17
Gambar 2. 4 Invers Document Frequency ............................................................ 19
Gambar 2. 5 Weight TF - IDF............................................................................... 19
Gambar 2. 6 Perhitungan Model Probabilistik...................................................... 20
Gambar 2. 7 Jaringan Syaraf ................................................................................. 23
Gambar 2. 8 Struktur Neural Network .................................................................. 24
Gambar 2. 9 Single Layer Neural Network .......................................................... 27
Gambar 2. 10 Multiple Layers Neural Network ................................................... 27
Gambar 2. 11 Competitive Layers ........................................................................ 28
Gambar 2. 12 Fungsi Aktivasi linear .................................................................... 28
Gambar 2. 13 Fungsi Aktivasi Sigmoid ................................................................ 29
Gambar 2. 14 Fungsi aktivasi Tanh ...................................................................... 30
Gambar 2. 15 Fungsi Aktivasi ReLU.................................................................... 30
Gambar 2. 16 Arsitektur Convolution Neural Network ........................................ 33
Gambar 2. 17 Convolution Layer ......................................................................... 35
Gambar 2. 18 Iterasi 1 Conv Layer ....................................................................... 35
Gambar 2. 19 Iterasi 2 Conv Layer ....................................................................... 36
Gambar 2. 20 Iterasi 3 Conv Layer ....................................................................... 36
Gambar 2. 21 Iterasi 4 Conv Layer ....................................................................... 36
Gambar 2. 22 Pooling Layer ................................................................................. 37
Gambar 2. 23 Fully Connected Layer ................................................................... 38
Gambar 2. 24 Softmax Classifier .......................................................................... 40
Gambar 2. 25 Arsitektur Skip-Gram ..................................................................... 43
Gambar 3. 1 Data .................................................................................................. 47
Gambar 3. 2 Diagram Perancangan Sistem .......................................................... 48
Gambar 3. 3 Diagram Preprocessing .................................................................... 49
Gambar 3. 4 Diagram Feature Extraction ............................................................. 55
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xvii
Gambar 3. 5 Contoh Hasil Term Frequency ......................................................... 56
Gambar 3. 6 Contoh Hasil Document Frecuency ................................................. 57
Gambar 3. 7 Contoh Hasil Weight TF-IDF .......................................................... 58
Gambar 3. 8 Diagram Klasifikasi ......................................................................... 59
Gambar 3. 9 Diagram Convolution Neural Network ............................................ 60
Gambar 3. 10 Modelling Convolution Neural Network ....................................... 61
Gambar 3. 11 Hasil Representasi Word Embedding ............................................ 63
Gambar 3. 12 Convolution Layer ......................................................................... 63
Gambar 3. 13 Max Pooling Layer ......................................................................... 64
Gambar 3. 14 Flatten Layer .................................................................................. 65
Gambar 3. 15 Diagram Confusion Matrix ............................................................ 67
Gambar 3. 16 Confusion Matrix ........................................................................... 68
Gambar 3. 17 Diagram Prediksi ............................................................................ 68
Gambar 3. 18 Desain GUI..................................................................................... 70
Gambar 4. 1 Embedding Layer to Conv1D Layer ................................................ 86
Gambar 4. 2 Conv1D Layer to Max Pooling Layer .............................................. 87
Gambar 4. 3 MaxPooling Layer to Flatten Layer ................................................. 87
Gambar 4. 4 Flatten Layer to Dense Layer ........................................................... 88
Gambar 4. 5 Kompilasi Model Covolution Neural Network ................................ 90
Gambar 4. 6 Confusion Matrix ............................................................................. 92
Gambar 4. 7 Akurasi dan Confusion Matrix Percobaan 1 .................................... 94
Gambar 4. 8 Akurasi dan Confusion Matrix Percobaan 2 .................................... 94
Gambar 4. 9 Akurasi dan Confusion Matrix Percobaan 3 .................................... 95
Gambar 4. 10 Akurasi dan Confusion Matrix Percobaan 1 .................................. 96
Gambar 4. 11 Akurasi dan Confusion Matrix Percobaan 2 .................................. 97
Gambar 4. 12 Akurasi dan Confusion Matrix Percobaan 3 .................................. 97
Gambar 4. 13 Akurasi dan Confusion Matrix Percobaan 1 .................................. 99
Gambar 4. 14 Akurasi dan Confusion Matrix Percobaan 2 .................................. 99
Gambar 4. 15 Akurasi dan Confusion Matrix Percobaan 3 ................................ 100
Gambar 4. 16 Akurasi dan Confusion Matrix Percobaan 1 ................................ 101
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xviii
Gambar 4. 17 Akurasi dan Confusion Matrix Percobaan 2 ................................ 102
Gambar 4. 18 Akurasi dan Confusion Matrix Percobaan 3 ................................ 102
Gambar 4. 19 Akurasi dan Confusion Matrix Percobaan 1 ................................ 104
Gambar 4. 20 Akurasi dan Confusion Matrix Percobaan 2 ................................ 104
Gambar 4. 21 Akurasi dan Confusion Matrix Percobaan 3 ................................ 105
Gambar 4. 22 Tampilan Awal GUI ..................................................................... 106
Gambar 4. 23 Pengisian Text Field Judul dan Narasi ......................................... 107
Gambar 4. 24 Tampilan Prediksi Berita GUI ..................................................... 108
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xix
DAFTAR TABEL
Tabel 2. 1 Case Folding ........................................................................................ 11
Tabel 2. 2 Stemming ............................................................................................. 12
Tabel 2. 3 Tokenizing ........................................................................................... 12
Tabel 2. 4 Stopwords Removal ............................................................................. 13
Tabel 2. 5 Punctuation removal ............................................................................ 13
Tabel 2. 6 Confusion Matrix ................................................................................. 44
Tabel 3. 1 Case Folding ........................................................................................ 50
Tabel 3. 2 Stemming ............................................................................................. 51
Tabel 3. 3 Tokenizing ........................................................................................... 52
Tabel 3. 4 Stopwords Removal ............................................................................. 53
Tabel 3. 5 Punctuation Removal ........................................................................... 54
Tabel 3. 6 Setelah Preprocessing .......................................................................... 54
Tabel 3. 7 Proses Perhitungan Term Frequency ................................................... 56
Tabel 3. 8 Proses Perhitungan Invers Docoment Frequency ................................ 57
Tabel 3. 9 Proses Perhitungan Weight TF-IDF .................................................... 58
Tabel 3. 10 Contoh Representasi Word Embedding ............................................. 61
Tabel 3. 11 Contoh Hasil Prediksi Berita ............................................................. 67
Tabel 4. 1 Contoh Data ......................................................................................... 72
Tabel 4. 2 Case Folding ........................................................................................ 73
Tabel 4. 3 Stemming ............................................................................................. 75
Tabel 4. 4 Tokenizing ........................................................................................... 76
Tabel 4. 5 Stopwords Removal ............................................................................. 79
Tabel 4. 6 Punctuation Removal ........................................................................... 81
Tabel 4. 7 Tokenizer ............................................................................................. 83
Tabel 4. 8 List Sequence ....................................................................................... 83
Tabel 4. 9 Term Frequency ................................................................................... 84
Tabel 4. 10 IDF ..................................................................................................... 84
Tabel 4. 11 Tabel Weight TF - IDF ...................................................................... 84
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xx
Tabel 4. 12 Feature Extraction .............................................................................. 85
Tabel 4. 13 Tabel Prediksi .................................................................................... 91
Tabel 4. 14 Struktur Model Skenario Pertama ...................................................... 92
Tabel 4. 15 Akurasi Percobaan Pertama ............................................................... 93
Tabel 4. 16 Struktur Model Skenario Kedua ........................................................ 95
Tabel 4. 17 Akurasi Percobaan Kedua .................................................................. 96
Tabel 4. 18 Struktur Model Skenario Ketiga ........................................................ 98
Tabel 4. 19 Akurasi Percobaan Ketiga.................................................................. 98
Tabel 4. 20 Struktur Model Skenario Keempat .................................................. 100
Tabel 4. 21 Akurasi Percobaan Keempat ............................................................ 101
Tabel 4. 22 Struktur Model Skenario Kelima ..................................................... 103
Tabel 4. 23 Akurasi Percobaan Kelima .............................................................. 103
Tabel 4. 24 Hasil Akurasi Rata - Rata ................................................................ 105
Tabel 4. 25 Preprocessing ................................................................................... 107
Tabel 4. 26 Ekstraksi Ciri ................................................................................... 108
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

1
BAB I
PENDAHULUAN
1.1. Latar Belakang
Berita adalah sebuah informasi yang bersifat fakta yang sedang
terjadi maupun sudah terjadi dan disampaikan melalui perantara media, baik
di media elektronik maupun media cetak. J.B. Wahyudi (dalam Drs. Arifin
S. Harahap, 2006:4) berpendapat bahwa berita adalah laporan tentang
sebuah peristiwa yang menarik, memiliki nilai penting bagi khalayak ramai,
masih baru, serta dipublikasikan atau disiarkan melalui berbagai media
dalam kurun waktu yang periodik. Penyampaian berita juga bisa melalui
mulut ke mulut dan harus merupakan sebuah berita lisan, bukan karangan
fiktif atau cerita yang dibuat-buat. Umumnya, berita yang disampaikan
merupakan sebuah fakta tentang kejadian yang telah terjadi ataupun sedang
terjadi di masyarakat. Oleh karena itu, dalam penyampaiannya harus
disertai fakta-fakta yang sifatnya terbaru atau terkini. Berita bertujuan untuk
memberikan informasi kepada masyarakat tentang sebuah kejadian terbaru.
Selain itu, berita juga bertujuan untuk mempengaruhi masyarakat secara
luas. Ketika berita tidak disajikan berdasarkan fakta, maka berita akan turut
berpengaruh pada masyarakat itu sendiri.
Berita mudah diakses lewat berbagai media, baik media cetak atau
media elektronik. Persebaran berita di media elektronik sangatlah tinggi
sekali karena berita elektronik mudah diakses oleh masyarakat umum,
khususnya media sosial. Media sosial yang sering digunakan masyarakat
untuk memberikan sebuah informasi berita yang paling sering adalah
Twitter, Facebook, dan Instagram.
Persebaran berita yang ada pada media elektronik tidak bisa
dikontrol sehingga banyak sekali berita yang tidak valid atau dapat disebut
berita palsu. Menurut Silverman (2015), berita palsu atau fake news adalah
sebagai rangkaian informasi yang memang sengaja disesatkan, namun
dijual sebagai kebenaran. Berita palsu bukan sekadar misleading alias
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

2
menyesatkan, informasi dalam berita palsu juga tidak memiliki landasan
faktual, namun disajikan seolah-olah sebagai serangkaian fakta. Media
penyebaran berita palsu internet pertama yang diketahui adalah via email,
biasanya berisi peringatan akan hal sebuah klaim palsu. Namun, dengan
berkembangnya teknologi, terutama pada smartphone dan media sosial,
jenis berita palsu di internet semakin banyak dan berbahaya.
Dengan cara manual, pembaca dapat melakukan deteksi berita palsu
bisa dilakukan. Misalnya membaca berita – berita di media massa. Akan
tetapi untuk berita yang begitu banyak, cara manual tidak mungkin bisa
dilakukan karena jumlah datanya sangat besar dan terus bertambah. Di
sinilah peran prediksi berita palsu yang secara otomatis dapat melakukan
prediksi berita. Pada proses prediksi berita palsu ini, peneliti tertarik
melakukan proses prediksi dengan menggunakan metode Convolution
Neural Network. Dalam proses prediksi, penggunaan metode ini lebih
efisien karena dalam proses klasifikasi dengan data teks yang banyak, tentu
perlu metode yang baik sehingga peneliti menggunakan Convolution Neural
Network.
Pada penelitian yang telah dilakukan oleh beberapa peneliti yang
menggunakan metode Covolution Neural Network, penelitian-penelitian
tersebut mendapatkan hasil dengan akurasi yang tinggi. Pada penelitian TI
– CNN: Covolution Neural Network for Fake News Detection, penelitian
menggunakan data text dan image dan melakukan proses klasifikasi dengan
mengunakan CNN dan mendapatkan hasil akurasi 92,2% (Yang Yang,
2018). Selanjutnya penelitian tentang Fake News Detection Using a Blend
of neural Network: An Application of Deep Learning. Penelitian tersebut
menggunakan data text yang dilakukan proses word embedding untuk
preprocessing-nya dan masuk ke dalam proses klasifikasi CNN sehingga
mendapatkan hasil akurasi sebesar 97,21% (Agarmal, Mittal, Pathak, &
Goyal, 2020).
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

3
Pada penelitian ini, peneliti menggunakan metode Convolution
Neural Network karena berdasarkan dari hasil penelitian – penelitian di atas,
peneliti mendapatkan hasil lebih dari 90% sehingga diharapkan dari hasil
prediksi berita palsu tersebut mendapatkan hasil akurasi yang tinggi.
1.2. Rumusan Masalah
Berdasarkan latar belakang di atas, rumusan masalah dalam penelitian ini
adalah:
a. Bagaimana pendekatan Convolution Neural Network mampu
memprediksi dengan baik berita palsu atau tidak palsu?
b. Berapa besar akurasi prediksi Convolution Neural Network?
1.3. Tujuan Penelitian
Berdasarkan rumusan masalah di atas, tujuan penelitian dalam penelitian ini
adalah:
a. Mengetahui pendekatan Convolution Neural Network mampu
memprediksi dengan baik berita palsu atau tidak palsu.
b. Mengetahui tingkat akurasi prediksi Convolution Neural Network.
1.4. Manfaat Penelitian
Berdasarkan tujuan penelitian di atas, manfaat dalam penelitian ini adalah:
a. Bagi Peneliti
Mampu mengimplementasikan ilmu informatika terutama yang
berkaitan dengan information retrieval.
b. Bagi Masyarakat
Masyarakat dapat mengambil keputusan dari berita yang telah diketahui
berita tersebut palsu atau asli.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

4
c. Bagi Universitas
Memberikan kontribusi penambahan ilmu pengetahuan, khususnya bagi
prodi Informatika dan menambah bacaan untuk perpustakaan
Universitas Sanata Dharma serta memberikan referensi bagi mahasiswa
lain yang sedang dan/atau akan melakukan penelitian.
1.5. Batasan Masalah
Batasan masalah dalam penelitian ini adalah:
a. Berita yang digunakan adalah berita berbahasa Indonesia.
b. Berita yang diambil dari periode Juli 2015 hingga Agustus 2020 dari
situs turnbackhoax.id.
c. Data yang dikumpulkan dengan format .csv
1.6. Sistematika Penelitian
Penelitian ini disusun secara sistematika yang tersusun dari beberapa bab,
diantaranya sebagai berikut:
BAB I: PENDAHULUAN
Bagian ini berisi mengenai latar belakang, rumusan masalah, tujuan,
batasan masalah, metodologi penelitian, dan sistematika penulisan.
BAB II: LANDASAN TEORI
Bab ini berisi tentang teori-teori dasar yang berkaitan dengan
penelitian yang akan dilakukan, yang meliputi dari objek yang
digunakan, metode preprocessing yang digunakan, ekstraksi ciri
yang digunakan, dan klasifikasi yang digunakan.
BAB III: METODOLOGI PENELITIAN
Bagian ini berisi mengenai bahan riset atau data, peralatan
penelitian, metode pengumpulan data, tahap penelitian, desain alat
uji, cara pengujian, dan cara pengukuran akurasi sistem.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

5
BAB IV: HASIL DAN ANALISIS
Bagian ini berisi mengenai implementasi dari konsep yang sudah
dibuat dan memaparkan hasil analisis terhadap langkah-langkah
penelitian yang sudah dikerjakan.
BAB V: PENUTUP
Bagian ini berisi mengenai kesimpulan dari penelitian yang telah
dikerjakan, kemudian berisi saran untuk kemajuan dan
perkembangan penelitian berikutnya yang mengulas tentang
penelitian ini.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

6
BAB II
LANDASAN TEORI
Bab ini akan menjelaskan tentang teori – teori yang digunakan pada
penelitian ini, antara lain: Berita, Berita Palsu, Information Retrieval, Natural
Language Processing, Feature Extraction, Machine Learning, Deep Learning,
Jaringan Syaraf Tiruan, Convolution Neural Network, Pengukuran Performa, dan
Bahasa Python. Teori tersebut akan dijelaskan sebagai berikut ini.
2.1 Berita
Berita cerita atau keterangan mengenai kejadian atau peristiwa yang
hangat. Kejadian tersebut memiliki informasi fakta yang sedang terjadi
maupun sudah terjadi dan disampaikan melalui perantara media, baik itu
media elektronik maupun media cetak. Penyampaian berita juga bisa
melalui mulut ke mulut dan harus merupakan sebuah kenyataan, bukan
karangan fiktif atau cerita yang dibuat-buat. Oleh karena itu, dalam
penyampaiannya, berita harus disertai fakta-fakta yang sifatnya terbaru atau
terkini dan bisa diuji kredibilitasnya. Selain itu, tujuan dibuatnya berita ini
adalah juga untuk memberitahu kepada masyarakat secara luas. Ketika
berita yang disajikan tidak berdasarkan fakta, maka berita tersebut akan
turut berpengaruh pada masyarakat itu sendiri.
Beberapa ahli juga mengemukakan pendapatnya tentang pengertian
berita. Salah satunya J.B. Wahyudi yang mendefinisikan berita sebagai
laporan tentang sebuah peristiwa yang menarik, memiliki nilai penting bagi
khalayak ramai, masih baru, serta dipublikasikan atau disiarkan melalui
berbagai media dalam kurun waktu yang periodik. Eric C. Hepwood (1996)
mengemukakan bahwa berita adalah laporan pertama dari kejadian yang
penting sehingga dapat menarik perhatian umum. Definisi ini
mengungkapkan tiga unsur berita yakni aktual, penting, dan menarik.
Berita yang baik adalah berita yang memenuhi kode etik dalam
jurnalistik yang sudah memenuhi syarat-syarat (Drs. Arifin S. Harahap,
2006):
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

7
a. Berita harus berdasarkan fakta. Informasi dalam berita yang
disampaikan haruslah sesuai fakta yang sesungguhnya terjadi di
lapangan. Berita tidak boleh dibuat berdasarkan karangan atau
cerita fiktif.
b. Berita harus aktual, artinya informasi dalam berita yang
disampaikan adalah informasi terkini atau terbaru. Hal ini bisa
dibuktikan dengan jarak waktu antara berita disiarkan dengan
kejadian yang diberitakan tidak berbeda terlalu jauh.
c. Berimbang dengan informasi yang disampaikan. Tidak hanya
harus berupa fakta, namun juga berimbang. Berimbang artnya
fakta atau informasi yang disampaikan adalah informasi yang
sebenarnya serta tidak memihak maupun memojokkan salah satu
pihak. Dengan demikian, masyarakat yang membaca atau
melihat juga tidak akan terpengaruh.
2.2 Berita Palsu
Menurut Silverman (2017), berita palsu atau fake news adalah
sebagai rangkaian informasi yang memang sengaja disesatkan, namun
dijual sebagai kebenaran. Menurut Werme (2016), berita palsu adalah berita
yang mengandung informasi yang sengaja menyesatkan orang dan memiliki
agenda politik tertentu. Berita palsu bukan sekedar misleading alias
menyesatkan. Informasi dalam berita palsu juga tidak memiliki landasan
faktual, namun disajikan seolah-olah sebagai serangkaian fakta. Media
penyebaran berita palsu internet pertama yang diketahui adalah via email
dan biasanya berisi peringatan akan hal sebuah klaim palsu. Namun, dengan
berkembangnya teknologi, terutama pada smartphone dan media sosial,
jenis berita palsu di internet semakin banyak dan berbahaya.
Salah satu jenis kabar yang perlu diwaspadai adalah berita palsu
tentang virus. Berita palsu jenis ini biasanya dikembangkan oleh hacker dan
melakukan penyebarannya lewat email atau aplikasi chatting. Berita palsu
jenis ini biasanya berisi tentang adanya virus berbahaya di komputer atau
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

8
smartphone Anda yang sebenarnya tidak terinfeksi, sedangkan yang paling
sering terjadi dan sangat sulit dihindari adalah berita palsu dengan mengirim
pesan berantai. Pengguna aktif aplikasi chatting WhatsApp pasti sering
mendapat pesan untuk melanjutkan pesan ke beberapa teman lain dengan
berbagai alasan. Biasanya, pesan tersebut tentang mendapat hadiah tertentu
atau mengalami hal buruk jika tidak mengirimkannya. Selanjutnya ada pula
berita palsu pencemaran nama baik. Berita palsu dengan sifat ini sangat
berbahaya karena berita palsu bisa dengan mudah tersebar di dunia maya
dan mampu menghancurkan hidup seseorang.
2.3 Information Retrieval
Information Retrieval merupakan sebuah ilmu yang bertujuan untuk
pengambilan informasi dari dokumen – dokumen berdasarkan isi dan
konteks dari dokumen – dokumen itu sendiri. Tujuan dari information
retrieval adalah untuk memenuhi informasi pengguna dengan cara
mengambil dokumen yang akurat atau mengurangi dokumen yang tidak
akurat. Menurut Gerald Kowalski, Information Retrieval adalah suatu
sistem yang mampu melakukan penyimpanan, pencarian, dan pemeliharaan
informasi. Informasi dalam konteks yang dibaha dalam buku ini dapat
berupa informasi teks, gambar, audio, video, dan objek multimedia lainnya.
(Kowalski, 1997).
Menurut Christoper Manning, Information Retrieval adalah proses
menemukan suatu tema utama dalam dokumen yang tidak terstruktur dalam
koleksi yang besar untuk memenuhi kebutuhan informasi yang relevan.
Data tidak tersturktur adalah data yang tidak memiliki susunan simantik
atau dapat juga dikatakan data yang tidak memiliki struktur yang mudah
dikenali oleh computer. Data ini biasanya berupa teks. Selain memberikan
fasilitas penemuan kembali pada data yang tidak terstruktur, Information
Retrieval juga memberikan fasilitas pencarian data semistruktur, misalnya
mencari dokumen dengan judul dokumen yang mengandung kata “Java”
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

9
dengan badan teks yang mengandung kata “threading” (Manning,
Raghavan, & Schutze, 2008).
Information Retrieval memiliki beberapa subbidang, yaitu:
1. Document routing, filtering dan selective dissemination. Subbagian
ini berbalik arah dengan proses Information Retrieval pada
umumnya. Jika proses Information Retrieval yang umum adalah
membandingkan dokumen dengan query yang dimasukan user,
sedangkan pada document routing, filtering, dan selective
dissemination system akan membandingkan antardokumen
berdasarkan query untuk mendapatkan dokumen yang dapat
menarik minat pengguna. Contoh pada subbagian ini adalah
aggregator berita, misalnya dengan menggunakan proses routing
untuk memisahkan berita berdasarkan tema tertentu (bisnis, politik,
olahraga, dan sebagainya).
2. Text clustering and categorization system, adalah sistem
information retrieval yang akan mengelompokkan dokumen
berdasarkan kata kunci tertentu.
3. Summarization system atau peringkas teks sistem ini akan membuat
ringkasan dari teks yang diberikan. Contohnya adalah snippet yang
ditampilkan pada hasil pemcarian web.
4. Information extraction system, berfungsi untuk mengidentifikasi
entitas bernama, seperti nama tempat dan tanggal. Sistem ini juga
dapat mengkombinasikan informasi – informasi ke dalam remakan
terstruktur yang mendeskripsikan hubungan antara entitas – entitas
tersebut. Contohnya untuk membuat daftar buku dan pengarang dari
web data, ekstraksi informasi dari legal dokumen
5. Topic detection and tracking system, sistem ini berguna untuk
mengidentifikasi topik peristiwa dalam berita dan sumber – sumber
informasi yang sama.
6. Expert search system, sistem ini akan melakukan pengidentifikasian
keahlian dari seorang anggota organisasi.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

10
7. Question answering system adalah sistem yang mengintegrasikan
informasi dari berbagai sumber untuk memberikan jawaban yang
singkat dari pertanyaan tertentu. Sistem ini kadang juga
digabungkan dengan tema information retrieval lain seperti
pencarian, peringkas teks, dan ekstraksi informasi. Jika sistem
information retrieval yang umumnya adalah mengembalikan
dokumen yang relevan kepada user berdasarkan query yang
diinputkan, namun pada sistem tanya jawab yang dikembalikan
adalah berupa kalimat singkat untuk menjawab pertanyaan user.
8. Multimedia information retrieval system adalah subbagian dari
information retrieval yang mengembangkan teknik – teknik dari
information retrieval pada data multimedia seperti gambar, video,
music dan pidato. Contoh dari sub bidang ini berupa pencarian
gambar, musik, video, dan sebagainya.
2.4 Natural Language Processing
Natural Language Processing (NLP) atau Pemrosesan Bahasa
Alami adalah sebuah otomatisasi proses untuk mengkaji interaksi antara
komputer dan bahasa alami manusia yang digunakan dalam kehidupan
sehari-hari. Karena bahasa alami manusia beraneka ragam, dalam
penerapan Natural Language Processing, pengguna sering menemui
permasalahan dalam ambiguitas kata ataupun kata dengan makna ganda
(Priansya, 2017). NLP merupakan cabang ilmu kecerdasan buatan yang
dikhususkan untuk mengolah pemrosesan linguistik. Bahasa alami manusia
memiliki kebergaman dan aturan tata bahasa yang berbeda-beda sehingga
komputer perlu untuk memproses bahasa yang biasa digunakan sehari-hari
oleh manusia sehingga dapat memahami maksud dari manusia pengguna
sistem. Dalam penerapannya, untuk membuat sebuah sistem yang dapat
melakukan Pemrosesan Bahasa Alami, pengguna harus terlebih dahulu
melalui text preprocessing atau tahap sebelum memproses teks. Text
preprocessing memiliki beberapa tahapan yaitu:
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

11
2.4.1 Case Folding
Case Folding adalah salah satu bentuk text preprocessing
yang paling sederhana dan efektif meskipun sering diabaikan.
Tujuan dari Case Folding untuk mengubah semua huruf dalam
dokumen menjadi huruf kecil. Hanya huruf ‘a’ sampai ‘z’ yang
diterima. Hal ini sering digunakan untuk sebagian besar masalah text
mining dan NLP untuk membantu dalam kasus dimana dataset yang
digunakan tidak terlalu besar dan membantu secara signifikan untuk
mendapatkan output yang konsisten.
Berikut contoh bagaimana penyelesaian Case Folding,
dimana kata – kata akan di konversi kedalam bentuk Case Folding
pada tabel 2.1:
Tabel 2. 1 Case Folding
Sebelum Sesudah
Italia pUnyA] FasilITas$
PeraWataN KESEHATAN
italia punya] fasilitas$
perawatan kesehatan
2.4.2 Stemming
Stemming adalah proses untuk mengurai infleksi dalam kata
ke bentuk kata dasar. Proses stemming ini dilakukan dengan
memotong akhir kata ataupun awalan kata dengan harapan dapat
mengubah kata menjadi kata dasarnya. Sebagai contoh pada tabel
2.2, terdapat kata “bermasalah”, maka kata akan menjadi “masalah”.
Selain itu, proses stemming juga berguna untuk mengurangi ukuran
struktur pengindeksan karena jumlah istilah indeks yang berbeda
menjadi berkurang.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

12
Tabel 2. 2 Stemming
Sebelum Sesudah
italia punya] fasilitas$
perawatan kesehatan
italia punya] fasilitas$ awat
sehat
2.4.3 Tokenizing
Tokenizing adalah proses pemisahan teks menjadi potongan-
potongan yang disebut sebagai token untuk kemudian dianalisis.
Kata, angka, simbol, tanda baca, dan entitas penting lainnya dapat
dianggap sebagai token. Di dalam NLP, token diartikan sebagai
“kata” meskipun tokenize juga dapat dilakukan pada paragraf
maupun kalimat seperti pada tabel 2.3.
Tabel 2. 3 Tokenizing
Sebelum Sesudah
italia punya] fasilitas$ awat
sehat
'italia', 'punya]', 'fasilitas$',
'awat', 'sehat'
2.4.4 Stopwords Removal
Stopwords Removal yaitu menghilangkan kata – kata umum
yang sering digunakan dalam sebuah teks dan biasanya tidak
berguna jika digunakan untuk tujuan pencarian. Penghapusan
stopwords memiliki manfaat penting yaitu untuk mengurangi
ukuran indeks yang digunakan nantinya. Dengan mengurangi kata –
kata dengan informasi rendah dari teks, maka teks tersebut akn dapat
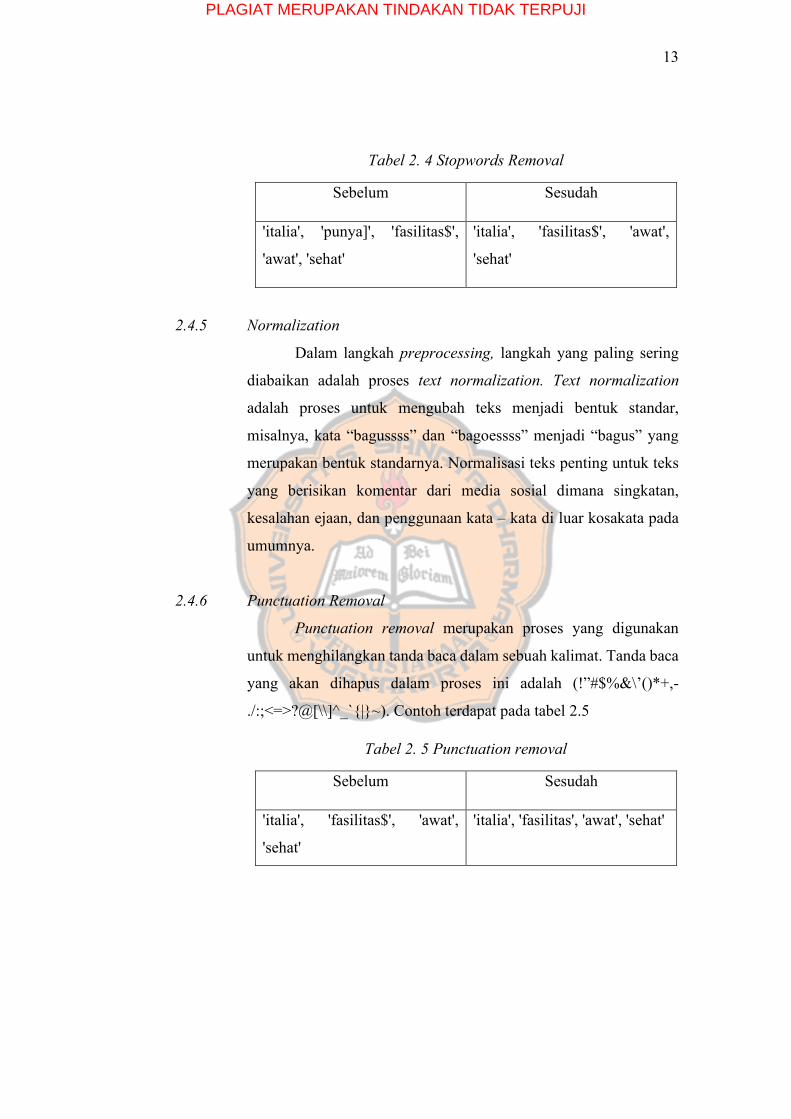
fokus pada kata – kata penting saja. Contoh terdapat pada tabel 2.4.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
13
Tabel 2. 4 Stopwords Removal
Sebelum Sesudah
'italia', 'punya]', 'fasilitas$',
'awat', 'sehat'
'italia', 'fasilitas$', 'awat',
'sehat'
2.4.5 Normalization
Dalam langkah preprocessing, langkah yang paling sering
diabaikan adalah proses text normalization. Text normalization
adalah proses untuk mengubah teks menjadi bentuk standar,
misalnya, kata “bagussss” dan “bagoessss” menjadi “bagus” yang
merupakan bentuk standarnya. Normalisasi teks penting untuk teks
yang berisikan komentar dari media sosial dimana singkatan,
kesalahan ejaan, dan penggunaan kata – kata di luar kosakata pada
umumnya.
2.4.6 Punctuation Removal
Punctuation removal merupakan proses yang digunakan
untuk menghilangkan tanda baca dalam sebuah kalimat. Tanda baca
yang akan dihapus dalam proses ini adalah (!”#$%&\’()*+,-
./:;<=>?@[\\]^_`{|}~). Contoh terdapat pada tabel 2.5
Tabel 2. 5 Punctuation removal
Sebelum Sesudah
'italia', 'fasilitas$', 'awat',
'sehat'
'italia', 'fasilitas', 'awat', 'sehat'
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

14
2.5 Feature Extraction
Feature Extraction merupakan sebuah proses untuk mendapatkan
fitur-fitur yang terkandung dalam dokumen. Feature Extraction berfungsi
untuk mengurangi noise dengan menghapus feature yang tidak relevan,
sehingga dapat mengingkatkan akurasi klasifikasi.
Menurut Baeza-Yates, menyatakan terdapat 3 model yang
mendukung untuk proses Feature Extraction, yaitu model Boolean, model
ruang vektor, dan model probabilistic (Baeza-Yates & Ribeiro-Neto, 1999).
2.5.1. Model Boolean
Model Boolean adalah model pencarian sederhana yang
berasal dari teori Aljabar Boolean. Model ini menyediakan sebuah
framework yang mudah dimengerti oleh user umum dari
Information Retrieval. Selain itu, query dimasukkan sebagai
ekspresi Boolean yang memiliki sematik yang tepat. Dengan bentuk
sederhana tersebut, model Boolean banyak mendapat perhatian di
awal kemunculannya. Namun, model ini memiliki beberapa
kelemahan, di antaranya.
- Strategi pencarian berdasarkan standar keputusan biner, yaitu
dengan memprediksi apakah suatu dokumen relevan atau tidak
tanpa adanya skala penilaian sehingga menghalangi kinerja
pencarian yang baik.
- Dengan adanya penggunaan sematik yang tepat, seringkali
menyulitkan untuk menerjemahkan kebutuhan informasi ke
dalam ekpresi Boolean.
2.5.2. Model Ruang Vektor
Gambaran dari serangkaian dokumen sebagai vektor –
vektor dalam ruangan vektor umum disebut dengan model ruang
vektor. Model ruang vektor merupakan dasar untuk operasi
pencarian sejumlah informasi mulai dari memberi nilai dokumen
pada query, serta klasifikasi dan pembagian dokumen. Menurut
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

15
(Zhai & Massung, 2016), ruang vektor adalah sebuah model yang
simple dan model ini dapat digunakan secara efektif dalam proses
memberikan ranking dalam sebuah pemerolehan informasi. Model
ruang vektor ini memiliki kesamaan dalam model similarity yaitu
kedua model tersebut mencari relevansi terhadap kesamaan antara
dokumen dan query yang dimasukkan sehingga dapat diasumsikan
jika dalam satu dokumen tersebut terdapat kemiripan dengan query
daripada dokumen kedua, maka dokumen pertama akan
diasumsikan lebih relevan daripada dokumen yang kedua. Ini adalah
basic dari proses penilaian dokumen dalam model ruang vektor. Ide
dasar dari model ruang vektor sangat mudah dipahami.
Untuk menilai apakah model ruang vektor paling sederhana
ini benar-benar berfungsi dengan baik, dapat dilihat pada gambar
Gambar 2. 1 Contoh Sederhana Model Ruang Vektor (Zhai &
Massung, 2016)
Gambar 2.1 merupakan sebuah sample dokumen dan sample
query. Dalam query, terdapat kata “news about presidential
campaign”. Selanjutnya terdapat lima dokumen berasal dari corpus
yang memiliki perbedaan terms dalam query-nya. Dalam model
ruang vektor, pertama-tama menghitung vektor untuk dokumen ini
dan query. Dalam query terdapat 4 kata yaitu � ��"news","about", "presidential", "campaign"}. Sehingga dalam ��
terdapat dua kata yang memilik similarity yaitu news dan about
sehingga nilai dari �� adalah 2. Pada �� terdapat tiga kata yang
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

16
memiliki similarity dengan query yaitu news, presidential, dan
campaign, sehingga nilai dari �� adalah 3. Berdasarkan
perbandingan tingkat similarity antara �� dan ��, �� memiliki
ranking lebih tinggi dari ��. Jika diterapkan pada
��, �, ��, �, ��� � , maka akan mendapatkan hasil pada gambar
2.2
Gambar 2. 2 Ranking Dokumen Model Ruang Vektor (Zhai &
Massung, 2016)
Gambar 2.2 telah dilakukan ranking dari kelima dokumen
tersebut. Fungsi penilaian vektor bit menghitung jumlah istilah kueri
unik yang cocok di setiap dokumen. Namun, terdapat masalah pada
dokumen �, ��, dan �. Ketiga dokumen tersebut memiliki nilai
yang sama yaitu 3. Setelah diperiksa lebih dekat, � seharusnya nilai
tinggi dari �� karena �� hanya menyebutkan kata “presidential”
hanya sekali dibandingkan dengan � yang menyebutkan kata
“presidential” berulang kali. Selain itu, �� lebih relevan dan
mendapatkan nilai lebih dari �. Kata “presidential” lebih penting
daripada kata “about” meskipun kata “presidential” dan “about”
terdapat dalam query. Tetapi model ruang vektor ini tidak
melakukan tersebut sehingga untuk mengatasi hal tersebut, perlu
dilakukan proses perhitungan kembali dengan menggunakan Term
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

17
Frequency untuk menghitung frekuensi kemuculan sebuah kata
dalam dokumen.
Pada model ruang vektor, kata unik yang muncul dalam
dokumen diberi nilai 1 dan 0, sedangkan dalam Term Frequency
kata unik yang muncul dalam dokumen akan dihitung dari
banyaknya kata tersebut muncul sehingga nilai dari kata yang
muncul tidak hanya 1 dan 0, melainkan akan dihitung kemunculam
kata di query dalam dokumen. Dengan demikian, dapat disimpulkan
dengan rumus:
�����, �� � � � � � ���� � �� � ⋯ � ���� � � ���� �
���
(2. 1)
Dengan penggunaan rumus tersebut, penilaian dokumen
dengan query yang ada tentu memiliki perbedaan. Contoh yaitu nilai
dari �, ��, dan � memiliki nilai yang sama, tetapi saat
menggunakan Term Frequency nilai tersebut akan berbeda. Contoh
bisa dilihat pada gambar 2.3
Gambar 2. 3 Term Frequency (Zhai & Massung, 2016)
Kemunculan pada � lebih tinggi karena terdapat perulangan kata
yang dihitung yaitu kata “presidential” terdapat 2 kata dalam �
sehingga nilai dari � lebih tinggi dari � dan ��.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

18
Namun, hasil dari perhitungan � dan �� memiliki nilai yang
sama. Proses perankingan tersebut dapat dilakukan dengan
melakukan proses Inverse Document Frequency, yaitu jumlah
dokumen yang mengandung sebuah term yang dicari dari kumpulan
dokumen yang ada.
������ � log "# � 1�����%
(2. 2)
Keterangan:
������ : inverse document frequency yang
mengandung term �
# : Jumlah dokumen dalam koleksi
����� : jumlah koleksi dokumen yang
mengandung term �
Sebagai contoh, melakukan perbandingan pada � dan ��,
dimana terdapat kata” campaign” dan “about”. Untuk melakukan
perhitungan, perlu diasumsikan untuk nilai #, ����&'()�, dan
���*��+��,��.
M : 10.000
����&'()� : 5000
���*��+��,�� : 1166
Kemudian, menghitung idf dari about:
-./��&'()� � log " 10.001����&'()�% � log "10.001
5000 % ≈ 1.0
Idf dari campaign:
-./�*��+��,�� � log " 10.001���*��+��,��% � log "10.001
1166 % ≈ 3.1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

19
Setelah melakukan perhitungan nilai idf pada kedua kata
tersebut, selanjutnya adalah menghitung perankingan dengan hasil
dari IDF dan dikalikan dengan nilai TF tersebut.
��,6 � )��,6 7 ���� (2. 3)
Sehingga mendapatkan hasil pada gambar 2.4
Gambar 2. 4 Invers Document Frequency
Dapat disimpulkan nilai dari � lebih tinggi dari ��. Berdasarkan
proses perurutan pada 5 dokumen tersebut dan berdasarkan proses
pembobotan TF-IDF, perhitungan mendapatkan hasil
Gambar 2. 5 Weight TF - IDF
2.5.3. Model Probabilistik
Model probabilistik adalah model untuk mengurutkan
dokumen dalam urutan menurun terhadap peluang relevansi sebuah
dokumen terhadap kebutuhan informasi user (Zhai & Massung,
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

20
2016). Perhitungan yang dilakukan pada setiap kata pada query dan
akan diketahui nilai bobot dari dokumen yang dicari. Dokumen yang
paling relevan memiliki jumlah nilai bobot tertinggi.
Pada model probabilistik ini, proses perankingan
berdasarkan probabilitas yang diberikan dokumen � apakan relevan
dengan query �, atau +�8 � 1|�, �� dimana 8 ∈ �0,1; adalah
variabel acak biner yang menunjukkan relevansi (Gambar 2.6).
Gambar 2. 6 Perhitungan Model Probabilistik
Pada gambar di atas, � dan � dalam tabel ini dan kemudian
menghitung dengan:
+�8 � 1|�, �� � *'(�)�8 � 1, �, ��*'(�)��, ��
(2. 4)
Keterangan:
+�8 � 1|�, �� : Probabilitas kemunculan kata dalam
dokumen
*'(�)�8 � 1, �, �� : Jumlah kemunculan kata pada dokumen
*'(�)��, �� : Panjang dokumen
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

21
Sebagai contoh, melakukan perhitungan probabilitas pada query
“presidential campaign”, maka kata “presidential” akan dicari pada
setiap kata pada dokumen, berapa banyak kemunculan kata tesebut
dalam dokumen, sama halnya dengan kata “campaign” sehingga
dimasukkan ke dalam rumus:
+�� � "presidential campaign"|��
� *�"presidential", ��|�| 7 *�"campaign", ��
|�|
Sehingga jika diimplementasikan pada dokumen �, ��, dan
� menjadi:
+��|�� � 2|�| 7 1
|�|
+��|��� � 1|��| 7 1
|��|
+��|�� � 0|�| 7 1
|�| Untuk menghitung score pada dokumen tersebut, telah
dilakukan perhitungan berapa kali kata presidential dan campaign
muncul. Data dapat dilihat pada kata presidential muncul 2 kali
dalam � maka ditulis
|>?| dan dikalikan dengan kata campaign yang
muncul 1 kali pada � maka ditulis �
|>?|. Sama halnya pada � dan
��. Perhitungan probabilitas tersebut perlu dilakukan perhitungan
untuk proses scoring pada setiap dokumen agar pada setiap
dokumen mendapatkan hasil akhir apakah dokumen tersebut relevan
atau tidak dengan query yang di inputkan, untuk melakukan
perhitungan scoring tersebut dapat menggunakan rumus:
@*'AB��, �� � log +��|��� � log +���|�� � � *��, �� log +��|��
C∈D
�
���
(2. 5)
Keterangan:
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

22
@*'AB��, �� : Score probabilitas query terhadap dokumen
+���|�� : Probabilitas kata dalam dokumen
*��, �� : Jumlah kata dalam dokumen
2.6 Machine Learning
Istilah machine learning pertama kali didefinisikan oleh Arthur
Samuel pada tahun 1959. Menurut Arthur Samuel, machine learning adalah
salah satu bidang ilmu komputer yang memberikan kemampuan
pembelajaran kepada komputer untuk mengetahui sesuatu tanpa pemrogram
yang jelas (Samuel, 1988). Menurut Mohri dkk (2012), machine learning
dapat didefinisikan sebagai metode komputasi berdasarkan pengalaman
untuk meningkatkan performa atau membuat prediksi yang akurat. Definisi
pengalaman disini ialah informasi sebelumnya yang telah tersedia dan bisa
dijadikan data pembelajar.
Dalam pembelajaran machine learning, terdapat beberapa skenario-
scenario, seperti:
1. Supervised Learning
Penggunaan skenario supervised learning, pembelajaran menggunakan
masukan data pembelajaran yang telah diberi label. Setelah itu membuat
prediksi dari data yang telah diberi label.
2. Unsupervised Learning
Penggunaan skenario Unsupervised Learning, pembelajaran
menggunakan masukan data pembelajaran yang tidak diberi label.
Setelah itu mencoba untuk mengelompokan data berdasarkan
karakteristik-karakteristik yang ditemui.
3. Reinforcement Learning
Pada skenario reinforcement learning, fase pembelajaran dan tes saling
dicampur dengan tujuan untuk mengumpulkan informasi pembelajar
secara aktif dengan berinteraksi ke lingkungan sehingga untuk
mendapatkan balasan untuk setiap aksi dari pembelajar.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

23
Saat ini telah banyak pendekatan machine learning yang digunakan
untuk deteksi spam, Optical character recognition (OCR), pengenalan
wajah, deteksi penipuan online, NER (Named Entity Recognition), Part-of-
Speech Tagger.
2.7 Jaringan Syaraf Tiruan
Jaringan Syaraf Tiruan atau Artificial Neural Network (ANN)
merupakan suatu model komputasi paralel yang meniru fungsi dari sistem
jaringan syaraf biologi otak manusia. Otak manusia terdiri dari milyaran
neuron yang saling berhubungan. Hubungan ini disebut dengan Synapses.
Komponen neuron terdiri atas satu inti sel yang akan melakukan
pemrosesan informasi, satu akson (axon), dan minimal satu dendrit.
Informasi yang masuk akan diterima oleh dendrit. Selain itu, dendrit juga
menyertasi akson sebagai keluaran dari suatu pemrosesan informasi.
Gambar 2. 7 Jaringan Syaraf
Cara kerja dari sistem syaraf di atas adalah bermula pada sinyal
masuk melalui dendrit menuju cell body. Kemudian sinyal akan diproses di
dalam cell body berdasarkan fungsi tertentu (Summation Process). Jika
sinyal hasil proses melebihi nilai ambang batas (treshold) tertentu, maka
sinyal tersebut akan membangkitkan neuron untuk meneruskan sinyal
tersebut. Jika sinyal hasil proses di bawah nilai ambang batasnya, maka
sinyal tersebut akan dihalangi (inhibited). Kemudian sinyal yang diteruskan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

24
akan menuju ke axon dan akhirnya menuju ke neuron lainnya melewati
synapse.
ANN merupakan sistem adatif yang dapat mengubah strukturnya
untuk memecahkan suatu masalah berdasarkan informasi internal maupun
eksternal. ANN bersifat fleksibel terhadap inputan data dan menghasilkan
output respon konsisten. ANN telah banyak digunakan dalam area yang
luas. Penerapan ANN dapat mengidentifikasi beberapa aplikasi yaitu:
a. Estimasi/prediksi (aproksimasi fungsi, peramalah)
b. Pengenalan Pola (klasifikasi, diagnosis, dan analisis diskriminan)
c. Klustering (pengelompokan tanpa adanya pengetahuan sebelumnya).
2.7.1. Komponen Neural Network
Neural Network memiliki beberapa tipe yang berbeda-beda,
akan tetapi hampir semua komponen yang dimiliki sama. Seperti
halnya jaringan syaraf pada otak manusia, neural network juga terdiri
atas beberapa neuron unit yang saling behubungan. Masing-masing
dari neuron tersebut akan melakukan transformasi informasi yang
diterima melalui sambungan keduanya menuju neuron lain.
Hubungan ini biasanya disebut dengan sebutan bobot (Weight).
Informasi tersebut disimpan pada suatu nilai tertentu pada bobot
tertentu. Berikut adalah struktur neuron pada neural network:
Gambar 2. 8 Struktur Neural Network
Gambar 2.8 di atas menunjukan struktur yang dimiliki oleh
Neural Network. Komponen yang dimiliki struktur tersebut sebagai
berikut:
1. Input terdiri atas variabel independet �E1, E2, E3, . . . . . E�� yang
merupakan sebuah sinyal yang masuk ke sel syaraf.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

25
2. Bobot (Weigth) terdiri atas beberapa bobot
�F1, F2, F3, . . . . . F�, � yang berhubungan dengan masing-
masing node.
3. Threshold merupakan nilai ambang batas internal dari node.
Besar nilai ini mempengaruhi aktivasi dari output node �.
4. Activation Function (Fungsi Aktivasi) merupakan operasi
matematika yang dikenal pada sinyal output y.
Cara kerja struktur neural network diatas tidak jauh berbeda
dengan struktur jaringan syaraf pada manusia. Informasi (input)
akan dikirimkan dengan bobot kedatangan tertentu. Input tersebut
kemudian diproses oleh suatu fungsi perambatan yang akan
menjumlahkan nilai-nilai semua bobot yang datang. Hasil
penjumlahan ini kemudian akan dibandingkan dengan suatu nilai
ambang (threshold) tertentu melalui fungsi aktivasi setiap neuron.
Jika input tersebut melewati suatu nilai ambang tertentu, maka
neuron tersebut akan diaktifkan. Jika tidak, neuron tersebut tidak
akan diaktifkan. Apabila neuron diaktifkan, selanjutnya neuron
tersebut akan mengirimkan output melalui bobot-bobot outputnya
ke semua neuron yang berhubungan dengannya, begitu seterusnya.
Pada neuron layer, penempatan neuron-neuron akan
dikumpulkan dalam neuron layer (lapisan-lapisan). Kemudian
neuron-neuron pada satu lapisan akan dihubungkan dengan lapsan-
lapisan sebelum dan sesudahnya, kecuali lapisan input dan output.
Informasi yang dibawa dari langkah input awal akan dirambatkan
dari lapisan ke lapisan dari lapisan input sampai lapisan output.
Lapisan ini sering disebut dengan istilah hidden layer (lapisan
tersembunyi). Pada umumnya, setiap neuron terletak pada lapisan
yang sama akan memiliki keadaan yang sama sehingga pada setiap
lapisan sama, setiap neuron akan memiliki fungsi aktivasi yang sama.
Koneksi antarlapisan dengan neuron harus selalu berhubungan.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

26
Faktor terpenting dalam menentukan kelakuan suatu neuron adalah
terletak pada pola bobot dan fungsi aktivasinya.
2.7.2. Arsitektur Neural Network
Pada Neural Network, neuron-neuron yang ada pada lapisan
yang sama memiliki keadaan yang sama. Terdapat faktor penting
dalam menentukan sifat suaru neuron yaitu bobot (Weight) dan
penggunaan fungsi aktivasi dari neuron tersebut. Setiap lapisan pada
neuron memiliki fungsi aktivasi yang sama. Arsitektur yang dapat
dibentuk oleh ANN bermacam-macam, dari yang paling sederhana
terdiri satu neuron (single neuron) sampai yang paling rumit menjadi
multi neuron (multiple neuron) dalam satu lapis (single layer),
sampai jaringan multiple neuron dalam multiple layers. Beberapa
jaringan tersebut memiliki kemampuan yang berbeda-beda. Semakin
rumit suatu jaringan, persoalan yang dapat diselesaikan menjadi lebih
luas. Namun, terdapat kelemahan yaitu kerumitan tersebut dapat
menimbulkan persoalan tersendiri pada kebutuhan proses trainning
dan simulasi (testing) yang akan memerlukan waktu lebih lama.
Menurut Hermawan (2006), a rsitektur neural network dapat dibagi
berdasarkan jumlah lapisannya di antaranya:
1. Single Layer Neural Network: Jaringan dengan lapisan tunggal
terdiri atas 1 lapisan input dan 1 lapisan output. Setiap neuron
yang terdapat di dalam lapisan input selalu terhubung dengan
setiap neuron yang terdapat pada lapisan output. Jaringan ini
hanya menerima input kemudian secara langsung akan
mengolahnya menjadi output tanpa harus melalui lapisan
tersembunyi:
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

27
Gambar 2. 9 Single Layer Neural Network
2. Multiple Layers Neural Network: Jaringan dengan lapisan jamak
memiliki ciri khas tertentu yaitu memiliki 3 jenis lapisan yakni
lapisan input, lapisan output, dan lapisan tersembunyi. Jaringan
dengan banyak lapisan ini dapat menyelesaikan permasalahan
yang lebih kompleks dibandingkan jaringan dengan lapisan
tunggal. Akan tetapi, proses pelatihan sering membutuhkan
waktu yang cenderung lama.
Gambar 2. 10 Multiple Layers Neural Network
3. Competitive Layers: Pada jaringan ini, sekumpulan neuron
bersaing untuk mendapatkan hak menjadi aktif. Contoh
algoritma yang menggunakan jaringan ini adalah LVQ.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

28
Gambar 2. 11 Competitive Layers
2.7.3. Fungsi Aktivasi
Fungsi aktivasi merupakan fungsi yang menggambarkan
hubungan antara tingkat aktivitas internal (summation function) yang
mungkin berbentuk linear ataupun nonlinear. Fungsi ini bertujuan
untuk menentukan apakah neuron diaktifkan atau tidak. Ada
beberapa fungsi aktivasi yang sering digunakan dalam Neural
Network, yaitu sebagai berikut:
1. Fungsi Aktivasi Linear
Fungsi aktivasi linear merupakan fungsi yang memiliki
nilai output yang sama dengan nilai input-nya. Hal ini berkaitan
dengan, jika sebuah neuron menggunakan linear activation,
maka keluaran dari neuron tersebut adalah weighted sum dari
input + bias. Grafik fungsi linear ditunjukan oleh gambar 2.12.
Gambar 2. 12 Fungsi Aktivasi linear
2. Fungsi Aktivasi Sigmoid
Fungsi aktivasi sigmoid merupakan fungsi nonlinear.
Masukan untuk fungsi aktivasi ini berupa bilangan real dan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

29
output dari fungsi tersebut memiliki range antara 0 sampai 1.
Berikut ini grafik fungsi aktivasi sigmoid:
Gambar 2. 13 Fungsi Aktivasi Sigmoid
Jika input dari suatu node pada neural network bernilai
negatif, maka keluaran yang didapatkan adalah 0. Jika
masukannya berilai positif, maka keluaran nilainya adalah satu.
Fungsi ini memiliki kekurangan yaitu sigmoid dapat mematikan
gradient, ketika aktivasi dari neuron mengeluarkan nilai yang
berada pada range 0 atau satu, gradient di wilayah ini hampir
bernilai 0. Kemudian output dari sigmoid tidak zero-centered.
3. Fungsi Aktivasi Tanh
Fungsi aktivasi Tanh merupakan fungsi nonlinear.
Masukan untuk fungsi aktivasi ini berupa bilangan real dan
output dari fungsi tersebut memiliki range antara -1 sampai 1.
Berikut ini grafik fungsi aktivasi tanh:
)��ℎ��� � 2H�2�� − 1 (2. 6)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

30
Gambar 2. 14 Fungsi aktivasi Tanh
Sama seperti fungsi sigmoid, fungsi ini memiliki
kekurangan yaitu dapat mematikan gradient. Akan tetapi fungsi
ini juga memiliki kelebihan yaitu output yang dimiliki fungsi
Tanh merupakan zero-centered. Dalam pengaplikasiannya,
fungsi Tanh lebih menjadi pilihan jika dibandingkan dengan
fungsi sigmoid. Perlu diketahui fungsi tanh merupakan
pengembangan dari fungsi Sigmoid.
4. Fungsi Aktivasi ReLU
Pada dasarnya, fungsi ReLU (Rectified Linear Unit)
melakukan “threshold” dari 0 hingga infinity. Fungsi ini menjadi
salah satu fungsi yang populer saat ini. Berikut ini grafik fungsi
aktivasi tanh
Gambar 2. 15 Fungsi Aktivasi ReLU
Pada fungsi ini, masukan dari neuron-neuron berupa
bilangan negatif, maka fungsi ini akan menerjemahkan nilai
tersebut ke dalam nilai 0, dan jika masukan bernilai positif maka
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

31
output dari neuron adalah nilai aktivasi itu sendiri. Fungsi
aktivasi ini memiliki kelebihan yaitu dapat mempercepat proses
konvigurasi yang dilakukan dengan Stochastic Gradient Descent
(SGD) jika dibandingkan dengan fungsi sigmoid dan tanh.
Namun, aktivasi ini juga memiliki kelemahan yaitu aktivasi ini
bisa menjadi rapuh pada proses training dan bisa membuat unit
tersebut mati.
2.8 Deep Learning
Deep Learning merupakan salah satu bidang dari Machine Learning
untuk implementasi permasalahan dengan dataset yang besar. Teknik Deep
Learning memberikan arsitektur yang sangat kuat untuk Supervised
Learning. Dengan menambahkan lebih banyak lapisan, model pembelajaran
tersebut bisa mewakili data citra berlabel dengan lebih baik. Pada Machine
Learning, terdapat teknik untuk menggunakan ekstraksi fitur dari data
pelatihan dan algoritma pembelajaran khusus untuk mengklasifikasi citra
maupun untuk mengenali suara. Namun, metode ini masih memiliki
beberapa kekurangan baik dalam hal kecepatan dan akurasi.
Aplikasi konsep jaringan syaraf tiruan yang dalam (banyak lapisan)
dapat ditangguhkan pada algoritma Machine Learning yang sudah ada
sehingga komputer sekarang bisa belajar dengan kecepatan, akurasi, dan
skala yang besar. Prinsip ini terus berkembang hingga Deep Learning
semakin sering digunakan pada komunitas riset dan industri untuk
membantu memecahkan banyak masalah data besar seperti Computer
Vision, Speech Recognition, dan Natural Language Processing. Feature
Engineering adalah salah satu fitur utama dari Deep Learning untuk
mengekstrak pola yang berguna dari data yang akan memudahkan model
untuk membedakan kelas. Feature Engineering juga merupakan teknik
yang paling penting untuk mencapai hasil yang baik pada tugas prediksi.
Namun, sulit untuk dipelajari dan dikuasai karena kumpulan data dan jenis
data yang berbeda memerlukan pendekatan teknik yang berbeda juga.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

32
Algoritma yang digunakan pada Feature Engineering dapat
menemukan pola umum yang penting untuk membedakan antara kelas
Dalam Deep Learning, metode Convolutional Neural Network sangatlah
bagus dalam menemukan fitur yang baik pada teks ke lapisan berikutnya
untuk membentuk hipotesis nonlinier yang dapat meningkatkan
kekompleksitasan sebuah model.
Model yang kompleks tentunya akan membutuhkan waktu pelatihan
yang lama sehingga di dunia Deep Learning pengunaan GPU sudah
sangatlah umum (Danukusumo, 2017).
2.9 Convolution Neural Network
Convolutional Neural Network (CNN) merupakan salah satu
pengembangan dari Jaringan Syaraf Tiruan yang terinspirasi dari jaringan
syaraf manusia dan biasanya digunakan untuk melakukan peramalan dan
pengenalan pola. Convolutional Neural Network merupakan pengembangan
dari Multilayer Perception yang didesain untuk melakukan pengolahan data
dalam bentuk dua dimensi. Tidak seperti MLP yang setiap neuron hanya
berukuran satu dimensi, CNN termasuk dalam Deep Neural Network karena
ke dalam jaringan yang tinggi dan banyak diaplikasikan dalam machine
learning. CNN hampir sama dengan neural network pada umumnya yang
memiliki neuron, bobot, dan bias.
Pada dasarnya, Convolution Neural Network merupakan
beberapa lapisan konvolusi dengan fungsi aktivasi ReLU atau Tanh
yang biasa diterapkan pada proses pelatihan. Di dalam feed forward
neuron network menghubungkan setiap neutron ke output neuron
pada lapisan berikutnya, biasanya disebut dengan fully – connected
atau affine layer. Pada CNN, tidak diperlukan beberapa langkah
yang dilakukan pada neural network tradisional, sebaliknya yaitu
menggunakan metode konvolusi yang melalui input layer untuk
menghitung output. Setiap layer diterapkan filter yang berbeda,
biasanya terdiri atas ratusan atau ribuan filter dan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

33
mengkombinasukan hasil dari operasi kovolusi tersebut. Selama
proses traning terjadi, CNN secara otomatis mempelajari nilai hasil
penerapan filter pada operator konvolusi berdasarkan pada tugas
yang diinginkan. CNN dapat belajar untuk mendeteksi pada layer
pertama, kemudian menggunakannya untuk mendeteksi bentuk
sederhana pada lapisan kedua, dan kemudian menggunakan hasil
ekstraksi fitur pada filter sebelumnya untuk mendeteksi fitur pada
tingkatan yang lebih tinggi.
Gambar 2. 16 Arsitektur Convolution Neural Network
2.9.1. Embedding Layer
Komputer melihat text input pada Embedding Layer dengan
yang memetakan indeks kata kosakata dalam representasi matrix
vector dalam low dimensional space untuk mengasumsikan bahwa
setiap kata sesuai dengan vektor dalam ruang dimensi rendah yang
tidak diketahui dan mendefinisikan model bahasa hanya
berdasarkan representasi vektor dari kata-kata yang terlibat sehingga
parameter untuk model bahasa seperti itu akan menjadi representasi
vektor dari kata-kata. Hasilnya dengan menyesuaikan model ke
kumpulan data tertentu, maka dapat mempelajari representasi vektor
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

34
untuk semua kata. Model bahasa ini disebut neural language models
karena dapat direpresentasikan sebagai jaringan saraf.
Misalnya, dalam skip-gram neural language model, tujuan
dari fungsi ini adalah menggunakan setiap kata untuk memprediksi
semua kata lain dalam konteksnya seperti yang ditentukan oleh
jendela di sekitar kata dan probabilitas untuk memprediksi kata w1
jika kata w2 didapatkan dari persamaan rumus
+���|�� � B�+�J�KKKK⃗ . JKKKK⃗ �∑ B�+�JNKKK⃗ . JKKKK⃗ �CO∈D
(2. 7)
Keterangan:
+���|�� : Score probabilitas kata �� jika �
J� : representasi vektor yang sesuai dari kata ��.
2.9.2. Convolution Layer
Convolution layer adalah blok utama di dalam CNN yang
terdiri atas beragam filter yang diinisialisasi secara acak untuk
melakukan operasi konvolusi yang berfungsi sebagai ekstraksi fitur
untuk mempelajari representasi fitur dari suatu input text. Pada
convolution layer, neuron tersusun menjadi feature maps. Setiap
neuron pada feature map sebagai receptive field, terhubung pada
neuron – neuron dari convolution layer sebelumnya melalui
serangkaian bobot yang dilatih, biasa juga disebut dengan filter bank
(LeCun, 2015).
Convolution layer terdiri atas neuron yang tersusun
sedemikian rupa sehingga membentuk sebuah filter yang panjang
dan tinggi. Sebagai contoh, layer pertama pada layer dengan ukuran
4x7. Kedua filter ini akan digeser ke seluruh bagian dari text. Setiap
pergeseran akan dilakukan operasi dot antara input dan nilai dari
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

35
filter tersebut sehingga menghasilkan sebuah output atau biasa
disebut sebagai feature map.
Gambar 2. 17 Convolution Layer
Contoh perhitungan:
Langkah 1: membuat filter terlebih dahulu, sebagai contoh membuat
3 ukuran wilayah (2,3,4) dan 2 filter setiap wilayah sehingga
mendapatkan 6 filter. Filter pertama berukuran 4x7, filter kedua
berukuran 3x7 dan filter ketiga berukuran 2x7
Langkah 2: Melakukan proses perhitungan sliding
Proses perhitungan convolution matrix 4x7 pertama
Iterasi 1:
Gambar 2. 18 Iterasi 1 Conv Layer
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

36
Iterasi 2:
Gambar 2. 19 Iterasi 2 Conv Layer
Iterasi 3:
Gambar 2. 20 Iterasi 3 Conv Layer
Iterasi 4:
Gambar 2. 21 Iterasi 4 Conv Layer
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

37
2.9.3. Operasi Pooling
Pooling merupakan pengurangan ukuran matriks dengan
menggunakan operasi pooling. Pooling layer biasanya berada
setelah proses convolution layer. Pada dasarnya, pooling layer
terdiri dari sebuah filter dengan ukuran � 7 � dan stride tertentu
yang akan secara bergantian bergeser pada seluruh area feature map.
Dalam pooling, layer secara bergantian bergeser pada seluruh area
feature map. Dalam pooling layer, terdapat dua macam pooling yang
biasa digunakan yaitu average pooling dan max pooling. Nilai yang
diambil dari average pooling adalah nilai rata – rata, sedangkan pada
max pooling adalah nilai maksimal. Laporan Pooling yang
dimasukkan di antara lapisan konvolusi secara berturut – turut dalam
arsitektur dalam model CNN dapat secara progresif mengurangi
ukuran volume output pada feature map sehingga mengurangi
jumlah parameter dan perhitungan di jaringan tersebut untuk
mengendalikan overfitting. Lapisan pooling bekerja di setiap
tumpukan feature map dan menggunakan pengurangan pada
ukurannya. Bentuk lapisan pooling umumnya dengan menggunakan
panjang dari filter tersebut.
Gambar 2. 22 Pooling Layer
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

38
2.9.4. Fully Connected Layer
Fully Connected Layer adalah sebuah lapisan yang semua
neuron aktivasi dari lapisan sebelumnya terhubung semua dengan
neuron di lapisan selanjutnya sama seperti halnya dengan neural
network pada umumnya. Pada dasarnya, lapisan ini biasanya
digunakan pada MLP (Multi-Layer Perceptron) yang mempunyai
tujuan untuk melakukan transformasi pada dimensi data agar data
dapat diklasifikasikan secara linear. Perbedaan antara lapisan fully -
connected dan lapisan konvolusi biasa adalah neuron di lapisan
konvolusi terhubung hanya ke daerah tertentu pada input, sementara
lapisan fully - connected memiliki neuron yang secara keseluruhan
terhubung. Namun, kedua lapisan tersebut masih mengoperasikan
produk dot sehingga fungsinya tidak begitu berbeda. Berikut ini
adalah proses fully – connected.
Gambar 2. 23 Fully Connected Layer
2.9.5. Softmax Classifier
Fungsi softmax menghitung distribusi probabilitas dari
kejadian di atas 'n' dari berbagai kejadian. Secara umum, fungsi ini
akan menghitung probabilitas masing-masing kelas tujuan melalui
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

39
semua kelas yang ada. Kemudian probabilitas melakukan kalkulasi
yang sangat membantu untuk menentukan kelas tujuan dari input
yang diberikan. Keuntungan utama menggunakan Softmax adalah
output dengan rentang probabilitas. Rentang akan 0 sampai 1 dan
jumlah semua probabilitas akan sama dengan satu. Jika fungsi
softmax digunakan untuk model multi-classification, softmax dapat
mengembalikan probabilitas masing-masing kelas dan kelas target
akan memiliki probabilitas tinggi. Fungsi softmax didefinisikan
sebagai berikut:
/���� � P�+����∑ P+��6�Q6�R
, � � 0,1,2,3, . . ., (2. 8)
Perhitunganan Feed forward menggunakan softmax
#�� � S�/T�� 7 F�� � �/T� 7 F�� � �/T�� 7 F �� �/T� 7 FU� � �/T � 7 FV� � �/TW� 7 F���� �X/T 7 1�Y
#�� � S�0.11 7 0.1� � �0.14 7 0.3� � �0.14 7 0.4�� �0.09 7 0.2� � �0.17 7 0.7� � �0.14 7 0.19�� �0.35 7 1�Y � 1.86376754
#� � S�/T�� 7 F� � �/T� 7 F� � �/T�� 7 FW�� �/T� 7 F^� � �/T � 7 F�R� � �/TW� 7 F��� �X/T 7 1�Y
#� � S�0.11 7 0.3� � �0.14 7 0.4� � �0.14 7 0.3�� �0.09 7 0.1� � �0.17 7 0.8� � �0.14 7 0.1�� �0.35 7 1�Y � 1.89648088
�'�)����#��� � exp�#���B+�#��� � exp �#�� �'�)����#�� � exp�#��
B+�#��� � exp �#��
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

40
�'�)����#��� � 1.863767543.76024842
�'�)����#��� � 0.49565011
�'�)����#�� � 1.896480883.76024842
�'�)����#�� � 0.50434989
Gambar 2. 24 Softmax Classifier
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

41
2.10 Word Embedding
Word Embedding yang dikembangkan oleh Thomas Mikolov,
merupakan implementasi jaringan syaraf tiruan yang dapat mengolah kata-
kata dari dataset yang sangat besar dengan waktu yang relatif singkat dan
nilai akurasi yang lebih baik dibandingkan dengan metode yang pernah ada
sebelumnya. Alat ini bekerja dengan cara mengambil korpus teks sebagai
input, lalu menghasilkan representasi vektor dari setiap kata yang ada pada
korpus teks tersebut sebagai output. Hasil dari file vektor ini dapat
digunakan sebagai penelitian pada natural language processing dan aplikasi
machine learning. Selain itu, vektor kata tersebut juga dapat digunakan
dalam mengukur jarak kedekatan terhadap vektor kata yang lain. Misalnya
sebuah kata “Indonesia” direpresentasikan menjadi sebuah vektor dengan
panjang 5 yaitu: [0.2, 0.4, -0.8, 0.9, -0.5]. Vektor tersebut tidak hanya
merepresentasikan kata secara sintaktik tapi juga secara semantik atau
secara makna.
Sebagai contoh, apabila word embeding di-train menggunakan
korpus yang cukup lengkap, maka vektor representasi dari kata “Indonesia”
akan berdekatan dengan vektor “Jakarta” sebagaimana vektor “Perancis”
akan berdekatan dengan vektor “Paris”. Dengan kata lain, model word2vec
akan memahami bahwa “Indonesia” dan “Jakarta memiliki hubungan yang
sama dengan “Perancis” dan “Paris” yaitu negara dan ibukotanya.
Word embedding menggunakan neural network untuk mendapatkan
vektor tersebut. Arsitektur Word Embedding hanya terdiri tas 3-layer yaitu
Input, Projection (Hidden Layer), dan Output. Input pada Word Embedding
berbentuk one-hot encoded vector dengan panjang jumlah kata unik pada
data training. Terdapat 2 jenis arsitektur neural network dari Word2Vec
yaitu “Skip-gram” dan “Continuous Bag of Word” (CBOW).
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

42
a. Skip-gram
Tujuan dari arsitektur skip-gram adalah untuk memprediksi
konteks (output) di sekitar current word (input). Misal data training-
nya adalah sebuah kalimat “Ibu kota Negara Indonesia adalah
Jakarta” dengan window size = 2.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

43
Data input berbentuk one-hot encoded vector sehingga
bentuk datanya adalah seperti berikut (anggap seluruh data di
lowercase terlebih dahulu):
Ibu :[1,0,0,0,0,0]
kota :[0,1,0,0,0,0]
negara :[0,0,1,0,0,0]
Indonesia :[0,0,0,1,0,0]
adalah :[0,0,0,0,1,0]
jakarta :[0,0,0,0,0,1]
Misal current word Indonesia, maka ilustrasinya adalah sebagai
berikut:
Gambar 2. 25 Arsitektur Skip-Gram
Inisialisasi bobot pada F dan F’ adalah random. Bobot F
dan F’ merupakan matrik dengan ukuran F � c 7 d dan F’ � d 7 c. Pada proses feedforward, vektor input akan di-dot product
dengan bobot F dan menghasilkan nilai pada layer projection.
Kemudian layer projection di dot product dengan bobot F’ dan
menghasilkan vektor output. Setelah mendapatkan nilai output pada
tahap feedforward, maka akan dihitung nilai erornya dengan
menggunakan metode cross entropy yaitu Target - Output.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

44
Selanjutnya adalah tahap backpropagation dengan memanfaatkan
teknik gradient descent yaitu dengan melakukan update bobot F
dan F’. Proses ini akan diulang kembali ke tahap feedforward
hingga tercapai nilai eror minimum.
Setelah didapatkan nilai eror minimum pada cross entropy,
maka vektor yang merepresentasikan kata tersebut diambil dari
bobot F dengan cara mengalikan dot product antara one-hot
encoded vector masing-masing kata dengan bobot F, sedangkan
bobot pada F’ akan diabaikan.
2.11 Pengukuran Performa
Ketika sebuah sistem telah berhasil dirancang sebagaimana
mestinya dan sudah diimplementasikan dan kemudian menghasilkan nilai
seperti yang diinginkan, tahapan selanjutnya adalah pengukuran performa.
Pengukuran performa dilakukan untuk menguji keakuratan, keefektifan,
dan efisiensi sistem yang dibangun. Terdapat sekumpulan rumus yang dapat
digunakan sebagai media pengukuran yang sesuai dengan penelitian yang
sedang dilakukan yaitu Precision, Recall dan Accuracy.
Precision and Recall adalah matriks perhitungan yang digunakan
untuk mengukur kefektifitasan pengambilan informasi (Manning,
Raghavan, & Schütze, 2008).
Precision (e) adalah pecahan dari dokumen dan diambil yang
relevan.
eAB*�@�'� � #��'g(�B� &BA�)� +�h@( )BAgh�@���g�@� +�h@(�#�i(�h�ℎ �'g(�B� )BAgh�@���g�@� +�h@(�
Recall (8) adalah bagian dari dokumen yang relevan yang diambil.
8B*�hh � #��'g(�B� &BA�)� +�h@( )BAgh�@���g�@� +�h@(�#�i(�h�ℎ �'g(�B� +�h@( ���, ��(i��
Gagasan tersebut dapat diperjelas melalui tabel berikut:
Tabel 2. 6 Confusion Matrix
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

45
Relevan Tidak Relevan
)A(B +'@�)�JB �)+� ��h@B +'@�)�JB ��+�
��h@B �B,�)�JB ���� )A(B �B,�)�JB �)��
Berdasarkan tabel di atas, dapat dituliskan rumus sebagai berikut untuk
menghitung akurasi sebuah sistem menggunakan perhitungan Precision and
Recall (Manning et al., 2008):
e � )+
)+ � �+
8 � )+)+ � ��
(2. 9)
Misal jika terdapat 10 buah dokumen berita yang akan diuji dalam
sistem deteksi berita palsu dan telah diklasifikasi sebelumnya menjadi 5
dokumen memiliki konten palsu dan 5 dokumen merupakan berita orisinal.
Kemudian 10 dokumen tersebut diuji dalam sistem dan sistem memberikan
hasil bahwa terdapat 7 dokumen yang terdeteksi sebagai konten palsu yaitu
4 berita berkonten palsu dan 3 berita berkonten orisinal. Dapat disebutkan
bahwa 4 berita berkonten palsu yang diambil merupakan nilai true positive
()+), 3 berita berkonten orisinal yang diambil merupakan nilai false positive
(�+), 1 berita berkonten palsu yang tidak diambil merupakan nilai false
negative (��) dan 3 berita berkonten orisinal sisanya yang tidak diambil
merupakan nilai true negative ()�). Selain Precision and Recall, dalam
perhitungan performa sistem juga diperlukan adanya perhitungan akurasi
sistem untuk memastikan seberapa akurat sistem tersebut dapat digunakan
dalam mendeteksi konten palsu pada berita. Tingkat akurasi sebuah sistem
dapat dihitung menggunakan persamaan berikut (Syafitri, 2010).
�**(A�*� � ∑ ��)*ℎ∑ )+ 7 100%
(2.
10)
Keterangan:
�**(A�*� : tingkat akurasi (%)
∑ ��)*ℎ : jumlah deteksi yang benar
∑ )+ : jumlah data yang diuji
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

46
Jumlah deteksi benar adalah jumlah banyaknya data uji yang telah
diuji dan sesuai dengan pengelompokannya, nilai tersebut didapatkan dari
penjumlahan antara nilai true positive dan nilai true negative. Kemudian
pembaginya adalah total dari seluruh data yang digunakan dalam pengujian.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

47
BAB III
METODE PENELITIAN
3.1. Deskripsi Data
Data yang digunakan pada penelitian ini adalah berita dari website situs
turnbackhoax.id yang diambil dari periode Juli 2015 hingga Agustus 2020
dengan mengambil dataset dari perlombaan Satria Data 2020, data dapat di
akses melalui link pada halaman lampiran. Data tersebut merupakan data
berita palsu maupun asli yang sudah diuji kebenarannya sehingga bisa
dipertanggungjawabkan.
Data yang diperoleh dari tersebut sebanyak 4.231 berita dengan berita
asli sebanyak 766 data dan berita palsu sebanyak 3.465 data. Data pada
Gambar 3.1 berisi ID, label, tanggal, judul, narasi, nama file gambar.
Gambar 3. 1 Data
3.2. Kebutuhan Perangkat Hardware dan Software
a. Spesifikasi Hardware
i. Processor AMD A9-9420 3.00 GHz
ii. VGA Radeon R5 M420 2GB
iii. RAM 12 GB
b. Spesifikasi Software
i. Sistem Operasi Windows 10 Home Single Language
ii. PyCharm 2020.2.1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

48
3.3. Perancangan Sistem
Pada tahap ini, akan dirancang sebuah sistem untuk melakukan
sebuah prediksi berita palsu dengan menggunkan metode Convolution
Neural Network. Tahapan pertama adalah sistem akan membaca data berita
yang sudah memiliki label kemudian melakukan proses preprocessing untuk
membuat data teks tersebut menjadi terstruktur. Proses selanjutnya adalah
melakukan ekstrasi ciri dengan melakukan pembobotan kata dengan TF -
IDF. Setelah dilakukan ekstraksi ciri maka dilakukan proses embedding text
pada klasifikasi dengan menggunakan pendekatan Convolution Neural
Network. Hasil model dari proses klasifikasi tersebut akan diuji dengan data
uji sehingga mendapatkan hasil akurasi dengan perhitungan menggunakan
confusion matrix. Gambar 3.2 merupakan diagram perancangan sistem
Gambar 3. 2 Diagram Perancangan Sistem
3.3.1. Preprocessing
Pada tahap awal untuk melakukan proses klasifikasi dengan
menggunakan metode convolution neural network adalah
melakukan proses preprocessing terlebih dahulu. Pada tahap ini data
mentah yang berupa text berita menjadi data yang akan dimasukkan
dalam proses feature extraction, sehingga dapat diproses ke tahap
selanjutnya. Proses preprocessing (Gambar 3.3) terdapat beberapa
proses yaitu case folding, stemming, tokenizing, stopword removal,
dan punctuation removal.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

49
Gambar 3. 3 Diagram Preprocessing
1. Case Folding
Case Folding merupakan tahapan awal dari
preprocessing yang bertujuan untuk mengubah kata – kata yang
didapat menjadi format yang sama. Pada tahap ini dilakukan
dengan mengubah kata menjadi huruf kecil. Berikut
implementasi proses case folding
Pada tahap ini setelah data berita telah dibaca, sistem
akan mengubah seluruh kalima menjadi huruf kecil.
Langkah – langkah case folding:
a. Baca pada text berita sebagai satu kesatuan dokumen
b. Dokumen yang terdiri dari huruf besar akan diubah
menjadi huruf kecil dengan fungsi lower
c. Dokumen disimpan dengan hasil seluruh huruf menjadi
huruf kecil.
Pada langkah – langkah diatas, dapat diimplementasikan
pada pemrograman python menggunakan library yang tersedia.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

50
Tabel 3. 1 Case Folding
Sebelum Case Folding Setelah Case Folding
Irina, Istri Ahli IT
Hermansyah disebut Mantan
PSK
irina, istri ahli it hermansyah
disebut mantan psk
Nezar Patria adalah Kader
PKI, Ikut Rapat Setiap
Malam di Istana Setelah Jam
8 Malam, Demikian Tuduhan
dari Alfian Tandjung
nezar patria adalah kader
pki, ikut rapat setiap malam
di istana setelah jam 8
malam, demikian tuduhan
dari alfian tandjung
Hati -hati Panggilan Telpon
Nomor Tidak Dikenal !!
hati -hati panggilan telpon
nomor tidak dikenal !!
2. Stemming
Setelah melakukan proses case folding, hasil tersebut
masuk kedalam proses stemming. Proses stemming dilakukan
untuk mengembalikan kata menjadi kata dasar dengan cara
menghilangka awalan kata dan akhiran kata.
Langkah – langkah stemming:
a. Baca setiap kata dan bandingkan dengan kata pada
kamus dari normalisasi
b. Jika hasil kata sama dengan kamus maka sudah
termasuk kata normalisasi
c. Jika kata memiliki kata ber-imbuhan maka hapus
imbuhan kata sehingga membentuk kata dasar sesuai
dengan kamus normalisasi
Pada langkah – langkah diatas, dapat
diimplementasikan pada pemrograman python menggunakan
library yang tersedia atau dengan menggunakan library dari
Sastrawi dalam StemmerFactory.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

51
Tabel 3. 2 Stemming
Sebelum Stemming Setelah Stemming
irina, istri ahli it hermansyah
disebut mantan psk
irina istri ahli it hermansyah
sebut mantan psk
nezar patria adalah kader pki,
ikut rapat setiap malam di
istana setelah jam 8 malam,
demikian tuduhan dari alfian
tandjung
nezar patria adalah kader pki
ikut rapat tiap malam di
istana telah jam 8 malam
demikian tuduh dari alfian
tandjung
hati -hati panggilan telpon
nomor tidak dikenal !!
hati -hati panggil telpon
nomor tidak kenal
3. Tokenizing
Tokenizing adalah proses untuk memisakan kalimat
menjadi pecahan per kata yang bertujuan untuk menghilangkan
spasi pada kalimat menjadi bentuk token. Tahap ini dilakukan
dengan melakukan split data berdasarkan spasi.
Langkah – langkah tokenizing:
a. Baca text berita sebagai satu kesatuan dokumen
b. Jika text tersebut terdapat spasi maka akan dilakukan
split data
c. Dokumen disimpan dengan hasil setiap kata terpisah
Pada langkah – langkah diatas, dapat diimplementasikan
pada pemrograman python menggunakan library yang tersedia
atau dengan menggunakan library dari nltk.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

52
Tabel 3. 3 Tokenizing
Sebelum Tokenizing Setelah Tokenizing
irina istri ahli it hermansyah
sebut mantan psk
['irina', 'istri', 'ahli', 'it',
'hermansyah', 'sebut',
'mantan', 'psk']
nezar patria adalah kader pki
ikut rapat tiap malam di
istana telah jam 8 malam
demikian tuduh dari alfian
tandjung
['nezar', 'patria', 'adalah',
'kader', 'pki', 'ikut', 'rapat',
'tiap', 'malam', 'di', 'istana',
'telah', 'jam', '8', 'malam',
'demikian', 'tuduh', 'dari',
'alfian', 'tandjung']
hati -hati panggil telpon
nomor tidak kenal
['hati', '-hati', 'panggil',
'telpon', 'nomor', 'tidak',
'kenal']
4. Stopword Removal
Selanjutnya akan melalui proses stopword removal.
Stopword Removal adalah tahap mengambil kata-kata penting
dari hasil token dengan menggunakan algoritma stoplist
(membuang kata kurang penting) atau wordlist (menyimpan kata
penting).
Langkah- langkah Stopword Removal:
a. Baca tiap token setiap dokumen dan bandingkan dengan
kamus dalam stoplist
b. Jika hasil token sama dengan kata dalam stoplist, maka
kata tersebut dibuang
c. Jika tidak maka kata tersebut disimpan
Pada langkah – langkah diatas, dapat diimplementasikan
pada pemrograman python menggunakan library yang tersedia
atau dengan menggunakan library dari Sastrawi dalam
StopWordRemoverFactory.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
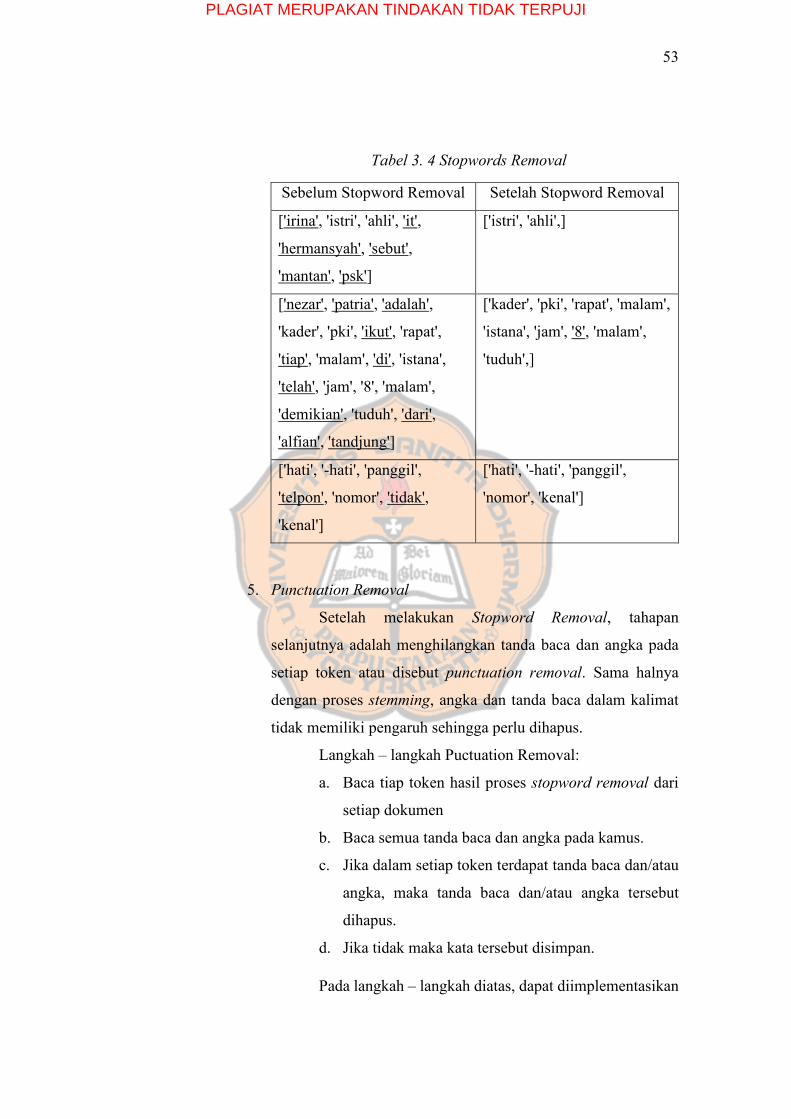
53
Tabel 3. 4 Stopwords Removal
Sebelum Stopword Removal Setelah Stopword Removal
['irina', 'istri', 'ahli', 'it',
'hermansyah', 'sebut',
'mantan', 'psk']
['istri', 'ahli',]
['nezar', 'patria', 'adalah',
'kader', 'pki', 'ikut', 'rapat',
'tiap', 'malam', 'di', 'istana',
'telah', 'jam', '8', 'malam',
'demikian', 'tuduh', 'dari',
'alfian', 'tandjung']
['kader', 'pki', 'rapat', 'malam',
'istana', 'jam', '8', 'malam',
'tuduh',]
['hati', '-hati', 'panggil',
'telpon', 'nomor', 'tidak',
'kenal']
['hati', '-hati', 'panggil',
'nomor', 'kenal']
5. Punctuation Removal
Setelah melakukan Stopword Removal, tahapan
selanjutnya adalah menghilangkan tanda baca dan angka pada
setiap token atau disebut punctuation removal. Sama halnya
dengan proses stemming, angka dan tanda baca dalam kalimat
tidak memiliki pengaruh sehingga perlu dihapus.
Langkah – langkah Puctuation Removal:
a. Baca tiap token hasil proses stopword removal dari
setiap dokumen
b. Baca semua tanda baca dan angka pada kamus.
c. Jika dalam setiap token terdapat tanda baca dan/atau
angka, maka tanda baca dan/atau angka tersebut
dihapus.
d. Jika tidak maka kata tersebut disimpan.
Pada langkah – langkah diatas, dapat diimplementasikan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

54
pada pemrograman python menggunakan library yang tersedia
atau dengan menggunakan library dari re dan string.
Tabel 3. 5 Punctuation Removal
Sebelum Punctuation
Removal
Setelah Punctuation
Removal
['istri', 'ahli',] ['istri', 'ahli',]
['kader', 'pki', 'rapat', 'malam',
'istana', 'jam', '8', 'malam',
'tuduh', 'kader', 'pki', 'rapat',
'malam', 'istana', 'jam',
'malam', 'tuduh']
['kader', 'pki', 'rapat', 'malam',
'istana', 'jam', 'malam',
'tuduh']
['hati', '-hati', 'panggil',
'nomor', 'kenal']
['hati', '-hati', 'panggil',
'nomor', 'kenal']
Hasil akhir dari preprocessing tersebut maka data yang
semula tidak terstruktur menjadi terstruktur
Tabel 3. 6 Setelah Preprocessing
Sebelum Preprocessing Setelah Preprocessing
Irina, Istri Ahli IT
Hermansyah disebut Mantan
PSK
['istri', 'ahli',]
Nezar Patria adalah Kader
PKI, Ikut Rapat Setiap
Malam di Istana Setelah Jam
8 Malam, Demikian Tuduhan
dari Alfian Tandjung
['kader', 'pki', 'rapat', 'malam',
'istana', 'jam', 'malam',
'tuduh']
Hati -hati Panggilan Telpon
Nomor Tidak Dikenal !!
['hati', '-hati', 'panggil',
'nomor', 'kenal']
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

55
3.3.2. Feature Extraction
Ektrasi ciri dari hasil preprocessing tersebut dengan
menghitung kemunculan kata dan menentukan bobot dari setiap kata
dengan menggunakan TF-IDF (Gambar 3.4)
Gambar 3. 4 Diagram Feature Extraction
1. TF-IDF
Tahap ini adalah melakukan pembobotan menggunakan
tf-idf, dimana tahap ini akan menghitung kemunculan kata unik
dalam dokumen kemudian menghitung nilai idf. Berikut adalah
implementasi dari pembobotan tf-idf.
Langkah – langkah proses pembobotan tf-idf:
a. Mencari kata unik dalam dokumen
b. Hitung nilai term frequency dengan persamaan
rumus (2.1) dari masing – masing kata
c. Hitung nilai invers document frequency dengan
persamaan rumus (2.2) dari masing – masing kata
d. Hitung bobot dari term frequency dikalikan dengan
invers document frequency dengan persamaan rumus
(2.3)
e. Ulangi langkah b sampai d untuk setiap dokumen.
Pada langkah – langkah diatas, dapat diimplementasikan
pada pemrograman python menggunakan library dari Tokenizer.
Berikut contoh proses pembobotan kata:
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

56
a. Menghitung Term Frequency
Tabel 3. 7 Proses Perhitungan Term Frequency
D1 D2 D3 D4 D5 indonesia 1 0 0 0 0 orang 0 0 0 0 0 jokowi 0 0 0 2 0 foto 0 0 0 0 1 video 0 0 0 0 0 corona 0 0 0 0 0 virus 0 0 0 0 0 nyata 0 0 0 0 0 covid 0 2 0 0 0 laku 0 0 0 1 0 china 0 0 0 0 0 the 0 0 0 0 0 presiden 0 0 0 0 0 anak 0 0 2 0 0 jakarta 0 0 0 0 0
Gambar 3. 5 Contoh Hasil Term Frequency
Pada proses perhitungan Term Frequency ini,
perhitungan dilakukan dengan menjumlah kata unik yang
muncul pada setiap kata di dalam dokumen. Hal tersebut
bertujuan kata unik tersebut ada atau tidak ada di dalam
sebuah dokumen, jika dalam dokumen tersebut maka akan
ditambah satu dan seterusnya.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

57
b. Menghitung Invers Document Frequency
Tabel 3. 8 Proses Perhitungan Invers Docoment Frequency
D1 D2 D3 D4 D5 N ni idf indonesia 1 0 3 0 2 5 3 0.30103 orang 0 2 0 0 1 5 2 0.47712 jokowi 1 1 1 2 0 5 4 0.17609 foto 1 0 1 0 1 5 3 0.30103 video 0 2 0 4 0 5 2 0.47712 corona 0 5 0 1 1 5 3 0.30103 virus 2 0 0 2 0 5 2 0.47712 nyata 2 0 2 0 2 5 3 0.30103 covid 0 2 0 1 0 5 2 0.47712 laku 5 3 0 1 0 5 3 0.30103 china 1 0 2 1 1 5 4 0.17609 the 0 0 0 1 0 5 1 0.77815 presiden 5 2 0 2 1 5 4 0.17609 anak 1 0 2 1 0 5 3 0.30103 jakarta 0 1 0 2 3 5 3 0.30103
Gambar 3. 6 Contoh Hasil Document Frecuency
Proses invers document frequency (���), dengan
menggunakan rumus persamaan (2.2). ������adalah
perhitungan dari suatu kata yang muncul dari dokumen yang
bersangkutan dimana jumlah dokumen dalam koleksi (M)
dibagi dengan jumlah koleksi dokumen yang mengandung
term �.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

58
c. Menghitung Weight TF-IDF
Tabel 3. 9 Proses Perhitungan Weight TF-IDF
D1 D2 D3 D4 D5 0.30103 0 0.90309 0 0.60206
0 0.95424 0 0 0.47712 0.17609 0.17609 0.17609 0.35218 0 0.30103 0 0.30103 0 0.30103
0 0.95424 0 1.90849 0 0 1.50515 0 0.30103 0.30103
0.95424 0 0 0.95424 0 0.60206 0 0.60206 0 0.60206
0 0.95424 0 0.47712 0 1.50515 0.90309 0 0.30103 0 0.17609 0 0.35218 0.17609 0.17609
0 0 0 0.77815 0 0.88046 0.35218 0 0.35218 0.17609 0.30103 0 0.60206 0.30103 0
0 0.30103 0 0.60206 0.90309
Gambar 3. 7 Contoh Hasil Weight TF-IDF
Pada proses ini perhitungan bobot pada setiap kata
dengan menggunakan persamaan (2.3). ��,6 adalah bobot
dokumen � terhadap kata i. Sedangkan )��,6 adalah jumlah
kemunjulan term (j) dalam sebuah dokumen (i). IDF
diperoleh dari hasil perhitungan ���� dimana perhitungan
dari suatu kata yang muncul dari dokumen yang
bersangkutan. Sehingga hasil dari )��,6 dikali dengan ����
sehingga mendapatkan nilai bobot untuk TF-IDF.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

59
3.3.3. Klasifikasi
Setelah mendapatkan hasil dari proses feature extraction
maka tahapan selanjutnya adalah melakukan proses klasifikasi
(Gambar 3.8).
Gambar 3. 8 Diagram Klasifikasi
Langkah – langkah klasifikasi:
a. Melakukan pembagian data sebesar 70:30, dimana 70
untuk data latih sedangkan 30 untuk data uji berisi label
dan teks berita
b. Melakukan feature extraction pada data yang telah
dibagi.
c. Data latih digunakan untuk membuat model dengan
menggunakan CNN sehingga mendapatkan sebuah
model
d. Setelah mendapatkan model maka tahap selanjutnya
adalah melakukan proses klasifikasi dengan data uji
sehingga mendapatkan hasil data klasifikasi tersebut
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

60
3.3.4. Convolution Neural Network
Metode Convolution Neural Network. Convolutional neural
network (CNN) merupakan salah satu metode deep learning yang
dapat diterapkan untuk melakukan klasifikasi dokumen teks. Pada
Gambar 3.9 merupakan diagram alur dari metode CNN.
Gambar 3. 9 Diagram Convolution Neural Network
Langkah – langkah metode CNN:
a. Membuat Embedding Word dari hasil feature extraction
b. Melakukan proses perhitungan convolution layer
sehingga mendapatkan feature map berdasarkan ukuran
filter yang ditentukan dan membentuk sebuah matriks
berukuran � 7 � 7 +
c. Jika telah selesai maka melakukan Max Pooling Layer,
yaitu mengambil nilai max dengan filter � 7 � dari setiap
feature map yang didapatkan sehingga matrix tersebut
menjadi lebih kecil dari matriks convolution
d. Setelah mendapatkan matrix max pooling, selanjutnya
reshape feature map dari matriks vektor menjadi sebuah
vektor 1 7 �
e. Vektor 1 7 � yang telah didapatkan dilakukan proses
Fully Connected Layer dengan � Layer
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

61
f. Hitung softmax dari hasil fully connected layer, untuk
memprediksi kelas
Pada langkah – langkah diatas, dapat diimplementasikan
pada pemrograman python menggunakan library dari Tensorflow.
Sehingga pada Gambar 3.10 merupakan modelling Convolution
Neural Network
Gambar 3. 10 Modelling Convolution Neural Network
Contoh perhitungan Convolution Neural Network:
a. Membentuk Embedding Layer
Tabel 3. 10 Contoh Representasi Word Embedding
D1 Input Embedding Embedding Layer
Indonesia 0.30103, 0, 0.90309, …, 0, 0.60206
-0.04638, 0.02711, -0.04863, 0.04224, 0.01683,... ,0.00573, 0.00087, -0.02173
orang 0, 0.95424, 0, ..., 0, 0.47712
-0.04638, 0.02711, -0.04863, 0.04224,
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

62
0.01683,..., 0.00573, 0.00087, -0.02173
jokowi 0.17609, 0.17609, 0.17609, ..., 0.35218, 0
0.0369, 0.0112, -0.01504, -0.04817, -0.02483,..., 0.01842, 0.04409, -0.0316
… …
video 0.30103, 0, 0.30103, ..., 0, 0.30103
0.0369, 0.0112, -0.01504, -0.04817, -0.02483,..., 0.01842, 0.04409, -0.0316
corona 0, 0.95424, 0, ..., 1.90849, 0
0.0369, 0.0112, -0.01504, -0.04817, -0.02483,..., 0.01842, 0.04409, -0.0316
Pada proses ini, inisialisasi bobot pada F dan F’ adalah
random. Bobot F dan F’ merupakan matrik dengan ukuran F � c 7 d dan F’ � d 7 c. Pada proses feedforward, vektor input
akan di dot product dengan bobot F dan menghasilkan nilai pada
layer projection. Kemudian layer projection di dot product dengan
bobot F’ dan menghasilkan vektor output. Setelah mendapatkan
nilai output pada tahap feedforward, maka akan dihitung nilai eror
nya dengan menggunakan metode cross entropy yaitu Target -
Output. Selanjutnya adalah tahap backpropagation dengan
memanfaatkan teknik gradient descent yaitu dengan melakukan
update bobot F dan F’. Proses ini akan diulang kembali ke tahap
feedforward hingga tercapai nilai eror minimum.
Setelah didapatkan nilai eror minimum pada cross entropy,
maka vektor yang merepresentasikan kata tersebut diambil dari
bobot F dengan cara mengalikan dot product antara one-hot
encoded vector masing-masing kata dengan bobot F, sedangkan
bobot pada F’ akan diabaikan. Gambar 3.11 merupakan contoh
hasil dari proses repesentasi embedding layer.
vocab_size : Ukuran dari kosakata. Ini diperlukan untuk
mendefinisikan ukuran dari embedding
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

63
layer, yang akan memiliki bentuk
[vocabulary_size, embedding_size]
embedding_size : Dimensi dari embeddings
Weights : Bobot
input_length : Panjang input sequence
Gambar 3. 11 Hasil Representasi Word Embedding
b. Menghitung Convolution
Gambar 3. 12 Convolution Layer
Pada proses ini, embedding yang sudah didapatkan
dikalikan dengan filter W0 dan W1 dengan stride 1, sehingga
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

64
matriks embedding tersebut akan terpecah menjadi 2 bagian,
tahapan ini disebut dengan tahap konvolusi seperti Gambar 3.12.
Dengan parameter yang digunakan:
filters : Ukuran dimensi kata untuk proses konvulasi
kernel_size : Banyaknya jendela konvolusi 1D.
activation : Fungsi Aktivasi (relu, sigmoid, softmax, softplus,
softsign, selu, elu, exponential)
c. Menghitung Max Pooling
Gambar 3. 13 Max Pooling Layer
Proses ini adalah mengurangi dimensi dari feature map
dengan mencari nilai maximal dari feature map tersebut. Pada
contoh diatas digunakan filter berukuran 2 x 2 dan dilakukan
pergeseran sebanyak 1 kali sehingga ukuran matriks berukuran
4 x 5 menjadi 3 x 4. Gambar 3.13 merupakan contoh dari max
pooling layer
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

65
d. Flatten Layer
Gambar 3. 14 Flatten Layer
Pada proses ini, yaitu reshape feature map menjadi
sebuah vektor, matriks berukuran 3 7 4 7 2 tersebut akan
dibentuk menjadi 1 7 24. Hal ini dilakukan agar bisa gunakan
sebagai input dari fully connected layer. Gambar 3.14
merupakan contoh dari flatten layer.
e. Fully Connected Layer
Fully Connected Layer adalah sebuah lapisan dimana
semua neuron aktivasi dari lapisan sebelumnya terhubung semua
dengan neuron di lapisan selanjutnya sama seperti halnya
dengan neural network pada umumnya. Dengan parameter yang
digunakan
units : Jumlah neuron
activation : Fungsi aktivasi (relu, sigmoid, softmax,
softplus, softsign, selu, elu, exponential)
Setelah membangun model Convolution Neural
Network, saatnya melakukan kompilasi. Dengan parameter yang
digunakan:
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

66
optimizer : optimisasi dengan algoritma (SGD, RMSprop,
Adam, Adadelta, Adagrad, Adamax, Nadam, Ftrl)
loss : menghitung kuantitas yang harus diminimalkan
(binary_crossentropy, categorical_crossentropy,
sparse_categorical_crossentropy)
metrics : Daftar metrics yang akan dievaluasi oleh model
selama pelatihan dan pengujian. (accuracy,
probabilistic, classification, image segmentation,
hinge)
Selanjutnya melakukan pelatihan model atau fitting
model, dengan parameter yang digunakan:
epochs : Jumlah iterasi dalam melakukan pelatihan
model
validation_data : Data untuk mengevaluasi loss dan metrics
model di akhir setiap epoch.
3.3.5. Pengukuran Performa
Tahap ini penghitungan akurasi adalah hasil yang diprediksi
oleh sistem akan dibandingkan dengan label aktual dari setiap berita.
Kecocokan dari setiap label berita akan mempengaruhi hasil dari
sistem. Setelah perhitungan Convolution Neural Network dilakukan
maka pengujian akurasi dilakukan untuk mengetahui keakuratan
dasil klasifikasi. Pada pengujian akurasi dilakukan dengan
menggunakan Confusion Matrix. Confusion Matrix (Gambar 3.15)
digunakan untuk mengetahui seberapa besar keberhasilan sistem
dalam melakukan klasifikasi. Confusion matrix mempermudah
perhitungan akurasi dalam melihat suatu permodelan antara label
aktual dari berita dan prediksi dari sistem seperti pada Gambar 3.16.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

67
Gambar 3. 15 Diagram Confusion Matrix
Berikut langkah – langkah uji akurasi:
a. Baca label aktual dari setiap berita
b. Baca label berita hasil dari prediksi sistem
c. Bandingkan menggunakan tabel confusion matriks.
d. Hitung akurasi dengan cara membagi berita benar dibagi
dengan seluruh data dikalikan dengan 100%.
Menghitung akurasi menggunakan persamaan rumus
(2.8)
Pada langkah – langkah diatas, dapat diimplementasikan
pada pemrograman python menggunakan fungsi confusion_matrix
dalam library metrics di sklearn.
Contoh perhitungan pengukuran performa:
Tabel 3. 11 Contoh Hasil Prediksi Berita
Document Prediksi Aktual
Document 1 1 1
Document 2 0 0
Document 3 1 1
Document 4 0 1
Document 5 0 0
T'��(@�'� ��)A�� � 45 7 100% � 80%
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

68
Gambar 3. 16 Confusion Matrix
3.3.6. Prediksi
Proses prediksi tersebut dapat dilakukan setelah proses
klasifikasi telah dilakukan sehingga mendapatkan sebuah array
akhir hasil dari perhitungan klasifikasi CNN tersebut. Pada Gambar
3.17 merupakan diagram bagaimana proses prediksi dilakukan
dengan model yang tersedia dengan data baru.
Gambar 3. 17 Diagram Prediksi
Langkah – langkah prediksi:
a. Ambil data berita baru yang belum ada dalam data
pengujian
b. Data dilakukan proses preprocessing, sehingga data
tidak tersturktur menjadi data terstruktur.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

69
c. Masukkan data terstruktur kedalam model CNN
d. Mendapatkan hasil prediksi
Pada langkah – langkah diatas, dapat diimplementasikan
pada pemrograman python menggunakan fungsi Conv1D dalam
library keras di tensorflow.
3.4. Cara Pengujian
Pada tahap pengujian, dilakukan analisis dari hasil luaran sistem yang
telah dibuat. Tujuannya untuk menjawab rumusan masalah yang telah
dipaparkan dibab sebelumnya. Pada tahap ini data dilakukan preprocessing
terlebih dahulu agar data yang tidak terstruktur menjadi terstruktur.
Selanjutnya data yang sudah terstruktur tersebut dilakukan split data dengan
perbandingan 70:30, dimana 70% untuk data training dan 30% untuk data
testing. Setelah dilakukan split data, maka selanjutnya menghitung term
frequency dan invers document frequency. Hasil dari ekstraksi ciri tersebut
akan dilakukan evaluasi dengan pendekatan Convolution Neural Network,
dimana dilakukan beberapa percobaan yaitu membuat variasi percobaan
dengan mengganti jumlah layer Conv1D dan jumlah filter yang digunakan,
lalu jumlah hidden layer pada fully connected layer dan jumlah neuron yang
digunakan. Sedangkan untuk fungsi aktivasi yang digunakan dalam fully
connected layer adalah ReLu sedangkan untuk softmax classifier
menggunakan fungsi aktivasi sigmoid. Sehingga dari model yang telah
dibuat lalu dilakukan proses kompilasi model dengan parameter yang
digunakan adalah untuk optimizer menggunakan adam, loss menggunakan
binary_crossentropy dan metrics menggunakan accuracy. Pada proses
evaluasi model tersebut parameter yang digunakan adalah epoch
menggunakan 5 iterasi, dan dilakukan validasi data dengan data uji. Setelah
mendapatkan hasil akurasi yang optimal maka model yang telah dibuat
dengan implementasi algoritma Convolution Neural Network dapat
digunakan untuk melakukan prediksi berita tersebut palsu atau asli.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

70
3.5. Desain User Interface
Gambar 3. 18 Desain GUI
3.5.1. Input GUI
1. Memasukkan isi salah satu berita baru kedalam text field yang di
sediakan
2. Menekan tombol Prediksi untuk melakukan proses prediksi
3.5.2. Output GUI
1. Hasil keluaran dari prediksi tersebut adalah Asli atau Palsu di
dalam text field Hasil
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

71
BAB IV
HASIL DAN ANALISIS
Bab ini akan membahas hasil implementasi dari sistem yang telah dibuat
serta menganalisis hasil pengujian yang telah dilakukan.
4.1. Data
Data yang digunakan pada penelitian ini adalah berita dari website situs
turnbackhoax.id yang diambil dari periode Juli 2015 hingga Agustus 2020
dengan mengambil dataset dari perlombaan Satria Data 2020, data dapat di
akses melalui link pada halaman lampiran. Data tersebut merupakan data
berita palsu maupun asli yang sudah diuji kebenarannya sehingga bisa
dipertanggungjawabkan. Data yang diperoleh dari tersebut sebanyak 4.231
berita dengan berita asli sebanyak 766 data dan berita palsu sebanyak 3.465
data. Data tersebut berisi ID, label, tanggal, judul, narasi, nama file gambar.
Data yang akan digunakan adalah label dan judul + narasi. Data pada
judul akan disatukan dengan narasi sehingga hal tersebut dapat menjadi
tambahan agar sistem dapat membaca data dengan baik. Sedangkan ID,
tanggal, dan nama file gambar tidak digunakan karena data tersebut tidak
diperlukan dalam penelitian ini. Bahasa yang digunakan dalam penelitian
ini adalah dengan menggunakan Bahasa Python.
Proses pada python untuk membaca data adalah dengan import library
pandas terlebih dahulu, selanjutnya adalah membaca file dari folder data
dengan mengambil file data.csv. Selanjutnya, isi pada judul dan narasi
dijadikan satu sehingga bisa dilihat pada pada tabel 4.1 untuk isi dari judul
dan narasi.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

72
Tabel 4. 1 Contoh Data
Label Judul + Narasi
1
Pemakaian Masker Menyebabkan Penyakit Legionnaires A caller to a radio talk show recently shared that his wife was hospitalized n told she had COVID n only a couple of days left to live . A doctor friend suggested she be tested for legionnaires disease because she wore the same mask every day all day long . Turns out it WAS legionnaires disease from the moisture n bacteria in her mask . She was given antibiotics n within two days was better . WHAT IF these ‘spikes’ in COVID are really something else due to ‘mask induced infections’ .????????
1
Instruksi Gubernur Jateng tentang penilangan bagi yg tidak bermasker di muka umum Rp.150.000 menggunakan e-tilang Via apps PIKOBAR Yth.Seluruh Anggota Grup Sesuai Instruksi Gubernur Jawa Tengah Hasil Rapat Tim Gugus Tugas Covid 19 Jateng sbb:
1 Foto Jim Rohn: Jokowi adalah presiden terbaik dlm sejarah bangsa Indonesia Jokowi adalah presiden terbaik dlm sejarah bangsa Indonesia. Jim Rohn, motivator terbaik dunia
1
ini bukan politik, tapi kenyataan Pak Jokowi berhasil memulangkan 11,000 Triliun uang negara dari Swiss. Maaf Mas2 dan Mbak2, ini bukan politik, tapi kenyataan Pak Jokowi berhasil memulangkan 11,000 Triliun uang negara dari Swiss. 11ribu Triliun siap di bawa balik ke Indonesia.RUU Treaty on Mutual Legal Assistance in Criminal Matters between the Republic of Indonesia and The Swiss Confederation (MLA RI-Swiss) resmi disahkan DPR RI tanggal 3 juli 2020. Dengan demikian proses konstitusi menarik dana di Swiss sudah selesai. Perjuangan yang panjang menghadapi ex koruptor yang bersenggama dengan agama. Terimakasih para kadrun yang terus nyinyirian kapan uang 11.000 triliun kembali ke Indonesia. Tanpa anda nyinyir, rasanya sulit RUU itu bisa disahkan oleh DPR. Pemilik 84 rekening gendut siap siap gigit jari . Mungkin tekanan ke Pak Jokowi makin kencang. ini baca beritanya
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

73
4.2. Implementasi Preprocessing
4.2.1. Case Folding
Dataset akan dilakukan proses case folding dengan tujuan
untuk membuat semua huruf menjadi kecil
Pada proses di dalam python untuk membuat teks menjadi
lower case dengan menggunakan function lower() sehingga hasil
dari proses ini dapat dilihat pada tabel 4.2 dimana tulisan yang
berawal terdapat huruf kapital akan di ubah menjadi huruf kecil.
Tabel 4. 2 Case Folding
Sebelum Case Folding Setelah Case Folding Pemakaian Masker Menyebabkan Penyakit Legionnaires A caller to a radio talk show recently shared that his wife was hospitalized n told she had COVID n only a couple of days left to live . A doctor friend suggested she be tested for legionnaires disease because she wore the same mask every day all day long . Turns out it WAS legionnaires disease from the moisture n bacteria in her mask . She was given antibiotics n within two days was better . WHAT IF these ‘spikes’ in COVID are really something else due to ‘mask induced infections’ .????????
pemakaian masker menyebabkan penyakit legionnaires a caller to a radio talk show recently shared that his wife was hospitalized n told she had covid n only a couple of days left to live . a doctor friend suggested she be tested for legionnaires disease because she wore the same mask every day all day long . turns out it was legionnaires disease from the moisture n bacteria in her mask . she was given antibiotics n within two days was better . what if these â‘spikesâ’ in covid are really something else due to â‘mask induced infectionsâ’ .????????
Instruksi Gubernur Jateng tentang penilangan bagi yg tidak bermasker di muka umum Rp.150.000 menggunakan e-tilang Via apps PIKOBAR Yth.Seluruh Anggota Grup Sesuai Instruksi Gubernur Jawa Tengah Hasil Rapat Tim Gugus Tugas Covid 19 Jateng sbb:
instruksi gubernur jateng tentang penilangan bagi yg tidak bermasker di muka umum rp.150.000 menggunakan e-tilang via apps pikobar yth.seluruh anggota grup sesuai instruksi gubernur jawa tengah hasil rapat tim gugus tugas covid 19 jateng sbb:
Foto Jim Rohn: Jokowi adalah presiden terbaik dlm sejarah bangsa Indonesia Jokowi adalah presiden terbaik dlm
foto jim rohn: jokowi adalah presiden terbaik dlm sejarah bangsa indonesia jokowi adalah presiden terbaik dlm
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

74
sejarah bangsa Indonesia. Jim Rohn, motivator terbaik dunia
sejarah bangsa indonesia. jim rohn, motivator terbaik dunia
ini bukan politik, tapi kenyataan Pak Jokowi berhasil memulangkan 11,000 Triliun uang negara dari Swiss. Maaf Mas2 dan Mbak2, ini bukan politik, tapi kenyataan Pak Jokowi berhasil memulangkan 11,000 Triliun uang negara dari Swiss. 11ribu Triliun siap di bawa balik ke Indonesia.RUU Treaty on Mutual Legal Assistance in Criminal Matters between the Republic of Indonesia and The Swiss Confederation (MLA RI-Swiss) resmi disahkan DPR RI tanggal 3 juli 2020. Dengan demikian proses konstitusi menarik dana di Swiss sudah selesai. Perjuangan yang panjang menghadapi ex koruptor yang bersenggama dengan agama. Terimakasih para kadrun yang terus nyinyirian kapan uang 11.000 triliun kembali ke Indonesia. Tanpa anda nyinyir, rasanya sulit RUU itu bisa disahkan oleh DPR. Pemilik 84 rekening gendut siap siap gigit jari . Mungkin tekanan ke Pak Jokowi makin kencang. ini baca beritanya
ini bukan politik, tapi kenyataan pak jokowi berhasil memulangkan 11,000 triliun uang negara dari swiss. maaf mas2 dan mbak2, ini bukan politik, tapi kenyataan pak jokowi berhasil memulangkan 11,000 triliun uang negara dari swiss. 11ribu triliun siap di bawa balik ke indonesia.ruu treaty on mutual legal assistance in criminal matters between the republic of indonesia and the swiss confederation (mla ri-swiss) resmi disahkan dpr ri tanggal 3 juli 2020. dengan demikian proses konstitusi menarik dana di swiss sudah selesai. perjuangan yang panjang menghadapi ex koruptor yang bersenggama dengan agama. terimakasih para kadrun yang terus nyinyirian kapan uang 11.000 triliun kembali ke indonesia. tanpa anda nyinyir, rasanya sulit ruu itu bisa disahkan oleh dpr. pemilik 84 rekening gendut siap siap gigit jari . mungkin tekanan ke pak jokowi makin kencang. ini baca beritanya
4.2.2. Stemming
Setelah dataset telah melakukan proses case folding maka
lanjut ke tahapan selanjutnya. Data dilakukan proses stemming
untuk mengembalikan kata menjadi kata dasar yaitu dengan cara
menghilangkan semua imbuhan yang terdiri dari awalan, sisipan,
akhiran dan kombinasi awalan dan akhiran.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

75
Pada proses di dalam python untuk mengembalikan kata
menjadi kata dasar yaitu pertama import library dari Sastrawi,
selanjutnya adalah mendefinisikan kamus dari StemmerFactory dan
membuat kamus dengan create_stemmer. Sehingga hasil dari
stemming ini dapat dilihat pada tabel 4.3 dimana kata berimbuhan
akan diubah menjadi kata dasar.
Tabel 4. 3 Stemming
Sebelum Stemming Setelah Stemming pemakaian masker menyebabkan penyakit legionnaires a caller to a radio talk show recently shared that his wife was hospitalized n told she had covid n only a couple of days left to live . a doctor friend suggested she be tested for legionnaires disease because she wore the same mask every day all day long . turns out it was legionnaires disease from the moisture n bacteria in her mask . she was given antibiotics n within two days was better . what if these â‘spikesâ’ in covid are really something else due to â‘mask induced infectionsâ’ .????????
pakai masker sebab sakit legionnaires a caller to a radio talk show recently shared that his wife was hospitalized n told she had covid n only a couple of days left to live a doctor friend suggested she be tested for legionnaires disease because she wore the same mask every day all day long turns out it was legionnaires disease from the moisture n bacteria in her mask she was given antibiotics n within two days was better what if these spikes in covid are really something else due to mask induced infections
instruksi gubernur jateng tentang penilangan bagi yg tidak bermasker di muka umum rp.150.000 menggunakan e-tilang via apps pikobar yth.seluruh anggota grup sesuai instruksi gubernur jawa tengah hasil rapat tim gugus tugas covid 19 jateng sbb:
instruksi gubernur jateng tentang tilang bagi yg tidak masker di muka umum rp 150 000 guna e-tilang via apps pikobar yth seluruh anggota grup sesuai instruksi gubernur jawa tengah hasil rapat tim gugus tugas covid 19 jateng sbb
foto jim rohn: jokowi adalah presiden terbaik dlm sejarah bangsa indonesia jokowi adalah presiden terbaik dlm sejarah bangsa indonesia. jim rohn, motivator terbaik dunia
foto jim rohn jokowi adalah presiden baik dlm sejarah bangsa indonesia jokowi adalah presiden baik dlm sejarah bangsa indonesia jim rohn motivator baik dunia
ini bukan politik, tapi kenyataan pak jokowi berhasil memulangkan 11,000 triliun uang negara dari swiss. maaf mas2 dan mbak2, ini bukan politik, tapi kenyataan pak jokowi berhasil memulangkan 11,000 triliun uang negara dari swiss. 11ribu triliun siap di bawa
ini bukan politik tapi nyata pak jokowi hasil pulang 11 000 triliun uang negara dari swiss maaf mas2 dan mbak2 ini bukan politik tapi nyata pak jokowi hasil pulang 11 000 triliun uang negara dari swiss 11ribu triliun siap di bawa balik ke indonesia
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

76
balik ke indonesia.ruu treaty on mutual legal assistance in criminal matters between the republic of indonesia and the swiss confederation (mla ri-swiss) resmi disahkan dpr ri tanggal 3 juli 2020. dengan demikian proses konstitusi menarik dana di swiss sudah selesai. perjuangan yang panjang menghadapi ex koruptor yang bersenggama dengan agama. terimakasih para kadrun yang terus nyinyirian kapan uang 11.000 triliun kembali ke indonesia. tanpa anda nyinyir, rasanya sulit ruu itu bisa disahkan oleh dpr. pemilik 84 rekening gendut siap siap gigit jari . mungkin tekanan ke pak jokowi makin kencang. ini baca beritanya
ruu treaty on mutual legal assistance in criminal matters between the republic of indonesia and the swiss confederation mla ri-swiss resmi sah dpr ri tanggal 3 juli 2020 dengan demikian proses konstitusi tarik dana di swiss sudah selesai juang yang panjang hadap ex koruptor yang bersenggama dengan agama terimakasih para kadrun yang terus nyinyirian kapan uang 11 000 triliun kembali ke indonesia tanpa anda nyinyir rasa sulit ruu itu bisa sah oleh dpr milik 84 rekening gendut siap siap gigit jari mungkin tekan ke pak jokowi makin kencang ini baca berita
4.2.3. Tokenizing
Data yang telah dilakukan proses stemming akan dilakukan
proses tokenization atau memecah dokumen menjadi bentuk per
kata.
Pada proses di pyton untuk memecah dokumen menjadi per
kata dengan menggunakan function split, dimana split ini
berdasarkan spasi. Sebagai contoh dapat dilihat pada tabel 4.4 untuk
proses tokenizing.
Tabel 4. 4 Tokenizing
Sebelum Tokenizing Setelah Tokenizing pakai masker sebab sakit legionnaires a caller to a radio talk show recently shared that his wife was hospitalized n told she had covid n only a couple of days left to live a doctor friend suggested she be tested for legionnaires disease because she wore the same
['Pemakaian', 'Masker', 'Menyebabkan', 'Penyakit', 'LegionnairesA', 'caller', 'to', 'a', 'radio', 'talk', 'show', 'recently', 'shared', 'that', 'his', 'wife', 'was', 'hospitalized', 'n', 'told', 'she', 'had', 'COVID', 'n', 'only', 'a', 'couple', 'of', 'days', 'left', 'to', 'live', '.', 'A', 'doctor',
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
77
mask every day all day long turns out it was legionnaires disease from the moisture n bacteria in her mask she was given antibiotics n within two days was better what if these spikes in covid are really something else due to mask induced infections
'friend', 'suggested', 'she', 'be', 'tested', 'for', 'legionnaires', 'disease', 'because', 'she', 'wore', 'the', 'same', 'mask', 'every', 'day', 'all', 'day', 'long', '.', 'Turns', 'out', 'it', 'WAS', 'legionnaires', 'disease', 'from', 'the', 'moisture', 'n', 'bacteria', 'in', 'her', 'mask', '.', 'She', 'was', 'given', 'antibiotics', 'n', 'within', 'two', 'days', 'was', 'better', '.', 'WHAT', 'IF', 'these', '\x91spikes\x92', 'in', 'COVID', 'are', 'really', 'something', 'else', 'due', 'to', '\x91mask', 'induced', 'infections\x92', '.????????']
instruksi gubernur jateng tentang tilang bagi yg tidak masker di muka umum rp 150 000 guna e-tilang via apps pikobar yth seluruh anggota grup sesuai instruksi gubernur jawa tengah hasil rapat tim gugus tugas covid 19 jateng sbb
['Instruksi', 'Gubernur', 'Jateng', 'tentang', 'penilangan', '', 'bagi', 'yg', 'tidak', 'bermasker', 'di', 'muka', 'umum', 'Rp.150.000', 'menggunakan', 'e-tilang', 'Via', 'apps', 'PIKOBARYth.Seluruh', 'Anggota', 'Grup', 'Sesuai', 'Instruksi', 'Gubernur', 'Jawa', 'Tengah', 'Hasil', 'Rapat', 'Tim', 'Gugus', 'Tugas', 'Covid', '19', 'Jateng', 'sbb:']
foto jim rohn jokowi adalah presiden baik dlm sejarah bangsa indonesia jokowi adalah presiden baik dlm sejarah bangsa indonesia jim rohn motivator baik dunia
['Foto', 'Jim', 'Rohn:', 'Jokowi', 'adalah', 'presiden', 'terbaik', 'dlm', 'sejarah', 'bangsa', 'IndonesiaJokowi', 'adalah', 'presiden', 'terbaik', 'dlm', 'sejarah', 'bangsa', 'Indonesia.', 'Jim', 'Rohn,', 'motivator', 'terbaik', 'dunia']
ini bukan politik tapi nyata pak jokowi hasil pulang 11 000 triliun uang negara dari swiss maaf mas2 dan mbak2 ini bukan politik tapi nyata pak jokowi hasil pulang 11 000 triliun uang negara dari swiss 11ribu triliun siap di bawa balik ke indonesia ruu treaty on mutual legal assistance in criminal matters between the republic of indonesia and the swiss confederation mla ri-swiss resmi sah dpr ri tanggal 3 juli 2020 dengan demikian proses konstitusi tarik dana di swiss sudah selesai juang yang panjang hadap ex koruptor yang bersenggama dengan agama terimakasih para kadrun yang terus nyinyirian kapan uang 11 000 triliun kembali ke indonesia tanpa anda
['ini', 'bukan', 'politik,', 'tapi', 'kenyataan', 'Pak', 'Jokowi', 'berhasil', 'memulangkan', '11,000', 'Triliun', 'uang', 'negara', 'dari', 'Swiss.Maaf', 'Mas2', 'dan', 'Mbak2,', 'ini', 'bukan', 'politik,', 'tapi', 'kenyataan', 'Pak', 'Jokowi', 'berhasil', 'memulangkan', '11,000', 'Triliun', 'uang', 'negara', 'dari', 'Swiss.', '11ribu', 'Triliun', 'siap', 'di', 'bawa', 'balik', 'ke', 'Indonesia.RUU', 'Treaty', 'on', 'Mutual', 'Legal', 'Assistance', 'in', 'Criminal', 'Matters', 'between', 'the', 'Republic', 'of', 'Indonesia', 'and', 'The', 'Swiss', 'Confederation', '(MLA', 'RI-Swiss)', 'resmi', 'disahkan', 'DPR', 'RI', 'tanggal', '3', 'juli', '2020.', 'Dengan', 'demikian', 'proses', 'konstitusi', 'menarik', 'dana',
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

78
nyinyir rasa sulit ruu itu bisa sah oleh dpr milik 84 rekening gendut siap siap gigit jari mungkin tekan ke pak jokowi makin kencang ini baca berita
'di', 'Swiss', 'sudah', 'selesai.', 'Perjuangan', 'yang', 'panjang', 'menghadapi', 'ex', 'koruptor', 'yang', 'bersenggama', 'dengan', 'agama.', 'Terimakasih', 'para', 'kadrun', 'yang', 'terus', 'nyinyirian', 'kapan', 'uang', '11.000', 'triliun', 'kembali', 'ke', 'Indonesia.', 'Tanpa', 'anda', 'nyinyir,', 'rasanya', 'sulit', 'RUU', 'itu', 'bisa', 'disahkan', 'oleh', 'DPR.', 'Pemilik', '84', 'rekening', 'gendut', 'siap', 'siap', 'gigit', 'jari', '.', 'Mungkin', 'tekanan', 'ke', 'Pak', 'Jokowi', 'makin', 'kencang.', 'ini', 'baca', 'beritanya']
4.2.4. Stopwords Removal
Setelah melakukan proses tokenization dilakukan proses
stopwords removal yaitu menghilangkan kata – kata umum yang
sering digunakan dalam sebuah teks dan biasanya tidak berguna jika
digunakan untuk tujuan pencarian.
stopword = pd.read_csv('data/stopwords.csv',
encoding='latin')
listStopwords = set(list(stopword.Stopwords))
shortlisted_words = []
# remove stop words
for w in words:
if w not in listStopwords:
shortlisted_words.append(w)
print('Stopword: ', shortlisted_words)
Pada proses di python untuk melakukan proses stopword
removal yaitu dengan cara membaca file stopword.csv. Selanjutnya
yaitu melakukan membuat list untuk dijadikan stopword. Lalu
dilakukan perulangan sebanyak panjang dari satu dokumen, jika
kata dalam dokumen tidak sama dengan stopword maka kata
tersebut disimpan jika sama maka kata tersebut tidak disimpan.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

79
Sebagai contoh dapat dilihat pada tabel 4.5 untuk proses stopword
removal.
Tabel 4. 5 Stopwords Removal
Sebelum Stopword Setelah Stopword ['Pemakaian', 'Masker', 'Menyebabkan', 'Penyakit', 'LegionnairesA', 'caller', 'to', 'a', 'radio', 'talk', 'show', 'recently', 'shared', 'that', 'his', 'wife', 'was', 'hospitalized', 'n', 'told', 'she', 'had', 'COVID', 'n', 'only', 'a', 'couple', 'of', 'days', 'left', 'to', 'live', '.', 'A', 'doctor', 'friend', 'suggested', 'she', 'be', 'tested', 'for', 'legionnaires', 'disease', 'because', 'she', 'wore', 'the', 'same', 'mask', 'every', 'day', 'all', 'day', 'long', '.', 'Turns', 'out', 'it', 'WAS', 'legionnaires', 'disease', 'from', 'the', 'moisture', 'n', 'bacteria', 'in', 'her', 'mask', '.', 'She', 'was', 'given', 'antibiotics', 'n', 'within', 'two', 'days', 'was', 'better', '.', 'WHAT', 'IF', 'these', '\x91spikes\x92', 'in', 'COVID', 'are', 'really', 'something', 'else', 'due', 'to', '\x91mask', 'induced', 'infections\x92', '.????????']
['pakai', 'masker', 'sakit', 'covid',]
['Instruksi', 'Gubernur', 'Jateng', 'tentang', 'penilangan', '', 'bagi', 'yg', 'tidak', 'bermasker', 'di', 'muka', 'umum', 'Rp.150.000', 'menggunakan', 'e-tilang', 'Via', 'apps', 'PIKOBARYth.Seluruh', 'Anggota', 'Grup', 'Sesuai', 'Instruksi', 'Gubernur', 'Jawa', 'Tengah', 'Hasil', 'Rapat', 'Tim', 'Gugus', 'Tugas', 'Covid', '19', 'Jateng', 'sbb:']
['instruksi', 'gubernur', 'jateng', 'tilang', 'masker', 'muka', '150', '000', 'tilang', 'anggota', 'grup', 'instruksi', 'gubernur', 'jawa', 'rapat', 'tim', 'tugas', 'covid', '19', 'jateng']
['Foto', 'Jim', 'Rohn:', 'Jokowi', 'adalah', 'presiden', 'terbaik', 'dlm', 'sejarah', 'bangsa', 'IndonesiaJokowi', 'adalah', 'presiden', 'terbaik', 'dlm', 'sejarah', 'bangsa', 'Indonesia.', 'Jim', 'Rohn,', 'motivator', 'terbaik', 'dunia']
['foto', 'jokowi', 'presiden', 'sejarah', 'bangsa', 'indonesia', 'jokowi', 'presiden', 'sejarah', 'bangsa', 'indonesia', 'dunia']
['ini', 'bukan', 'politik,', 'tapi', 'kenyataan', 'Pak', 'Jokowi', 'berhasil', 'memulangkan', '11,000', 'Triliun', 'uang', 'negara', 'dari', 'Swiss.Maaf', 'Mas2', 'dan', 'Mbak2,', 'ini', 'bukan',
['politik', 'nyata', 'jokowi', 'pulang', '11', '000', 'triliun', 'uang', 'negara', 'politik', 'nyata', 'jokowi', 'pulang', '11', '000', 'triliun', 'uang', 'negara', 'triliun', 'bawa', 'indonesia', 'indonesia', 'resmi', 'dpr',
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

80
'politik,', 'tapi', 'kenyataan', 'Pak', 'Jokowi', 'berhasil', 'memulangkan', '11,000', 'Triliun', 'uang', 'negara', 'dari', 'Swiss.', '11ribu', 'Triliun', 'siap', 'di', 'bawa', 'balik', 'ke', 'Indonesia.RUU', 'Treaty', 'on', 'Mutual', 'Legal', 'Assistance', 'in', 'Criminal', 'Matters', 'between', 'the', 'Republic', 'of', 'Indonesia', 'and', 'The', 'Swiss', 'Confederation', '(MLA', 'RI-Swiss)', 'resmi', 'disahkan', 'DPR', 'RI', 'tanggal', '3', 'juli', '2020.', 'Dengan', 'demikian', 'proses', 'konstitusi', 'menarik', 'dana', 'di', 'Swiss', 'sudah', 'selesai.', 'Perjuangan', 'yang', 'panjang', 'menghadapi', 'ex', 'koruptor', 'yang', 'bersenggama', 'dengan', 'agama.', 'Terimakasih', 'para', 'kadrun', 'yang', 'terus', 'nyinyirian', 'kapan', 'uang', '11.000', 'triliun', 'kembali', 'ke', 'Indonesia.', 'Tanpa', 'anda', 'nyinyir,', 'rasanya', 'sulit', 'RUU', 'itu', 'bisa', 'disahkan', 'oleh', 'DPR.', 'Pemilik', '84', 'rekening', 'gendut', 'siap', 'siap', 'gigit', 'jari', '.', 'Mungkin', 'tekanan', 'ke', 'Pak', 'Jokowi', 'makin', 'kencang.', 'ini', 'baca', 'beritanya']
'juli', 'tarik', 'dana', 'selesai', 'juang', 'hadap', 'koruptor', 'agama', 'uang', 'triliun', 'indonesia', 'sulit', 'dpr', 'rekening', 'jari', 'tekan', 'jokowi', 'baca', 'berita']
4.2.5. Punctuation Removal
Setelah dilakukan proses penghilangan kata dengan
stopword maka tahapan selanjutnya yaitu menghilangkan tanda
baca, angka, dan symbol pada dokumen
def punctuation_removal(text):
text = re.sub(r'([' + ''.
join(map(re.escape,
character))
+ r'])(?=\S)', r'\1 ', text)
text = re.sub(r'(\S)([' + ''.
join(map(re.escape,
character))
+ r'])', r'\1 \2', text)
# remove html markup
text = re.sub(r"\s—\s", "", text)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

81
text = re.sub(r"http\S+", "", text)
text = re.sub("(<.*?>)", "", text)
# remove non-ascii and digits
text = re.sub("(\\W|\\d)", " ", text)
# remove whitespace
text = text.strip()
return text
# Punctuation Removal
cleaned_words = [punctuation_removal(w) for w
in shortlisted_words]
print('Punctuation: ', cleaned_words)
Pada proses di python untuk melakukan proses punctuation
removal ini, yaitu mengimport library re, lalu mendefinisikan untuk
menghilangkan tanda baca, markup html dan angka, serta
mnghilangkan nilai kosong. Sehingga pada tabel 4.6 merupakan
hasil dari punctuation removal.
Tabel 4. 6 Punctuation Removal
Sebelum Punctuation Removal Setelah Punctuation Removal ['pakai', 'masker', 'sakit', 'covid',] ['pakai', 'masker', 'sakit', 'covid',]
['instruksi', 'gubernur', 'jateng', 'tilang',
'masker', 'muka', '150', '000', 'tilang',
'anggota', 'grup', 'instruksi', 'gubernur',
'jawa', 'rapat', 'tim', 'tugas', 'covid', '19',
'jateng']
['instruksi', 'gubernur', 'jateng', 'tilang',
'masker', 'muka', 'tilang', 'anggota',
'grup', 'instruksi', 'gubernur', 'jawa',
'rapat', 'tim', 'tugas', 'covid', 'jateng']
['foto', 'jokowi', 'presiden', 'sejarah',
'bangsa', 'indonesia', 'jokowi',
'presiden', 'sejarah', 'bangsa',
'indonesia', 'dunia']
['foto', 'jokowi', 'presiden', 'sejarah',
'bangsa', 'indonesia', 'jokowi',
'presiden', 'sejarah', 'bangsa',
'indonesia', 'dunia']
['politik', 'nyata', 'jokowi', 'pulang', '11',
'000', 'triliun', 'uang', 'negara', 'politik',
'nyata', 'jokowi', 'pulang', '11', '000',
'triliun', 'uang', 'negara', 'triliun', 'bawa',
'indonesia', 'indonesia', 'resmi', 'dpr',
'juli', 'tarik', 'dana', 'selesai', 'juang',
'hadap', 'koruptor', 'agama', 'uang',
['politik', 'nyata', 'jokowi', 'pulang',
'triliun', 'uang', 'negara', 'politik',
'nyata', 'jokowi', 'pulang', 'triliun',
'uang', 'negara', 'triliun', 'bawa',
'indonesia', 'indonesia', 'resmi', 'dpr',
'juli', 'tarik', 'dana', 'selesai', 'juang',
'hadap', 'koruptor', 'agama', 'uang',
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

82
'triliun', 'indonesia', 'sulit', 'dpr',
'rekening', 'jari', 'tekan', 'jokowi', 'baca',
'berita']
'triliun', 'indonesia', 'sulit', 'dpr',
'rekening', 'jari', 'tekan', 'jokowi', 'baca',
'berita']
4.3. Implementasi Pembagian Data
Setelah melakukan preprocessing dilakukan pembagian data dengan
membagi menjadi 2 data, yaitu data training dan data testing. Dalam proses
pembagian data tersebut dalam data training dan testing dilakukan
pembagian data dengan perbandingan 70:30 atau 70% merupakan data
training dan 30% data testing. Dalam proses pembagian tersebut dilakukan
proses pengacakan data agar mendapatkan data yang bervariasi.
sentences_train, sentences_test, y_train, y_test = \
train_test_split(df.narasi, df.label,
test_size=0.3, random_state=100)
Parameter yang digunakan dalam proses pembagian data adalah:
test_size : 0.3
random_state : 100
Keterangan:
test_size : Perbandingan pembagian data training dan data
testing
random_state : Banyaknya penacakan data yang dilakukan
.�)� kA�����, � 70100 7 4231 � 2961 .�)� kB@)��, � 30
100 7 4231 � 1270
Data Training : 2961
Data Testing : 1270 +
Total : 4231
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

83
4.4. Implementasi Feature Extraction
4.4.1. TF - IDF
Setelah melakukan proses pembagian data, yaitu data training
dan data testing tahapan selanjutnya adalah teks perlu dikonversi
menjadi angka sebelum diinput dalam proses klasifikasi
Convolution Neural Network. Keras menyediakan class Tokenizer,
yang berfungsi untuk mengkonversi teks menjadi vektor. Teks yang
digunakan dalam membuat list urutan adalah data training. Sebagai
contoh salah satu data yang dibuat data list urutan dalam data
training:
Tabel 4. 7 Tokenizer
Teks Tokenizer
'bahaya', 'laku', 'panggil',
'panggil', 'suami', 'dokter',
'sedih', 'bawa', 'rumah',
'sakit', 'bakar', 'panggil', 'gas'
{1: 'panggil', 2: 'bahaya', 3:
'laku', 4: 'suami', 5: 'dokter', 6:
'sedih', 7: 'bawa', 8: 'rumah', 9:
'sakit', 10: 'bakar', 11: 'gas'}
Setelah terbentuk sebuah list urutan tersebut, maka tahapan
selanjutnya adalah mengubah teks tersebut menjadi list sequence
berdasarkan list index kata unik yang telah dibentuk untuk data
training maupun data testing.
Tabel 4. 8 List Sequence
Teks List Sequence
'bahaya', 'laku', 'panggil',
'panggil', 'suami', 'dokter',
'sedih', 'bawa', 'rumah',
'sakit', 'bakar', 'panggil', 'gas'
[[2], [3], [1], [1], [4], [5], [6],
[7], [8], [9], [10], [1], [11]]
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

84
Setelah list Sequence tersebut maka dilakukan menghitung
kemunculan angka pada teks tersebut dengan term frequency
Tabel 4. 9 Term Frequency
Term Frequency
panggil bahaya laku suami dokter sedih bawa rumah sakit bakar gas
3 1 1 1 1 1 1 1 1 1 1
Hasil dari Term Frequency tersebut, dilakukan perhitungan
dengan menghitung Invers Document Frequency menjadi:
Tabel 4. 10 IDF
Invers Document Frequency 1.44692
2.0149
2.0149
2.0149
2.0149
2.0149
2.0149
2.0149
2.0149
2.0149
2.0149
Selanjtunya adalah menghitung bobot dari TF-IDF tersebut:
Tabel 4. 11 Tabel Weight TF - IDF
Weight TF – IDF 4.34076
2.0149
2.0149
2.0149
2.0149
2.0149
2.0149
2.0149
2.0149
2.0149
2.0149
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences_train)
seq_train = tokenizer.texts_to_sequences(sentences_train)
seq_test = tokenizer.texts_to_sequences(sentences_test)
encoded_tfidf_train =
tokenizer.sequences_to_matrix(seq_train, mode="tfidf")
encoded_tfidf_test =
tokenizer.sequences_to_matrix(seq_test, mode="tfidf")
X_train = pad_sequences(encoded_tfidf_train,
dtype='float64', padding="post", truncating="post")
X_test = pad_sequences(encoded_tfidf_test,
dtype='float64', padding="post", truncating="post")
Sedangkan parameter yang digunakan dalam proses TF - IDF
yaitu:
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

85
mode : Metode yang akan digunakan untuk proses
feature extraction adalah “tfidf”.
Maka matriks tersebut sudah bisa untuk dilakukan proses
klasifikasi.
Tabel 4. 12 Feature Extraction
Sentences Feature Extraction
(0, ['pakai', 'masker', 'sakit',
'covid', 'covid']) (1, ['instruksi',
'gubernur', 'jateng', 'tilang',
'masker', 'muka', 'tilang',
'anggota', 'grup', 'instruksi',
'gubernur', 'jawa', 'rapat', 'tim',
'tugas', 'covid', 'jateng']) (2,
['foto', 'jokowi', 'presi …
[[0. 0. 0. ... 0. 0. 0.],
[0. 0. 0. ... 0. 0. 0.],
[0. 0. 0. ... 0. 0. 0.], ...,
[0. 4,8434. 0. ... 0. 0. 0.],
[0. 0. 0. ... 0. 0. 0.],
[0. 0. 0. ... 0. 0. 0.]]
4.5. Implementasi Convolution Neural Network
Setelah data training dan data testing telah dilakukan proses
ekstraksi ciri sehingga data tersebut berubah menjadi matriks, tahapan
selanjutnya yaitu melakukan proses klasifikasi dengan menggunakan
metode Convolution Neural Network. Data yang akan digunakan dalam
proses klasifikasi ini adalah data training. Dalam proses klasifikasi ini
terdapat 5 Layer utama yang akan diterapkan. Layer pertama yaitu
embedding layer, yang memetakan indeks kata kosakata dalam representasi
matriks vektor yang dilakukan proses pre-trained dengan menggunakan
word2vec sehingga mendapatkan hasil matriks vector yang baik. Dengan
parameter yang akan digunakan:
vocab_size : Ukuran dari kosakata. Ini diperlukan untuk
mendefinisikan ukuran dari embedding
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

86
layer, yang akan memiliki bentuk
[vocabulary_size, embedding_size]
embedding_size : Dimensi dari embeddings
Weights : Bobot
input_length : Panjang input sequence
Layer kedua adalah Conv1D, yaitu layer yang membuat kernel
konvolusi yang digabungkan dengan masukan lapisan melalui dimensi
spasial tunggal berdasarkan ukuran filter. Dengan parameter yang
digunakan:
filters : Ukuran dimensi kata untuk proses konvulasi
kernel_size : Banyaknya jendela konvolusi 1D.
activation : Fungsi Aktivasi
Gambar 4. 1 Embedding Layer to Conv1D Layer
Layer ketiga adalah MaxPooling1D, yaitu lapisan yang mengurangi
dimensi dari feature map atau lebih dikenal dengan langkah untuk
downsampling dengan mengambil nilai max dengan filter � 7 � dari setiap
feature map, sehingga mempercepat komputasi dan mengatasi overfitting.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

87
Gambar 4. 2 Conv1D Layer to Max Pooling Layer
Layer keempat adalah Flatten, yaitu reshape feature map dari
matriks vektor menjadi sebuah vektor 1 7 �, penggunaan Flatten ini agar
bisa gunakan sebagai input dari fully connected layer.
Gambar 4. 3 MaxPooling Layer to Flatten Layer
Layer kelima adalah Fully Connected, yaitu lapisan hidden layer
yang akan diterapkan dengan menggunakan Dense. Tujuan penggunaan
hidden layer ini untuk melakukan transformasi pada dimensi data agar data
dapat diklasifikasikan secara linier. Dengan parameter yang digunakan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

88
units : Jumlah neuron
activation : Fungsi aktivasi
Gambar 4. 4 Flatten Layer to Dense Layer
EMBEDDING_DIM = 1000
vocab_size = len(tokenizer.word_index) + 1
model = Sequential()
model.add(layers.Embedding(vocab_size, 100,
input_length=vocab_size))
model.add(layers.Conv1D(16, 5, activation="relu"))
model.add(layers.MaxPooling1D())
model.add(layers.Conv1D(32, 5, activation="relu"))
model.add(layers.MaxPooling1D())
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(8, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
history = model.fit(X_train, y_train,
epochs=5,
validation_data=(X_test, y_test))
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

89
Setelah membangun model Convolution Neural Network, saatnya
melakukan kompilasi. Dengan parameter yang digunakan:
optimizer : optimisasi dengan algoritma Adam
loss : menghitung kuantitas yang harus diminimalkan
binary_crossentropy
metrics : Daftar metrics yang akan dievaluasi oleh model
selama pelatihan dan pengujian menggunakan
accuracy.
Selanjutnya melakukan pelatihan model atau fitting model, dengan
parameter yang digunakan:
epochs : Jumlah iterasi dalam melakukan pelatihan
model menggunakan 5 iterasi
validation_data : Data untuk mengevaluasi loss dan metrics
model di akhir setiap epoch menggunakan
data uji
Sehingga hasil dari pelatihan model tersebut akan mendapatkan
catatan nilai loss pelatihan dan nilai metrics pada periode yang berurutan,
serta nilai loss validasi dan nilai metrics validasi dan dari catatan tersebut
dapat diperoleh hasil akurasinya. Selanjutnya yaitu melakukan proses
prediksi dengan menggunakan data testing untuk mengetahui hasil output
dari model yang telah dibuat.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

90
Gambar 4. 5 Kompilasi Model Covolution Neural Network
Setelah proses prediksi dibuat maka akan mendapatkan nilai
probabilitas dalam range 0 - 1. Nilai probabilitas tersebut harus diubah
menjadi 1 atau 0 dengan ketentuan jika:
e > 0.5 � 1 e ≤ 0.5 � 0
Keterangan:
P : Nilai Probabilitas
Nilai yang bernilai 1 dapat didefinisikan sebagai berita palsu,
sedangkan nilai yang bernilai 0 didefinisikan sebagai berita asli.
4.6. Implementasi Pengukuran Performa
Hasil prediksi yang sudah didapatkan sebelumnya, akan dilakukan
perhitungan pengukuran performa dengan menggunakan confusion matrix.
Pada penggunaan confusion matrix ini, label dari data testing akan
dilakukan proses perbandingan dengan hasil prediksi. Dengan cara
membandingkan nilai aktual dengan nilai prediksi. Ada empat istilah yang
merupakan representasi hasil proses klasifikasi pada confusion matrix yaitu
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

91
True Positif, True Negatif, False Positif, dan False Negatif dapat dilihat
pada tabel 4.13.
Tabel 4. 13 Tabel Prediksi
Nomor Dokumen Label Aktual Label Prediksi
4163
730
3085
2288
1762
…
515
1
1
1
0
1
…
1
0
1
1
0
1
…
0
Dari hasil prediksi tersebut, perbandingan dengan label aktual atau
label asli tersebut yaitu (Gambar 4.6):
Label Prediksi dan Label Aktual bernilai asli
dan memang asli
: 67
Label Prediksi dan Label Aktual bernilai asli,
namun bernilai palsu
: 147
Label Prediksi dan Label Aktual bernilai palsu,
namun bernilai asli
: 81
Label Prediksi dan Label Aktual bernilai palus
dan memang palsu
: 975
y_pred = model.predict(X_test)
y_pred[y_pred > 0.5] = 1
y_pred[y_pred <= 0.5] = 0
cf_matrix = confusion_matrix(y_test, y_pred)
print(confusion_matrix(y_test, y_pred, labels=[1, 0]))
Pada proses di python untuk melakukan pembuatan confusion matrix,
yaitu dengan memprediksi data uji dengan model yang telah dibuat.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

92
Selanjutnya mengubah nilai, jika hasil dari prediksi diatas 0.5 maka akan
diganti dengan 1 dan jika hasil dari prediksi dibawah sama dengan 0.5 maka
akan diganti dengan 0. Sehingga dengan menggunakan library
confusion_matrix dengan isi label asli dari data uji dan label hasil dari model
akan dibandingkan dan mendapatkan confusion matrix pada gambar 4.6.
Gambar 4. 6 Confusion Matrix
4.7. Hasil Penelitian
Dalam hasil penelitian ini lakukan proses percobaan dengan
melakukan perubahan pada banyaknya layer Conv1D dan Dense yang
digunakan. Sedangkan untuk pembagian data latih dan data uji adalah
70:30.
4.7.1. Skenario Pertama
Pada skenario pertama ini, struktur model yang dibuat:
Tabel 4. 14 Struktur Model Skenario Pertama
Layer (type) Output Shape Parameters
embedding (Embedding) 1026, 100 102600
conv1d (Conv1D) 1022, 32 16032
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

93
conv1d (Conv1D) 1018, 64 10304
max_pooling1d (MaxPooling1D) 509, 64 0
flatten (Flatten) 32576
dense (Dense) 256 8339712
dense_1 (Dense) 128 32896
dropout (Dropout) 128 0
dense_2 (Dense) 64 8256
dense_3 (Dense) 32 2080
dense_4 (Dense) 10 330
dense_5 (Dense) 1 11
Setelah membuat model tersebut dilakukan proses
kompilasi dengan parameter optimisasi ‘adam’, loss
‘binary_crossentropy’, dan metrics ‘accuracy’. Selanjutnya
melakukan percobaan sebanyak 3 kali dengan iterasi yang sama
yaitu 5 iterasi atau 5 epoch.
Hasil Akurasi:
Tabel 4. 15 Akurasi Percobaan Pertama
Percobaan Akurasi
Training Testing
Percobaan 1 0.9095 0.8465
Percobaan 2 0.9044 0.8528
Percobaan 3 0.9041 0.8512
Rata – rata 0.9060 0.8502
Hasil rata – rata dari percobaan 1, percobaan 2 dan
percobaan 3 adalah 0.8502
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

94
Gambar 4. 7 Akurasi dan Confusion Matrix Percobaan 1
Gambar 4. 8 Akurasi dan Confusion Matrix Percobaan 2
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
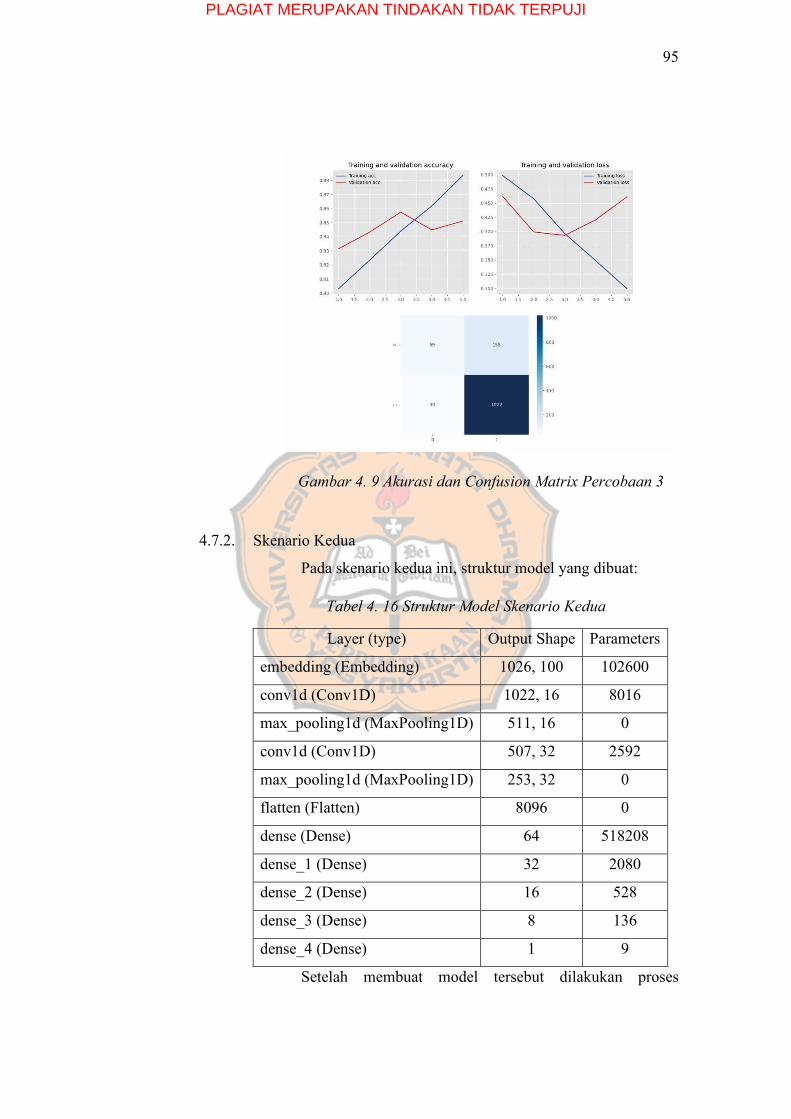
95
Gambar 4. 9 Akurasi dan Confusion Matrix Percobaan 3
4.7.2. Skenario Kedua
Pada skenario kedua ini, struktur model yang dibuat:
Tabel 4. 16 Struktur Model Skenario Kedua
Layer (type) Output Shape Parameters
embedding (Embedding) 1026, 100 102600
conv1d (Conv1D) 1022, 16 8016
max_pooling1d (MaxPooling1D) 511, 16 0
conv1d (Conv1D) 507, 32 2592
max_pooling1d (MaxPooling1D) 253, 32 0
flatten (Flatten) 8096 0
dense (Dense) 64 518208
dense_1 (Dense) 32 2080
dense_2 (Dense) 16 528
dense_3 (Dense) 8 136
dense_4 (Dense) 1 9
Setelah membuat model tersebut dilakukan proses
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

96
kompilasi dengan parameter optimisasi ‘adam’, loss
‘binary_crossentropy’, dan metrics ‘accuracy’. Selanjutnya
melakukan percobaan sebanyak 3 kali dengan iterasi yang sama
yaitu 5 iterasi atau 5 epoch.
Hasil Akurasi:
Tabel 4. 17 Akurasi Percobaan Kedua
Percobaan Akurasi
Training Testing
Percobaan 1 0.8632 0.8520
Percobaan 2 0.8548 0.8504
Percobaan 3 0.8646 0.8496
Rata – rata 0.8609 0.8507
Hasil rata – rata dari percobaan 1, percobaan 2 dan
percobaan 3 adalah 0.8507
Gambar 4. 10 Akurasi dan Confusion Matrix Percobaan 1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

97
Gambar 4. 11 Akurasi dan Confusion Matrix Percobaan 2
Gambar 4. 12 Akurasi dan Confusion Matrix Percobaan 3
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

98
4.7.3. Skenario Ketiga
Pada skenario ketiga ini, struktur model yang dibuat:
Tabel 4. 18 Struktur Model Skenario Ketiga
Layer (type) Output Shape Parameters
embedding (Embedding) 1026, 100 102600
conv1d (Conv1D) 1022, 32 16032
max_pooling1d (MaxPooling1D) 511, 32 0
flatten (Flatten) 16352 0
dense (Dense) 10 163530
dense_1 (Dense) 1 11
Setelah membuat model tersebut dilakukan proses
kompilasi dengan parameter optimisasi ‘adam’, loss
‘binary_crossentropy’, dan metrics ‘accuracy’. Selanjutnya
melakukan percobaan sebanyak 3 kali dengan iterasi yang sama
yaitu 5 iterasi atau 5 epoch.
Hasil Akurasi:
Tabel 4. 19 Akurasi Percobaan Ketiga
Percobaan Akurasi
Training Testing
Percobaan 1 0.8970 0.8433
Percobaan 2 0.8977 0.8433
Percobaan 3 0.8845 0.8472
Rata – rata 0.8931 0.8446
Hasil rata – rata dari percobaan 1, percobaan 2 dan
percobaan 3 adalah 0.8446
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

99
Gambar 4. 13 Akurasi dan Confusion Matrix Percobaan 1
Gambar 4. 14 Akurasi dan Confusion Matrix Percobaan 2
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

100
Gambar 4. 15 Akurasi dan Confusion Matrix Percobaan 3
4.7.4. Skenario Keempat
Pada skenario keempat ini, struktur model yang dibuat:
Tabel 4. 20 Struktur Model Skenario Keempat
Layer (type) Output Shape Parameters
embedding (Embedding) 1026, 100 102600
conv1d (Conv1D) 1022, 64 32064
max_pooling1d (MaxPooling1D) 511, 64 0
flatten (Flatten) 32704 0
dense (Dense) 20 654100
dense_1 (Dense) 1 21
Setelah membuat model tersebut dilakukan proses
kompilasi dengan parameter optimisasi ‘adam’, loss
‘binary_crossentropy’, dan metrics ‘accuracy’. Selanjutnya
melakukan percobaan sebanyak 3 kali dengan iterasi yang sama
yaitu 5 iterasi atau 5 epoch.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

101
Hasil Akurasi:
Tabel 4. 21 Akurasi Percobaan Keempat
Percobaan Akurasi
Training Testing
Percobaan 1 0.8609 0.8551
Percobaan 2 0.9112 0.8370
Percobaan 3 0.9142 0.8283
Rata – rata 0.8954 0.8401
Hasil rata – rata dari percobaan 1, percobaan 2 dan
percobaan 3 adalah 0.8401
Gambar 4. 16 Akurasi dan Confusion Matrix Percobaan 1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

102
Gambar 4. 17 Akurasi dan Confusion Matrix Percobaan 2
Gambar 4. 18 Akurasi dan Confusion Matrix Percobaan 3
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

103
4.7.5. Skenario Kelima
Pada skenario kelima ini, struktur model yang dibuat:
Tabel 4. 22 Struktur Model Skenario Kelima
Layer (type) Output Shape Parameters
embedding (Embedding) 1026, 100 102600
conv1d (Conv1D) 1022, 32 16032
max_pooling1d (MaxPooling1D) 511, 32 0
flatten (Flatten) 16352 0
dense (Dense) 20 327060
dense_1 (Dense) 15 315
dense_2 (Dense) 1 16
Setelah membuat model tersebut dilakukan proses
kompilasi dengan parameter optimisasi ‘adam’, loss
‘binary_crossentropy’, dan metrics ‘accuracy’. Selanjutnya
melakukan percobaan sebanyak 3 kali dengan iterasi yang sama
yaitu 5 iterasi atau 5 epoch.
Hasil Akurasi:
Tabel 4. 23 Akurasi Percobaan Kelima
Percobaan Akurasi
Training Testing
Percobaan 1 0.9078 0.8465
Percobaan 2 0.8715 0.8455
Percobaan 3 0.8902 0.8433
Rata – rata 0.8898 0.8451
Hasil rata – rata dari percobaan 1, percobaan 2 dan
percobaan 3 adalah 0.8451
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

104
Gambar 4. 19 Akurasi dan Confusion Matrix Percobaan 1
Gambar 4. 20 Akurasi dan Confusion Matrix Percobaan 2
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
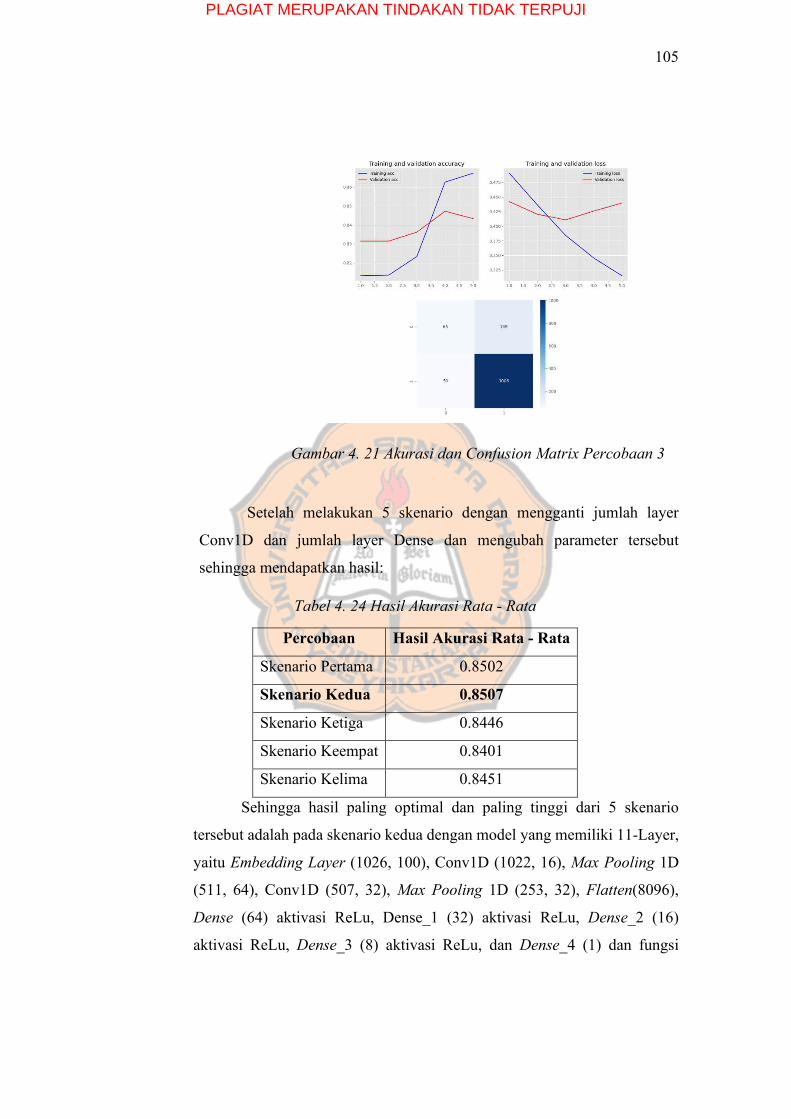
105
Gambar 4. 21 Akurasi dan Confusion Matrix Percobaan 3
Setelah melakukan 5 skenario dengan mengganti jumlah layer
Conv1D dan jumlah layer Dense dan mengubah parameter tersebut
sehingga mendapatkan hasil:
Tabel 4. 24 Hasil Akurasi Rata - Rata
Percobaan Hasil Akurasi Rata - Rata
Skenario Pertama 0.8502
Skenario Kedua 0.8507
Skenario Ketiga 0.8446
Skenario Keempat 0.8401
Skenario Kelima 0.8451
Sehingga hasil paling optimal dan paling tinggi dari 5 skenario
tersebut adalah pada skenario kedua dengan model yang memiliki 11-Layer,
yaitu Embedding Layer (1026, 100), Conv1D (1022, 16), Max Pooling 1D
(511, 64), Conv1D (507, 32), Max Pooling 1D (253, 32), Flatten(8096),
Dense (64) aktivasi ReLu, Dense_1 (32) aktivasi ReLu, Dense_2 (16)
aktivasi ReLu, Dense_3 (8) aktivasi ReLu, dan Dense_4 (1) dan fungsi
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

106
aktivasi Sigmoid. Dengan struktur model tersebut hasil penelitian ini
mendapatkan hasil yang optimal dengan akurasi rata – rata sebesar 0.8507
4.8. Implementasi GUI
Pada proses pelatihan model dengan menggunakan metode
Convolution Neural Network ini sudah mendapatkan hasil akurasi yang
cukup optimal. Model tersebut dapat digunakan untuk proses prediksi berita
baru. Proses untuk melakukan prediksi berita tersebut yaitu dengan
menginputkan judul dari berita dan isi dari narasi tersebut pada masing –
masing text field.
Gambar 4. 22 Tampilan Awal GUI
Sebagai contoh berita yang akan di input adalah sebagai berikut:
a. Judul: Makan Bawang Mentah dan Garam bisa Ubah Positif
Covid-19 Menjadi Negatif setelah 15 Menit
b. Narasi:
” Setelah 15 menit makan bawang mentah kupas dengan garam
batu, orang berubah menjadi negatif dari positif Mawar Bendera
Tajikistan Jempolan * Dengarkan audio, apa yang salah dengan
makan …*”
Selanjutnya masukkan pada masing – masing text field judul dan
narasi pada GUI
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

107
Gambar 4. 23 Pengisian Text Field Judul dan Narasi
Selanjutnya klik pada button CHECK untuk melakukan proses
prediksi berita baru tersebut. Setelah mengklik button CHECK maka isi dari
judul berita dan narasi berita tersebut dijadikan satu dan dilakukan proses
preprocessing terlebih dahulu untuk membuat text tersebut menjadi
terstruktur.
Tabel 4. 25 Preprocessing
Sebelum Preprocessing Setelah Preprocessing
Makan Bawang Mentah dan Garam
bisa Ubah Positif Covid-19
Menjadi Negatif setelah 15 Menit ”
Setelah 15 menit makan bawang
mentah kupas dengan garam batu,
orang berubah menjadi negatif dari
positif Mawar Bendera Tajikistan
Jempolan *
Dengarkan audio, apa yang salah
dengan makan …*”
'makan', 'bawang', 'mentah',
'garam', 'ubah', 'positif', 'covid',
'negatif', '', 'menit', '', 'menit',
'makan', 'bawang', 'mentah', 'kupas',
'garam', 'batu', 'orang', 'ubah',
'negatif', 'positif', 'mawar',
'bendera', 'tajikistan', 'jempol',
'dengar', 'audio', 'salah', 'makan'
Setelah data teks sudah terstruktur maka tahapan selanjutnya
dilakukan proses ektraksi ciri sehingga menjadi:
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
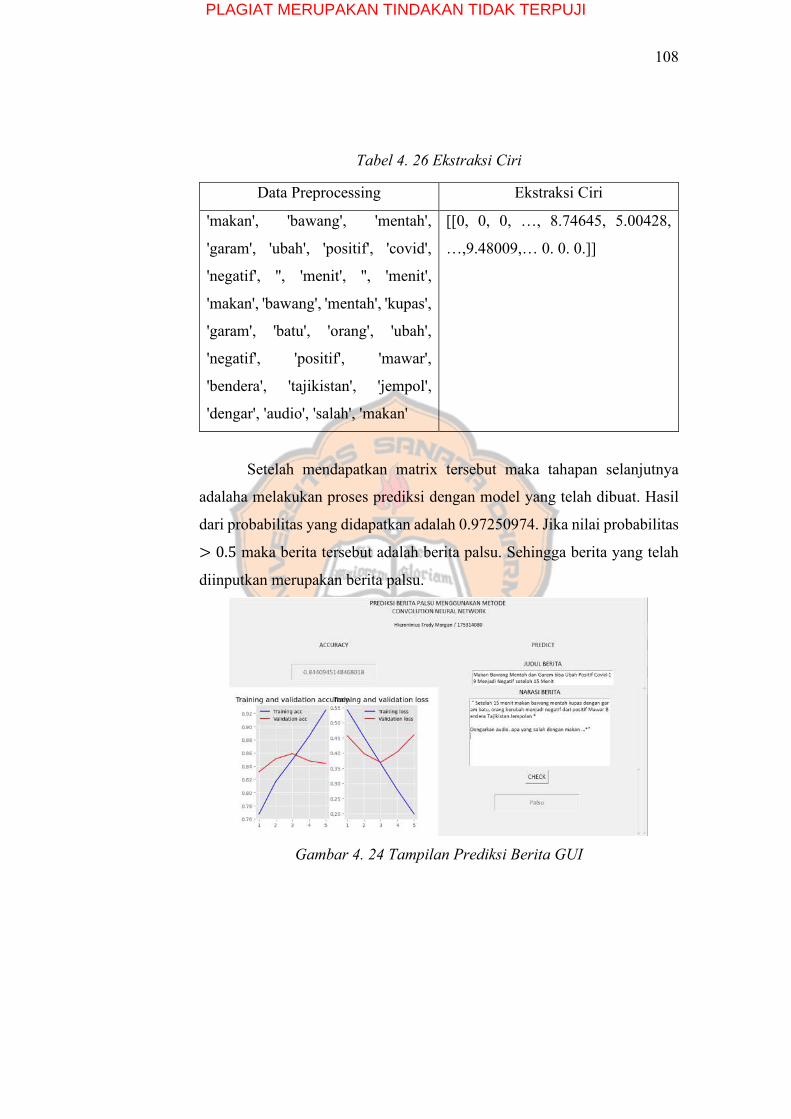
108
Tabel 4. 26 Ekstraksi Ciri
Data Preprocessing Ekstraksi Ciri
'makan', 'bawang', 'mentah',
'garam', 'ubah', 'positif', 'covid',
'negatif', '', 'menit', '', 'menit',
'makan', 'bawang', 'mentah', 'kupas',
'garam', 'batu', 'orang', 'ubah',
'negatif', 'positif', 'mawar',
'bendera', 'tajikistan', 'jempol',
'dengar', 'audio', 'salah', 'makan'
[[0, 0, 0, …, 8.74645, 5.00428,
…,9.48009,… 0. 0. 0.]]
Setelah mendapatkan matrix tersebut maka tahapan selanjutnya
adalaha melakukan proses prediksi dengan model yang telah dibuat. Hasil
dari probabilitas yang didapatkan adalah 0.97250974. Jika nilai probabilitas
> 0.5 maka berita tersebut adalah berita palsu. Sehingga berita yang telah
diinputkan merupakan berita palsu.
Gambar 4. 24 Tampilan Prediksi Berita GUI
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

109
BAB V
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Berdasarkan hasil penelitian, prediksi berita palsu menggunakan
metode Convolution Neural Network dengan data sebanyak 4.231 data
berita diperoleh kesimpulan sebagai berikut:
1. Nilai akurasi tertinggi mendapatkan hasil 0.8507 diperoleh pada
skenario kedua dengan layer yang digunakan Embedding Layer (1026,
100), Conv1D (1022, 16), Max Pooling 1D (511, 64), Conv1D (507,
32), Max Pooling 1D (253, 32), Flatten(8096), Dense (64) aktivasi
ReLu, Dense_1 (32) aktivasi ReLu, Dense_2 (16) aktivasi ReLu,
Dense_3 (8) aktivasi ReLu, dan Dense_4 (1) aktivasi Sigmoid.
2. Dari hasil ini dapat disimpulkan bahwa sistem mampu melakukan
prediksi dengan tingkat akurasi yang tinggi.
5.2. Saran
a. Diperlukan cara menyeimbangkan data berita palsu dan berita asli,
misalnya dengan pendekatan random undersampling, random
oversampling, atau SMOTE agar mendapatkan hasil akurasi yang lebih
optimal.
b. Pada proses preprocessing diperlukan normalisasi sehingga teks yang
dihasilkan lebih terstruktur.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

109
DAFTAR PUSTAKA
Agarmal, A., Mittal, M., Pathak, A., & Goyal, L. M. (2020). Fake News Detection
Using a Blend of Neural Networks: An Application of Deep Learning. SN
Computer Science, 143 -152.
Allcott, H., & Gentzkow, M. (2017). Social Media and Fake News in the 2016
Election. Journal of Economic Perspectives, Vol 31, No. 2.
Baeza-Yates, R., & Ribeiro-Neto, B. (1999). Modern information retrieval. ACM
Press / Addison Wesley.
Drs. Arifin S. Harahap, M. (2006). Jurnalistik Televisi: Teknik Memburu dan
Menulis Berita. Gramedia.
Knight, E. R. (1991). Artificial Intelligence: 2nd Edition. New Delhi: Tata
McGraw-Hill.
Kowalski, G. (1997). Information Retieval System: Theory and Implementation.
Kluwer Academic Publishers.
LeCun, Y. a. (2015). Deep learning. Nature Vol. 521 No. 7553, 436-444.
Manning, C. D., Raghavan, P., & Schutze, H. (2008). Introduction to information
retrieval. Cambridge University Press.
Pannu, A. &. (2015). Artificial Intelligence adn its Appication in Different Areas.
Internationnal Journal of Engineering and Innovative Technology (IJEIT),
Volume 4, ISSN: 2277 - 3754.
Priansya, S. (2017). Social Media Text Normalization Using Word2vec.
Levenshtein Distance, and Jaro-Winkler Distance. Institut Teknologi
Sepuluh Nopember Surabaya: Final Project - KS 141501.
Saadah, M. N. (2013). Sistem Temu Kembali Dokumen Teks dengan Pembobotan
Tf-Idf Dan LCS. Jurnal Ilmiah Teknologi Informasi (JUTI), 17–20.
Samuel, A. (1988). Some Studies in Machine Learning Using the Game of
Checkers. II—Recent Progress. Springer, 366–400.
Setiyono, M. Z. (2016). Convolution Neural Network untuk Pengenalan Wajah
Secara Real-Time. Jurnal Sains dan Seni ITS Vol. 5 No. 2, A-72 - A-77.
Silverman, C. (2017). Lies, Damn Lies, and Viral Content. Columbia : Tow
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

110
Center for Digital Journalism, Columbia University.
Yang Yang, L. Z. (2018). TI-CNN: Convolution Neural Network for Fake News
Detection. arXiv.org, -.
Zhai, C., & Massung, S. (2016). Text Data Management and Analysis.
Association fot Computing Machinery.
Zhang, Y. G. (2005). An improved TF-IDF approach for text classification.
Journal of Zhejiang University-SCIENCE A, 49–55.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

111
LAMPIRAN
DATA BERITA & STOPWORDS
Data Berita:
https://github.com/HieronimusMorgan/dataSkripsiMorgan/blob/8971f741d17379
89350c0acf7a92e97b1779fedc/data.csv
Data Berita (Cleaned):
https://github.com/HieronimusMorgan/dataSkripsiMorgan/blob/270f9b6098e7e54
91baa7f3db13fc78cb0c959d2/cleaned_fix.csv
Stopwords:
https://github.com/HieronimusMorgan/dataSkripsiMorgan/blob/8971f741d17379
89350c0acf7a92e97b1779fedc/stopwords.csv
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI