excel statistical function
DESCRIPTION
statistikTRANSCRIPT

NAMA : WAN RIZA AZWAR BAROSNIM : 102101064JURUSAN : D3 KEUANGANGRUP : B
AVEDEV fungsi
Pengembalian rata-rata penyimpangan absolut titik data dari rata-rata mereka. AVEDEV merupakan ukuran variabilitas dalam satu set data.
sintaksisAVEDEV (number1, number2, ...)Number1, number2, ... adalah 1-255 argumen yang Anda ingin rata-rata penyimpangan absolut. Anda juga dapat menggunakan array tunggal atau referensi ke array bukan argumen dipisahkan dengan koma.
Keterangan• AVEDEV dipengaruhi oleh unit pengukuran dalam input data.• Argumen baik harus menjadi nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Persamaan untuk deviasi rata-rata adalah:

Contoh :
1
2
3
4
5
6
7
8
A
Data
4
5
6
7
5
4
3
Formula Description (Result)
=AVEDEV(A2:A8)
Average of the absolute deviations of the numbers above from their mean (1.020408)
AVERAGE fungsi
DeskripsiPengembalian rata-rata (aritmatika mean) dari argumen. Misalnya, jika kisaran A1: A20 berisi nomor, rumus = AVERAGE (A1: A20) menghasilkan rata-rata angka-angka.
SintaksisAVERAGE (number1, [number2], ...)Sintaks fungsi AVERAGE memiliki argumentasi sebagai berikut:• Diperlukan number1. Nomor pertama, referensi sel, atau range yang Anda ingin rata-rata.• number2, ... Opsional. Tambahan angka, referensi sel atau rentang yang Anda ingin rata-rata, hingga maksimum 255.
Keterangan• Argumen dapat berupa nomor atau nama, rentang, atau referensi sel yang berisi angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika berbagai argumen atau referensi sel berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika Anda ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, gunakan fungsi AVERAGEA.

• Jika Anda ingin menghitung rata-rata hanya nilai-nilai yang memenuhi kriteria tertentu, gunakan fungsi AVERAGEIF atau fungsi AVERAGEIFS.
CATATAN Fungsi AVERAGE mengukur tendensi sentral, yang merupakan lokasi dari pusat grup nomor dalam distribusi statistik. Tiga langkah yang paling umum tendensi sentral adalah:• Rata-rata, yang merupakan mean aritmetika, dan dihitung dengan menambahkan grup nomor dan kemudian membaginya dengan hitungan angka-angka. Sebagai contoh, rata-rata 2, 3, 3, 5, 7, dan 10 adalah 30 dibagi dengan 6, yang adalah 5.• Median, yang merupakan jumlah tengah sekelompok nomor, yaitu setengah angka memiliki nilai yang lebih besar dari median, dan setengah angka memiliki nilai yang kurang dari median. Sebagai contoh, rata-rata 2, 3, 3, 5, 7, dan 10 adalah 4.• Mode, yang merupakan jumlah yang paling sering terjadi pada sekelompok angka. Sebagai contoh, modus dari 2, 3, 3, 5, 7, dan 10 adalah 3.Untuk distribusi simetris sekelompok nomor, ketiga ukuran tendensi sentral semua sama. Untuk distribusi miring dari sekelompok angka, mereka bisa berbeda.
Contoh :
1
2
3
4
5
6
7
8
9
10
A B C
Data
10 15 32
7
9
27
2
Formula Description Result
=AVERAGE(A2:A6) Average of the numbers in cells A2 through A6.
11
=AVERAGE(A2:A6, 5)
Average of the numbers in cells A2 through A6 and the number 5.
10
=AVERAGE(A2:C2) Average of the numbers in cells A2 through C2.
19
AVERAGEA fungsi
Menghitung rata-rata (aritmatika mean) dari nilai-nilai dalam daftar argumen.

SintaksisAVERAGEA (value1, value2, ...)Value1, value2, ... adalah 1-255 sel, kisaran sel, atau nilai-nilai yang Anda ingin rata-rata.
Keterangan• Argumen bisa menjadi berikut: Nomor; nama, array, atau referensi yang mengandung angka; representasi teks angka, atau nilai-nilai logis, seperti TRUE dan FALSE, dalam referensi.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Argumen yang mengandung BENAR mengevaluasi sebagai 1; argumen yang mengandung mengevaluasi SALAH dengan 0 (nol).• Array atau referensi argumen yang berisi teks mengevaluasi sebagai 0 (nol). Teks kosong ("") mengevaluasi sebagai 0 (nol).• Jika argumen adalah array atau referensi, hanya nilai dalam array atau referensi yang digunakan. Sel kosong dan nilai-nilai teks dalam array atau referensi akan diabaikan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika Anda tidak ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, gunakan fungsi AVERAGE.
CATATAN Fungsi AVERAGEA mengukur tendensi sentral, yang merupakan lokasi dari pusat grup nomor dalam distribusi statistik. Tiga langkah yang paling umum tendensi sentral adalah:• Rata-rata yang merupakan mean aritmetika, dan dihitung dengan menambahkan grup nomor dan kemudian membaginya dengan hitungan angka-angka. Sebagai contoh, rata-rata 2, 3, 3, 5, 7, dan 10 adalah 30 dibagi dengan 6, yang adalah 5.• Median yang merupakan jumlah tengah sekelompok nomor; yang, setengah angka memiliki nilai yang lebih besar dari median, dan setengah angka memiliki nilai yang kurang dari median. Sebagai contoh, rata-rata 2, 3, 3, 5, 7, dan 10 adalah 4.• Mode yang merupakan jumlah yang paling sering terjadi pada sekelompok angka. Sebagai contoh, modus dari 2, 3, 3, 5, 7, dan 10 adalah 3.Untuk distribusi simetris sekelompok nomor, ketiga ukuran tendensi sentral semua sama. Untuk distribusi miring dari sekelompok angka, mereka bisa berbeda.
Contoh :
1A
Data

2
3
4
5
6
7
10
7
9
2
Not available
Formula Description (Result)
=AVERAGEA(A2:A6) Average of the numbers above, and the text "Not Available". The cell with the text "Not available" is used in the calculation. (5.6)
=AVERAGEA(A2:A5,A7) Average of the numbers above, and the empty cell. (7)
AVERAGEIF fungsi
Pengembalian rata-rata (aritmatika mean) dari semua sel dalam suatu range yang memenuhi kriteria tertentu.
sintaksisAVERAGEIF (range, kriteria, average_range)Rentang adalah satu atau lebih sel untuk rata-rata, termasuk nomor atau nama, array, atau referensi yang mengandung angka.Kriteria adalah kriteria dalam bentuk nomor, ekspresi, referensi sel, atau teks yang mendefinisikan sel dirata-ratakan. Sebagai contoh, kriteria dapat dinyatakan sebagai 32, "32", "> 32", "apel", atau B4.Average_range adalah himpunan yang sebenarnya dari sel untuk rata-rata. Jika diabaikan, rentang digunakan.
Keterangan• Sel dalam rentang yang berisi TRUE atau FALSE diabaikan.• Jika sebuah sel di average_range adalah sel kosong, AVERAGEIF mengabaikannya.• Jika rentang nilai kosong atau teks, AVERAGEIF mengembalikan # DIV0! nilai kesalahan.• Jika sebuah sel dalam kriteria kosong, AVERAGEIF memperlakukan sebagai nilai 0.• Jika tidak ada sel dalam kisaran memenuhi kriteria, AVERAGEIF mengembalikan DIV # / 0! nilai kesalahan.• Anda dapat menggunakan karakter wildcard, tanda tanya (?) Dan tanda bintang (*), dalam kriteria. Tanda tanya cocok dengan satu karakter apapun; tanda bintang pertandingan setiap urutan karakter. Jika Anda ingin menemukan tanda tanya yang sebenarnya atau tanda bintang, ketik tilde (~) sebelum karakter.
• Average_range tidak harus menjadi ukuran yang sama dan bentuk sebagai jangkauan. Sel-sel aktual yang rata-rata ditentukan dengan menggunakan sel, kiri atas di average_range

sebagai sel awal, dan kemudian termasuk sel-sel yang sesuai dalam ukuran dan bentuk untuk jangkauan. Sebagai contoh:
IF RANGE IS
AND AVERAGE_RANGE IS
THEN THE ACTUAL CELLS EVALUATED ARE
A1:A5 B1:B5 B1:B5
A1:A5 B1:B3 B1:B5
A1:B4 C1:D4 C1:D4
A1:B4 C1:C2 C1:D4
CATATAN Fungsi AVERAGEIF mengukur tendensi sentral, yang merupakan lokasi dari pusat grup nomor dalam distribusi statistik. Tiga langkah yang paling umum tendensi sentral adalah:• Rata-rata yang merupakan mean aritmetika, dan dihitung dengan menambahkan grup nomor dan kemudian membaginya dengan hitungan angka-angka. Sebagai contoh, rata-rata 2, 3, 3, 5, 7, dan 10 adalah 30 dibagi dengan 6, yang adalah 5.• Median yang merupakan jumlah tengah sekelompok nomor; yang, setengah angka memiliki nilai yang lebih besar dari median, dan setengah angka memiliki nilai yang kurang dari median. Sebagai contoh, rata-rata 2, 3, 3, 5, 7, dan 10 adalah 4.• Mode yang merupakan jumlah yang paling sering terjadi pada sekelompok angka. Sebagai contoh, modus dari 2, 3, 3, 5, 7, dan 10 adalah 3.
Contoh: nilai properti Averaging dan komisi
1234567
8
9
A B
Property Value Commission
100,000 7,000
200,000 14,000
300,000 21,000
400,000 28,000
Formula Description (result)
=AVERAGEIF(B2:B5,"<23000") Average of all commissions less than 23,000 (14,000)
=AVERAGEIF(A2:A5,"<95000") Average of all property values less than 95,000 (#DIV/0!)
=AVERAGEIF(A2:A5,">250000",B2:B5)
Average of all commissions with a property value greater than 250,000 (24,500)
Contoh: Averaging keuntungan dari kantor regional

1
2
3
4
5
6
7
8
9
A B
Region Profits (Thousands)
East 45,678
West 23,789
North -4,789
South (New Office) 0
MidWest 9,678
Formula Description (result)
=AVERAGEIF(A2:A6,"=*West",B2:B6) Average of all profits for the West and MidWest regions (16,733.5)
=AVERAGEIF(A2:A6,"<>*(New Office)",B2:B6)
Average of all profits for all regions excluding new offices (18,589)
AVERAGEIFS fungsi
Pengembalian rata-rata (aritmatika mean) dari semua sel yang memenuhi beberapa kriteria.
SintaksisAVERAGEIFS (average_range, criteria_range1, criteria1, criteria_range2, criteria2 ...)Average_range adalah satu atau lebih sel untuk rata-rata, termasuk nomor atau nama, array, atau referensi yang mengandung angka.Criteria_range1, criteria_range2, ... adalah 1-127 berkisar di mana untuk mengevaluasi kriteria yang terkait.Criteria1, criteria2, ... adalah 1-127 kriteria dalam bentuk nomor, ekspresi, referensi sel, atau teks yang menentukan mana sel-sel akan dirata-ratakan. Sebagai contoh, kriteria dapat dinyatakan sebagai 32, "32", "> 32", "apel", atau B4.Keterangan• Jika average_range adalah nilai kosong atau teks, AVERAGEIFS mengembalikan # DIV0! nilai kesalahan.• Jika sebuah sel di berbagai kriteria kosong, AVERAGEIFS memperlakukan sebagai nilai 0.• Sel dalam rentang yang mengandung BENAR mengevaluasi sebagai 1; sel dalam kisaran yang mengandung mengevaluasi SALAH dengan 0 (nol).• Setiap sel dalam average_range digunakan dalam perhitungan rata-rata hanya jika semua kriteria sesuai yang ditentukan adalah benar untuk sel tersebut.• Berbeda dengan berbagai kriteria dan argumen dalam fungsi AVERAGEIF, dalam AVERAGEIFS criteria_range masing-masing harus sama ukuran dan bentuk sebagai jumlah_rentang.• Jika sel-sel di average_range tidak dapat diterjemahkan ke dalam angka, AVERAGEIFS mengembalikan # DIV0! nilai kesalahan.• Jika tidak ada sel yang memenuhi semua kriteria, AVERAGEIFS mengembalikan DIV # /

0! nilai kesalahan.• Anda dapat menggunakan karakter wildcard, tanda tanya (?) Dan tanda bintang (*), dalam kriteria. Tanda tanya cocok dengan satu karakter apapun; tanda bintang pertandingan setiap urutan karakter. Jika Anda ingin menemukan tanda tanya yang sebenarnya atau tanda bintang, ketik tilde (~) sebelum karakter.Perhatikan fungsi AVERAGEIFS mengukur tendensi sentral, yang merupakan lokasi dari pusat grup nomor dalam distribusi statistik. Tiga langkah yang paling umum tendensi sentral adalah:• Rata-rata yang merupakan mean aritmetika, dan dihitung dengan menambahkan grup nomor dan kemudian membaginya dengan hitungan angka-angka. Sebagai contoh, rata-rata 2, 3, 3, 5, 7, dan 10 adalah 30 dibagi dengan 6, yang adalah 5.• Median yang merupakan jumlah tengah sekelompok nomor; yang, setengah angka memiliki nilai yang lebih besar dari median, dan setengah angka memiliki nilai yang kurang dari median. Sebagai contoh, rata-rata 2, 3, 3, 5, 7, dan 10 adalah 4.• Mode yang merupakan jumlah yang paling sering terjadi pada sekelompok angka. Sebagai contoh, modus dari 2, 3, 3, 5, 7, dan 10 adalah 3.
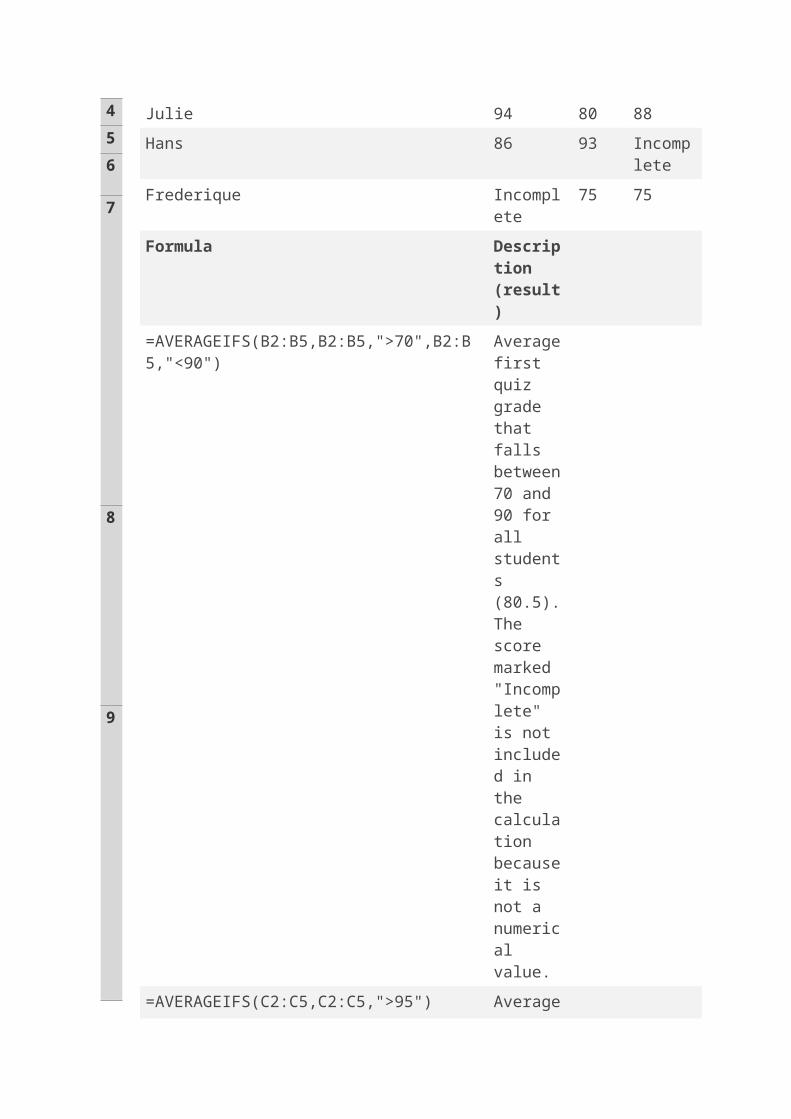
Contoh: Averaging siswa kelas
1
2
3
4
5
6
7
A B C D
Student First Quiz Grade
Second Quiz Grade
Final Exam Grade
Emilio 75 85 87
Julie 94 80 88
Hans 86 93 Incomplete
Frederique Incomplete
75 75
Formula Description (result)
=AVERAGEIFS(B2:B5,B2:B5,">70",B2:B5,"<90")
Average first quiz grade that falls between 70 and 90 for all students (80.5). The score marked "Incomplete" is not

8
9
included in the calculation because it is not a numerical value.
=AVERAGEIFS(C2:C5,C2:C5,">95") Average second quiz grade that is greater than 95 for all students. Because there are no scores greater than 95, #DIV0! is returned.
=AVERAGEIFS(D2:D5,D2:D5,"<>Incomplete",D2:D5,">80")
Average final exam grade that is greater than 80 for all students (87.5). The score marked "Incomplete" is not included in the calculation because it is not a numerical value.
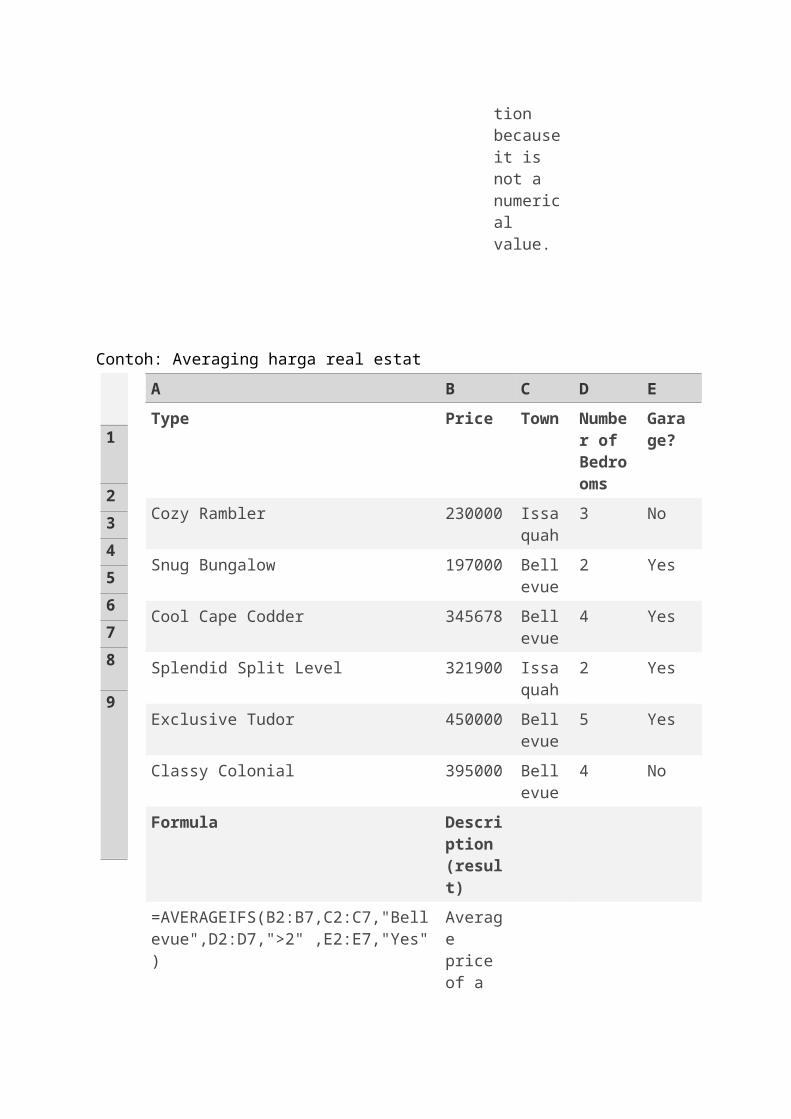
Contoh: Averaging harga real estat
A B C D E

1
2
3
4
5
6
7
8
9
10
Type Price Town Number of Bedrooms
Garage?
Cozy Rambler 230000 Issaquah
3 No
Snug Bungalow 197000 Bellevue
2 Yes
Cool Cape Codder 345678 Bellevue
4 Yes
Splendid Split Level 321900 Issaquah
2 Yes
Exclusive Tudor 450000 Bellevue
5 Yes
Classy Colonial 395000 Bellevue
4 No
Formula Description (result)
=AVERAGEIFS(B2:B7,C2:C7,"Bellevue",D2:D7,">2" ,E2:E7,"Yes")
Average price of a home in Bellevue that has at least 3 bedrooms and a garage (397839)
=AVERAGEIFS(B2:B7,C2:C7,"Issaquah",D2:D7,"<=3" ,E2:E7,"No")
Average price of a home in Issaquah that has up to 3 bedrooms and no garage (230000)
BETADIST fungsi
Mengembalikan fungsi kerapatan probabilitas kumulatif beta. Distribusi beta umumnya digunakan untuk mempelajari variasi dalam persentase sesuatu di seluruh sampel, seperti sebagian kecil dari orang menghabiskan hari menonton televisi.
SintaksisBETADIST (x, alfa, beta, A, B)X adalah nilai antara A dan B di mana untuk mengevaluasi fungsi.Alpha adalah parameter dari distribusi.Beta adalah parameter dari distribusi.A adalah lebih rendah opsional terikat pada interval x.B adalah opsional atas terikat pada interval x.
Keterangan• Jika argumen apapun nonnumeric, BETADIST mengembalikan # VALUE! nilai kesalahan.• Jika alpha ≤ 0 atau beta ≤ 0, BETADIST mengembalikan NUM #! nilai kesalahan.• Jika x <A, x> B, atau A = B, BETADIST mengembalikan NUM #! nilai kesalahan.• Jika Anda menghilangkan nilai-nilai untuk A dan B, BETADIST menggunakan standar distribusi beta kumulatif, sehingga A = 0 dan B = 1.
Contoh
1
2
3
4
5
6
A B
Data Description
2 Vlue at which to evaluate the function
8 Parameter of the distribution
10 Parameter of the distribution
1 Lower bound
3 Upper bound
Formula Description (Result)
=BETADIST(A2,A3,A4,A5,A6)
Cumulative beta probability density function, for the above parameters (0.685470581)
BETAINV fungsi
Mengembalikan kebalikan dari fungsi probabilitas beta kepadatan kumulatif untuk distribusi beta tertentu. Artinya, jika probabilitas = BETADIST (x, ...), kemudian BETAINV (probabilitas, ...) = x. Distribusi beta dapat digunakan dalam perencanaan proyek untuk

model waktu penyelesaian kemungkinan diberi waktu penyelesaian yang diharapkan dan variabilitas.
SintaksisBETAINV (probabilitas, alfa, beta, A, B)Probabilitas adalah kemungkinan terkait dengan distribusi beta.Alpha adalah parameter dari distribusi.Beta adalah parameter distribusi.A adalah lebih rendah opsional terikat pada interval x.B adalah opsional atas terikat pada interval x.
Keterangan• Jika argumen apapun nonnumeric, BETAINV mengembalikan # VALUE! nilai kesalahan.• Jika alpha ≤ 0 atau beta ≤ 0, BETAINV mengembalikan NUM #! nilai kesalahan.• Jika probabilitas ≤ 0 atau probabilitas> 1, BETAINV mengembalikan NUM #! nilai kesalahan.• Jika Anda menghilangkan nilai-nilai untuk A dan B, BETAINV menggunakan standar distribusi beta kumulatif, sehingga A = 0 dan B = 1.Mengingat nilai probabilitas, BETAINV berusaha bahwa x nilai seperti yang BETADIST (x, alfa, beta, A, B) = probabilitas. Dengan demikian, ketepatan BETAINV tergantung pada ketepatan BETADIST. BETAINV menggunakan teknik iteratif pencarian. Jika pencarian tidak berkumpul setelah 100 iterasi, fungsi mengembalikan # N / A nilai kesalahan.
Contoh
1
2
3
4
5
6
A B
Data Description
0.685470581 Probability associated with the beta distribution
8 Parameter of the distribution
10 Parameter of the distribution
1 Lower bound
3 Upper bound
Formula Description (Result)
=BETAINV(A2,A3,A4,A5,A6)
Inverse of the cumulative beta probability density function for the parameters above (2)
BINOMDIST fungsi
Mengembalikan probabilitas distribusi individu istilah binomial. Gunakan BINOMDIST dalam masalah dengan tetap jumlah tes atau uji coba, ketika hasil dari percobaan pun hanya keberhasilan atau kegagalan, ketika uji coba yang independen, dan ketika probabilitas keberhasilan adalah konstan sepanjang percobaan. Sebagai contoh, BINOMDIST dapat menghitung probabilitas bahwa dua dari tiga bayi berikutnya lahir adalah pria.
SintaksisBINOMDIST (number_s, percobaan, probability_s, kumulatif)Number_s adalah jumlah sukses dalam percobaan.Ujian adalah jumlah percobaan independen.Probability_s adalah probabilitas keberhasilan pada setiap percobaan.Kumulatif adalah nilai logis yang menentukan bentuk dari fungsi. Jika kumulatif adalah TRUE, maka BINOMDIST mengembalikan fungsi distribusi kumulatif, yang merupakan probabilitas bahwa ada pada keberhasilan number_s paling, jika FALSE, ia mengembalikan fungsi probabilitas massa, yang merupakan probabilitas bahwa ada keberhasilan number_s.
Keterangan• Number_s dan uji coba yang dipotong ke integer.• Jika number_s, pencobaan, atau probability_s adalah nonnumeric, BINOMDIST mengembalikan # VALUE! nilai kesalahan.• Jika number_s <0 atau number_s> percobaan, BINOMDIST mengembalikan NUM #! nilai kesalahan.• Jika probability_s <0 atau probability_s> 1, BINOMDIST mengembalikan NUM #! nilai kesalahan.• Fungsi probabilitas binomial massa adalah:
dimana:
adalah COMBIN (n, x).Distribusi binomial kumulatif adalah:
Contoh
1
2
3
4
A B
Data Description
6 Number of successes in trials
10 Number of independent trials
0.5 Probability of success on each trial
Formula Description (Result)

=BINOMDIST(A2,A3,A4,FALSE)
Probability of exactly 6 of 10 trials being successful (0.205078)
CHIDIST fungsi
Mengembalikan kemungkinan satu-ekor dari distribusi chi-kuadrat. Distribusi χ2 dikaitkan dengan tes χ2. Gunakan tes χ2 untuk membandingkan nilai diamati dan diharapkan. Sebagai contoh, sebuah percobaan genetik mungkin berhipotesis bahwa generasi berikutnya tanaman akan menunjukkan satu set tertentu dari warna. Dengan membandingkan hasil pengamatan dengan yang diharapkan, Anda dapat memutuskan apakah hipotesis asli Anda valid.
SintaksisCHIDIST (x, degrees_freedom)X adalah nilai di mana Anda ingin mengevaluasi distribusi.Degrees_freedom adalah jumlah derajat kebebasan.
Keterangan• Jika argumen baik adalah nonnumeric, CHIDIST mengembalikan # VALUE! nilai kesalahan.• Jika x adalah negatif, CHIDIST mengembalikan NUM #! nilai kesalahan.• Jika degrees_freedom tidak integer, itu terpotong.• Jika degrees_freedom <1 atau degrees_freedom> 10 ^ 10, CHIDIST mengembalikan NUM #! nilai kesalahan.• CHIDIST dihitung sebagai CHIDIST = P (X> x), dimana X adalah variabel acak χ2.
Contoh
1
2
3
A B
Data Description
8.307Value at which you want to evaluate the distribution
10 Degrees of freedom
Formula Description (Result)
=CH One-tailed probability of the chi-squared distribution, for the

IST(
,A3)
above terms (0.050001)
CHIINV fungsi
Mengembalikan kebalikan dari probabilitas satu-ekor dari distribusi chi-kuadrat. Jika probabilitas = CHIDIST (x, ...), kemudian CHIINV (probabilitas, ...) = x. Gunakan fungsi ini untuk membandingkan hasil yang diamati dengan yang diharapkan untuk memutuskan apakah hipotesis asli Anda valid.
SintaksisCHIINV (probabilitas, degrees_freedom)Probabilitas adalah kemungkinan terkait dengan distribusi chi-kuadrat.Degrees_freedom adalah jumlah derajat kebebasan.
Keterangan• Jika argumen baik adalah nonnumeric, CHIINV mengembalikan # VALUE! nilai kesalahan.• Jika probabilitas <0 atau probabilitas> 1, CHIINV mengembalikan NUM #! nilai kesalahan.• Jika degrees_freedom tidak integer, itu terpotong.• Jika degrees_freedom <1 atau degrees_freedom> 10 ^ 10, CHIINV mengembalikan NUM #! nilai kesalahan.Mengingat nilai probabilitas, CHIINV berusaha bahwa x nilai seperti yang CHIDIST (x, degrees_freedom) = probabilitas. Dengan demikian, ketepatan CHIINV tergantung pada ketepatan CHIDIST. CHIINV menggunakan teknik iteratif pencarian. Jika pencarian tidak berkumpul setelah 100 iterasi, fungsi mengembalikan # N / A nilai kesalahan.
Contoh
1
2
3
A B
Data Description
0.050001 Probability associated with the chi-squared distribution
10 Degrees of freedom
Formula Description (Result)
=CHIINV(A2,A3)
Inverse of the one-tailed probability of the chi-squared distribution (18.3069735)

CHITEST fungsi
Mengembalikan tes untuk kemerdekaan. CHITEST mengembalikan nilai dari distribusi chi-kuadrat (χ2) untuk statistik dan derajat kebebasan yang tepat. Anda dapat menggunakan χ2 tes untuk menentukan apakah hasil hipotesis diverifikasi oleh percobaan.
SintaksisCHITEST (actual_range, expected_range)Actual_range adalah rentang data yang berisi pengamatan uji terhadap nilai yang diharapkan.Expected_range adalah rentang data yang berisi rasio produk dari total baris dan total kolom ke grand total.
Keterangan• Jika actual_range dan expected_range memiliki nomor yang berbeda dari titik data, CHITEST mengembalikan # N / A nilai kesalahan.• Uji χ2 pertama menghitung statistik χ2 menggunakan rumus:dimana:
Aij = frekuensi yang sebenarnya di-i, kolom baris ke-jEij = frekuensi diharapkan dalam ke-i, kolom baris ke-jr = jumlah baris atauc = jumlah kolom
• Nilai rendah χ2 merupakan indikator kemerdekaan. Seperti dapat dilihat dari rumus, χ2 selalu positif atau 0, dan 0 hanya jika Aij = Eij untuk setiap i, j.
• CHITEST mengembalikan probabilitas bahwa nilai statistik χ2 setidaknya setinggi nilai yang dihitung dengan rumus di atas bisa terjadi secara kebetulan di bawah asumsi kemerdekaan. Dalam menghitung probabilitas ini, CHITEST menggunakan distribusi χ2 dengan jumlah yang sesuai derajat kebebasan, df. Jika r> 1 dan c> 1, maka df = (r - 1) (c - 1). Jika r = 1 dan c> 1, maka df = c - 1 atau jika r> 1 dan c = 1, maka df = r - 1. r = c = 1 tidak diperbolehkan dan # N / A dikembalikan.• Penggunaan CHITEST paling tepat saat ini Eij tidak terlalu kecil. Beberapa statistik menunjukkan bahwa setiap Eij harus lebih besar dari atau sama dengan 5.
Contoh
1
2
A B C
Men (Actual) Women (Actual) Description
58 35 Agree

3
4
5
6
7
8
11 25 Neutral
10 23 Disagree
Men (Expected) Women (Expected) Description
45.35 47.65 Agree
17.56 18.44 Neutral
16.09 16.91 Disagree
Formula Description (Result)
=CHITEST(A2:B4,A6:B8)
The χ2 statistic for the data above is 16.16957 with 2 degrees of freedom (0.000308)
CONFIDENCE fungsi
Mengembalikan nilai yang dapat Anda gunakan untuk membangun selang kepercayaan untuk rata-rata populasi. Interval kepercayaan adalah rentang nilai. Sampel rata-rata Anda, x, adalah pusat kisaran ini dan kisaran adalah x ± CONFIDENCE. Misalnya, jika x adalah rata-rata sampel dari waktu pemesanan produk yang dipesan melalui surat, x ± CONFIDENCE adalah berbagai mean populasi. Untuk setiap rata-rata populasi, μ0, dalam kisaran ini, peluang mendapatkan sampel berarti lebih jauh dari μ0 dari x lebih besar dari alpha, karena populasi setiap Maksudku, μ0, tidak dalam kisaran ini, peluang mendapatkan sampel berarti lebih jauh dari μ0 dari x lebih kecil dari alfa. Dengan kata lain, menganggap bahwa kita menggunakan x, standard_dev, dan ukuran untuk membangun sebuah uji dua sisi pada tingkat signifikansi alpha hipotesis bahwa penduduk maksud adalah μ0. Kemudian kita tidak akan menolak hipotesis bahwa jika μ0 adalah dalam interval kepercayaan dan akan menolak hipotesis bahwa jika μ0 tidak dalam interval kepercayaan. Interval keyakinan tidak memungkinkan kita untuk menyimpulkan bahwa ada peluang 1 - alpha bahwa paket kami berikutnya akan memakan waktu pengiriman yang ada di interval kepercayaan.
SintaksisCONFIDENCE (alfa, standard_dev, ukuran)Alpha adalah tingkat signifikansi yang digunakan untuk menghitung tingkat kepercayaan. Tingkat kepercayaan sama dengan 100 * (1 - alpha)%, atau dengan kata lain, alpha 0,05 menunjukkan tingkat kepercayaan 95 persen.Standard_dev adalah deviasi standar populasi untuk rentang data dan diasumsikan diketahui.Ukuran adalah ukuran sampel.
Keterangan• Jika argumen apapun nonnumeric, CONFIDENCE mengembalikan # VALUE! nilai kesalahan.• Jika alpha ≤ 0 atau alpha ≥ 1, CONFIDENCE mengembalikan NUM #! nilai kesalahan.• Jika standard_dev ≤ 0, CONFIDENCE mengembalikan NUM #! nilai kesalahan.• Jika ukuran tidak integer, itu terpotong.

• Jika ukuran <1, CONFIDENCE mengembalikan NUM #! nilai kesalahan.• Jika kita berasumsi sama dengan alpha 0,05, kita perlu menghitung luas area di bawah kurva normal standar yang sama (1 - alpha), atau 95 persen. Nilai ini adalah ± 1,96. Interval keyakinan karena itu:
ContohMisalkan kita mengamati bahwa, dalam sampel kami dari 50 penumpang, rata-rata panjang perjalanan untuk bekerja adalah 30 menit dengan standar deviasi populasi 2,5. Dengan alpha = .05, CONFIDENCE (.05, 2,5, 50) kembali 0,692952. Interval keyakinan yang sesuai adalah dari 30 ± 0,692952 = sekitar [29,3, 30,7]. Untuk setiap rata-rata populasi, μ0, dalam interval ini, peluang mendapatkan sampel berarti lebih jauh dari μ0 dari 30 lebih dari 0,05. Demikian juga, untuk setiap rata-rata populasi, μ0, di luar interval ini, peluang mendapatkan sampel berarti lebih jauh dari μ0 dari 30 kurang dari 0,05.
1
2
3
4
A B
Data Description
0.05 Significance level
2.5 Standard deviation of the population
50 Sample size
Formula Description (Result)
=CONFIDENCE(A2,A3,A4)
Confidence interva fr a population mean. In other words, the confidence interval for the underlying population mean for travel to work equals 30 ± 0.692952 minutes, or 29.3 to 30.7 minutes. (0.692952)
CORREL fungsi
Mengembalikan koefisien korelasi dari array1 dan array2 rentang sel. Gunakan koefisien korelasi untuk mengetahui hubungan antara dua sifat. Sebagai contoh, Anda dapat menguji hubungan antara suhu rata-rata lokasi dan penggunaan AC.
SintaksisCORREL (array1, array2)Array1 adalah rentang sel nilai.Array2 adalah berbagai sel kedua nilai.
Keterangan• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.

• Jika array1 dan array2 memiliki nomor yang berbeda dari titik data, CORREL mengembalikan # N / A nilai kesalahan.• Jika salah array1 atau array2 kosong, atau jika s (deviasi standar) dari nilai-nilai mereka sama dengan nol, CORREL mengembalikan DIV # / 0! nilai kesalahan.• Persamaan untuk koefisien korelasi adalah:
Contohdi mana x dan y adalah sampel berarti RATA-RATA (array1) dan RATA-RATA (array2).
1
2
3
4
5
6
A B
Data1 Data2
3 9
2 7
4 12
5 15
6 17
Formula Description (Result)
=CORREL(A2:A6,B2:B6) Correlation coefficient of the two data sets above (0.997054)
COUNT fungsi
DeskripsiFungsi COUNT menghitung jumlah sel yang berisi angka, dan angka jumlah dalam daftar argumen. Gunakan fungsi COUNT untuk mendapatkan jumlah entri dalam field nomor yang berada dalam jangkauan atau array angka. Sebagai contoh, Anda dapat memasukkan rumus berikut untuk menghitung angka-angka dalam kisaran A1: A20:= COUNT (A1: A20)Dalam contoh ini, jika lima dari sel-sel dalam kisaran mengandung angka, hasilnya adalah 5.
SintaksisCOUNT (value1, [value2], ...)Sintaks fungsi COUNT memiliki argumen ini:• Diperlukan nilai1. Item pertama, referensi sel, atau range di mana Anda ingin menghitung angka.• nilai2, ... Opsional. Hingga 255 item tambahan, referensi sel, atau rentang di mana Anda ingin menghitung angka.

Perhatikan argumen dapat berisi atau mengacu pada berbagai berbagai jenis data, tetapi hanya angka-angka tersebut dihitung.
Keterangan• Argumen yang nomor, tanggal, atau representasi teks nomor (misalnya, nomor tertutup dalam tanda kutip, seperti "1") dihitung.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor tersebut tidak dihitung.• Jika argumen adalah array atau referensi, angka saja dalam array atau referensi dihitung. Sel kosong, nilai-nilai logis, teks, atau nilai-nilai kesalahan dalam array atau referensi tidak dihitung.• Jika Anda ingin menghitung nilai-nilai logis, teks, atau nilai kesalahan, gunakan fungsi COUNTA.• Jika Anda ingin menghitung angka saja yang memenuhi kriteria tertentu, gunakan fungsi COUNTIF atau fungsi COUNTIFS.
Contoh
1
2
3
4
5
6
7
8
9
10
A B C
Data
Sales
12/8/2008
19
22.24
TRUE
#DIV/0!
Formula Description Result
=COUNT(A2:A8) Counts the number of cells that contain numbers in cells A2 through A8.
3

11
12
=COUNT(A5:A8) Counts the number of cells that contain numbers in cells A5 through A8.
2
=COUNT(A2:A8,2) Counts the number of cells that contain numbers in cells A2 through A8, and the value 2
COUNTA fungsi
DeskripsiFungsi COUNTA menghitung jumlah sel yang tidak kosong di kisaran.
SintaksisCOUNTA (nilai1, [value2], ...)Sintaks fungsi COUNTA memiliki argumentasi sebagai berikut:• Diperlukan nilai1. Argumen pertama yang mewakili nilai-nilai yang Anda ingin menghitung.• nilai2, ... Opsional. Tambahan argumen yang mewakili nilai-nilai yang Anda ingin menghitung, hingga maksimal 255 argumen.Keterangan• Fungsi COUNTA jumlah sel yang mengandung semua jenis informasi, termasuk nilai kesalahan dan teks kosong (""). Misalnya, jika kisaran berisi formula yang mengembalikan string kosong, fungsi COUNTA menghitung nilai tersebut. Fungsi COUNTA tidak menghitung sel kosong.• Jika Anda tidak perlu untuk menghitung nilai-nilai logis, teks, atau nilai kesalahan (dengan kata lain, jika Anda ingin menghitung sel-sel hanya yang mengandung angka), menggunakan fungsi COUNT.
• Jika Anda ingin menghitung sel hanya yang memenuhi kriteria tertentu, gunakan fungsi COUNTIF atau fungsi COUNTIFS.
Contoh
1
2
3
4
5
6
7
8
9
A B C
Data
Sales
12/8/2008
19
22.24
TRUE
#DIV/0!

10Formula Description Result
=COUNTA(A2:A8) Counts the number of nonblank cells in cells A2 through A8.
6
COUNTBLANK fungsi
Menghitung sel kosong dalam rentang tertentu dari sel.
SintaksisCOUNTBLANK (kisaran)Range adalah dari mana Anda ingin menghitung sel kosong.UcapanSel dengan formula yang kembali "" (teks kosong) juga dihitung. Sel dengan nilai nol tidak dihitung.
Contoh
1
2
3
4
5
A B
Data Data
6 =IF(B4<30,"",B4)
27
4 34
Formula Description (Result)
=COUNTBLANK(A2:B5)
Counts empty cells in the range above. The formula returns empty text. (4)
COUNTIF fungsi
DeskripsiFungsi COUNTIF menghitung jumlah sel dalam suatu range yang memenuhi satu kriteria

yang Anda tentukan. Misalnya, Anda dapat menghitung semua sel yang dimulai dengan huruf tertentu, atau Anda dapat menghitung semua sel yang berisi angka yang lebih besar atau lebih kecil dari jumlah yang Anda tentukan. Sebagai contoh, misalkan Anda memiliki worksheet yang berisi daftar tugas di kolom A, dan nama pertama orang yang ditugaskan untuk setiap tugas dalam kolom B. Anda dapat menggunakan fungsi COUNTIF menghitung berapa kali nama seseorang muncul dalam kolom B dan, dengan cara itu, menentukan berapa banyak tugas yang ditugaskan kepada orang itu. Sebagai contoh:= COUNTIF (B2: B25, "Nancy")Perhatikan Untuk menghitung sel berdasarkan beberapa kriteria, lihat fungsi COUNTIFS.
SintaksisCOUNTIF (range, kriteria)Sintaks fungsi COUNTIF memiliki argumentasi sebagai berikut:• Bidang Diperlukan. Satu atau lebih sel untuk menghitung, termasuk nomor atau nama, array, atau referensi yang mengandung angka. Kosong dan nilai-nilai teks diabaikan.• kriteria yang disyaratkan. Sejumlah, ekspresi, referensi sel, atau string teks yang mendefinisikan sel yang akan dihitung. Sebagai contoh, kriteria dapat dinyatakan sebagai 32, "> 32", B4, "apel", atau "32".
CATATAN• Anda dapat menggunakan karakter wildcard - tanda tanya dan tanda bintang (*) (?) - Dalam kriteria. Tanda tanya cocok dengan satu karakter apapun, dan tanda bintang pertandingan setiap urutan karakter. Jika Anda ingin menemukan tanda tanya yang sebenarnya atau tanda bintang, ketik tilde (~) sebelum karakter.• Kriteria bersifat case sensitif, misalnya string "apel" dan string "APPLES" akan cocok dengan sel yang sama.
Contoh 1: Umum COUNTIF formula
1
2
3
4
5
6
7
8
A B C
Data Data
apples 32
oranges 54
peaches 75
apples 86
Formula Description Result
=COUNTIF(A2:A5,"apples") Number of cells with apples in cells A2 through A5.
2
=COUNTIF(A2:A5,A4) Number of cells with peaches in cells A2 through
1

9
10
11
12
A5.
=COUNTIF(A2:A5,A3)+COUNTIF(A2:A5,A2) Number of cells with oranges and apples in cells A2 through A5.
3
=COUNTIF(B2:B5,">55") Number of cells with a value greater than 55 in cells B2 through B5.
2
=COUNTIF(B2:B5,"<>"&B4) Number of cells with a value not equal to 75 in cells B2 through B5.
3
=COUNTIF(B2:B5,">=32")-COUNTIF(B2:B5,">85")
Number of cells with a value greater than or equal to 32 and less than or equal to 85 in cells B2 through B5.
3
Contoh 2: COUNTIF formula menggunakan karakter wildcard dan menangani nilai-nilai kosong
1
2
3
4
5
6
7
8
A B C
Data Data
apples Yes
oranges NO
peaches No
apples yes
Formula Description Result
=COUNTIF(A2:A7,"*es") Number of cells ending 4

9
10
11
12
13
14
with the letters "es" in cells A2 through A7.
=COUNTIF(A2:A7,"?????es") Number of cells ending with the letters "les" and having exactly 7 letters in cells A2 through A7.
2
=COUNTIF(A2:A7,"*") Number of cells containing any text in cells A2 through A7.
4
=COUNTIF(A2:A7,"<>"&"*") Number of cells not containing text in cells A2 through A7.
2
=COUNTIF(B2:B7,"No") / ROWS(B2:B7)
The average number of No votes (including blank cells) in cells B2 through B7.
0.333333333
=COUNTIF(B2:B7,"Yes") / (ROWS(B2:B7) -COUNTIF(B2:B7, "<>"&"*"))
The average number of Yes votes (excluding blank cells) in cells B2 through B7.
0.5
CATATAN Untuk melihat nomor sebagai persentase, pilih sel dan kemudian, pada tab Sheet, pada kelompok Jumlah, klik Style Persentase.
COUNTIFS fungsi
DeskripsiBerlaku kriteria untuk sel-sel di beberapa kisaran dan jumlah berapa kali seluruh kriteria tersebut terpenuhi.
SintaksisCOUNTIFS (criteria_range1, criteria1, [criteria_range2, criteria2] ...)Sintaks fungsi COUNTIFS memiliki argumentasi sebagai berikut:• criteria_range1 Diperlukan. Kisaran pertama di mana untuk mengevaluasi kriteria yang terkait.• criteria1 Diperlukan. Kriteria dalam bentuk nomor, ekspresi, referensi sel, atau teks yang menentukan mana sel-sel akan dihitung. Sebagai contoh, kriteria dapat dinyatakan sebagai

32, "> 32", B4, "apel", atau "32".• criteria_range2, criteria2, ... Opsional. Tambahan rentang dan kriteria yang terkait. Hingga 127 kisaran / kriteria pasangan diperbolehkan.PENTING Setiap rentang tambahan harus memiliki jumlah yang sama dari baris dan kolom sebagai argumen criteria_range1. Kisaran tidak harus berdekatan satu sama lain.
Keterangan• Setiap kriteria jangkauan yang diterapkan satu sel pada suatu waktu. Jika semua sel pertama memenuhi kriteria yang terkait, jumlah bertambah 1. Jika semua sel kedua memenuhi kriteria yang terkait, jumlah bertambah 1 lagi, dan seterusnya sampai semua sel dievaluasi.• Jika argumen kriteria adalah referensi ke sel kosong, fungsi COUNTIFS memperlakukan sel kosong sebagai nilai 0.• Anda dapat menggunakan karakter wildcard-tanda tanya dan tanda bintang (*) (?) - Dalam kriteria. Tanda tanya cocok dengan satu karakter apapun, dan tanda bintang pertandingan setiap urutan karakter. Jika Anda ingin menemukan tanda tanya yang sebenarnya atau tanda bintang, ketik tilde (~) sebelum karakter.
Contoh 1
12
3
4
5
6
7
A B C D
Sales Person Exceeded Widgets Quota
Exceeded Gadgets Quota
Exceeded Doodads Quota
Davidoski Yes No No
Burke Yes Yes No
Sundaram Yes Yes Yes
Levitan No Yes Yes
Formula Description
Result
=COUNTIFS(B2:D2,"=Yes") Counts how many times Davidoski exceeded a sales quota for Widgets,
1

8
9
Gadgets, and Doodads.
=COUNTIFS(B2:B5,"=Yes",C2:C5,"=Yes")
Counts how many sales people exceeded both their Widgets and Gadgets Quota.
2
=COUNTIFS(B5:D5,"=Yes",B3:D3,"=Yes")
Counts how many times Levitan and Burke exceeded the same quota for Widgets, Gadgets, and Doodads.
1
Contoh 2
1
2
3
4
5
6
7
8
A B C
Data Data
1 5/1/2008
2 5/2/2008
3 5/3/2008
4 5/4/2008
5 5/5/2008
6 5/6/2008
Formula Description Result
=COUNTIFS(A2:A7,"<6",A2:A7,">1") Counts how many numbers between 1 and 6 (not
4

9
10
11
including 1 and 6) are contained in cells A2 through A7.
=COUNTIFS(A2:A7, "<5",B2:B7,"<5/3/2008")
Counts how many rows have numbers that are less than 5 in cells A2 through A7, and also have dates that are are earlier than 5/3/2008 in cells B2 through B7.
2
=COUNTIFS(A2:A7, "<" & A6,B2:B7,"<" & B4)
Same description as the previous example, but using cell references instead of constants in the criteria.
2
COVAR fungsi
Pengembalian kovarians, rata-rata produk deviasi untuk setiap pasangan titik data. Gunakan kovarians untuk menentukan hubungan antara dua set data. Misalnya, Anda dapat memeriksa apakah pendapatan yang lebih besar menyertai tingkat yang lebih besar dari pendidikan.
SintaksisCOVAR (array1, array2)Array1 adalah rentang sel pertama dari bilangan bulat.Array2 adalah rentang sel kedua bilangan bulat.
Keterangan• Argumen baik harus menjadi nomor atau nama, array, atau referensi yang mengandung angka.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Jika array1 dan array2 memiliki perbedaan jumlah titik data, COVAR mengembalikan # N / A nilai kesalahan.• Jika salah array1 atau array2 kosong, COVAR mengembalikan DIV # / 0! nilai kesalahan.• kovariansi adalah: di mana x dan y adalah sampel berarti RATA-RATA (array1) dan RATA-RATA (array2),

dan n adalah ukuran sampel.
Contoh
1
2
3
4
5
6
A B
Data1 Data2
3 9
2 7
4 12
5 15
6 17
Formula Description (Result)
=COVAR(A2:A6, B2:B6)
Covariance, the average of the products of deviations for each data point pair above (5.2)
CRITBINOM fungsi
Menampilkan nilai terkecil dimana distribusi binomial kumulatif lebih besar dari atau sama dengan nilai kriteria. Gunakan fungsi ini untuk aplikasi jaminan kualitas. Misalnya, gunakan CRITBINOM untuk menentukan jumlah terbesar komponen yang rusak yang diizinkan untuk datang dari jalur perakitan berjalan tanpa menolak seluruh banyak.
SintaksisCRITBINOM (percobaan, probability_s, alfa)Ujian adalah jumlah percobaan Bernoulli.Probability_s adalah probabilitas sukses pada setiap percobaan.Alpha adalah nilai kriteria.
Keterangan• Jika argumen apapun nonnumeric, CRITBINOM mengembalikan # VALUE! nilai kesalahan.• Jika percobaan tidak integer, itu terpotong.• Jika percobaan <0, CRITBINOM mengembalikan NUM #! nilai kesalahan.• Jika probability_s adalah <0 atau probability_s> 1, CRITBINOM mengembalikan NUM #! nilai kesalahan.• Jika alpha <0 atau alpha> 1, CRITBINOM mengembalikan NUM #! nilai kesalahan.
Contoh
A B

1
2
3
4
Data Description
6 Number of Bernoulli trials
0.5 Probability of a success on each trial
0.75 Criterion value
Formula Description (Result)
=CRITBINOM(A2,A3,A4) Smallest value for which the cumulative binomial distribution is greater than or equal to a criterion value (4)
DEVSQ fungsi
Mengembalikan jumlah kuadrat penyimpangan dari titik data dari sampel mereka berarti.
SintaksisDEVSQ (number1, number2, ...)Number1, number2, ... adalah 1-255 argumen yang Anda ingin menghitung jumlah kuadrat deviasi. Anda juga dapat menggunakan array tunggal atau referensi ke array bukan argumen dipisahkan dengan koma.
Keterangan• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Persamaan untuk jumlah dari kuadrat deviasi adalah:
Contoh
1
2
3
4
5
A
Data
4
5
8
7

6
7
8
11
4
3
Formula Description (Result)
=DEVSQ(A2:A8) Sum of squares of deviations of data above from their sample mean (48)
EXPONDIST fungsi
Mengembalikan distribusi eksponensial. Gunakan EXPONDIST untuk model waktu antara peristiwa, seperti berapa lama bank teller otomatis diperlukan untuk memberikan kas. Sebagai contoh, Anda dapat menggunakan EXPONDIST untuk menentukan probabilitas bahwa proses tersebut memakan waktu paling 1 menit.
SintaksisEXPONDIST (x, lambda, kumulatif)X adalah nilai dari fungsi.Lambda adalah nilai parameter.Kumulatif adalah nilai logis yang menunjukkan yang bentuk fungsi eksponensial untuk menyediakan. Jika kumulatif adalah TRUE, EXPONDIST mengembalikan fungsi distribusi kumulatif, jika FALSE, ia mengembalikan fungsi kepadatan probabilitas.
Keterangan• Jika x atau lambda adalah nonnumeric, EXPONDIST mengembalikan # VALUE! nilai kesalahan.• Jika x <0, EXPONDIST mengembalikan NUM #! nilai kesalahan.• Jika lambda ≤ 0, EXPONDIST mengembalikan NUM #! nilai kesalahan.• Persamaan untuk fungsi kepadatan probabilitas adalah:
• Persamaan untuk fungsi distribusi kumulatif adalah:
Contoh
1
2
3
A B
Data Description
0.2 Value of the function
10 Parameter value

Formula Description (Result)
=EXPONDIST(A2,A3,TRUE) Cumulative exponential distribution function (0.864665)
=EXPONDIST(0.2,10,FALSE)
Probability exponential distribution function (1.353353)
FDIST fungsi
Mengembalikan distribusi probabilitas F. Anda dapat menggunakan fungsi ini untuk menentukan apakah dua data set memiliki derajat yang berbeda keanekaragaman. Misalnya, Anda dapat memeriksa nilai tes laki-laki dan perempuan memasuki sekolah tinggi dan menentukan apakah variabilitas dalam wanita berbeda dengan yang ditemukan pada laki-laki.
SintaksisFDIST (x, degrees_freedom1, degrees_freedom2)X adalah nilai di mana untuk mengevaluasi fungsi.Degrees_freedom1 adalah derajat pembilang kebebasan.Degrees_freedom2 adalah derajat penyebut kebebasan.
Keterangan• Jika argumen apapun nonnumeric, FDIST mengembalikan # VALUE! nilai kesalahan.• Jika x adalah negatif, FDIST mengembalikan NUM #! nilai kesalahan.• Jika degrees_freedom1 atau degrees_freedom2 tidak integer, itu terpotong.
• Jika degrees_freedom1 <1 atau degrees_freedom1 ≥ 10 ^ 10, FDIST mengembalikan NUM #! nilai kesalahan.• Jika degrees_freedom2 <1 atau degrees_freedom2 ≥ 10 ^ 10, FDIST mengembalikan NUM #! nilai kesalahan.• FDIST dihitung sebagai FDIST = P (F> x), dimana F adalah variabel acak yang memiliki distribusi F dengan degrees_freedom1 dan degrees_freedom2 derajat kebebasan.
Contoh
1
2
3
4
A B
Data Description
15.20686486 Value at which to evaluate the function
6 Numerator degrees of freedom
4 Denominator degrees of freedom
Formula Description (Result)
=FDIST(A2,A3,A4)
F probability distribution for the terms above (0.01)

FINV fungsi
Mengembalikan kebalikan dari distribusi probabilitas F. Jika p = FDIST (x, ...), kemudian FINV (p, ...) = x.Distribusi F dapat digunakan dalam uji F-yang membandingkan derajat variabilitas dalam dua set data. Sebagai contoh, Anda dapat menganalisis distribusi pendapatan di Amerika Serikat dan Kanada untuk menentukan apakah kedua negara memiliki tingkat yang sama keragaman pendapatan.
SintaksisFINV (probabilitas, degrees_freedom1, degrees_freedom2)Probabilitas adalah kemungkinan terkait dengan distribusi F kumulatif.Degrees_freedom1 adalah derajat pembilang kebebasan.Degrees_freedom2 adalah derajat penyebut kebebasan.
Keterangan• Jika argumen apapun nonnumeric, FINV mengembalikan # VALUE! nilai kesalahan.• Jika probabilitas <0 atau probabilitas> 1, FINV mengembalikan NUM #! nilai kesalahan.• Jika degrees_freedom1 atau degrees_freedom2 tidak integer, itu terpotong.• Jika degrees_freedom1 <1 atau degrees_freedom1 ≥ 10 ^ 10, FINV mengembalikan NUM #! nilai kesalahan.• Jika degrees_freedom2 <1 atau degrees_freedom2 ≥ 10 ^ 10, FINV mengembalikan NUM #! nilai kesalahan.FINV dapat digunakan untuk mengembalikan nilai-nilai kritis dari distribusi F. Sebagai contoh, output dari perhitungan ANOVA sering kali berisi data untuk statistik F, probabilitas F, dan nilai F kritis pada tingkat signifikansi 0,05. Untuk kembali nilai kritis F, menggunakan tingkat signifikansi sebagai argumen probabilitas untuk FINV.Mengingat nilai probabilitas, FINV berusaha bahwa x nilai seperti yang FDIST (x, degrees_freedom1, degrees_freedom2) = probabilitas. Dengan demikian, ketepatan FINV tergantung pada ketepatan FDIST. FINV menggunakan teknik iteratif pencarian. Jika pencarian tidak berkumpul setelah 100 iterasi, fungsi mengembalikan # N / A nilai kesalahan.
Contoh
1
2
3
4
A B
Data Description
0.01 Probability associated with the F cumulative distribution
6 Numerator degrees of freedom
4 Denominator degrees of freedom
Formula Description (Result)
=FINV(A2,A3,A4)
Inverse of the F probability distribution for the terms above (15.20686486)

FISHER fungsi
Mengembalikan transformasi Fisher pada x. Transformasi ini menghasilkan fungsi yang biasanya didistribusikan bukan miring. Gunakan fungsi ini untuk melakukan pengujian hipotesis pada koefisien korelasi.
SintaksisFISHER (x)X adalah nilai numerik yang Anda ingin transformasi.
Keterangan• Jika x adalah nonnumeric, FISHER mengembalikan # VALUE! nilai kesalahan.• Jika x ≤ -1 atau jika x ≥ 1, FISHER mengembalikan NUM #! nilai kesalahan.• Persamaan untuk transformasi Fisher adalah:
Contoh
1
2
A B
Formula Description (Result)
=FISHER(0.75)
Fisher transformation at 0.75 (0.972955)
FISHERINV fungsi
Mengembalikan kebalikan dari transformasi Fisher. Gunakan transformasi ini ketika menganalisis korelasi antara rentang atau array data. Jika y = FISHER (x), maka FISHERINV (y) = x.SintaksisFISHERINV (y)Y adalah nilai yang Anda ingin melakukan kebalikan dari transformasi.
Keterangan• Jika y adalah nonnumeric, FISHERINV mengembalikan # VALUE! nilai kesalahan.• Persamaan untuk invers transformasi Fisher adalah:
Contoh
A B

1
2Formula Description (Result)
=FISHERINV(0.972955)
Inverse of the Fisher transformation at 0.972955 (0.75)
FORECAST fungsi
Menghitung, atau memprediksi, nilai masa depan dengan menggunakan nilai yang ada. Nilai prediksi adalah y-nilai untuk nilai x yang diberikan. Nilai-nilai yang dikenal ada x-dan y nilai-nilai, dan nilai baru diperkirakan dengan menggunakan regresi linier. Anda dapat menggunakan fungsi ini untuk memprediksi penjualan masa depan, kebutuhan persediaan, atau tren konsumen.
SintaksisFORECAST (x, yang known_y, yang known_x)X adalah titik data yang Anda ingin untuk memprediksi nilai.Yang Known_y adalah array tergantung atau jangkauan data.Yang Known_x adalah array independen atau jangkauan data.
Keterangan• Jika x adalah nonnumeric, FORECAST mengembalikan # VALUE! nilai kesalahan.• Jika kita known_y dan itu known_x kosong atau berisi nomor yang berbeda dari titik data, FORECAST mengembalikan # N / A nilai kesalahan.• Jika varians dari itu known_x sama dengan nol, maka FORECAST mengembalikan DIV # / 0! nilai kesalahan.
• Persamaan untuk FORECAST adalah a + bx, dimana:
dan
dan di mana x dan y adalah sampel berarti RATA-RATA (s known_x) dan RATA-RATA (dikenal itu y).
Contoh
A B

1
2
3
4
5
6
Known Y Known X
6 20
7 28
9 31
15 38
21 40
Formula Description (Result)
=FORECAST(30,A2:A6,B2:B6)
Predicts a value for y given an x value of 30 (10.60725)
FREKUENSI fungsi
Menghitung seberapa sering nilai-nilai terjadi dalam rentang nilai, dan kemudian mengembalikan sebuah array vertikal angka. Misalnya, gunakan FREKUENSI untuk menghitung jumlah nilai tes yang berada dalam rentang nilai. Karena FREKUENSI mengembalikan array, ia harus dimasukkan sebagai formula array.
SintaksisFREKUENSI (data_array, bins_array)Data_array adalah array atau referensi untuk satu set nilai yang Anda ingin menghitung frekuensi. Jika data_array tidak mengandung nilai-nilai, FREKUENSI mengembalikan array nol.
Bins_array adalah array atau referensi untuk interval di mana Anda ingin mengelompokkan nilai-nilai dalam data_array. Jika bins_array tidak mengandung nilai-nilai, FREKUENSI mengembalikan jumlah elemen dalam data_array.
Keterangan• FREKUENSI dimasukkan sebagai formula array setelah Anda memilih kisaran sel yang berdekatan di mana Anda ingin distribusi kembali muncul.• Jumlah elemen dalam array dikembalikan adalah salah satu lebih dari jumlah elemen dalam bins_array. Elemen tambahan dalam array kembali mengembalikan jumlah dari setiap nilai di atas interval tertinggi. Misalnya, ketika menghitung tiga rentang nilai (interval) yang dimasukkan ke dalam tiga sel, pastikan untuk memasukkan FREKUENSI menjadi empat sel untuk hasilnya. Sel ekstra mengembalikan jumlah nilai dalam data_array yang lebih besar dari nilai interval ketiga.• FREKUENSI mengabaikan sel kosong dan teks.• Formula yang array kembali harus dimasukkan sebagai formula array.
ContohContoh ini mengasumsikan semua nilai ujian adalah bilangan bulat.

1
2
3
4
5
6
7
8
9
10
A B
Scores Bins
79 70
85 79
78 89
85
50
81
95
88
97
Formula Description (Result)
=FREQUENCY(A2:A10,B2:B4)
Number of scores less than or equal to 70 (1)
Number of scores in the bin 71-79 (2)
Number of scores in the bin 80-89 (4)
Number of scores greater than or equal to 90 (2)
CATATAN Rumus dalam contoh harus dimasukkan sebagai formula array. Setelah menyalin contoh untuk lembar kerja kosong, pilih rentang A12: A15, tekan F2, lalu tekan CTRL + SHIFT + ENTER. Jika formula tidak dimasukkan sebagai formula array, akan ada hanya satu hasil di sel A12 (1).FTEST fungsi
Mengembalikan hasil dari uji F-. F-tes mengembalikan probabilitas dua ekor bahwa varians dalam array1 dan array2 tidak berbeda nyata. Gunakan fungsi ini untuk menentukan apakah dua sampel memiliki varians yang berbeda. Sebagai contoh, diberikan tes skor dari sekolah negeri dan swasta, Anda dapat menguji apakah sekolah-sekolah ini memiliki berbagai tingkat keanekaragaman skor tes.
SintaksisUji F (array1, array2)Array1 adalah array pertama atau rentang data.Array2 adalah array kedua atau rentang data.
Keterangan• Argumen harus berupa nomor atau nama, array, atau referensi yang mengandung angka.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Jika jumlah titik data dalam array1 atau array2 kurang dari 2, atau jika varians dari array1

atau array2 adalah nol, Uji F mengembalikan DIV # / 0! nilai kesalahan.
Contoh
1
2
3
4
5
6
A B
Data1 Data2
6 20
7 28
9 31
15 38
21 40
Formula Description (Result)
=FTEST(A2:A6,B2:B6)
F-test for the data sets above (0.648318)
GAMMADIST fungsi
Mengembalikan distribusi gamma. Anda dapat menggunakan fungsi ini untuk mempelajari variabel yang mungkin memiliki distribusi miring. Distribusi gamma umumnya digunakan dalam analisis antrian.
SintaksisGAMMADIST (x, alfa, beta, kumulatif)X adalah nilai di mana Anda ingin mengevaluasi distribusi.Alpha adalah suatu parameter untuk distribusi.Beta adalah suatu parameter untuk distribusi. Jika beta = 1, GAMMADIST mengembalikan distribusi gamma standar.Kumulatif adalah nilai logis yang menentukan bentuk dari fungsi. Jika kumulatif adalah TRUE, GAMMADIST mengembalikan fungsi distribusi kumulatif, jika FALSE, ia mengembalikan fungsi kepadatan probabilitas.
Keterangan• Jika x, alfa, beta atau nonnumeric, GAMMADIST mengembalikan # VALUE! nilai kesalahan.• Jika x <0, GAMMADIST mengembalikan NUM #! nilai kesalahan.• Jika alpha ≤ 0 atau jika beta ≤ 0, GAMMADIST mengembalikan NUM #! nilai kesalahan.• Persamaan untuk fungsi probabilitas kepadatan gamma adalah:
Probabilitas gamma fungsi kepadatan standar:

• Ketika alpha = 1, GAMMADIST mengembalikan distribusi eksponensial dengan:
• Untuk n bilangan bulat positif, ketika alpha = n / 2, beta = 2, dan kumulatif = TRUE kembali GAMMADIST, (1 - CHIDIST (x)) dengan derajat kebebasan n.• Ketika alpha adalah bilangan bulat positif, GAMMADIST juga dikenal sebagai distribusi Erlang.
Contoh
1
2
3
4
A B
Data Description
10.00001131 Value at which you want to evaluate the distribution
9 Alpha parameter to the distribution
2 Beta parameter to the distribution
Formula Description (Result)
=GAMMADIST(A2,A3,A4,FALSE)
Probability gamma distribution with the terms above (.03263913)
=GAMMADIST(A2,A3,A4,TRUE) Cumulative gamma distribution with the terms above (0.068094)
GAMMAINV fungsi
Mengembalikan invers dari distribusi kumulatif gamma. Jika p = GAMMADIST (x, ...), kemudian GAMMAINV (p, ...) = x.Anda dapat menggunakan fungsi ini untuk mempelajari distribusi variabel yang mungkin miring.
SintaksisGAMMAINV (probabilitas, alfa, beta)Probabilitas adalah probabilitas yang terkait dengan distribusi gamma.Alpha adalah suatu parameter untuk distribusi.Beta adalah suatu parameter untuk distribusi. Jika beta = 1, GAMMAINV mengembalikan distribusi gamma standar.
Keterangan• Jika argumen adalah teks, GAMMAINV mengembalikan # VALUE! nilai kesalahan.

• Jika probabilitas <0 atau probabilitas> 1, GAMMAINV mengembalikan NUM #! nilai kesalahan.• Jika alpha ≤ 0 atau jika beta ≤ 0, GAMMAINV mengembalikan NUM #! nilai kesalahan.Mengingat nilai probabilitas, GAMMAINV berusaha bahwa x nilai seperti yang GAMMADIST (x, alfa, beta, TRUE) = probabilitas. Dengan demikian, ketepatan GAMMAINV tergantung pada ketepatan GAMMADIST. GAMMAINV menggunakan teknik iteratif pencarian. Jika pencarian tidak berkumpul setelah 100 iterasi, fungsi mengembalikan # N / A nilai kesalahan.
Contoh
1
2
3
4
A B
Data Description
0.068094 Probability associated with the gamma distribution
9 Alpha parameter to the distribution
2 Beta parameter to the distribution
Formula Description (Result)
=GAMMAINV(A2,A3,A4)
Inverse of the gamma cumulative distribution for the above terms (10.00001131)
GAMMALN fungsiMengembalikan logaritma natural dari fungsi gamma, Γ (x).
SintaksisGAMMALN (x)X adalah nilai yang Anda ingin menghitung GAMMALN.
Keterangan• Jika x adalah nonnumeric, GAMMALN mengembalikan # VALUE! nilai kesalahan.• Jika x ≤ 0, GAMMALN mengembalikan NUM #! nilai kesalahan.• E nomor pangkat (i) GAMMALN, di mana i adalah integer, mengembalikan hasil yang sama seperti (i - 1)!.• GAMMALN dihitung sebagai berikut:
dimana:

Contoh
1
2
A B
Formula Description (Result)
=GAMMALN(4) Natural logarithm of he gamma function at 4 (1.791759)
GEOMEAN fungsi
Pengembalian rata-rata geometris dari sebuah array atau range data positif. Sebagai contoh, Anda dapat menggunakan GEOMEAN untuk menghitung tingkat pertumbuhan rata-rata diberikan bunga majemuk dengan tingkat variabel.
SintaksisGEOMEAN (number1, number2, ...)Number1, number2, ... adalah 1-255 argumen yang Anda ingin menghitung berarti. Anda juga dapat menggunakan array tunggal atau referensi ke array bukan argumen dipisahkan dengan koma.
Keterangan• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika ada titik data ≤ 0, GEOMEAN mengembalikan NUM #! nilai kesalahan.
• Persamaan untuk mean geometrik adalah:
Contoh
1
2
3
4
5
A
Data
4
5
8

6
7
8
7
11
4
3
Formula Description (Result)
=GEOMEAN(A2:A8) Geometric meanof the dataset above (5.476987)
GROWTH fungsi
Menghitung memperkirakan pertumbuhan eksponensial dengan menggunakan data yang ada. GROWTH mengembalikan y-nilai untuk serangkaian baru x-nilai yang Anda tentukan yang ada dengan menggunakan x-dan y nilai-nilai. Anda juga dapat menggunakan fungsi worksheet GROWTH agar sesuai kurva eksponensial yang ada x-dan y nilai-nilai.
SintaksisGROWTH (s known_y, yang known_x, yang new_x, const)Yang Known_y adalah himpunan dari y-nilai yang Anda sudah tahu dalam hubungan y = b * m ^ x.• Jika array known_y itu adalah dalam satu kolom, maka setiap kolom yang known_x diinterpretasikan sebagai variabel terpisah.• Jika array known_y itu adalah dalam satu baris, maka setiap baris yang known_x diinterpretasikan sebagai variabel terpisah.• Jika salah satu nomor dalam yang known_y adalah 0 atau negatif, GROWTH mengembalikan NUM #! nilai kesalahan.Yang Known_x merupakan perangkat opsional dari x-nilai yang Anda mungkin sudah tahu dalam hubungan y = b * m ^ x.
• Para s Array known_x dapat mencakup satu atau lebih set variabel. Jika hanya satu variabel yang digunakan, yang known_y dan itu known_x dapat berkisar dari bentuk apapun, selama mereka memiliki dimensi yang sama. Jika lebih dari satu variabel yang digunakan, yang known_y harus menjadi vektor (yaitu, berbagai dengan tinggi satu baris atau lebar satu kolom).• Jika kita known_x diabaikan, diasumsikan array {1,2,3, ...} yang ukuran sama seperti known_y.Yang New_x baru x-nilai yang Anda ingin GROWTH kembali sesuai y-nilai.• yang New_x harus menyertakan kolom (atau baris) untuk setiap variabel independen, sama seperti known_x tidak. Jadi, jika kita known_y dalam satu kolom, yang known_x dan itu new_x harus memiliki jumlah kolom yang sama. Jika itu known_y dalam satu baris, yang known_x dan itu new_x harus memiliki jumlah baris yang sama.• Jika kita new_x dihilangkan, diasumsikan untuk menjadi sama seperti known_x.• Jika kedua itu known_x dan itu new_x dihilangkan, mereka diasumsikan array {1,2,3, ...}

yang ukuran sama seperti known_y.Const adalah nilai logis menentukan apakah akan memaksa b konstan untuk 1 sama.• Jika const adalah TRUE atau dihilangkan, b dihitung secara normal.• Jika const adalah FALSE, b ditetapkan sama dengan 1 dan m-nilai yang disesuaikan sehingga y = m ^ x.
Keterangan• Formula yang array kembali harus dimasukkan sebagai formula array setelah memilih nomor yang benar dari sel.• Ketika memasuki sebuah array konstan untuk argumen seperti itu known_x, gunakan koma untuk memisahkan nilai-nilai pada baris yang sama dan titik koma untuk baris yang terpisah.
ContohContoh ini menggunakan data yang sama seperti contoh LOGEST. Rumus pertama menunjukkan nilai-nilai yang sesuai dengan nilai-nilai diketahui. Rumus kedua memprediksi nilai bulan berikutnya, jika tren eksponensial terus berlanjut.
1
2
3
4
5
6
7
A B C
Month Units Formula (Corresponding Units)
11 33,100 =GROWTH(B2:B7,A2:A7)
12 47,300
13 69,000
14 102,000
15 150,000
16 220,000
Month Formula (Predicted Units)
17 =GROWTH(B2:B7,A2:A7, A9:A10)
18
CATATAN Rumus dalam contoh harus dimasukkan sebagai formula array. Setelah menyalin contoh untuk lembar kerja kosong, memilih kisaran C2: C7 atau B9: B10 dimulai dengan sel formula. Tekan F2, kemudian tekan CTRL + SHIFT + ENTER. Jika formula tidak dimasukkan sebagai formula array, hasil tunggal 32618,20377 dan 320196,7184.
HARMEAN fungsi
Pengembalian rata-rata harmonik dari kumpulan data. Mean harmonik adalah kebalikan dari mean aritmetik dari resiprokal.

SintaksisHARMEAN (number1, number2, ...)Number1, number2, ... adalah 1-255 argumen yang Anda ingin menghitung berarti. Anda juga dapat menggunakan array tunggal atau referensi ke array bukan argumen dipisahkan dengan koma.
Keterangan• Rata-rata harmonik selalu kurang dari mean geometrik, yang selalu kurang dari mean aritmetik.• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika ada titik data ≤ 0, HARMEAN mengembalikan NUM #! nilai kesalahan.• Persamaan untuk mean harmonik adalah:
Contoh
1
2
3
4
A
Data
4
5
8

5
6
7
8
7
11
4
3
Formula Description (Result)
=HARMEAN(A2:A8) Harmonic man of the data se above (5.028376)
HYPGEOMDIST fungsi
Mengembalikan distribusi hipergeometrik. HYPGEOMDIST kembali kemungkinan angka yang diberikan keberhasilan sampel, mengingat ukuran sampel, keberhasilan populasi, dan ukuran populasi. Gunakan HYPGEOMDIST untuk masalah dengan populasi terbatas, dimana setiap pengamatan bisa berupa sukses atau gagal, dan di mana masing-masing subset dari ukuran tertentu dipilih dengan kemungkinan yang sama.
SintaksisHYPGEOMDIST (sample_s, number_sample, population_s, number_population)Sample_s adalah jumlah keberhasilan dalam sampel.Number_sample adalah ukuran sampel.Population_s adalah jumlah sukses dalam populasi.Number_population adalah ukuran populasi.
Keterangan• Semua argumen yang dipotong ke integer.• Jika argumen apapun nonnumeric, HYPGEOMDIST mengembalikan # VALUE! nilai kesalahan.• Jika sample_s <0 atau sample_s lebih besar dari yang lebih rendah dari number_sample atau population_s, HYPGEOMDIST mengembalikan NUM #! nilai kesalahan.• Jika sample_s kurang dari yang lebih besar dari 0 atau (number_sample - number_population + population_s), HYPGEOMDIST mengembalikan NUM #! nilai kesalahan.• Jika number_sample ≤ 0 atau number_sample number_population>, HYPGEOMDIST mengembalikan NUM #! nilai kesalahan.
• Jika population_s ≤ 0 atau population_s number_population>, HYPGEOMDIST mengembalikan NUM #! nilai kesalahan.• Jika number_population ≤ 0, HYPGEOMDIST mengembalikan NUM #! nilai kesalahan.• Persamaan untuk distribusi hipergeometris adalah:

dimana:x = sample_sn = number_sampleM = population_sN = number_population
HYPGEOMDIST digunakan dalam sampling tanpa penggantian dari suatu populasi terbatas.
ContohSebuah sampler cokelat berisi 20 buah. Delapan buah adalah karamel, dan 12 sisanya adalah kacang-kacangan. Jika seseorang memilih 4 buah secara acak, fungsi berikut mengembalikan probabilitas bahwa persis 1 buah adalah karamel.
1
2
3
4
5
A B
Data Description
1 Number of successes in the sample
4 Sample size
8 Number of successes in the population
20 Population size
Formula Description (Result)
=HYPGEOMDIST(A2,A3,A4,A5)
Hypergeometric distribution for sample and population above (0.363261)
INTERCEPT fungsi
Menghitung titik di mana garis akan berpotongan dengan sumbu y dengan menggunakan yang sudah ada x-dan y nilai-nilai. Titik potong sumbu didasarkan pada garis regresi yang dianggap terbaik diplot melalui x-nilai yang diketahui dan dikenal y-nilai. Gunakan fungsi INTERCEPT bila Anda ingin menentukan nilai dari variabel tidak bebas ketika variabel

independennya adalah 0 (nol). Misalnya, Anda dapat menggunakan fungsi INTERCEPT untuk memprediksi hambatan listrik suatu logam pada 0 ° C ketika titik data Anda diambil pada suhu kamar dan lebih tinggi.
SintaksisINTERCEPT (s known_y, yang known_x)Yang Known_y adalah himpunan tergantung dari pengamatan atau data.Yang Known_x adalah himpunan independen dari pengamatan atau data.
Keterangan• Argumen harus berupa nomor atau nama, array, atau referensi yang mengandung angka.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Jika kita known_y dan itu known_x mengandung nomor yang berbeda dari titik data atau tidak mengandung titik data, INTERCEPT mengembalikan # N / A nilai kesalahan.• Persamaan untuk intercept dari garis regresi, a, adalah:
di mana kemiringan, b, dihitung sebagai:
dan di mana x dan y adalah sampel berarti RATA-RATA (s known_x) dan RATA-RATA (s known_y).• Algoritma yang mendasari digunakan dalam fungsi INTERCEPT dan LERENG berbeda dari algoritma yang mendasari digunakan dalam fungsi LINEST. Perbedaan antara algoritma ini dapat menyebabkan hasil yang berbeda ketika data belum ditentukan dan kesegarisan. Misalnya, jika titik data dari argumen known_y adalah 0 dan titik data dari argumen known_x adalah 1: INTERCEPT dan LERENG kembali DIV # / 0! kesalahan. Para INTERCEPT dan algoritma LERENG dirancang untuk mencari satu dan hanya satu jawaban, dan dalam hal ini terdapat lebih dari satu jawaban. LINEST mengembalikan nilai 0. Algoritma LINEST dirancang untuk memberikan hasil yang wajar untuk data collinear, dan dalam hal ini paling tidak satu jawaban yang dapat ditemukan.
Contoh
A B

1
2
3
4
5
6
Known y Known x
2 6
3 5
9 11
1 7
8 5
Formula Description (Result)
=INTERCEPT(A2:A6, B2:B6)
Point at which a line will intersect the y-axis by using the x-values and y-values above (0.0483871)
KURT fungsi
Mengembalikan kurtosis dari kumpulan data. Kurtosis mencirikan peakedness relatif atau kerataan distribusi dibandingkan dengan distribusi normal. Kurtosis yang positif menunjukkan distribusi relatif memuncak. Kurtosis negatif menunjukkan distribusi relatif datar.
SintaksisKuRt (number1, number2, ...)Number1, number2, ... adalah 1-255 argumen yang Anda ingin menghitung kurtosis. Anda juga dapat menggunakan array tunggal atau referensi ke array bukan argumen dipisahkan dengan koma.
Keterangan• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika ada kurang dari empat titik data, atau jika standar deviasi dari sampel sama dengan nol, KuRt mengembalikan DIV # / 0! nilai kesalahan.
• Kurtosis didefinisikan sebagai:

dimana s adalah standar deviasi sampel.
Contoh
1
2
3
4
5
6
7
8
9
10
11
A
Data
3
4
5
2
3
4
5
6
4
7
Formula Description (Result)
=KURT(A2:A11) Kurtosis of the data set above (-0.1518)
LARGE fungsi
Menampilkan nilai-k terbesar dalam satu set data. Anda dapat menggunakan fungsi ini untuk memilih nilai berdasarkan relativestanding nya. Sebagai contoh, Anda dapat menggunakan LARGE untuk mengembalikan, tertinggi runner-up, atau ketiga-tempat skor.
SintaksisLARGE (array, k)

Array adalah array atau range data yang Anda ingin untuk menentukan nilai k-th terbesar.K adalah posisi (dari yang terbesar) di kisaran array atau sel data untuk kembali.
Keterangan• Jika array kosong, LARGE mengembalikan NUM #! nilai kesalahan.• Jika k ≤ 0 atau jika k lebih besar dari jumlah titik data, LARGE mengembalikan NUM #! nilai kesalahan.Jika n adalah jumlah titik data dalam suatu range, maka LARGE (array, 1) mengembalikan nilai terbesar, dan LARGE (array, n) mengembalikan nilai terkecil.
Contoh
1
2
3
4
5
6
A B
Data Data
3 4
5 2
3 4
5 6
4 7
Formula Description (Result)
=LARGE(A2:B6,3) 3rd largest number in the numbers above (5)
=LARGE(A2:B6,7) 7th largest number in the numbers above (4)
LINEST fungsi
DeskripsiFungsi LINEST menghitung statistik untuk sebuah baris dengan menggunakan "kuadrat terkecil" metode untuk menghitung garis lurus yang paling sesuai dengan data Anda, dan kemudian mengembalikan array yang menggambarkan garis. Anda juga dapat menggabungkan LINEST dengan fungsi lain untuk menghitung statistik untuk jenis lain model yang linear dalam parameter yang tidak diketahui, termasuk polinomial, logaritmik seri, eksponensial, dan kekuasaan. Karena fungsi ini mengembalikan array nilai, harus dimasukkan sebagai formula array. Instruksi mengikuti contoh dalam artikel ini.Persamaan untuk garis adalah: y = mx + b -Atau- y = m1x1 + m2x2 + ... + B (jika ada beberapa kisaran x-nilai)dimana tergantung y-nilai adalah fungsi dari x-nilai independen. M-nilai adalah koefisien sesuai untuk setiap nilai x, dan b adalah nilai konstan. Perhatikan bahwa y, x, dan m dapat menjadi vektor. Array yang kembali fungsi LINEST adalah {mn, mn-1, ..., m1, b}. LINEST juga dapat kembali statistik regresi tambahan.

SintaksisLINEST (s known_y, [itu known_x], [const], [stats])Sintaks fungsi LINEST memiliki argumentasi sebagai berikut:• known_y yang Diperlukan. Himpunan y-nilai yang Anda sudah tahu dalam hubungan y = mx + b. Jika kisaran yang known_y dalam satu kolom, setiap kolom yang known_x diinterpretasikan sebagai variabel terpisah. Jika kisaran yang known_y terkandung dalam satu baris, setiap baris yang known_x diinterpretasikan sebagai variabel terpisah.• Opsional itu known_x. Satu set x-nilai yang Anda mungkin sudah tahu dalam hubungan y = mx + b. Kisaran yang known_x dapat mencakup satu atau lebih set variabel. Jika hanya satu variabel yang digunakan, yang known_y dan itu known_x dapat berkisar dari bentuk apapun, selama mereka memiliki dimensi yang sama. Jika lebih dari satu variabel yang digunakan, yang known_y harus menjadi vektor (yaitu, berbagai dengan tinggi satu baris atau lebar satu kolom). Jika itu known_x diabaikan, diasumsikan array {1,2,3, ...} yang ukuran sama seperti known_y.• const Opsional. Sebuah nilai logis menentukan apakah akan memaksa b konstan 0 sama. Jika const adalah TRUE atau dihilangkan, b dihitung secara normal. Jika const adalah FALSE, b ditetapkan sama dengan 0 dan m-nilai disesuaikan agar sesuai dengan y = mx.• statistik Opsional. Sebuah nilai logis menentukan apakah akan kembali statistik regresi tambahan. Jika statistik adalah TRUE, LINEST mengembalikan statistik regresi tambahan, sebagai akibatnya, array dikembalikan {mn, mn-1, ..., m1, b; sen, sen-1, ..., SE1, seb; r2 , sey; F, df; ssreg, ssresid}. Jika statistik adalah FALSE atau dihilangkan, LINEST kembali hanya m-koefisien dan b konstan.
Statistik regresi tambahan adalah sebagai berikut.
STATISTIC DESCRIPTION

se1,se2,...,sen
The standard error values for the coefficients m1,m2,...,mn.
seb The standard error value for the constant b (seb = #N/A when const is FALSE).
r2 The coefficient of determination. Compares estimated and actual y-values, and ranges in value from 0 to 1. If it is 1, there is a perfect correlation in the sample — there is no difference between the estimated y-value and the actual y-value. At the other extreme, if the coefficient of determination is 0, the regression equation is not helpful in predicting a y-value. For information about how r2 is calculated, see "Remarks," later in this topic.
sey The standard error for the y estimate.
F The F statistic, or the F-observed value. Use the F statistic to determine whether the observed relationship between the dependent and independent variables occurs by chance.
df The degrees of freedom. Use the degrees of freedom to help you find F-critical values in a statistical table. Compare the values you find in the table to the F statistic returned by LINEST to determine a confidence level for the model. For information about how df is calculated, see "Remarks," later in this topic. Example 4 shows use of F and df.
ssreg The regression sum of squares.
ssresid The residual sum of squares. For information about how ssreg and ssresid are calculated, see "Remarks," later in this topic.
Ilustrasi berikut menunjukkan urutan statistik regresi tambahan dikembalikan.
Keterangan• Anda dapat menggambarkan setiap garis lurus dengan kemiringan dan y-intercept:Slope (m):Untuk mencari kemiringan garis, sering ditulis sebagai m, mengambil dua titik pada garis, (x1, y1) dan (x2, y2); lereng sama dengan (y2 - y1) / (x2 - x1).Y-intercept (b):Y-intercept dari garis, sering ditulis sebagai b, adalah nilai dari y pada titik di mana garis melintasi sumbu y.Persamaan garis lurus adalah y = mx + b. Setelah Anda tahu nilai-nilai m dan b, Anda dapat menghitung setiap titik di telepon dengan mencolokkan y atau x-nilai ke dalam persamaan itu. Anda juga dapat menggunakan fungsi TREND.• Bila Anda hanya memiliki satu variabel x-independen, Anda dapat memperoleh kemiringan dan y-intercept nilai langsung dengan menggunakan rumus berikut:Lereng:

= INDEX (LINEST (s known_y, yang known_x), 1)Y-intercept:= INDEX (LINEST (s known_y, yang known_x), 2)• Akurasi garis dihitung dengan fungsi LINEST tergantung pada derajat tersebarnya data Anda. Semakin linier data, semakin akurat LINEST model. LINEST menggunakan metode kuadrat terkecil untuk menentukan yang paling cocok untuk data. Bila Anda hanya memiliki satu independen x-variabel, perhitungan untuk m dan b didasarkan pada rumus berikut:di mana x dan y adalah rata sampel, yaitu, x = AVERAGE (dikenal itu x) dan y = AVERAGE (s known_y).
• Garis-dan kurva-fitting fungsi LINEST dan LOGEST dapat menghitung garis lurus terbaik atau kurva eksponensial yang sesuai dengan data Anda. Namun, Anda harus memutuskan yang mana dari dua hasil terbaik sesuai data Anda. Anda dapat menghitung TREND (yang known_y, yang known_x) untuk garis lurus, atau GROWTH (s known_y, yang known_x) untuk kurva eksponensial. Fungsi-fungsi, tanpa argumen new_x itu, mengembalikan array y-nilai diprediksi sepanjang garis atau kurva pada titik-titik Anda yang sebenarnya data. Anda kemudian dapat membandingkan nilai prediksi dengan nilai-nilai yang sebenarnya. Anda mungkin ingin untuk memetakan mereka berdua untuk perbandingan visual.• Dalam analisis regresi, Excel menghitung untuk setiap titik perbedaan kuadrat antara nilai y-diperkirakan untuk saat itu dan sebenarnya y-nilai. Jumlah dari perbedaan-perbedaan kuadrat disebut jumlah sisa kotak, ssresid. Excel kemudian menghitung jumlah total kotak, sstotal. Ketika argumen const = TRUE atau dihilangkan, jumlah total kotak adalah jumlah perbedaan kuadrat antara nilai-nilai y aktual dan rata-rata dari nilai-y. Ketika argumen const = FALSE, jumlah total kotak adalah jumlah kuadrat dari nilai-nilai y yang sebenarnya (tanpa mengurangkan nilai y-rata dari masing-masing individu y-nilai). Kemudian regresi jumlah kuadrat, ssreg, dapat ditemukan dari: ssreg = sstotal - ssresid. Semakin kecil jumlah kuadrat residu adalah, dibandingkan dengan total jumlah kuadrat, semakin besar nilai koefisien determinasi, r2, yang merupakan indikator seberapa baik persamaan yang dihasilkan dari analisis regresi menjelaskan hubungan antar variabel. Nilai r2 sama ssreg / sstotal.• Dalam beberapa kasus, satu atau lebih kolom X (menganggap itulah Y dan X dalam kolom) mungkin tidak memiliki nilai prediktif tambahan dengan adanya kolom X lainnya. Dengan kata lain, menghilangkan satu atau lebih kolom X dapat mengakibatkan prediksi nilai Y yang sama-sama akurat. Dalam hal ini kolom X berlebihan harus dihilangkan dari model regresi. Fenomena ini disebut "collinearity" karena setiap kolom X berlebihan dapat dinyatakan sebagai jumlah dari kelipatan dari non-redundant kolom X. Fungsi LINEST memeriksa collinearity dan menghapus semua kolom X berlebihan dari model regresi ketika mengidentifikasi mereka. Kolom X Dihapus dapat diakui dalam output LINEST memiliki 0 koefisien selain 0 nilai se. Jika satu atau lebih kolom yang dihapus sebagai berlebihan, df df dipengaruhi karena tergantung pada jumlah kolom X benar-benar digunakan untuk tujuan prediksi. Untuk rincian perhitungan df, lihat Contoh 4. Jika df diubah karena kolom X berlebihan dihapus, nilai-nilai sey dan F juga terpengaruh. Collinearity harus relatif jarang terjadi dalam praktek. Namun, satu kasus di mana itu lebih mungkin timbul adalah ketika beberapa kolom X hanya berisi 0 dan 1 nilai sebagai indikator apakah subjek dalam percobaan atau tidak anggota kelompok tertentu. Jika const = TRUE atau dihilangkan, fungsi LINEST efektif menyisipkan kolom X tambahan dari semua nilai 1 untuk model INTERCEPT. Jika Anda memiliki kolom dengan 1 untuk setiap subyek jika laki-laki, atau 0 jika tidak, dan Anda juga memiliki kolom dengan 1 untuk setiap subyek jika perempuan, atau 0 jika tidak, ini kolom terakhir ini berlebihan karena entri di dalamnya dapat diperoleh dari mengurangkan entri dalam kolom "laki-laki indikator" dari entri di kolom tambahan dari semua 1 nilai tambah oleh fungsi LINEST.

• Nilai dari df dihitung sebagai berikut, ketika tidak ada kolom X dikeluarkan dari model karena collinearity: jika ada kolom k dari itu known_x dan const = TRUE atau dihilangkan, df = n - k - 1. Jika const = FALSE, df = n - k. Dalam kedua kasus, setiap kolom X yang dihapus karena collinearity meningkatkan nilai df sebesar 1.• Formula yang array kembali harus dimasukkan sebagai formula array.• Ketika memasuki sebuah array konstan (seperti yang known_x) sebagai argumen, gunakan koma untuk nilai-nilai terpisah yang terdapat dalam baris yang sama dan titik koma untuk memisahkan baris. Karakter pemisah mungkin berbeda, tergantung pada pengaturan lokal Anda di Regional dan Language Options di Control Panel.• Perhatikan bahwa y-nilai diprediksi oleh persamaan regresi dapat tidak berlaku jika mereka berada di luar jangkauan-nilai y yang digunakan untuk menentukan persamaan.• Algoritma yang mendasari digunakan dalam fungsi LINEST berbeda dari algoritma yang mendasari digunakan dalam LERENG dan fungsi INTERCEPT. Perbedaan antara algoritma ini dapat menyebabkan hasil yang berbeda ketika data belum ditentukan dan kesegarisan. Misalnya, jika titik data dari argumen known_y adalah 0 dan titik data dari argumen known_x adalah 1: LINEST mengembalikan nilai 0. Algoritma dari fungsi LINEST dirancang untuk memberikan hasil yang wajar untuk data collinear dan, dalam hal ini, paling tidak satu jawaban yang dapat ditemukan. LERENG dan INTERCEPT kembali DIV # / 0! kesalahan. Algoritma dari LERENG dan fungsi INTERCEPT dirancang untuk mencari satu jawaban, dan dalam hal ini terdapat lebih dari satu jawaban.• Selain menggunakan LOGEST untuk menghitung statistik regresi untuk jenis lain, Anda dapat menggunakan LINEST untuk menghitung berbagai jenis regresi lain dengan memasukkan fungsi dari variabel x dan y sebagai x dan y seri untuk LINEST. Misalnya, rumus berikut:= LINEST (yvalues, xvalues ^ KOLOM ($ A: $ C))bekerja ketika Anda memiliki satu kolom dari y-nilai dan satu kolom x-nilai untuk menghitung kubik (polinomial orde 3) pendekatan dalam bentuk:y = m1 * m2 * x + x ^ 2 + m3 * x ^ 3 + bAnda dapat menyesuaikan rumus ini untuk menghitung jenis-jenis regresi, tetapi dalam beberapa kasus memerlukan penyesuaian nilai output dan statistik lainnya.
Contoh 1Lereng dan Y-Intercept
1
2
3
4
5
6
7
A B C
Known y Known x
1 0
9 4
5 2
7 3
Formula Formula Result
=LINEST(A2:A5,B2:B5,,FALSE) A7=2, B7=1
PENTING Rumus dalam contoh harus dimasukkan sebagai formula array. Setelah menyalin

contoh untuk lembar kerja kosong, pilih rentang A7: B7, dimulai dengan sel formula. Tekan F2, kemudian tekan CTRL + SHIFT + ENTER. Jika formula tidak dimasukkan sebagai formula array, hasil tunggal adalah 2.Ketika masuk sebagai array, kemiringan (2) dan y-intercept (1) dikembalikan.
Contoh 2Regresi Linier Sederhana
1
2
3
4
5
6
7
8
9
A B C
Month Sales
1 3100
2 4500
3 4400
4 5400
5 7500
6 8100
Formula Description Result
=SUM(LINEST(B2:B7, A2:A7)*{9,1})
Estimate sales for the ninth month
11000
Secara umum, SUM ({m, b} * {x, 1}) sama dengan mx + b, y nilai taksiran nilai x yang diberikan. Anda juga dapat menggunakan fungsi TREND.
Contoh 3Beberapa Linear RegresiMisalkan pengembang komersial sedang mempertimbangkan membeli sekelompok bangunan kantor kecil di sebuah distrik bisnis yang mapan.Pengembang dapat menggunakan analisis regresi linier berganda untuk mengestimasi nilai dari sebuah gedung perkantoran di daerah tertentu berdasarkan variabel-variabel berikut.
VARIABLE
REFERS TO THE
y Assessed value of the office building
x1 Floor space in square feet
x2 Number of offices

x3 Number of entrances
x4 Age of the office building in years
Contoh ini mengasumsikan bahwa hubungan garis lurus ada antara setiap variabel bebas (x1, x2, x3, dan x4) dan variabel terikat (y), nilai gedung perkantoran di daerah tersebut.Pengembang secara acak memilih sampel dari 11 gedung perkantoran dari 1.500 bangunan kantor dan mungkin memperoleh data sebagai berikut. "Setengah pintu masuk" berarti pintu masuk untuk pengiriman saja.
12
3
4
5
6
7
8
9
10111213
14
A B C D E
Floor space (x1) Offices (x2)
Entrances (x3)
Age (x4)
Assessed value (y)
2310 2 2 20 142,000
2333 2 2 12 144,000
2356 3 1.5 33 151,000
2379 3 2 43 150,000
2402 2 3 53 139,000
2425 4 2 23 169,000
2448 2 1.5 99 126,000
2471 2 2 34 142,900
2494 3 3 23 163,000
2517 4 4 55 169,000
2540 2 3 22 149,000
Formula
=LINEST(E2:E12,A2:D12,TRUE,TRUE)
PENTING Rumus dalam contoh harus dimasukkan sebagai formula array. Setelah menyalin contoh untuk lembar kerja kosong, pilih rentang A14: E18 dimulai dengan sel formula. Tekan F2, kemudian tekan CTRL + SHIFT + ENTER. Jika formula tidak dimasukkan sebagai formula array, hasil tunggal -234,2371645.

Persamaan regresi berganda, y = m1 * m2 + x1 * x2 + x3 + * m3 m4 * x4 + b, dapat diperoleh dengan menggunakan nilai dari baris 14:y = 27,64 * x1 + x2 + 12.530 * 2553 * x3 - x4 + 234,24 * 52.318
Pengembang sekarang dapat memperkirakan nilai dinilai dari sebuah gedung perkantoran di daerah yang sama yang memiliki 2.500 kaki persegi, tiga kantor, dan dua pintu masuk dan 25 tahun, dengan menggunakan persamaan berikut:y = 27,64 * 2500 + 12530 * 3 + 2553 * 2 - 234,24 * 25 + 52318 = $ 158.261Atau, Anda dapat menyalin tabel berikut untuk sel A21 dari worksheet yang Anda buat untuk contoh ini.
FLOOR SPACE (X1)
OFFICES (X2)
ENTRANCES (X3)
AGE (X4)
ASSESSED VALUE (Y)
2500 3 2 25 =D14*A22 + C14*B22 + B14*C22 + A14*D22 + E14
Anda juga dapat menggunakan fungsi TREND untuk menghitung nilai ini.
Contoh 4Menggunakan Statistik F dan r2Dalam contoh sebelumnya, koefisien determinasi, atau r2, adalah 0,99675 (lihat A17 sel dalam output untuk LINEST), yang akan menunjukkan hubungan yang kuat antara variabel bebas dan harga jual. Anda dapat menggunakan statistik F untuk menentukan apakah hasil tersebut, dengan seperti nilai r2 tinggi, terjadi secara kebetulan.Asumsikan untuk saat ini bahwa sebenarnya tidak ada hubungan antara variabel-variabel, tetapi bahwa Anda telah diambil sampel langka dari 11 gedung perkantoran yang menyebabkan analisis statistik menunjukkan hubungan yang kuat. Istilah "Alpha" digunakan untuk probabilitas keliru menyimpulkan bahwa ada hubungan.Nilai-nilai F dan df dalam output dari fungsi LINEST dapat digunakan untuk menilai kemungkinan nilai F lebih tinggi terjadi secara kebetulan. F dapat dibandingkan dengan nilai-nilai penting dalam diterbitkan F-tabel distribusi atau fungsi FDIST di Excel dapat digunakan untuk menghitung probabilitas nilai F lebih besar terjadi secara kebetulan. Distribusi F yang sesuai memiliki derajat v1 dan v2 kebebasan. Jika n adalah jumlah titik data dan const = TRUE atau dihilangkan, kemudian v1 = n - df - 1 dan v2 = df. (Jika const = FALSE, maka v1 = n - df dan v2 = df.) Fungsi FDIST - dengan FDIST sintaks (F, v1, v2) - akan kembali probabilitas nilai F lebih tinggi terjadi secara kebetulan. Dalam contoh ini, df = 6 (sel B18) dan F = 459,753674 (sel A18).Dengan asumsi nilai Alpha 0,05, v1 = 11 - 6 - 1 = 4 dan v2 = 6, tingkat kekritisan F adalah 4,53. Karena F = 459.753674 jauh lebih tinggi dari 4,53, adalah sangat tidak mungkin bahwa nilai F ini tinggi terjadi secara kebetulan. (Dengan Alpha = 0,05, hipotesis bahwa tidak ada hubungan antara yang known_y dan itu known_x ada yang haram ketika F melebihi tingkat kritis, 4,53.) Anda dapat menggunakan fungsi FDIST di Excel untuk mendapatkan probabilitas bahwa nilai F ini tinggi terjadi secara kebetulan. Sebagai contoh, FDIST (459.753674, 4, 6) = 1.37E-7, sebuah kemungkinan yang sangat kecil. Anda dapat menyimpulkan, baik dengan mencari tingkat kritis F tabel atau dengan menggunakan fungsi FDIST, bahwa persamaan regresi berguna dalam memprediksi nilai dinilai gedung

perkantoran di daerah ini. Ingatlah bahwa sangat penting untuk menggunakan nilai yang benar dari v1 dan v2 yang dihitung dalam paragraf sebelumnya.
Contoh 5Menghitung t-StatistikLain uji hipotesis akan menentukan apakah masing-masing koefisien kemiringan berguna dalam memperkirakan nilai dinilai dari gedung perkantoran pada Contoh 3. Misalnya, untuk menguji koefisien usia untuk signifikansi statistik, membagi -234,24 (umur koefisien kemiringan) dengan 13,268 (standard error estimasi koefisien usia di sel A15). Berikut ini adalah nilai t-diamati:t = m4 ÷ se4 = -234,24 ÷ 13,268 = -17,7
Apabila nilai absolut t cukup tinggi, dapat disimpulkan bahwa koefisien kemiringan berguna dalam memperkirakan nilai dinilai dari gedung perkantoran pada Contoh 3. Tabel berikut menunjukkan nilai absolut dari 4 t-nilai yang diamati.Jika Anda berkonsultasi meja di manual statistik, Anda akan menemukan bahwa t-kritis, dua ekor, dengan 6 derajat kebebasan dan Alpha = 0,05 adalah 2,447. Nilai kritis juga dapat ditemukan dengan menggunakan fungsi TINV di Excel. TINV (0.05,6) = 2,447. Karena nilai absolut t (17,7) lebih besar dari 2,447, usia merupakan variabel penting ketika memperkirakan nilai dinilai dari gedung kantor. Setiap variabel independen lain dapat diuji untuk signifikansi statistik dengan cara yang sama. Berikut ini adalah t-diamati nilai untuk setiap variabel independen.
VARIABLE T-OBSERVED VALUE
Floor space 5.1
Number of offices 31.3
Number of entrances
4.8
Age 17.7
Nilai-nilai ini semua memiliki nilai absolut lebih besar dari 2,447, sehingga semua variabel yang digunakan dalam persamaan regresi berguna dalam memprediksi nilai dinilai gedung perkantoran di daerah ini.
LOGINV fungsi
Mengembalikan kebalikan dari fungsi distribusi lognormal kumulatif dari x, dimana ln (x) terdistribusi normal dengan parameter mean dan standard_dev. Jika p = LOGNORMDIST (x, ...) maka LOGINV (p, ...) = x.Gunakan distribusi lognormal untuk menganalisis data logaritmis berubah.
SintaksisLOGINV (probabilitas, berarti, standard_dev)Probabilitas adalah kemungkinan terkait dengan distribusi lognormal.Rata-rata adalah mean dari ln (x).

Standard_dev adalah deviasi standar dari ln (x).
Keterangan• Jika argumen apapun nonnumeric, LOGINV mengembalikan # VALUE! nilai kesalahan.• Jika probabilitas <0 atau probabilitas> 1, LOGINV mengembalikan NUM #! nilai kesalahan.• Jika standard_dev <= 0, LOGINV mengembalikan NUM #! nilai kesalahan.• Kebalikan dari fungsi distribusi lognormal adalah:
Contoh
1
2
3
4
A B
Data Description
0.039084 Probability associated with the lognormal distribution
3.5 Mean of ln(x)
1.2 Standard deviation of ln(x)
Formula Description (Result)
=LOGINV(A2, A3, A4)
Inverse of the lognormal cumulative distribution function for the terms above (4.000014)
LOGNORMDIST fungsi
Mengembalikan distribusi lognormal kumulatif dari x, dimana ln (x) terdistribusi normal dengan parameter mean dan standard_dev. Gunakan fungsi ini untuk menganalisis data yang telah ditransformasikan logaritmis.
SintaksisLOGNORMDIST (x, berarti, standard_dev)X adalah nilai di mana untuk mengevaluasi fungsi.Rata-rata adalah mean dari ln (x).Standard_dev adalah deviasi standar dari ln (x).

Keterangan• Jika argumen apapun nonnumeric, LOGNORMDIST mengembalikan # VALUE! nilai kesalahan.• Jika x ≤ 0 atau jika standard_dev ≤ 0, LOGNORMDIST mengembalikan NUM #! nilai kesalahan.
• Persamaan untuk fungsi distribusi lognormal kumulatif adalah:
Contoh
1
2
3
4
A B
Data Description
4 Value at which to evaluate the function x)
3. Mean of ln(x)
1.2 Standard deviation of ln(x)
Formula Description (Result)
=LOGNORMDIST(A2,A3,A4) Cumulative lognormal distribution at 4 with the terms above (0.039084)
MAX fungsi
Menampilkan nilai terbesar dalam satu set nilai.
SintaksisMAX (number1, number2, ...)Number1, number2, ... adalah 1-255 nomor yang Anda ingin mencari nilai maksimum.
Keterangan• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.

• Jika argumen adalah array atau referensi, angka saja dalam array atau referensi yang digunakan. Sel kosong, nilai-nilai logis, atau teks dalam array atau referensi akan diabaikan.• Jika argumen tidak mengandung angka, MAX mengembalikan 0 (nol).• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika Anda ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, gunakan fungsi MAXA.
Contoh
1
2
3
4
5
6
A
Data
10
7
9
27
2
Formula Description (Result)
=MAX(A2:A6) Largest of the numbers above (27)
=MAX(A2:A6, 30) Largest of the numbers above and 30 (30)
MAXA fungsi
Menampilkan nilai terbesar dalam daftar argumen.MAXA mirip dengan Mina. Untuk informasi lebih lanjut, lihat contoh untuk Mina.

SintaksisMAXA (value1, value2, ...)Value1, value2, ... adalah 1-255 nilai-nilai yang Anda ingin mencari nilai terbesar.
Keterangan• Argumen bisa menjadi berikut: Nomor; nama, array, atau referensi yang mengandung angka; representasi teks angka, atau nilai-nilai logis, seperti TRUE dan FALSE, dalam referensi.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika argumen adalah array atau referensi, hanya nilai dalam array atau referensi yang digunakan. Sel kosong dan nilai-nilai teks dalam array atau referensi akan diabaikan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Argumen yang mengandung BENAR mengevaluasi sebagai 1; argumen yang berisi teks mengevaluasi atau FALSE sebagai 0 (nol).• Jika argumen tidak mengandung nilai-nilai, MAXA kembali 0 (nol).• Jika Anda tidak ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, menggunakan fungsi MAX.
Contoh
1
2
3
4
5
6
A
Data
0
0.2
0.5
0.4
TRUE
Formula Description (Result)
=MAXA(A2:A6) Largest of the numbers above. TRUE evaluates to 1 (1)
MEDIAN fungsi
Mengembalikan median dari angka yang diberikan. Median adalah nomor di tengah satu set angka.

SintaksisMEDIAN (number1, number2, ...)Number1, number2, ... adalah 1-255 nomor yang Anda ingin median.
Keterangan• Jika ada bahkan jumlah angka di set, maka MEDIAN menghitung rata-rata dari dua angka di tengah. Lihat rumus kedua dalam contoh.• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.CATATAN Fungsi MEDIAN mengukur tendensi sentral, yang merupakan lokasi dari pusat grup nomor dalam distribusi statistik. Tiga langkah yang paling umum tendensi sentral adalah:• Rata-rata yang merupakan mean aritmetika, dan dihitung dengan menambahkan grup nomor dan kemudian membaginya dengan hitungan angka-angka. Sebagai contoh, rata-rata 2, 3, 3, 5, 7, dan 10 adalah 30 dibagi dengan 6, yang adalah 5.• Median yang merupakan jumlah tengah sekelompok nomor; yang, setengah angka memiliki nilai yang lebih besar dari median, dan setengah angka memiliki nilai yang kurang dari median. Sebagai contoh, rata-rata 2, 3, 3, 5, 7, dan 10 adalah 4.
• Mode yang merupakan jumlah yang paling sering terjadi pada sekelompok angka. Sebagai contoh, modus dari 2, 3, 3, 5, 7, dan 10 adalah 3.
Untuk distribusi simetris sekelompok nomor, ketiga ukuran tendensi sentral semua sama. Untuk distribusi miring dari sekelompok angka, mereka bisa berbeda.
Contoh
1234567
A
Data
1
2
3
4
5
6
Formula Description (Result)
=MEDIAN(A2:A6)
Median of the first 5 numbers in the list above (3)
=MEDIAN(A2:A7)
Median of all the numbers above, or the average of 3 and 4 (3.5)

MIN fungsi
Mengembalikan jumlah terkecil dalam satu set nilai.
SintaksisMIN (number1, number2, ...)Number1, number2, ... adalah 1-255 nomor yang Anda ingin mencari nilai minimum.
Keterangan• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika argumen adalah array atau referensi, angka saja dalam array atau referensi yang digunakan. Sel kosong, nilai-nilai logis, atau teks dalam array atau referensi akan diabaikan.• Jika argumen tidak mengandung angka, MIN kembali 0.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika Anda ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, gunakan fungsi Mina.
Contoh
123456
A
Data
10
7
9
27
2
Formula Description (Result)
=MIN(A2:A6) Smallest of the numbers above (2)
=MIN(A2:A6,0) Smallest of the numbers above and 0 (0)
MINA fungsi
Menampilkan nilai terkecil dalam daftar argumen.
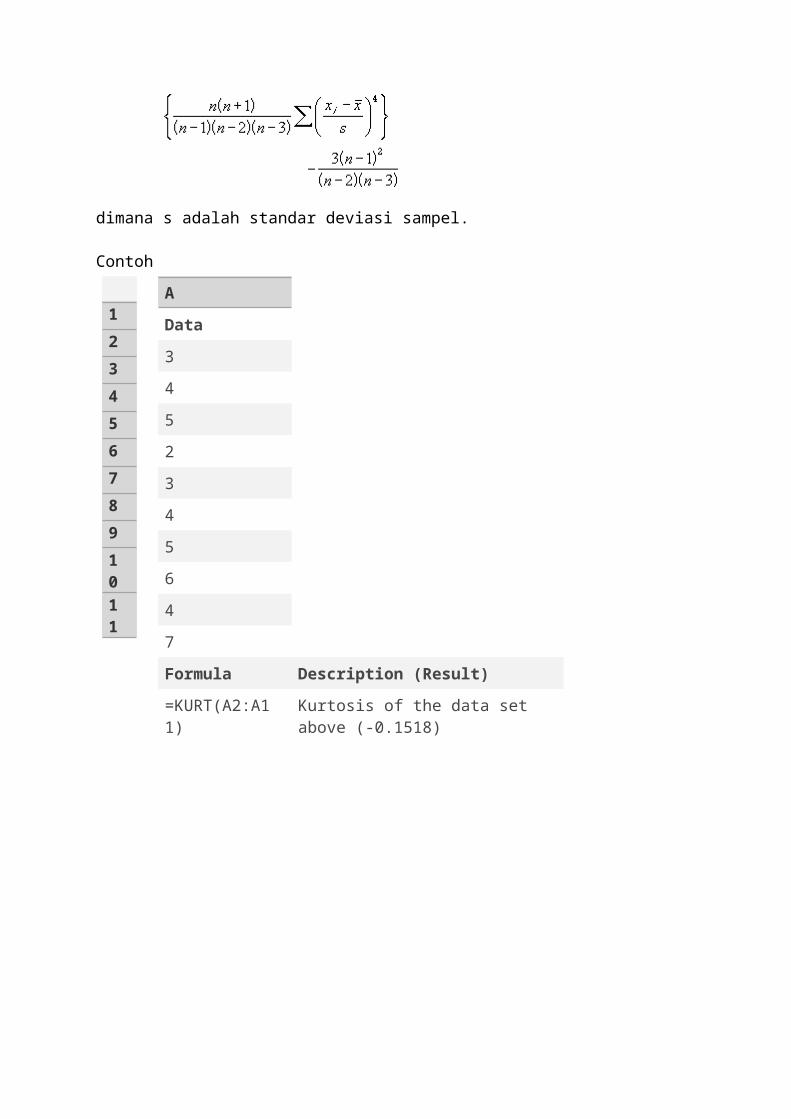
SintaksisMINA (value1, value2, ...)Value1, value2, ... adalah 1-255 nilai-nilai yang Anda ingin mencari nilai terkecil.
Keterangan• Argumen bisa menjadi berikut: Nomor; nama, array, atau referensi yang mengandung angka; representasi teks angka, atau nilai-nilai logis, seperti TRUE dan FALSE, dalam referensi.• Jika argumen adalah array atau referensi, hanya nilai dalam array atau referensi yang digunakan. Sel kosong dan nilai-nilai teks dalam array atau referensi akan diabaikan.• Argumen yang mengandung BENAR mengevaluasi sebagai 1; argumen yang berisi teks mengevaluasi atau FALSE sebagai 0 (nol).• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika argumen tidak mengandung nilai-nilai, Mina kembali 0.• Jika Anda tidak ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, menggunakan fungsi MIN.
Contoh
123456
A
Data
FALSE
0.2
0.5
0.4
0.8
Formula Description (Result)
=MINA(A2:A6)
Smallest of the numbers above. FALSE evaluates to 0 (0)
MODE fungsiMengembalikan nilai, yang paling sering terjadi, atau berulang dalam array atau range data.

SintaksisMODE (number1, number2, ...)Number1, number2, ... adalah 1-255 argumen yang Anda ingin menghitung mode. Anda juga dapat menggunakan array tunggal atau referensi ke array bukan argumen dipisahkan dengan koma.
Keterangan• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika data set tidak mengandung titik data duplikat, MODE mengembalikan # N / A nilai kesalahan.CATATAN Fungsi MODE mengukur tendensi sentral, yang merupakan lokasi dari pusat grup nomor dalam distribusi statistik. Tiga langkah yang paling umum tendensi sentral adalah:• Rata-rata yang merupakan mean aritmetika, dan dihitung dengan menambahkan grup nomor dan kemudian membaginya dengan hitungan angka-angka. Sebagai contoh, rata-rata 2, 3, 3, 5, 7, dan 10 adalah 30 dibagi dengan 6, yang adalah 5.• Median yang merupakan jumlah tengah sekelompok nomor; yang, setengah angka memiliki nilai yang lebih besar dari median, dan setengah angka memiliki nilai yang kurang dari median. Sebagai contoh, rata-rata 2, 3, 3, 5, 7, dan 10 adalah 4.• Mode yang merupakan jumlah yang paling sering terjadi pada sekelompok angka. Sebagai contoh, modus dari 2, 3, 3, 5, 7, dan 10 adalah 3.Untuk distribusi simetris sekelompok nomor, ketiga ukuran tendensi sentral semua sama. Untuk distribusi miring dari sekelompok angka, mereka bisa berbeda.
Contoh
1234567
A
Data
5.6
4
4
3
2
4
Formula Description (Result)
=MODE(A2:A7)
Mode, or most frequently occurring number above (4)

NEGBINOMDIST fungsi
Mengembalikan distribusi binomial negatif. NEGBINOMDIST kembali kemungkinan bahwa akan ada kegagalan number_f sebelum keberhasilan number_s-th, ketika probabilitas konstan sukses adalah probability_s. Fungsi ini mirip dengan distribusi binomial, kecuali bahwa jumlah keberhasilan adalah tetap, dan jumlah percobaan adalah variabel. Seperti binomial tersebut, uji coba diasumsikan independen.Misalnya, Anda perlu mencari 10 orang dengan refleks yang sangat baik, dan Anda tahu probabilitas bahwa seorang kandidat memiliki kualifikasi ini adalah 0,3. NEGBINOMDIST menghitung probabilitas bahwa Anda akan mewawancarai sejumlah calon wajar tanpa pengecualian sebelum menemukan semua 10 kandidat yang memenuhi syarat.
SintaksisNEGBINOMDIST (number_f, number_s, probability_s)Number_f adalah jumlah kegagalan.Number_s adalah jumlah ambang keberhasilan.Probability_s adalah probabilitas sukses.
Keterangan• Number_f dan number_s yang dipotong ke integer.• Jika argumen apapun nonnumeric, NEGBINOMDIST mengembalikan # VALUE! nilai kesalahan.• Jika probability_s <0 atau jika probabilitas> 1, NEGBINOMDIST mengembalikan NUM #! nilai kesalahan.• Jika number_f <0 atau number_s <1, NEGBINOMDIST mengembalikan NUM #! nilai kesalahan.
• Persamaan untuk distribusi binomial negatif adalah:dimana:
x adalah number_f, r adalah number_s, dan p adalah probability_s.
Contoh
1234
A B
Data Description
10 Number of failures
5 Threshold number of successes
0.25 Probability of a success

Formula Description (Result)
=NEGBINOMDIST(A2,A3,A4)
Negative binomial distribution for the terms above (0.055049)
NORMDIST fungsi
Mengembalikan distribusi normal untuk rata-rata yang ditentukan dan deviasi standar. Fungsi ini memiliki rentang yang sangat luas dari aplikasi dalam statistik, termasuk pengujian hipotesis.
SintaksisNORMDIST (x, berarti, standard_dev, kumulatif)X adalah nilai yang Anda ingin distribusi.Maksud adalah mean aritmetik dari distribusi.Standard_dev adalah deviasi standar dari distribusi.Kumulatif adalah nilai logis yang menentukan bentuk dari fungsi. Jika kumulatif adalah TRUE, NORMDIST mengembalikan fungsi distribusi kumulatif, jika FALSE, ia mengembalikan fungsi massa probabilitas.
Keterangan• Jika rata-rata atau standard_dev adalah nonnumeric, NORMDIST mengembalikan # VALUE! nilai kesalahan.• Jika standard_dev ≤ 0, NORMDIST mengembalikan NUM #! nilai kesalahan.• Jika mean = 0, standard_dev = 1, dan kumulatif = TRUE, NORMDIST mengembalikan distribusi normal standar, NORMSDIST.
• Persamaan untuk fungsi kepadatan normal (kumulatif = FALSE) adalah:
• Ketika kumulatif = TRUE, rumus adalah integral dari infinity negatif ke x dari rumus yang diberikan.Contoh
12
A B
Data Description
42 Value for which you want the distribution

3
4
40 Arithmetic mean of the distribution
1.5 Standard deviation of the distribution
Formula Description (Result)
=NORMDIST(A2,A3,A4,TRUE) Cumulative distribution function for the terms above (0.908789)
=NORMDIST(A2,A3,A4,FALSE) Probability mass function for the terms above (0.10934005)
NORMINV fungsi
Mengembalikan invers dari distribusi kumulatif normal untuk mean dan deviasi standar yang ditentukan.
SintaksisNORMINV (probabilitas, berarti, standard_dev)Probabilitas adalah peluang yang sesuai dengan distribusi normal.Maksud adalah mean aritmetik dari distribusi.Standard_dev adalah deviasi standar dari distribusi.
Keterangan• Jika argumen apapun nonnumeric, NORMINV mengembalikan # VALUE! nilai kesalahan.• Jika probabilitas <0 atau jika probabilitas> 1, NORMINV mengembalikan NUM #! nilai kesalahan.• Jika standard_dev ≤ 0, NORMINV mengembalikan NUM #! nilai kesalahan.• Jika mean = 0 dan standard_dev = 1, NORMINV menggunakan distribusi normal standar (lihat NORMSINV).Mengingat nilai probabilitas, NORMINV berusaha bahwa x nilai seperti yang NORMDIST (x, berarti, standard_dev, TRUE) = probabilitas. Dengan demikian, ketepatan NORMINV tergantung pada ketepatan NORMDIST. NORMINV menggunakan teknik iteratif pencarian. Jika pencarian tidak berkumpul setelah 100 iterasi, fungsi mengembalikan # N / A nilai kesalahan.
Contoh
12
34
A B
Data Description
0.908789 Probability corresponding to the normal distribution
40 Arithmetic mean of the distribution
1.5 Standard deviation of the distribution
Formula Description (Result)
=NORMINV(A2,A3,A4) Inverse of the normal cumulative distribution for the

terms above (42)
NORMSDIST fungsi
Mengembalikan fungsi distribusi kumulatif standar normal. Distribusi ini memiliki rata-rata 0 (nol) dan deviasi standar dari satu. Gunakan fungsi ini di tempat tabel luas kurva normal standar.SintaksisNORMSDIST (z)Z adalah nilai yang Anda ingin distribusi.
Keterangan• Jika z adalah nonnumeric, NORMSDIST mengembalikan # VALUE! nilai kesalahan.• Persamaan untuk fungsi kepadatan standar normal adalah:
Contoh
12
A B
Formula Description (Result)
=NORMSDIST(1.333333)
Normal cumulative distribution function at 1.333333 (0.908789)
NORMSINV fungsi
Mengembalikan invers dari distribusi kumulatif standar normal. Distribusi ini memiliki rata-rata nol dan standar deviasi satu.
SintaksisNORMSINV (probabilitas)Probabilitas adalah peluang yang sesuai dengan distribusi normal.
Keterangan• Jika probabilitas nonnumeric, NORMSINV mengembalikan # VALUE! nilai kesalahan.• Jika probabilitas <0 atau jika probabilitas> 1, NORMSINV mengembalikan NUM #! nilai

kesalahan.Mengingat nilai probabilitas, NORMSINV berusaha bahwa nilai z sehingga NORMSDIST (z) = probabilitas. Dengan demikian, ketepatan NORMSINV tergantung pada ketepatan NORMSDIST. NORMSINV menggunakan teknik iteratif pencarian. Jika pencarian tidak berkumpul setelah 100 iterasi, fungsi mengembalikan # N / A nilai kesalahan.
Contoh
12
A B
Formula Description (Result)
=NORMSINV(0.908789) Inverse of the standard normal cumulative distribution, with a probability of 0.908789 (1.3333)
PEARSON fungsi
Mengembalikan produk PEARSON saat koefisien korelasi, r, indeks berdimensi yang berkisar dari -1.0 sampai 1,0 inklusif dan mencerminkan tingkat hubungan linear antara dua set data.
SintaksisPEARSON (array1, array2)Array1 adalah seperangkat nilai-nilai independen.Array2 adalah seperangkat nilai-nilai tergantung.
Keterangan• Argumen harus berupa nomor atau nama, konstanta array, atau referensi yang mengandung angka.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Jika array1 dan array2 kosong atau memiliki nomor yang berbeda dari titik data, PEARSON mengembalikan # N / A nilai kesalahan.
• Rumus untuk produk saat koefisien korelasi PEARSON, r, adalah:
di mana x dan y adalah sampel berarti RATA-RATA (array1) dan RATA-RATA (array2).Contoh
A B

1
23456
Independent values Dependent values
9 10
7 6
5 1
3 5
1 3
Formula Description (Result)
=PEARSON(A2:A6,B2:B6) Pearson product moment correlation coefficient for the data sets above (0.699379)
PERSENTIL fungsi
Mengembalikan persentil ke-k dari nilai-nilai dalam kisaran. Anda dapat menggunakan fungsi ini untuk menetapkan ambang batas penerimaan. Sebagai contoh, Anda dapat memutuskan untuk memeriksa calon yang mendapat skor di atas persentil ke-90.
SintaksisPERSENTIL (array, k)Array adalah array atau range data yang mendefinisikan berdiri relatif.K adalah nilai persentil dalam rentang 0 .. 1, inklusif.
Keterangan• Jika array kosong atau berisi lebih dari 8.191 titik data, PERSENTIL mengembalikan NUM #! nilai kesalahan.• Jika k adalah nonnumeric, PERSENTIL mengembalikan # VALUE! nilai kesalahan.• Jika k adalah <0 atau jika k> 1, PERSENTIL mengembalikan NUM #! nilai kesalahan.• Jika k adalah bukan kelipatan dari 1 / (n - 1), PERSENTIL interpolates untuk menentukan nilai pada persentil ke-k.
Contoh
12345
A
Data
1
3
2

4
Formula Description (Result)
=PERCENTILE(A2:A5,0.3)
30th percentile of the list above (1.9)
PERCENTRANK fungsi
Mengembalikan pangkat nilai dalam data set sebagai persentase dari kumpulan data. Fungsi ini dapat digunakan untuk mengevaluasi posisi relatif dari nilai dalam kumpulan data. Sebagai contoh, Anda dapat menggunakan PERCENTRANK untuk mengevaluasi berdiri dari nilai ujian bakat antara semua skor untuk ujian.
SintaksisPERCENTRANK (array, x, signifikansi)Array adalah array atau range data dengan nilai numerik yang mendefinisikan berdiri relatif.X adalah nilai yang Anda ingin tahu peringkat.Signifikansi adalah nilai opsional yang menunjukkan jumlah digit yang signifikan untuk nilai persentase dikembalikan. Jika diabaikan, PERCENTRANK menggunakan tiga digit (0.xxx).
Keterangan• Jika array kosong, PERCENTRANK mengembalikan NUM #! nilai kesalahan.• Jika signifikansi <1, PERCENTRANK mengembalikan NUM #! nilai kesalahan.• Jika x tidak cocok dengan salah satu nilai dalam array, PERCENTRANK interpolates untuk mengembalikan peringkat persentase yang benar.
ContohA
Data
13

12
11
8
4
3
2
1
1
1
Formula Description (Result)
=PERCENTRANK(A2:A11,2)
Percent rank of 2 in the list above (0.333, because 3 values in the set are smaller than 2, and 6 are larger than 2; 3/(3+6)=0.333)
=PERCENTRANK(A2:A11,4)
Percent rank of 4 in the list above (0.555)
=PERCENTRANK(A2:A11,8)
Percent rank of 8 in the list above (0.666)
=PERCENTRANK(A2:A11,5)
Percent rank of 5 in the list above (0.583, one-quarter of the way between the PERCENTRANK of 4 and the PERCENTRANK of 8)
PERMUT fungsi
Mengembalikan jumlah permutasi untuk sejumlah tertentu objek yang bisa dipilih dari benda-benda nomor. Sebuah permutasi adalah setiap set atau subset dari objek atau peristiwa dimana pesanan internal adalah signifikan. Permutasi berbeda kombinasi, yang urutan internal tidak signifikan. Gunakan fungsi ini untuk lotere gaya perhitungan probabilitas.
SintaksisPERMUT (nomor, number_chosen)Nomor adalah bilangan bulat yang menggambarkan jumlah objek.Number_chosen adalah bilangan bulat yang menggambarkan jumlah objek dalam setiap permutasi.
Keterangan• Kedua argumen yang dipotong ke integer.• Jika nomor atau number_chosen adalah nonnumeric, PERMUT mengembalikan # VALUE! nilai kesalahan.• Jika nomor ≤ 0 atau jika number_chosen <0, PERMUT mengembalikan NUM #! nilai kesalahan.
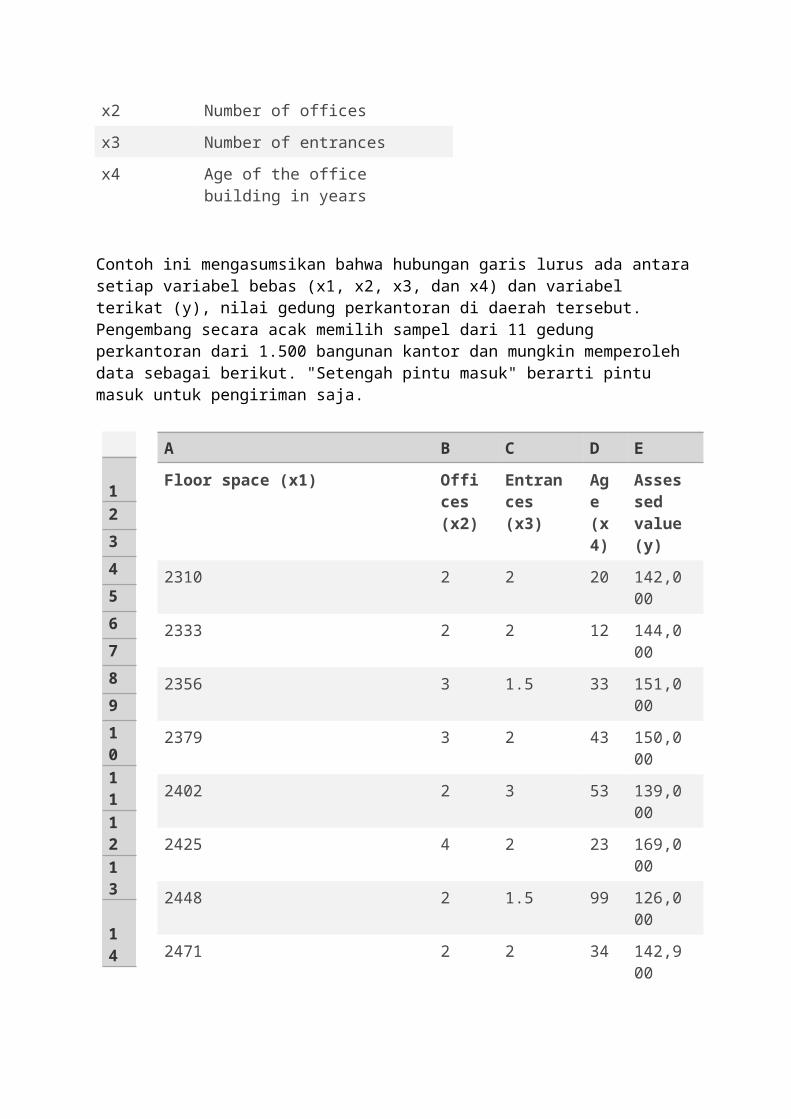
• Jika nomor <number_chosen, PERMUT mengembalikan NUM #! nilai kesalahan.• Persamaan untuk jumlah permutasi adalah:
ContohMisalnya anda ingin menghitung peluang memilih nomor lotere yang menang. Setiap nomor undian berisi tiga angka, yang masing-masing dapat antara 0 (nol), dan 99 inklusif. Fungsi berikut menghitung jumlah permutasi yang mungkin:
123
A B
Data Description
100 Number of objects
3 Number of objects in each permutation
Formula Description (Result)
=PERMUT(A2,A3) Permutations possible for the terms above (970200)
POISSON fungsi
Mengembalikan distribusi Poisson. Sebuah aplikasi umum dari distribusi Poisson adalah memprediksi jumlah kejadian selama waktu tertentu, seperti jumlah mobil tiba di sebuah plaza tol dalam 1 menit.
SintaksisPOISSON (x, berarti, kumulatif)X adalah jumlah kejadian.Berarti adalah nilai numerik yang diharapkan.Kumulatif adalah nilai logis yang menentukan bentuk distribusi probabilitas kembali. Jika kumulatif adalah TRUE, POISSON mengembalikan probabilitas Poisson kumulatif bahwa jumlah peristiwa acak yang terjadi akan menjadi antara nol dan inklusif x, jika FALSE, ia mengembalikan fungsi massa probabilitas Poisson bahwa jumlah peristiwa yang terjadi akan persis x.
Keterangan• Jika x tidak integer, itu terpotong.• Jika x atau maksud adalah nonnumeric, POISSON mengembalikan # VALUE! nilai kesalahan.• Jika x <0, POISSON mengembalikan NUM #! nilai kesalahan.• Jika berarti <0, POISSON mengembalikan NUM #! nilai kesalahan.• POISSON dihitung sebagai berikut.Untuk kumulatif = FALSE:

Untuk kumulatif = TRUE:
Contoh
123
A B
Data Description
2 Number of events
5 Expected mean
Formula Description (Result)
=POISSON(A2,A3,TRUE) Cumulative Poisson probability with the terms above (0.124652)
=POISSON(A2,A3,FALSE)
Poisson probability mass function with the terms above (0.084224)
Probabilitas, PROB fungsiMengembalikan probabilitas bahwa nilai-nilai berkisar adalah antara dua batas. Jika upper_limit ini tidak disertakan, mengembalikan probabilitas bahwa nilai dalam x_range sama dengan lower_limit.
SintaksisProbabilitas, PROB (x_range, prob_range, lower_limit, upper_limit)X_range adalah rentang nilai-nilai numerik dari x dengan yang ada probabilitas yang terkait.Prob_range adalah seperangkat probabilitas yang terkait dengan nilai-nilai dalam x_range.Lower_limit adalah batas bawah pada nilai yang Anda ingin probabilitas.Upper_limit adalah opsional atas terikat pada nilai yang Anda ingin probabilitas.
Keterangan• Jika nilai apapun dalam prob_range ≤ 0 atau jika ada nilai di prob_range> 1, probabilitas, PROB mengembalikan # NUM! nilai kesalahan.• Jika jumlah nilai di prob_range tidak sama dengan 1, probabilitas, PROB mengembalikan NUM #! nilai kesalahan.

• Jika upper_limit dihilangkan, probabilitas, PROB kembali probabilitas yang sama dengan lower_limit.• Jika x_range dan prob_range mengandung nomor yang berbeda dari titik data, probabilitas, PROB mengembalikan # N / A nilai kesalahan.
Contoh
12345
A B
x Probability
0 0.2
1 0.3
2 0.1
3 0.4
Formula Description (Result)
=PROB(A2:A5,B2:B5,2) Probability that x is 2 (0.1)
=PROB(A2:A5,B2:B5,1,3)
Probability that x is between 1 and 3 (0.8)
QUARTILE fungsi
Mengembalikan QUARTILE dari suatu kumpulan data. QUARTILE sering digunakan dalam penjualan dan data survei untuk membagi populasi ke dalam kelompok. Sebagai contoh, Anda dapat menggunakan QUARTILE untuk menemukan atas 25 persen dari pendapatan dalam suatu populasi.
SintaksisQUARTILE (array, liter)Array adalah rentang array atau sel dari nilai numerik yang Anda ingin nilai QUARTILE.Quart menunjukkan nilai untuk kembali.
IF QUART EQUALS
QUARTILE RETURNS
0 Minimum value
1 First quartile (25th percentile)

2 Median value (50th percentile)
3 Third quartile (75th percentile)
4 Maximum value
Keterangan• Jika array kosong, QUARTILE mengembalikan NUM #! nilai kesalahan.• Jika liter tidak integer, itu terpotong.• Jika liter <0 atau jika liter> 4, QUARTILE mengembalikan NUM #! nilai kesalahan.• MIN, MEDIAN, dan MAX mengembalikan nilai yang sama seperti ketika QUARTILE liter sama dengan 0 (nol), 2, dan 4, masing-masing.
Contoh
123456789
A
Data
1
2
4
7
8
9
10
12
Formula Description (Result)
=QUARTILE(A2:A9,1)
First quartile (25th percentile) of the data above (3.5)
RANK fungsi
Mengembalikan pangkat angka dalam daftar nomor. Pangkat angka adalah ukuran relatif terhadap nilai-nilai lain dalam daftar. (Jika Anda adalah untuk menyortir daftar, pangkat nomor akan posisinya.)
SintaksisRANK (angka, ref, order)

Nomor adalah nomor yang peringkat Anda ingin mencari.Ref adalah array, atau referensi untuk, daftar nomor. Nilai nonnumeric di ref diabaikan.Order sejumlah menentukan bagaimana peringkat nomor.• Jika order adalah 0 (nol) atau diabaikan, Microsoft Excel peringkat nomor seolah ref adalah daftar diurutkan dalam urutan.• Jika pesanan adalah setiap nilai nol, Microsoft Excel peringkat nomor seolah ref adalah daftar diurutkan dalam urutan menaik.
Keterangan• RANK memberikan nomor duplikat nilai yang sama. Namun, kehadiran sejumlah duplikat mempengaruhi jajaran nomor berikutnya. Sebagai contoh, dalam daftar bilangan bulat diurutkan dalam urutan menaik, jika jumlah 10 muncul dua kali dan memiliki pangkat 5, maka 11 akan memiliki peringkat 7 (tidak ada nomor yang akan memiliki peringkat 6).• Untuk beberapa tujuan orang mungkin ingin menggunakan definisi peringkat yang mengambil hubungan ke rekening. Pada contoh sebelumnya, orang akan ingin peringkat revisi 5,5 untuk nomor 10. Hal ini dapat dilakukan dengan menambahkan faktor koreksi berikut untuk nilai yang dikembalikan oleh RANK. Faktor koreksi yang tepat baik untuk kasus di mana peringkat dihitung dalam urutan (order = 0 atau dihilangkan) atau urutan menaik (order = nilai nol).Faktor koreksi untuk jajaran terikat = [COUNT (ref) + 1 - RANK (angka, ref, 0) - RANK (angka, ref, 1)] / 2.Pada contoh berikut, RANK (A2, A1: A5, 1) sama dengan 3. Faktor koreksi adalah (5 + 1 - 2 - 3) / 2 = 0,5 dan peringkat revisi yang mengambil hubungan diperhatikan adalah 3 + 0,5 = 3,5. Jika nomor terjadi hanya sekali dalam ref, faktor koreksi akan 0, karena RANK tidak harus disesuaikan dengan dasi.
Contoh
123456
A
Data
7
3.5
3.5
1
2
Formula Description (Result)
=RANK(A3,A2:A6,1) Rank of 3.5 in the list above (3)
=RANK(A2,A2:A6,1) Rank of 7 in the list above (5)
RSQ Fungsi
Mengembalikan kuadrat dari koefisien korelasi product moment PEARSON melalui titik data dalam yang known_y dan itu known_x. Untuk informasi lebih lanjut, lihat PEARSON. Nilai r-squared dapat diartikan sebagai proporsi varians dalam y disebabkan oleh varians dalam x.

SintaksisRSQ (s known_y, yang known_x)Yang Known_y adalah array atau range titik data.Yang Known_x adalah array atau range titik data.
Keterangan• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika kita known_y dan itu known_x kosong atau memiliki nomor yang berbeda dari titik data, RSQ mengembalikan # N / A nilai kesalahan.• Jika kita known_y dan itu known_x hanya berisi 1 data titik, RSQ mengembalikan DIV # / 0! nilai kesalahan.
• Persamaan untuk produk saat koefisien korelasi PEARSON, r, adalah:
di mana x dan y adalah sampel berarti RATA-RATA (s known_x) dan RATA-RATA (s known_y).RSQ kembali r2, yang merupakan kuadrat dari koefisien korelasi.
Contoh
12345678
A B
Known y Known x
2 6
3 5
9 11
1 7
8 5
7 4
5 4
Formula Description (Result)
=RSQ(A2:A8,B2:B8)
Square of the Pearson product moment correlation coefficient through data points above (0.05795)

SKEW fungsi
Mengembalikan kemiringan dari suatu distribusi. Skewness ciri derajat asimetri dari suatu distribusi sekitar mean. Kemiringan positif menunjukkan distribusi dengan ekor yang asimetris memperluas ke arah nilai-nilai positif lebih banyak. Kemiringan negatif menunjukkan distribusi dengan ekor asimetris memperluas ke arah nilai-nilai negatif lagi.
SintaksisSKEW (number1, number2, ...)Number1, number2 ... adalah 1-255 argumen yang Anda ingin menghitung kemiringan. Anda juga dapat menggunakan array tunggal atau referensi ke array bukan argumen dipisahkan dengan koma.
Keterangan• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika ada kurang dari tiga data poin atau standar deviasi sampel adalah nol, SKEW mengembalikan DIV # / 0! nilai kesalahan.• Persamaan untuk kemiringan didefinisikan sebagai:
Contoh
123456789
A
Data
3
4
5
2
3
4
5

1011
6
4
7
Formula Description (Result)
=SKEW(A2:A11) Skewness of a distribution of the data set above (0.359543)
SLOPE fungsi
Mengembalikan kemiringan garis regresi linier melalui titik data dalam yang known_y dan itu known_x. Kemiringan adalah jarak vertikal dibagi dengan jarak horizontal antara dua titik pada garis, yang merupakan tingkat perubahan sepanjang garis regresi.
SintaksisSLOPE (s known_y, yang known_x)Yang Known_y adalah berbagai array atau sel numerik titik data dependen.Yang Known_x adalah himpunan titik data independen.
Keterangan• Argumen harus berupa nomor atau nama, array, atau referensi yang mengandung angka.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Jika kita known_y dan itu known_x kosong atau memiliki nomor yang berbeda dari titik data, SLOPE mengembalikan # N / A nilai kesalahan.• Persamaan untuk kemiringan garis regresi adalah:
di mana x dan y adalah sampel berarti RATA-RATA (s known_x) dan RATA-RATA (s known_y).• Algoritma yang mendasari digunakan dalam SLOPE dan fungsi mencegat berbeda dari algoritma yang mendasari digunakan dalam fungsi LINEST. Perbedaan antara algoritma ini dapat menyebabkan hasil yang berbeda ketika data belum ditentukan dan kesegarisan. Misalnya, jika titik data dari argumen known_y adalah 0 dan titik data dari argumen known_x adalah 1: SLOPE dan mencegat kembali DIV # / 0! kesalahan. Para SLOPE dan algoritma mencegat dirancang untuk mencari satu dan hanya satu jawaban, dan dalam hal ini terdapat lebih dari satu jawaban. LINEST mengembalikan nilai 0. Algoritma LINEST dirancang untuk memberikan hasil

yang wajar untuk data collinear, dan dalam hal ini paling tidak satu jawaban yang dapat ditemukan.
Contoh
12345678
A B
Known y Known x
2 6
3 5
9 11
1 7
8 5
7 4
5 4
Formula Description (Result)
=SLOPE(A2:A8,B2:B8) Slope of the linear regression line through the data points above (0.305556)
SMALL fungsi
Menampilkan nilai terkecil ke-k dalam satu set data. Gunakan fungsi ini untuk mengembalikan nilai dengan berdiri relatif tertentu dalam kumpulan data.
SintaksisSMALL (array, k)Array adalah array atau range data numerik yang Anda ingin menentukan nilai terkecil ke-k.

K adalah posisi (dari terkecil) dalam array atau range data untuk kembali.
Keterangan• Jika array kosong, SMALL mengembalikan NUM #! nilai kesalahan.• Jika k ≤ 0 atau jika k melebihi jumlah titik data, SMALL mengembalikan NUM #! nilai kesalahan.• Jika n adalah jumlah titik data dalam array, SMALL (array, 1) sama dengan nilai terkecil, dan SMALL (array, n) sama dengan nilai terbesar.
Contoh
12345678910
A B
Data Data
3 1
4 4
5 8
2 3
3 7
4 12
6 54
4 8
7 23
Formula Description (Result)
=SMALL(A2:A10,4)
4th smallest number in first column (4)
=SMALL(B2:B10,2) 2nd smallest number in the second column (3)
STANDARDIZE fungsi

Mengembalikan nilai dari distribusi normal ditandai dengan mean dan standard_dev.
SintaksisSTANDARDIZE (x, berarti, standard_dev)X adalah nilai yang akan menormalkan.Maksud adalah mean aritmetik dari distribusi.Standard_dev adalah deviasi standar dari distribusi.Keterangan• Jika standard_dev ≤ 0, STANDARDIZE mengembalikan NUM #! nilai kesalahan.• Persamaan untuk nilai normalisasi adalah:
Contoh
1234
A B
Data Description
42 Value to normalize
40 Arithmetic mean of the distribuion
1.5 Standard deviation of the distribution
Formula Description (Result)
=STANDARDIZE(A2,A3,A4) Normalized value of 42 for the terms above (1.333333)
STDEV fungsi
Estimasi standar deviasi berdasarkan sampel. Standar deviasi adalah ukuran dari seberapa besar nilai tersebar dari nilai rata-rata (mean).
SintaksisSTDEV (number1, number2, ...)Number1, number2, ... adalah 1-255 argumen angka yang sesuai dengan sampel dari populasi. Anda juga dapat menggunakan array tunggal atau referensi ke array bukan argumen dipisahkan dengan koma.

Keterangan• STDEV mengasumsikan bahwa argumen adalah contoh dari populasi. Jika data Anda mewakili seluruh populasi, kemudian menghitung deviasi standar menggunakan STDEVP.• Standar deviasi dihitung menggunakan "n-1" metode.• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika argumen adalah array atau referensi, angka saja dalam array atau referensi dihitung. Sel kosong, nilai-nilai logis, teks, atau nilai-nilai kesalahan dalam array atau referensi akan diabaikan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika Anda ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, gunakan fungsi STDEVA.• STDEV menggunakan rumus berikut:
di mana x adalah rata-rata sampel AVERAGE (number1, number2, ...) dan n adalah ukuran sampel.
Contoh
1234567891011
A
Strength
1345
1301
1368
1322
1310
1370
1318
1350
1303
1299
Formula Description (Result)
=STDEV(A2:A11)
Standard deviation of breaking strength (27.46391572)

STDEVA fungsi
Estimasi standar deviasi berdasarkan sampel. Standar deviasi adalah ukuran dari seberapa besar nilai tersebar dari nilai rata-rata (mean).
SintaksisSTDEVA (value1, value2, ...)Value1, value2, ... adalah 1-255 nilai yang sesuai dengan sampel populasi. Anda juga dapat menggunakan array tunggal atau referensi ke array bukan argumen dipisahkan dengan koma.
Keterangan• STDEVA mengasumsikan bahwa argumen adalah contoh dari populasi. Jika data Anda mewakili seluruh populasi, Anda harus menghitung deviasi standar menggunakan STDEVPA.• Standar deviasi dihitung menggunakan "n-1" metode.• Argumen bisa menjadi berikut: Nomor; nama, array, atau referensi yang mengandung angka; representasi teks angka, atau nilai-nilai logis, seperti TRUE dan FALSE, dalam referensi.• Argumen yang mengandung BENAR mengevaluasi sebagai 1; argumen yang berisi teks mengevaluasi atau FALSE sebagai 0 (nol).• Jika argumen adalah array atau referensi, hanya nilai dalam array atau referensi yang digunakan. Sel kosong dan nilai-nilai teks dalam array atau referensi akan diabaikan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika Anda tidak ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, menggunakan fungsi STDEV.• STDEVA menggunakan rumus berikut:
di mana x adalah rata-rata sampel RATA-RATA (value1, value2, ...) dan n adalah ukuran sampel.
Contoh
123456
A
Strength
1345
1301
1368
1322

7891011
1310
1370
1318
1350
1303
1299
Formula Description (Result)
=STDEVA(A2:A11) Standard deviation of breaking strength for all the tools (27.46391572)
STDEVP fungsi
Menghitung deviasi standar berdasarkan seluruh penduduk diberikan sebagai argumen. Standar deviasi adalah ukuran dari seberapa besar nilai tersebar dari nilai rata-rata (mean).
SintaksisSTDEVP (number1, number2, ...)Number1, number2, ... adalah 1-255 argumen angka yang sesuai untuk populasi. Anda juga dapat menggunakan array tunggal atau referensi ke array bukan argumen dipisahkan dengan koma.
Keterangan• STDEVP mengasumsikan bahwa argumen adalah seluruh penduduk. Jika data Anda merupakan sampel dari populasi, kemudian menghitung deviasi standar menggunakan STDEV.• Untuk ukuran sampel yang besar, STDEV dan STDEVP kembali nilai-nilai kurang lebih sama.• Standar deviasi dihitung menggunakan "n" metode.• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis, dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika argumen adalah array atau referensi, angka saja dalam array atau referensi dihitung. Sel kosong, nilai-nilai logis, teks, atau nilai-nilai kesalahan dalam array atau referensi akan diabaikan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika Anda ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, gunakan fungsi STDEVPA.• STDEVP menggunakan rumus berikut:

di mana x adalah rata-rata sampel AVERAGE (number1, number2, ...) dan n adalah ukuran sampel.
Contoh
1234567891011
A
Strength
1345
1301
1368
1322
1310
1370
1318
1350
1303
1299
Formula Description (Result)
=STDEVP(A2:A11)
Standard deviation of breaking strength, assuming only 10 tools are produced (26.05455814)

STDEVPA fungsi
Menghitung deviasi standar berdasarkan seluruh penduduk diberikan sebagai argumen, termasuk teks dan nilai-nilai logis. Standar deviasi adalah ukuran dari seberapa besar nilai tersebar dari nilai rata-rata (mean).
SintaksisSTDEVPA (value1, value2, ...)Value1, value2, ... adalah 1-255 sesuai dengan nilai-nilai populasi. Anda juga dapat menggunakan array tunggal atau referensi ke array bukan argumen dipisahkan dengan koma.
Keterangan• STDEVPA mengasumsikan bahwa argumen adalah seluruh penduduk. Jika data Anda merupakan sampel dari populasi, Anda harus menghitung deviasi standar dengan menggunakan STDEVA.• Untuk ukuran sampel yang besar, STDEVA dan STDEVPA kembali nilai-nilai kurang lebih sama.• Standar deviasi dihitung menggunakan "n" metode.• Argumen bisa menjadi berikut: Nomor; nama, array, atau referensi yang mengandung angka; representasi teks angka, atau nilai-nilai logis, seperti TRUE dan FALSE, dalam referensi.Representasi Teks • angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Argumen yang mengandung BENAR mengevaluasi sebagai 1; argumen yang berisi teks mengevaluasi atau FALSE sebagai 0 (nol).• Jika argumen adalah array atau referensi, hanya nilai dalam array atau referensi yang digunakan. Sel kosong dan nilai-nilai teks dalam array atau referensi akan diabaikan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika Anda tidak ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, gunakan fungsi STDEVP.• STDEVPA menggunakan rumus berikut:
di mana x adalah rata-rata sampel RATA-RATA (value1, value2, ...) dan n adalah ukuran sampel.
Contoh
12345
A
Strength
1345
1301
1368

67891011
1322
1310
1370
1318
1350
1303
1299
Formula Description (Result)
=STDEVPA(A2:A11) Standard deviation of breaking strength, assuming only 10 tools are produced (26.05455814)
STEYX fungsi
Mengembalikan standard error dari nilai y diprediksi untuk setiap x dalam regresi. Kesalahan standar adalah ukuran dari jumlah kesalahan dalam prediksi dari y untuk x individu.
SintaksisSTEYX (s known_y, yang known_x)Yang Known_y adalah array atau range titik data dependen.Yang Known_x adalah array atau range titik data independen.
Keterangan• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika array atau argumen referensi berisi teks, nilai-nilai logis, atau sel kosong, nilai-nilai tersebut diabaikan, namun, sel-sel dengan nilai nol disertakan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika kita known_y dan itu known_x memiliki nomor yang berbeda dari titik data, STEYX mengembalikan # N / A nilai kesalahan.• Jika kita known_y dan itu known_x kosong atau memiliki kurang dari tiga titik data, STEYX mengembalikan DIV # / 0! nilai kesalahan.• Persamaan untuk kesalahan standar dari y diperkirakan adalah:

di mana x dan y adalah sampel berarti RATA-RATA (s known_x) dan RATA-RATA (s known_y), dan n adalah ukuran sampel.
Contoh
12345678
A B
Known y Known x
2 6
3 5
9 11
1 7
8 5
7 4
5 4
Formula Description (Result)
=STEYX(A2:A8,B2:B8) Standard error of the predicted y-value for each x in the regression (3.305719)
TDIST fungsi
Pengembalian Poin Persentase tersebut (probabilitas) untuk Student t-distribusi di mana nilai numerik (x) adalah nilai yang dihitung t yang Poin Persentase harus dihitung. T-distribusi yang digunakan dalam pengujian hipotesis set data sampel yang kecil. Gunakan fungsi ini di tempat merupakan tabel nilai kritis untuk distribusi t-.
SintaksisTDIST (x, degrees_freedom, ekor)X adalah nilai numerik di mana untuk mengevaluasi distribusi.Degrees_freedom adalah bilangan bulat yang menunjukkan jumlah derajat kebebasan.Ekor menentukan jumlah ekor distribusi untuk kembali. Jika ekor = 1, TDIST mengembalikan distribusi satu-ekor. Jika ekor = 2, TDIST mengembalikan distribusi dua-ekor.
Keterangan• Jika argumen apapun nonnumeric, TDIST mengembalikan # VALUE! nilai kesalahan.• Jika degrees_freedom <1, TDIST mengembalikan NUM #! nilai kesalahan.• Para degrees_freedom dan argumen ekor yang dipotong ke integer.• Jika ekor adalah nilai lain dari 1 atau 2, TDIST mengembalikan NUM #! nilai kesalahan.• Jika x <0, maka TDIST mengembalikan NUM #! nilai kesalahan.• Jika ekor = 1, TDIST dihitung sebagai TDIST = P (X> x), dimana X adalah variabel acak yang mengikuti t-distribusi. Jika ekor = 2, TDIST dihitung sebagai TDIST = P (| x |> x) = P (X> x atau X <-x).• Karena x <0 tidak diperbolehkan, untuk menggunakan TDIST ketika x <0, perhatikan

bahwa TDIST (-x, df, 1) = 1 - TDIST (x, df, 1) = P (X>-x) dan TDIST ( -x, df, 2) = TDIST (x df, 2) = P (| x |> x).
Contoh
12
3
A B
Data Description
1.959999998 Value at which to evaluate the distribution
60 Degrees of freedom
Formula Description (Result)
=TDIST(A2,A3,2)
Two-tailed distribution (0.054644927, or 5.46 percent)
=TDIST(A2,A3,1)
One-tailed distribution (0.027322464 or 2.73 percent)
CATATAN Untuk melihat nomor sebagai persentase, pilih sel, dan kemudian pada tab Sheet, di grup Nomor, klik Style Persen.
TINV fungsi
Mengembalikan t-nilai Student t-distribusi sebagai fungsi dari probabilitas dan derajat kebebasan.
SintaksisTINV (probabilitas, degrees_freedom)Probabilitas adalah probabilitas yang terkait dengan t-distribusi Student dua sisi itu.Degrees_freedom adalah jumlah derajat kebebasan yang dapat digunakan untuk mengkarakterisasi distribusi.
Keterangan• Jika argumen baik adalah nonnumeric, TINV mengembalikan # VALUE! nilai kesalahan.• Jika probabilitas <0 atau jika probabilitas> 1, TINV mengembalikan NUM #! nilai kesalahan.• Jika degrees_freedom tidak integer, itu terpotong.• Jika degrees_freedom <1, TINV mengembalikan NUM #! nilai kesalahan.• TINV pengembalian yang nilai t, sehingga P (| x |> t) = probabilitas di mana X adalah variabel acak yang mengikuti t-distribusi dan P (| x |> t) = P (X <-t atau X> t).• Sebuah satu sisi t-nilai dapat dikembalikan dengan mengganti probabilitas dengan 2 probabilitas *. Untuk probabilitas 0,05 dan derajat kebebasan 10, nilai dua sisi dihitung dengan TINV (0.05,10), yang mengembalikan 2,28139. Nilai satu-ekor untuk probabilitas yang sama dan derajat kebebasan dapat dihitung dengan TINV (2 * 0.05,10), yang mengembalikan 1,812462.
CATATAN Dalam beberapa tabel, probabilitas digambarkan sebagai (1-p).Mengingat nilai probabilitas, TINV berusaha bahwa x nilai seperti yang TDIST (x, degrees_freedom, 2) = probabilitas. Dengan demikian, ketepatan TINV tergantung pada

ketepatan TDIST. TINV menggunakan teknik iteratif pencarian. Jika pencarian tidak berkumpul setelah 100 iterasi, fungsi mengembalikan # N / A nilai kesalahan.
Contoh
12
3
A B
Data Description
0.054644927 Probability associated with the two-tailed Student's t-distribution
60 Degrees of freedom
Formula Description (Result)
=TINV(A2,A3)
t-value of the Student's t-distribution for the terms above (1.959999998)
TREND fungsi
Pengembalian nilai sepanjang tren linier. Fits garis lurus (menggunakan metode kuadrat terkecil) ke known_y array dan yang known_x. Mengembalikan y-nilai sepanjang garis bahwa untuk array yang new_x yang Anda tentukan.
SintaksisTREND (yang known_y, yang known_x, yang new_x, const)Yang Known_y adalah himpunan dari y-nilai yang Anda sudah tahu dalam hubungan y = mx + b.• Jika array known_y itu adalah dalam satu kolom, maka setiap kolom yang known_x diinterpretasikan sebagai variabel terpisah.• Jika array known_y itu adalah dalam satu baris, maka setiap baris yang known_x diinterpretasikan sebagai variabel terpisah.Yang Known_x merupakan perangkat opsional dari x-nilai yang Anda mungkin sudah tahu dalam hubungan y = mx + b.• Para s Array known_x dapat mencakup satu atau lebih set variabel. Jika hanya satu variabel yang digunakan, yang known_y dan itu known_x dapat berkisar dari bentuk apapun, selama mereka memiliki dimensi yang sama. Jika lebih dari satu variabel yang digunakan, yang known_y harus menjadi vektor (yaitu, berbagai dengan tinggi satu baris atau lebar satu kolom).• Jika kita known_x diabaikan, diasumsikan array {1,2,3, ...} yang ukuran sama seperti known_y.Yang New_x baru x-nilai yang Anda ingin TREND kembali sesuai y-nilai.• yang New_x harus menyertakan kolom (atau baris) untuk setiap variabel independen, sama seperti known_x tidak. Jadi, jika kita known_y dalam satu kolom, yang known_x dan itu new_x harus memiliki jumlah kolom yang sama. Jika itu known_y dalam satu baris, yang known_x dan itu new_x harus memiliki jumlah baris yang sama.• Jika Anda menghilangkan itu new_x, diasumsikan untuk menjadi sama seperti known_x.• Jika Anda menghilangkan kedua yang known_x dan itu new_x, mereka diasumsikan array

{1,2,3, ...} yang ukuran sama seperti known_y.Const adalah nilai logis menentukan apakah akan memaksa b konstan 0 sama.• Jika const adalah TRUE atau dihilangkan, b dihitung secara normal.• Jika const adalah FALSE, b ditetapkan sama dengan 0 (nol), dan m-nilai yang disesuaikan sehingga y = mx.
Keterangan• Untuk informasi mengenai bagaimana Microsoft Excel sesuai garis untuk data, lihat LINEST.• Anda dapat menggunakan TREND untuk pemasangan kurva polinomial dengan regresi terhadap variabel yang sama dinaikkan menjadi kekuatan yang berbeda. Misalnya, kolom A berisi nilai-nilai y dan kolom B berisi x-nilai. Anda dapat memasukkan x ^ 2 di kolom C, x ^ 3 di kolom D, dan sebagainya, dan kemudian mundur kolom B melalui D terhadap kolom A.• Formula yang array kembali harus dimasukkan sebagai formula array.• Ketika memasuki sebuah array konstan untuk argumen seperti itu known_x, gunakan koma untuk memisahkan nilai-nilai pada baris yang sama dan titik koma untuk baris yang terpisah.ContohRumus pertama menunjukkan nilai-nilai yang sesuai dengan nilai-nilai diketahui. Rumus kedua memprediksi nilai bulan berikutnya, jika tren linier terus berlanjut.
1
2
345678910111213
A B C
Month Cost Formula (Corresponding Cost)
1 $133,890 =TREND(B2:B13,A2:A13)
2 $135,000
3 $135,790
4 $137,300
5 $138,130
6 $139,100
7 $139,900
8 $141,120
9 $141,890
10 $143,230
11 $144,000
12 $145,290
Month Formula (Predicted Cost)
13 =TREND(B2:B13,A2:A13,A15:A19)
14
15
16

17
CATATAN Rumus dalam contoh harus dimasukkan sebagai formula array. Setelah menyalin contoh untuk lembar kerja kosong, pilih C2 kisaran: C13 atau B15: B19 dimulai dengan sel formula. Tekan F2, kemudian tekan CTRL + SHIFT + ENTER. Jika formula tidak dimasukkan sebagai formula array, hasil tunggal 133953.3333 dan 146171,5152.
TRIMMEAN fungsi
Pengembalian rata-rata dari interior sebuah kumpulan data. TRIMMEAN menghitung mean diambil oleh tidak termasuk persentase titik data dari ekor atas dan bawah dari kumpulan data. Anda dapat menggunakan fungsi ini ketika Anda ingin mengecualikan data terpencil dari analisis Anda.
SintaksisTRIMMEAN (array, persen)Array adalah array atau rentang nilai untuk memangkas dan rata-rata.Persen adalah jumlah pecahan titik data untuk dikecualikan dari perhitungan. Sebagai contoh, jika = 0,2 persen, 4 poin dipangkas dari data set 20 poin (20 x 0,2): 2 dari atas dan 2 dari bagian bawah dari himpunan.
Keterangan• Jika persen <0 atau persen> 1, TRIMMEAN mengembalikan NUM #! nilai kesalahan.• TRIMMEAN putaran jumlah titik data dikecualikan ke kelipatan terdekat 2. Jika = 0,1 persen, 10 persen dari 30 titik data sama dengan 3 poin. Untuk simetri, TRIMMEAN tidak termasuk nilai tunggal dari atas dan bawah dari kumpulan data.
Contoh
1234567891011
A
Data
4
5
6
7
2
3
4
5
1
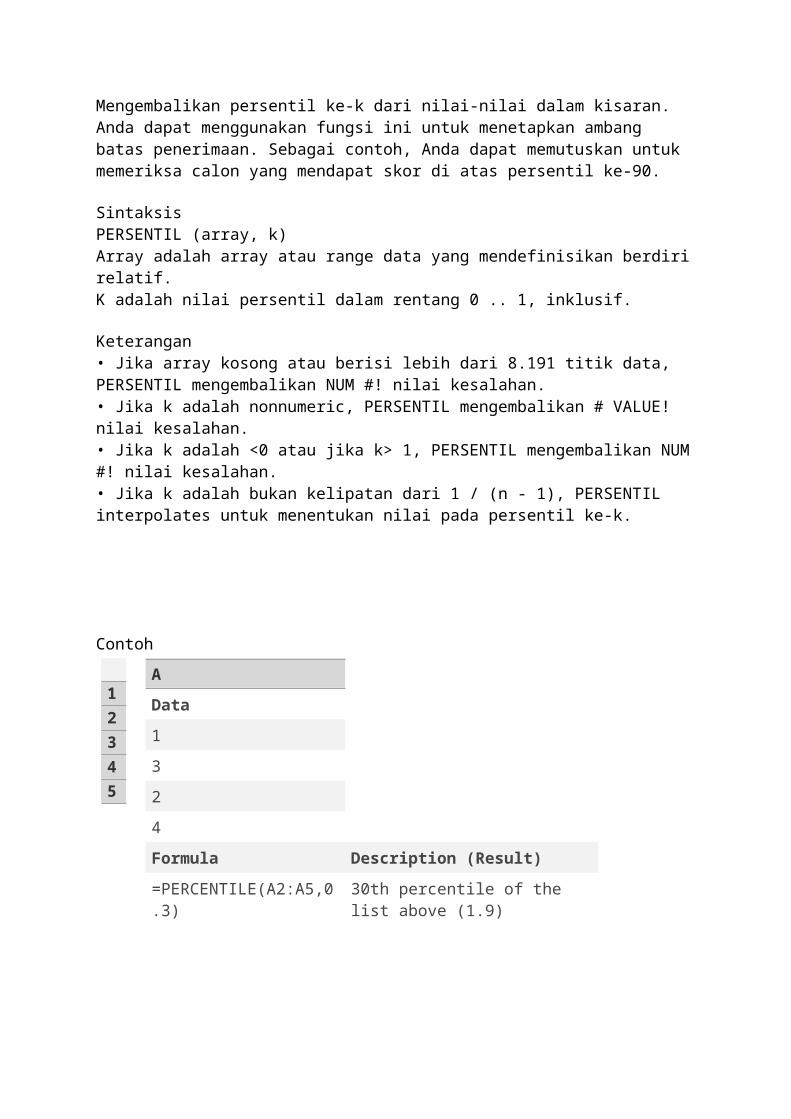
12 2
3
Formula Description (Result)
=TRIMMEAN(A2:A12,0.2) Mean of the interior of a data set above, with 20 percent excluded from calculation (3.777778)
TTEST fungsi
Mengembalikan probabilitas yang terkait dengan t Test-pelajar. Gunakan TTEST untuk menentukan apakah dua sampel yang mungkin berasal dari dua populasi yang sama yang mendasari yang memiliki mean yang sama.
SintaksisTTEST (array1, array2, ekor, jenis)Array1 adalah himpunan data pertama.Array2 adalah set data kedua.Ekor menentukan jumlah ekor distribusi. Jika ekor = 1, TTEST menggunakan distribusi satu-ekor. Jika ekor = 2, TTEST menggunakan distribusi dua-ekor.Jenis adalah jenis t-Test untuk melakukan.
IF TYPE EQUALS THIS TEST IS PERFORMED
1 Paired
2 Two-sample equal variance (homoscedastic)
3 Two-sample unequal variance (heteroscedastic)
Keterangan• Jika array1 dan array2 memiliki nomor yang berbeda dari titik data, dan tipe = 1 (pasangan), TTEST mengembalikan # N / A nilai kesalahan.• Ekor dan jenis argumen yang dipotong ke integer.• Jika ekor atau tipe nonnumeric, TTEST mengembalikan # VALUE! nilai kesalahan.• Jika ekor adalah nilai lain dari 1 atau 2, TTEST mengembalikan NUM #! nilai kesalahan.• TTEST menggunakan data di array1 dan array2 untuk menghitung non-negatif t-statistik. Jika ekor = 1, TTEST mengembalikan probabilitas nilai yang lebih tinggi dari statistik t-dengan asumsi bahwa array1 dan array2 adalah sampel dari populasi dengan mean yang sama. Nilai dikembalikan oleh TTEST ketika ekor = 2 adalah dua kali lipat kembali ketika ekor = 1 dan sesuai dengan probabilitas nilai absolut lebih tinggi dari statistik t-bawah "populasi yang sama berarti" asumsi.

Contoh
12345678910
A B
Data 1 Data 2
3 6
4 19
5 3
8 2
9 14
1 4
2 5
4 17
5 1
Formula Description (Result)
=TTEST(A2:A10,B2:B10,2,1)
Probability associated with a Student's paired t-Test, with a two-tailed distribution (0.196016)
VAR fungsi
Estimasi varians berdasarkan sampel.
SintaksisVAR (number1, number2, ...)Number1, number2, ... adalah 1-255 argumen angka yang sesuai dengan sampel dari populasi.
Keterangan• VAR mengasumsikan bahwa argumen adalah contoh dari populasi. Jika data Anda mewakili seluruh populasi, kemudian menghitung varians dengan menggunakan VARP.• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis, dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika argumen adalah array atau referensi, angka saja dalam array atau referensi dihitung. Sel

kosong, nilai-nilai logis, teks, atau nilai-nilai kesalahan dalam array atau referensi akan diabaikan.
• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.
• Jika Anda ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, gunakan fungsi Vara.• VAR menggunakan rumus berikut:
di mana x adalah rata-rata sampel AVERAGE (number1, number2, ...) dan n adalah ukuran sampel.
Contoh
1234567891011
A
Strength
1345
1301
1368
1322
1310
1370
1318
1350
1303
1299
Formula Description (Result)
=VAR(A2:A11) Variance for the breaking strength of the tools (754.2666667)
VARA fungsi

Estimasi varians berdasarkan sampel.
SintaksisVARA (value1, value2, ...)Value1, value2, ... adalah 1-255 argumen nilai yang sesuai dengan sampel dari populasi.
Keterangan• VARA mengasumsikan bahwa argumen adalah contoh dari populasi. Jika data Anda mewakili seluruh populasi, Anda harus menghitung varians dengan menggunakan VARPA.• Argumen bisa menjadi berikut: Nomor; nama, array, atau referensi yang mengandung angka; representasi teks angka, atau nilai-nilai logis, seperti TRUE dan FALSE, dalam referensi.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Argumen yang mengandung BENAR mengevaluasi sebagai 1; argumen yang berisi teks mengevaluasi atau FALSE sebagai 0 (nol).• Jika argumen adalah array atau referensi, hanya nilai dalam array atau referensi yang digunakan. Sel kosong dan nilai-nilai teks dalam array atau referensi akan diabaikan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika Anda tidak ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, gunakan fungsi VAR.• VARA menggunakan rumus berikut:
di mana x adalah rata-rata sampel RATA-RATA (value1, value2, ...) dan n adalah ukuran sampel.
Contoh
12
A
Strength

34567891011
1345
1301
1368
1322
1310
1370
1318
1350
1303
1299
Formula Description (Result)
=VARA(A2:A11)
Estimates the variance for the breaking strength (754.2666667)
VARP fungsi
Menghitung varians berdasarkan seluruh penduduk.
SintaksisVARP (number1, number2, ...)Number1, number2, ... adalah 1-255 argumen angka yang sesuai untuk populasi.
Keterangan• VARP mengasumsikan bahwa argumen adalah seluruh penduduk. Jika data Anda merupakan sampel dari populasi, kemudian menghitung varians dengan menggunakan VAR.• Argumen dapat berupa nomor atau nama, array, atau referensi yang mengandung angka.• nilai-nilai logis, dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Jika argumen adalah array atau referensi, angka saja dalam array atau referensi dihitung. Sel kosong, nilai-nilai logis, teks, atau nilai-nilai kesalahan dalam array atau referensi akan diabaikan.• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika Anda ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, gunakan fungsi VARPA.
• Persamaan untuk VARP adalah:

di mana x adalah rata-rata sampel AVERAGE (number1, number2, ...) dan n adalah ukuran sampel.
Contoh
1234567891011
A
Strength
1345
1301
1368
1322
1310
1370
1318
1350
1303
1299
Formula Description (Result)
=VARP(A2:A11)
Variance of breaking strengths for all the tools, assuming that only 10 tools are produced (678.84)
VARPA fungsi
Menghitung varians berdasarkan seluruh penduduk.
SintaksisVARPA (value1, value2, ...)Value1, value2, ... adalah 1-255 argumen nilai yang sesuai untuk populasi.
Keterangan• VARPA mengasumsikan bahwa argumen adalah seluruh penduduk. Jika data Anda merupakan sampel dari populasi, Anda harus menghitung varians dengan menggunakan VARA.• Argumen bisa menjadi berikut: Nomor; nama, array, atau referensi yang mengandung angka; representasi teks angka, atau nilai-nilai logis, seperti TRUE dan FALSE, dalam referensi.• nilai-nilai logis dan representasi teks angka yang Anda ketik langsung ke dalam daftar argumen dihitung.• Argumen yang mengandung BENAR mengevaluasi sebagai 1; argumen yang berisi teks mengevaluasi atau FALSE sebagai 0 (nol).• Jika argumen adalah array atau referensi, hanya nilai dalam array atau referensi yang

digunakan. Sel kosong dan nilai-nilai teks dalam array atau referensi akan diabaikan.
• Argumen yang kesalahan nilai atau teks yang tidak dapat diterjemahkan ke dalam nomor menyebabkan kesalahan.• Jika Anda tidak ingin memasukkan nilai-nilai logis dan representasi teks angka dalam referensi sebagai bagian dari perhitungan, gunakan fungsi VARP.• Persamaan untuk VARPA adalah:
di mana x adalah rata-rata sampel RATA-RATA (value1, value2, ...) dan n adalah ukuran sampel.Contoh
1234567891011
A
Strength
1345
1301
1368
1322
1310
1370
1318
1350
1303
1299
Formula Description (Result)
=VARPA(A2:A11)
Variance of breaking strengths for all the tools, assuming that only 10 tools are produced (678.84)
WEIBULL fungsi
Mengembalikan distribusi Weibull. Gunakan distribusi ini dalam analisis reliabilitas, seperti menghitung waktu yang berarti perangkat untuk kegagalan.
SintaksisWEIBULL (x, alfa, beta, kumulatif)X adalah nilai di mana untuk mengevaluasi fungsi.Alpha adalah suatu parameter untuk distribusi.Beta adalah suatu parameter untuk distribusi.

Kumulatif menentukan bentuk fungsi.
Keterangan• Jika x, alfa, beta atau nonnumeric, WEIBULL mengembalikan # VALUE! nilai kesalahan.• Jika x <0, WEIBULL mengembalikan NUM #! nilai kesalahan.• Jika alpha ≤ 0 atau jika beta ≤ 0, WEIBULL mengembalikan NUM #! nilai kesalahan.• Persamaan untuk fungsi distribusi kumulatif adalah:
• Persamaan untuk fungsi kepadatan probabilitas Weibull adalah:
• Ketika alpha = 1, WEIBULL mengembalikan distribusi eksponensial dengan:
Contoh
12
3
4
A B
Data Description
105 Value at which to evaluate the function
20 Alpha parameter to the distribution
100 Beta parameter to the distribution
Formula Description (Result)
=WEIBULL(A2,A3,A4,TRUE) Weibull cumulative distribution function for the terms above (0.929581)
=WEIBULL(A2,A3,A4,FALSE)
Weibull probability density function for the terms above (0.035589)
ZTEST fungsi
Mengembalikan satu sisi probabilitas-nilai tes z-. Selama rata-rata populasi tertentu dihipotesiskan, μ0, ZTEST mengembalikan probabilitas bahwa mean sampel akan lebih besar daripada rata-rata pengamatan pada set data (array) - yaitu, sampel yang diamati berarti.Untuk melihat bagaimana ZTEST dapat digunakan dalam rumus untuk menghitung nilai probabilitas dua sisi, lihat "Keterangan" di bawah.
SintaksisZTEST (array, μ0, sigma)Array adalah array atau range data terhadap yang untuk menguji μ0

μ0 adalah nilai untuk menguji.Sigma adalah populasi (dikenal) deviasi standar. Jika diabaikan, deviasi standar sampel yang digunakan.
Keterangan• Jika array kosong, ZTEST mengembalikan # N / A nilai kesalahan.• ZTEST dihitung sebagai berikut ketika sigma tidak dihilangkan:
atau ketika sigma dihilangkan:
di mana x adalah rata-rata sampel RATA-RATA (array); s adalah deviasi standar sampel STDEV (array), dan n adalah jumlah pengamatan dalam sampel COUNT (array).• ZTEST mewakili probabilitas bahwa mean sampel akan lebih besar daripada nilai yang diamati RATA-RATA (array), ketika rata-rata populasi yang mendasarinya adalah μ0. Dari simetri dari distribusi Normal, jika RATA-RATA (array) <μ0, ZTEST akan mengembalikan nilai lebih besar dari 0,5.• Rumus Excel berikut dapat digunakan untuk menghitung probabilitas dua ekor bahwa mean sampel akan lebih jauh dari μ0 (ke arah baik) daripada RATA-RATA (array), ketika rata-rata populasi yang mendasarinya adalah μ0:= 2 * MIN (ZTEST (array, μ0, sigma), 1 - ZTEST (array, μ0, sigma)).
Contoh
1
2
3
4
5
6
A
Data
3
6
7
8
6
5

7
8
9
10
11
4
2
1
9
Formula Description (Result)
=ZTEST(A2:A11,4) One-tailed probability-value of a z-test for the data set above, at the hypothesized population mean of 4 (0.090574)
=2 * MIN(ZTEST(A2:A11,4), 1 - ZTEST(A2:A11,4))
Two-tailed probability-value of a z-test for the data set above, at the hypothesized population mean of 4 (0.181148)
=ZTEST(A2:A11,6) One-tailed probability-value of a z-test for the data set above, at the hypothesized population mean of 6 (0.863043)
=2 * MIN(ZTEST(A2:A11,6), 1 - ZTEST(A2:A11,6))
Two-tailed probability-value of a z-test for the data set above, at the hypothesized population mean of 6 (0.273913)