pengelompokan kode program c berdasarkan … · pengelompokan kode program c berdasarkan ... 1...
TRANSCRIPT

PENGELOMPOKAN KODE PROGRAM C BERDASARKAN
KEMIRIPAN STRUKTUR MENGGUNAKAN METODE
HIERARCHICAL AGGLOMERATIVE CLUSTERING
RUSMAN TRIATMOJO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2014


PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Pengelompokan Kode
Program C Berdasarkan Kemiripan Struktur Menggunakan Metode Hierarchical
Agglomerative Clustering adalah benar karya saya dengan arahan dari komisi
pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi
mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan
maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan
dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut
Pertanian Bogor.
Bogor, Agustus 2014
Rusman Triatmojo
NIM G64100090

ABSTRAK
RUSMAN TRIATMOJO. Pengelompokan Kode Program C Berdasarkan
Kemiripan Struktur Menggunakan Metode Hierarchical Agglomerative
Clustering. Dibimbing oleh AHMAD RIDHA.
Tujuan penelitian ini adalah mengimplementasikan algoritme hierarchical
agglomerative clustering untuk membantu pendeteksian penjiplakan pada kode
program C secara otomatis dan membandingkan hasil penelitian dengan penelitian
sebelumnya menggunakan metode iterasi K-means otomatis dan bisecting K-
means. Data yang digunakan dalam penelitian ini sebanyak 386 kode program C
yang terdiri atas 4 dataset. Metode yang digunakan Single Linkage, Complete
Linkage, dan Average Linkage. Hasil clustering yang dilakukan menunjukkan
eksekusi waktu metode Single Linkage sebesar 1.7220 detik dengan jumlah
cluster 14 dan RI sebesar 0.9706, eksekusi waktu metode Complete Linkage sebesar
1.7500 detik dengan jumlah cluster 10 dan RI sebesar 0.8560, dan eksekusi waktu
metode Average Linkage sebesar 1.7400 detik dengan jumlah cluster 14 dan RI
sebesar 0.9546. Hasil penelitian ini menunjukkan adanya perbaikan waktu
eksekusi clustering dari penelitian sebelumnya yang menggunakan metode iterasi
K-means sebesar 8.41 detik dan metode bisecting K-means sebesar 4.69 detik.
Katakunci : Hierarchical clustering, Kode Program C, Pendeteksi penjiplakan.
ABSTRACT
RUSMAN TRIATMOJO. Grouping of C Programs Based on Structure Similarity
Using Hierarchical Agglomerative Clustering. Supervised by AHMAD RIDHA.
The purpose of this research is to implement the agglomerative
hierarchical clustering algorithm to assist plagiarism detection in C program code
automatically and compare this research’s results with previous research using K-
means automatic iteration and bisecting K-means method. The data used in this
research are 386 C programs comprised of 4 datasets. The method used are Single
Linkage, Complete Linkage, and Average Linkage. The results show that the
execution time of Single Linkage method is 1.7440 seconds with 14 clusters
found and 0.9706 of RI, the execution time of Complete Linkage method is
1.7240 seconds with 10 clusters found and 0.8576 of RI, and the execution time of
Average Linkage method is 1.7340 seconds with 14 clusters found and 0.9546 of
RI. The results of this research show an improved execution time of clustering
from previous research using K-means automatic iteration method (11.68
seconds) and bisecting K-means method (6.64 seconds).
Keywords : C code program, Detect Plagiarism, Hierarchical clustering.

Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer
pada
Departemen Ilmu Komputer
PENGELOMPOKAN KODE PROGRAM C BERDASARKAN
KEMIRIPAN STRUKTUR MENGGUNAKAN METODE
HIERARCHICAL AGGLOMERATIVE CLUSTERING
RUSMAN TRIATMOJO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2014

Penguji : 1 Aziz Kustiyo, SSi MKom
2 Dr Imas S Sitanggang, SSi MKom

Judul Skripsi : Pengelompokan Kode Program C Berdasarkan Kemiripan
Struktur Menggunakan Metode Hierarchical Agglomerative
Clustering Nama : Rusman Triatmojo
NIM : G64100090
Disetujui oleh
Ahmad Ridha, SKom MS
Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom
Ketua Departemen
Tanggal Lulus:

PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhanahu Wa Ta’ala atas
segala limpahan rahmat dan karunia-Nya sehingga karya ilmiah berjudul
Pengelompokan Kode Program C Berdasarkan Kemiripan Struktur Menggunakan
Metode Hierarchical Agglomerative Clustering ini dapat penulis selesaikan.
Shalawat dan salam tak lupa penulis curahkan kepada Nabi Besar Muhammad
Shallallahu 'Alaihi Wasallam beserta seluruh keluarga, sahabat, dan para
pengikutnya sampai akhir zaman.
Terima kasih penulis ucapkan kepada Bapak Ahmad Ridha, SKom MS
selaku pembimbing yang telah banyak memberikan arahan dalam penyusunan
skripsi ini, dan terima kasih kepada Bapak Aziz Kustiyo, SSi MKom dan Ibu Dr
Imas S Sitanggang, SSi MKom selaku penguji. Selain itu, ungkapan terima kasih
juga penulis sampaikan kepada teman-teman yang telah memberikan saran,
motivasi, dan dukungan bagi kelancaran penyusunan skripsi ini. Tak lupa pula
ungkapan terima kasih penulis sampaikan kepada ayah, ibu, serta seluruh keluarga,
atas segala doa dan kasih sayangnya. Semoga skripsi ini bermanfaat.
Bogor, Agustus 2014
Rusman Triatmojo

DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE PENELITIAN 2
Pengambilan Data Penelitian 2
Pemilihan Sampel Tugas dan Pengelompokan Awal 3
Praproses data 3
Clustering 5
Penghentian Looping 6
Validasi Hasil Clustering 6
Perbandingan dengan Penelitian Sebelumnya 6
Lingkungan Implementasi 7
HASIL DAN PEMBAHASAN 7
Pengambilan dan Pemilihan Data 7
Pengelompokan Manual 7
Praproses Data 8
Hierarchical Agglomerative Clustering 9
Validasi Hasil Clustering 11
Perbandingan dengan Penelitian Sebelumnya 12
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 13
DAFTAR PUSTAKA 13
RIWAYAT HIDUP 27

DAFTAR TABEL
1 Beberapa hasil konversi term dari kode program (Burrows 2004) 4 2 Term frequency 5 3 Set data awal 7
4 Set data setelah pengelompokan manual 8 5 Hasil percobaan Single Linkage clustering untuk DataSet1 9 6 Nilai RI, jumlah cluster, jumlah dokumen, dan waktu eksekusi
clustering setiap set data percobaan Single Linkage clustering 9 7 Hasil percobaan Complete Linkage clustering untuk DataSet1 10
8 Nilai RI, jumlah cluster, jumlah dokumen, dan waktu eksekusi
clustering setiap set data percobaan Complete Linkage clustering 10 9 Hasil percobaan Average Linkage clustering untuk DataSet1 10 10 Nilai RI, jumlah cluster, jumlah dokumen, dan waktu eksekusi
clustering setiap set data percobaan Average Linkage clustering 11 11 Perbandingan hasil clustering pada saat nilai i terbaik dengan
penelitian sebelumnya 12
DAFTAR GAMBAR
1 Tahapan praproses sebelum clustering 3 2 Ilustrasi dari ukuran kesamaan kosinus 5
3 Contoh program sebelum dilakukan tokenisasi 8 4 Contoh program setelah dilakukan tokenisasi 8 5 False positive dokumen D58 dan D59 pada DataSet2 11

DAFTAR LAMPIRAN
1 Tabel aturan konversi kode program menjadi token sederhana
(Burrows 2004) 14 2 Hasil pengelompokan manual untuk DataSet1 15 3 Hasil pengelompokan manual untuk DataSet3 16
4 Hasil pengelompokan manual untuk DataSet4 17 5 Hasil pengelompokan manual untuk DataSet1 18 6 Tabel Hasil percobaan Single Linkage clustering untuk DataSet1 19 7 Hasil percobaan Single Linkage clustering untuk DataSet2 19 8 Hasil percobaan Single Linkage clustering untuk DataSet3 20
9 Hasil percobaan Single Linkage clustering untuk DataSet4 20 10 Hasil percobaan Single Linkage clustering untuk DataSetAll 21 11 Hasil percobaan Complete Linkage clustering untuk DataSet1 21
12 Hasil percobaan Complete Linkage clustering untuk DataSet2 22 13 Hasil percobaan Complete Linkage clustering untuk DataSet3 22 14 Hasil percobaan Complete Linkage clustering untuk DataSet4 23
15 Hasil percobaan Complete Linkage clustering untuk DataSetAll 23 16 Hasil percobaan Average Linkage clustering untuk DataSet1 24 17 Hasil percobaan Average Linkage clustering untuk DataSet2 24
18 Hasil percobaan Average Linkage clustering untuk DataSet3 25 19 Hasil percobaan Average Linkage clustering untuk DataSet4 25
20 Hasil percobaan Average Linkage clustering untuk DataSetAll 26


PENDAHULUAN
Latar Belakang
Mata kuliah pemrograman komputer biasanya akan memberikan tugas
kepada mahasiswanya untuk melatih kemampuan pemrograman. Tugas
pemrograman yang diberikan umumnya berupa berkas elektronik. Tugas ini
biasanya sangat rentan sekali dengan terjadinya penjiplakan yang dilakukan oleh
mahasiswa. Penjiplakan yang dilakukan dapat bermacam-macam cara, misalnya
mengubah variabel yang ada. Untuk memeriksa terjadinya penjiplakan dilakukan
pemeriksaan kesamaan dari program yang dibuat. Namun pemeriksaan yang
dilakukan secara manual akan memakan waktu lama dan melelahkan. Oleh karena
itu proses pendeteksian secara cepat dan tepat sangatlah dibutuhkan.
Pemeriksaan kemiripan kode program yang dilakukan oleh Burrows (2004)
ialah dengan cara mencari kode program dari query yang diberikan dan
menghitung kemiripannya. Sistem yang digunakan oleh Burrows adalah
structure-oriented code-based system. Sistem berbasis kode dengan
berorientasikan pada struktur kode program ini membuat representasi yang lebih
ringkas dari kode program. Penelitian mengenai pendeteksian penjiplakan kode
program C sebelumnya dilakukan oleh Gumilang (2013) dan Notyasa (2013),
keduanya mengadopsi aturan penyederhanaan yang dilakukan Burrows (2004).
Gumilang (2013) dan Notyasa (2013) keduanya menerapkan pengelompokan
berdasarkan kesamaan strukturnya. Penelitian yang dilakukan Gumilang (2013)
mengelompokkan kode program secara otomatis dengan iterasi K-means otomatis.
Iterasi K-means otomatis yaitu melakukan clustering menggunakan K-means
dengan nilai K bertambah secara otomatis pada setiap iterasinya. Iterasi berhenti
apabila anggota-anggota cluster hasil sudah cukup dekat dengan centroid-nya.
Iterasi K-means otomatis ini membutuhkan waktu eksekusi yang lama. Hal ini
dikarenakan pada setiap iterasi dilakukan proses clustering dengan jumlah
dokumen yang sama dan jumlah centroid yang semakin bertambah. Sedangkan
penelitian yang dilakukan Notyasa (2013) dengan hierarchical divisive clustering.
Algoritme hierarchical divisive clustering yang digunakan adalah bisecting K-
means. Bisecting K-means adalah algoritme hierarchical divisive clustering yang
menggunakan K-means untuk pemisahan setiap cluster-nya.
Pengelompokan kode program pada penelitian ini menggunakan tehnik
pengelompokan dalam kategori Hierarchical Agglomerative Clustering yaitu
metode Single Linkage, Complete Linkage, dan Average Linkage. Pemodelan
Single Linkage dapat digunakan untuk mengelompokkan dokumen yang
didasarkan pada jarak terkecil. Jika dua dokumen terpisah oleh jarak yang pendek
maka kedua dokumen tersebut akan digabung menjadi satu cluster dan demikian
seterusnya. Pemodelan Complete Linkage dapat digunakan untuk
mengelompokkan dokumen yang didasarkan pada jarak terbesar. Jika dua
dokumen terpisah oleh jarak yang besar maka kedua dokumen tersebut akan
digabung menjadi satu cluster dan demikian seterusnya. Pemodelan Average
Linkage dapat digunakan untuk mengelompokkan dokumen yang didasarkan
pada jarak rata-rata.

2
Perumusan Masalah
Berdasarkan latar belakang yang telah dijelaskan, dapat disimpulkan
bahwa:
1 Bagaimana mengimplementasikan algoritme hierarchical agglomerative
clustering dalam pendeteksian penjiplakan kode program C.
2 Apakah pengelompokan kode-kode program dengan menggunakan
hierarchical agglomerative clustering membutuhkan waktu eksekusi yang
lebih singkat dibandingkan dengan iterasi K-means otomatis dan bisecting K-
means.
3 Apakah hierarchical agglomerative clustering dapat menghasilkan cluster
yang lebih baik dibandingkan dengan iterasi K-means otomatis dan bisecting
K-means.
Tujuan Penelitian
Tujuan dari penelitian ini ialah mengimplementasikan algoritme
hierarchical agglomerative clustering untuk membantu pendeteksian penjiplakan
pada kode program C secara otomatis.
Manfaat Penelitian
Hasil dari penelitian ini diharapkan dapat memudahkan pemeriksaan
penjiplakan kode program C, sehingga proses pemeriksaan menjadi lebih cepat
dan efisien.
Ruang Lingkup Penelitian
1 Data yang digunakan adalah 386 buah kode program tugas pemrograman
berbahasa C yang didapat dari data penelitian sebelumnya yang dilakukan
oleh Gumilang (2013) dan Notyasa (2013)
2 Penelitian ini mengasumsikan tidak adanya makro sehingga bagian
preprocessor directives dibuang semua.
METODE PENELITIAN
Secara umum terdapat 6 tahapan penelitian, yaitu pengambilan data
penelitian, pemilihan sampel tugas dan pengelompokan manual, praproses data,
clustering,validasi hasil, dan perbandingan dengan penelitian sebelumnya.
Pengambilan Data Penelitian
Tahap awal penelitian dimulai dengan pengambilan data, data yang
digunakan dalam penelitian ini adalah data penelitian sebelumnya yang dilakukan
oleh Gumilang (2013) dan Notyasa (2013) yang diperoleh dari mata kuliah
algoritme dan pemrograman Program Studi S1 Ilmu Komputer. Data penelitian ini
adalah kumpulan berkas elektronik tugas pemrograman yang berisi kode program
bahasa C.

3
Pemilihan Sampel Tugas dan Pengelompokan Awal
Pada tahap ini dilakukan pemilihan sampel tugas dan pengelompokan tugas
secara manual. Sampel yang dipilih pada penelitian ini memiliki tingkat kesulitan
tidak terlalu mudah dan tidak terlalu sulit. Hal ini dikarenakan tugas yang terlalu
mudah akan memiliki variasi algoritme pemecahan yang sedikit, sedangkan tugas
yang terlalu susah cenderung memiliki jumlah kode program yang sedikit karena
banyak mahasiswa yang tidak mengumpulkan tugas. Sampel yang dipilih
sebanyak 92 kode program. Sampel diperiksa satu per satu dan dikelompokkan
berdasarkan kemiripan algoritme dan struktur kode programnya. Pengelompokan
awal ini untuk dasar sebagai perbandingan dalam validasi clustering.
Praproses data
Praproses data dilakukan untuk mengubah data mentah kode program C ke
dalam format yang dapat diproses ke dalam tahapan clustering, hasil praproses
data yaitu berupa term frequency. Tahapan-tahapan dalam praproses dapat dilihat
pada Gambar 1.
Gambar 1 Tahapan praproses sebelum clustering
Pembuangan preprocessor directives Tahap pertama adalah pembuangan preprocessor directives. Preprocessor
directives adalah sejumlah baris di awal kode program yang diawali dengan
karakter “#”. Pembuangan ini dilakukan karena pada penelitian ini diasumsikan
tidak adanya penggunaan makro pada kode program.
Tokenisasi Proses Tokenisasi dilakukan untuk mendapatkan keywords dan special
characters dari kode program. Pada proses tokenisasi, karakter whitespace
dibuang semua sehingga didapat term atau string uniknya saja (Manning et al.
2008). Baris komentar pada kode program dibuang karena tidak berpengaruh
terhadap output program. Karakter “;” juga dibuang karena merupakan karakter
umum yang selalu digunakan di setiap akhir baris kode program C.
Konversi Token Selanjutnya pada proses konversi token, keywords dan special characters
kode program diubah menjadi token sederhana agar lebih ringkas dan mudah
dalam pembentukan term. Kode program yang telah diubah menjadi sebuah string
panjang token sederhana disebut dengan token stream (Burrows 2004). Beberapa
Kumpulan
program
Pembuangan
preprocessor
directives
Tokenisasi
Konversi Token Pembentukan
N-gram
Tabel
term
frequency

4
konversi kode program menjadi token sederhana dilakukan berdasarkan aturan
konversi seperti pada Tabel 1. Aturan konversi kode program menjadi token
sederhana lebih lengkapnya dapat dilihat pada Lampiran 1.
Tabel 1 Beberapa hasil konversi term dari kode program (Burrows 2004)
Term Token
sederhana Term Token
sederhana Int A } L
Main N = O
For M < M
Return R + A
( H , J
) I ALPHANUM N
{ K STRING 5
Tabel 1 memperlihatkan perubahan penulisan kode menjadi token sederhana.
ALPHANUM adalah nama fungsi nama variabel atau nilai variabel. STRING
adalah sederetan karakter yang diapit oleh tanda petik (“ ”). Berikut adalah contoh
kode program yang diubah menjadi token stream:
#include <stdio.h>
int main (){
int var;
for (var=0; var<5;
var++){ printf("%d\n", var);
}
return 0;
}
Tokenstream: ANhikANMhNoNNmNNaaikNh5jNilRNl
N-gram Tahap selanjutnya adalah proses N-gram. Pada penelitian ini metode N-
gram digunakan untuk mengambil potongan-potongan karakter huruf sejumlah N
dari suatu token stream. N-gram adalah potongan sejumlah N karakter dari sebuah
string. N-gram merupakan sebuah metode yang diaplikasikan untuk
pembangkitan kata atau karakter. Cavnar dan Trenkle (1994) menyatakan N-Gram
dibedakan berdasarkan jumlah potongan karakter sebesar N. Untuk membantu
dalam mengambil potongan-potongan kata berupa karakter huruf tersebut,
dilakukan padding dengan blank karakter di awal dan di akhir suatu kata.
Nilai N yang digunakan pada penelitian ini adalah nilai N terbaik untuk
pendeteksian penjiplakan kode program, yaitu N=4 (Chawla 2003 dalam Burrows
2004). Kemudian kemunculan tiap substring dihitung sehingga didapat tabel term
frequency. Tabel 2 merupakan contoh tabel term frequency dari N-gram. Tabel ini
digunakan sebagai vektor dokumen untuk proses pengelompokan pada pemodelan
single linkage, complete linkage, dan average linkage.

5
Tabel 2 Term frequency
Dok Term
_Nhi Nhik hikF ikHF kHFA HFAN FANj ...
dok1 1 1 1 1 1 1 1 ...
dok2 1 1 1 0 0 2 1 ...
dok3 1 1 1 1 1 3 2 ...
... ... ... ... ... ... ... ... ...
Clustering
Proses pengelompokan sekumpulan objek ke dalam kelas-kelas yang objek-
objeknya serupa disebut clutering. Objek-objek dalam sebuah cluster mirip satu
sama lain dan berbeda dengan objek-objek dalam cluster lain (Han & Kamber
2006). Agglomerative secara rekursif menggabungkan sepasang titik yang
memiliki paling banyak kesamaan ke dalam satu cluster sehingga berbentuk
herarkikal. (Jain 2009). Terdapat beberapa skema yang dapat digunakan dalam
penghitungan jarak yang dilakukan pada AHC, yaitu single link, complete link,
centroid link, dan average link (Lance 1967).
Single link adalah proses clustering yang didasarkan pada jarak terdekat
antar-objeknya (minimum distance) (Lance 1967). Complete link adalah proses
clustering yang didasarkan pada jarak terjauh dari data antar-kelompok (maximum
distance) (Lance 1967). Average link adalah proses clustering yang didasarkan
pada jarak rata-rata antar-obyek (average distance) (Lance 1967).
Penelitian ini menggunakan ukuran kesamaan kosinus sebagai pengukur
jarak antar-vektor dokumen. Kesamaan kosinus memiliki sifat semakin besar nilai
persamaan kosinusnya, semakin dekat jarak kedua vektor, dan berarti semakin
mirip kedua dokumen tersebut. Gambar 2 adalah ilustrasi dari ukuran kesamaan
kosinus.
Gambar 2 Ilustrasi dari ukuran kesamaan kosinus
Perhitungan standar kesamaan antara dua dokumen d1 dan d2 adalah dengan
menghitung kesamaan kosinus dari representasi vektor dokumen (d1) dan (d2).
Vektor dokumen merupakan term frequency yang merepresentasikan jumlah term
pada tiap dokumen. Kesamaan kosinus diformulasikan sebagai berikut:
| || |

6
Pembilang menunjukkan perkalian dalam atau dot product antara dua vector,
(d1) dan (d2). Penyebut menunjukkan perkalian panjang jarak Euclid masing-
masing vektor (Manning et al. 2008).
Penghentian Looping
Penelitian ini menggunakan nilai i sebagai parameter pemberhenti looping
algoritme hierarchical agglomerative clustering. Apabila I < i maka looping
dihentikan. I adalah jarak setiap dokumen. Nilai i adalah bilangan desimal antara
0 sampai 1. Penentuan nilai i terbaik dilakukan dengan melakukan percobaan.
Nilai i yang diambil karena memiliki RI yang cukup baik dan memiliki banyak
cluster yang mendekati hasil pengelompokan manual. Percobaan dilakukan dari
nilai i=0.80 sampai i=1.00 dengan increment sebesar 0.01. Setiap percobaan i
dicatat jumlah cluster, nilai akurasi Rand Index, nilai I, dan lama waktu
eksekusinya.
Validasi Hasil Clustering
Validasi dari hasil clustering dilakukan pada tahap ini. Validasi clustering
dilakukan dengan menggunakan perhitungan akurasi Rand Index (RI). RI
menghitung persentase keputusan yang benar (Manning et al. 2008). Tujuannya
adalah memasukkan dua dokumen ke dalam satu cluster yang sama jika dan
hanya jika keduanya mirip. Formula RI ditunjukkan sebagai berikut:
T T
T T
dengan
RI : Rand index
TP : true positive / keputusan 2 dokumen mirip berada di cluster yang sama, yang
dibandingkan adalah hasil dari cluster manual dengan cluster yang dibuat
oleh sistem.
FP : false positive / keputusan 2 dokumen berbeda berada di cluster yang sama,
yang dibandingkan adalah hasil dari cluster manual dengan cluster yang
dibuat oleh sistem.
TN : true negative / keputusan 2 dokumen berbeda berada di cluster yang
berbeda, yang dibandingkan adalah hasil dari cluster manual dengan cluster
yang dibuat oleh sistem.
FN : false negative / keputusan 2 dokumen mirip berada di cluster yang berbeda,
yang dibandingkan adalah hasil dari cluster manual dengan cluster yang
dibuat oleh sistem.
Perbandingan dengan Penelitian Sebelumnya
Hasil dari penelitian ini kemudian dibandingkan dengan hasil penelitian
sebelumnya dengan menggunakan data dari penelitian Gumilang (2013). Variabel
yang dibandingkan antara lain jumlah cluster yang dihasilkan, ukuran akurasi
hasil clustering-nya, dan lama waktu clustering. Selanjutnya berdasarkan hasil

7
perbandingan tersebut, dapat dianalisis kelebihan dan kekurangan penelitian ini
dibandingkan dengan penelitian sebelumnya.
Lingkungan Implementasi
Lingkungan implementasi perangkat keras yang digunakan pada penelitian
ini berupa desktop dengan spesifikasi sebagai berikut:
Processor : Intel Core i5 @2.30GHz
Memory : 4.00 GB
Harddisk : 640GB
Perangkat lunak yang termasuk lingkungan implementasi pada penelitian ini
adalah sebagai berikut:
Windows 7 Professional sebagai sistem operasi
PHP 5.3.0 sebagai bahasa pemrograman
Netbeans 7.1.2 sebagai integrated development environment
XAMPP 3.2.1 sebagai server control panel
MySQL 5.6.14 sebagai database management system
Notepad++ 6.5.2 sebagai editor
HASIL DAN PEMBAHASAN
Pengambilan dan Pemilihan Data
Data yang digunakan pada penelitian ini adalah tugas pemrograman kode
program berbahasa C. Jumlah data yang digunakan sebanyak 386, yang terdiri
atas 4 set data. DataSetAll merupakan gabungan semua DataSet yang digunakan
dalam penelitian. Tabel 3 menunjukkan komposisi set data yang digunakan pada
penelitian ini.
Tabel 3 Set data awal
Set data Jumlah dokumen
DataSet1 92
DataSet2 92
DataSet3 75
DataSet4 66
DataSetAll 325
Pengelompokan Manual
Pengelompokan manual dilakukan dengan memeriksa nilai output program
dan struktur kode programnya. Untuk DataSet1, penelitian ini menggunakan hasil
pengelompokan manual yang sudah dilakukan oleh Gumilang (2013). Hasil
pengelompokan manual untuk DataSet1 dapat dilihat pada Lampiran 2. Untuk
DataSet3 dan DataSet4, penelitian ini menggunakan pengelompokan manual yang
sudah dilakukan oleh Notyasa (2013). Hasil pengelompokan manual untuk
DataSet3 dan DataSet4 dapat dilihat pada Lampiran 3 dan 4. Setelah dilakukan
pemeriksaan nilai output kode program dan dibandingkan strukturnya maka
didapat hasil pada DataSet2 menghasilkan 24 cluster. Cluster yang berisi terlalu

8
sedikit dokumen seperti cluster yang hanya berisi 1 atau 2 kode program tersebut
kemudian dihilangkan, karena cluster yang anggotanya terlalu sedikit membuat
jumlah cluster yang dihasilkan totalnya menjadi lebih banyak. Hasil
pengelompokan manual untuk DataSet2 dapat dilihat pada Lampiran 5. Tabel 4
menunjukkan set data setelah dilakukan pengelompokan manual.
Tabel 4 Set data setelah pengelompokan manual
Set data Jumlah dokumen Cluster manual
DataSet1 92 9
DataSet2 79 11
DataSet3 60 2
DataSet4 60 6
DataSetAll 291 28
Praproses Data
Praproses data terbagi dalam beberapa tahapan, yaitu: pembuangan
preprocessor directives, tokenisasi, konversi token, dan N-gram. Pembuangan
preprocessor directives dilakukan karena pada penelitian ini diasumsikan tidak
adanya penggunaan makro pada kode program. Berikut contoh kode program dari
Contoh kode program yang telah dihilangkan preprocessor directives, whitespace,
baris comments, karakter “;”, karakter “,”, dan pengubahan huruf uppercase
menjadi lowercase. Gambar 3 adalah contoh program sebelum dilakukan
tokenisasi, sedangkan Gambar 4 adalah contoh program setelah dilakukan
tokenisasi.
main()
{
unsigned long int a,n=0;
long int b=0;
scanf("%lu", &a); //baca input
while ((pow(10,n++))<=a)
b+=1;
printf("%lu\n", b); //cetak hasil
return 0;
}
Gambar 3 Contoh program sebelum dilakukan tokenisasi
main()
{
unsigned long int a n=0
long int b=0
scanf("%lu" &a)
while ((pow(10 n++))<=a)
b+=1
printf("%lu\n" b)
return 0
}
Gambar 4 Contoh program setelah dilakukan tokenisasi

9
Selanjutnya dilakukan proses konversi token dengan mengubah keywords
dan special characters kode program menjadi deretan token sederhana yang
merepresentasikan struktur kode program. Sebelum dilakukan pengubahan,
dilakukan pengecekan dan penambahan spasi di awal dan akhir keywords atau
special characters. Hal ini dilakukan untuk memastikan tidak terjadi kesalahan
konversi karena adanya keywords atau special characters yang berhimpitan.
Contoh keywords atau special characters yang berhimpitan misalnya inisialisasi
variabel dari int a,n=0 setelah dilakukan tokenisasi maka menjadi int an=0, untuk
itulah perlu ditambahkan spasi sehingga terpisah tidak berhimpit menjadi int a
n=0. Hasil dari proses konversi token adalah string panjang token sederhana yang
disebut token stream. Konversi kode program menjadi token sederhana dilakukan
berdasarkan aturan konversi seperti pada Tabel 1. Berikut contoh token stream
hasil konversi token kode program yang ada di Gambar 4:
NhikHFANjNoNFANoNNh5jfNiKhhNhNjNaaiimoNiNaoNNh5jNiRNl
Hierarchical Agglomerative Clustering
Proses clustering pada penelitian ini menggunakan metode Single Linkage,
Complete Linkage, dan Average Linkage.
Single Linkage
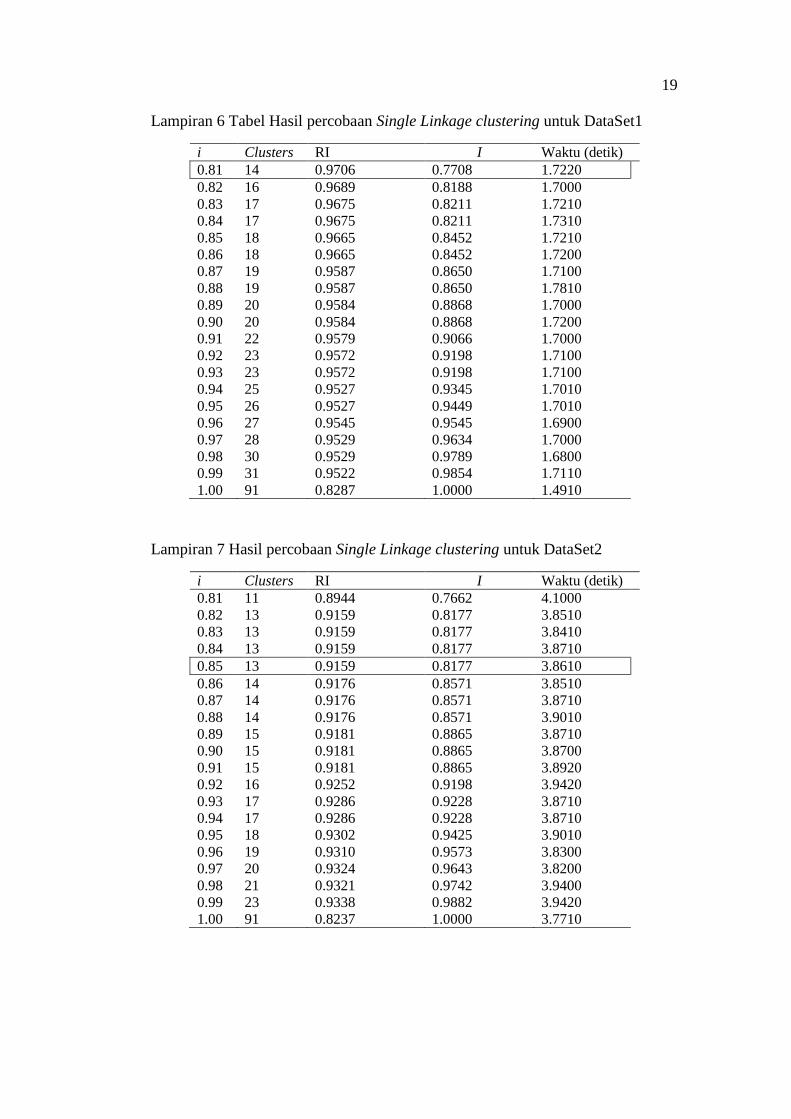
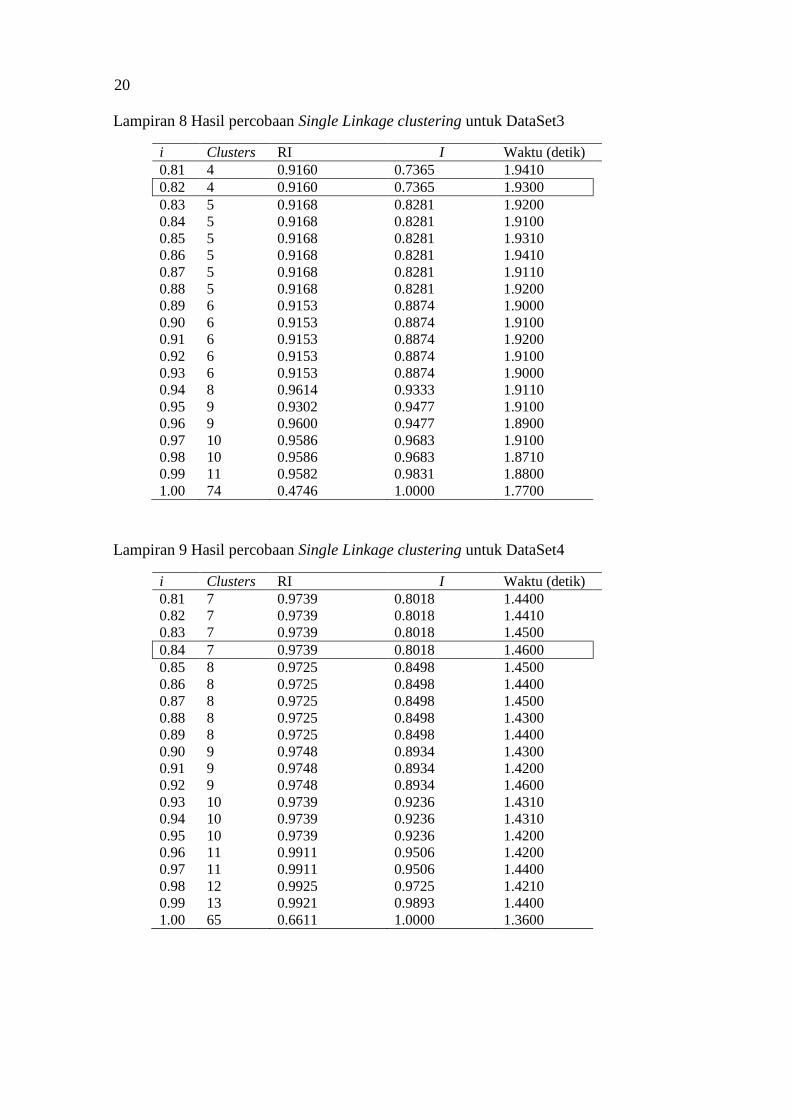
Tabel 5 menunjukkan hasil percobaan clustering pada DataSet1.
Berdasarkan hasil percobaan tersebut, dipilih nilai i=0.81. Nilai tersebut dipilih
karena memiliki rata-rata RI yang sudah cukup baik, yaitu 0.9706, dan jumlah
cluster yang tidak terlalu banyak, yaitu 14. Selanjutnya dilakukan percobaan pada
DataSet2, DataSet3, DataSet4, DataSetAll, dan diambil nilai i yang terbaik, dan
hasilnya dapat dilihat pada Tabel 6. Untuk hasil lengkap percobaan pada Dataset1,
Dataset2, Dataset3, Dataset4, dan DatasetAll dapat dilihat pada Lampiran 6,
Lampiran 7, Lampiran 8, Lampiran 9, dan Lampiran 10.
Tabel 5 Hasil percobaan Single Linkage clustering untuk DataSet1
i Jumlah Cluster RI I Waktu (detik)
0.81 14 0.9706 0.7708 1.7220
0.82 16 0.9689 0.8188 1.7000
0.83 17 0.9675 0.8211 1.7210
Tabel 6 Nilai RI, jumlah cluster, jumlah dokumen, dan waktu eksekusi
clustering setiap set data percobaan Single Linkage clustering
Set Data RI Jumlah Cluster Dokumen Waktu (detik)
DataSet1 0.9706 14 92 1.7220
DataSet2 0.9159 13 79 3.8610
DataSet3 0.9160 4 60 1.9300
DataSet4 0.9739 7 60 1.4600
DataSetAll 0.9721 39 325 74.7553
10
Complete Linkage
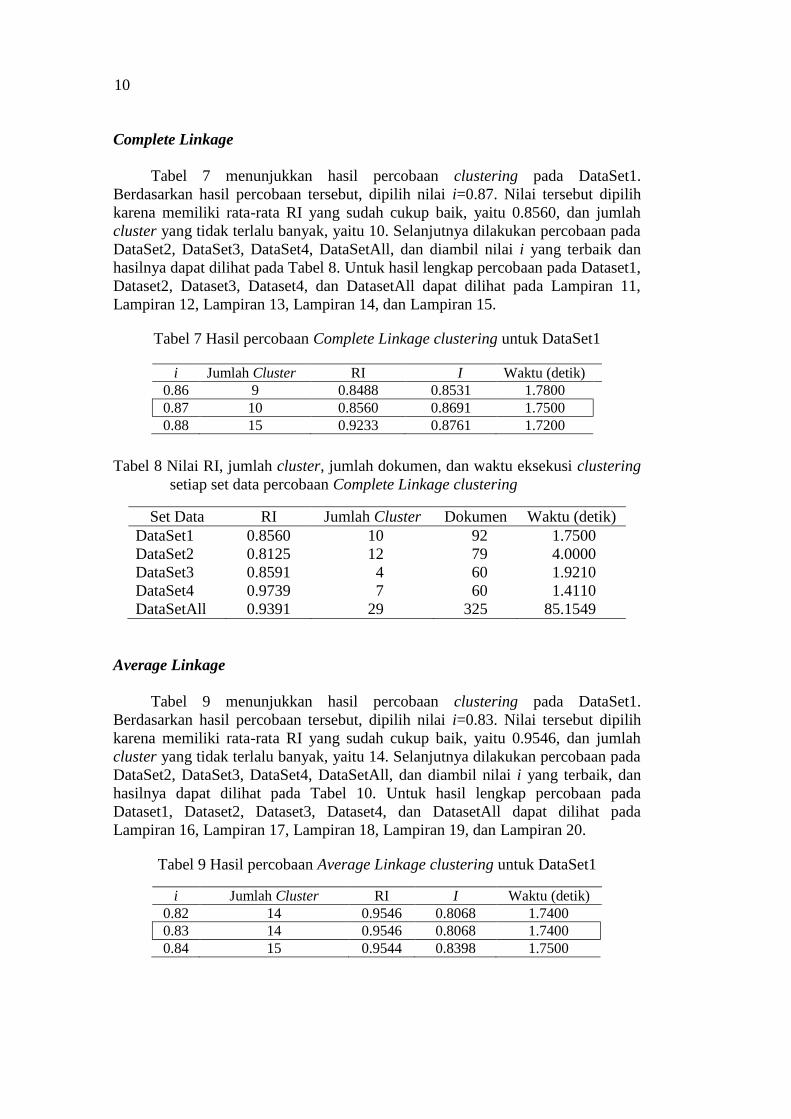
Tabel 7 menunjukkan hasil percobaan clustering pada DataSet1.
Berdasarkan hasil percobaan tersebut, dipilih nilai i=0.87. Nilai tersebut dipilih
karena memiliki rata-rata RI yang sudah cukup baik, yaitu 0.8560, dan jumlah
cluster yang tidak terlalu banyak, yaitu 10. Selanjutnya dilakukan percobaan pada
DataSet2, DataSet3, DataSet4, DataSetAll, dan diambil nilai i yang terbaik dan
hasilnya dapat dilihat pada Tabel 8. Untuk hasil lengkap percobaan pada Dataset1,
Dataset2, Dataset3, Dataset4, dan DatasetAll dapat dilihat pada Lampiran 11,
Lampiran 12, Lampiran 13, Lampiran 14, dan Lampiran 15.
Tabel 7 Hasil percobaan Complete Linkage clustering untuk DataSet1
i Jumlah Cluster RI I Waktu (detik)
0.86 9 0.8488 0.8531 1.7800
0.87 10 0.8560 0.8691 1.7500
0.88 15 0.9233 0.8761 1.7200
Tabel 8 Nilai RI, jumlah cluster, jumlah dokumen, dan waktu eksekusi clustering
setiap set data percobaan Complete Linkage clustering
Set Data RI Jumlah Cluster Dokumen Waktu (detik)
DataSet1 0.8560 10 92 1.7500
DataSet2 0.8125 12 79 4.0000
DataSet3 0.8591 4 60 1.9210
DataSet4 0.9739 7 60 1.4110
DataSetAll 0.9391 29 325 85.1549
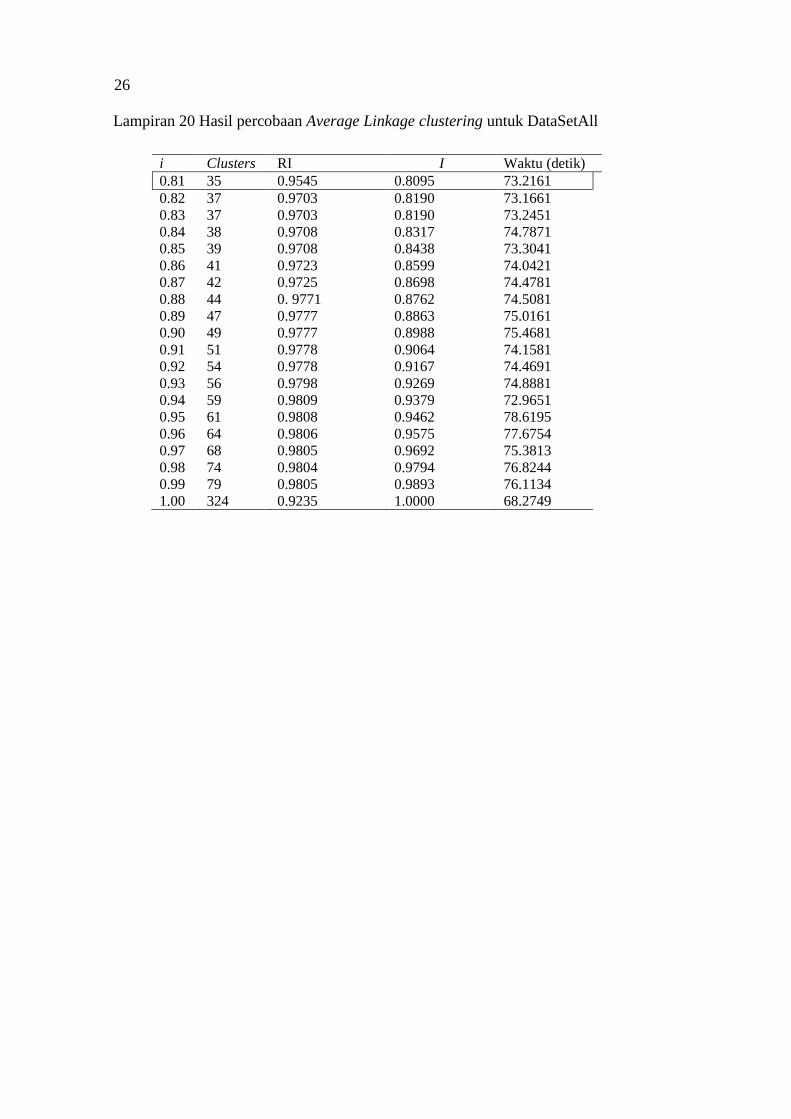
Average Linkage
Tabel 9 menunjukkan hasil percobaan clustering pada DataSet1.
Berdasarkan hasil percobaan tersebut, dipilih nilai i=0.83. Nilai tersebut dipilih
karena memiliki rata-rata RI yang sudah cukup baik, yaitu 0.9546, dan jumlah
cluster yang tidak terlalu banyak, yaitu 14. Selanjutnya dilakukan percobaan pada
DataSet2, DataSet3, DataSet4, DataSetAll, dan diambil nilai i yang terbaik, dan
hasilnya dapat dilihat pada Tabel 10. Untuk hasil lengkap percobaan pada
Dataset1, Dataset2, Dataset3, Dataset4, dan DatasetAll dapat dilihat pada
Lampiran 16, Lampiran 17, Lampiran 18, Lampiran 19, dan Lampiran 20.
Tabel 9 Hasil percobaan Average Linkage clustering untuk DataSet1
i Jumlah Cluster RI I Waktu (detik)
0.82 14 0.9546 0.8068 1.7400
0.83 14 0.9546 0.8068 1.7400
0.84 15 0.9544 0.8398 1.7500

11
Tabel 10 Nilai RI, jumlah cluster, jumlah dokumen, dan waktu eksekusi
clustering setiap set data percobaan Average Linkage clustering
Set Data RI Jumlah Cluster Dokumen Waktu (detik)
DataSet1 0.9546 14 92 1.7400
DataSet2 0.8698 11 79 3.8720
DataSet3 0.9160 4 60 1.9000
DataSet4 0.9739 7 60 1.4600
DataSetAll 0.9545 35 325 73.2161
Validasi Hasil Clustering
Validasi hasil clustering pada penelititan ini dilakukan dengan
menggunakan ukuran akurasi RI. Hasil clustering untuk set data selain DataSet2
menghasilkan nilai RI kurang dari 1.00. Hal ini menunjukkan bahwa masih
terdapat kesalahan pada hasil pendeteksian dengan menggunakan sistem.
Kesalahan yang mungkin terjadi adalah dikelompokkannya 2 kode program yang
berbeda ke cluster yang sama (false positive). Contoh pasangan dokumen false
positive pada DataSet2 saat i=0.85 ditunjukkan pada Gambar 5.
Gambar 5 menunjukkan false positive antara dokumen D58 dan D59. Kedua
kode program ini memiliki sejumlah perbedaan, namun kedua kode program
tersebut dikelompokkan ke dalam cluster yang sama oleh sistem. Hal ini dapat
disebabkan oleh adanya beberapa bagian kode program yang mirip sehingga token
stream yang dihasilkan juga masih memiliki banyak kemiripan.
#include <stdio.h> 1 #include <stdio.h>
unsigned long int 2 unsigned long int F(unsigned
long int n) fibonacci(long int n)
{
F(unsigned long int n)
unsigned long int
b,c,i,x,d;
3 {
if (n==0) 4 unsigned long int a=0, b=1,
c, i; return 0; 5 a=0, b=1, c, i;
else if (n==1) 6 if ((n==0)||(n==1))
return 1; 7 return n;
else { 8 Else
b=0; 9 {
c=1; 1
0
for (i=1; i<n; i++)
for (i=1;i<=n;i++){ 1
1
{
b=b+c; 1
2
c=a+b;
c=b-c; 1
3
a=b;
} 1
4
b=c;
return b; 1
5
}
} 1
6
return c;
} 1
7
}
main() 1
8
}
{ 1
9
main()
unsigned long int x; 2
0
{
scanf("%lu", &x); 2
1
unsigned long int x;
printf("%lu",fibonacci(x))
; (x));
2
2
scanf ("%lu", &x);
return 0; 2
3
printf("%lu\n", F(x));
} 2
4
return 0;
2
5
}
Gambar 5 False positive dokumen D58 dan D59 pada DataSet2

12
Token stream dokumen D58:
HFANhFANikHFANjNjNjNjNIhNooNiRNJIhNooNiRNJkNoNNoNMhNo
NNmoNNaaikNoNaNNoNbNlRNllNhikHFANNh5jfNiNh5jNhNiiRNl
Token stream dokumen D59:
HFANhHFANikHFANoNjNoNjNjNIhhNooNigghNooNiiRNJkMhNoNNm
NNaaikNoNaNNoNNoNlRNllNhikHFANNh5jfNiNh5jNhNiiRNl
Perbandingan dengan Penelitian Sebelumnya
Hasil penelitian ini dibandingkan dengan hasil pendeteksian penjiplakan
kode program yang telah dilakukan oleh Gumilang (2013) dan Notyasa (2013).
Algoritme yang digunakan pada penelitian Gumilang adalah algoritme flat
clustering K-means. Gumilang menggunakan iterasi K-means otomatis agar
banyaknya cluster yang diinginkan tidak perlu ditentukan terlebih dahulu.
Notyasa (2013) menggunakan algoritme bisecting K-means. Semua proses
perbandingan dilakukan pada lingkungan implementasi yang sama. Set data yang
digunakan adalah DataSet1 yang berjumlah 92 kode progam. Variabel yang
dibandingkan adalah rata-rata jumlah cluster, nilai RI, dan lama waktu eksekusi.
Hasil clustering saat nilai i terbaik pada penelitian ini dibandingkan dengan hasil
clustering saat nilai i terbaik pada penelitian Gumilang (2013) dan Notyasa (2013)
hasilnya Tabel 11.
Tabel 11 Perbandingan hasil clustering pada saat nilai i terbaik dengan penelitian
sebelumnya
Berdasarkan Tabel 11 dapat dilihat bahwa Single Linkage menghasilkan
waktu eksekusi yang lebih cepat dan nilai RI yang lebih tinggi, sedangkan jumlah
cluster yang dihasilkan lebih banyak. Complete Linkage menghasilkan waktu
eksekusi yang relatif sama dengan Single Linkage dan nilai RI yang lebih rendah,
sedangkan jumlah cluster yang dihasilkan tidak terlalu banyak seperti Bisecting
K-means. Average Linkage menghasilkan waktu eksekusi yang lebih cepat relatif
sama juga dengan Single Linkage dan Complete Linkage dengan nilai RI yang
tinggi namun tidak sebagus Single Linkage, sedangkan jumlah cluster yang
dihasilkan lebih banyak seperti halnya Single Linkage.
Variabel Bisecting
K-means
Iterasi K-
means
Single
Linkage
Complete
Linkage
Average
Linkage
Nilai i terbaik 0.94 0.97 0.81 0.87 0.83
Jumlah cluster 9 11 14 10 14
Nilai RI 0.9140 0.9028 0.9706 0.8560 0.9546
Waktu eksekusi
(detik)
4.6939 8.4126 1.7220 1.7500 1.7400

13
SIMPULAN DAN SARAN
Simpulan
Algoritme Hierarchical Agglomerative Clustering dapat diimplementasikan
untuk mendeteksi penjiplakan kode program C. Hasil dari pendeteksian ini cukup
baik dengan cluster yang dihasilkan memiliki rata-rata akurasi RI lebih dari 80%.
Pendeteksian pada penelitian ini melakukan pengelompokan kode program dalam
waktu yang lebih cepat dibandingkan pendeteksian dengan iterasi K-means
otomatis dan bisecting K-means, tetapi memiliki rata-rata akurasi RI yang lebih
sedikit dibandingkan dengan hasil pendeteksian dengan iterasi K-means otomatis
dan bisecting K-means. Jadi berdasarkan hasil penelitian yang dilakukan,
rekomendasi algoritme untuk deteksi penjiplakan kode program C yang paling
bagus menggunakan metode Single Linkage.
Saran
Pendeteksian penjiplakan pada penelitian ini dilakukan hanya
berorientasikan pada struktur kode program. Hal ini dapat menyebabkan
terjadinya kesalahan pada pendeteksian apabila dilakukan modifikasi yang
mengubah struktur kode program tanpa mengubah nilai keluarannya. Hal ini dapat
diatasi pada penelitian selanjutnya dengan juga memperhatikan faktor semantik
kode program pada saat pendeteksian. Pemeriksaan faktor semantik ini dapat
dilakukan dengan mengecek nilai keluaran kode program terlebih dahulu sebelum
dilakukan proses clustering.
DAFTAR PUSTAKA
Burrows S, 2004. Efficient and effective plagiarism detection for large code
repositories [tesis]. Melbourne (AU): RMIT University.
Cavnar WB, Trenkle JM. 1994. N-Gram-Based Text Categorization. Ann Arbor
(US): Environmental Research Institute of Michigan.
Chawla M. 2003. An indexing technique for efficiently detecting plagiarism in
large volume of source code [tesis]. Melbourne (AU): RMIT University.
Gumilang AP. 2013. Pendeteksian penjiplakan kode program C dengan K-Means
[skripsi]. Bogor (ID): Institut Pertanian Bogor.
Han J, Kamber M. 2006. Data Mining Concepts and Techniques. Edisi Ke-2. San
Francisco (US): Morgan Kaufmann Publisher.
Jain AK. 2009. Data clustering: 50 years beyond K-Means. Pattern Recognition
Letters Journal 31 (8): 651-666. doi: 10.1016/j.patrec.2009.09.011
Lance GN, Williams WT. 1967. A general theory of classificatory sorting
strategies. Computer Journal 9 (4): 373-380. doi: 10.1093/comjnl/9.4.373.
Manning CD, Raghavan P, Schütze H. 2008. An Introduction to Information
Retrieval. Cambridge (UK): Cambridge University Press.
Notyasa A. 2013. Pendeteksian penjiplakan kode program C dengan Bisecting K-
Means [skripsi]. Bogor (ID): Institut Pertanian Bogor.

14
Lampiran 1 Tabel aturan konversi kode program menjadi token sederhana
(Burrows 2004)
Keyword / special
character
Token
sederhana
Keyword / special
character
Token
sederhana
+ a short E
- b long F
* c signed G
/ d unsigned H
% e if I
& f else J
| g while K
( h do L
) i for M
, j ALPHANUM N
{ k goto O
} l case P
< m break Q
> n return R
= o switch S
. p const T
! q continue U
: r sizeof W
int A struct X
float B enum Y
char C typedef Z
double D "STRING" 5

15
Lampiran 2 Hasil pengelompokan manual untuk DataSet1
1 2 3 4 5 6 7 8 9
D13 D1 D2 D3 D6 D9 D19 D25 D20
D16 D60 D4 D5 D18 D12 D41 D50 D59
D17 D68 D11 D7 D28 D34 D54
D66
D22 D86 D14 D8 D39 D38 D63
D71
D23 D87 D15 D10 D58 D40
D75
D24 D90 D21 D47 D64
D76
D26 D91 D29 D53 D69
D77
D27 D31 D56 D72
D88
D30 D35 D78
D92
D32
D43 D84
D33
D49
D36
D52
D37
D55
D42
D57
D44
D67
D45
D73
D46
D83
D48
D51
D61
D62
D65
D70
D74
D79
D80
D81
D82
D85
D89

16
Lampiran 3 Hasil pengelompokan manual untuk DataSet3
1 2
D1 D32 D5
D2 D33 D25
D3 D34 D31
D4 D35 D36
D6 D37 D40
D7 D38 D52
D8 D39 D56
D9 D41 D60
D10 D42
D11 D43
D12 D44
D13 D45
D14 D46
D15 D47
D16 D48
D17 D49
D18 D50
D19 D51
D20 D53
D21 D54
D22 D55
D23 D57
D24 D58
D26 D59
D27
D28
D29
D30

17
Lampiran 4 Hasil pengelompokan manual untuk DataSet4
1 2 3 4 5 6
D1 D2 D3 D6 D9 D33
D27 D12 D4 D7 D17 D35
D59 D24 D10 D8 D41 D45
D29 D11 D15 D54
D39 D13 D44 D57
D49 D14
D56 D16
D18
D19
D20
D21
D22
D23
D25
D26
D28
D30
D31
D32
D34
D36
D37
D38
D40
D42
D43
D46
D47
D48
D50
D51
D52
D53
D55
D58
D60
D61

18
Lampiran 5 Hasil pengelompokan manual untuk DataSet2
1 2 3 4 5 6 7 8 9 10 11
D1 D2 D3 D4 D6 D8 D16 D21 D29 D33 D90
D32 D5 D34 D35 D7 D10 D17 D75 D41 D46 D98
D93 D30 D49 D45 D12 D11 D24 D83 D56 D48
D53 D94 D59 D13 D18 D60 D62
D64 D79 D14 D63 D76 D96
D89 D15 D70 D80
D20 D78
D23
D26
D27
D33
D36
D37
D42
D43
D50
D51
D54
D55
D65
D66
D68
D71
D72
D77
D81
D82
D85
D86
D87
D88
D91
D92
D95
D97
19
Lampiran 6 Tabel Hasil percobaan Single Linkage clustering untuk DataSet1
i Clusters RI I Waktu (detik)
0.81 14 0.9706 0.7708 1.7220
0.82 16 0.9689 0.8188 1.7000
0.83 17 0.9675 0.8211 1.7210
0.84 17 0.9675 0.8211 1.7310
0.85 18 0.9665 0.8452 1.7210
0.86 18 0.9665 0.8452 1.7200
0.87 19 0.9587 0.8650 1.7100
0.88 19 0.9587 0.8650 1.7810
0.89 20 0.9584 0.8868 1.7000
0.90 20 0.9584 0.8868 1.7200
0.91 22 0.9579 0.9066 1.7000
0.92 23 0.9572 0.9198 1.7100
0.93 23 0.9572 0.9198 1.7100
0.94 25 0.9527 0.9345 1.7010
0.95 26 0.9527 0.9449 1.7010
0.96 27 0.9545 0.9545 1.6900
0.97 28 0.9529 0.9634 1.7000
0.98 30 0.9529 0.9789 1.6800
0.99 31 0.9522 0.9854 1.7110
1.00 91 0.8287 1.0000 1.4910
Lampiran 7 Hasil percobaan Single Linkage clustering untuk DataSet2
i Clusters RI I Waktu (detik)
0.81 11 0.8944 0.7662 4.1000
0.82 13 0.9159 0.8177 3.8510
0.83 13 0.9159 0.8177 3.8410
0.84 13 0.9159 0.8177 3.8710
0.85 13 0.9159 0.8177 3.8610
0.86 14 0.9176 0.8571 3.8510
0.87 14 0.9176 0.8571 3.8710
0.88 14 0.9176 0.8571 3.9010
0.89 15 0.9181 0.8865 3.8710
0.90 15 0.9181 0.8865 3.8700
0.91 15 0.9181 0.8865 3.8920
0.92 16 0.9252 0.9198 3.9420
0.93 17 0.9286 0.9228 3.8710
0.94 17 0.9286 0.9228 3.8710
0.95 18 0.9302 0.9425 3.9010
0.96 19 0.9310 0.9573 3.8300
0.97 20 0.9324 0.9643 3.8200
0.98 21 0.9321 0.9742 3.9400
0.99 23 0.9338 0.9882 3.9420
1.00 91 0.8237 1.0000 3.7710
20
Lampiran 8 Hasil percobaan Single Linkage clustering untuk DataSet3
i Clusters RI I Waktu (detik)
0.81 4 0.9160 0.7365 1.9410
0.82 4 0.9160 0.7365 1.9300
0.83 5 0.9168 0.8281 1.9200
0.84 5 0.9168 0.8281 1.9100
0.85 5 0.9168 0.8281 1.9310
0.86 5 0.9168 0.8281 1.9410
0.87 5 0.9168 0.8281 1.9110
0.88 5 0.9168 0.8281 1.9200
0.89 6 0.9153 0.8874 1.9000
0.90 6 0.9153 0.8874 1.9100
0.91 6 0.9153 0.8874 1.9200
0.92 6 0.9153 0.8874 1.9100
0.93 6 0.9153 0.8874 1.9000
0.94 8 0.9614 0.9333 1.9110
0.95 9 0.9302 0.9477 1.9100
0.96 9 0.9600 0.9477 1.8900
0.97 10 0.9586 0.9683 1.9100
0.98 10 0.9586 0.9683 1.8710
0.99 11 0.9582 0.9831 1.8800
1.00 74 0.4746 1.0000 1.7700
Lampiran 9 Hasil percobaan Single Linkage clustering untuk DataSet4
i Clusters RI I Waktu (detik)
0.81 7 0.9739 0.8018 1.4400
0.82 7 0.9739 0.8018 1.4410
0.83 7 0.9739 0.8018 1.4500
0.84 7 0.9739 0.8018 1.4600
0.85 8 0.9725 0.8498 1.4500
0.86 8 0.9725 0.8498 1.4400
0.87 8 0.9725 0.8498 1.4500
0.88 8 0.9725 0.8498 1.4300
0.89 8 0.9725 0.8498 1.4400
0.90 9 0.9748 0.8934 1.4300
0.91 9 0.9748 0.8934 1.4200
0.92 9 0.9748 0.8934 1.4600
0.93 10 0.9739 0.9236 1.4310
0.94 10 0.9739 0.9236 1.4310
0.95 10 0.9739 0.9236 1.4200
0.96 11 0.9911 0.9506 1.4200
0.97 11 0.9911 0.9506 1.4400
0.98 12 0.9925 0.9725 1.4210
0.99 13 0.9921 0.9893 1.4400
1.00 65 0.6611 1.0000 1.3600

21
Lampiran 10 Hasil percobaan Single Linkage clustering untuk DataSetAll
i Clusters RI I Waktu (detik)
0.81 39 0.9721 0. 8077 74.7553
0.82 40 0.9734 0. 8194 74.4223
0.83 41 0.9733 0. 8203 75.1283
0.84 43 0.9781 0.8329 75.0423
0.85 44 0.9780 0.8425 76.3354
0.86 46 0.9774 0.8582 76.9124
0.87 47 0.9779 0.8677 76.4224
0.88 48 0.9779 0.8767 75.7523
0.89 50 0.9783 0.8882 78.4695
0.90 51 0.9784 0.8958 77.2734
0.91 53 0.9784 0.9079 76.6034
0.92 56 0.9784 0.9198 81.3106
0.93 58 0.9783 0.9294 74.7153
0.94 60 0.9810 0.9392 74.4793
0.95 64 0.9811 0.9483 74.1672
0.96 67 0.9811 0.9597 75.4673
0.97 70 0.9812 0.9684 76.4704
0.98 74 0.9810 0.9781 81.5977
0.99 79 0.9804 0.9889 84.4048
1.00 324 0.9235 1.0000 76.4024
Lampiran 11 Hasil percobaan Complete Linkage clustering untuk DataSet1
i Clusters RI I Waktu (detik)
0.81 7 0.7917 0.8086 1.8000
0.82 7 0.7917 0.8086 1.7910
0.83 7 0.7917 0.8086 1.7800
0.84 8 0.8418 0.8335 1.7510
0.85 8 0.8418 0.8335 1.7500
0.86 9 0.8488 0.8531 1.7800
0.87 10 0.8560 0.8691 1.7500
0.88 15 0.9233 0.8761 1.7200
0.89 15 0.9233 0.8761 1.7310
0.90 18 0.9477 0.8985 1.7500
0.91 18 0.9477 0.8985 1.7400
0.92 21 0.9575 0.9186 1.7300
0.93 21 0.9575 0.9186 1.7200
0.94 22 0.9568 0.9313 1.7200
0.95 23 0.9575 0.9427 1.7100
0.96 24 0.9565 0.9513 1.7210
0.97 27 0.9584 0.9670 1.7000
0.98 29 0.9505 0.9785 1.7500
0.99 31 0.9460 0.9871 1.6900
1.00 91 0.8287 1.0000 1.5410

22
Lampiran 12 Hasil percobaan Complete Linkage clustering untuk DataSet2
i Clusters RI I Waktu (detik)
0.81 8 0.6457 0.8071 4.0420
0.82 8 0.6457 0.8071 4.0200
0.83 8 0.6457 0.8071 4.0110
0.84 9 0.6581 0.8336 4.0110
0.85 9 0.6581 0.8336 4.1400
0.86 11 0.8022 0.8509 4.0220
0.87 11 0.8022 0.8509 4.0500
0.88 12 0.8125 0.8750 4.0510
0.89 12 0.8125 0.8750 4.1310
0.90 12 0.8125 0.8750 4.0000
0.91 13 0.8196 0.9079 4.0410
0.92 14 0.8617 0.9177 3.9710
0.93 15 0.9161 0.9209 4.0800
0.94 15 0.9161 0.9209 4.0210
0.95 16 0.9176 0.9431 4.0020
0.96 18 0.9219 0.9592 3.9710
0.97 19 0.9243 0.9667 3.9300
0.98 21 0.9283 0.9776 4.0100
0.99 22 0.9290 0.9846 4.0600
1.00 91 0.8237 1.0000 3.8100
Lampiran 13 Hasil percobaan Complete Linkage clustering untuk DataSet3
i Clusters RI I Waktu (detik)
0.81 4 0.8591 0.7955 1.9000
0.82 4 0.8591 0.7955 1.9210
0.83 4 0.8591 0.7955 1.9000
0.84 4 0.8591 0.7955 1.9400
0.85 4 0.8591 0.7955 1.9110
0.86 4 0.8591 0.7955 1.9200
0.87 4 0.8591 0.7955 1.9210
0.88 5 0.8605 0.8709 1.9000
0.89 5 0.8605 0.8709 1.9000
0.90 5 0.8605 0.8709 1.9000
0.91 5 0.8605 0.8709 1.9110
0.92 6 0.8778 0.9151 1.9300
0.93 6 0.8778 0.9151 1.8920
0.94 6 0.8778 0.9151 1.9000
0.95 8 0.9225 0.9411 1.9000
0.96 8 0.9225 0.9411 1.9010
0.97 10 0.9586 0.9683 1.8700
0.98 10 0.9586 0.9683 1.8900
0.99 11 0.9831 0.9831 1.8700
1.00 74 0.4746 1.0000 1.7410

23
Lampiran 14 Hasil percobaan Complete Linkage clustering untuk DataSet4
i Clusters RI I Waktu (detik)
0.81 6 0.9403 0.7517 1.4300
0.82 7 0.9739 0.8141 1.4100
0.83 7 0.9739 0.8141 1.4210
0.84 7 0.9739 0.8141 1.4000
0.85 7 0.9739 0.8141 1.4110
0.86 7 0.9739 0.8141 1.4110
0.87 8 0.9762 0.8627 1.4400
0.88 8 0.9762 0.8627 1.4210
0.89 8 0.9762 0.8627 1.4300
0.90 9 0.9748 0.8941 1.4000
0.91 9 0.9748 0.8941 1.4300
0.92 9 0.9748 0.8941 1.4200
0.93 10 0.9739 0.9236 1.4200
0.94 10 0.9739 0.9236 1.4000
0.95 10 0.9739 0.9236 1.4200
0.96 11 0.9911 0.9506 1.4100
0.97 11 0.9911 0.9506 1.4300
0.98 12 0.9925 0.9725 1.4400
0.99 13 0.9921 0.9893 1.4100
1.00 65 0.6611 1.0000 1.3200
Lampiran 15 Hasil percobaan Complete Linkage clustering untuk DataSetAll
i Clusters RI I Waktu (detik)
0.81 22 0.9220 0.8065 78.6635
0.82 22 0.9220 0.8065 83.5878
0.83 24 0.9274 0.8265 85.7099
0.84 25 0.9283 0.8385 82.6517
0.85 26 0.9316 0.8464 84.1158
0.86 29 0.9391 0.8579 85.1549
0.87 33 0.9476 0.8699 86.3919
0.88 35 0.9486 0.8781 85.9339
0.89 36 0.9500 0.8868 82.1837
0.90 44 0.9716 0.8980 82.5077
0.91 45 0.9723 0.9052 82.7137
0.92 47 0.9723 0.9168 81.5457
0.93 51 0.9744 0.9272 80.4536
0.94 55 0.9751 0.9383 84.5848
0.95 57 0.9760 0.9462 81.9087
0.96 60 0.9778 0.9572 81.1246
0.97 67 0.9782 0.9691 80.0356
0.98 73 0.9805 0.9792 75.1873
0.99 79 0.9807 0.9897 76.1134
1.00 324 0.9235 1.0000 67.1638

24
Lampiran 16 Hasil percobaan Average Linkage clustering untuk DataSet1
i Clusters RI I Waktu (detik)
0.81 14 0.9546 0.8068 1.7300
0.82 14 0.9546 0.8068 1.7400
0.83 14 0.9546 0.8068 1.7400
0.84 15 0.9544 0.8398 1.7500
0.85 15 0.9544 0.8398 1.7300
0.86 15 0.9544 0.8398 1.7600
0.87 16 0.9534 0.8603 1.7510
0.88 18 0.9584 0.8650 1.7400
0.89 19 0.9582 0.8898 1.7510
0.90 21 0.9577 0.8987 1.7210
0.91 22 0.9591 0.9086 1.7200
0.92 22 0.9591 0.9086 1.7400
0.93 23 0.9589 0.9221 1.7100
0.94 24 0.9591 0.9338 1.7030
0.95 25 0.9560 0.9444 1.6800
0.96 26 0.9545 0.9525 1.6900
0.97 28 0.9560 0.9693 1.7200
0.98 29 0.9551 0.9751 1.7210
0.99 31 0.9474 0.9862 1.6900
1.00 91 0.8287 1.0000 1.5510
Lampiran 17 Hasil percobaan Average Linkage clustering untuk DataSet2
i Clusters RI I Waktu (detik)
0.81 11 0.8698 0.7863 3.9410
0.82 11 0.8698 0.7863 3.8720
0.83 12 0.8724 0.8256 3.9000
0.84 12 0.8724 0.8256 3.9310
0.85 12 0.8724 0.8256 3.9010
0.86 12 0.8724 0.8256 3.8700
0.87 13 0.8741 0.8674 3.9300
0.88 13 0.8741 0.8674 3.8810
0.89 14 0.9090 0.8872 3.8900
0.90 14 0.9090 0.8872 3.8710
0.91 14 0.9090 0.8872 3.8800
0.92 15 0.9161 0.9150 3.8800
0.93 16 0.9181 0.9277 3.8730
0.94 16 0.9181 0.9277 3.8710
0.95 17 0.9197 0.9482 3.8610
0.96 18 0.9219 0.9596 3.9400
0.97 19 0.9271 0.9610 3.8810
0.98 21 0.9283 0.9760 3.8720
0.99 23 0.9358 0.9897 3.9510
1.00 91 0.8237 1.0000 3.6010

25
Lampiran 18 Hasil percobaan Average Linkage clustering untuk DataSet3
i Clusters RI I Waktu (detik)
0.81 4 0.9160 0.7517 1.8910
0.82 4 0.9160 0.7517 1.8810
0.83 4 0.9160 0.7517 1.9000
0.84 5 0.9168 0.8377 1.8600
0.85 5 0.9168 0.8377 1.9010
0.86 5 0.9168 0.8377 1.8510
0.87 5 0.9168 0.8377 1.8600
0.88 5 0.9168 0.8377 1.8700
0.89 5 0.9168 0.8377 1.8900
0.90 5 0.9168 0.8377 1.8910
0.91 6 0.9542 0.9019 1.8700
0.92 6 0.9542 0.9019 1.8500
0.93 6 0.9542 0.9019 1.8700
0.94 6 0.9542 0.9019 1.8610
0.95 9 0.9600 0.9487 1.8300
0.96 9 0.9600 0.9487 1.8400
0.97 10 0.9586 0.9683 1.8800
0.98 10 0.9586 0.9683 1.9010
0.99 11 0.9582 0.9831 1.8710
1.00 74 0.4746 1.0000 1.6900
Lampiran 19 Hasil percobaan Average Linkage clustering untuk DataSet4
i Clusters RI I Waktu (detik)
0.81 7 0.9739 0.8085 1.5400
0.82 7 0.9739 0.8085 1.4000
0.83 7 0.9739 0.8085 1.4610
0.84 7 0.9739 0.8085 1.4600
0.85 7 0.9739 0.8085 1.4600
0.86 8 0.9725 0.8528 1.4400
0.87 8 0.9725 0.8528 1.4500
0.88 8 0.9725 0.8528 1.4500
0.89 8 0.9725 0.8528 1.4600
0.90 9 0.9748 0.8939 1.4100
0.91 9 0.9748 0.8939 1.4800
0.92 9 0.9748 0.8939 1.4300
0.93 10 0.9739 0.9236 1.4400
0.94 10 0.9739 0.9236 1.4300
0.95 10 0.9739 0.9236 1.4500
0.96 11 0.9911 0.9506 1.4800
0.97 11 0.9911 0.9506 1.4310
0.98 12 0.9925 0.9725 1.4710
0.99 13 0.9921 0.9893 1.4400
1.00 65 0.6611 1.0000 1.3400
26
Lampiran 20 Hasil percobaan Average Linkage clustering untuk DataSetAll
i Clusters RI I Waktu (detik)
0.81 35 0.9545 0.8095 73.2161
0.82 37 0.9703 0.8190 73.1661
0.83 37 0.9703 0.8190 73.2451
0.84 38 0.9708 0.8317 74.7871
0.85 39 0.9708 0.8438 73.3041
0.86 41 0.9723 0.8599 74.0421
0.87 42 0.9725 0.8698 74.4781
0.88 44 0. 9771 0.8762 74.5081
0.89 47 0.9777 0.8863 75.0161
0.90 49 0.9777 0.8988 75.4681
0.91 51 0.9778 0.9064 74.1581
0.92 54 0.9778 0.9167 74.4691
0.93 56 0.9798 0.9269 74.8881
0.94 59 0.9809 0.9379 72.9651
0.95 61 0.9808 0.9462 78.6195
0.96 64 0.9806 0.9575 77.6754
0.97 68 0.9805 0.9692 75.3813
0.98 74 0.9804 0.9794 76.8244
0.99 79 0.9805 0.9893 76.1134
1.00 324 0.9235 1.0000 68.2749

27
RIWAYAT HIDUP
Penulis dilahirkan pada tanggal 24 Mei 1992 di Kota Bekasi, Jawa Barat.
Penulis merupakan anak ketiga dari pasangan Bapak Supardi dan Ibu Sulanjari.
Penulis memiliki dua orang kakak yang bernama Bekti Siswati dan Desi
Widyawati.
Penulis menyelesaikan pendidikan sekolah menengah atas pada tahun 2010
di SMA Negeri 2 Kota Bekasi. Pada tahun 2010 penulis diterima sebagai
mahasiswa Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB
(USMI) dan diterima sebagai mahasiswa Departemen Ilmu Komputer, Fakultas
Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor. Pada tahun
2013 penulis menjalankan praktik kerja lapangan di PT. Suntory Garuda Beverage.