
1
PEMODELAN DENGAN
EKONOMETRIKA
Oleh: Uka Wikarya

PENDAHULUAN
2

OutlineMateri
� Pengertian
� Model Ekonomi
� Model Matematika
� Ekonometrika
� Tahapan Metode Ekonometrika
1. Pernyataan Teori atau hipotesis (dugaan)
2. Spesifikasi model matematika
3. Spesifikasi model ekometrika
4. Pengumpulan data
5. Estimasi parameter
6. Pengujian Hipotesis
7. Peramalan atau prediksi
8. Mengunakan model
3

Pengertian Model Ekonomi
� Model ekonomi adalah bangunan logika yang
berusaha menyederhanakan hubungan sebab-
akibat yg rumit dan pengaruh diantara elemen-
elemen yg saling berinteraksi dalam
perekonomian.
� Dengan model ekonomi para ekonom dapat
melakukan percobaan atau simulasi dengan
skenario yg berbeda, untuk mengevaluasi
pengaruh dari suatu pilihan kebijakan.
Ekonometrika Terapan 1,
MPKP - FEUI 4

Pengertian Model Matematika
� Pemodelan matematika adalah memodelkan
hubungan fungsional dalam dunia nyata
dengan menggunakan bahasa matematika.
� Pemodelan matematika digunakan untuk
� Mendeskripsikan (describe) fenomena dunia nyata
� Menyelidiki pertanyaan penting berkenaan dengan dunia yang teramati
� Menjelaskan (explain) fenomena dunia-nyata
� Menguji gagasan atau ide-ide
� Membuat prediksi
5

Pengertian Ekonometrika
� Arti bahasa � econometrics : ‘pengukuran keekonomian’, ttp cakupannya jauh lebih luas
� Pengertian konsep: � Econometrics: the result of certain outlook on the rule of economics, consist of the
application ot mathematical statistics to economic data to lend empirical support to
the models constructed by mathematical economics and to obtaoin numerical results
(Gerhard Tinthner, 1968)
� …. Econometrics my be defined as the quantitative analysis of actual economic
phenomena based on the concurrent development of theory and observation, related
by appropriate methods of inference (Samulelson, 1954).
� Econometrics my be defined as sosial sciences in which the tools of econometric
theory, mathematics, and statistical inference are applied to the analysis of economic
phenomena (Goldberger. 1964).
� Masih banyak definisi-definisi lainnya.
� Umumnya para modeler ekonometrika lebih sering menggunakan data “obervasional” ketimbang “eksperimental”.
6

What are the goals of Econometrics?
1. Knowledge of the real economy
Econometric methods allow us to estimate economic magnitudes such as the marginal propensity to consume (MPC) or the elasticity of labor with respect to output. Econometric methods allow us to perform tests of hypothesis.
2. Economic simulation policy Econometrics methods can be used to simulate the effects of alternative policies.
3. Prediction or forecasting Very often econometric met hods are used to predict values of economic variables in the future, trying to reduce our uncertainty in the future of the economy.
7

Metodologi Ekonometrika
Langkap-2 metodologi ekonometrika:
1. Pernyataan Teori atau hipotesis (dugaan)
2. Spesifikasi model matematika dari teori atau hipotesis
3. Spesifikasi model statistika atau ekometrika
4. Pengumpulan data
5. Estimasi parameter dalam model ekonometrika
6. Pengujian Hipotesis
7. Peramalan atau prediksi
8. Menggunakan model untuk pengendalian atau tujuan
kebijakan
8

Ilustrasi tahapan metode
1. Pernyataan atau hipotesis
Teori Marginal Propensity to Consume (MPC), y.i. laju perubahan konsumsi
untuk setiap penambahan 1 unit (rupiah) pendapatan, MPC berada antara 0
dan 1
2. Spesifikasi Model matematika konsumsi
Y = β1 + β2X, 0< β2< 1
dimana
Y = pengeluaran Konsumsi
X = pendapatan
β1, β2 = parameter persamaan (model)
β1= intersep
β2 = slope , dalam hal ini sbg MPC
9
X
Y
β1
1
β2 =MPC
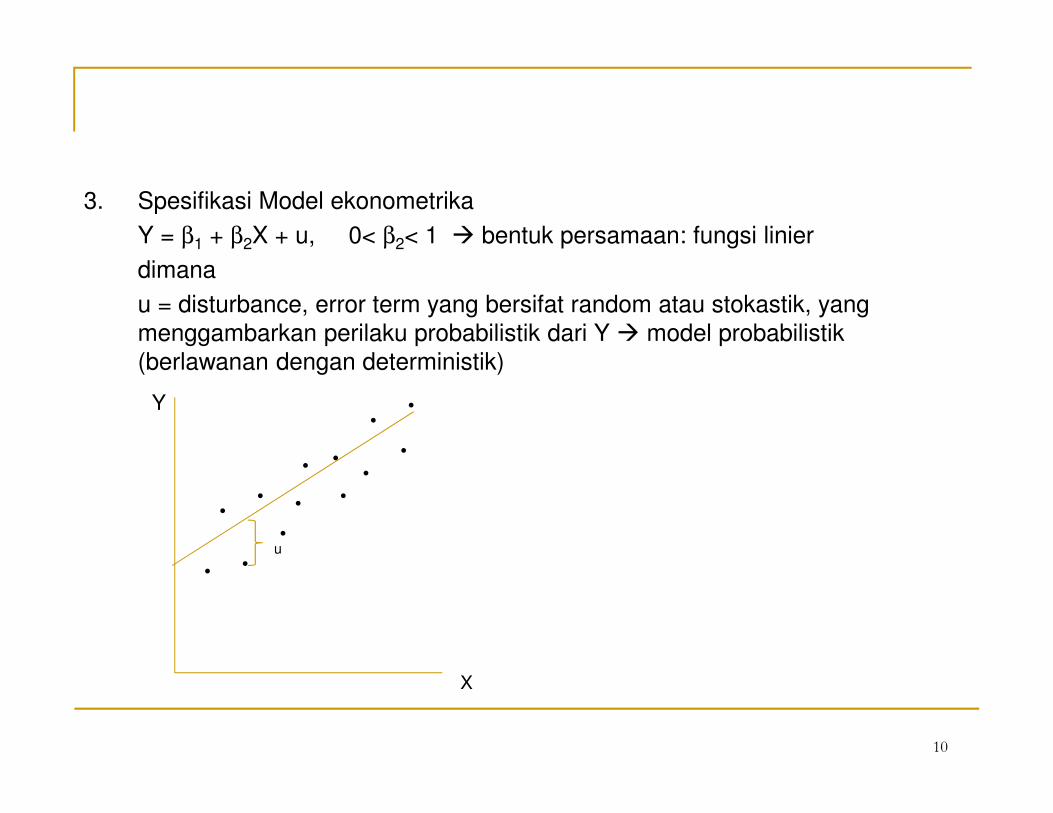
3. Spesifikasi Model ekonometrika
Y = β1 + β2X + u, 0< β2< 1 � bentuk persamaan: fungsi linier
dimana
u = disturbance, error term yang bersifat random atau stokastik, yang
menggambarkan perilaku probabilistik dari Y � model probabilistik
(berlawanan dengan deterministik)
10
X
Y
•
•
•
•
•
•
•
•
•
•
•
•
•
u
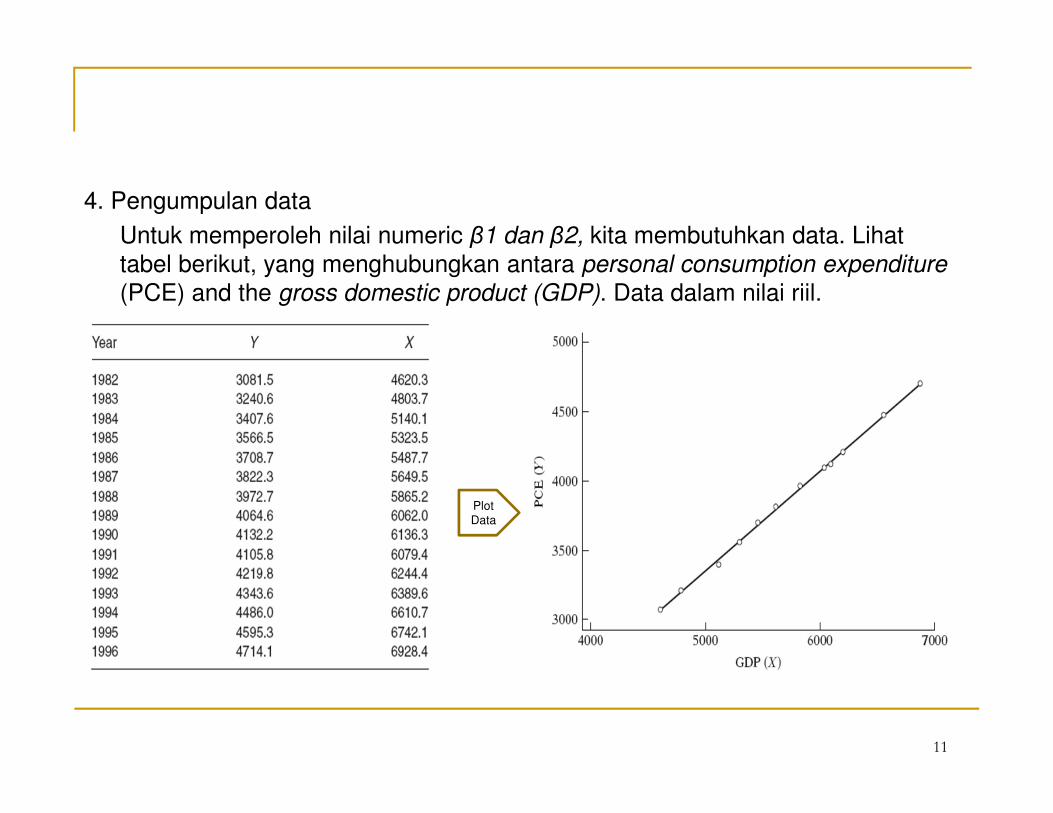
4. Pengumpulan data
Untuk memperoleh nilai numeric β1 dan β2, kita membutuhkan data. Lihat
tabel berikut, yang menghubungkan antara personal consumption expenditure
(PCE) and the gross domestic product (GDP). Data dalam nilai riil.
11
Plot
Data

5. Estimasi dalam Model ekonometrika
� Analisis regresi adalah alat utama yang digunkaan untuk memperoleh dugaan
koefisien-koefisien. Dengan metode regresi dan data pada tabel di atas diperoleh
dugaan β1 and β2, yaitu, −184.08 dan 0.7064. dengan demikian fungsi konsumsi
dugaan:
� = −184.08 + 0.7064Xi
� Garis regresi lumayan bagus dengan slope coefficient (i.e., MPC) = 0.70, setiap
peningkatan pendapatan riil 1 dollar akan meningkatkan sekitar 70 sen (secara rata-
rata) dalam konsumsi riil.
12
Y

6. Pengujian Hipotesis
Untuk mengetahui apakah koefisien dugaan yang diperoleh di atas sejalan dengan harapan teori maka perlu diuji. Keynes mengharapkan MPC bernilai positif tetapi kurang dari satu
(β2≤1). Dalam kasus ini kita mendapati MPC = 0.70. Sebelum mengkonfirmasi teory konsumsi Keynes, kita harus meneliti apakah angka dugaan berada dibawah satu. Dengan kata lain secara statistika 0,70 kurang dari satu. Jika benar maka temuan ini mendukung Teori Keynes.
� Konfirmasi dengan cara seperti itu atau sanggahan terhadap teori ekonomi berbasis bukti sampel adalah dasar dari teori statistika yang dikenal dengan statistical inference (hypothesis testing).
13

7. Peramalan dan Prediksi
� Misalkan kita bermaksud meprediksi rata-rata belanja konsumsi untuk tahun
1997. GPD 1997 adalah $7269.8 milyar:
Yˆ1997 = −184.0779 + 0.7064 (7269.8) = 4951.3 (I.3.4)
� Angka actual dari belanja konsumsi yang dilaorkan pada tahun 1997 adalah
$4913.5 milyar, sementara prediksi model adalah $4951.3 milyar. Jadi
kelebihan $37.82 milyar, atau kesalahan prediksi adalah $37.82 milyar atau
sekitar 0.76% dari nilai actual GDP 1997
14

8. Menggunakan model untuk Pengendalian atau Penyusunan Kebijakan
� Dengan persamaaan terestimasi di atas, pemerintah percaya bahwa belanja konsumen sekitar $4900 milyar akan menahan laju pengangguran pada level 4.2%. Berapa level pendapatan yang akan menjamin tercapaiknya target belanja konsumsi tsb?
� Jika hasil regresi di atas dianggap benar, aritmatika sederhana akan menunjukkan :
� 4900 = −184.0779 + 0.7064X
� Dengan menyelesaikan persamaan diperoleh X = 7197 (kira-kira), Jadi dengan level pendapatan $7197 milyar, dan MPC =0,70, akan melahirkan belanja konsumen sekitar $4900 milyar.
15
16
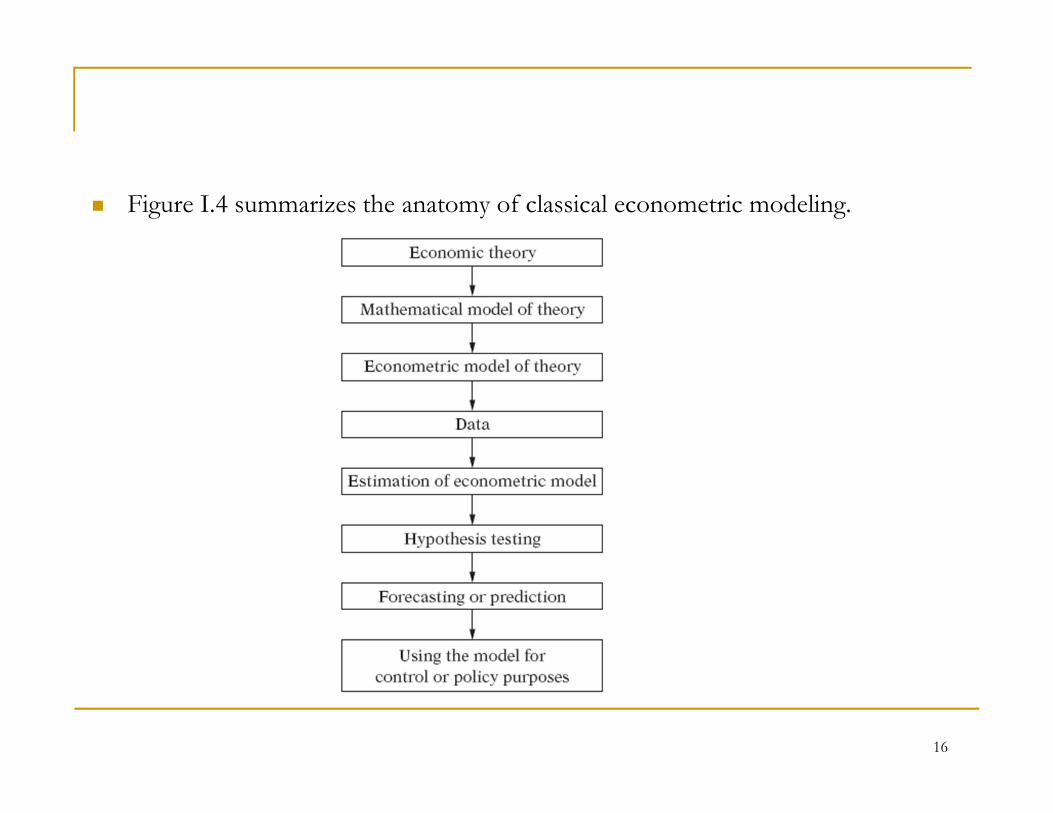
� Figure I.4 summarizes the anatomy of classical econometric modeling.

17
MULTIPLE REGRESSION ANALYSIS

Bentuk Umum Model
18
uiXXXY kikiii +++++= ββββ .....22110
Bentuk model populasi:
dimana
Yi = nilai dependen variabel pada obeservasi ke-i
X1, X2, ..., Xk = variabel independen X1, X2,...., Xk
k = banyaknya variabel independent
β0, β1, β2,...., βk, = koefisien persamaan (sebagai parameter)
ui = gangguan acak atas nilai observasi di pengamatan ke-i.
β0 = intersep, pengaruh rata-rata untuk Y dari semua variabel yang tidak
dimasukkan ke dalam model
β1, β2,...., βk = partial regression coefficient

Asumsi Classical Linear Regression Model (CLRM)
� Zero mean of ui, atau
� E(ui|X1i, X2i, ...Xki) = 0 untuk setiap i
� No serial autocorrelation atau
� Cov(ui, uj)= 0
� Homoscedasticity. Atau
� Var(ui) = σ2 , untuk semua i
� Zero covariance antara ui dan setiap variabel X, atau
� Cov(ui., X1i) = cov(ui, X2i) = ....=cov(ui, Xki) = 0
� No spesification bias, atau
� The model correctly specified
� No exact collinearity relationship between the X’s variables (Explain!) atau
� Additional assumption: � Model is Linear in paramaters
� Value of regressor are fixed (non stochastic)
� There is sufficient variability in the values of regressor variables
19

Interpretation of Multiple Regression Equation
Given the assumption of CLRM, the expectation of the equation:
20
kikiikiiii XXXXXXYE ββββ ++++= ....),...,,|( 2211021
That is the conditional mean or expected value of Y conditional upon the given or fixed value of X1, X2, ..., Xk

The meaning of Partial Regression Coefficient
Perhatikan kembali persamaan berikut:
21
kikiikiiii XXXXXXYE ββββ ++++= ....),...,,|( 2211021
β1, β2, ...., βk = partial slope coefficient atau partial regression coefficient
Makna koefisien:
β1 = besarnya perubahan pada rata-rata Y atau E(Y) jika X1 berubah satu unit, dengan menjaga variabel-variabel lain tidak berubah (ceteris paribus). Atau effek langsung atau effect bersih dari perubahan satu unit pada X1 terhadap Y.
Demikian juga untuk koefisien yang lainnya.
Explain hubungan sederhana antara Y , X1 dan X2

Metode Estimasi OLS
Model regresi sampel
22
2)ˆ....ˆˆˆ(min 22110
2
kikiii XXXYiu ββββ ++++−=∑∑
dimana
kβββ ˆ,....,ˆ,ˆ
21= estimator atau penduga bagi paramater populasi
Jika punya data sampel maka OLS kita dapat memperoleh satu set angka dugaan (estimate) bagi parameter-2 tersebut.
Bagaimana prinsip dasar metode OLS? Minimumkan SSE (atau RSS dalam Gujarati)
iuXXXY kikiiiˆˆ....ˆˆˆ
22110 +++++= ββββ

Rumus penduga OLS dengan matriks
Rumus pendugaan parameter dengan solusi sistem persamaan sangat rumit. Rumus dengan pendekatan matriks:
23
( ) ( )YX'XX'β1ˆ −
=
=
kβ
β
β
ˆ
...
ˆ
ˆ
ˆ 1
0
β
=
knnn
k
k
xxx
xxx
xxx
...1
..............
..............
...1
...1
21
22212
12111
X
=
ny
y
y
...
...
2
1
Y
Kita tidak akan memperdalam proses pendugaan secara teknis. Sudah banyak
software ekonometrika yang dapat mengerjakan tugas ini.

Standar Error Penduga Koefisien?
24
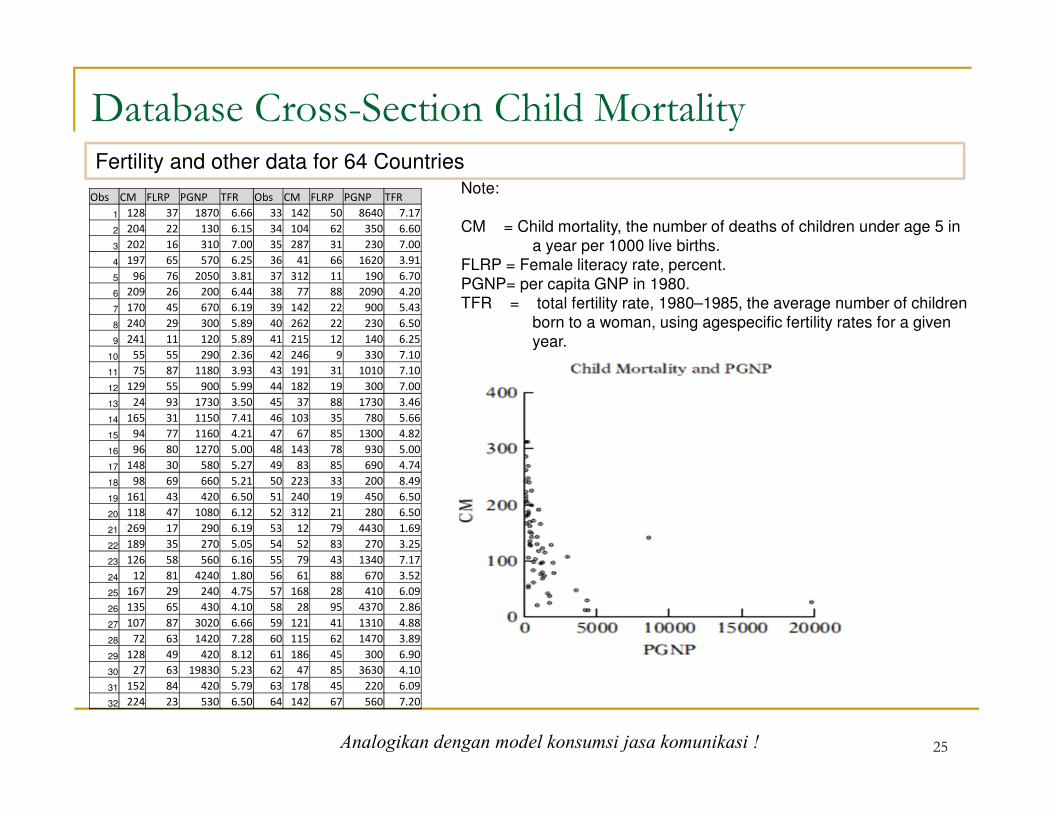
Database Cross-Section Child Mortality
Obs CM FLRP PGNP TFR Obs CM FLRP PGNP TFR
1 128 37 1870 6.66 33 142 50 8640 7.17
2 204 22 130 6.15 34 104 62 350 6.60
3 202 16 310 7.00 35 287 31 230 7.00
4 197 65 570 6.25 36 41 66 1620 3.91
5 96 76 2050 3.81 37 312 11 190 6.70
6 209 26 200 6.44 38 77 88 2090 4.20
7 170 45 670 6.19 39 142 22 900 5.43
8 240 29 300 5.89 40 262 22 230 6.50
9 241 11 120 5.89 41 215 12 140 6.25
10 55 55 290 2.36 42 246 9 330 7.10
11 75 87 1180 3.93 43 191 31 1010 7.10
12 129 55 900 5.99 44 182 19 300 7.00
13 24 93 1730 3.50 45 37 88 1730 3.46
14 165 31 1150 7.41 46 103 35 780 5.66
15 94 77 1160 4.21 47 67 85 1300 4.82
16 96 80 1270 5.00 48 143 78 930 5.00
17 148 30 580 5.27 49 83 85 690 4.74
18 98 69 660 5.21 50 223 33 200 8.49
19 161 43 420 6.50 51 240 19 450 6.50
20 118 47 1080 6.12 52 312 21 280 6.50
21 269 17 290 6.19 53 12 79 4430 1.69
22 189 35 270 5.05 54 52 83 270 3.25
23 126 58 560 6.16 55 79 43 1340 7.17
24 12 81 4240 1.80 56 61 88 670 3.52
25 167 29 240 4.75 57 168 28 410 6.09
26 135 65 430 4.10 58 28 95 4370 2.86
27 107 87 3020 6.66 59 121 41 1310 4.88
28 72 63 1420 7.28 60 115 62 1470 3.89
29 128 49 420 8.12 61 186 45 300 6.90
30 27 63 19830 5.23 62 47 85 3630 4.10
31 152 84 420 5.79 63 178 45 220 6.09
32 224 23 530 6.50 64 142 67 560 7.20
25
Note:
CM = Child mortality, the number of deaths of children under age 5 in
a year per 1000 live births.
FLRP = Female literacy rate, percent.
PGNP= per capita GNP in 1980.
TFR = total fertility rate, 1980–1985, the average number of children
born to a woman, using agespecific fertility rates for a given
year.
Fertility and other data for 64 Countries
Analogikan dengan model konsumsi jasa komunikasi !

Partial Regression Coefficient
26
Dependent Variable: CM
Method: Least Squares
Sample(adjusted): 1 64
Included observations: 64 after adjusting endpoints
Variable Coefficient Std. Error t-Statistic Prob.
C 168.3067 32.89165 5.117003 0.0000
PGNP -0.005511 0.001878 -2.934275 0.0047
FLR -1.768029 0.248017 -7.128663 0.0000
TFR 12.86864 4.190533 3.070883 0.0032
R-squared 0.747372 Mean dependent var 141.5000
Adjusted R-squared 0.734740 S.D. dependent var 75.97807
S.E. of regression 39.13127 Akaike info criterion 10.23218
Persamaaan regresi dugaan:
CMi = 168.307 -0.0055PGNP -1.768FLR+12.869TFR+ui
Interpretasikan setiap koefisien!
Bagaimana menghitung Standar Error Penduga Koefisien?

Regresi dengan data distandardisasika ke variabel normal
baku
Dimana:
27
FLRi
CM i
mean(FLR)/-[FLR *FLR
mean(CM)]/-[CM *CM
σ
σ
=
=
Persamaan tersebut tidak mengandung intersep krn rata-rata CM* dan FLR* adalah nol.
Makna koefisien:
� Jk PGNP naik sebesar satu standar deviasinya, maka CM akan berkurang sebesar -
0.2026 std deviasinya dengan asumsi variabel FLR tidak berubah.
� Jika FLR naik 1 std deviasinya, maka CM berkurang sebesar 0.7639 std deviasinya
dengan asumsi PGNP tidak berusah
� Variabel FLR memberikan pengaruh lebih kuat terhadap CM dibandingkan PGNP

Goodness of Fit (Koefisien determinasi) Dalam kasus regresi linier sederhana, r2, atau koefisien determinasi mengukur proporsi
variasi dalam variabel Y yang dapat dijelaskan oleh variasi dalam variabel X sendiri.
Dalam model regresi berganda atau multiple regression, r2, memiliki makna proporsi variasi
dalam variabel Y yang dapat dijelaskan secara simultan oleh variasi semua variabel X atau
variabel penjelas; dan diberi simbol R2.
Sifat R2:
a. Meningkat dengan bertambahnya variabel penjelas
b. Menurun dengan bertambahnya observasi
Untuk mengatasi sifat-sifat tersebut agar tidak keliru dalam menafsirkan maka diperkenalkan
R2 adjusted dengan rumus:
Perbandingan: R2adj < R2
R2adj diigunakan untuk membandingkan kecocokan-suai atau kesesuaian suatu model
peresamaan dengan model-2 lainnya.
28
)1/(
)1/(12
−
−−−=
nSST
knSSERadj
k= banyak var bebas dalam model
n = banyak observasi

� Apakah kita dapat membandingkan R2 antara dua
model berikut?
� Jawaban tidak bisa. Kenapa?
� Dua angka R2 bisa dibandingan jika
� Jumlah Observasi sama
� Banyak variabel sama
� Bentuk fungsional persamaan sama
29
ii
ii
uXXY
uXXY
+++=
+++=
33221
33221ln
ααα
βββ

Contoh Model Multiple Regression: Polynomial
Regression Model
Kasus Hubungan Output dan Biaya atau Fungsi Biaya, dengan bentuk fungsi third-degree polynomial, atau qubic function.
30
Bentuk Second-degree polynomial atau quadratic function
Bentuk kth-degree polynomial:

Hipotesis dari model, dengan mempertimbangkan
scatter diagram:
1. β0, β1, β3 >0
2. β2 < 0
3. β2 2 < 3 β1 β3
31
Hasil empiris:
(estimated standard errors)

Pengujian (hipotesis) Model
� Distribusi sampling parameter dugaan.
Asumsi kenormalan dalam u:
We assumed that the ui follow the normal distribution with zero mean and constant variance σ2.
We continue to make the same assumption for multiple regression models. With the normality
assumption we find that the OLS estimators of the partial regression coefficients, which are
Identical with the maximum likelihood (ML) estimators, are best linear unbiased estimators
(BLUE). the estimators β2, β3, and β1 are normally distributed with means equal to true β2, β3,
and β1 and varians σ2 (X’X)-1. Oleh karena varians estimator diganti oleh penduga varians
sampel maka estimators β2, β3, and β1 mengikuti distribusi t-students dengan formula sebagai
berikut:
32
Dengan derajat bebas: n – 3
Atau secara umum dengan derajat bebas:
df=n – k – 1; dimana n=banyak observasi; dan
k=banyak variabel penjelas.

Output Komputer: Contoh kasus Child Mortality
33
Dependent Variable: CM
Method: Least Squares
Date: 10/04/12 Time: 15:49
Sample(adjusted): 1 64
Included observations: 64 after adjusting endpoints
Variable Coefficient Std. Error t-Statistic Prob.
C 263.6416 11.59318 22.74109 0.0000
PGNP -0.005647 0.002003 -2.818703 0.0065
FLR -2.231586 0.209947 -10.62927 0.0000
R-squared 0.707665 Mean dependent var 141.5000
Adjusted R-squared 0.698081 S.D. dependent var 75.97807
S.E. of regression 41.74780 Akaike info criterion 10.34691
Sum squared resid 106315.6 Schwarz criterion 10.44811
Log likelihood -328.1012 F-statistic 73.83254
Durbin-Watson stat 2.186159 Prob(F-statistic) 0.000000
Persamaan regresi dugaan:
CM = 263.6416 -0.00565 PGNP -2.231 FLR + u
P-value dari two-
tails
� Berlaku untuk uji dua
arah
� Jk ujinya satu arah
maka P-Valu harus
dibagi dua

Pengujian Koefisien regresi individu
� Disain Hipotesis:
� PGNP tidak berpengaruh secara linier terhadap CM, menggunakan level
of significance atau taraf nyata 5% atau , α = 0.05
H0: β2 = 0 vs H1: β2 ≠ 0
Tolak Ho jk tstat > 2.000 atau tstat < -2.000, atau jika p-value < α
t-stast dari penduga β2 (khusus untuk uji 2 arah) :
Keputusan : totak Ho, karena tstat < -2.000,
Kesimpulan: koefisien β2 yang sebenarnya berbeda dari nol , sehingga PGNP memiliki pengaruh linier signifikan terhadap CM.
34
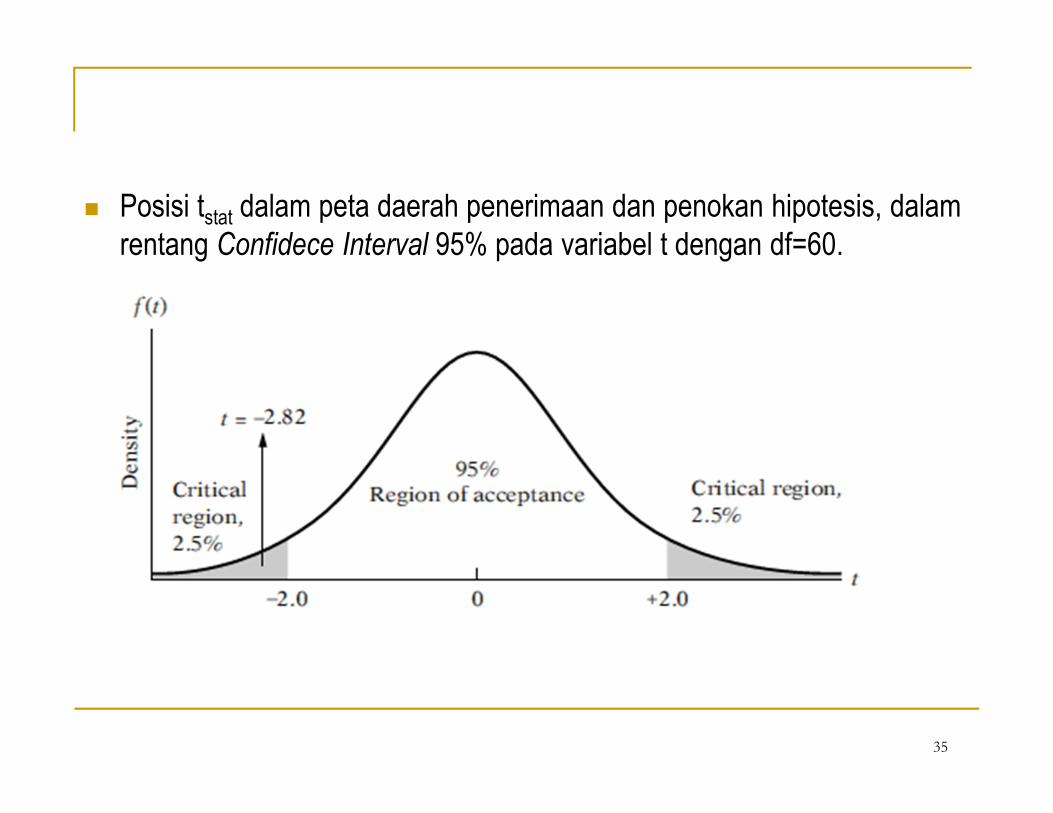
� Posisi tstat dalam peta daerah penerimaan dan penokan hipotesis, dalam
rentang Confidece Interval 95% pada variabel t dengan df=60.
35

36
� Disain Hipotesis:
� PGNP berpengaruh negatif secara linier terhadap CM, menggunakan level of
significance atau taraf nyata 5% atau , α = 0.05
H0: β2 >= 0 vs H1: β2 < 0
Tolak Ho jk tstat < -1.671 atau p-value < 2α (khusus untuk uji 1 arah).
t-stast dari penduga β2:
Keputusan : totak Ho, karena tstat < -1.671,
Kesimpulan: koefisien β2 yang sebenarnya negatif, sehingga PGNP memiliki
pengaruh negatif signifikasi terhadap CM.
� Lakukan Pengujian Hipotesis untuk Paramater lainnya!

Pengujian Hipotesis untuk Signifikansi semua
Paramater Slope
� Disebut juga uji global
37
Statisk uji:
1)-k-SSE/(n
SSR/k Fstat =
Tolak Ho jk Fstat > Fα (k, n-k-1). Fα (k, n-k-1) adalah nilai kritis F pada level of
significance α dan derajat bebas pembilang k, dan derajat bebas
penyebut n-k-1. Uji Alternatif : tolak Ho jk p-value < α.

Hubungan antara F dan R2
38
)1/()1(
)/(2
2
−−−=
knR
kRF
Secara umum, pada kasus k-variable (termasuk intersep) jika kita mengasumsikan
bahwa suku residual (error) berdistribusi normal dan hipotesis nol adalah sebagai
berikut:
H0: ß2=ß3= ··· =ßk=0
Kemudian berlaku rumus:
Mengikuti distribusi F dengan derajat bebas k
dan n-k-1 (catatan: total variable dalam model
adalah k)
Semakin besar R2 semakin besar F. Ketika R2=1, pada limit atasnya, maka F tidak
terhingga (infinite). Dengan dmikian, uji F, yang mengukur signifikansi keseluruhan dari
koefisien regresi testimasi, juga adalah uji terhadap R2. Dengan kata lain menguji hipotesis
nol seperti tertulis di atas adalah equivalen dengan menguji hipotesis nol bahwa (secara
populasi) R2 adalah nol.

Asumsi-asumsi OLS
Asumsi-asumi yg mendasari berlakunya metode estimasi OLS atau disebut juga
asumsi-asumsi model regresi linier klasik atau asumsi Gaussian, atau Asumsi
Standar; ada 10 items:
Asumsi 1. Model Regresi Linier
Model persamaan regresi adalah linier dalam parameter
Yi = β1 + β2 Xi + ui
Asumsi 2: Nilai X bersifat tetap dalam repeated sampling.
Nilai-nilai yang dipilih untuk variabel X bersifat tetap dalam repeated sampling.
Atau X diasumsikan bersifata non-stochastic.
Ekonometrika Terapan 1,
MPKP - FEUI 39

Obs X Y obs X Y obs X Y obs X Y
1 20 35.92 11 30 43.15 21 40 49.09 31 50 59.05
2 20 35.08 12 30 43.39 22 40 50.47 32 50 57.64
3 20 35.48 13 30 40.70 23 40 49.57 33 50 57.15
4 20 35.47 14 30 43.82 24 40 50.01 34 50 57.69
5 20 36.29 15 30 42.97 25 40 50.24 35 50 57.53
6 20 34.82 16 30 43.53 26 40 51.00 36 50 58.31
7 20 36.61 17 30 43.14 27 40 49.50 37 50 58.05
8 20 36.81 18 30 41.92 28 40 50.35 38 50 56.20
9 20 35.53 19 30 43.32 29 40 50.29 39 50 56.51
10 20 34.36 20 30 42.85 30 40 48.99 40 50 57.88
Mean 35.637 42.879 49.951 57.601
Stdev 0.782 0.918 0.645 0.834
Over all mean 46.52
8.30
Ekonometrika Terapan 1,
MPKP - FEUI 40
Repeated sampling in X X : bersifat fixed
Y: bersifat random
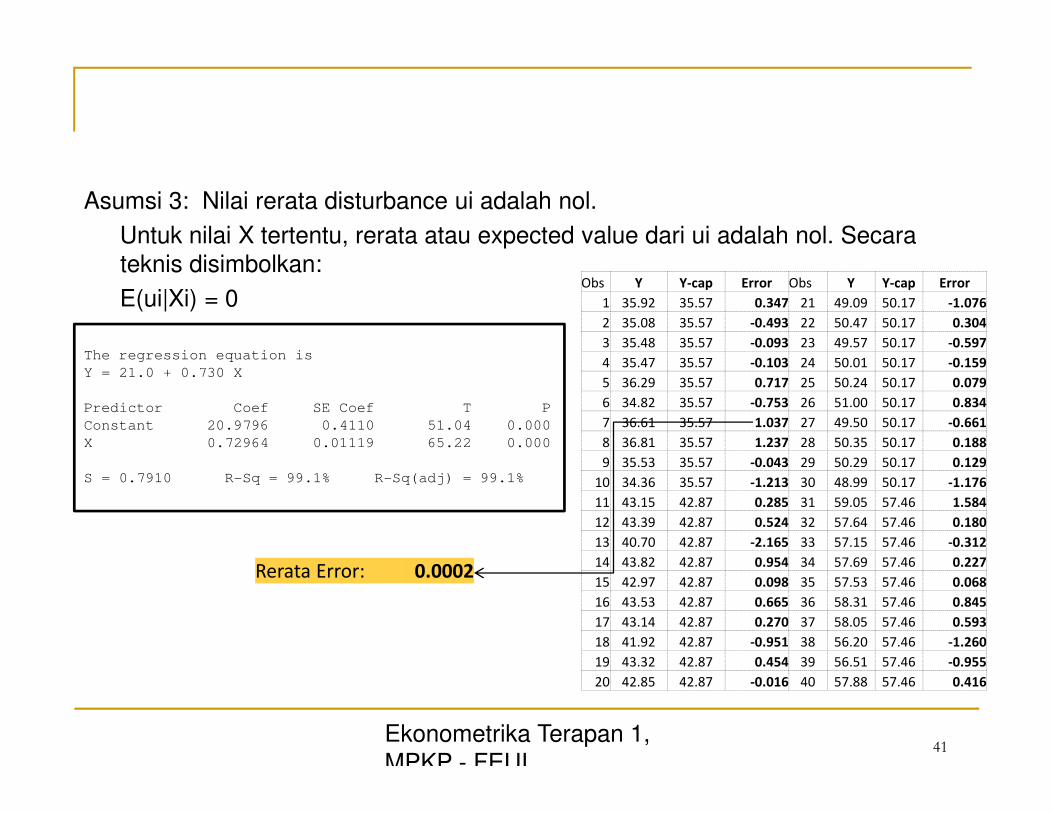
Asumsi 3: Nilai rerata disturbance ui adalah nol.
Untuk nilai X tertentu, rerata atau expected value dari ui adalah nol. Secara
teknis disimbolkan:
E(ui|Xi) = 0
Ekonometrika Terapan 1,
MPKP - FEUI 41
Obs Y Y-cap Error Obs Y Y-cap Error
1 35.92 35.57 0.347 21 49.09 50.17 -1.076
2 35.08 35.57 -0.493 22 50.47 50.17 0.304
3 35.48 35.57 -0.093 23 49.57 50.17 -0.597
4 35.47 35.57 -0.103 24 50.01 50.17 -0.159
5 36.29 35.57 0.717 25 50.24 50.17 0.079
6 34.82 35.57 -0.753 26 51.00 50.17 0.834
7 36.61 35.57 1.037 27 49.50 50.17 -0.661
8 36.81 35.57 1.237 28 50.35 50.17 0.188
9 35.53 35.57 -0.043 29 50.29 50.17 0.129
10 34.36 35.57 -1.213 30 48.99 50.17 -1.176
11 43.15 42.87 0.285 31 59.05 57.46 1.584
12 43.39 42.87 0.524 32 57.64 57.46 0.180
13 40.70 42.87 -2.165 33 57.15 57.46 -0.312
14 43.82 42.87 0.954 34 57.69 57.46 0.227
15 42.97 42.87 0.098 35 57.53 57.46 0.068
16 43.53 42.87 0.665 36 58.31 57.46 0.845
17 43.14 42.87 0.270 37 58.05 57.46 0.593
18 41.92 42.87 -0.951 38 56.20 57.46 -1.260
19 43.32 42.87 0.454 39 56.51 57.46 -0.955
20 42.85 42.87 -0.016 40 57.88 57.46 0.416
The regression equation is
Y = 21.0 + 0.730 X
Predictor Coef SE Coef T P
Constant 20.9796 0.4110 51.04 0.000
X 0.72964 0.01119 65.22 0.000
S = 0.7910 R-Sq = 99.1% R-Sq(adj) = 99.1%
Rerata Error: 0.0002
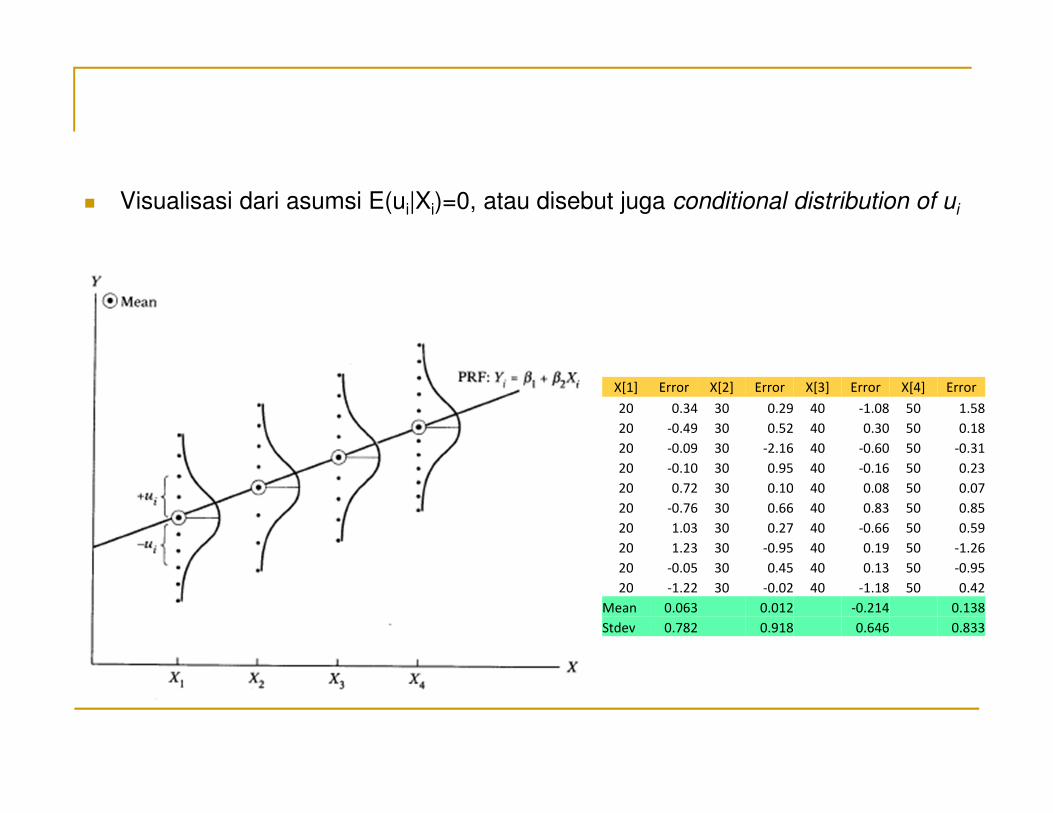
� Visualisasi dari asumsi E(ui|Xi)=0, atau disebut juga conditional distribution of ui
X[1] Error X[2] Error X[3] Error X[4] Error
20 0.34 30 0.29 40 -1.08 50 1.58
20 -0.49 30 0.52 40 0.30 50 0.18
20 -0.09 30 -2.16 40 -0.60 50 -0.31
20 -0.10 30 0.95 40 -0.16 50 0.23
20 0.72 30 0.10 40 0.08 50 0.07
20 -0.76 30 0.66 40 0.83 50 0.85
20 1.03 30 0.27 40 -0.66 50 0.59
20 1.23 30 -0.95 40 0.19 50 -1.26
20 -0.05 30 0.45 40 0.13 50 -0.95
20 -1.22 30 -0.02 40 -1.18 50 0.42
Mean 0.063 0.012 -0.214 0.138
Stdev 0.782 0.918 0.646 0.833

Asumsi 4: Homoscedasticity atau equal variance of ui
Untuk setiap nilai Xi tertentu (given), varians dari ui adalah σ2 . Secara matematis dapat disimbolkan:
Var(ui|Xi) = E[(ui|Xi)-E(ui|Xi) ]2
= E(u2i|Xi)
= σ2
Ekonometrika Terapan 1,
MPKP - FEUI 43
Dapat ditulis bhw:
Var(u|X1) = var(u|X2) =…..=var(u|Xn) = σ2
X[1] Error X[2] Error X[3] Error X[4] Error
20 0.34 30 0.29 40 -1.08 50 1.58
20 -0.49 30 0.52 40 0.30 50 0.18
20 -0.09 30 -2.16 40 -0.60 50 -0.31
20 -0.10 30 0.95 40 -0.16 50 0.23
20 0.72 30 0.10 40 0.08 50 0.07
20 -0.76 30 0.66 40 0.83 50 0.85
20 1.03 30 0.27 40 -0.66 50 0.59
20 1.23 30 -0.95 40 0.19 50 -1.26
20 -0.05 30 0.45 40 0.13 50 -0.95
20 -1.22 30 -0.02 40 -1.18 50 0.42
Mean 0.063 0.012 -0.214 0.138
Var u|X) 0.611 0.843 0.417 0.693
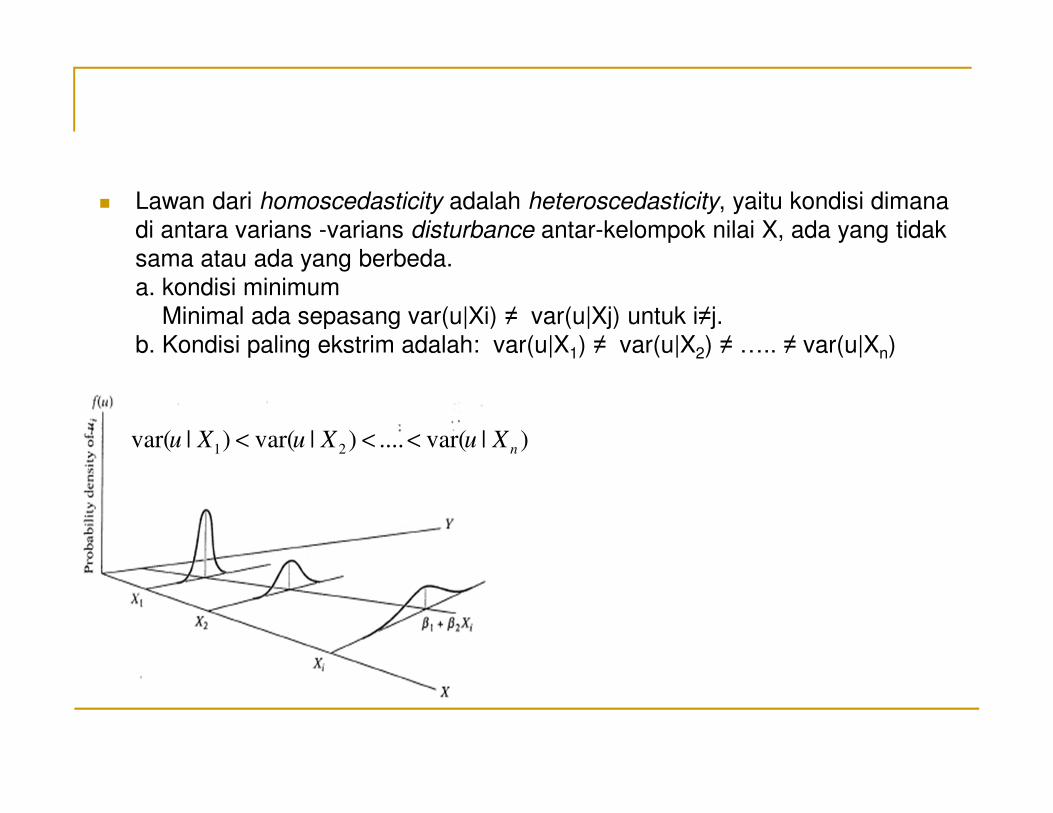
� Lawan dari homoscedasticity adalah heteroscedasticity, yaitu kondisi dimana
di antara varians -varians disturbance antar-kelompok nilai X, ada yang tidak
sama atau ada yang berbeda.
a. kondisi minimum
Minimal ada sepasang var(u|Xi) ≠ var(u|Xj) untuk i≠j.
b. Kondisi paling ekstrim adalah: var(u|X1) ≠ var(u|X2) ≠ ….. ≠ var(u|Xn)
)|var(....)|var()|var( 21 nXuXuXu <<<

Ekonometrika Terapan 1,
MPKP - FEUI 45
Obs X Y obs X Y obs X Y obs X Y
1 20 35.92 11 30 43.15 21 40 52.89 31 50 63.28
2 20 35.08 12 30 43.39 22 40 42.70 32 50 58.41
3 20 35.48 13 30 40.70 23 40 45.43 33 50 54.59
4 20 35.47 14 30 43.82 24 40 51.66 34 50 59.45
5 20 36.29 15 30 42.97 25 40 52.03 35 50 62.26
6 20 34.82 16 30 43.53 26 40 56.51 36 50 56.56
7 20 36.61 17 30 43.14 27 40 46.90 37 50 57.34
8 20 36.81 18 30 41.92 28 40 54.44 38 50 57.54
9 20 35.53 19 30 43.32 29 40 51.87 39 50 59.53
10 20 34.36 20 30 42.85 30 40 49.50 40 50 53.75
Mean 35.63 42.88 50.39 58.27
Var 0.611 0.843 18.142 9.149
Data dengan gejala heteroskedastik
Heteroskedastik
Dalam Nilai Y
The regression equation is
Y = 20.4 + 0.754 X
Predictor Coef SE Coef T P
Constant 20.399 1.358 15.02 0.000
X 0.75416 0.03697 20.40 0.000
S = 2.614 R-Sq = 91.6% R-Sq(adj) = 91.4%
Y Y-cap Y Y-cap Y Y-cap Y Y-cap
35.92 35.48 43.15 43.02 52.89 50.57 63.28 58.11
35.08 35.48 43.39 43.02 42.70 50.57 58.41 58.11
35.48 35.48 40.70 43.02 45.43 50.57 54.59 58.11
35.47 35.48 43.82 43.02 51.66 50.57 59.45 58.11
36.29 35.48 42.97 43.02 52.03 50.57 62.26 58.11
34.82 35.48 43.53 43.02 56.51 50.57 56.56 58.11
36.61 35.48 43.14 43.02 46.90 50.57 57.34 58.11
36.81 35.48 41.92 43.02 54.44 50.57 57.54 58.11
35.53 35.48 43.32 43.02 51.87 50.57 59.53 58.11
34.36 35.48 42.85 43.02 49.50 50.57 53.75 58.11
Y Actual dan Y-Fitted

Ekonometrika Terapan 1,
MPKP - FEUI 46
X[1] Error X[2] Error X[3] Error X[4] Error
20 0.43 30 0.13 40 2.32 50 5.18
20 -0.40 30 0.37 40 -7.87 50 0.30
20 0.00 30 -2.32 40 -5.14 50 -3.52
20 -0.01 30 0.80 40 1.09 50 1.34
20 0.81 30 -0.06 40 1.47 50 4.16
20 -0.67 30 0.51 40 5.94 50 -1.55
20 1.12 30 0.11 40 -3.66 50 -0.77
20 1.32 30 -1.11 40 3.87 50 -0.57
20 0.04 30 0.30 40 1.31 50 1.42
20 -1.13 30 -0.17 40 -1.07 50 -4.36
Mean 0.153 -0.143 -0.173 0.163
Var 0.611 0.843 18.142 9.149
Distribusi Error yang heteroskedastik
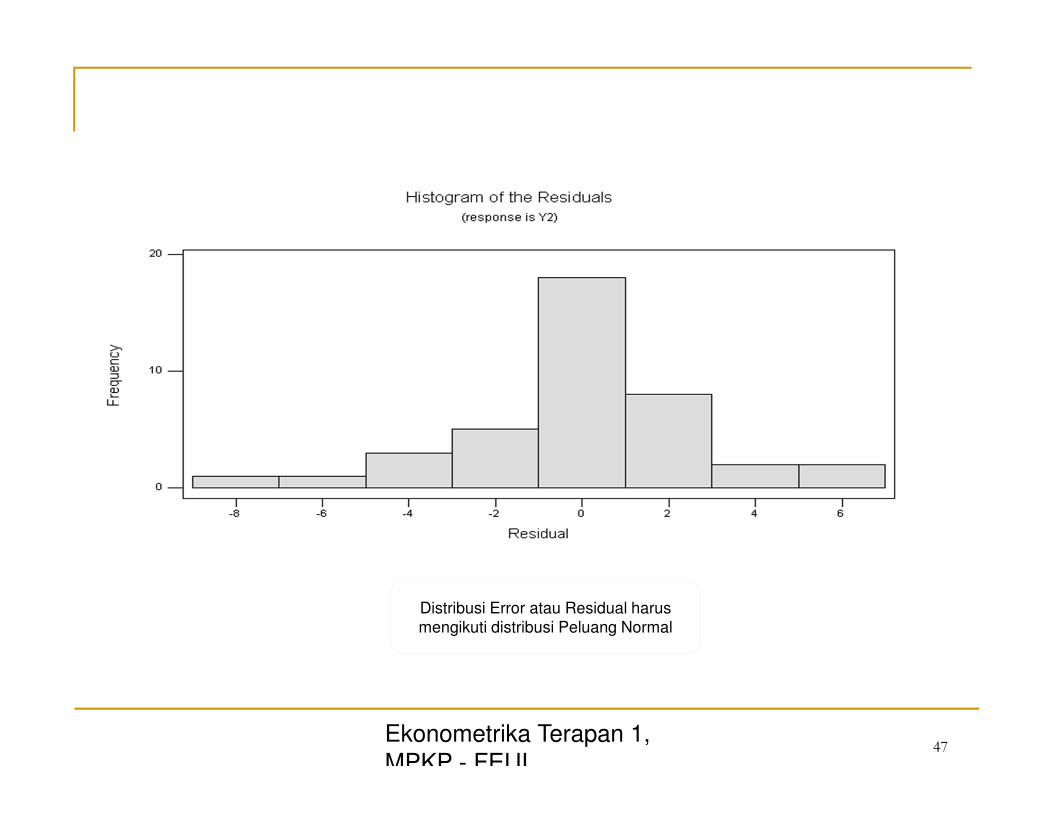
Ekonometrika Terapan 1,
MPKP - FEUI 47
Distribusi Error atau Residual harus
mengikuti distribusi Peluang Normal
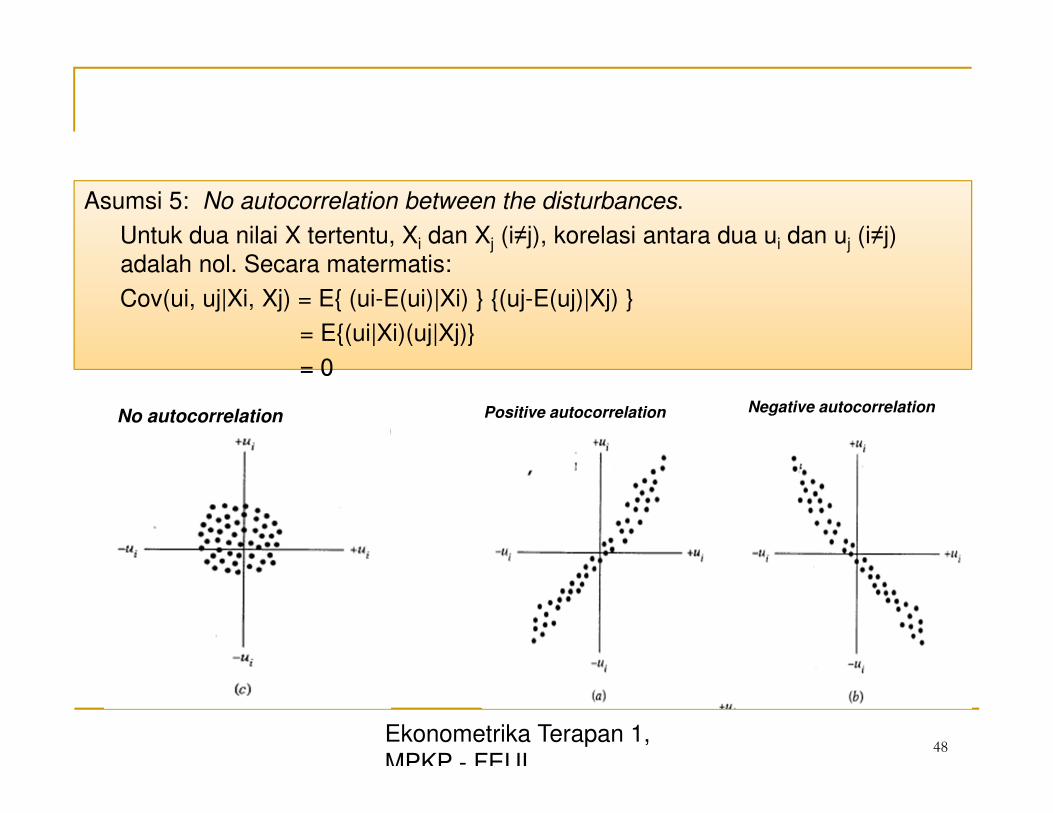
= 0
Asumsi 5: No autocorrelation between the disturbances. Untuk dua nilai X tertentu, Xi dan Xj (i≠j), korelasi antara dua ui dan uj (i≠j)
adalah nol. Secara matermatis:
Cov(ui, uj|Xi, Xj) = E{ (ui-E(ui)|Xi) } {(uj-E(uj)|Xj) }
= E{(ui|Xi)(uj|Xj)}
= 0
Ekonometrika Terapan 1,
MPKP - FEUI 48
No autocorrelation Positive autocorrelation Negative autocorrelation
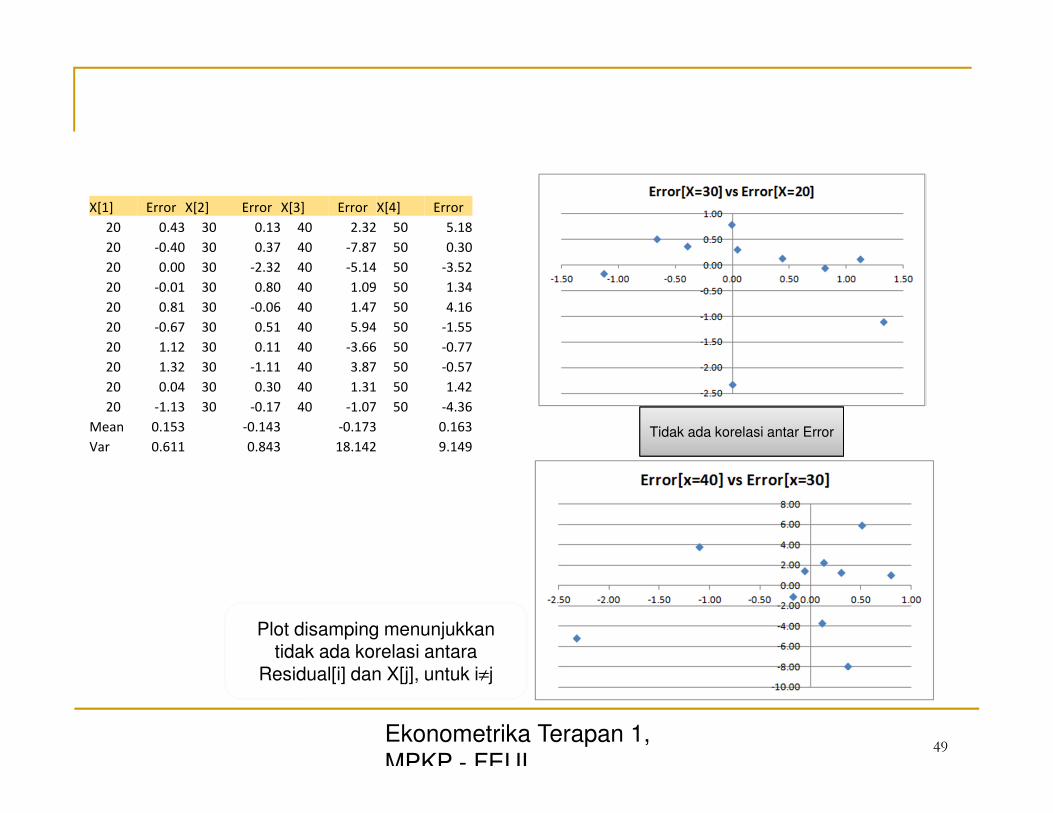
Ekonometrika Terapan 1,
MPKP - FEUI 49
X[1] Error X[2] Error X[3] Error X[4] Error
20 0.43 30 0.13 40 2.32 50 5.18
20 -0.40 30 0.37 40 -7.87 50 0.30
20 0.00 30 -2.32 40 -5.14 50 -3.52
20 -0.01 30 0.80 40 1.09 50 1.34
20 0.81 30 -0.06 40 1.47 50 4.16
20 -0.67 30 0.51 40 5.94 50 -1.55
20 1.12 30 0.11 40 -3.66 50 -0.77
20 1.32 30 -1.11 40 3.87 50 -0.57
20 0.04 30 0.30 40 1.31 50 1.42
20 -1.13 30 -0.17 40 -1.07 50 -4.36
Mean 0.153 -0.143 -0.173 0.163
Var 0.611 0.843 18.142 9.149 Tidak ada korelasi antar Error
Plot disamping menunjukkan tidak ada korelasi antara
Residual[i] dan X[j], untuk i≠j
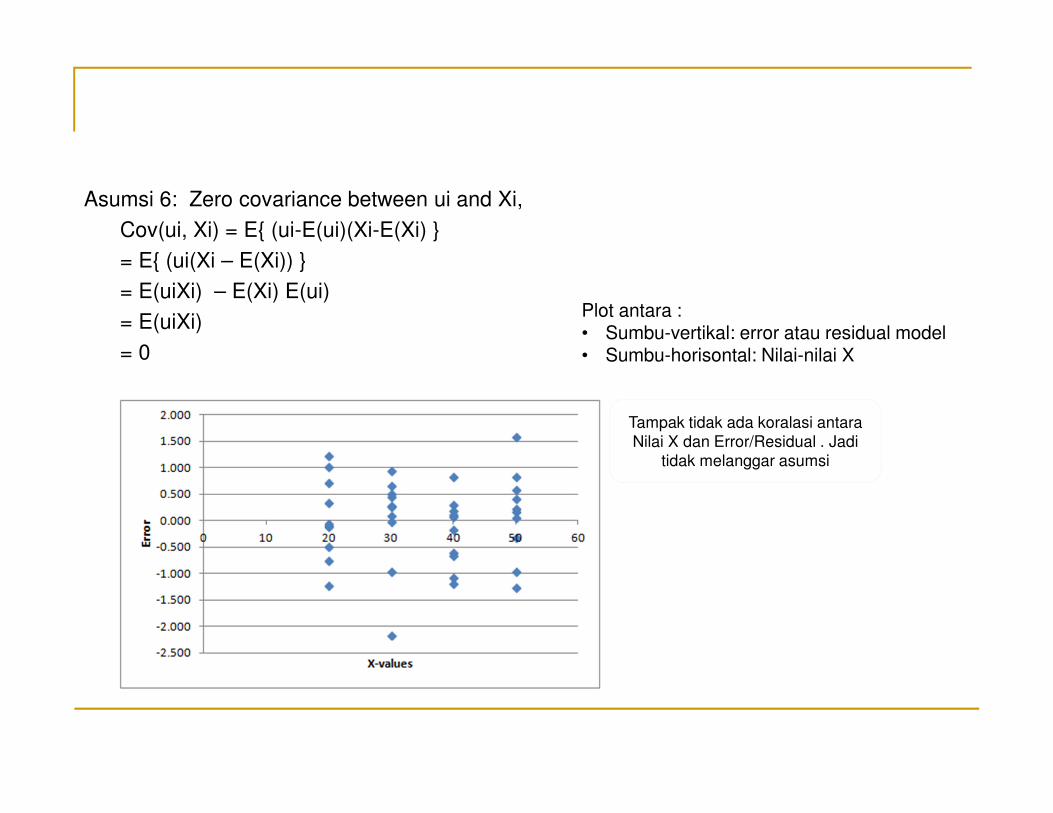
Asumsi 6: Zero covariance between ui and Xi,
Cov(ui, Xi) = E{ (ui-E(ui)(Xi-E(Xi) }
= E{ (ui(Xi – E(Xi)) }
= E(uiXi) – E(Xi) E(ui)
= E(uiXi)
= 0
Plot antara : • Sumbu-vertikal: error atau residual model • Sumbu-horisontal: Nilai-nilai X
Tampak tidak ada koralasi antara
Nilai X dan Error/Residual . Jadi
tidak melanggar asumsi

Asumsi 7: banyak pengamatan n harus lebih besar daripada banyaknya parameter yang diestimasi. Alternatif: banyak observasi harus jauh lebih besar daripada banyaknya variable penjelas.
Asumsi 8: Variabilitas X. Nilai-nilai dalam variable X tidak boleh sama. Alternatif: varians(X) harus benar-benar bilangan positif.
Asumsi 9: Model regresi dispesifikasikan dengan benar. Alternatif: tidak ada bias spesifikasi dalam model yang digunakaan dalam analisis empirik.
Asumsi 10: Tidak ada Multikolinier Sempurna. Tidak ada hubungan linier sempurna diantara variable penjelas.
Ekonometrika Terapan 1,
MPKP - FEUI 51
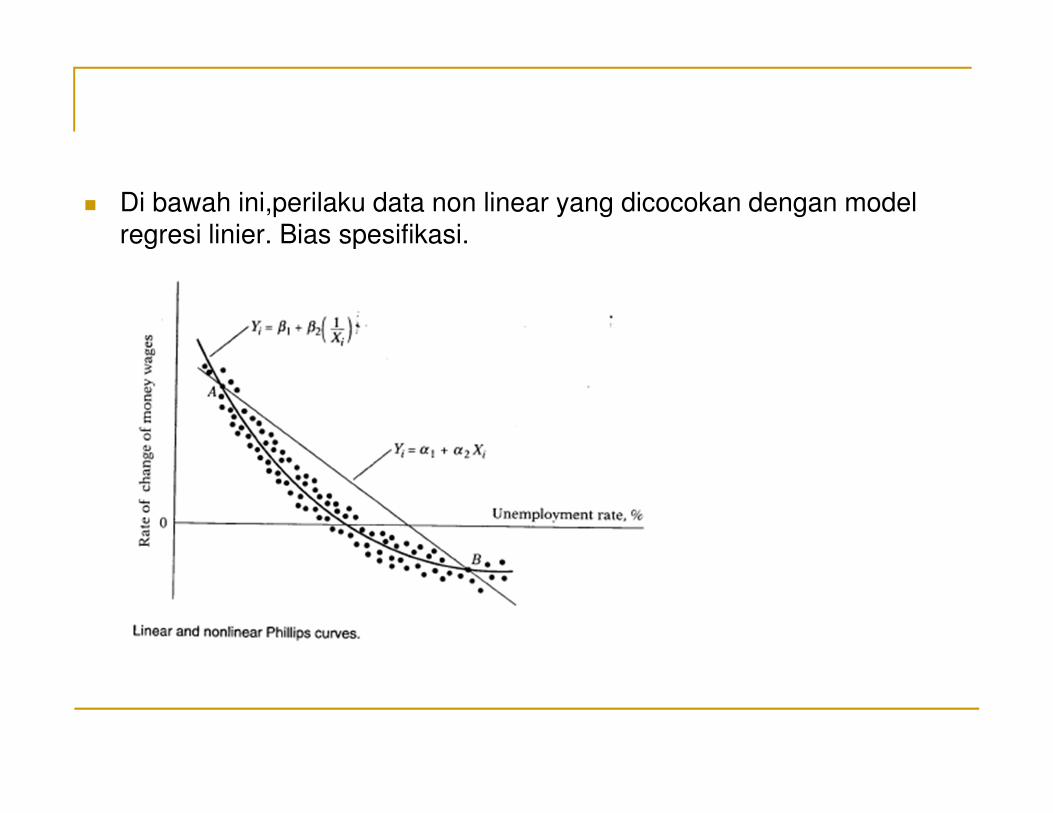
� Di bawah ini,perilaku data non linear yang dicocokan dengan model regresi linier. Bias spesifikasi.

� PROPERTIES OF LEAST-SQUARE (LS) ESTIMATORS: GAUSS-MARKOV THEOREM Given the assumption of Classical Linear Regression Model, the LS estimate
posses some ideal or optimum properties, that is found in the Gauss-Markov
Theorem, that is Best Linear Unbiased Estimate. Lets OLS estimator
said to be a Best Linear Unbiased Estimate (BLUE ) of ββββ2 if the following
holds:
1. Linear, linear function of a random variable, such as dependent variable Y
2. Unbiased, expected value is equal to the true value β2
3. Minimum variance, in the class of all such linear unbiased estimator.
Unbiased estimator with the minimum variance is known as an efficient
estimator. The OLS estimator are BLUE.
Gauss-Markov Theorem: Given the assumption of the classical linear regression
model, the LS estimator, in the class of unbiased linear estimator, have the minimum
variance, that is, they are BLUE.
Ekonometrika Terapan 1,
MPKP - FEUI 53
2β
)ˆ( 2βE

Asumsi: Non Perfect Multicollinearity � Asumsi 10 dari model regresi linier klasik (CLRM) adalah tidak ada
multikolinieritas di antara regressors yang dimasukkan ke dalam model regresi.
� Istilah multikolinearitas berasal dari Ragnar Frisch. Awalnya berarti adanya hubungan linear antara beberapa atau semua variabel penjelas dari model regresi yang "sempurna", atau tepat, .
� Untuk k-variabel regresi yang melibatkan variable penjelas X1, X2, ..., Xk (di mana X1 = 1 untuk semua pengamatan untuk memungkinkan suku intercept), hubungan tepat dikatakan linear:
� Kasus di mana variabel X saling berhubungan tetapi tidak begitu sempurna:
Ekonometrika Terapan 1,
MPKP - FEUI 54
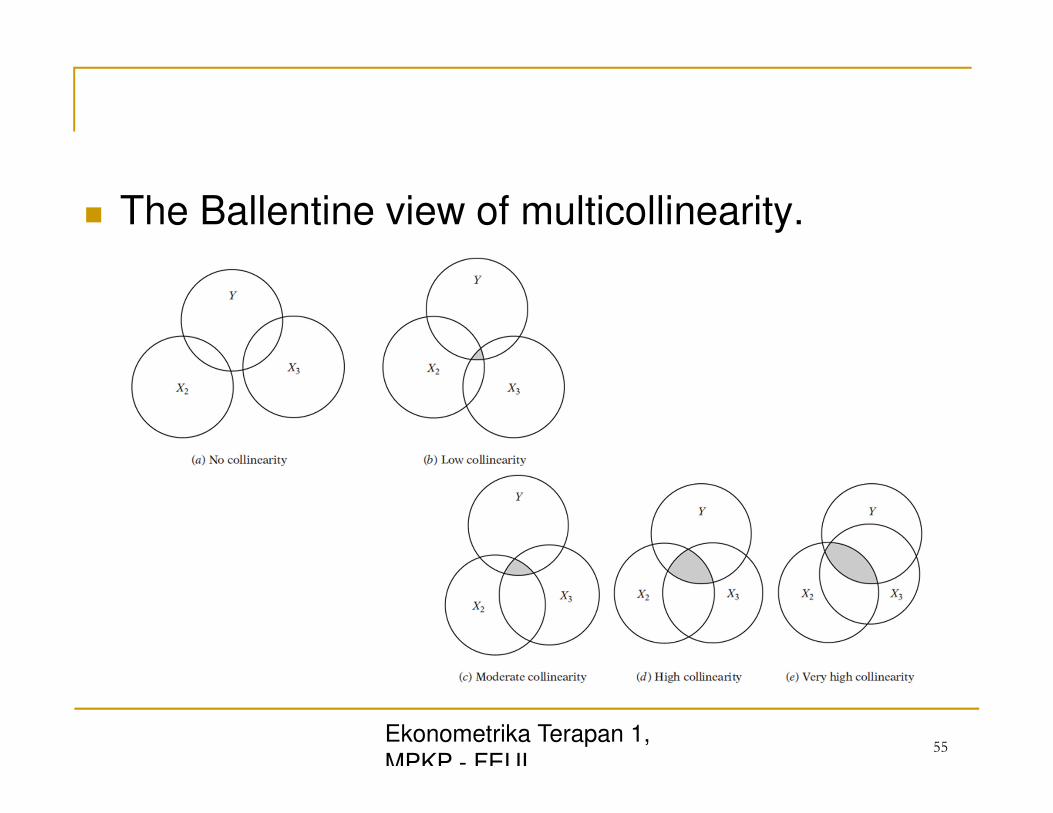
� The Ballentine view of multicollinearity.
Ekonometrika Terapan 1,
MPKP - FEUI 55

Why multicollinearity?
Ekonometrika Terapan 1,
MPKP - FEUI 56
Jika multikolineritas bersifat sempurna,
• koefisien regresi dari variable X tidak bisa
ditentukan
• Standar error koefisien dugaan menjadi tidak
terhingga,
Jika multikolinieritas kurang sempurna:
• Koefisien regresi walaupun bisa ditentukan, tetapi
memiliki standar error (relatif terhadap koefisien itu
sendiri) berarti koefisien-koefisien tidak dapat
diestimasi dengan presisi dan akurasi yang tinggi.

Sumber Multikolinieritas
Ekonometrika Terapan 1,
MPKP - FEUI 57
1. Metode pengumpulan data yang diterapkan. Terbatasnya
kisaran nilai pada variable X ketika mengambil sampel dari
populasi.
2. Kendala-kendala pada model atau populasi yang diambil
sampel nya. Regresi konsumsi listrik oleh pendapatan (X2)
dan luas rumah (X3). Secara fisik keluarga dengan
pendapatan semakin besar, memiliki rumah semakin besar.
3. Spesifikasi model. Menambahkan suku polynomial (X2, X3)
ketika kisaran nilai X sangat pendek.
4. Overdetermined Model. Terlalu banyak variable penjelas.

Konsekuensi Praktis dari Multicollinierity
Ekonometrika Terapan 1,
MPKP - FEUI 58
Dalam kasus multikolinieritas sedang atau tinggi, kemungkinan
akan menghadapi konsekuensi berikut:
1. Walaupun BLUE, penduga OLS memiliki variance dan
covariance yang terlalu besar, menyulitkan memperoleh estimasi
yang akurat
2. Oleh karena konsekuensi 1, selang keyakinan cenderung lebih
lebar, lebih sering mengarahkan untuk menerima “Hipotesis null”
3. Oleh karena konsekuensi 1, rasio-T dari satu atau lebih variable
secara statistic tidak signifikan.
4. Walaupun rasio-T dari satu atau lebih variable tidak signifikan,
namun R2 sangat tinggi.
5. Penduga OLS dan standar error menjadi sensitive terhadap
perubahan kecil dalam data.

Bagaimana mendeteksi
1. High R2 but few significant t ratios.
2. High pair-wise correlations among regresors.
3. Examination of partial correlations.
4. Auxiliary regressions.
Ekonometrika Terapan 1,
MPKP - FEUI 59

Ilustrasi Multikolinieritas Y X1 X2 X3
167.349 50 110 25.1672
158.921 50 110 23.5555
158.945 50 110 23.8647
168.751 50 110 24.7598
164.548 50 110 25.0701
198.235 60 100 30.5601
198.677 60 100 30.5268
191.024 60 100 28.8592
197.178 60 100 30.5772
190.825 60 100 28.7815
245.532 80 90 40.0588
245.885 80 90 40.6819
253.976 80 90 42.0141
248.709 80 90 40.3368
249.185 80 90 38.4482
300.875 100 70 47.8078
302.493 100 70 50.8256
308.509 100 70 51.2236
305.338 100 70 50.2455
304.256 100 70 50.6173
Ekonometrika Terapan 1,
MPKP - FEUI 60
X1 X2 X3
X1 1
X2 -0.99027 1
X3 0.994819 -0.98364 1
Koefisien korelasi antar-variabel penjelas
The regression equation is
Y = 90.1 + 1.21 X1 - 0.417 X2 + 2.45 X3
Predictor Coef SE Coef T P Paramater
Constant 90.09 46.72 1.93 0.072 50.00
X1 1.2112 0.4302 2.82 0.012 1.90
X2 -0.4171 0.3152 -1.32 0.204 -0.15
X3 2.4488 0.6441 3.80 0.002 1.50
S = 2.885 R-Sq = 99.8% R-Sq(adj) = 99.7%
Dugaan berbias
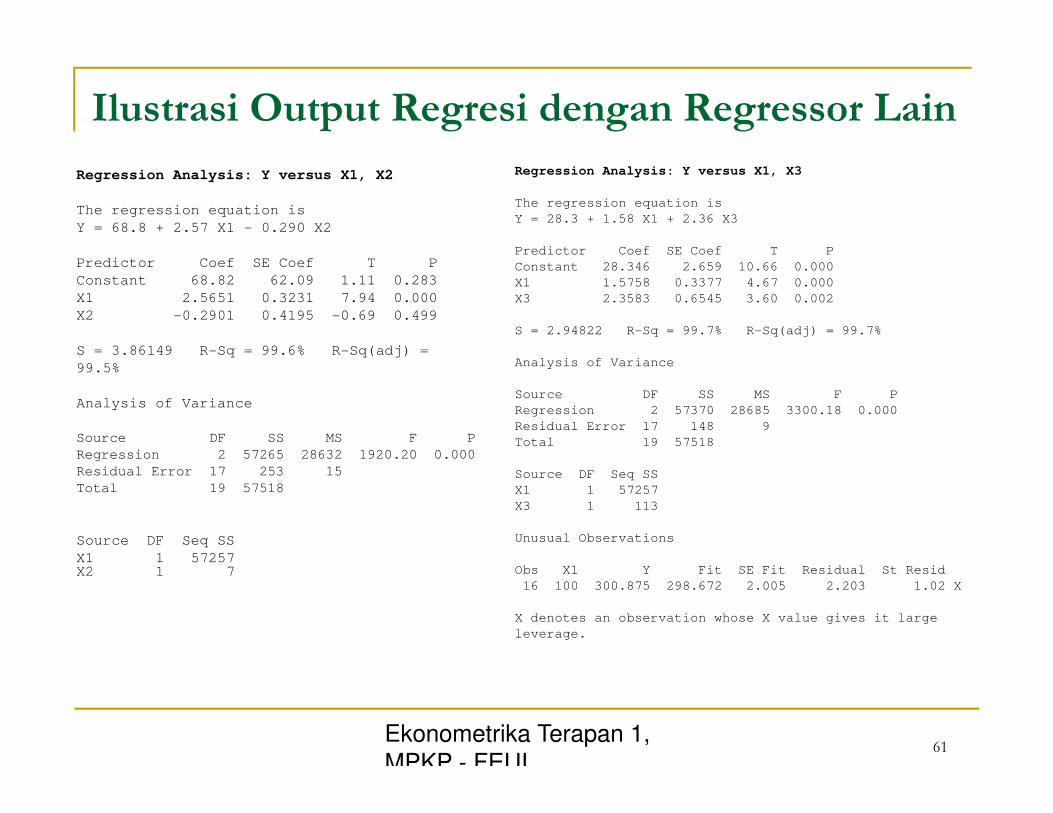
Ilustrasi Output Regresi dengan Regressor Lain
Ekonometrika Terapan 1,
MPKP - FEUI 61
Regression Analysis: Y versus X1, X2
The regression equation is
Y = 68.8 + 2.57 X1 - 0.290 X2
Predictor Coef SE Coef T P
Constant 68.82 62.09 1.11 0.283
X1 2.5651 0.3231 7.94 0.000
X2 -0.2901 0.4195 -0.69 0.499
S = 3.86149 R-Sq = 99.6% R-Sq(adj) =
99.5%
Analysis of Variance
Source DF SS MS F P
Regression 2 57265 28632 1920.20 0.000
Residual Error 17 253 15
Total 19 57518
Source DF Seq SS
X1 1 57257 X2 1 7
Regression Analysis: Y versus X1, X3
The regression equation is
Y = 28.3 + 1.58 X1 + 2.36 X3
Predictor Coef SE Coef T P
Constant 28.346 2.659 10.66 0.000
X1 1.5758 0.3377 4.67 0.000
X3 2.3583 0.6545 3.60 0.002
S = 2.94822 R-Sq = 99.7% R-Sq(adj) = 99.7%
Analysis of Variance
Source DF SS MS F P
Regression 2 57370 28685 3300.18 0.000
Residual Error 17 148 9
Total 19 57518
Source DF Seq SS
X1 1 57257
X3 1 113
Unusual Observations
Obs X1 Y Fit SE Fit Residual St Resid
16 100 300.875 298.672 2.005 2.203 1.02 X
X denotes an observation whose X value gives it large
leverage.

Ekonometrika Terapan 1,
MPKP - FEUI 62
Variance Inflation Factor � A general rule is if the correlation between two independent variables is
between -0.70 and 0.70 there likely is not a problem using both of the independent variables.
� A more precise test is to use the variance inflation factor (VIF).
� A VIF > 10 is unsatisfactory. Remove that independent variable from the analysis.
� The value of VIF is found as follows:
The term R2j refers to the coefficient of determination, where the selected
independent variable is used as a dependent variable and the remaining
independent variables are used as independent variables.
21
1
jRVIF
−=

Ekonometrika Terapan 1,
MPKP - FEUI 63
Y X1 X2 X3
167.349 50 110 25.1672
158.921 50 110 23.5555
158.945 50 110 23.8647
168.751 50 110 24.7598
164.548 50 110 25.0701
198.235 60 100 30.5601
198.677 60 100 30.5268
191.024 60 100 28.8592
197.178 60 100 30.5772
190.825 60 100 28.7815
245.532 80 90 40.0588
245.885 80 90 40.6819
253.976 80 90 42.0141
248.709 80 90 40.3368
249.185 80 90 38.4482
300.875 100 70 47.8078
302.493 100 70 50.8256
308.509 100 70 51.2236
305.338 100 70 50.2455
304.256 100 70 50.6173
Variance Inflation Factor: Regresi X1 oleh X2 dan X3
Coefficie
nts
Standard Error t Stat P-value
Intercept 90.094 46.725 1.928 0.072
X1 1.211 0.430 2.815 0.012
X2 -0.417 0.315 -1.324 0.204
X3 2.449 0.644 3.802 0.002
Regression Statistics
Multiple R 0.998842
R Square 0.997685
Adjusted R Square 0.99725
Standard Error 2.885111
Observations 20
10431.88998.01
1>=
−=VIF
VIF terlalu besar, korelasi antar variable bebas
sangat besar, mengganggu validitas dan
akurasi dugaan. Perlu mengeluarkan satu atau
lebih variable bebas

Bagaimana mengatasi ?
� A priori information.
� Combining cross-sectional and time series data.
� Dropping a variable(s) and specification bias (But
in dropping a variable from the model specification
bias or specification error )
� Transformation of variables.
� Reducing colinearity in polynomial regressions.
Ekonometrika Terapan 1,
MPKP - FEUI 64

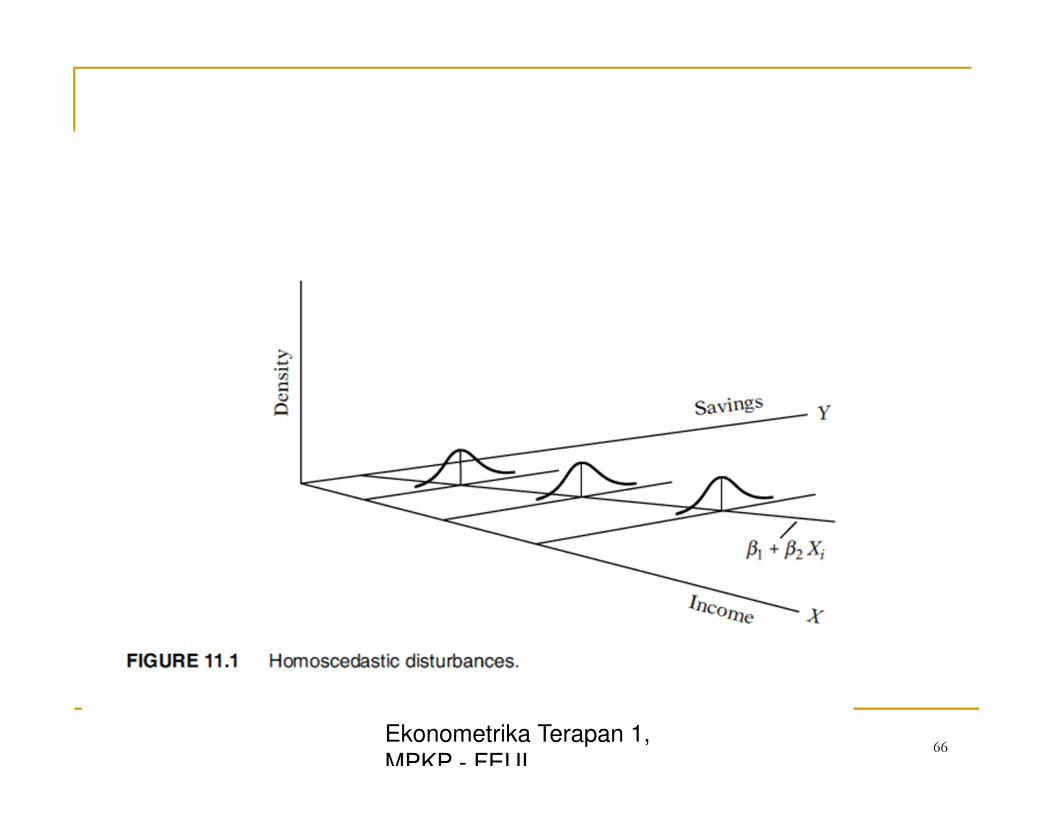
Asumsi: Homoskedastisitas (Homescedasticity atau non
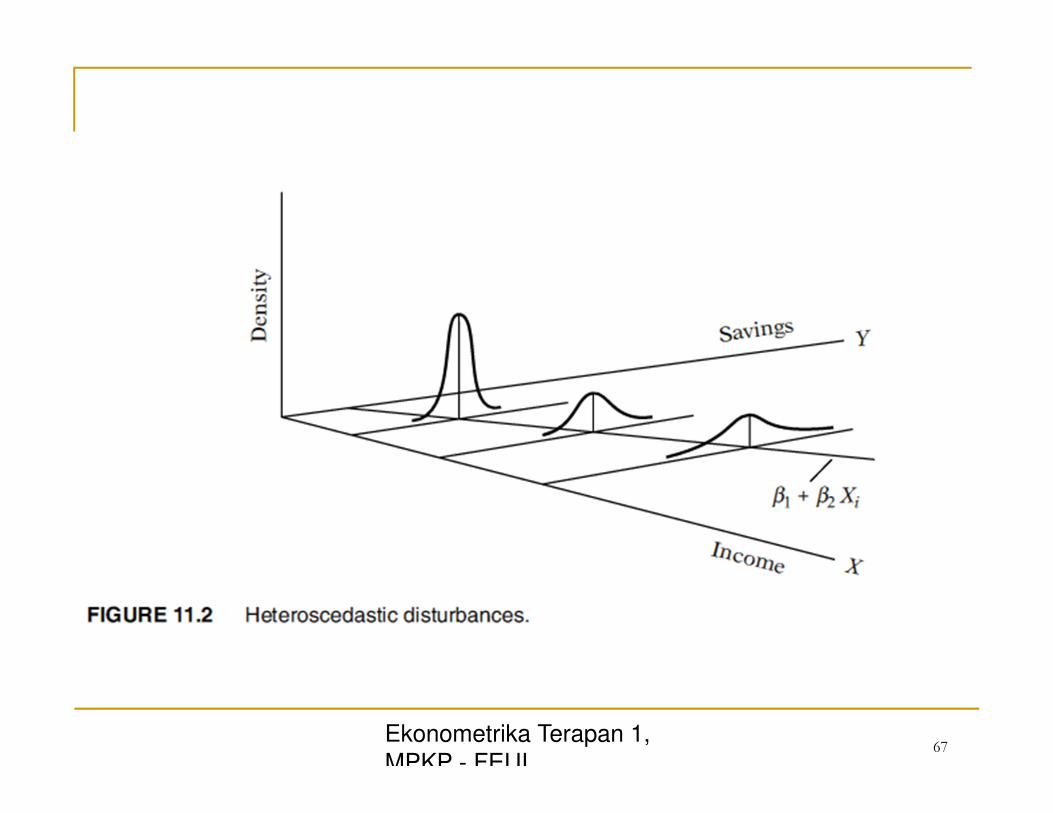
Heteroskedastisitas ( Heteroscedasticity)
� Homskedastisitas?
� Asumsi homoskedastisitas, homo=sama, scedasticity
=variance, atau “kesamaan variance”:
� Vairane Yi tidak sama, jadi disebut heteroskedastisitas:
Ekonometrika Terapan 1,
MPKP - FEUI 65
Ekonometrika Terapan 1,
MPKP - FEUI 66
Ekonometrika Terapan 1,
MPKP - FEUI 67
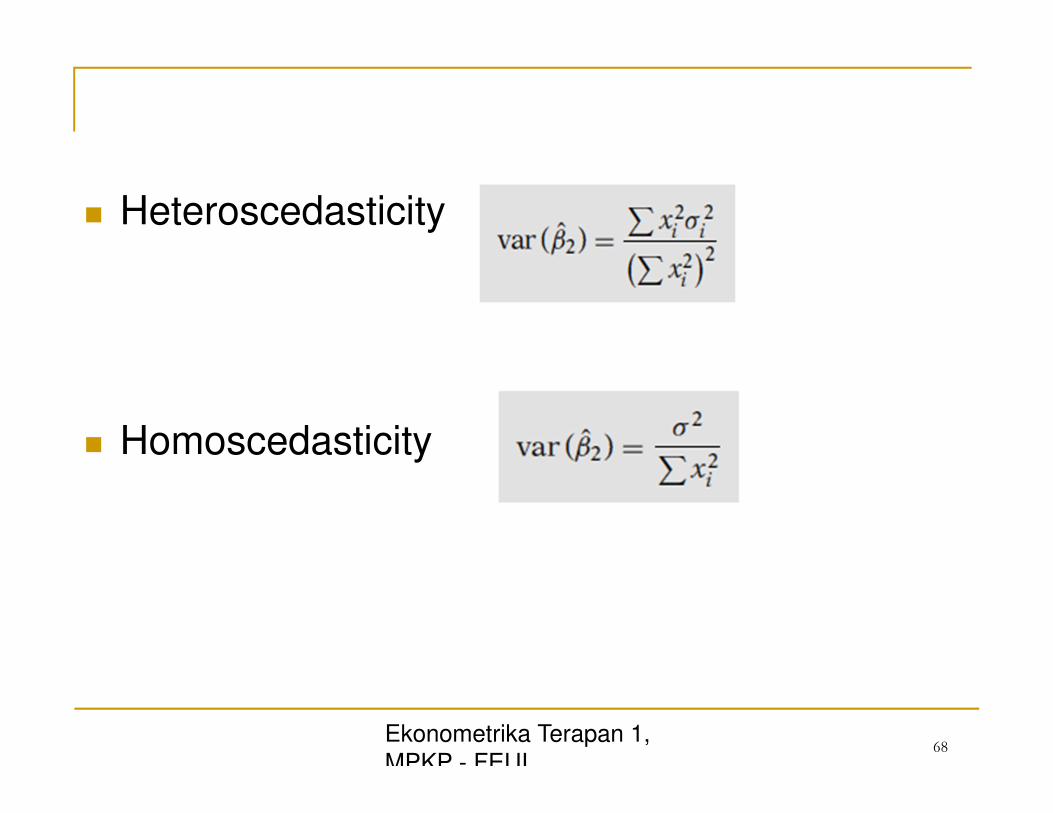
� Heteroscedasticity
� Homoscedasticity
Ekonometrika Terapan 1,
MPKP - FEUI 68

Penyebab?
� Mengikuti Error-Learning model, seperti orang belajar, kesalahan perilaku mereka menjadi lebih kecil dari waktu ke waktu
� Dengan tumbuhnya pendapatan, orang memiliki lebih banyak pendapatan dan karenanya cakupan pilihan belanja semakin banyak.
� Sejalan dengan perbaikan pengumpulan data, σi2 semakin menurun.
� Heteroskedastisitas juga bisa timbul sebagai akibat dari kehadiran outlier.
� Sumber lain dari heteroskedastisitas muncul dari melanggar Asumsi 9 dari CLRM, yaitu, bahwa model regresi ditentukan dengan benar.
� Sumber lain dari heteroskedastisitas adalah skewness dalam distribusi satu atau lebih regressors dimasukkan dalam model
Ekonometrika Terapan 1,
MPKP - FEUI 69

Konsekuensi?
� Singkatnya, jika kita bertahan dalam menggunakan
prosedur pengujian yang biasa meskipun hadir gejala
heteroskedastisitas, kesimpulan apa pun yang kita buat
mungkin sangat menyesatkan.
Ekonometrika Terapan 1,
MPKP - FEUI 70
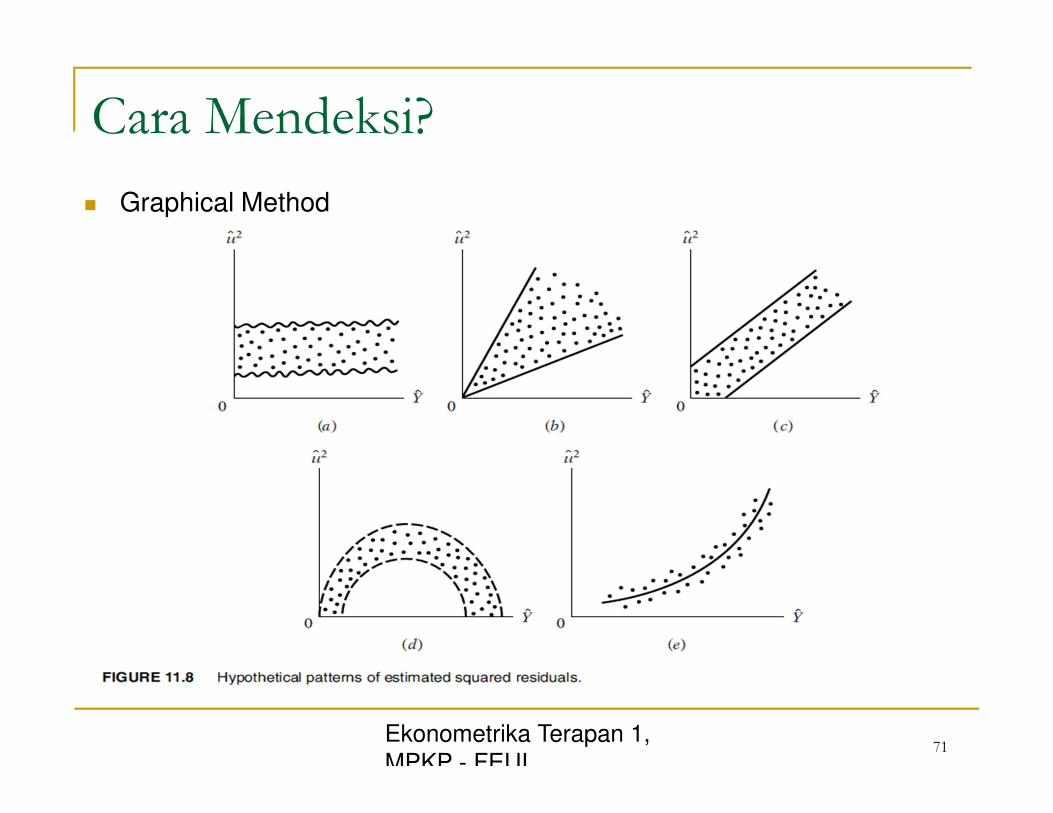
Cara Mendeksi?
� Graphical Method
Ekonometrika Terapan 1,
MPKP - FEUI 71
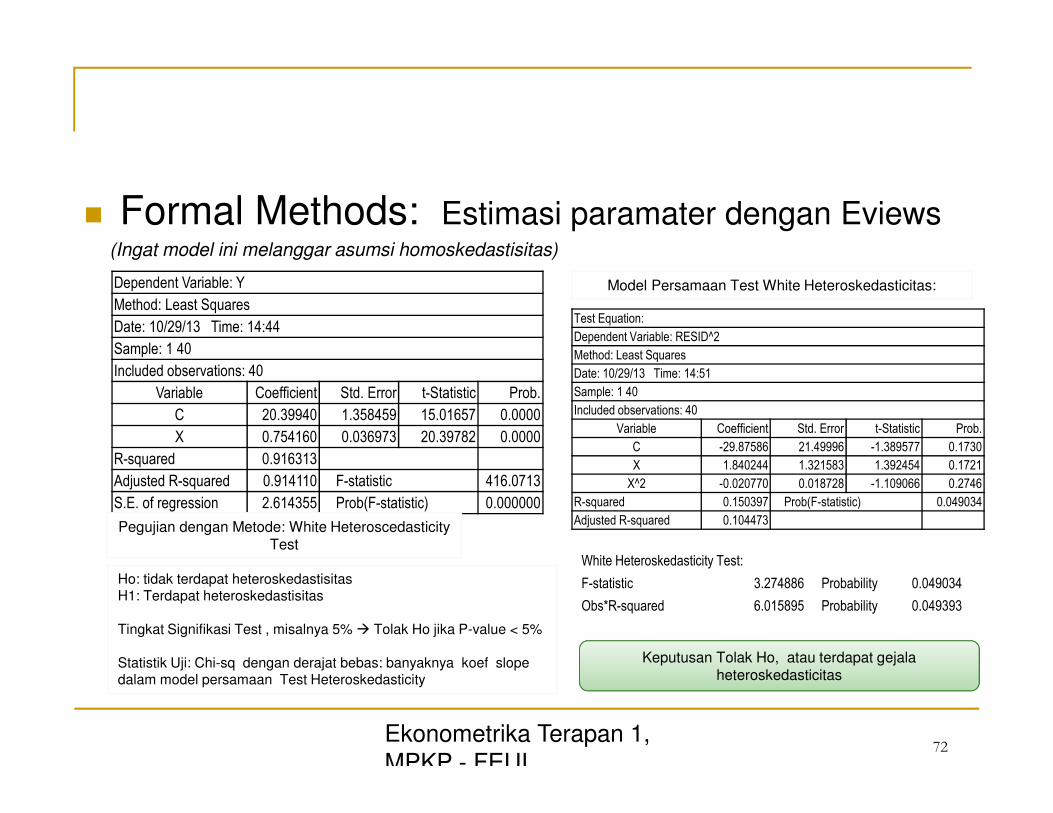
� Formal Methods: Estimasi paramater dengan Eviews (Ingat model ini melanggar asumsi homoskedastisitas)
Ekonometrika Terapan 1,
MPKP - FEUI 72
Dependent Variable: Y
Method: Least Squares
Date: 10/29/13 Time: 14:44
Sample: 1 40
Included observations: 40
Variable Coefficient Std. Error t-Statistic Prob.
C 20.39940 1.358459 15.01657 0.0000
X 0.754160 0.036973 20.39782 0.0000
R-squared 0.916313
Adjusted R-squared 0.914110 F-statistic 416.0713
S.E. of regression 2.614355 Prob(F-statistic) 0.000000
Pegujian dengan Metode: White Heteroscedasticity Test
Ho: tidak terdapat heteroskedastisitas H1: Terdapat heteroskedastisitas Tingkat Signifikasi Test , misalnya 5% � Tolak Ho jika P-value < 5% Statistik Uji: Chi-sq dengan derajat bebas: banyaknya koef slope dalam model persamaan Test Heteroskedasticity
White Heteroskedasticity Test:
F-statistic 3.274886 Probability 0.049034
Obs*R-squared 6.015895 Probability 0.049393
Test Equation:
Dependent Variable: RESID^2
Method: Least Squares
Date: 10/29/13 Time: 14:51
Sample: 1 40
Included observations: 40
Variable Coefficient Std. Error t-Statistic Prob.
C -29.87586 21.49996 -1.389577 0.1730
X 1.840244 1.321583 1.392454 0.1721
X^2 -0.020770 0.018728 -1.109066 0.2746
R-squared 0.150397 Prob(F-statistic) 0.049034
Adjusted R-squared 0.104473
Model Persamaan Test White Heteroskedasticitas:
Keputusan Tolak Ho, atau terdapat gejala heteroskedasticitas

No Serial Autocorrelation
(Autokorelasi serial): Konskuensi,
Cara Mendeteksi dan Mengatasinya

74
Pengertian Autokorelasi
� autocorrelated error menggambarkan korelasi
antara error ei dengan ej untuk i ≠ j.
� Di dalam literatur ekonometrika persoalan ini
sering disebut dengan otokorelasi yang
merupakan persoalan yang umum ditemukan
dalam data time series.

75
Penyebab adanya Autokorelasi
1. Adanya shocks yang seringkali pengaruhnya
tetap muncul dalam suatu periode waktu yang
cukup lama.
2. inertia atau psychological conditioning.
3. Manipulasi data.
4. Salah spesifikasi (Adanya variabel yang
penting tidak masuk dalam model dan bentuk
fungsi tidak tepat)

Penyebab adanya Autokorelasi
5. Lag: Dalam model autoregressive terdapat variable bebas yang nilainya merupakan lag dari variable terikat.
6. Manipulasi data Misalkan seseorang dapat memperoleh data kuartalan dari data
bulanan dengan merata-ratakan data secara 3 bulanan. Sedang data untuk kuartal ke dua diperoleh dengan merata-ratakan data secara 3 bulanan selanjutnya. Jika kita melakukan ini, maka kita akan medapatkan smoothness/kehalusan dalam data yang tidak ada sebelumnya. Selanjutnya ini akan mempengaruhi error term
7. Fenomena CobWeb Jika pada akhir t, harga pertanian saat t lebih kecil dibanding t-1, maka
supply pertanian saat t+1 lebih kecil dibandng saat t. Sehingga , error pada saat t (ut), tidak akan random, karena jika petani memproduksi hasil pertanian berlebih (overproduce) pada saat t, maka mereka akan mengurangi poduksi saat t+1, sehingga membentuk pola Cobweb.

Konsekuensi Adanya Autokorelasi
1. Estimasi OLS tetap linear dan tidak bias namun tidak lagi efisien/BLUE (variannya tidak minimum).
2. Interval keyakinan akan semakin lebar, menyebabkan kita menerima hipotesa H0 (koefisien tidak signifikan).
3. R2 juga akan over estimate.
4. t-stat dan F-ratio akan tidak valid; yang jika digunakan akan menyebabkan kesimpulan yang salah.
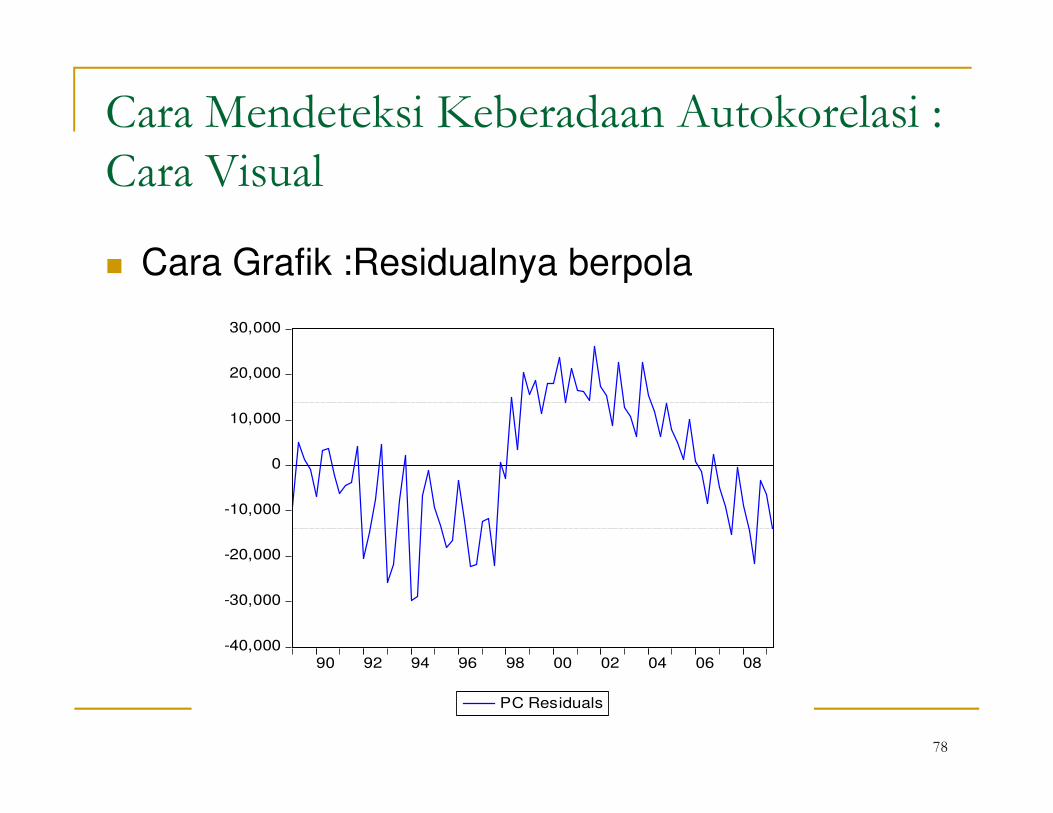
78
Cara Mendeteksi Keberadaan Autokorelasi :
Cara Visual
� Cara Grafik :Residualnya berpola
-40,000
-30,000
-20,000
-10,000
0
10,000
20,000
30,000
90 92 94 96 98 00 02 04 06 08
PC Residuals

79
Cara Mendeteksi Keberadaan Autokorelasi:
DW test
Durbin Watson Test
H0: No Autocorrelation
H1: Autocorrelation
Terdapat
Autokorelasi
Positif
Inconclusiv
e
Interval
Ho diterima
Tidak ada
Autokorelasi
Inconclusive
Interval
Terdapat
Autokorelasi
Negatif
(dl) (du) 2 (4-du) (4-dl)
Jika nilai Durbin-Watson Statistik terletak diantara nilai (du) dan (4-du) maka tidak terdapat autokorelasi di dalam model. Nilai dl dan du didapat dari tabel statistik Durbin-Watson dengan significance level tertentu (biasanya 5%) dan degree of freedom (didasarkan dari besarnya sampel dikurang dengan jumlah parameter yang diestimasi di dalam model). Simple Rule of Thumb: Jika nilai Durbin Watson statistik ada disekitar angka dua maka tidak terdapat autokorelasi di dalam model

80
Cara Mendeteksi Keberadaan Autokorelasi :
BG-test
� The Breusch-Godfrey
(BG) Test
Digunakan Jika model regresi
yang kita gunakan terdapat
unsur lag variabel dependen
pada variabel
independennya, maka nilai
Durbin Watson statistik ini
tidak valid lagi. Jika ini terjadi
gunakan tes statistik lain
untuk mencek autokorelasi
(misal dengan BG-test).
Breusch-Godfrey Serial Correlation LM Test: F-statistic 46.76927 Prob. F(2,78) 0.0000
Obs*R-squared 44.71392 Prob. Chi-Square(2) 0.0000
Test Equation:
Dependent Variable: RESID
Method: Least Squares
Date: 03/09/10 Time: 14:07
Sample: 1989Q1 2009Q2
Included observations: 82
Presample missing value lagged residuals set to zero. Variable Coefficient Std. Error t-Statistic Prob. C 1761.852 4606.631 0.382460 0.7032
PDB -0.005328 0.012476 -0.427027 0.6705
RESID(-1) 0.552783 0.110516 5.001831 0.0000
RESID(-2) 0.239940 0.110732 2.166864 0.0333 R-squared 0.545292 Mean dependent var -3.87E-11
Adjusted R-squared 0.527803 S.D. dependent var 13867.13
S.E. of regression 9529.023 Akaike info criterion 21.20962
Sum squared resid 7.08E+09 Schwarz criterion 21.32702
Log likelihood -865.5945 Hannan-Quinn criter. 21.25676
F-statistic 31.17951 Durbin-Watson stat 2.100832
Prob(F-statistic) 0.000000

Treatment Autokorelasi: Kasus A:
Saat struktur autokorelasi diketahui.
Misalkan kita ketahui hubungan antara gangguan memiliki pola first-order
autoregressive: dan kita mengetahui nilai
Misalkan kita memiliki model pada saat t:
dan model juga dianggap berlaku hingga periode t-1. (inertia effect)
Dengan mengalikan model dengan , maka model untuk periode t-1 adalah:
Dengan melakukan first differences:

Treatment Autokorelasi… cont’d
Persamaan diatas dapat ditulis ulang menjadi
Dimana :
dan
Ketika kita telah mentransformasikan model seperti diatas,
maka kita dapat melakukan regresi OLS dan estimator yang kita
dapatkan akan BLUE.

Treatment Autokorelasi; Kasus B : tidak diketahui.
1. Gunakan perhitungan DW stat untuk mengestimasi
Ingat bahwa
Dengan mengubah menjadi: maka dapat diestimasi.
Sehingga model ideal dapat diubah;
� Langkah 1: Lakukan regresi OLS dan dapatkan perhitungan DW stat.
� Langkah 2: Gunakan perhitungan DW stat untuk menghitung
� Langkah 3: Gunakan untuk mentransformasikan model ideal kita:
� Langkah 4: Gunkana OLS untuk menduga model yang telah

Treatment Autokorelasi; Kasus B : tidak diketahui.
Alternatif lain : Gunakan Cochrane Orcutt iterative (2 step) procedure untuk
mengestimasi
Misalkan kita memiliki model berikut beserta Struktur AR(1) :
dimana
Langkah 1: Resgresikan model dengan OLS. Dapatkan nilai residual
Langkah 2: Gunakan residual yang kita peroleh untuk membuat lag residual,
Lalu estimasikan

Treatment Autokorelasi; Kasus B :
tidak diketahui.
Sekarang kita menggunakan untuk mengestimasi
model first difference sebagai berikut:
Kita harus mentransformasikan model diatas menjadi
variable baru dan lalu kita bisa regresikan dengan OLS

SELESAI
TERIMA KASIH
86







