hadoop
TRANSCRIPT


WHY HADOOP?
• PROSES DATA DENGAN UKURAN YANG SANGAT BESAR
• MAHALNYA HARGA MESIN YANG DAPAT MEMPROSES DATA BESAR DENGAN CEPAT
• EFISIENSI, RELIABEL, DAN MUDAH DIGUNAKAN
• OPEN SOURCE

HADOOP
• SOFTWARE OPENSOURCE DARI APACHE UNTUK KOMPUTASI TERDEISTRIBUSI YANG HANDAL DAN
SKALABILITAS TINGGI
• PEMROSESAN TERDISTRIBUSI DARI KUMPULAN DATA YANG BESAR PADA CLUSTER DENGAN
MENGGUNAKAN PEMROGRAMAN SEDERHANA
• MEMILIKI KEMAMPUAN UNTUK MENDETEKSI DAN MENANGANI KEGAGALAN PADA LAYER APLIKASI UNTUK
MEMBERIKAN LAYANAN HIGH-AVAILABILTY PADA SETIAP CLUSTER

HADOOP
• HDFS
• NAME NODE
• DATA NODE
• MAP/REDUCE
• JOB TRACKER
• TASK TRACKER

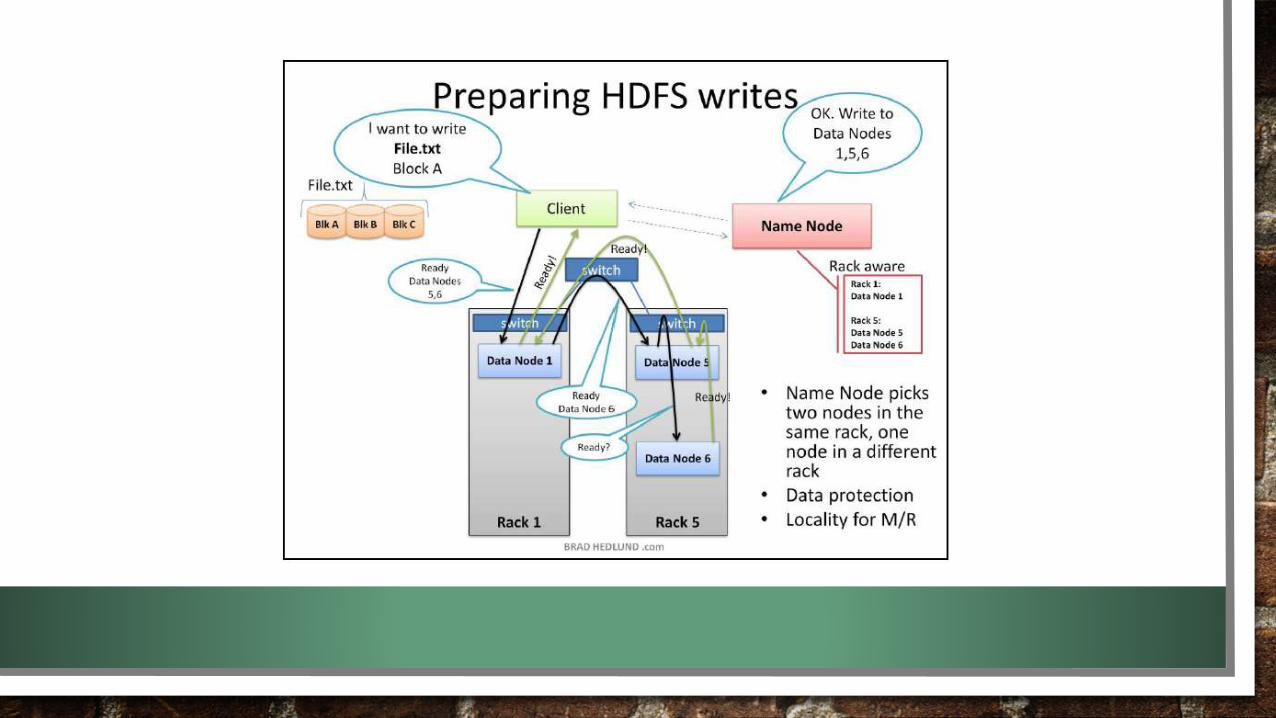
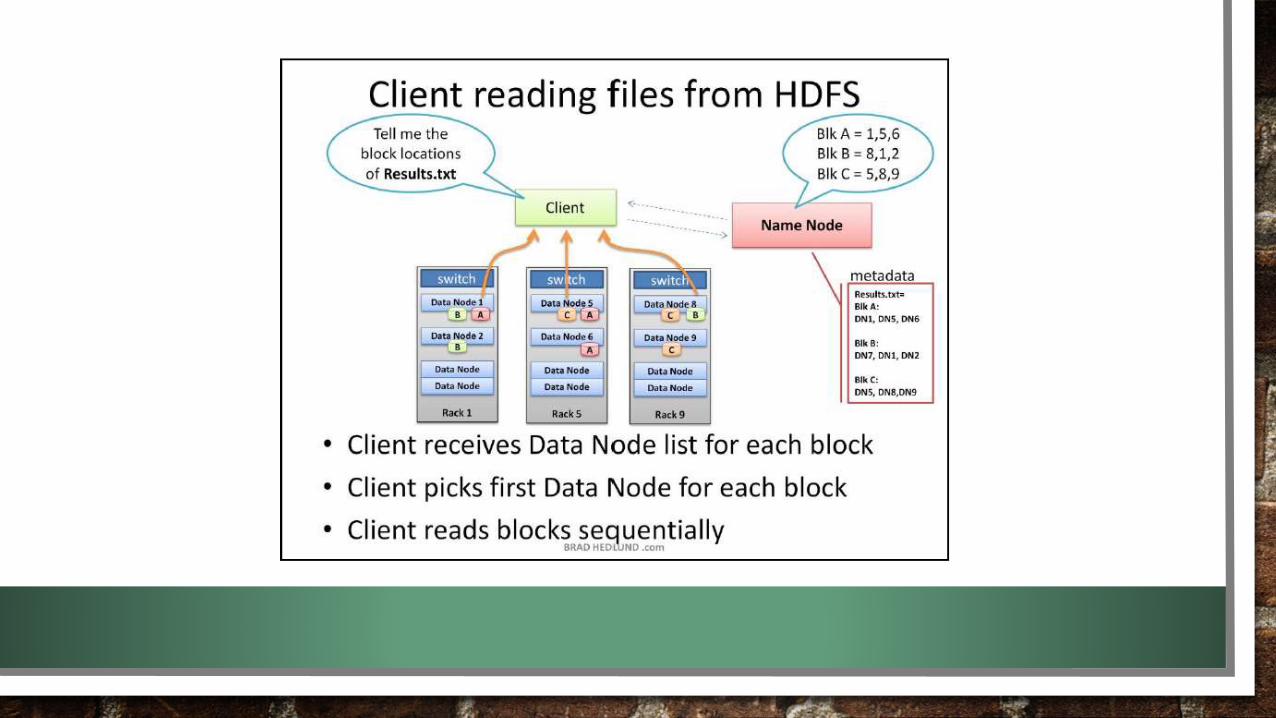
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
• TEMPAT PENYIMPANAN DATA PADA HADOOP TERDIRI DARI NODE-NODE PENYIMPANAN
• DAPAT MENYIMPAN DATA DALAM JUMLAH BESAR
• HIGH-AVAILABILITY (SETIAP DATA DIDUPLIKASI)
• DATA DIPECAH TERLEBIH DAHULU KE DALAM BENTUK BLOCK-BLOCK SEBELUM DIMASUKKAN KE DALAM
HDFS
• TERDIRI DARI DATANODE DAN NAMENODE

NAME NODE
• TEMPAT MENYIMPAN ALAMAT DATA YANG DIMASUKKAN PADA DATA NODE (META DATA)
• MANAGEMEN KONFIGURASI CLUSTER
• MAPPING BLOCK DATA PADA DATANODE
• SATU CLUSTER TERDAPAT 1 NAMENODE YANG BERJALAN

DATA NODE
• TEMPAT PENYIMPANAN BLOCK-BLOCK FILE
• SATU CLUSTER TERDIRI DARI BEBERAPA DATANODE
• BESAR BLOCK TERSERAH ADMIN (BIASANYA 64MB, 128MB, DST)

MAP/REDUCE
• PROGRAMMING MODEL UNTUK PENGOLAHAN DATA SECARA DISTRIBUSI
• PEMROSESAN DIPECAH MENJADI 2, TAHAPAN MAP DAN TAHAPAN REDUCE

WORD COUNT EXAMPLE
• MAPPER
• INPUT: VALUE: LINES OF TEXT OF INPUT
• OUTPUT: KEY: WORD, VALUE: 1
• REDUCER
• INPUT: KEY: WORD, VALUE: SET OF COUNTS
• OUTPUT: KEY: WORD, VALUE: SUM
• LAUNCHING PROGRAM
• DEFINES THIS JOB
• SUBMITS JOB TO CLUSTER

WORD COUNT DATAFLOW

MATUR TENGKYU