modul statistik (analisis komparasi)...uji statistik yang mengarahkan pada beberapa perbandingan...
TRANSCRIPT

i
Modul Statistik
(ANALISIS KOMPARASI)
Disusun Oleh:
Ana Ramadhayanti S.I.Kom, M.M
Jakarta, 10 Mei 2017/2018

ii
KATA PENGANTAR
Sebelumnya penulis panjatkan puji syukur kehadirat Tuhan Yang Maha Esa atas
segala nikmat dan kahrunia sehingga penulis masih diberi kesempatan untuk
menyelesaikan pembuatan modul ini.
Pada Modul Statistik berikut ini pembaca akan dihadirkan mengenai beberapa
uji statistik yang mengarahkan pada beberapa perbandingan hasil uji statistic dengan
menggunakan software SPSS. Beberapa uji yang ada dalam modul ini diantaranya
adalah Analisis Komparasi, Uji T Untuk Satu Sampel, Pengambilan Keputusan
Berdasarkan Signifikansi, Uji T, Uji F, Aplikasi Spss Untuk Anova Satu Jalur, Two-
Way Anova. Dalam sub bab modul ini dilengkapi contoh kasus dan pembahasan, hal
ini bertujuan untuk menguji teori dan praktek. Dalam setiap bab dilengkapi oleh
latihan, dengan tujuan agar dapat dipraktekkan secara langsung.
Penulis menyadari bahwa masih banyak kekurangan dalam pembuatan modul ini.
Oleh karena itu penulis sangat mengharapkan kritik dan saran dari pembaca guna
penyempurnaan modul ini. Atas perhatiannya, penulis mengucapkan bnyak terima
kasih.
Jakarta, 2020
Penulis
Ana Ramadhayanti

iii
DAFTAR PUSTAKA
KATA PENGANTAR ii
DAFTAR ISI iii
BAB 1. ANALISIS KOMPARASI
Uji t Untuk Satu Sampel 1
Contoh Kasus & Pembahasan 1
Latihan Soal 6
BAB 2. Pengambilan Keputusan Berdasarkan Signifikansi 7
Uji T untuk Sampel Bebas 7
Contoh Kasus & Pembahasan 7
UJI T untuk Sampel Berpasangan 16
Contoh Kasus & Pembahasan 17
Uji F 22
Latihan Soal 25
BAB.3 Aplikasi SPSS Untuk ANOVA Satu Jalur 27
Contoh Kasus & Pembahasan 34
Latihan Soal 35
BAB.4 TWO-WAY ANOVA 37
Pengertian TWO-WAY ANOVA 38
Contoh Soal & Pembahasan 38
Latihan Soal 48
1
BAB.1
ANALISIS KOMPARASI
Uji t Untuk Satu Sampel
Uji t untuk satu sampel dalam beberapa kasus dibutuhkan untuk menjawab pertanyaan atas
penelitian yang dilakukan. Istilah lain Uji t untuk satu sampel disebut juga One Sampel T-
Test digunakan untuk menguji rata-rata sebuah sampel yang dibandingkan dengan rata-rata
populasi. Uji ini dilakukan untuk data berskala interval atau rasio.
Contoh kasus:
Seorang mahasiswa dari salah perguruan tinggi “Z” sedang melakukan penelitian di suatu
Kelurahan berhipotesis bahwa jumlah kunjungan pasien per hari rata-rata 50 orang. Untuk
membuktikan apakah hipotesis tersebut benar atau tidak, maka jumlah kunjungan per hari
selama 20 hari diteliti. Data yang diperoleh kemudian di-input sebagai berikut.
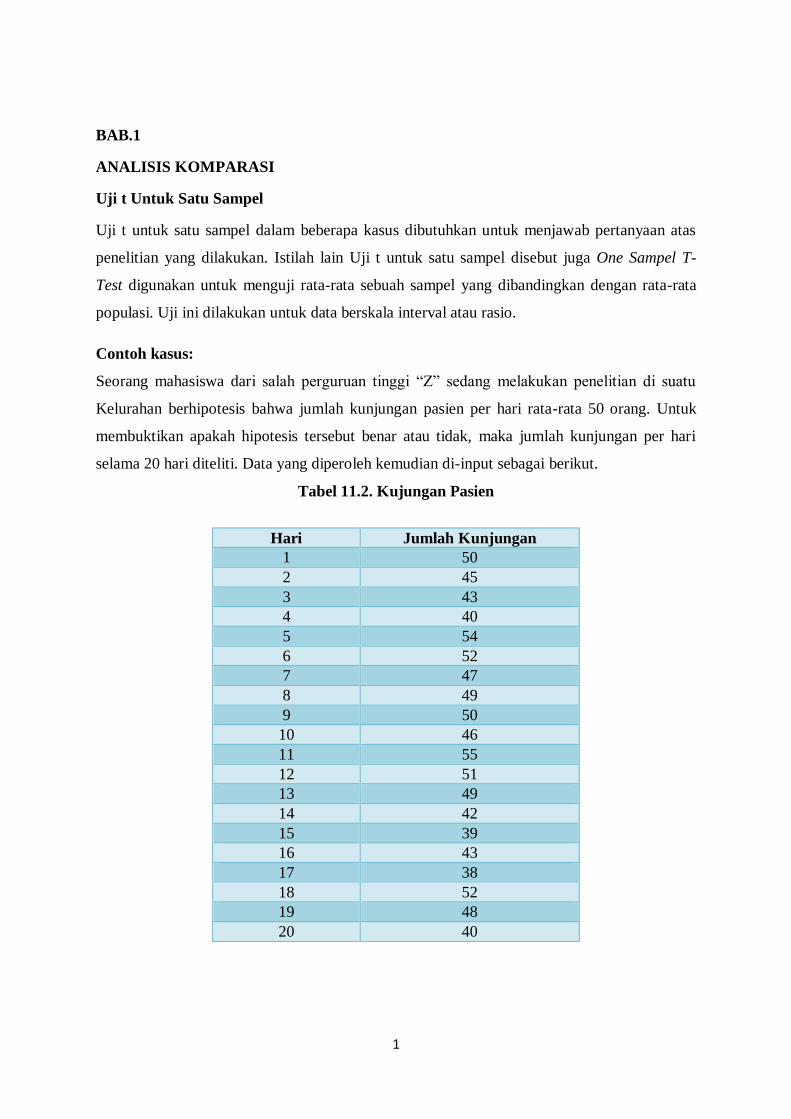
Tabel 11.2. Kujungan Pasien
Hari Jumlah Kunjungan
1 50
2 45
3 43
4 40
5 54
6 52
7 47
8 49
9 50
10 46
11 55
12 51
13 49
14 42
15 39
16 43
17 38
18 52
19 48
20 40

2
Sumber : Data Fiktif
Berikut akan dilakukan uji t satu sampel untuk mengetahui apakah jumlah kujungan di
Kelurahan rata-rata perhari 50 orang.
Langkah-langkah analisis pada SPSS adalah sebagai berikut.
1. Klik Start All programs IBM SPSS Statistiks IBM SPSS Statistiks,
berikut tampilannya.
2. Langkah selanjutnya adalah menginput data di sheet Data View. Klik Data View, lalu
isikan data jumlah kunjungan di kolom “jumlahkunjungan”. Hasil input data tampak
seperti gambar berikut ini.
3. Untuk analisis data, klik menu Analyze Compare Means One Sampel T Test,
seperti tampilan dibawah ini.

3
4. Pada kotak dialog One Sampel T-Test, klik variabel Jumlahkunjungan klik tombol
gambar tanda pertujuk. Maka variabel Jumlah kunjungan akan masuk ke kotak
Variabel. Kemudian pada Test Value, sisikan angka 50 (orang).
Setelah itu klik tombol OK. Maka akan didapat hasil ouput SPSS seperti berikut ini.
4
Hasil dan Interpretasi
T-Test
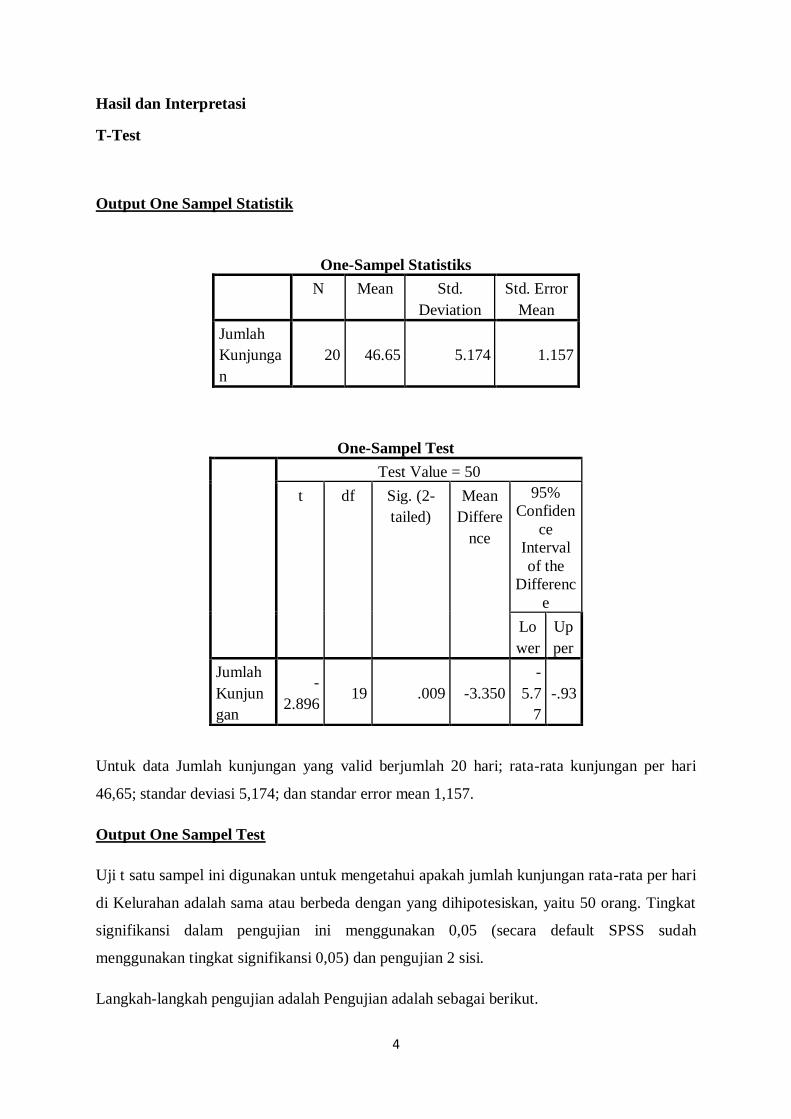
Output One Sampel Statistik
Untuk data Jumlah kunjungan yang valid berjumlah 20 hari; rata-rata kunjungan per hari
46,65; standar deviasi 5,174; dan standar error mean 1,157.
Output One Sampel Test
Uji t satu sampel ini digunakan untuk mengetahui apakah jumlah kunjungan rata-rata per hari
di Kelurahan adalah sama atau berbeda dengan yang dihipotesiskan, yaitu 50 orang. Tingkat
signifikansi dalam pengujian ini menggunakan 0,05 (secara default SPSS sudah
menggunakan tingkat signifikansi 0,05) dan pengujian 2 sisi.
Langkah-langkah pengujian adalah Pengujian adalah sebagai berikut.
One-Sampel Statistiks
N Mean Std.
Deviation
Std. Error
Mean
Jumlah
Kunjunga
n
20 46.65 5.174 1.157
One-Sampel Test
Test Value = 50
t df Sig. (2-
tailed)
Mean
Differe
nce
95%
Confiden
ce
Interval
of the
Differenc
e
Lo
wer
Up
per
Jumlah
Kunjun
gan
-
2.896 19 .009 -3.350
-
5.7
7
-.93

5
1. Merumuskan hipotesis
H0 : Rata-Rata Jumlah Kunjungan Perhari Adalah 50 Orang
Ha : Rata-rata jumlah kunjungan per hari adalah bukan 50 orang
2. Menentukan t hitung
Dari tabel di atas didapat nilai t hitung adalah -2,896
3. Menentukan t tabel
T tabel dapat dilihat pada tabel statistik pada signifikansi 0,05 : 2= 0,025 (uji 2 sisi)
dengan derajat kebebasan (df) n-1 atau 20-1 = 19 dan hasil diperoleh t tabel sebesar
2,093 (Lihat pada tabel t di bawah ini).
Tabel T
4. Kriteria Pengujian
jika nilai -t tabel ≤ t hitung ≤ t tabel maka H0 diterima
jika nilai -t hitung < - t tabel atau t hitung > t tabel maka H0 ditolak

6
Untuk nilai t hitung yang hasilnya positif maka dapat digunakan ketentuan sebagai
berikut:
H0 diterima dan H1 ditolak jika nilai t hitung < t tabel atau jika nilai Sig. > 0,05
H0 ditolak dan H1 diterima jika nilai t hitung > t tabel atau jika nilai Sig. < 0,05
5. Membuat kesimpulan
Nilai –t hitung <-t tabel (-2,896<-2,093) maka H0 ditolak dan H1 diterima. Jadi dapat
disimpulkan bahwa rata-rata jumlah kunjungan per hari di Kelurahan adalah bukan 50
orang. Dari rata-rata dapat diketahui bahwa jumlah kunjungan rata-rata adalah 46 orang
per hari.
Latihan:
Sauatu Dinas Staf Puskesmas ingin mengetahui, jumlah pengunjung Puskesmas. sedang
dengan berhipotesis bahwa jumlah kunjungan pasien per hari rata-rata 50 orang. Untuk
membuktikan apakah hipotesis tersebut benar atau tidak, silahkan Anda buktikan dengan data
berikut ini.
Hari Jumlah Kunjungan
1 40
2 55
3 43
4 40
5 53
6 52
7 47
8 50
9 50
10 46
11 55
12 51
13 49
14 42
15 39
16 43
17 38
18 52
19 59
20 40

7
BAB.2.
Pengambilan Keputusan Berdasarkan Signifikansi
Jika berdasarkan signifikansi maka jika signifikasi < 0,05 maka H0 ditolak, dan jika
signifikasni > 0,05 maka H0 diterima. Karena signifikansi (0,009<0,05) maka H0 ditolak.
Artinya bahwa rata-rata jumlah kunjungan perhari di Kelurahan adalah bukan 50 orang.
Uji T untuk Sampel Bebas
Pengujian Uji t untuk sampel bebas atau Independent Sampels T Test biasa dilakukan untuk
menguji rata-rata antara dua kelompok data yang independen.
Contoh kasus:
Seorang mahasiswa ingin mengetahui perbedaan kemampaun rasa kepekaan menghadapi
masalah antara laki-laki dan perempuan di suatu Universitas “Y”. Dalam penelitian ini
sampel yang digunakan sebanyak 20 orang yang terdiri dari 10 orang laki-laki dan 10 orang
Perempuan. Pengambilan data dilakukan menggunakan kueioner yang dibagikan kepada
responden. Data skor total item yang diperoleh ditabulasikan sebagai berikut.
Tabel 11.3. Kemampuan Rasa Kepekaan
Subjek Kepekaan Jenis Kelamin
1 75 2
2 60 1
3 64 1
4 76 2
5 61 1
6 58 1
7 73 2
8 58 1
9 66 2
10 70 2
11 64 2
12 55 1
13 71 1
14 65 2
15 67 2
16 58 2
17 67 1
8
Sumber : Data Fiktif
Keterangan:
Jenis kelamin:
Laki-laki : 1
Perempuan : 2
Berikut akan dilakukan uji t dua sampel bebas untuk mengetahui apakah ada perbedaan rasa
kepekaan antara laki-laki dan perempuan.
Langkah-langkah analisis pada SPSS adalah sebagai berikut:
1. Menginput data di sheet Data View. Klik Data View, lalu isi data Kepekaan
menghadapi masalah di kolom ”Kepekaan” dan data Jenis kelamin di kolom “Jenis
Kelamin”. Hasil penginputan data tampak seperti gambar berikut ini.
18 75 2
19 66 1
20 72 1
9
2. Berikutnya, beri nama variabel dengan jelas di kolom label, misalnya Jenis Kelamin.
Klik kotak kecil berwarna abu-abu di kolom Value dan akan muncul kotak Value
Labels. Isikan angka 1 di kotak Value dan isikan label laki-laki dikotak Label.
Kemudian, klik Add. Selanjutnya isikan angka 2 untuk label Perempuan seperti yang
terlihat dalam tampilan berikut.

10
Keterangan:
Jenis kelamin:
Laki-laki : 1
Perempuan : 2
3. Untuk analisis data, klik menu Analyze Compare Means Independent
Sampels T Test, seperti pada tampilan dibawah ini.
4. Pada kotak dialog Independent Sampel T Test, lakukan langkah-langkah sebagai
berikut.
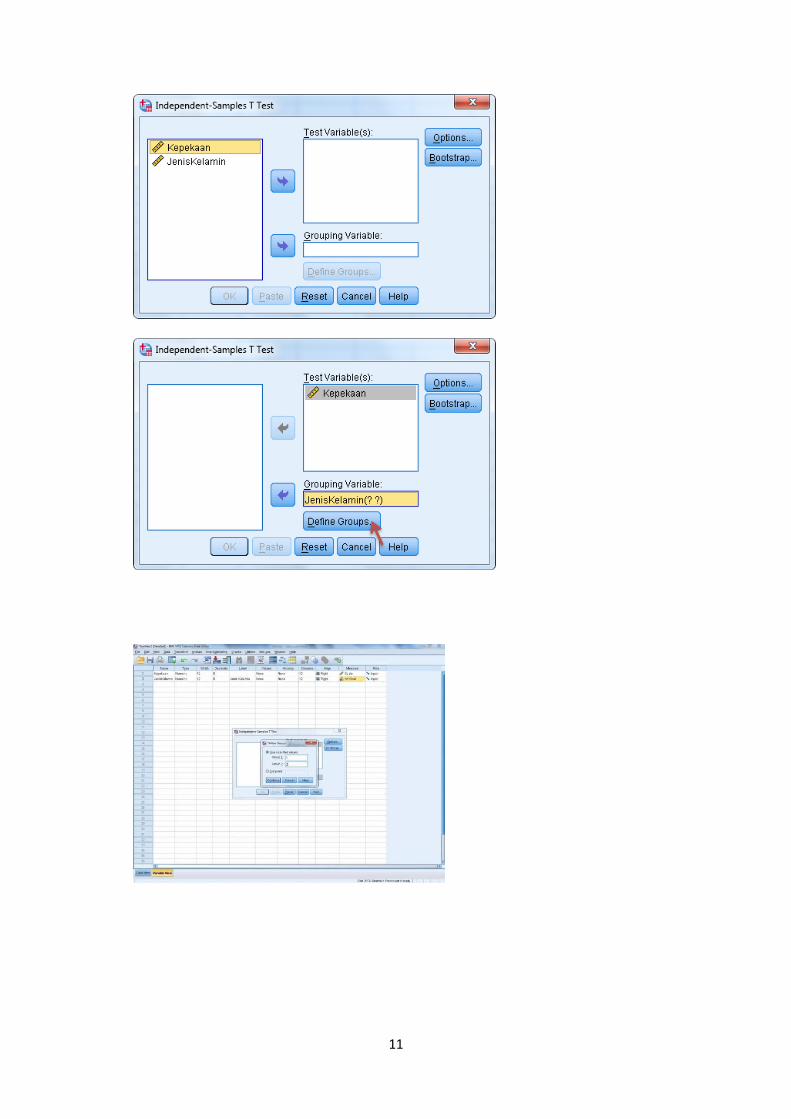
Klik variabel Rasa Kepekaan menghadapi masalah tombol gambar tanda penujuk
disebelah kotak Test Variabels (s). Maka variabel akan masuk ke kotak Test
Variabels(s).
Klik variabel Jenis Kelamin tombol gambar tanda penunjuk disebelah kotak
Grouping Variabel. Maka variabel akan masuk ke kotak Grouping Variabel.
11
12
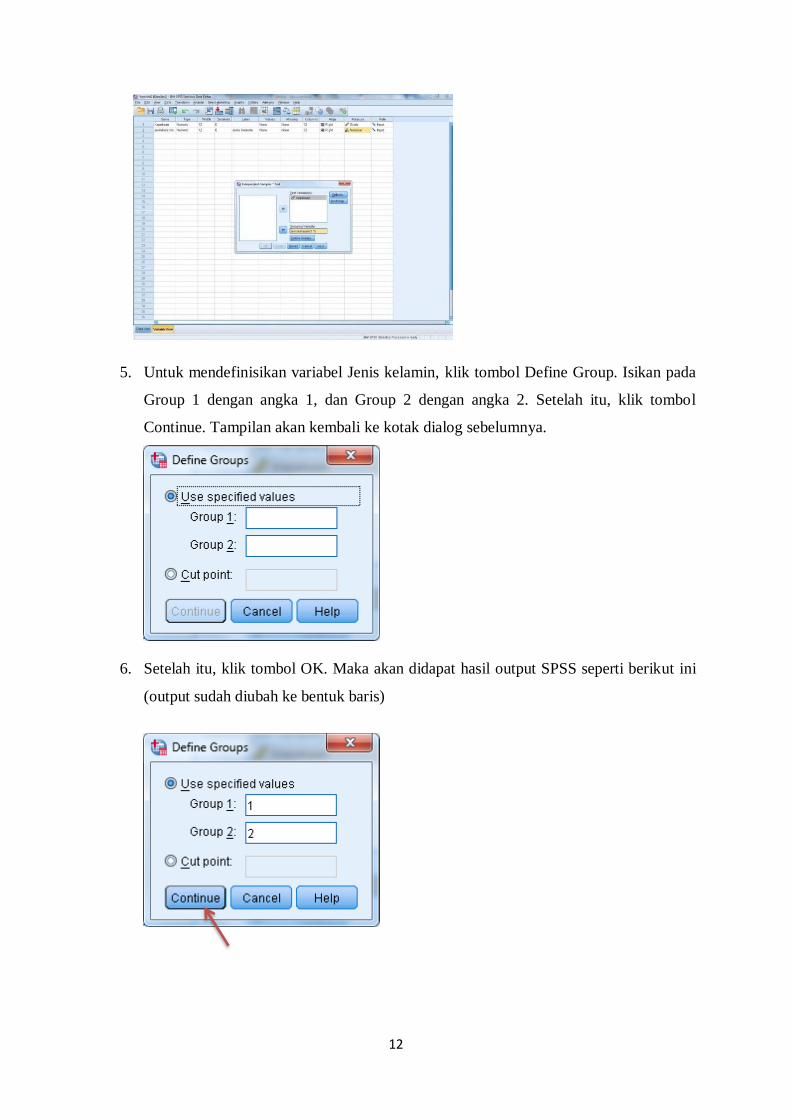
5. Untuk mendefinisikan variabel Jenis kelamin, klik tombol Define Group. Isikan pada
Group 1 dengan angka 1, dan Group 2 dengan angka 2. Setelah itu, klik tombol
Continue. Tampilan akan kembali ke kotak dialog sebelumnya.
6. Setelah itu, klik tombol OK. Maka akan didapat hasil output SPSS seperti berikut ini
(output sudah diubah ke bentuk baris)
13
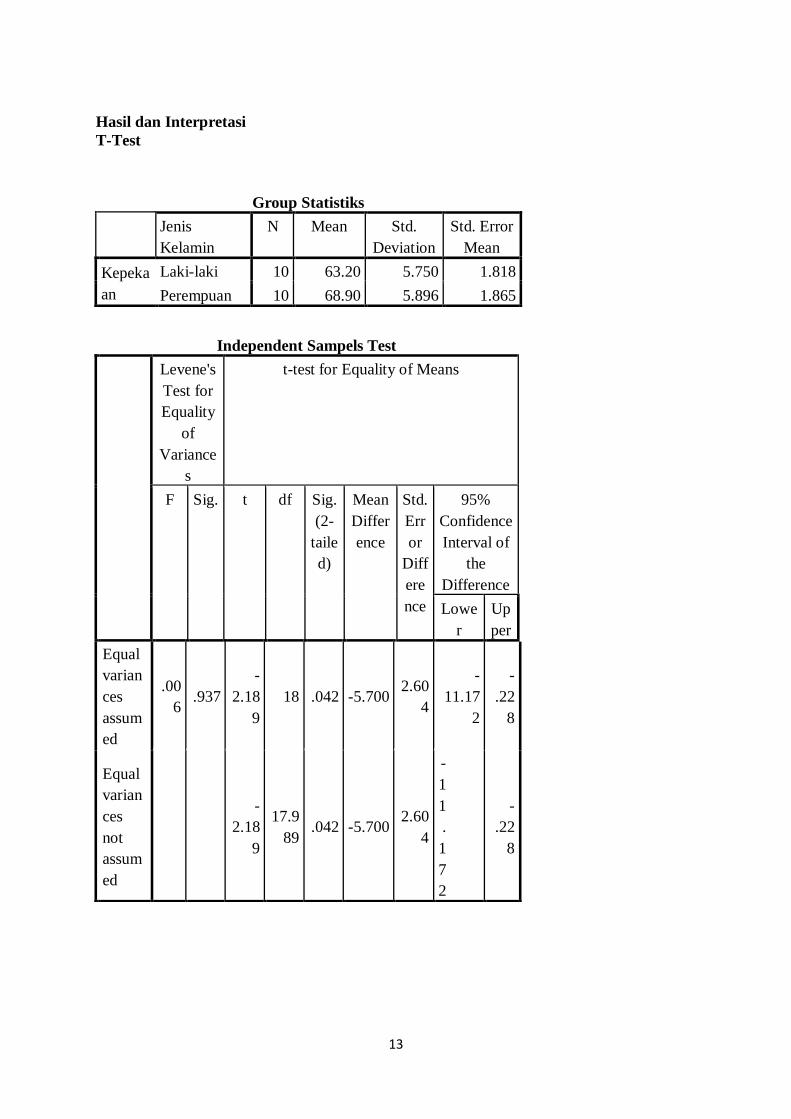
Hasil dan Interpretasi
T-Test
Group Statistiks
Jenis
Kelamin
N Mean Std.
Deviation
Std. Error
Mean
Kepeka
an
Laki-laki 10 63.20 5.750 1.818
Perempuan 10 68.90 5.896 1.865
Independent Sampels Test
Levene's
Test for
Equality
of
Variance
s
t-test for Equality of Means
F Sig. t df Sig.
(2-
taile
d)
Mean
Differ
ence
Std.
Err
or
Diff
ere
nce
95%
Confidence
Interval of
the
Difference
Lowe
r
Up
per
K
e
p
e
k
a
a
n
Equal
varian
ces
assum
ed
.00
6 .937
-
2.18
9
18 .042 -5.700 2.60
4
-
11.17
2
-
.22
8
Equal
varian
ces
not
assum
ed
-
2.18
9
17.9
89 .042 -5.700
2.60
4
-
1
1
.
1
7
2
-
.22
8

14
Interpretasi dari output SPSS adalah sebagai berikut:
Untuk data Kepekaan menghadapi masalah pada jenis kelamin laki-laki berjumlah 10, dan
untuk perempuan berjumlah 10. Rata-rata Kepekaan untuk laki-laki adalah 63,20, sedangkan
perempuan 68,90. Standar deviasi nilai kepekaan pada laki-laki 5,750 dan untuk perempuan
5,896. Standar error mean nilai kepekaan untuk laki-laki 1,818 dan untuk perempuan 1,865.
Output Independent Sampels Test
Output ini menjelaskan hasil uji t sampel bebas. Pengujuan menggunakan tingkat
signifikansi 0,05 (secara default SPSS sudah menggunakan tingkat signifikansi 0,05) dan uji
2 sisi.
Sebelum uji t sampel bebas dilakukan, uji F (uji homogenitas/uji Levene’s) dilakukan
terlebih dahulu. Artinya, jika varian sama maka uji t menggunakan nilai ‘Equal Variance
Assumed’ (diasumsikan varian sama) dan jika varian berbeda menggunakan nilai “Equal
Variance Not assumed” (diasumsikan varian berbeda).
Langkah-langkah uji homogenmitas adalah sebagai berikut
1. Merumuskan Hipotesis
H0 : Kelompok data kepekaan menghadapi masalah antara laki-laki dan perempuan
memiliki varian yang sama
Ha : Kelompok data kepekaan menghadapi masalah antara laki-laki dan
perempuan memiliki varian yang berbeda.
2. Kriteria Pengujian (berdsarkan Signifikansi)
Jika Signufikansi > 0,05 maka H0 diterima
Jika Signifikansi < 005 maka H0 ditolak
3. Membuat kesimpulan
Signifikansi dari uji F didapat 0,415. Dengan demikian, Signifikansi > 0,05 (0,937>0,05)
maka H0 diterima. Jadi dapat disismpulakn bahwa kelompok data kepekaan menghadapi

15
masalah antara laki-laki dan perempuan memiliki varian yang sama. Uji t (Independent
Sampels T Test) menggunakan yang nilai ‘Equal variance assumed’.
Langkah-langkah uji t sampel bebas (Independent Sampels T test) adalah sebagai
berikut.
1. Merumuskan hipotesis
H0 : Tidak ada perbedaan rata-rata kepekaan menghadapi masalah antara laki-
laki dan perempuan.
Ha : Ada perbedaan rata-rata kepekaan menghadapi masalah antara laki-laki
dan perempuan.
2. Menentukan t hitung
3. Dari output fidapt nilai t hitung (Equal variance assumed) adalah -2,189
4. Menentukan t tabel
5. T atabel dapat dilihat pada tabel statistik pada signifikansi 0,05 : 2 = 0,025 (uji 2 sisi)
dengan derajat kebebasan (df)n-2 atau 20-2= 18, hasil diperoleh untuk t tabel sebesar
2,101 (Lihat pada tabel t dibawah ini).
6. Kriteria Pengujian
Jika –t tabel ≤ t hitung ≤ t tabel maka Ho diterima
Jika –t hitung < -t tabel atau t hitung > t tabel maka H0 ditolak.
7. Membuat kesimpulan
Nilai –t hitung < -t tabel (-2,189<2,101) maka H0 ditolak. Jika dapat dismpulkan
bahwa ada perbedaan rata-rata kepekaan menghadapi masalah antara laki-laki dan
perempuan. Dari rata-rata dapat dilihat bahwa laki-laki memiliki kepekaan yang
lebih tinggi dari perempuan.

16
Tabel t
UJI T untuk Sampel Berpasangan
Pengujian untuk Uji t untuk sampel berpasangan atau dengan istilah lain Paired
Sampels T Test digunakan untuk mengetahui perbedaan rata-rata diantara dua sampel yang
berpasangan. Sampel yang berpasangan merupakan kelompok sampel yang memilki subjek
yang sama namun mengalami dua pengukuran yang berbeda, contoh perlakuan sebelum dan
sesudah.
Contoh kasus:
Dalam menghadapi persiapan Ujian Tri Out Murid di salah satu sekolah menengah pertama
mengadakan Pendalaman Materi. Dari hasil Pendalaman Materi tersebut didapatkan nilai
peningkatan nilai dari para siswa.Sampel yang digunakan sebanyak 15 orang siswa yang
diukur dari peningkat nilai yang diperoleh. Adapun data yang didapatkan sebagai berikut.
17
Tabel 11.4. Pendalaman Materi
Sumber : Data Fiktif
Berikut ini akan dilakukan uji t sampel berpasangan untuk mengetahui apakah ada
perbedaan nilai antara sebelum dan sesudah pendalaman materi.
Langkah-langkah analisis pada SPSS adalah sebagai berikut.
1. Buka Programs SPSS Pilih File Open Data
Subjek Sebelum
Pendalaman Materi
Setelah Pendalam
Materi
1 65 75
2 70 82
3 75 90
4 63 70
5 56 70
6 80 90
7 77 80
8 74 91
9 88 90
10 60 75
11 55 70
12 81 90
13 66 70
14 81 88
15 73 85
18
Jika muncul Opening Excel Data Source
2. Selanjutnya Klik menu Analyze Compare Means Paired Sampels T Test
3. Pada kotak dialog Paired Sampels T Test, lakukan langkah-langkah berikut.
19
Klik Variabel Sebelum pendalam materi Klik tombol gambar tanda penunjuk.
Kemudian Klik variabel Setelah Pendalam Materi klik tombol gambar tanda
penunjuk. Variabel akan masuk ke kotak Paired Variabels.
4. Selanjutnya klik tombol OK maka akan didapat hasil output SPSS seperti berikut.
Hasil dan Interpretasi
T-Test
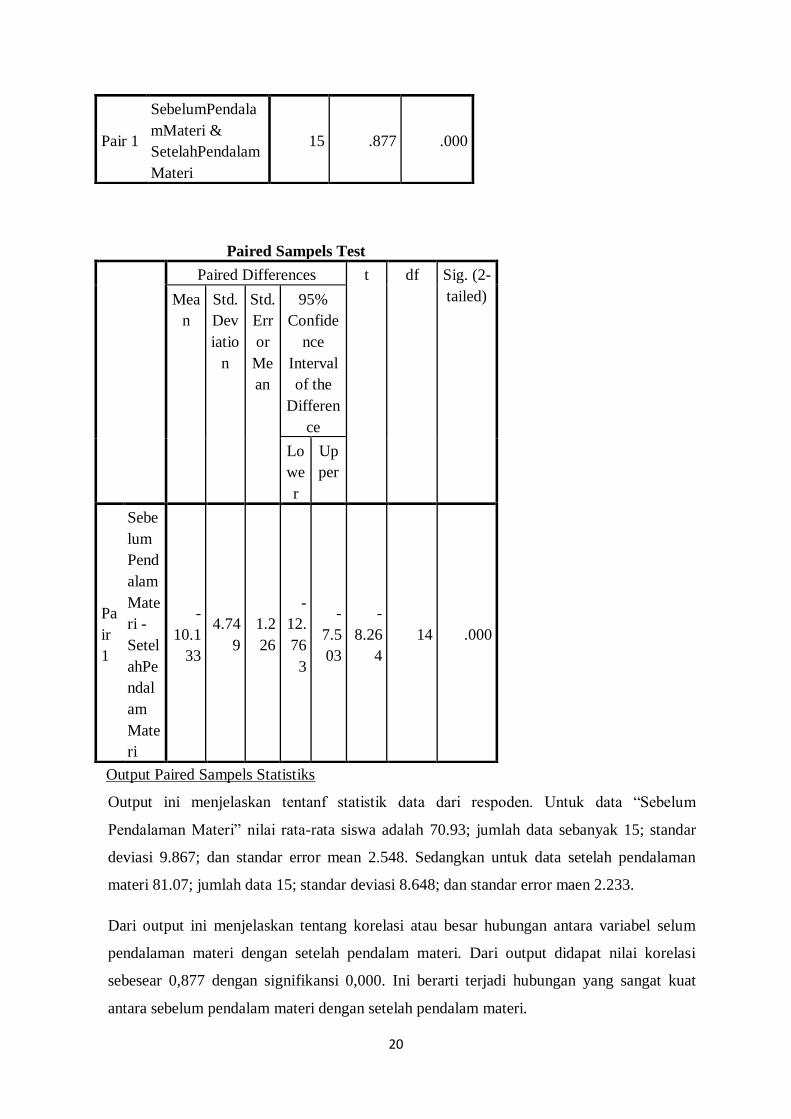
Paired Sampels Statistiks
Mean N Std.
Deviatio
n
Std.
Error
Mean
Pair
1
SebelumPen
dalamMateri 70.93 15 9.867 2.548
SetelahPend
alamMateri 81.07 15 8.648 2.233
Paired Sampels Correlations
N Correlati
on
Sig.
20
Output Paired Sampels Statistiks
Output ini menjelaskan tentanf statistik data dari respoden. Untuk data “Sebelum
Pendalaman Materi” nilai rata-rata siswa adalah 70.93; jumlah data sebanyak 15; standar
deviasi 9.867; dan standar error mean 2.548. Sedangkan untuk data setelah pendalaman
materi 81.07; jumlah data 15; standar deviasi 8.648; dan standar error maen 2.233.
Dari output ini menjelaskan tentang korelasi atau besar hubungan antara variabel selum
pendalaman materi dengan setelah pendalam materi. Dari output didapat nilai korelasi
sebesear 0,877 dengan signifikansi 0,000. Ini berarti terjadi hubungan yang sangat kuat
antara sebelum pendalam materi dengan setelah pendalam materi.
Pair 1
SebelumPendala
mMateri &
SetelahPendalam
Materi
15 .877 .000
Paired Sampels Test
Paired Differences t df Sig. (2-
tailed) Mea
n
Std.
Dev
iatio
n
Std.
Err
or
Me
an
95%
Confide
nce
Interval
of the
Differen
ce
Lo
we
r
Up
per
Pa
ir
1
Sebe
lum
Pend
alam
Mate
ri -
Setel
ahPe
ndal
am
Mate
ri
-
10.1
33
4.74
9
1.2
26
-
12.
76
3
-
7.5
03
-
8.26
4
14 .000

21
Output ini menjelaskan tentang hasil uji t sampel berpasangan. Pengujian menggunakan
tingkat signifikansi 0,05 (secara default SPSS sudah menggunakan tingkat signifikansi
0,05) dan uji 2 sisi.
Langkah-langkah pengujian adalah sebagai berikut.
1. Merumuskan hipotesis
H0 : Tidak ada perbedaan nilai antara sebelum dan sesudah pendalam materi.
Ha :Ada perbedaan berat badan antara sebelum dan sesudah pendalam materi.
2. Menentukan t hitung
Dari output dikethui t hitung adalah -8.264.
Menentukan t tabel
T tabel dapat dilihat pada tabel statistik pada signifikansi 0,05 : 2 = 0,025 (uji 2 sisi)
dengan derajat kebebasan (df) n-1 atau 15-1= 14, hasil diperoleh untuk t tabel sebesar
2,145/-2,145. Lihat tabel t dibawah ini.
Kriteria Pengujian

22
Jika –t tabel ≤ t hitung ≤ t tabel maka H0 diterima, jika –t hitung < -t tabel atau t hitung > t
tabel maka H0 ditolak
Berdasarkan Signifikansi:
Jika Signifikansi > 0,05 maka H0 diterima
Jika Signifikansi < 0,05 maka H0 ditolak.
Membuat kesimpulan
Nilai –t hitung < -t tabel (-8.264 < -2,145) maka H0 ditolak. Jadi dapat disimpulkan bahwa
ada perbedaan antara siswa sebelum diberi Pendalaman Materi dengan siswa setelah
pendalam materi. Dari rata-rata (mean) dapat diketahui bahwa rata-rata siswa sebelum dan
setelah diberi pelatihan materi lebih tinggi dari pada sebelum pendalam materi. Hal ini dapat
disimpulkan bahwa pendalaman materi dapat meningkatkan nilai siswa.
Uji F
Uji F disebut juga dengan uji koefisien regresi secara serentak atau bersama-sama, yaitu
untuk mengetahui pengaruh variabel independen secara serentak atau bersama-sama
terhadap pengaruh variabel dependen. Uji F ini sangat penting dilakukan terlebih untuk
mengetahui pengaruh atau hubungan antara variabel X dan Y. Dari uji F ini akan diketahui
apakah pengaruhnya signifikan atau tidak.
Rumusnya mencari F tabel adalah sebagai berikut:
df1 = k -1
df2 = n – k
Dimana :
k : adalah jumlah variabel (bebas + terikat)
n : adalah jumlah observasi/sampel pembentuk
23
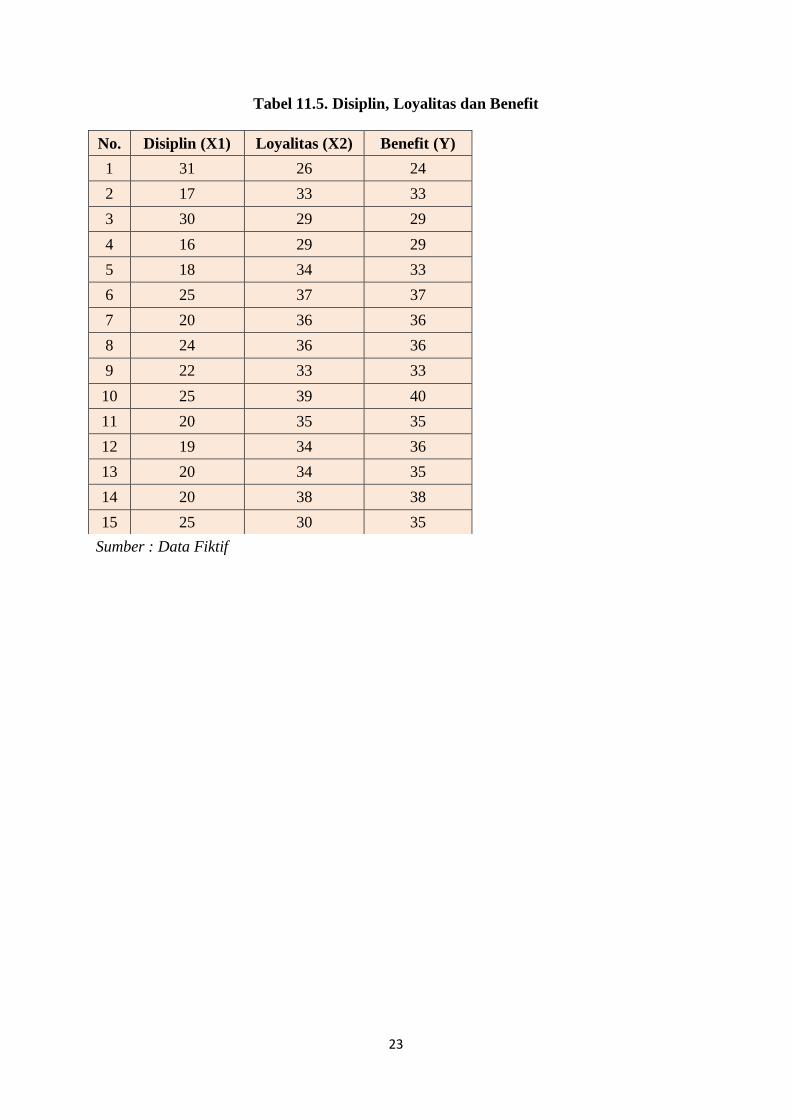
Tabel 11.5. Disiplin, Loyalitas dan Benefit
Sumber : Data Fiktif
No. Disiplin (X1) Loyalitas (X2) Benefit (Y)
1 31 26 24
2 17 33 33
3 30 29 29
4 16 29 29
5 18 34 33
6 25 37 37
7 20 36 36
8 24 36 36
9 22 33 33
10 25 39 40
11 20 35 35
12 19 34 36
13 20 34 35
14 20 38 38
15 25 30 35
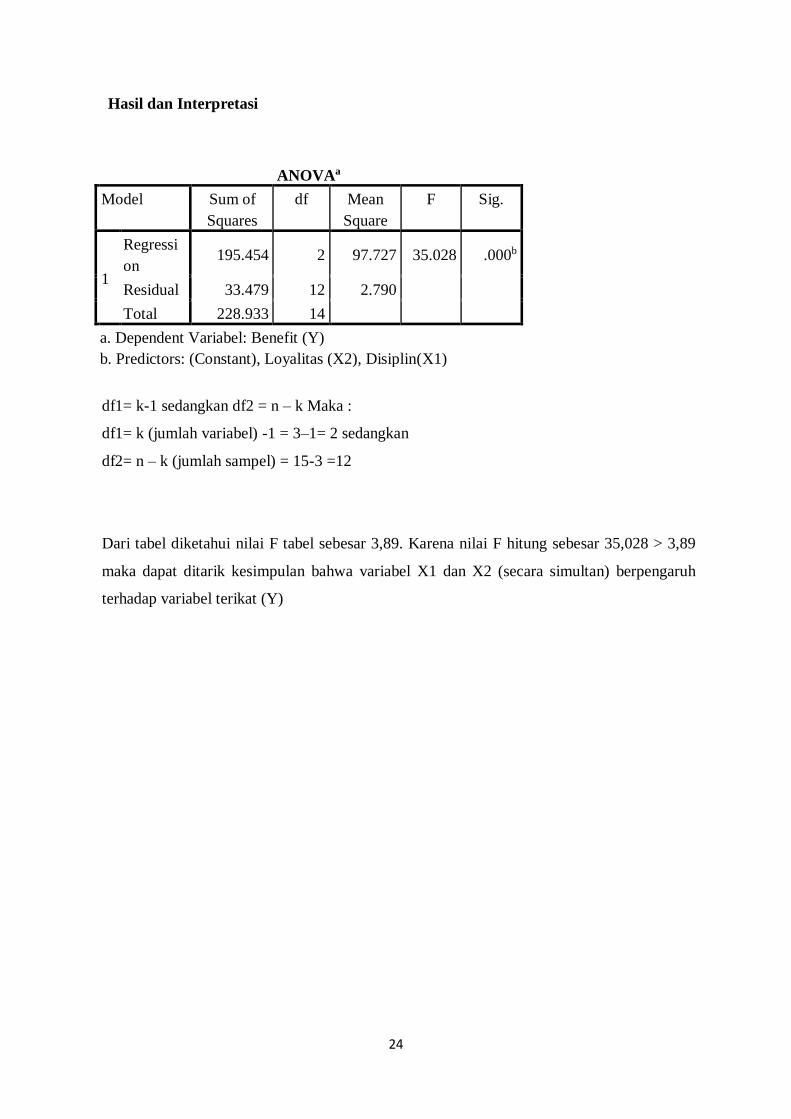
24
Hasil dan Interpretasi
df1= k-1 sedangkan df2 = n – k Maka :
df1= k (jumlah variabel) -1 = 3–1= 2 sedangkan
df2= n – k (jumlah sampel) = 15-3 =12
Dari tabel diketahui nilai F tabel sebesar 3,89. Karena nilai F hitung sebesar 35,028 > 3,89
maka dapat ditarik kesimpulan bahwa variabel X1 dan X2 (secara simultan) berpengaruh
terhadap variabel terikat (Y)
ANOVAa
Model Sum of
Squares
df Mean
Square
F Sig.
1
Regressi
on 195.454 2 97.727 35.028 .000b
Residual 33.479 12 2.790
Total 228.933 14
a. Dependent Variabel: Benefit (Y)
b. Predictors: (Constant), Loyalitas (X2), Disiplin(X1)

25
Latihan
Seorang Master Chef Ingin mengetahui perbandingan rasa masakan antara antara koki
Wanita dengan Koki Laki-Laki. Perbandingan ini pada dasarnya untuk mengetahui dan
menjadi masukan dalam hal kepuasan layanan pembeli.
Titik Persentase Distribusi F untuk
Probabilita = 0,05
df
untu
k
penye
but
(N2)
df untuk pembilang
(N1)
1 2 3 4 5 6 7 8 9 1
0
1
1
12
1 16
1
19
9
21
6
22
5
23
0
23
4
23
7
23
9
24
1
24
2
24
3
24
4 2 18.
51
19.
00
19.
16
19.
25
19.
30
19.
33
19.
35
19.
37
19.
38
19.
40
19.
40
19.
41 3 10.
13
9.5
5
9.2
8
9.1
2
9.0
1
8.9
4
8.8
9
8.85 8.8
1
8.7
9
8.7
6
8.7
4 4 7.7
1
6.9
4
6.5
9
6.3
9
6.2
6
6.1
6
6.0
9
6.04 6.0
0
5.9
6
5.9
4
5.9
1 5 6.6
1
5.7
9
5.4
1
5.1
9
5.0
5
4.9
5
4.8
8
4.82 4.7
7
4.7
4
4.7
0
4.6
8 6 5.9
9
5.1
4
4.7
6
4.5
3
4.3
9
4.2
8
4.2
1
4.15 4.1
0
4.0
6
4.0
3
4.0
0 7 5.5
9
4.7
4
4.3
5
4.1
2
3.9
7
3.8
7
3.7
9
3.73 3.6
8
3.6
4
3.6
0
3.5
7 8 5.3
2
4.4
6
4.0
7
3.8
4
3.6
9
3.5
8
3.5
0
3.44 3.3
9
3.3
5
3.3
1
3.2
8 9 5.1
2
4.2
6
3.8
6
3.6
3
3.4
8
3.3
7
3.2
9
3.23 3.1
8
3.1
4
3.1
0
3.0
7 10 4.9
6
4.1
0
3.7
1
3.4
8
3.3
3
3.2
2
3.1
4
3.07 3.0
2
2.9
8
2.9
4
2.9
1 11 4.8
4
3.9
8
3.5
9
3.3
6
3.2
0
3.0
9
3.0
1
2.95 2.9
0
2.8
5
2.8
2
2.7
9 12 4.7
5
3.8
9
3.4
9
3.2
6
3.1
1
3.0
0
2.9
1
2.85 2.8
0
2.7
5
2.7
2
2.6
9 13 4.6
7
3.8
1
3.4
1
3.1
8
3.0
3
2.9
2
2.8
3
2.77 2.7
1
2.6
7
2.6
3
2.6
0 14 4.6
0
3.7
4
3.3
4
3.1
1
2.9
6
2.8
5
2.7
6
2.70 2.6
5
2.6
0
2.5
7
2.5
3 15 4.5
4
3.6
8
3.2
9
3.0
6
2.9
0
2.7
9
2.7
1
2.64 2.5
9
2.5
4
2.5
1
2.4
8 16 4.4
9
3.6
3
3.2
4
3.0
1
2.8
5
2.7
4
2.6
6
2.59 2.5
4
2.4
9
2.4
6
2.4
2 17 4.4
5
3.5
9
3.2
0
2.9
6
2.8
1
2.7
0
2.6
1
2.55 2.4
9
2.4
5
2.4
1
2.3
8 18 4.4
1
3.5
5
3.1
6
2.9
3
2.7
7
2.6
6
2.5
8
2.51 2.4
6
2.4
1
2.3
7
2.3
4 19 4.3
8
3.5
2
3.1
3
2.9
0
2.7
4
2.6
3
2.5
4
2.48 2.4
2
2.3
8
2.3
4
2.3
1 20 4.3
5
3.4
9
3.1
0
2.8
7
2.7
1
2.6
0
2.5
1
2.45 2.3
9
2.3
5
2.3
1
2.2
8
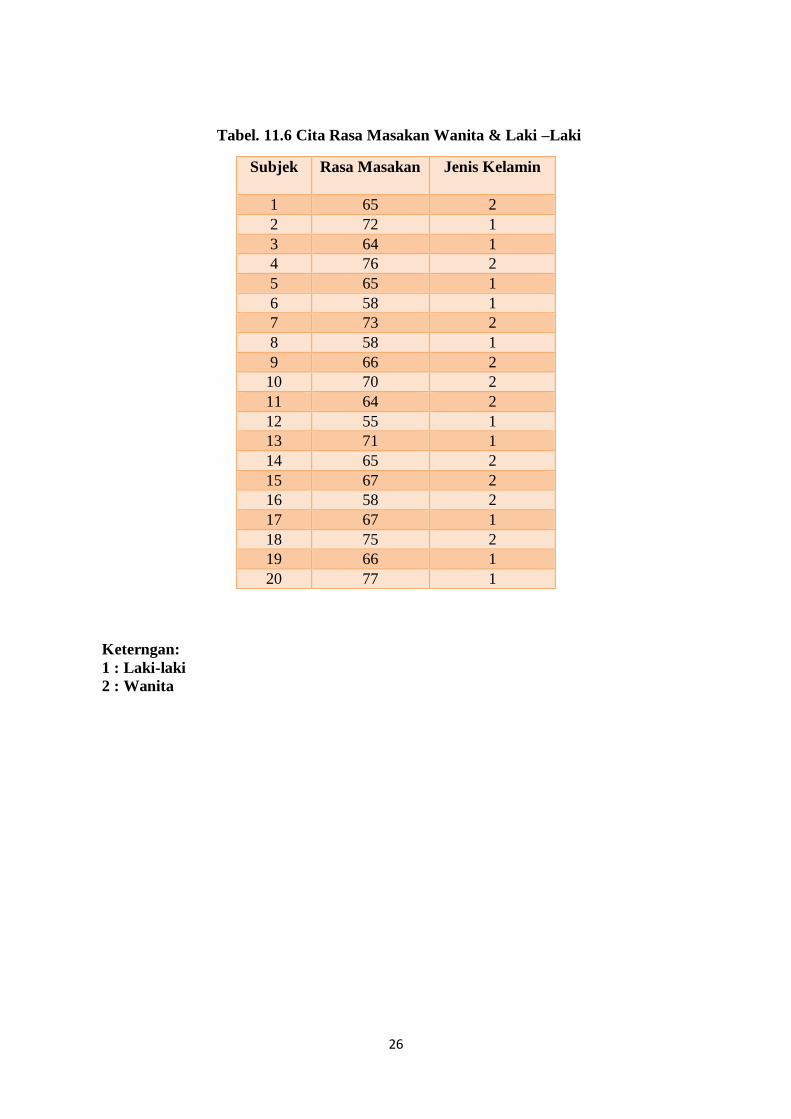
26
Tabel. 11.6 Cita Rasa Masakan Wanita & Laki –Laki
Keterngan:
1 : Laki-laki
2 : Wanita
Subjek Rasa Masakan Jenis Kelamin
1 65 2
2 72 1
3 64 1
4 76 2
5 65 1
6 58 1
7 73 2
8 58 1
9 66 2
10 70 2
11 64 2
12 55 1
13 71 1
14 65 2
15 67 2
16 58 2
17 67 1
18 75 2
19 66 1
20 77 1
27
BAB.3
Aplikasi SPSS Untuk ANOVA Satu Jalur
Analisis One Way ANOVA digunakan untuk menguji perbedaan diantara dua atau lebih
kelompok dimana hanya terdapat satu faktor yang dipertimbangkan.
Contoh Kasus:
Sebuah perusahaan “Z” yang bergerak dalam produksi makanan ringan chiki ingin
mengeluarkan produk chiki terbaru. Untuk mengetahui cita rasa yang dinginkan oleh
konsumen perusahaan tersebut mengambil tiga sampel Kelurahan di Jakarta Utara seperti
kelurahan “Koja”, “Cilincing” dan “Rawabadak”. Masing-masing kelurahan tersebut
memberikan penilaian terhadap cita rasa chiki baru.
Tabel 11.6. Cita Rasa Produk
No Kelurahan Penilaian
1 1 70
2 1 70
3 1 85
4 1 90
5 1 78
6 1 65
7 1 93
8 2 88
9 2 71
10 2 75
11 2 70
12 2 80
13 2 85
14 2 65
15 3 60
16 3 90
17 3 80
18 3 90
19 3 85
20 3 75
21 3 88

28
Sumber : Data Fiktif
Keterangan : 1 = Koja ; 2= Cilicing 3=Rawabadak
Berikut ini akan dilakukan langkah-langkah analisis dengan SPSS adalah sebagai berikut:
1. Buka program SPSS, laluklik File Open Data
2. Setelah itu pilih type data misalnya Excell
Jika muncul Opening Excel Data Source Maka Klik OK
29
3. Setelah itu akan muncul data sebagai berikut
4. Selanjutnya klik Analyze Compare Means One Way Anova.
5. Masukkan variabel “ Penilaian” ke kotak Dependent List dan Variabel “Kelurahan”
ke kotak Faktor, seperti pada tampilan dibawah ini.

30
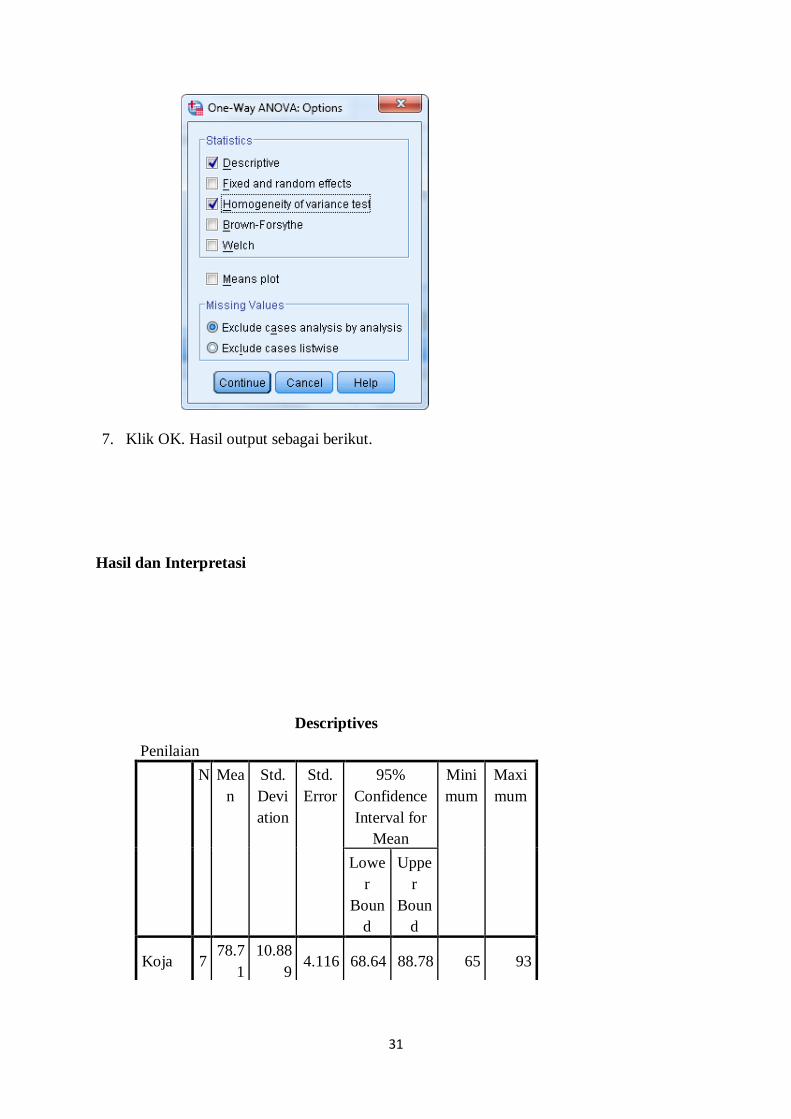
6. Setelah itu, klik tab Options. Selanjutnya, perhatikan kotak dialog yang tampil. Berilah
tanda centang pada Descriptive dan Homogeneity of Variance test. Kemudian, kliklah
Continue. Selanjutnya, Anda akan kembali ke kotak dialog sebelumnya.
31
7. Klik OK. Hasil output sebagai berikut.
Hasil dan Interpretasi
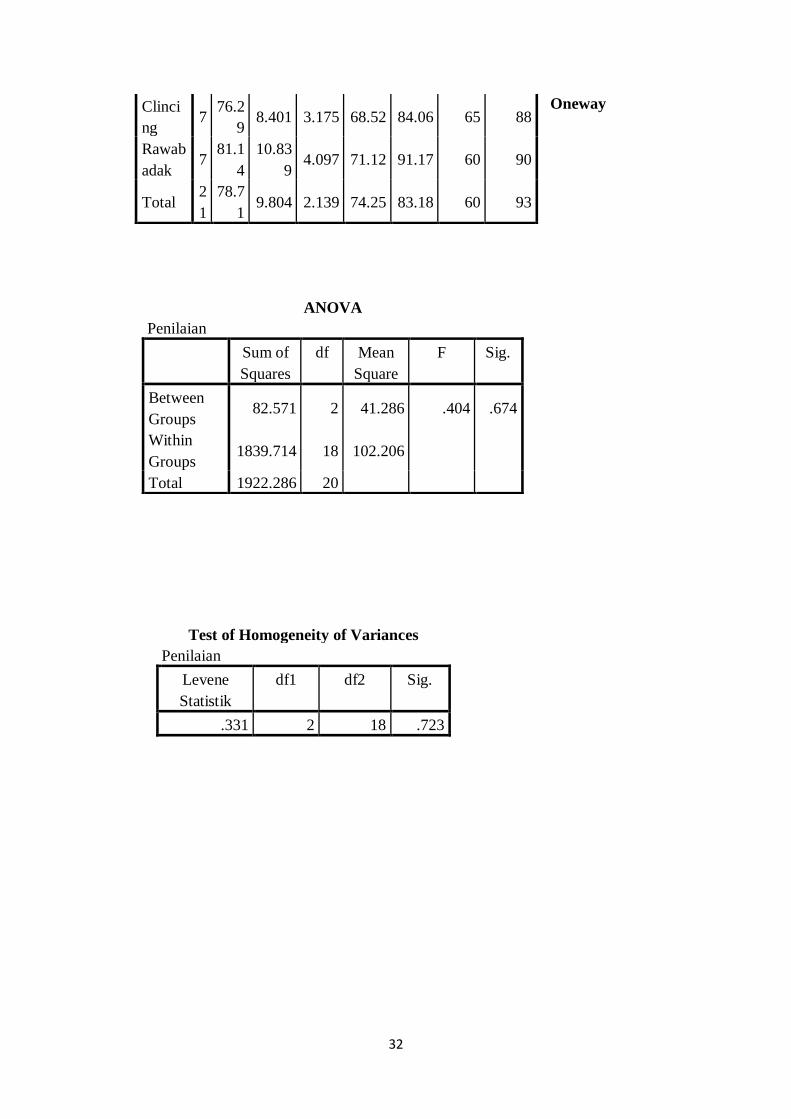
Descriptives
Penilaian
N Mea
n
Std.
Devi
ation
Std.
Error
95%
Confidence
Interval for
Mean
Mini
mum
Maxi
mum
Lowe
r
Boun
d
Uppe
r
Boun
d
Koja 7 78.7
1
10.88
9 4.116 68.64 88.78 65 93
32
Oneway
Test of Homogeneity of Variances
Penilaian
Levene
Statistik
df1 df2 Sig.
.331 2 18 .723
Clinci
ng 7
76.2
9 8.401 3.175 68.52 84.06 65 88
Rawab
adak 7
81.1
4
10.83
9 4.097 71.12 91.17 60 90
Total 2
1
78.7
1 9.804 2.139 74.25 83.18 60 93
ANOVA
Penilaian
Sum of
Squares
df Mean
Square
F Sig.
Between
Groups 82.571 2 41.286 .404 .674
Within
Groups 1839.714 18 102.206
Total 1922.286 20

33
Output Descriptives
Pada data kelompok Kelurahan Koja diperoleh hasil: jumlah data 7, rata-rata 78,71, deviasi
standar 10,889, dan standard error 4. Untuk data kelompok Kelurahan Cilincing; jumlah
data 7, rata-rata 76,29, deviasi standar 8,401 dan standard error 3. Dan untuk data
kelompok Rawabadak: jumlah data 7, rata-rata 81,14, deviasi standar 4,097 dan standard
error 4.
Output Test Of Homogeneity of Variance
Asumsi dalam pengajuan ANOVA adalah bahwa varian kelompok data adalah sama atau
homogen. Kriteria pengujiannya, yaitu jika signifikansi < 0,05, maka varian kelompok data
tidak sama. Namun sebaliknya, jika signifikansi > 0,05, maka varian kelompok data adalah
sama. Dari output dapat dilihat bahwa signifikansi > 0,05 (0,723 >0,05). Jadi, dapat
disimpulkan bahwa varian ketiga kelompok data, yaitu Koja, Cilincing, dan Rawabadak,
maka hal ini telah memenuhi asumsi dasar.
Output ANOVA
Analisis ANOVA dapat digunakan untuk mengetahui apakah ada perbedaan. Jika dalam
kasus ini kita kita dapat mengetahui penilaian masing-masing kelurahan yang dalam hal ini
Koja, Cilincing dan Rawabadak terkait dengan rasa baru dari chiki. Beberapa langkah yang
dapat dilakukan adalah:
Merumuskan hipotesis.
H0 : Tidak ada perbedaan rata-rata antara penilaian dari kelurahan Koja, Clincing dan
Rawabadak.
Ha : Ada perbedaan rata-rata antara nilai ujian dari kelurahan Koja, Cilincing dan
Rawabadak.
Menentukan F hitung dan Signifikansi

34
Untuk menentukan apakah terdapat perbedaan penilaian antara kelurahan Koja, Cilincing
dan Rawabadak kita mengacu pada koefisien Fhitung atau P-value dan membandingkannya
dengan Ftabel atau taraf signifikansi, baik pada α = 0,05 maupun α = 0,01. Jika Fhitung lebih
besar dari Ftabel atau P-value lebih kecil dari 0,05 dinyatakan terdapat perbedaan. Artinya,
hipotesis kerja (H1) diterima dan hipotesis nol (H0) ditolak.
Hasil analisis menujukkan nilai koefisien Fhitung adalah 0,404 dengan Pvalue 0,674. Ftabel
dicari dengan cara df1 = 3-1 = 2 dan df2 = 21-3= 18. Hasil yang diperoleh untuk Ftabel 3,55.
Latihan
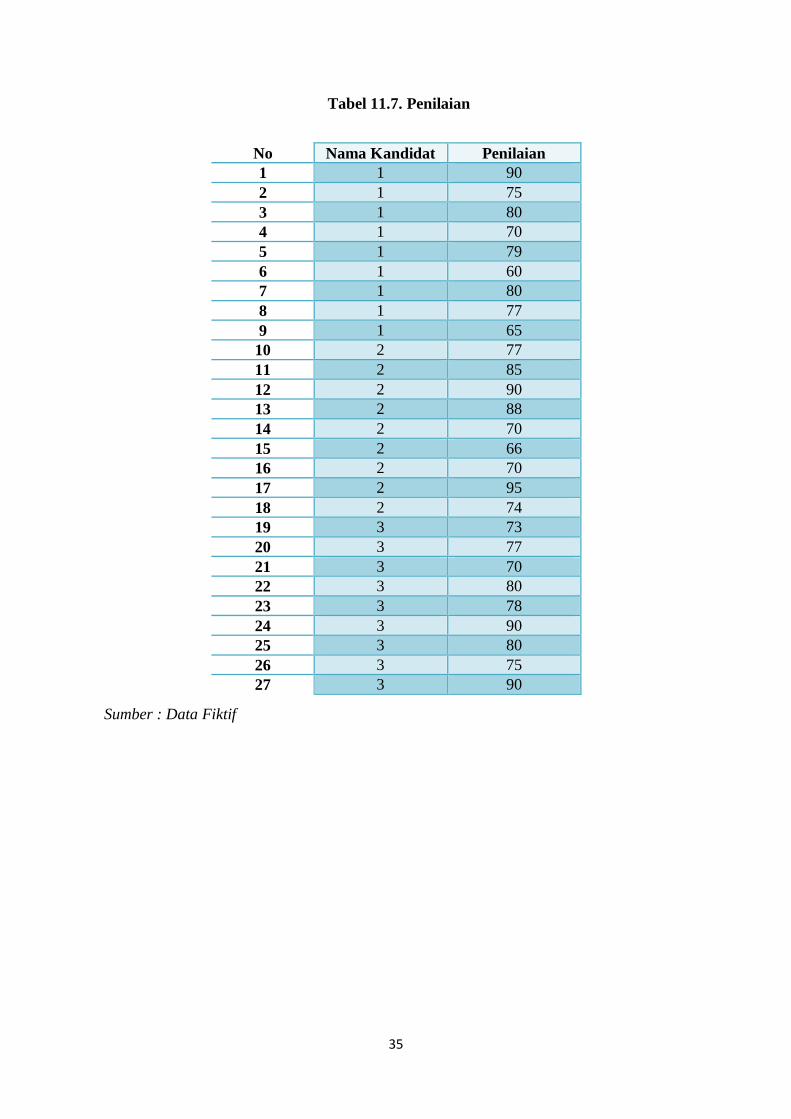
Sebuah organisasi kemahasiswaan ingin melakukan pemilihan ketua kemahasiswaan di
Universitas “ABC”. Terdapat tiga kandidat yang terpilih ada yakni “Marcel”, “Farrel”,
“Andika”. Masing-masing mahasiswa tersebut memberikan penilaian terhadap calon
kandidat sebagai berikut.
Keterangan :
1 = “Marcel”;
2= “Farrel”;
3= “Andika”;
Tentukan:
Dari data diatas apakah ada perbedaan diantara kandidat tersebut? Gunakan Analisis One
Way ANOVA untuk menguji perbedaan tersebut.
35
Tabel 11.7. Penilaian
Sumber : Data Fiktif
No Nama Kandidat Penilaian
1 1 90
2 1 75
3 1 80
4 1 70
5 1 79
6 1 60
7 1 80
8 1 77
9 1 65
10 2 77
11 2 85
12 2 90
13 2 88
14 2 70
15 2 66
16 2 70
17 2 95
18 2 74
19 3 73
20 3 77
21 3 70
22 3 80
23 3 78
24 3 90
25 3 80
26 3 75
27 3 90
36
Jika F hitung ≤ Ftabel, maka H0 di terima
Jika F hitung > F tabel, maka H0 ditolak.
Berdasarkan Signifikansi:
Jika signifikansi . 0,05, mka H0 diterima
Jika signifiknasi < 0,05, maka H0 ditolak.
Berdasarkan kesimpulan karena Fhitung > Ftabel ( 0,404 < 3,55) dan signifikansi > 0,05 (0,674
> 0,05), maka H0 diterima. Jadi dapat disimpulkan bahwa tidak ada perbedaan rata-rata
antara penilaian dari kelurahan Koja, Clincing dan Rawabadak.
Titik Persentase Distribusi F untuk
Probabilita = 0,05
df
unt
uk
pen
yeb
ut
(N2
)
df untuk pembilang
(N1)
1 2 3 4 5 6 7 8 9 1
0
1
1
12
1 161 19
9
21
6
22
5
2
3
0
2
3
4
2
3
7
23
9
2
4
1
2
4
2
2
4
3
24
4 2 18.5
1
19.
00
19.
16
19.
25
19.
30
19.
33
19.
35
19.
37
19.
38
19.
40
19.
40
19.
41 3 10.1
3
9.5
5
9.2
8
9.1
2
9.0
1
8.9
4
8.8
9
8.85 8.8
1
8.7
9
8.7
6
8.7
4 4 7.71 6.9
4
6.5
9
6.3
9
6.2
6
6.1
6
6.0
9
6.04 6.0
0
5.9
6
5.9
4
5.9
1 5 6.61 5.7
9
5.4
1
5.1
9
5.0
5
4.9
5
4.8
8
4.82 4.7
7
4.7
4
4.7
0
4.6
8 6 5.99 5.1
4
4.7
6
4.5
3
4.3
9
4.2
8
4.2
1
4.15 4.1
0
4.0
6
4.0
3
4.0
0 7 5.59 4.7
4
4.3
5
4.1
2
3.9
7
3.8
7
3.7
9
3.73 3.6
8
3.6
4
3.6
0
3.5
7 8 5.32 4.4
6
4.0
7
3.8
4
3.6
9
3.5
8
3.5
0
3.44 3.3
9
3.3
5
3.3
1
3.2
8 9 5.12 4.2
6
3.8
6
3.6
3
3.4
8
3.3
7
3.2
9
3.23 3.1
8
3.1
4
3.1
0
3.0
7 10 4.96 4.1
0
3.7
1
3.4
8
3.3
3
3.2
2
3.1
4
3.07 3.0
2
2.9
8
2.9
4
2.9
1 11 4.84 3.9
8
3.5
9
3.3
6
3.2
0
3.0
9
3.0
1
2.95 2.9
0
2.8
5
2.8
2
2.7
9 12 4.75 3.8
9
3.4
9
3.2
6
3.1
1
3.0
0
2.9
1
2.85 2.8
0
2.7
5
2.7
2
2.6
9 13 4.67 3.8
1
3.4
1
3.1
8
3.0
3
2.9
2
2.8
3
2.77 2.7
1
2.6
7
2.6
3
2.6
0 14 4.60 3.7
4
3.3
4
3.1
1
2.9
6
2.8
5
2.7
6
2.70 2.6
5
2.6
0
2.5
7
2.5
3 15 4.54 3.6
8
3.2
9
3.0
6
2.9
0
2.7
9
2.7
1
2.64 2.5
9
2.5
4
2.5
1
2.4
8 16 4.49 3.6
3
3.2
4
3.0
1
2.8
5
2.7
4
2.6
6
2.59 2.5
4
2.4
9
2.4
6
2.4
2 17 4.45 3.5
9
3.2
0
2.9
6
2.8
1
2.7
0
2.6
1
2.55 2.4
9
2.4
5
2.4
1
2.3
8 18 4.41 3.5
5
3.1
6
2.9
3
2.7
7
2.6
6
2.5
8
2.51 2.4
6
2.4
1
2.3
7
2.3
4 19 4.38 3.5
2
3.1
3
2.9
0
2.7
4
2.6
3
2.5
4
2.48 2.4
2
2.3
8
2.3
4
2.3
1 20 4.35 3.4
9
3.1
0
2.8
7
2.7
1
2.6
0
2.5
1
2.45 2.3
9
2.3
5
2.3
1
2.2
8
37
BAB.4
TWO-WAY ANOVA
Two-Way Anova atau istilah bahasa sederhanya merupakan ANOVA dua arah. Two-Way
Anova merupakan perbandingan dalam perbedaan rata-rata diantara kelompok yang telah
dibagi pada dua variabel independen. Analisis Two-Way ANOVA biasa dilakukan untuk uji
komparatif atau perbedaan dengan menggunakan dua faktor pembeda.
Contoh Soal
Salah satu perusahaan swasta sedang mencari kandidat untuk menduduki posisi tertentu.
Adapun beberapa calon kandidat yang melamar diperusahaan tersebut. Pihak perusahaan
merekrut calon pegawai baru dengan cara mengadakan test psikotest. Adapun data yang
diperolah dari hasil psikotest tersebut adalah:
Tabel 11.8. Test Psikotest
Sumber : Data Fiktif
Gender Pendidikan Ujian
2 1 65
2 2 68
1 3 70
1 2 50
1 2 80
2 2 75
1 3 80
2 2 88
2 1 50
1 1 60
1 1 78
1 2 67
1 1 80
2 2 75
1 2 84
1 3 88
2 2 74
1 3 88
2 1 60
1 2 70

38
Pembahasan
Berikut langkah-langkah menggunakan SPSS:
1. Klik SPSS, lalu input data
Keterangan:
Pendidikan
1 = S1(Bachelor)
2 = S2(Magister)
3 = S3(Doctoral)
Gender
1 = Laki-Laki
2= Perempuan
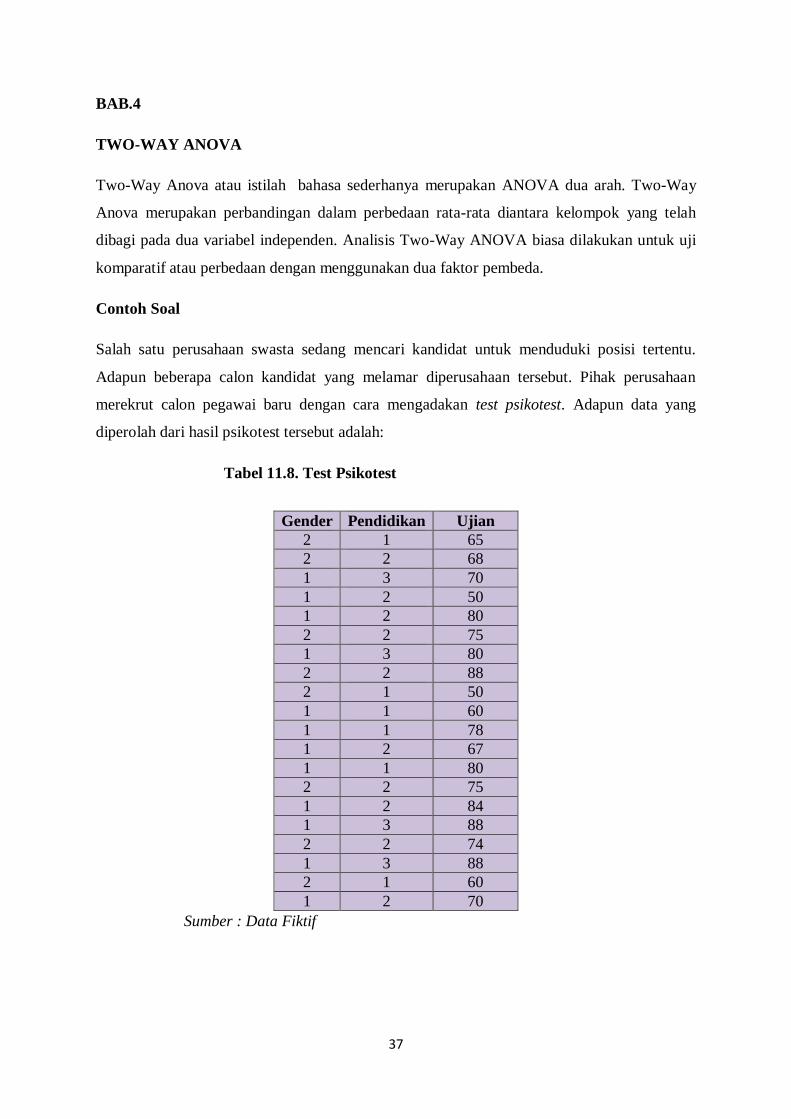
2. Sebelum memilih perintah rubah terlebih dahulu dikolom Variabel View dan di baris
Gender. Beri nilai 1 untuk label laki-laki, 2 untuk label perempuan.
39
3. Sementara itu di baris Pendidikan dan di kolom Values beri label 1 = S1(Bachelor), 2
= S2(Magister), 3 = S3(Doctoral).

40
4. Klik Analyze General Linear Model Univariate, seperti berikut ini.
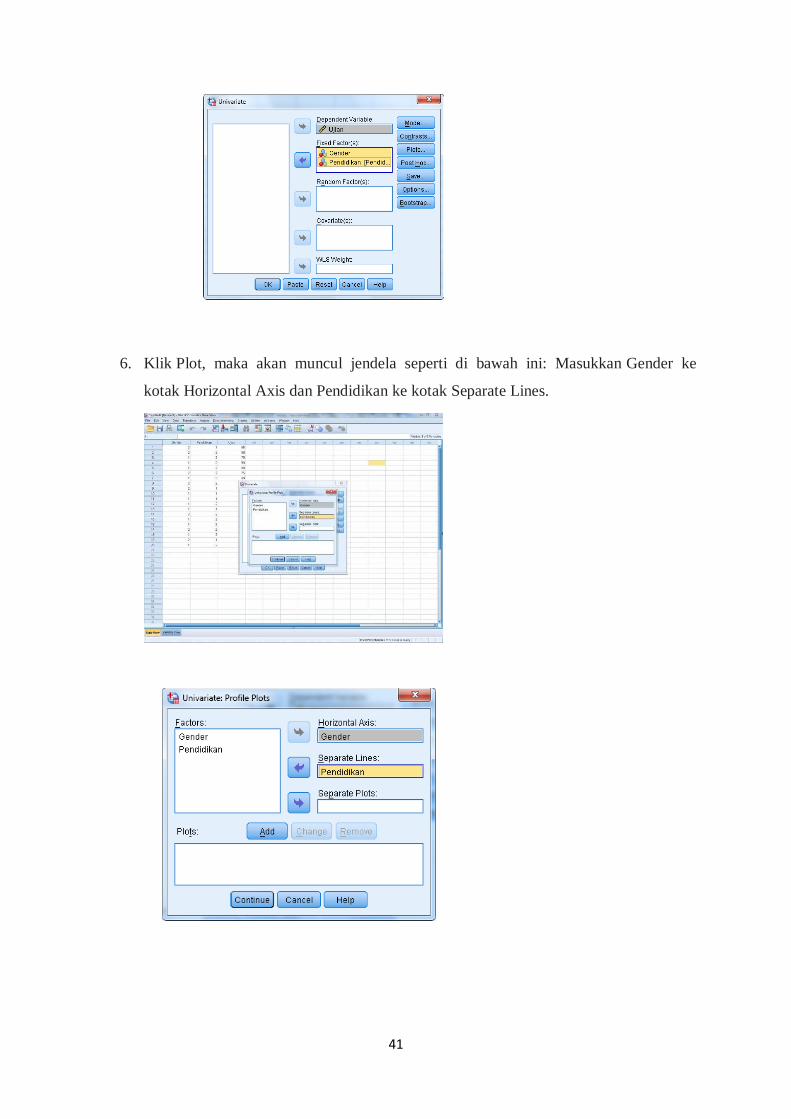
5. Kemudian akan mucul jendela sbb: Masukkan Ujian ke kotak Dependent Variabel,
masukkan Gender dan Pendidikan ke kotak Fixed faktor (s). (Kotak Random faktor
(s) dan Covariate (s) tidak akan kita gunakan dalam Two Ways Anova, kotak tersebut
akan digunakan pada "Uji Anova".
41
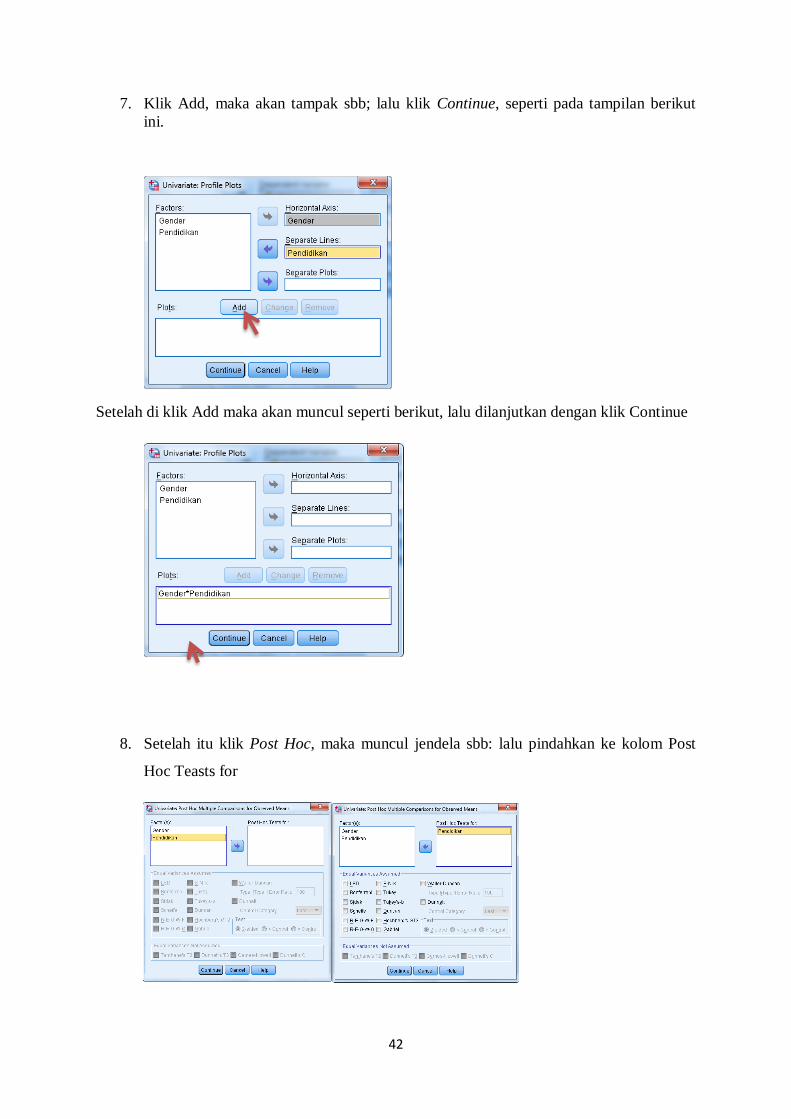
6. Klik Plot, maka akan muncul jendela seperti di bawah ini: Masukkan Gender ke
kotak Horizontal Axis dan Pendidikan ke kotak Separate Lines.
42
7. Klik Add, maka akan tampak sbb; lalu klik Continue, seperti pada tampilan berikut
ini.
Setelah di klik Add maka akan muncul seperti berikut, lalu dilanjutkan dengan klik Continue
8. Setelah itu klik Post Hoc, maka muncul jendela sbb: lalu pindahkan ke kolom Post
Hoc Teasts for
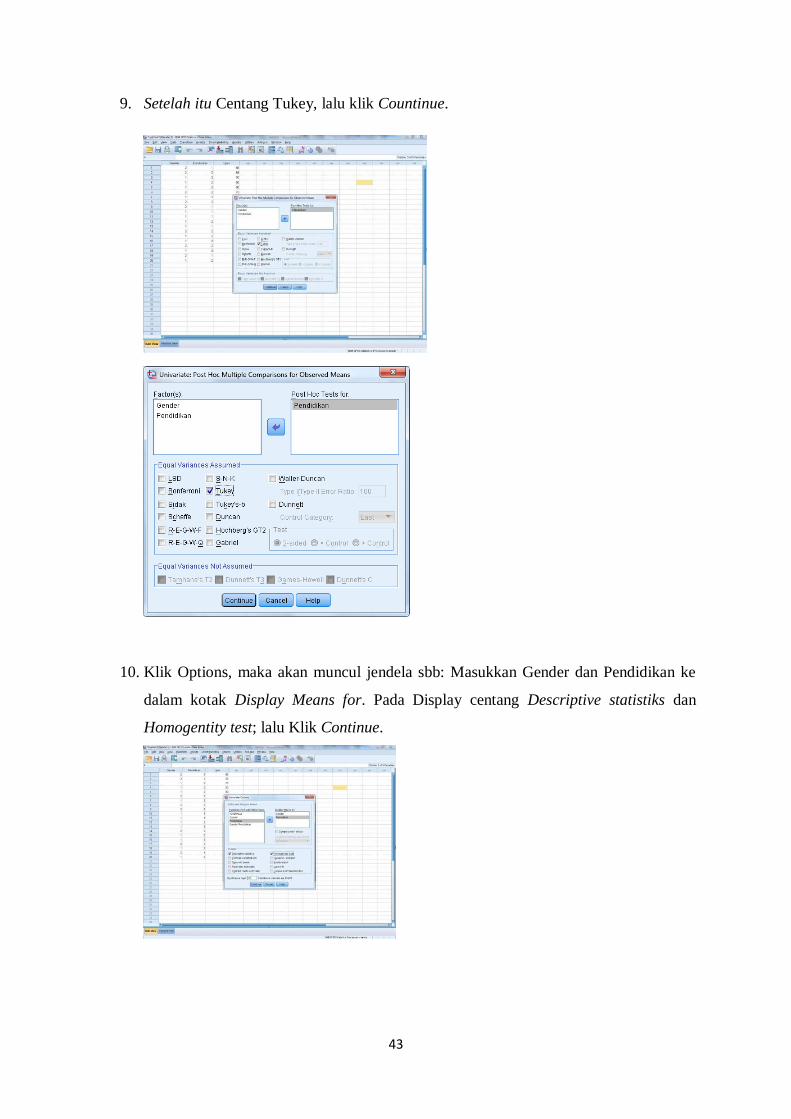
43
9. Setelah itu Centang Tukey, lalu klik Countinue.
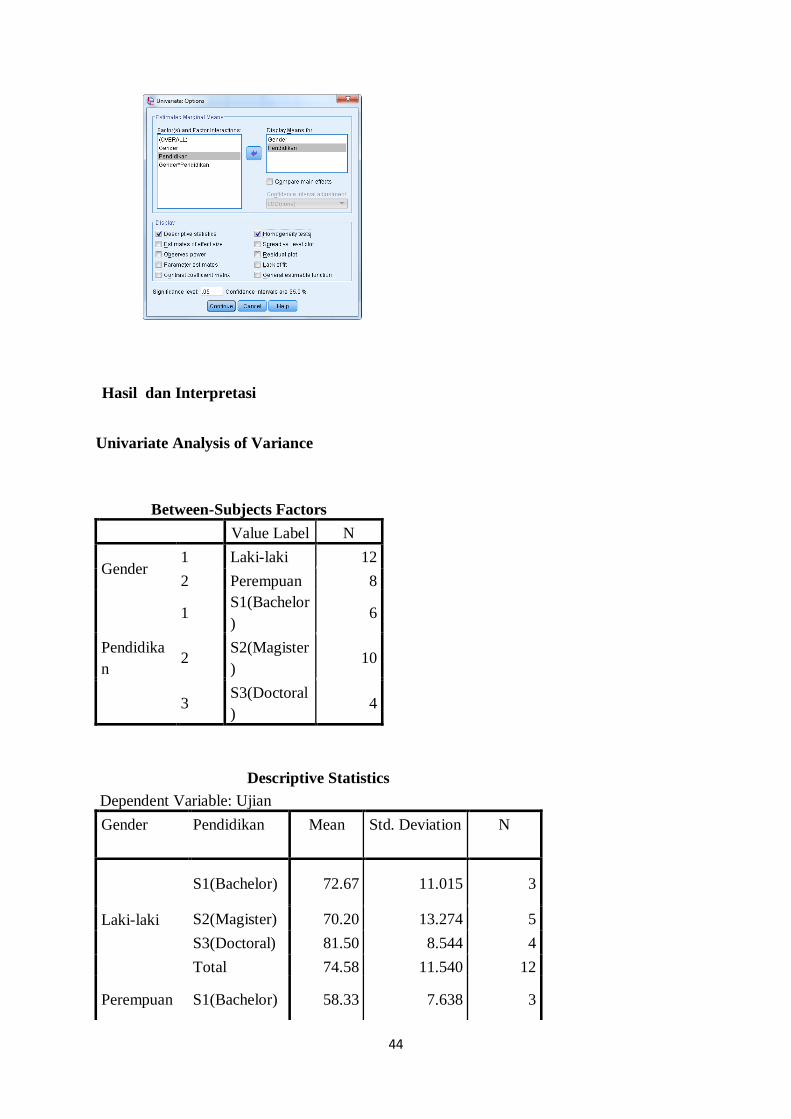
10. Klik Options, maka akan muncul jendela sbb: Masukkan Gender dan Pendidikan ke
dalam kotak Display Means for. Pada Display centang Descriptive statistiks dan
Homogentity test; lalu Klik Continue.
44
Hasil dan Interpretasi
Univariate Analysis of Variance
Between-Subjects Factors
Value Label N
Gender 1 Laki-laki 12
2 Perempuan 8
Pendidika
n
1 S1(Bachelor
) 6
2 S2(Magister
) 10
3 S3(Doctoral
) 4
Descriptive Statistics
Dependent Variable: Ujian
Gender Pendidikan Mean Std. Deviation N
Laki-laki
S1(Bachelor) 72.67 11.015 3
S2(Magister) 70.20 13.274 5
S3(Doctoral) 81.50 8.544 4
Total 74.58 11.540 12
Perempuan S1(Bachelor) 58.33 7.638 3
45
Levene's Test of Equality of Error
Variancesa
Dependent Variable: Ujian
F df1 df2 Sig.
.549 4 15 .703
Tests the null hypothesis that the error
variance of the dependent variable is
equal across groups.
a. Design: Intercept + Gender +
Pendidikan + Gender * Pendidikan
Estimated Marginal Means
S2(Magister) 76.00 7.314 5
Total 69.38 11.439 8
Total
S1(Bachelor) 65.50 11.554 6
S2(Magister) 73.10 10.556 10
S3(Doctoral) 81.50 8.544 4
Total 72.50 11.496 20
Tests of Between-Subjects Effects
Dependent Variable: Ujian
Source Type III
Sum of
Squares
df Mean
Square
F Sig.
Corrected
Model 1013.867a 4 253.467 2.540 .083
Intercept 93965.143 1 93965.14
3
941.45
1 .000
Gender 68.267 1 68.267 .684 .421
Pendidikan 435.801 2 217.900 2.183 .147
Gender *
Pendidikan 380.017 1 380.017 3.807 .070
Error 1497.133 15 99.809
Total 107636.000 20
Corrected
Total 2511.000 19
a. R Squared = .404 (Adjusted R Squared = .245)
46
1. Gender
Dependent Variable: Ujian
Gender Mean Std.
Error
95% Confidence Interval
Lower
Bound
Upper
Bound
Laki-laki 74.789 2.947 68.507 81.071
Perempuan 67.167a 3.648 59.391 74.942
a. Based on modified population marginal mean.
2. Pendidikan
Dependent Variable: Ujian
Pendidikan Mean Std.
Error
95% Confidence Interval
Lower
Bound
Upper
Bound
S1(Bachelor) 65.500 4.079 56.807 74.193
S2(Magister)
73.100 3.159 66.366 79.834
S3(Doctoral) 81.500a 4.995 70.853 92.147
a. Based on modified population marginal mean.
Multiple Comparisons
Dependent Variable: Ujian
Tukey HSD
(I)
Pendidik
an
(J)
Pendid
ikan
Mean
Differenc
e (I-J)
Std.
Error
Sig. 95% Confidence
Interval
Lower
Bound
Upper
Bound
S1(Bach
elor)
S2(Ma
gister) -7.60 5.159 .331 -21.00 5.80
S3(Do
ctoral) -16.00 6.449 .062 -32.75 .75
S2(Magi
ster)
S1(Ba
chelor
)
7.60 5.159 .331 -5.80 21.00
S3(Do
ctoral) -8.40 5.910 .355 -23.75 6.95
S3(Docto
ral)
S1(Ba
chelor
)
16.00 6.449 .062 -.75 32.75
S2(Ma
gister) 8.40 5.910 .355 -6.95 23.75
Based on observed means.
The error term is Mean Square(Error) = 99.809.
47
Post Hoc Tests
Pendidikan
Homogeneous Subsets
Ujian
Tukey HSD
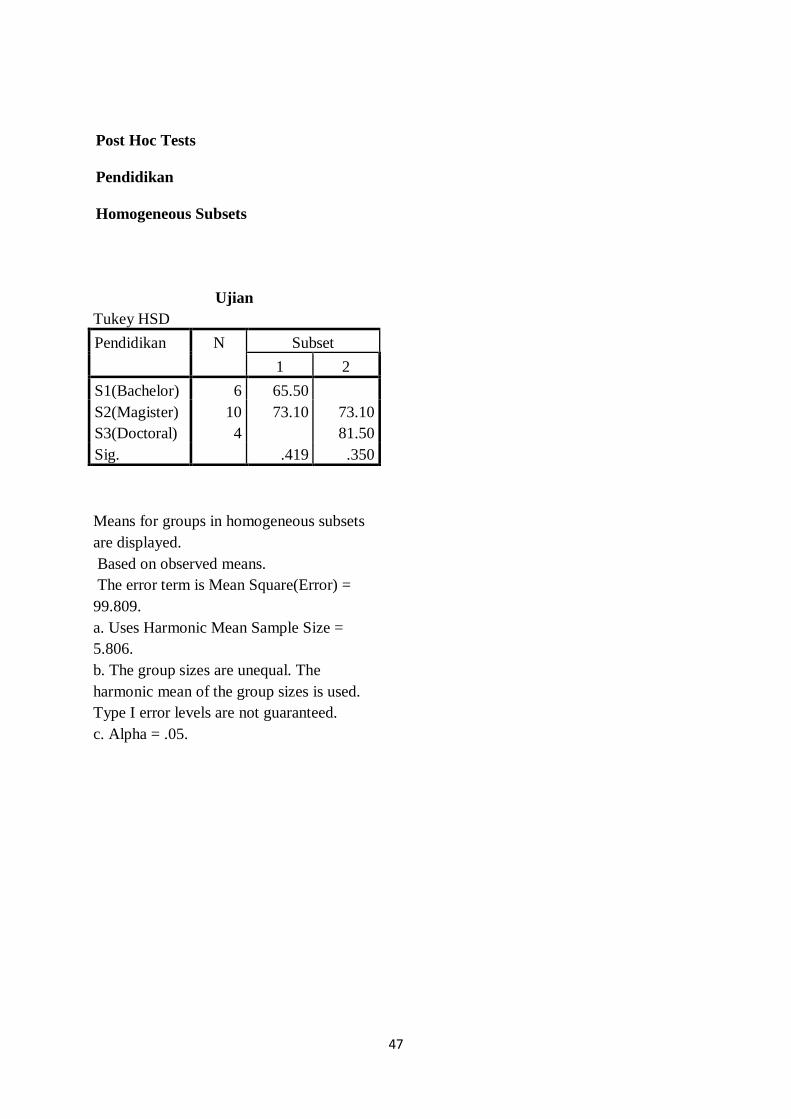
Pendidikan N Subset
1 2
S1(Bachelor) 6 65.50
S2(Magister) 10 73.10 73.10
S3(Doctoral) 4 81.50
Sig. .419 .350
Means for groups in homogeneous subsets
are displayed.
Based on observed means.
The error term is Mean Square(Error) =
99.809.
a. Uses Harmonic Mean Sample Size =
5.806.
b. The group sizes are unequal. The
harmonic mean of the group sizes is used.
Type I error levels are not guaranteed.
c. Alpha = .05.
48
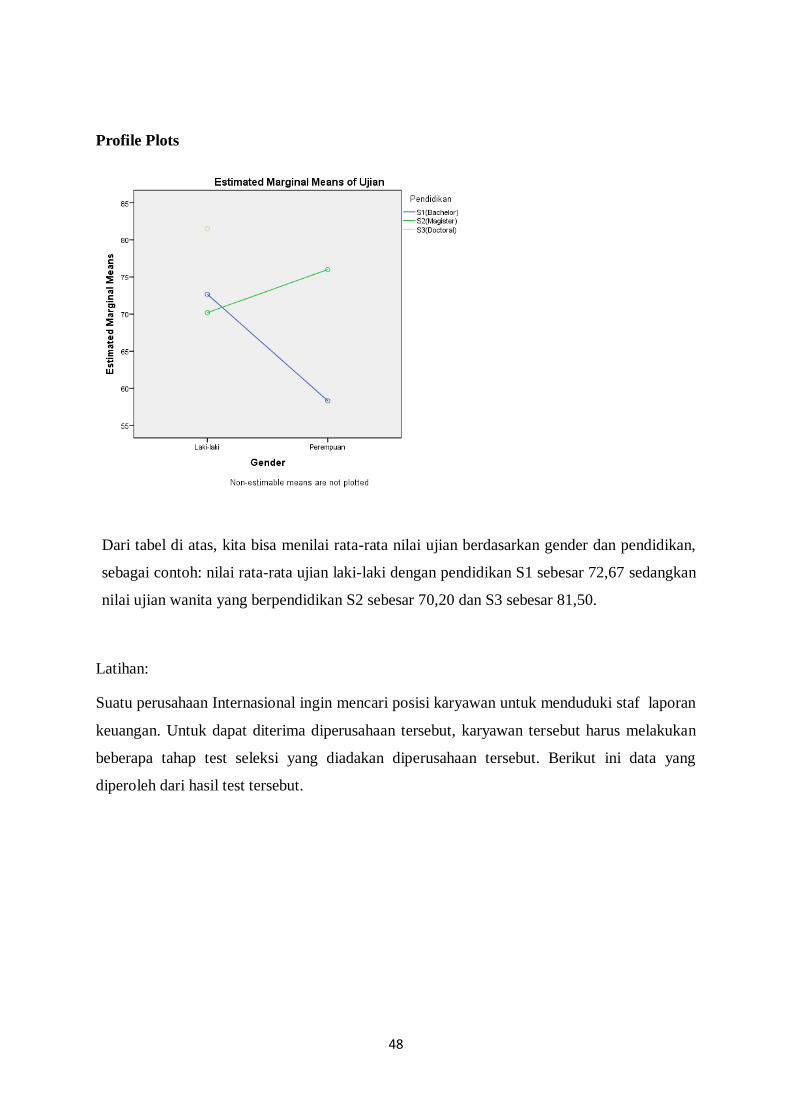
Profile Plots
Dari tabel di atas, kita bisa menilai rata-rata nilai ujian berdasarkan gender dan pendidikan,
sebagai contoh: nilai rata-rata ujian laki-laki dengan pendidikan S1 sebesar 72,67 sedangkan
nilai ujian wanita yang berpendidikan S2 sebesar 70,20 dan S3 sebesar 81,50.
Latihan:
Suatu perusahaan Internasional ingin mencari posisi karyawan untuk menduduki staf laporan
keuangan. Untuk dapat diterima diperusahaan tersebut, karyawan tersebut harus melakukan
beberapa tahap test seleksi yang diadakan diperusahaan tersebut. Berikut ini data yang
diperoleh dari hasil test tersebut.
49
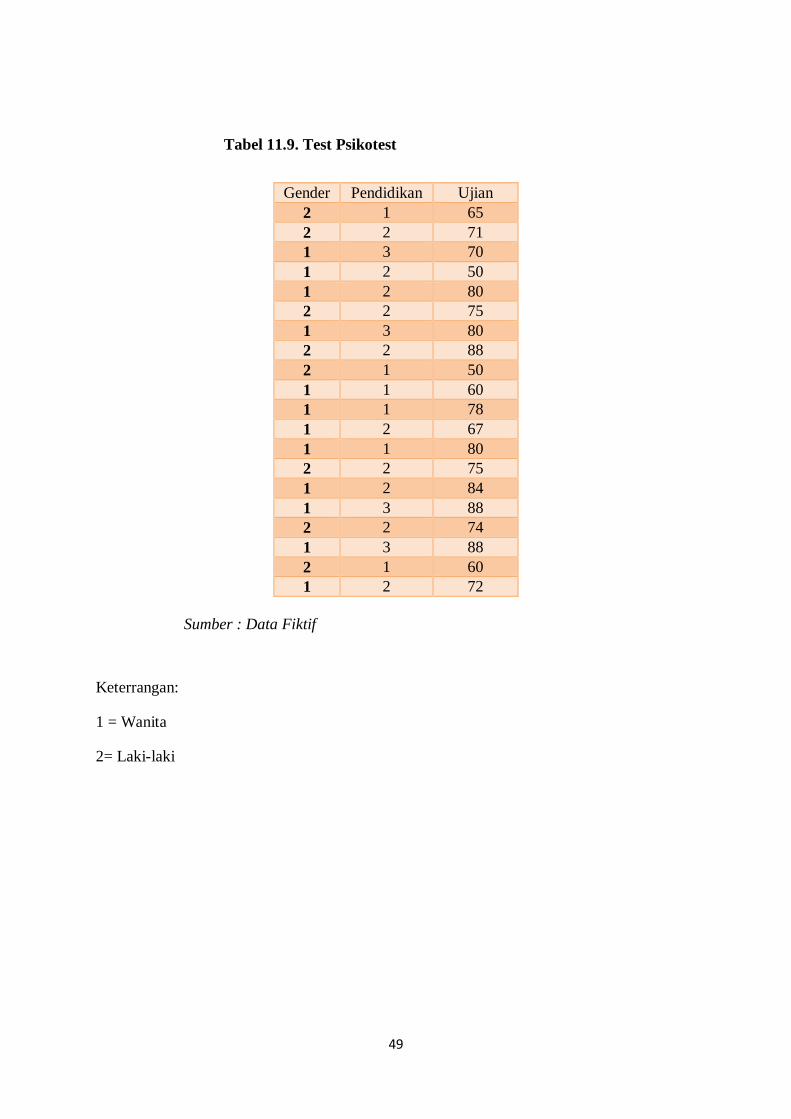
Tabel 11.9. Test Psikotest
Sumber : Data Fiktif
Keterrangan:
1 = Wanita
2= Laki-laki
Gender Pendidikan Ujian
2 1 65
2 2 71
1 3 70
1 2 50
1 2 80
2 2 75
1 3 80
2 2 88
2 1 50
1 1 60
1 1 78
1 2 67
1 1 80
2 2 75
1 2 84
1 3 88
2 2 74
1 3 88
2 1 60
1 2 72

50
DAFTAR PUSTAKA
Arikunto, Suharsimi.1998. Prosedur Penelitian: Suatu Pendekatan Pratek. Jakarta: Rineka Cipta.
Bahri, Syamsul dan Zamzam, Fahkry. 2015. Model Penelitian Kuantitatif Berbasis SEM-AMOS.
Yogyakarta: Deepublish.
Cochran, William G. 1979. Sampling Techniques. Tried Edition. New York: John Wiley & Sons.
Duei, Priyatno. 2012. Cara Kilat Belajar Analisis Data Dengan SPSS 20. Yogyakarta: ANDI.
Issac, S., & Michael, W.B. (1981). Handbokk in reserarch and evoluation California: Edits Publishers.
Santoso, Singgih. Panduan Lengkap Menguasai Statistik dengan SPSS 17. 2009. Jakarta: PT. Elex Media
Komputindo.
Sutanto, T.E dan Abdullah, Sarini. Statistika Tanpa Stres. Jakarta: TransMedia Pustaka.
Priyatno, Duwi. 2012.Cara Kilat Belajar Analisis Data Dengan SPSS 20. Yogyakarta: ANDI.
Priyatno, Duwi. 2009: 5 Jam Belajar Olah Data Dengan ASPSS 17. Yogyakarta: ANDI.
Widiyanto, Mikha. 2014. Statistika Untuk Penelitian Bidang Teologi, Pendidikan Agama Kriten, &
Pelayanan Gereja. Bandung: Kalam Hidup.
Wijaya, Tony. 2012. Cepat Menguasai SPSS 20 Untuk Olah dan Interpretasi Data. Yogyakarta: Cahaya
Atma Pustaka.
Yount, William R. 1999. Reseacrh Design and Statistikal Analysis in Chritian Ministry. Fort Worth:
Southwestern Baptis Theological Seminary.
https://www.freepik.com/