retrieval strategies -...
TRANSCRIPT

RETRIEVAL STRATEGIES Budi Susanto
Text & Web Mining - Budi Susanto - TI UKDW 1

Tujuan • Memahami model probabilitistic retrieval dengan metode
Simple Term Weights. • Memahami model Extended Boolean untuk IR. • Memahami language model dengan metode query
likelihood untuk IR.
Text & Web Mining - Budi Susanto - TI UKDW 2

Diskusi Latihan • Terdapat 3 dokumen
• D1 = Manajemen Sistem Informasi • D2 = Penggajian untuk meningkatkan Sumber Daya Manusia • D3 = Sistem Informasi Penggajian • Q = informasi daya manusia
• Hitunglah rangking dari semua dokumen terhadap query dengan pendekatan vector space model!
Text & Web Mining - Budi Susanto - TI UKDW 3

1. Probabilistic Retrieval • Model probabilitas menghitung koefisien kemiripan antara
sebuah query dan dokumen sebagai sebuah probabilitas bahwa dokumen tersebut akan relevan dengan query.
• Semua penelitian terhadap probabilitic retrieval berakar pada konsep perkiraan bobot term berdasar seberapa sering term muncul atau tidak dalam dokumen relevan dan non-relevan.
Text & Web Mining - Budi Susanto - TI UKDW 4

Simple Term Weights • Term dalam query dapat dilihat sebagai indikator bahwa
dokumen relevan. • Sehingga ada atau tidaknya term query dapat digunakan untuk
memprediksi apakah dokumen relevan atau tidak.
• Operasi dot product semua bobot dapat digunakan untuk menghitung probabilitas relevansi.
• Sebagian besar model probabilitic mengasumsikan independensi tiap term. • Karena untuk memperhatikan dependensi tiap term membutuhkan
komputasi lebih mahal dan membutuhkan adanya pelatihan ke sistem.
Text & Web Mining - Budi Susanto - TI UKDW 5

Simple Term Weights
Text & Web Mining - Budi Susanto - TI UKDW 6
q = { t1, t2 }
t1 t1
t2
t2 t1 t2
Dokumen Terambil
P(t1 | Di relevan) = ½ P(t1 | Di non relevan) = 2/3 P(t2 | Di relevan) = 1 P(t2 | Di non relevan ) = 1/3

Simple Term Weights • Metode Robertson dan Sparck Jones (1976)
menyediakan mekanisme perhitungan probabilitas relevan dan tidak relevan untuk sebuah term.
• Definisi asumsi mutually exclusive independence: • I1 = distribusi term dalam dokumen relevan adalah independen dan
distribusi term dalam sluruh dokumen juga independen • I2 = distribusi term dalam dokumen relevan adalah independen dan
distribusi term dalam dokumen non-relevan juga independen.
• Definisi dua metode untuk presentasi hasil: • O1 = kemungkinan relevan didasarkan hanya pada kemunculan
term yang dicari dalam dokumen • O2 = kemungkinan relevan didasarkan baik pada kemunculan atau
ketidakmunculan term yang dicari dalam dokumen
Text & Web Mining - Budi Susanto - TI UKDW 7

Simple Term Weights • Empat bobot diturunkan dari kombinasi prinsip rankings
dan asumsi independensi
Text & Web Mining - Budi Susanto - TI UKDW 8

Simple Term Weights • N = jumlah dokumen dalam koleksi • R = jumlah dokumen relevan untuk query q • n = jumlah dokumen yang mengandung term t • r = jumlah dokumen relevan yang memiliki term t
Text & Web Mining - Budi Susanto - TI UKDW 9

Simple Term Weights
O1 O2 I1 w1 w3
I2 w2 w4
Text & Web Mining - Budi Susanto - TI UKDW 10
• W4 merupakan hasil terbaik • W3 dan w4 adalah hasil lebih baik dari
pada w1 dan w2.

Simple Term Weights • Jika dalam suatu perhitungan bobot diketahui adanya
inifiniti, maka perhitungan keempat bobot dapat diubah menjadi:
Text & Web Mining - Budi Susanto - TI UKDW 11
w1 = log
(r + 0.5)(R+1)(n+1)(N + 2)
!
"
####
$
%
&&&&
w2 = log
(r + 0.5)(R+1)
(n− r + 0.5)(N − R+1)
!
"
####
$
%
&&&&
w3 = log
(r + 0.5)(R− r + 0.5)(n+1)
(N − n+1)
"
#
$$$$
%
&
''''
w4 = log
(r + 0.5)(R− r + 0.5)(n− r + 0.5)
(N − n− (R− r)+ 0.5)
"
#
$$$$
%
&
''''

Contoh • Q: “gold silver truck” • D1 = “Shipment of gold damaged in a fire” • D2 = “Delivery of silver arrived in a silver truck” • D3 = “Shipment of gold arrived in a truck” • Oleh karena dalam model probabilistik diperlukan
dokumen pelatihan, maka ketiga dokumen diasumsikan adalah dokumen pelatihan. • D1 dan D2 adalah relevan terhadap query.
Text & Web Mining - Budi Susanto - TI UKDW 12
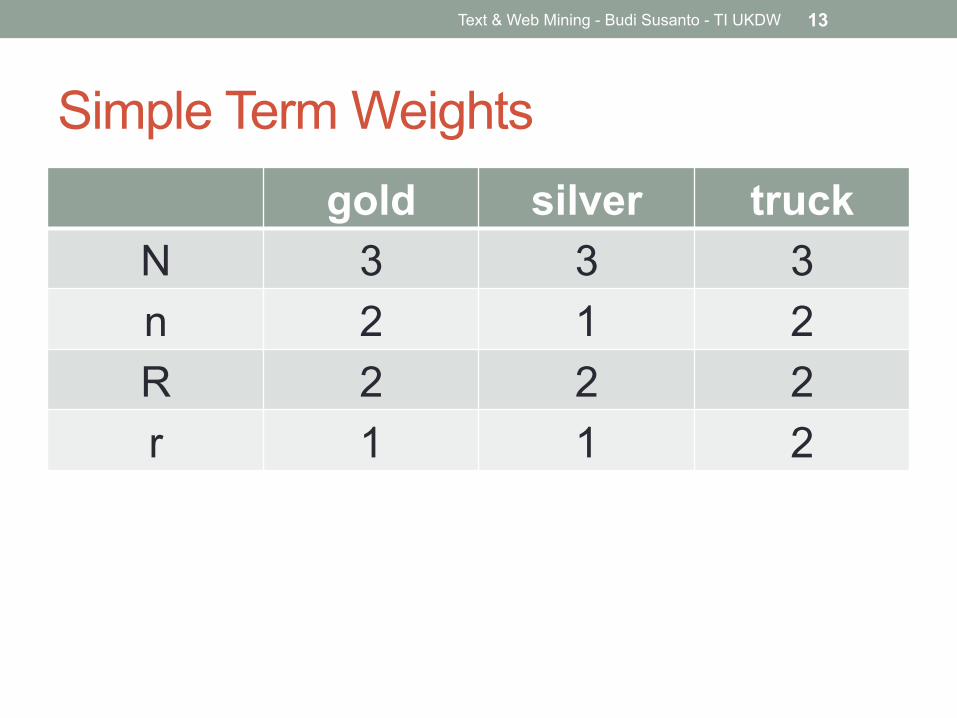
Simple Term Weights gold silver truck
N 3 3 3 n 2 1 2 R 2 2 2 r 1 1 2
Text & Web Mining - Budi Susanto - TI UKDW 13
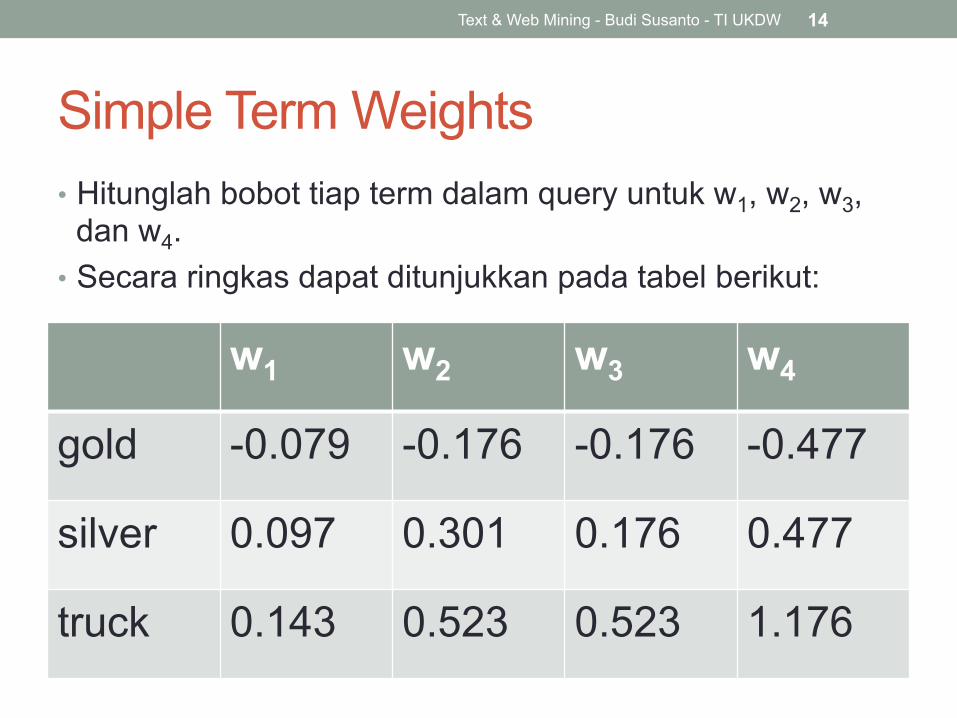
Simple Term Weights • Hitunglah bobot tiap term dalam query untuk w1, w2, w3,
dan w4. • Secara ringkas dapat ditunjukkan pada tabel berikut:
Text & Web Mining - Budi Susanto - TI UKDW 14
w1 w2 w3 w4
gold -0.079 -0.176 -0.176 -0.477
silver 0.097 0.301 0.176 0.477
truck 0.143 0.523 0.523 1.176
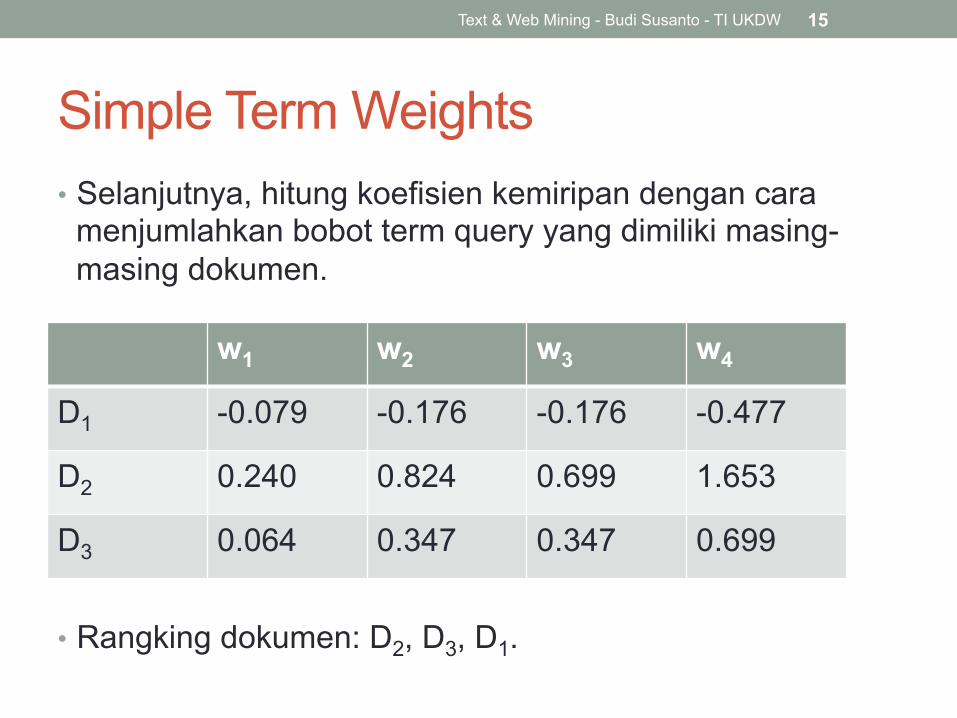
Simple Term Weights • Selanjutnya, hitung koefisien kemiripan dengan cara
menjumlahkan bobot term query yang dimiliki masing-masing dokumen.
• Rangking dokumen: D2, D3, D1.
Text & Web Mining - Budi Susanto - TI UKDW 15
w1 w2 w3 w4
D1 -0.079 -0.176 -0.176 -0.477
D2 0.240 0.824 0.699 1.653
D3 0.064 0.347 0.347 0.699

Latihan Simple Term Weight • Terdapat 3 dokumen
• D1 = Manajemen Sistem Informasi • D2 = Penggajian untuk meningkatkan Sumber Daya Manusia • D3 = Sistem Informasi Penggajian • Q = informasi daya manusia
• Tampilkan urutan dokumen yang ditampilkan dengan menggunakan strategi Simple Term Weight.
Text & Web Mining - Budi Susanto - TI UKDW 16

2. Extended Boolean • Ide dasar adalah memberikan bobot term untuk setiap
term dalam query dan untuk tiap term dalam dokumen. • Bobot-bobot term dikaitkan dengan perangkingan
dokumen. • Misal diberikan query (t1 OR t2) yang akan
mengembalikan dokumen yang berisi t1 dengan bobot w1 dan t2 dengan bobot w2.
• Jika baik w1 dan w2 adalah 1, sebuah dokumen yang berisi kedua term tersebut diberikan kemungkinan ranking paling tinggi.
• Dengan menggunakan Eucledian distance, dari titik (w1, w2) dari titik asal, kita dapat mendapatkan koefisien kemiripan.
Text & Web Mining - Budi Susanto - TI UKDW 17

Extended Boolean – 2 dimensi • Untuk sebuah dokumen berisi term t1 dan t2 dengan bobot w1 dan w2, maka koefisien kemiripan dapat dihitung sebagai:
• Nilai SC tertinggi adalah 1.414
Text & Web Mining - Budi Susanto - TI UKDW 18
sc(Q,di ) = (w1)2 + (w2 )
2

Extended Boolean – 2 dimensi • Jika t1 ∨ t2 dinormalisasikan:
• Jika t1 ∧ t2 dinormalisasikan :
Text & Web Mining - Budi Susanto - TI UKDW 19
sc(Qt1∨t2,di ) =
(w1)2 + (w2 )
2
2
sc(Qt1∧t2,di ) =1−
(1−w1)2 + (1−w2 )
2
2

Extended Boolean – p-Norm • Untuk sembarang term, m, kita mendapatkan ekspresi
yang tergantung pada parameter-p.
Text & Web Mining - Budi Susanto - TI UKDW 20

Extended Boolean – normalisasi TF-IDF • Oleh karena nilai bobot term harus bernilai [0, 1], maka
nilai bobot TF-IDF tiap term dalam dokumen harus dinormalisasikan.
• Dimana: • tfmax i,j = maksimum frekuensi term I dalam dokumen j • idfmax g = maksimum idf dari sebuah term dalam koleksi c
Text & Web Mining - Budi Susanto - TI UKDW 21

Latihan #2 • D1 = “Shipment of gold damaged in a fire” • D2 = “Delivery of silver arrived in a silver truck” • D3 = “Shipment of gold arrived in a truck”
• Q1: “gold OR silver OR truck” • Q2: “gold AND silver AND truck” • Q3: “gold OR silver AND truck”
Text & Web Mining - Budi Susanto - TI UKDW 22

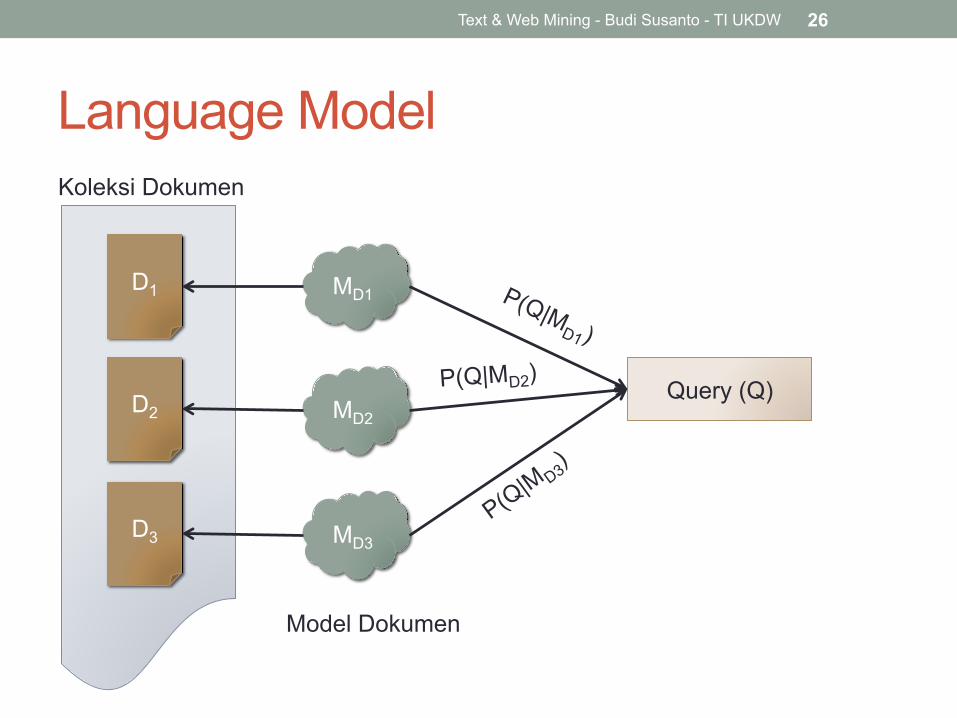
3. Query Likelihood Language Model • Statistical language model adalah sebuah mekanisme
probabilistik untuk menghasilkan sebuah deretan teks. • Language model untuk IR dimulai tahun 1998 oleh Ponte
dan Croft. • Idenya adalah dokumen dapat dirangking terhadap
kemungkinan (likelihood) dari generating query. • Koefisien kemiripan Q dan Di adalah:
• Dimana MDi adalah language model dalam dokumen Di.
Text & Web Mining - Budi Susanto - TI UKDW 23
SC(Q,Di ) = P(Q |MDi)

Language Model • Generating sebuah query memerlukan sebuah model
probabilistik untuk query. • Ponte dan Croft menghitung probabilitas query sebagai
product probabilitas baik terhadap adanya term dalam query atau tidak.
Text & Web Mining - Budi Susanto - TI UKDW 24
SC(Q,Di ) = P(t j |MDi) (1−P(t j |MDi
))t∉Q∏
t j∈Q∏

Language Model • Model p(tj|MDi) dapat diperkirakan dengan model:
• Dimana adalah perkiraan maximum likelihood dari distribusi term, yang diberikan dengan:
• Dimana dlDi adalah panjang dokumen Di.
Text & Web Mining - Budi Susanto - TI UKDW 25
p(t j |MDj) = pml (t j |MDi
)
pml (t j |MDi)
pml (t j |MDi) =
tf (t j,Di )dlDi
Language Model
Text & Web Mining - Budi Susanto - TI UKDW 26
D1
D2
D3
MD1
MD2
MD3
Query (Q) P(Q|MD2)
Model Dokumen
Koleksi Dokumen

Contoh Perkiraan Maximum Likelihood • D1 = “Shipment of gold damaged in a fire” • D2 = “Delivery of silver arrived in a silver truck” • D3 = “Shipment of gold arrived in a truck”
• Q1: “gold silver truck”
Text & Web Mining - Budi Susanto - TI UKDW 27
Pml (silver |MDi) = tf (silver,Di )
dlDi= 0

Smoothing untuk ML • Untuk menghindari masalah karena term query tidak ada
dalam dokumen, perlu diterapkan smoothing.
• dimana
Text & Web Mining - Budi Susanto - TI UKDW 28
p(t |MDi) =
pml (t,d)(1−R(t,d )) × pavg(t)
R(t,d )
cftcs
#
$%
&%
Jika tf(t,d)>0
Selain itu
pavg(t) =pml (t |MD )d (t∈d )∑dft
R(t,d ) =1.0
1.0+ ft
!
"#
$
%&×
ft1.0+ ft
!
"#
$
%&
tft ,d
ft = pavg(t)× dld

Contoh • cs = 22 token • Total jumlah token dalam tiap dokumen (dld)
• D1 = 7, D2 = 8, D3 = 7
• Jumlah dokumen dari tiap term t, dft, adalah
• Jumlah kemunculan token dalam koleksi, cft :
Text & Web Mining - Budi Susanto - TI UKDW 29
a arrived damaged delivery fire gold in of shipment silver truck
dft 3 2 1 1 1 2 3 3 2 1 2
a arrived damaged delivery fire gold in of shipment silver truck
cft 3 2 1 1 1 2 3 3 2 2 2

Contoh • Jumlah kemunculan tiap term di tiap dokumen, tft,d :
Text & Web Mining - Budi Susanto - TI UKDW 30
a arrived damaged delivery fire gold in of shipment silver truck
D1 1 0 1 0 1 1 1 1 1 0 0
D2 1 1 0 1 0 0 1 1 0 2 1
D3 1 1 0 0 0 1 1 1 1 0 1
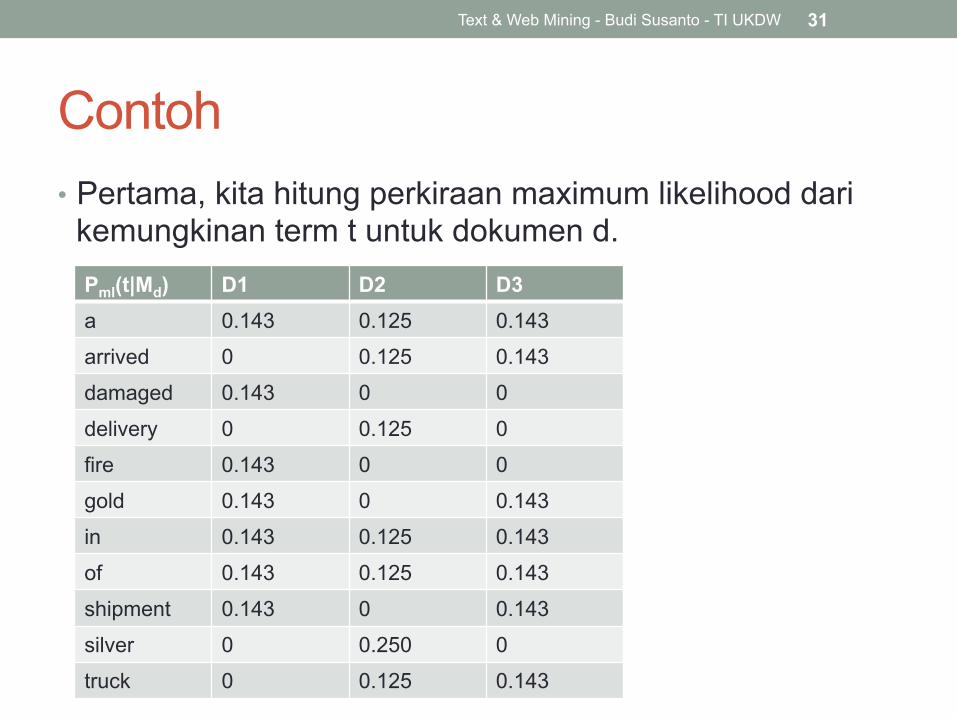
Contoh • Pertama, kita hitung perkiraan maximum likelihood dari
kemungkinan term t untuk dokumen d.
Text & Web Mining - Budi Susanto - TI UKDW 31
Pml(t|Md) D1 D2 D3 a 0.143 0.125 0.143
arrived 0 0.125 0.143
damaged 0.143 0 0
delivery 0 0.125 0
fire 0.143 0 0
gold 0.143 0 0.143
in 0.143 0.125 0.143
of 0.143 0.125 0.143
shipment 0.143 0 0.143
silver 0 0.250 0
truck 0 0.125 0.143

Contoh • Kedua, kita hitung rata-rata kemungkinan term t dalam
dokumen yang berisi term tersebut.
Text & Web Mining - Budi Susanto - TI UKDW 32
a arrived damaged delivery fire gold
Pavg(t) 0.137 0.134 0.143 0.125 0.143 0.143
in of shipment silver truck
Pavg(t) 0.137 0.137 0.143 0.250 0.134

Contoh • Ketiga, kita hitung resiko sebuah term t dalam sebuah
dokumen d. Sebelumnya kita hitung rata-rata kemunculan term dalam dokumen.
Text & Web Mining - Budi Susanto - TI UKDW 33
ft a arrived Damaged delivery fire gold
D1 0.958 0.938 1 0.875 1 1 D2 1.096 1.071 1.143 1 1.143 1.143 D3 0.958 0.938 1 0.875 1 1
ft In Of Shipment Silver truck
D1 0.958 0.958 1 1.750 0.938 D2 1.096 1.096 1.143 2 1.071 D3 0.958 0.958 1 1.750 0.938
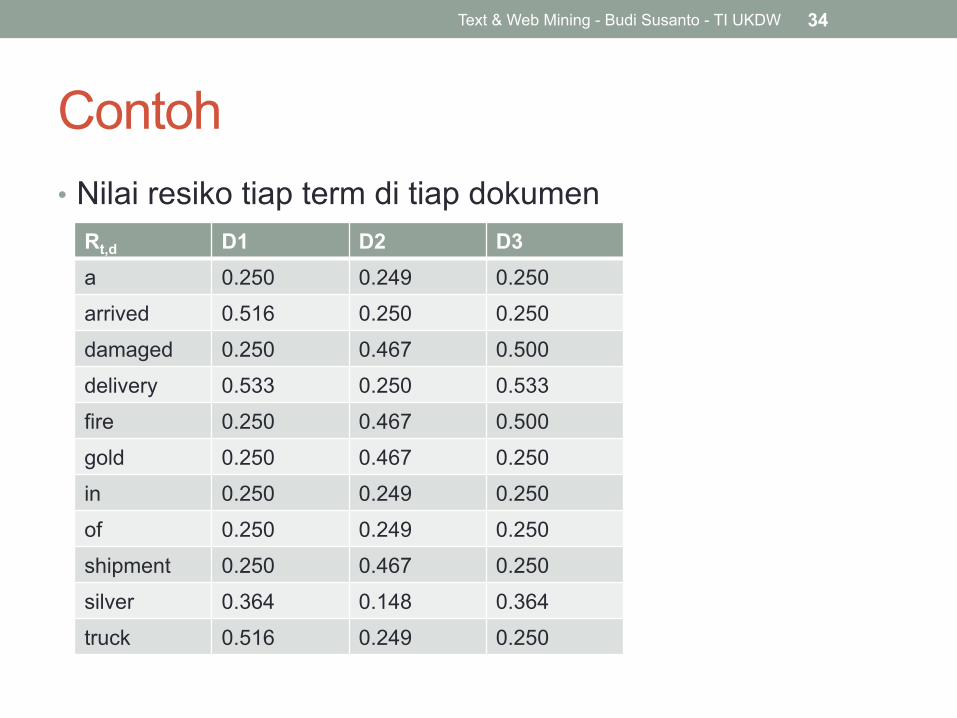
Contoh • Nilai resiko tiap term di tiap dokumen
Text & Web Mining - Budi Susanto - TI UKDW 34
Rt,d D1 D2 D3 a 0.250 0.249 0.250
arrived 0.516 0.250 0.250
damaged 0.250 0.467 0.500
delivery 0.533 0.250 0.533
fire 0.250 0.467 0.500
gold 0.250 0.467 0.250
in 0.250 0.249 0.250
of 0.250 0.249 0.250
shipment 0.250 0.467 0.250
silver 0.364 0.148 0.364
truck 0.516 0.249 0.250
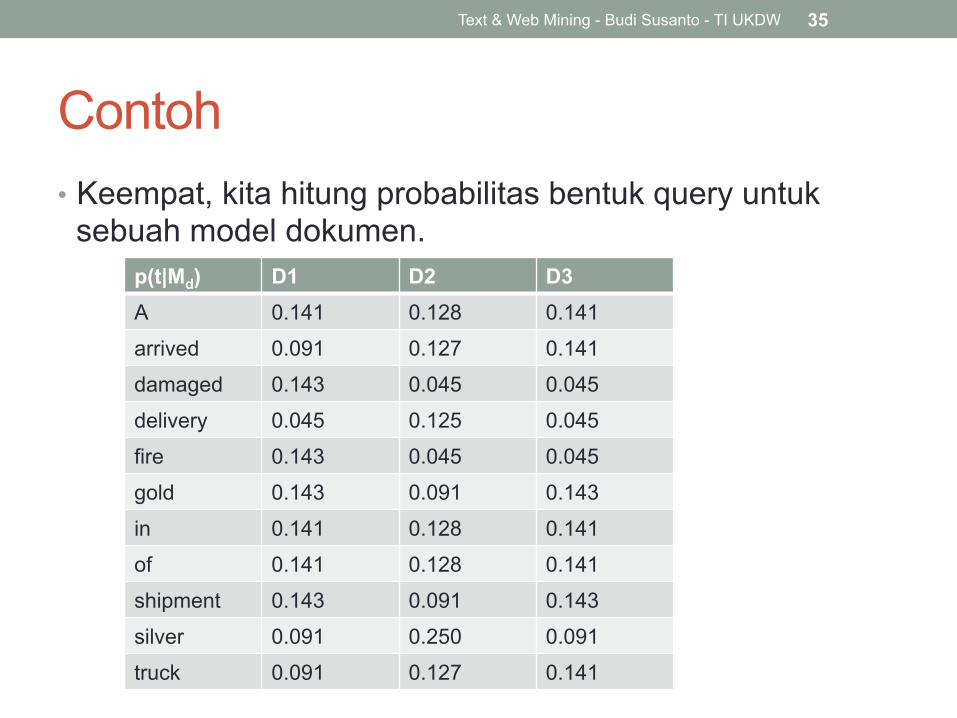
Contoh • Keempat, kita hitung probabilitas bentuk query untuk
sebuah model dokumen.
Text & Web Mining - Budi Susanto - TI UKDW 35
p(t|Md) D1 D2 D3 A 0.141 0.128 0.141
arrived 0.091 0.127 0.141
damaged 0.143 0.045 0.045
delivery 0.045 0.125 0.045
fire 0.143 0.045 0.045
gold 0.143 0.091 0.143
in 0.141 0.128 0.141
of 0.141 0.128 0.141
shipment 0.143 0.091 0.143
silver 0.091 0.250 0.091
truck 0.091 0.127 0.141

Contoh • Kelima, kita hitung kemiripan Query dengan model
dokumen.
Text & Web Mining - Budi Susanto - TI UKDW 36
D1 D2 D3
P(Q|Md) 0.000409 0.001211 0.000743

Latihan Query Likelihood • Terdapat 3 dokumen
• D1 = Manajemen Sistem Informasi • D2 = Penggajian untuk meningkatkan Sumber Daya Manusia • D3 = Sistem Informasi Penggajian • Q = informasi daya manusia
• Tampilkan urutan dokumen yang ditampilkan dengan menggunakan strategi Query Likelihood.
Text & Web Mining - Budi Susanto - TI UKDW 37

TERIMA KASIH Budi Susanto
Text & Web Mining - Budi Susanto - TI UKDW 38