jurnal pjk
TRANSCRIPT

5/16/2018 JURNAL PJK - slidepdf.com
http://slidepdf.com/reader/full/jurnal-pjk-55ab571558209 1/8
1
PEMBANGKITAN ATURAN FUZZY MENGGUNAKAN FUZZY C-MEANS (FCM)
CLUSTERING UNTUK DIAGNOSA RISIKO PENYAKIT JANTUNG KORONER
(PJK)
Resti Ludviani1, Candra Dewi, Dian Eka Ratnawati
Program Studi Ilmu Komputer, Jurusan Matematika
Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Brawijaya MalangJalan Mayjen Haryono 169, Malang 65145, Indonesia
Email1: [email protected]
ABSTRAK
Aturan fuzzy biasanya didefinisikan oleh pakar sehingga memerlukan waktu, pengalaman, dan
keahlian pakar. Pembangkitan aturan fuzzy secara otomatis oleh sistem dapat digunakan untuk
mengatasi permasalahan ini. Aturan fuzzy dapat diekstraksi dari data dengan menggunakan beberapa
teknik, salah satunya adalah Fuzzy C-Means (FCM) clustering. FCM memiliki kelebihan yaitu pusat
kelompok dan hasil pengelompokkan tidak mudah berubah dengan adanya data baru yang bernilai
ekstrim. Pada penelitian ini, dilakukan pembangkitan aturan fuzzy pada sistem diagnosa penyakit jantung koroner (PJK) untuk mengetahui implementasi FCM clustering dalam pembangkitan aturan
fuzzy dan akurasi dari hasil sistem tersebut. Penelitian dilakukan dengan beberapa skenario uji coba,
dengan jumlah data latih yang berbeda. Setiap uji coba, dilakukan percobaan sebanyak 5 kali. Hasil uji
coba kemudian dianalisis dimana aturan fuzzy dan akurasi sistem dari setiap skenario uji coba
dibandingkan sehingga aturan fuzzy yang terbaik dapat diketahui. Hasil penelitian menunjukkan bahwa
akurasi maksimum yang dihasilkan sistem diagnosa risiko PJK melalui pembangkitan aturan fuzzy
menggunakan FCM adalah 50%, yaitu pada jumlah aturan 2 dengan nilai batasan varian sebesar 0,0338
pada jumlah data latih 70.
Kata kunci: aturan fuzzy, sistem fuzzy, penyakit jantung koroner (PJK), clustering, FCM
1. PENDAHULUAN1.1 Latar Belakang
Sebelum ditemukan konsep kecerdasan
buatan, suatu permasalahan tidak dapat
diprediksi tanpa campur tangan seorang pakar
secara langsung sehingga memakan waktu yang
lama dalam proses pengambilan keputusan.
Seiring dengan perkembangan kecerdasan
buatan, suatu permasalahan dapat diprediksi
walaupun pakar tidak terlibat secara langsung.
Salah satu metode kecerdasan buatan yang
sering digunakan untuk menggantikan pakar
adalah sistem fuzzy, hal ini karena logika fuzzy
terbukti dapat dipakai untuk memodelkan proses
berpikir manusia yang penuh ketidakpastian
(Priyono, dkk., 2007). Logika fuzzy merupakan
logika yang memiliki nilai kekaburan atau
kesamaran (fuzzyness) yang digunakan untuk
melakukan penalaran (Kusumadewi, 2010).
Pada umumnya, aturan fuzzy didefinisikan
oleh pakar, dimana proses ini memerlukan
waktu, pengalaman, dan keahlian pakar
(Arapoglou, dkk., 2010). Namun, terkadang
pakar dapat mengalami kesulitanmendefinisikan aturan pada kasus tertentu.
Teknik pembentukan aturan secara otomatis
oleh sistem dapat digunakan untuk mengatasipermasalahan tersebut. Aturan fuzzy dapat
diekstraksi dari data dengan menggunakan
teknik clustering seperti Fuzzy C-Means (FCM).
Sistem fuzzy dapat digunakan untuk menangani
permasalahan yang rumit seperti diagnosa risiko
Penyakit Jantung Koroner (PJK). PJK
merupakan kelainan yang disebabkan oleh
penyempitan pembuluh arteri yang mengalirkan
darah ke otot jantung (Soeharto, 2010). Karena
PJK termasuk penyakit yang berbahaya, sistem
diagnosa untuk memeriksa risiko PJK akan
sangat bermanfaat. Faktor risiko PJK berupa
data numerik sehingga dapat digunakan untuk
membangkitkan aturan diagnosa risiko PJK.
1.2 Rumusan MasalahPermasalahan yang ada pada skripsi ini
dapat dirumuskan sebagai berikut:
1. Bagaimana membangkitkan aturan fuzzy dari
data faktor risiko penyakit jantung koroner
pasien dengan algoritma fuzzy C-means
(FCM)?
2.
Bagaimana akurasi aturan fuzzy yangterbentuk jika diimplementasikan pada

5/16/2018 JURNAL PJK - slidepdf.com
http://slidepdf.com/reader/full/jurnal-pjk-55ab571558209 2/8
2
sistem fuzzy untuk diagnosa risiko penyakit
jantung koroner?
1.3 Batasan MasalahMasalah yang dibahas pada skripsi ini
dibatasi pada:
1. Pembentukan aturan fuzzy didasarkan pada
faktor risiko PJK, yaitu umur, kadar LDL,kadar HDL, kolestrol total, trigliserida, dan
tekanan darah sistolik.
2. Tidak menangani data yang memiliki missing
value pada data latih maupun data uji,
sehingga input setiap data harus lengkap.
3. Aturan (rules) hasil pembangkitan digunakan
untuk inferensi fuzzy TSK.
4. Diagnosa risiko PJK pada penelitian ini
ditentukan berdasarkan kelas risiko PJK pada
penelitian yang dilakukan Wahyuni (2011).
1.4 Tujuan PenelitianSkripsi ini dibuat dengan tujuan untuk:
1. Membangkitkan aturan fuzzy dari data faktor
risiko penyakit jantung koroner pasien
dengan algoritma fuzzy C-means
2. Menghitung akurasi aturan fuzzy yang
terbentuk jika diimplementasikan pada
sistem fuzzy untuk diagnosa risiko penyakit
jantung koroner.
1.5 Manfaat Penelitian
Manfaat yang dapat diambil dari skripsi iniyaitu menghasilkan aplikasi yang dapat
membangkitkan aturan pada sistem fuzzy untuk
diagnosa risiko PJK, sehingga dapat membantu
dalam mendeteksi risiko penyakit jantung
koroner (PJK) secara dini.
2. TINJAUAN PUSTAKA
2.1 Penyakit Jantung KoronerPenyakit Jantung Koroner (PJK) adalah
suatu kelainan disebabkan oleh penyempitan
atau penghambatan pembuluh arteri yang
mengalirkan darah ke otot jantung. Bilamanapenyempitan ini menjadi parah maka dapat
terjadi serangan jantung. Adapun penyempitan
pembuluh arteri ke otak dapat menimbulkan
stroke. Kondisi tubuh yang semakin tua dan
memburuk oleh bermacam-macam faktor risiko,
seperti tekanan darah tinggi, merokok, kadar
kolesterol darah yang abnormal, dapat
menyebabkan PJK (Imam, 2010).
Adapun faktor risiko PJK yang dapat
digunakan sebagai parameter untuk diagnosa,
yaitu (Wahyuni, 2011):
1. Umur
2. Kadar LDL
3. Kadar HDL
4. Kadar kolesterol total
5. Kadar trigliserida
6. Tekanan darah sistolik
Sedangkan diagnosa risiko PJK terbagi dalam
beberapa kelas dan rentang nilai sebagai berikut:
Tabel 2.1 Rentang nilai kelas risiko PJK
No Rentang nilai risiko(y) Kelas risiko PJK
1 Kurang dari 10 (y ≤ 10) Sangat rendah
2 10 < y ≤ 20 Rendah
3 20 < y ≤ 30 Sedang
4 30 < y ≤ 40 Tinggi
5 Lebih dar 40 (y > 40) Sangat tinggi
2.2 Logika Fuzzy
2.2.1 Definisi logika fuzzy Logika fuzzy merupakan logika yang
memiliki nilai kekaburan atau kesamaran
(fuzzyness), yang digunakan untuk membantupengambilan keputusan dalam suatu
permasalahan. Logika fuzzy pertama kali
diperkenalkan oleh Lotfi A. Zadeh.
Logika fuzzy digunakan untuk menerjemahkan
suatu besaran yang diekspresikan menggunakan
bahasa/linguistik (Kusumadewi, 2010).
2.2.2 Fungsi keanggotaan GaussFungsi keanggotaan (membership function)
adalah suatu kurva yang menunjukkan pemetaan
titik-titik input data ke dalam nilai keanggotaan
( derajat keanggotaan) yang memiliki intervalantara 0 sampai 1. Untuk merepresentasikan
bilangan fuzzy, dapat digunakan kurva lonceng
Gauss. Nilai kurva Gauss untuk suatu nilai
domain x ditunjukkan pada gambar (2.1),
dengan fungsi keanggotaan Gauss seperti pada
persamaan (2.1) (Kusumadewi, 2010).
(2.1)
Gambar 2.1 Kurva Gauss (Kusumadewi, 2010)
2.2.3
Sistem inferensi fuzzy TSKSecara umum bentuk model fuzzy TSK
orde-satu adalah:

5/16/2018 JURNAL PJK - slidepdf.com
http://slidepdf.com/reader/full/jurnal-pjk-55ab571558209 3/8
3
IF(x1 is A1)o…o(xN is AN) THEN z =
p1*x1+…+pN*xN+q
dengan Ai adalah himpunan fuzzy ke-i sebagai
antiseden, dan k adalah suatu konstanta (tegas)
ke-i dan q juga merupakan konstanta dalam
konsekuen. Apabila komposisi aturan
menggunakan metode TSK maka defuzzifikasidilakukan dengan mencari nilai rata-rata. Misal
diasumsikan terdapat dua aturan fuzzy sebagai
berikut:
R1: if u is A1 and v is B1 then w= f1(u, v) = p1u +q1v +r1
R2: if u is A2 and v is B2 then w= f2(u, v) = p2u +q2v +r2
dimana p1, p2, q1, dan q2 adalah konstanta.
Nilai inferensi dari aturan pertama adalah f 1(u0,
v0) dimana u0 dan v0 adalah input tunggal, dan
α1 adalah derajat keanggotaan pada aturan
pertama. Nilai inferensi dari aturan kedua adalah
f 2(u, v) dengan α2 adalah derajat keanggotaan
pada aturan kedua. Derajat keanggotaan yang
sesuai didapatkan dari
Defuzzifikasi hasil inferensi TSK dapat
dilakukan dengan metode weighted average
yang ditunjukkan oleh persamaan (2.2) (Lee,
2005):
(2.2)
2.2.4 Fuzzy C-Means (FCM)
Fuzzy C-Means (FCM) merupakan salahsatu algoritma fuzzy clustering. Fuzzy C-Means
(FCM) adalah suatu teknik peng-cluster-an data
yang keberadaan setiap titik data dalam suatu
cluster ditentukan oleh derajat keanggotaan.
Konsep dasar FCM yaitu menentukan pusat
cluster , yang akan menandai lokasi rata-rata
untuk setiap cluster . Dengan cara memperbaiki
pusat cluster dan derajat keanggotaan setiap titik
data secara berulang, maka akan dapat dilihat
bahwa pusat cluster akan bergerak menuju
lokasi yang tepat. Perulangan ini didasarkanpada pada minimisasi fungsi obyektif yang
menggambarkan jarak dari titik data yang
diberikan ke pusat cluster yang terbobot oleh
derajat keanggotaan titik data tersebut.
Algoritma Fuzzy C-Means (FCM) adalah
sebagai berikut (Kusumadewi, 2010):
1. Input data yang akan di-cluster X, berupa
matriks berukuran n x m (n = jumlah
sampel data, m = atribut setiap data). X ij =
data sampel ke-i (i = 1, 2, 3, …, n), atributke- j (j = 1, 2, 3, …, m).
2. Menentukan:Jumlah cluster = c;
Pangkat = w;
Maksimum iterasi = MaxIter;
Eror terkecil yang diharapkan = ξ; Fungsi obyektif awal = P0= 0;
Iterasi awal = t = 1;
3. Membangkitkan bilangan random µ ik . i = 1,
2, …, n; k = 1, 2, …, c; sebagai elemen -
elemen matriks partisi awal U. Kemudian,
menghitung jumlah setiap kolom denganpersamaan (2.3),
(2.3)
dengan j= 1, 2, …, n. Setelah itu,menghitung derajat keanggotaan awal
dengan persamaan (2.4).
(2.4)
4. Menghitung pusat cluster ke-k (Vkj)
berdasarkan persamaan (2.5), dengan
k=1,2, …,c; dan j=1, 2, …, m.
(2.5)
5. Menghitung fungsi obyektif pada iterasi ke-
t (Pt) sesuai persamaan (2.6).
2 (2.6)
6. Menghitung perubahan matriks partisi
berdasarkan persamaan (2.7).
(2.7)
dengan i = 1, 2, …, n; dan k = 1, 2, …, c.7. Memeriksa kondisi berhenti:
Jika: (|Pt – Pt-1| < ξ) atau (t > MaxIter)
maka berhenti;
Jika tidak: t = t+1, ulangi langkah ke-4.
2.2.5 Ekstraksi aturan fuzzy dari cluster
Derajat keanggotaan dapat dicari denganmenggunakan fungsi Gauss karena terdapat n
buah titik data (Xij) dan pusat cluster (Vkj).
Berdasarkan hal itu, bentuk umum fungsi Gauss
pada persamaan (2.1) dapat ditulis menjadi
persamaan (2.8) (Kusumadewi, 2010).
(2.8)
Keterangan:
xij = data i atribut ke-j
vkj = pusat cluster ke-k atribut ke-jσkj = standar deviasi dari cluster ke-k atribut ke-j

5/16/2018 JURNAL PJK - slidepdf.com
http://slidepdf.com/reader/full/jurnal-pjk-55ab571558209 4/8
4
Sedangkan standar deviasi (σ) diperoleh dari
persamaan (2.9) (Walpole, 1995).
(2.9)
Keterangan:
σ = standar deviasi
x = data
= mean (rata-rata)n = jumlah data
Mulai proses berikut, derajat keanggotaan
hanya melibatkan variabel-variabel input saja.
Nilai j=1, 2, …, m digunakan untuk menyatakan
variabel input saja (m = jumlah variabel input ).
Nilai output dicari melalui langkah-langkah
sebagai berikut (Kusumadewi, 2010):
Derajat keanggotaan setiap data i dalam
cluster k dikalikan dengan setiap atribut j
dari data i, yang dapat dimisalkan dengan dk ij
dan dihitung berdasarkan persamaan (2.10).(2.10)
Proses normalisasi dilakukan dengan cara
membagi dk ij dan d
k i(m+1) dengan jumlah
derajat keanggotaan setiap titik data i pada
cluster k menggunakan persamaan (2.11)
untuk dk ij dan persamaan (2.12) untuk d
k i(m+1).
(2.11)
(2.12)
Langkah selanjutnya adalah membentuk
matriks U yang berukuran n x (c*(m+1))
Sehingga untuk n titik data akan diperoleh
matriks U sebagai berikut:
u11 u12 … u1m u1(m+1) … u1(c*(m+1))
U= u21 u22 … u2m u2(m+1) … u2(c*(m+1))
. . . . .
. . . . .
Un1un2 … unm un(m+1) … un(c*(m+1))
Selanjutnya, dilakukan perhitungan kuadrat
terkecil (least square) untuk membentuk
matriks K dengan persamaan (2.13) (Fariska,
2008).
(2.13)
Keterangan:
k = koefisien output
Y = nilai target output
U = matriks U
Untuk mempermudah komputasi, matriks K
yang berukuran c x (m+1), disusun menjadi
satu vektor berisi koefisien output yangnantinya digunakan dalam perhitungan
inferensi TSK.
2.3 Analisis Cluster Varian digunakan untuk mengukur nilai
penyebaran dari data-data hasil clustering.
Varian pada clustering ada dua macam, yaitu
variance within cluster dan variance between
cluster . Kepadatan suatu cluster bisa ditentukan
dengan variance within cluster (Vw) dan
variance between cluster (Vb) (Man, dkk.,2009).
Varian pada setiap tahap pembentukan
cluster bisa dihitung dengan persamaan (2.14).
(2.14)
dimana,
Vc2
= varian pada cluster c
c =1..k, dimana k= jumlah cluster
nc = jumlah data pada cluster c
yi = data ke-i pada suatu cluster
= rata-rata dari data pada suatu cluster
Berdasarkan nilai varian cluster yang diperoleh,maka nilai variance within cluster (Vw) dapat
dihitung dengan persamaan (2.15).
(2.15)
dimana,
N = jumlah semua data
ni = jumlah data cluster i
Vi = varian pada cluster i
dan nilai variance between cluster (Vb) dapat
dihitung dengan persamaan (2.16).
(2.16)
dimana, = rata-rata data pada cluster ke-i
sedangkan = rata-rata dari yi.
Salah satu metode yang digunakan untuk
menentukan cluster yang ideal adalah batasan
varian, yaitu dengan menghitung variance
within cluster (Vw) dan variance between
cluster (Vb). Cluster yang ideal mempunyai Vw
minimum yang merepresentasikan internal
homogenity dan Vb maksimum yang
menyatakan external homogenity. Batasan
varian dinyatakan dalam persamaan (2.17).(2.17)
Berdasarkan persamaan (2.17), semakin kecil
nilai batasan varian maka semakin baik
pengklasteran yang dilakukan.
2.4 Akurasi SistemAkurasi merupakan seberapa dekat suatu
angka hasil pengukuran terhadap angka
sebenarnya (true value atau reference value).
Akurasi dapat diperoleh dari persentase
kebenaran, yaitu perbandingan antara jumlahdiagnosa yang tepat dengan jumlah data

5/16/2018 JURNAL PJK - slidepdf.com
http://slidepdf.com/reader/full/jurnal-pjk-55ab571558209 5/8
5
keseluruhan (Nugraha, 2006). Akurasi
dinyatakan dalam persamaan (2.18).
(2.18) (2.18)
3. METODOLOGI DAN PERANCANGAN
3.1 Data Penelitian
Data yang digunakan diambil dari datapenelitian diagnosa Penyakit Jantung Koroner
(PJK) yang dilakukan oleh Wahyuni (2011),
yang diperoleh dari data rekam medik pasien
RSU Saiful Anwar, RSI Unisma Malang, dan
laboratorium cek fisik kesehatan. Data yang
digunakan sebanyak 100 data pasien yang
dinyatakan positif terkena penyakit jantung
koroner.
3.2 Perancangan SistemSistem memiliki 2 proses utama, yaitu proses
pembangkitkan aturan fuzzy dan proses diagnosarisiko PJK dengan sistem fuzzy. Pembangkitan
aturan merepresentasikan proses pelatihan
sedangkan diagnosa PJK merepresentasikan
proses pengujian. Perancangan proses pelatihan
dan pengujian ditunjukkan oleh gambar 3.1 dan
3.2.
Mulai
Input data PJK ¶meter clustering
Clustering data PJK
Analisis varian
Ekstraksi aturan fuzzy
Output aturan fuzzy
Selesai
Clustering data PJK pada c_pil
Pilih jumlah clustervarian terkecil (c_pil)
Apakah c>=2AND c<n?
Pilih hasil clusterdengan varian terkecil
For a=1 to 5
a
ya
tidak
Gambar 3.1 Alur proses pelatihan
Data untuk pelatihan berupa dataset PJK
yang terdiri atas faktor risiko PJK (umur, kadar
LDL, kadar kolesterol total, kadar HDL, kadar
trigliserida, tekanan darah sistolik) dan nilai
risiko PJK. Proses clustering data PJK
dilakukan untuk mengelompokan data dan
menemukan pusat cluster setiap kelompok.
Kemudian, proses analisis varian dilakukanuntuk mendapatkan nilai batasan varian (V)
untuk setiap jumlah cluster yang
diperhitungkan. Rangkaian proses ini dilakukan
secara iteratif hingga kondisi berhenti, dimana
iterasi mencapai jumlah data dikurangi satu (n-
1). Kemudian, dilakukan percobaan clustering
dengan jumlah cluster terpilih/ideal (c_pil)
sebanyak 5 kali. Hasil clustering dipilih
berdasarkan nilai batasan varian minimum dari
ke-5 percobaan tersebut. Kemudian, proses yang
dijalankan adalah ekstraksi aturan fuzzy. Prosesini berguna untuk membangkitkan aturan
sebagai dasar penentuan diagnosa risiko PJK
dalam sistem fuzzy. Aturan fuzzy yang
dihasilkan proses pelatihan berupa data pusat
cluster , standar deviasi, serta koefisien output
dari jumlah cluster terpilih.
Mulai
Input data pengujian (Xj) danaturan fuzzy (αkj dan Vkj)
Fuzzifikasi
Perhitungan nilai Z
Defuzzifikasi
Output Diagnosa risikoPJK
Selesai
Gambar 3.2 Alur proses pengujian
Proses fuzzifikasi berguna untuk mengubah
nilai tegas data (crisp) menjadi nilai fuzzy
(derajat keanggotaan rentang 0 hingga 1). Proses
perhitungan nilai Z berguna untuk mengetahui
nilai output tiap aturan berdasarkan derajat
keanggotaan terhadap aturan tersebut. Proses
defuzzifikasi berguna untuk menghitung nilai
tegas (crisp) dari risiko PJK. Perhitungan nilai Zdan defuzzifikasi dilakukan melalui inferensi
TSK dengan weighted average.

5/16/2018 JURNAL PJK - slidepdf.com
http://slidepdf.com/reader/full/jurnal-pjk-55ab571558209 6/8
6
4. IMPLEMENTASI DAN PEMBAHASAN
4.1 Implementasi ProgramImplementasi program terdiri atas 2 bagian
utama, yaitu:
1. Pelatihan
Proses pelatihan dilakukan untuk
membangkitan aturan fuzzy. Program untuk
pembangkitan aturan fuzzy ditunjukkan gambar4.1.
Gambar 4.1 Program pembangkitan aturan fuzzy
2. PengujianProses pengujian dilakukan untuk
melakukan diagnosa risiko PJK berdasarkan
aturan fuzzy yang terbentuk pada proses
pelatihan. Program untuk melakukan diagnosa
risiko PJK ditunjukkan gambar 4.2.
Gambar 4.2 Program diagnose risiko PJK
4.2 Skenario Uji CobaSkenario terdiri dari 5 kali uji coba dengan
jumlah data latih yang berbeda:
1. Uji coba 1, menggunakan 30 data latih.
2. Uji coba 2, menggunakan 40 data latih.
3. Uji coba 3, menggunakan 50 data latih.
4. Uji coba 4, menggunakan 60 data latih.
5. Uji coba 5, menggunakan 70 data latih.Pada proses pelatihan, iterasi maksimum yang
digunakan adalah 100 sedangkan kesalahan
minimum yang ditetapkan adalah 0,0001. Uji
coba dilakukan terhadap beberapa jumlah aturan
yang berbeda, yaitu pada jumlah cluster ideal
dan beberapa jumlah cluster lainnya sebagai
pembanding. Proses pengujian pada setiap uji
coba menggunakan 30 data uji. Proses ini akan
menghasilkan nilai dan kelas tingkat risiko PJK.
Hasil proses tersebut kemudian dibandingkan
dengan hasil diagnosa acuan yang ada sehinggadapat diketahui nilai akurasi sistem dalam
melakukan diagnosa tingkat risiko
PJK.Pelatihan dan pengujian pada setiap jumlah
aturan dilakukan sebanyak 5 kali percobaan.
Akurasi pengujian setiap jumlah aturan
diperoleh dari rata-rata akurasi pengujian yang
dilakukan sebanyak 5 kali percobaan.
4.3 Analisis Hasil Uji CobaPada beberapa uji coba, akurasi tertinggi
tidak terjadi pada jumlah aturan ideal. Jumlah
aturan ideal ditentukan berdasarkan nilai batasanvarian minimum. Perbandingan akurasi sistem
maksimum dari semua hasil uji coba
ditunjukkan tabel (4.1).
Tabel 4.1 Perbandingan akurasi jumlah cluster
ideal
Uji
coba
A Akurasi
A
B Akurasi
B
1 3 7% 2 33%
2 3 37% 3 37%
3 3 29% 2 37%
4 3 20% 2 47%5 3 38% 2 50%
Keterangan:
A : jumlah aturan ideal menurut sistem
B : jumlah aturan dengan akurasi tertinggi
Berdasarkan tabel (4.1), dapat dilihat
bahwa ada uji coba 1, akurasi hasil pengujian
tertinggi terjadi pada jumlah aturan 2 (33%),
yang mana lebih tinggi dari akurasi jumlah
cluster ideal 3 (7%). Pada uji coba 3, akurasi
hasil pengujian tertinggi terjadi pada jumlah
aturan 2 (37%), yang mana lebih tinggi dari
akurasi jumlah cluster ideal 3 (29%). Pada ujicoba 4, akurasi hasil pengujian tertinggi terjadi
pada jumlah aturan 2 (47%), yang mana lebih
5/16/2018 JURNAL PJK - slidepdf.com
http://slidepdf.com/reader/full/jurnal-pjk-55ab571558209 7/8
7
tinggi dari akurasi jumlah cluster ideal 3 (20%).
Pada uji coba 5, akurasi hasil pengujian tertinggi
terjadi pada jumlah aturan 2 (50%), yang mana
lebih tinggi dari akurasi jumlah cluster ideal 3
(38%). Hanya uji coba 2 yang memberikan hasil
yang positif, dimana jumlah aturan ideal
menghasilkan akurasi tertinggi diantara jumlah
aturan lain yang diujicobakan. Hal inimembuktikan bahwa penentuan jumlah aturan
ideal dengan metode analisis varian belum
optimal.
Setelah melakukan uji coba 1, 2, 3, 4, dan
5, maka akurasi pada setiap uji coba dapat
dibandingkan. Grafik perbandingan akurasi
sistem pada semua uji coba ditunjukkan oleh
gambar (4.3).
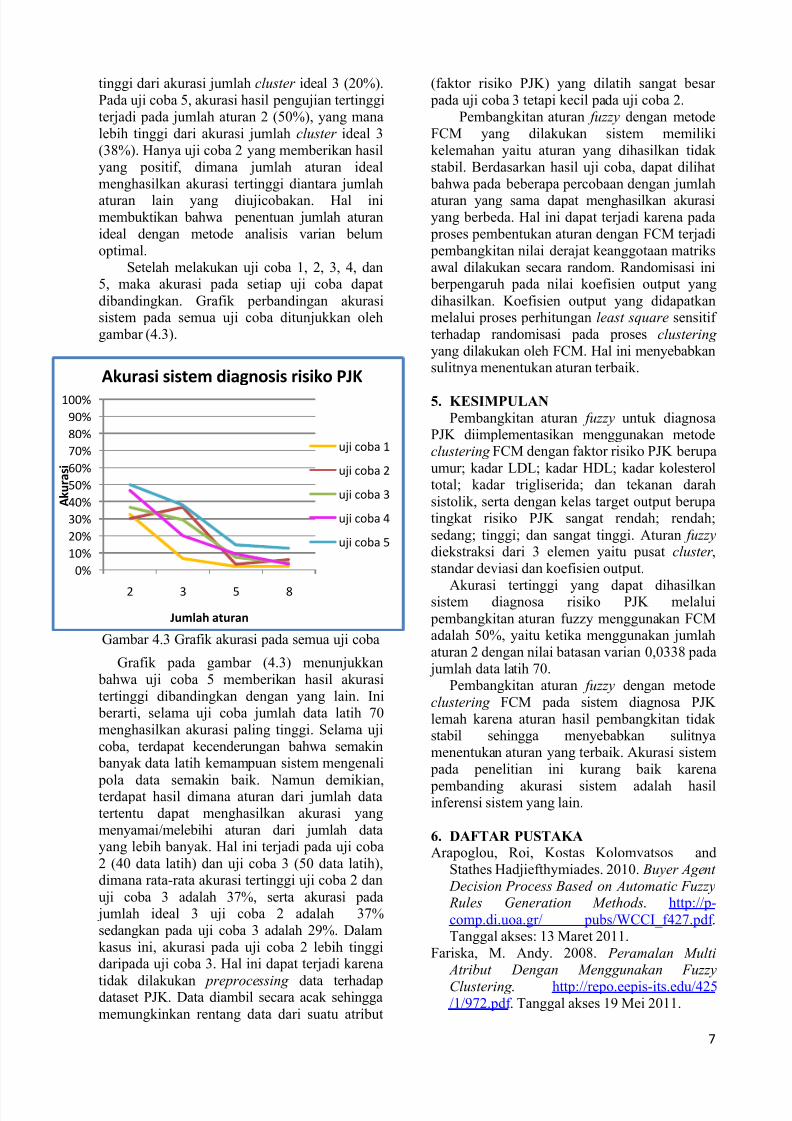
Gambar 4.3 Grafik akurasi pada semua uji coba
Grafik pada gambar (4.3) menunjukkan
bahwa uji coba 5 memberikan hasil akurasi
tertinggi dibandingkan dengan yang lain. Ini
berarti, selama uji coba jumlah data latih 70
menghasilkan akurasi paling tinggi. Selama uji
coba, terdapat kecenderungan bahwa semakin
banyak data latih kemampuan sistem mengenali
pola data semakin baik. Namun demikian,terdapat hasil dimana aturan dari jumlah data
tertentu dapat menghasilkan akurasi yang
menyamai/melebihi aturan dari jumlah data
yang lebih banyak. Hal ini terjadi pada uji coba
2 (40 data latih) dan uji coba 3 (50 data latih),
dimana rata-rata akurasi tertinggi uji coba 2 dan
uji coba 3 adalah 37%, serta akurasi pada
jumlah ideal 3 uji coba 2 adalah 37%
sedangkan pada uji coba 3 adalah 29%. Dalam
kasus ini, akurasi pada uji coba 2 lebih tinggi
daripada uji coba 3. Hal ini dapat terjadi karena
tidak dilakukan preprocessing data terhadapdataset PJK. Data diambil secara acak sehingga
memungkinkan rentang data dari suatu atribut
(faktor risiko PJK) yang dilatih sangat besar
pada uji coba 3 tetapi kecil pada uji coba 2.
Pembangkitan aturan fuzzy dengan metode
FCM yang dilakukan sistem memiliki
kelemahan yaitu aturan yang dihasilkan tidak
stabil. Berdasarkan hasil uji coba, dapat dilihat
bahwa pada beberapa percobaan dengan jumlah
aturan yang sama dapat menghasilkan akurasiyang berbeda. Hal ini dapat terjadi karena pada
proses pembentukan aturan dengan FCM terjadi
pembangkitan nilai derajat keanggotaan matriks
awal dilakukan secara random. Randomisasi ini
berpengaruh pada nilai koefisien output yang
dihasilkan. Koefisien output yang didapatkan
melalui proses perhitungan least square sensitif
terhadap randomisasi pada proses clustering
yang dilakukan oleh FCM. Hal ini menyebabkan
sulitnya menentukan aturan terbaik.
5. KESIMPULANPembangkitan aturan fuzzy untuk diagnosa
PJK diimplementasikan menggunakan metode
clustering FCM dengan faktor risiko PJK berupa
umur; kadar LDL; kadar HDL; kadar kolesterol
total; kadar trigliserida; dan tekanan darah
sistolik, serta dengan kelas target output berupa
tingkat risiko PJK sangat rendah; rendah;
sedang; tinggi; dan sangat tinggi. Aturan fuzzy
diekstraksi dari 3 elemen yaitu pusat cluster ,
standar deviasi dan koefisien output.
Akurasi tertinggi yang dapat dihasilkansistem diagnosa risiko PJK melalui
pembangkitan aturan fuzzy menggunakan FCM
adalah 50%, yaitu ketika menggunakan jumlah
aturan 2 dengan nilai batasan varian 0,0338 pada
jumlah data latih 70.
Pembangkitan aturan fuzzy dengan metode
clustering FCM pada sistem diagnosa PJK
lemah karena aturan hasil pembangkitan tidak
stabil sehingga menyebabkan sulitnya
menentukan aturan yang terbaik. Akurasi sistem
pada penelitian ini kurang baik karena
pembanding akurasi sistem adalah hasilinferensi sistem yang lain.
6. DAFTAR PUSTAKAArapoglou, Roi, Kostas Kolomvatsos and
Stathes Hadjiefthymiades. 2010. Buyer Agent
Decision Process Based on Automatic Fuzzy
Rules Generation Methods. http://p-
comp.di.uoa.gr/ pubs/WCCI_f427.pdf .
Tanggal akses: 13 Maret 2011.
Fariska, M. Andy. 2008. Peramalan Multi
Atribut Dengan Menggunakan Fuzzy
Clustering. http://repo.eepis-its.edu/425
/1/972.pdf . Tanggal akses 19 Mei 2011.
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
2 3 5 8
A k u r a s i
Jumlah aturan
Akurasi sistem diagnosis risiko PJK
uji coba 1
uji coba 2
uji coba 3
uji coba 4
uji coba 5

5/16/2018 JURNAL PJK - slidepdf.com
http://slidepdf.com/reader/full/jurnal-pjk-55ab571558209 8/8
8
Kusumadewi, Sri, Hari Purnomo. 2010. Aplikasi
Logika Fuzzy Untuk Pendukung Keputusan.
Jakarta: Graha Ilmu.
Lee, Kwang H. 2005. First Course on Theory
and Applications. New York: Springer-
Verlag Berlin Heidelberg.
Man L, Chew Lim T, Jian S, Yue L. 2009.
Supervised and Traditional Term Weighting Methods for Automatic Text Categorization.
Pattern Analysis and Machine Intelligence,
IEEE Transactions on.
Nugraha, Dany, dkk. 2006. Diagnosis Gangguan
Sistem Urinari Pada Anjing dan Kucing
Menggunakan VFI 5. Institut Pertanian
Bogor.
Priyono, Agus, dkk. 2007. Generation of Fuzzy
Rules With Substractive Clustering.
http://eprints.utm.my/1460/1/
JTDIS43D%5B10%5Dnew.pdf . Tanggalakses: 13 Maret 2011.
Soeharto, Imam. 2010. Penyakit Jantung
Koroner (PJK): Sebab, Mekanisme, dan
Gejala. http://fkunhas.com/penyakit-jantung-
koroner-pjk-sebab-mekanisme-dan-gejala-
20100716347.html. Tanggal akses: 24 Maret
2011.
Wahyuni, Kristin. 2011. Diagnosis Penyakit
Jantung Koroner (PJK) Berdasarkan Faktor
Risiko Menggunakan Metode FES. Skripsi.
Universitas Brawijaya Malang.
Walpole, Ronald E. 1995. Pengantar Statistika Edisi ke-3. Jakarta: Gramedia Pustaka
Utama.