
LEARNINGARTIFICIAL INTELLIGENT
Dr. Muljono, S.Si, M. Kom

Outline
Decision tree learning
Jaringan Syaraf Tiruan
K-Nearest Neighborhood
Naïve Bayes

Decision Tree Learning :
Klasifikasi untuk penerimaan pegawai baru
merupakan salah satu studi kasus yang akan
dijabarkan. Dimana terdapat 11 orang yang
mengikuti tes penerimaan pegawai baru dengan
menggunakan 3 parameter atau atribut penilaian
sebagai berikut:
IPK dikatagorikan (Bagus, Cukup, Kurang)
Psikologi dikatagorikan (Tinggi, Sedang, Rendah)
Wawancara dikatagorikan (Baik, Buruk)
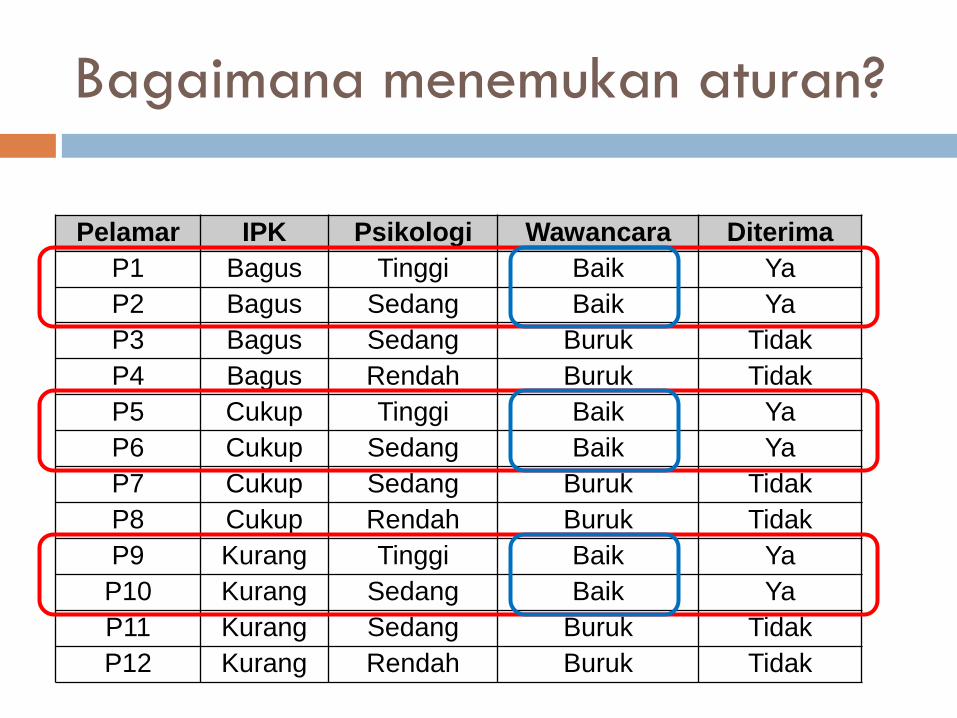
Bagaimana menemukan aturan?
Pelamar IPK Psikologi Wawancara Diterima
P1 Bagus Tinggi Baik Ya
P2 Bagus Sedang Baik Ya
P3 Bagus Sedang Buruk Tidak
P4 Bagus Rendah Buruk Tidak
P5 Cukup Tinggi Baik Ya
P6 Cukup Sedang Baik Ya
P7 Cukup Sedang Buruk Tidak
P8 Cukup Rendah Buruk Tidak
P9 Kurang Tinggi Baik Ya
P10 Kurang Sedang Baik Ya
P11 Kurang Sedang Buruk Tidak
P12 Kurang Rendah Buruk Tidak
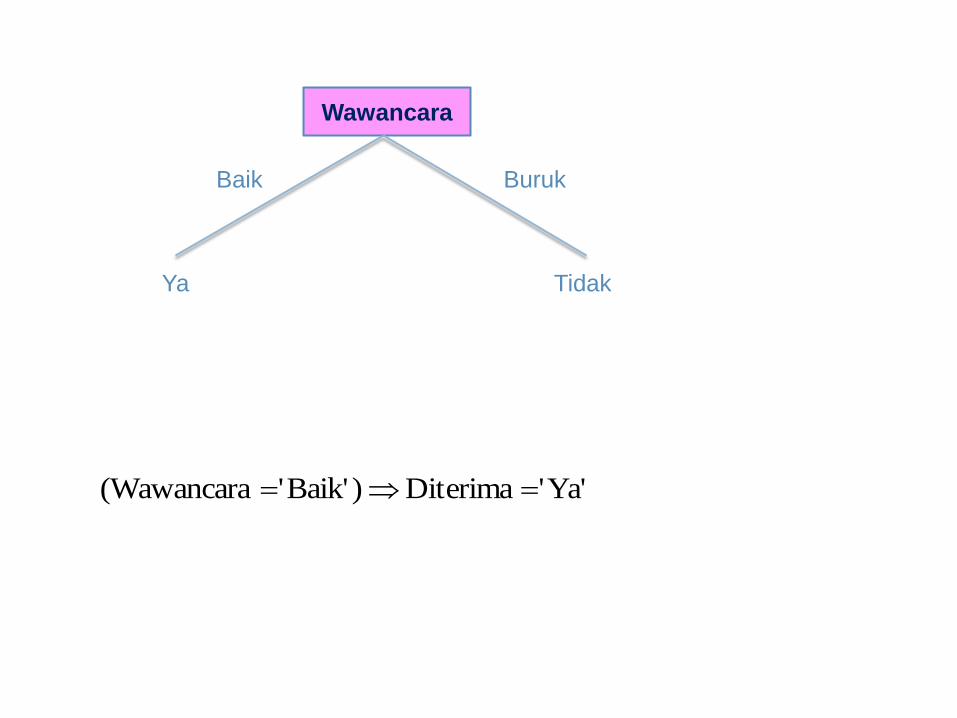
Wawancara
Baik
Ya
Buruk
Tidak
Ya''Diterima)Baik''(Wawancara
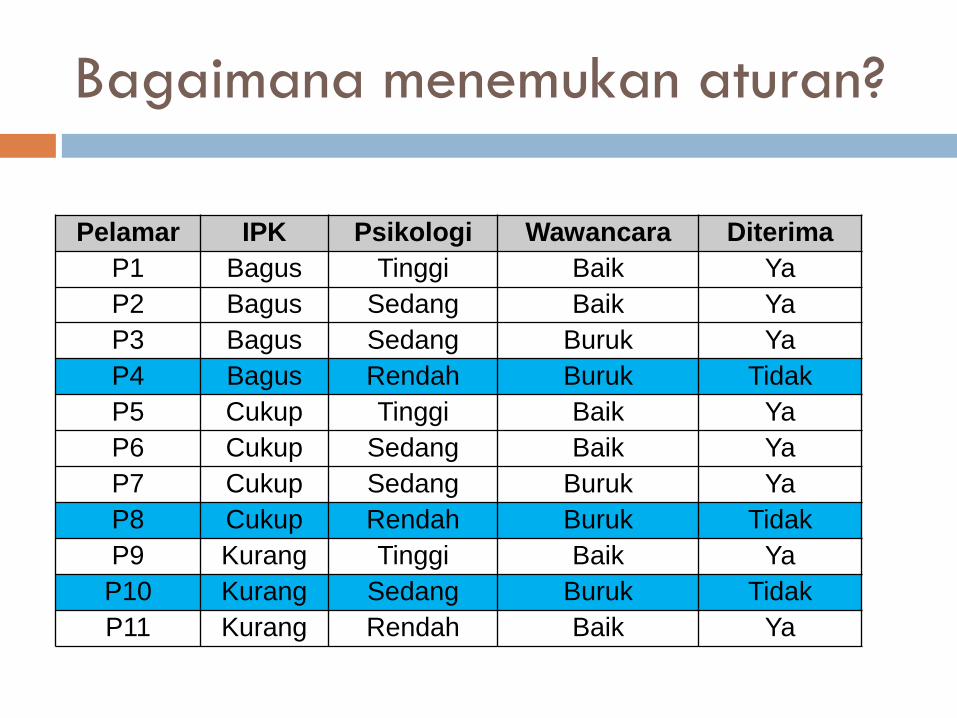
Pelamar IPK Psikologi Wawancara Diterima
P1 Bagus Tinggi Baik Ya
P2 Bagus Sedang Baik Ya
P3 Bagus Sedang Buruk Ya
P4 Bagus Rendah Buruk Tidak
P5 Cukup Tinggi Baik Ya
P6 Cukup Sedang Baik Ya
P7 Cukup Sedang Buruk Ya
P8 Cukup Rendah Buruk Tidak
P9 Kurang Tinggi Baik Ya
P10 Kurang Sedang Buruk Tidak
P11 Kurang Rendah Baik Ya
Bagaimana menemukan aturan?
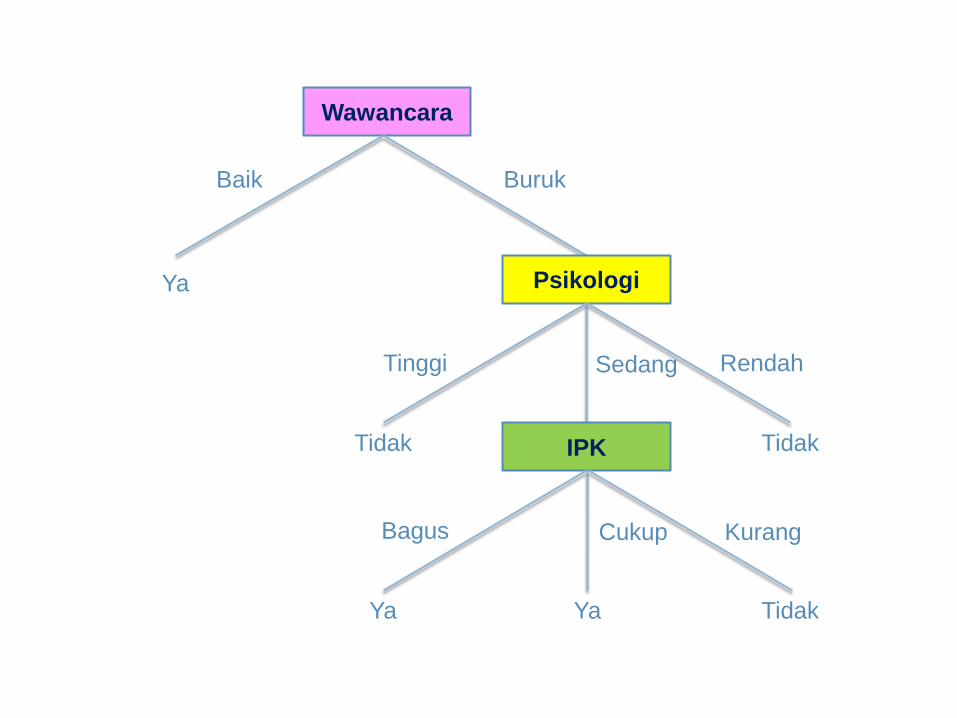
Wawancara
Baik
Ya
Buruk
Psikologi
Tinggi
Tidak
Sedang
IPK
Bagus
Ya
Cukup
Ya
Kurang
Tidak
Rendah
Tidak

Rule
''
))''()''()''((
))''()''()''((
)''(
YaDiterima
CukupIPKSedangPsikologiBurukWawancara
BagusIPKSedangPsikologiBurukWawancara
BaikWawancara

Masalah
Data tidak lengkap
IPK : 3 kemungkinan nilai
Psikologi: 3 kemungkinan nilai
Wawancara: 2 kemungkinan nilai
Data lengkap = 3 x 3 x 2 = 18 records
Aturan yang men-generalisasi unseen data?

Learning
Bagaimana untuk data yang sangat banyak?
Bagaimana menemukan aturan?
Bagaimana jika datanya tidak lengkap?
Aturan yang general untuk data yang akan
datang?
Menemukan perbedaan dari dua hal yang mirip?
Menemukan kesamaan dari dua hal yang
berbeda?

Data penerimaan pegawai baru
Pelamar IPK Psikologi Wawancara Diterima
P1 Bagus Tinggi Baik Ya
P2 Bagus Sedang Baik Ya
P3 Bagus Sedang Buruk Ya
P4 Bagus Rendah Buruk Tidak
P5 Cukup Tinggi Baik Ya
P6 Cukup Sedang Baik Ya
P7 Cukup Sedang Buruk Ya
P8 Cukup Rendah Buruk Tidak
P9 Kurang Tinggi Baik Ya
P10 Kurang Sedang Buruk Tidak
P11 Kurang Rendah Baik Ya


Langkah Pertama
Tentukan akar dari pohon, akar atau node
awal akan diambil dari atribut yang dipilih,
dengan cara menghitung kemudian memilih
informasi gain tertinggi dari masing-masing
atribut.
Namun sebelum menghitung gain dari atribut,
harus dihitung dulu nilai entropy dari setiap
tupel.
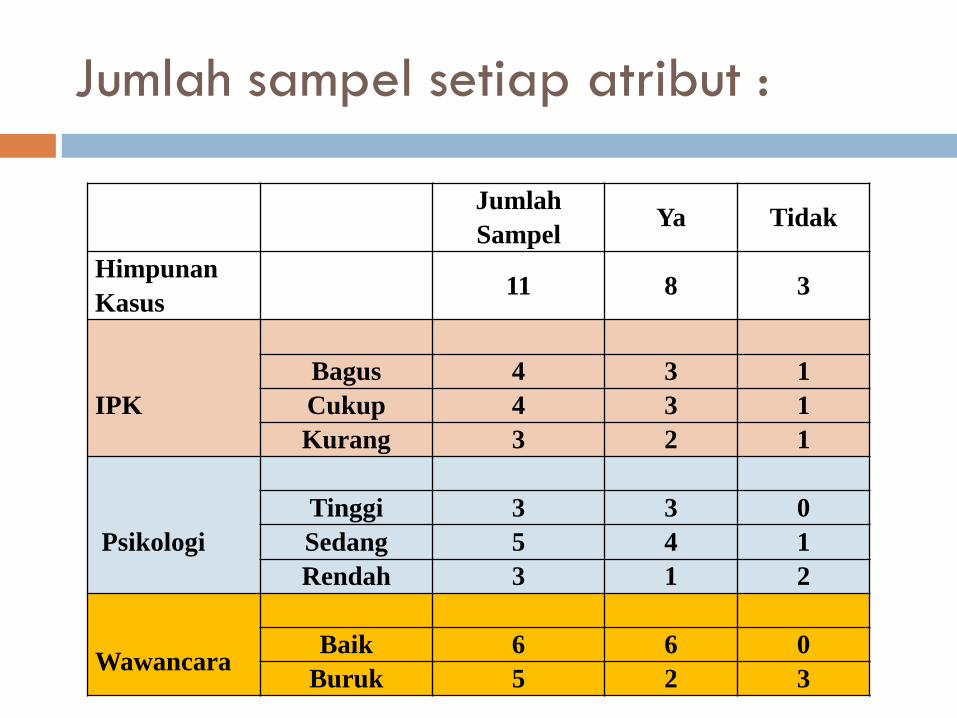
Jumlah sampel setiap atribut :
Jumlah
SampelYa Tidak
Himpunan
Kasus11 8 3
IPK
Bagus 4 3 1
Cukup 4 3 1
Kurang 3 2 1
Psikologi
Tinggi 3 3 0
Sedang 5 4 1
Rendah 3 1 2
WawancaraBaik 6 6 0
Buruk 5 2 3

Menghitung Entropy
Perhitungan untuk mencari nilai Entropy dari setiap
tupel atribut masing-masing
Entropy
Parameter untuk mengukur heterogenitas
(keberagaman) dari kumpulan sampel data.
Jika kumpulan sampel data semakin heterogen,
maka nilai entropy-nya semakin besar.
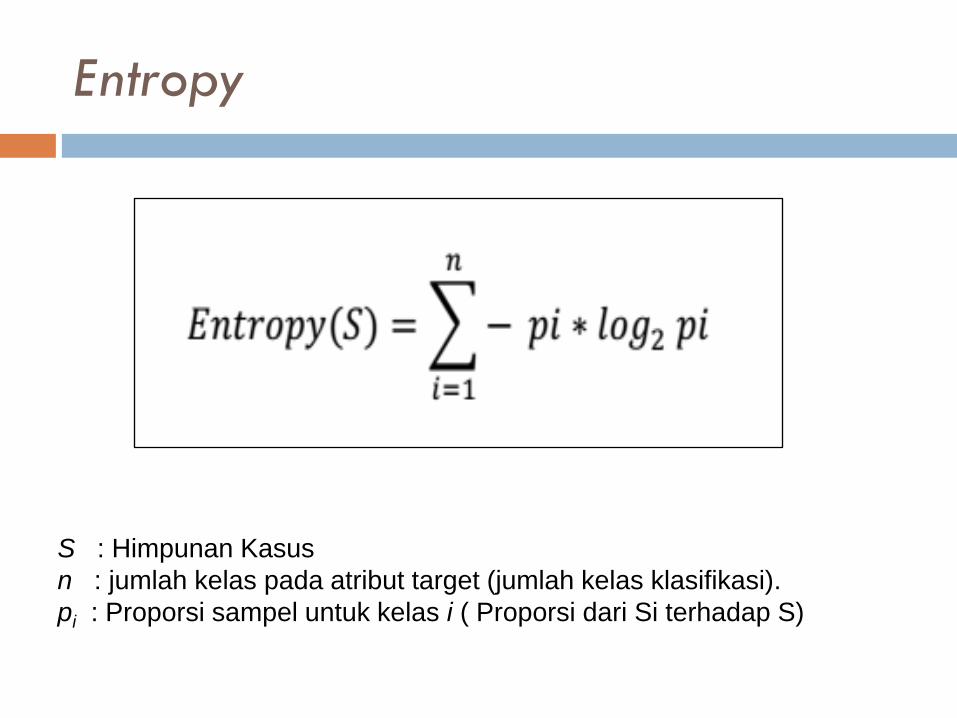
Entropy
S : Himpunan Kasus
n : jumlah kelas pada atribut target (jumlah kelas klasifikasi).
pi : Proporsi sampel untuk kelas i ( Proporsi dari Si terhadap S)

Jumlah sampel setiap atribut :
Jumlah
SampelYa Tidak
Himpunan
Kasus11 8 3
IPK
Bagus 4 3 1
Cukup 4 3 1
Kurang 3 2 1
Psikologi
Tinggi 3 3 0
Sedang 5 4 1
Rendah 3 1 2
WawancaraBaik 6 6 0
Buruk 5 2 3

Entropy (Total-Kelas)

Entropy IPK-Bagus

Entropy IPK-Cukup

Entropy IPK-Kurang

Entropy Psikologi-Tinggi

Entropy Psikologi-Sedang

Entropy Psikologi-Rendah
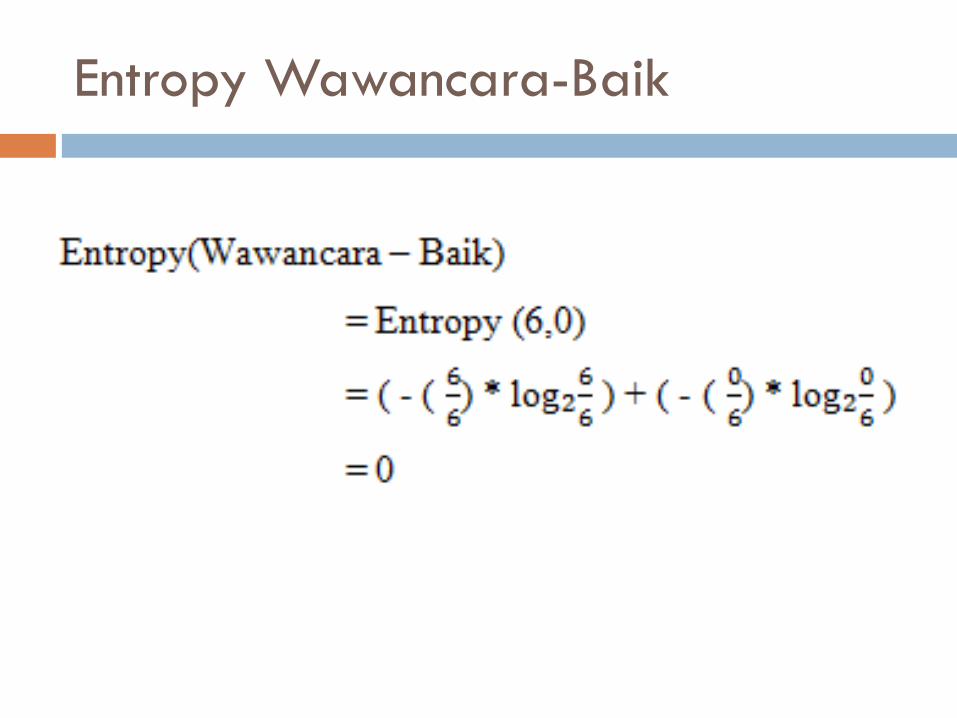
Entropy Wawancara-Baik

Entropy Wawancara-Buruk

Menghitung Information Gain (IG)
Efektivitas atribut dalam mengklasifikasikan data
Dihitung berdasarkan entropy
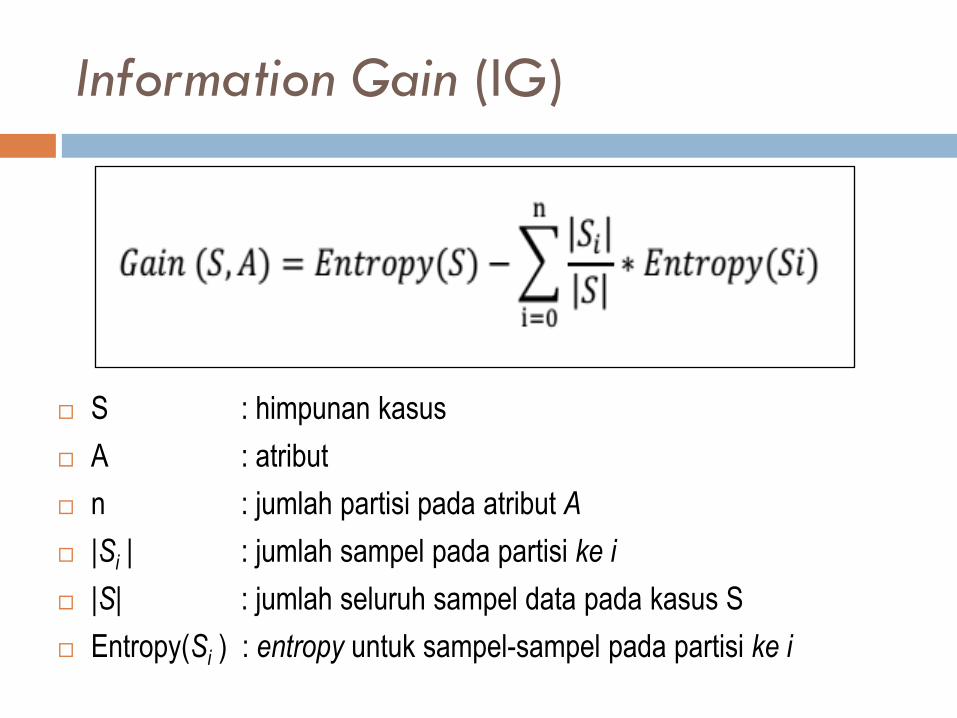
Information Gain (IG)
S : himpunan kasus
A : atribut
n : jumlah partisi pada atribut A
|Si | : jumlah sampel pada partisi ke i
|S| : jumlah seluruh sampel data pada kasus S
Entropy(Si ) : entropy untuk sampel-sampel pada partisi ke i

IG untuk IPK

IG untuk Psikologi

IG untuk Wawancara
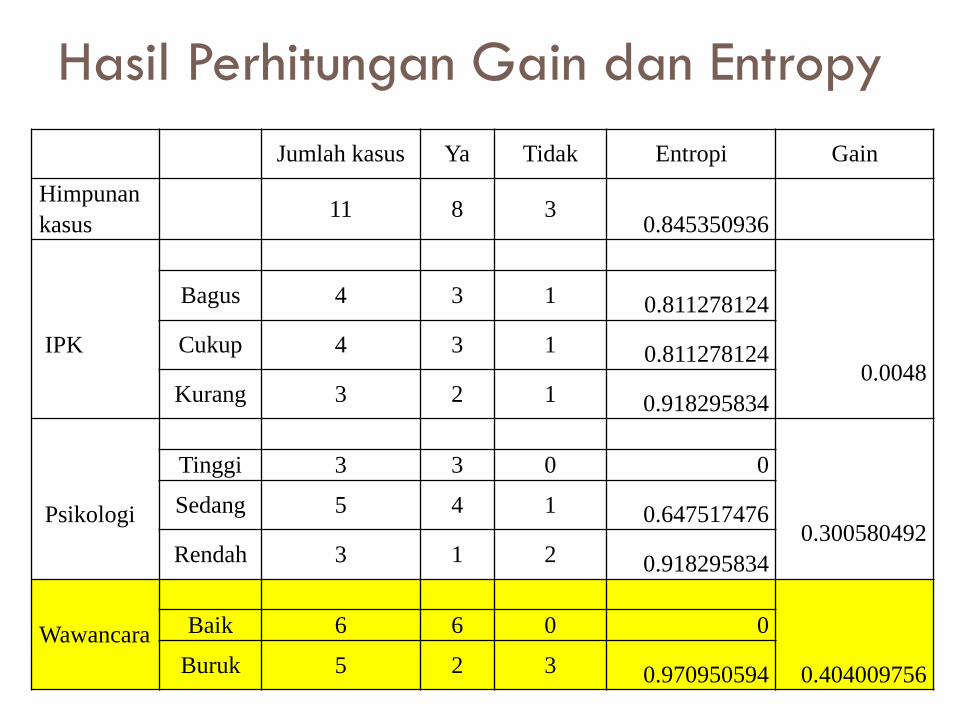
Hasil Perhitungan Gain dan Entropy
Jumlah kasus Ya Tidak Entropi Gain
Himpunan
kasus11 8 3
0.845350936
IPK
0.0048
Bagus 4 3 1 0.811278124
Cukup 4 3 1 0.811278124
Kurang 3 2 1 0.918295834
Psikologi0.300580492
Tinggi 3 3 0 0
Sedang 5 4 1 0.647517476
Rendah 3 1 2 0.918295834
Wawancara
0.404009756
Baik 6 6 0 0
Buruk 5 2 3 0.970950594

Menentukan Root dari Decision Tree
Gain Tertinggi adalah atribut Wawancara
(nilai = 0.404009756), Sehingga Atribut
Wawancara menjadi root dari Decision Tree
Atribut Wawancara (Nilai : Baik dan Buruk)
Nilai : Baik ada 6 kasus “Ya” diterima dan
0 kasus “Tidak” diterima
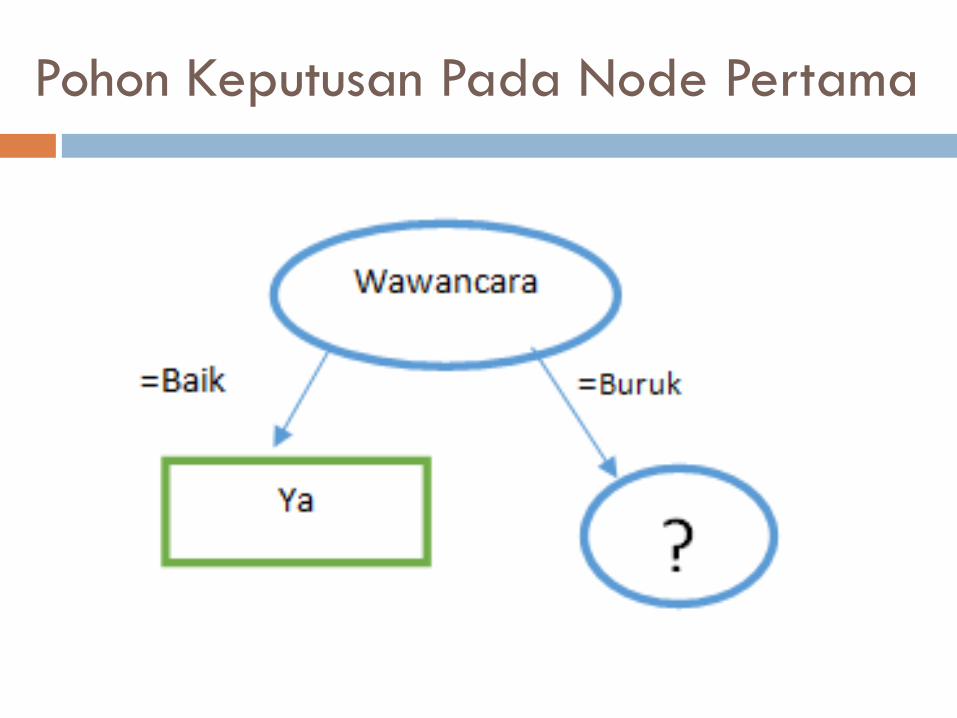
Pohon Keputusan Pada Node Pertama
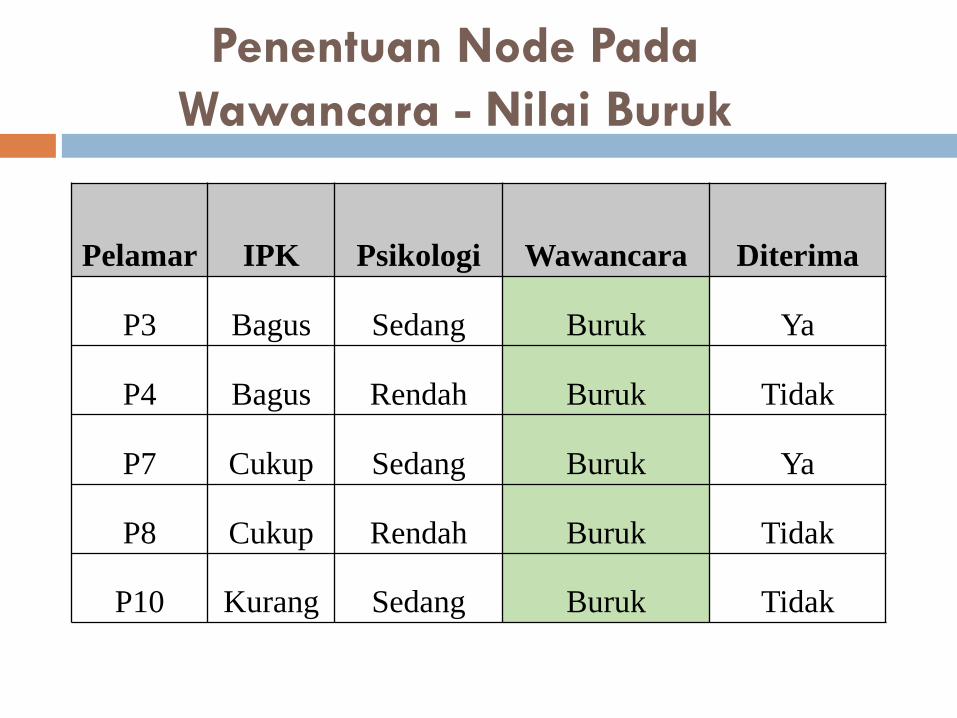
Penentuan Node Pada
Wawancara - Nilai Buruk
Pelamar IPK Psikologi Wawancara Diterima
P3 Bagus Sedang Buruk Ya
P4 Bagus Rendah Buruk Tidak
P7 Cukup Sedang Buruk Ya
P8 Cukup Rendah Buruk Tidak
P10 Kurang Sedang Buruk Tidak

Menghitung Entropy dari
Wawancara - nilai “Buruk”

Entropy IPK-Bagus

Entropy IPK-Cukup

Entropy IPK-Kurang

Entropy Psikologi-Sedang

Entropy Psikologi-Rendah

Menghitung Gain dari nilai “Buruk”
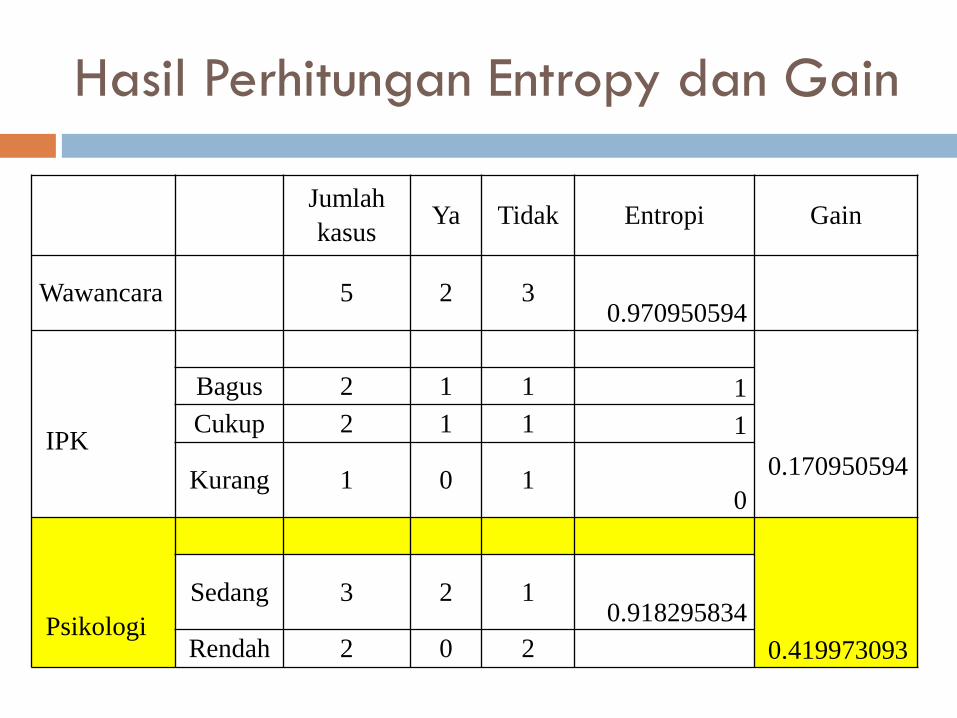
Hasil Perhitungan Entropy dan Gain
Jumlah
kasusYa Tidak Entropi Gain
Wawancara 5 2 30.970950594
IPK0.170950594
Bagus 2 1 1 1
Cukup 2 1 1 1
Kurang 1 0 10
Psikologi0.419973093
Sedang 3 2 10.918295834
Rendah 2 0 2

Penentuan Node Lanjutan
Gain tertinggi adalah Psikologi sebesar
0.419973093 atribut Psikologi dapat menjadi
node lanjutan dari atribut Wawancara – Buruk
Atribut Psikologi (Nilai : Sedang dan Rendah)
Nilai : Rendah ada 2 kasus “Tidak” diterima
dan 0 kasus “Ya” diterima
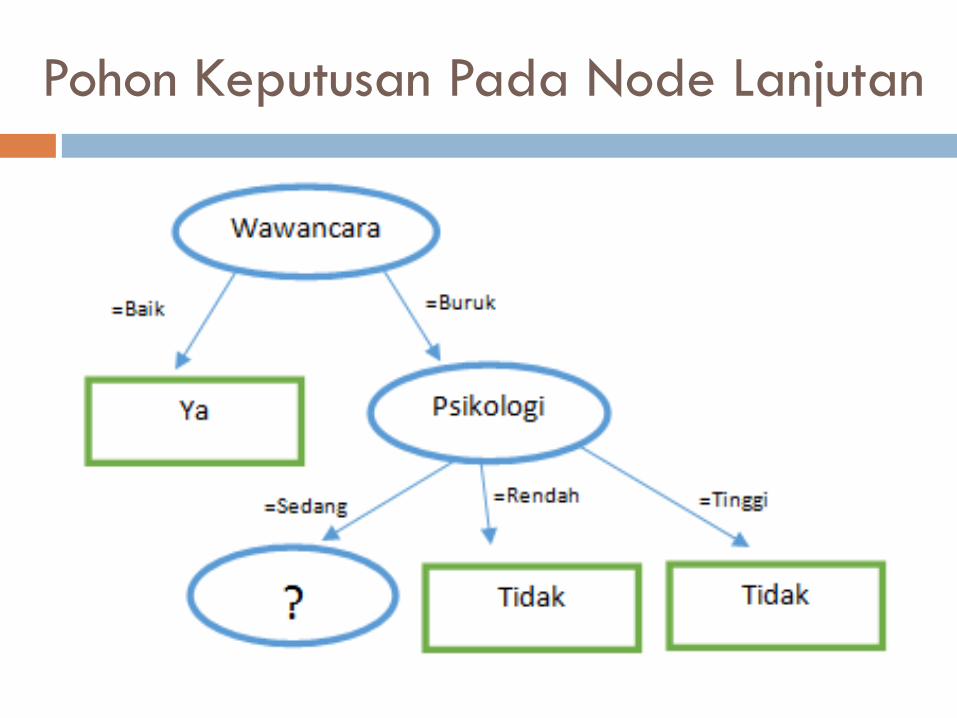
Pohon Keputusan Pada Node Lanjutan
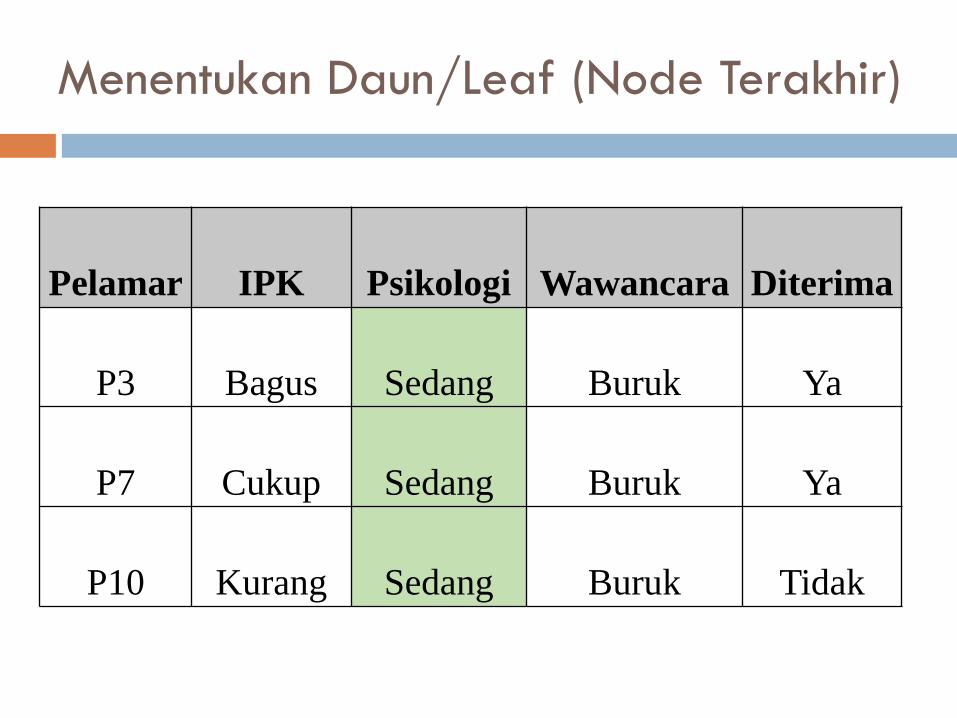
Menentukan Daun/Leaf (Node Terakhir)
Pelamar IPK Psikologi Wawancara Diterima
P3 Bagus Sedang Buruk Ya
P7 Cukup Sedang Buruk Ya
P10 Kurang Sedang Buruk Tidak

Menentukan Daun/Leaf (Node Terakhir)
Tanpa menghitung nilai Entropy dan Gain
Hal ini dikarenakan, untuk nilai Psikologi – Sedang,
hanya didapati sisa 3 cabang dan langsung
melengkapi yang kurang
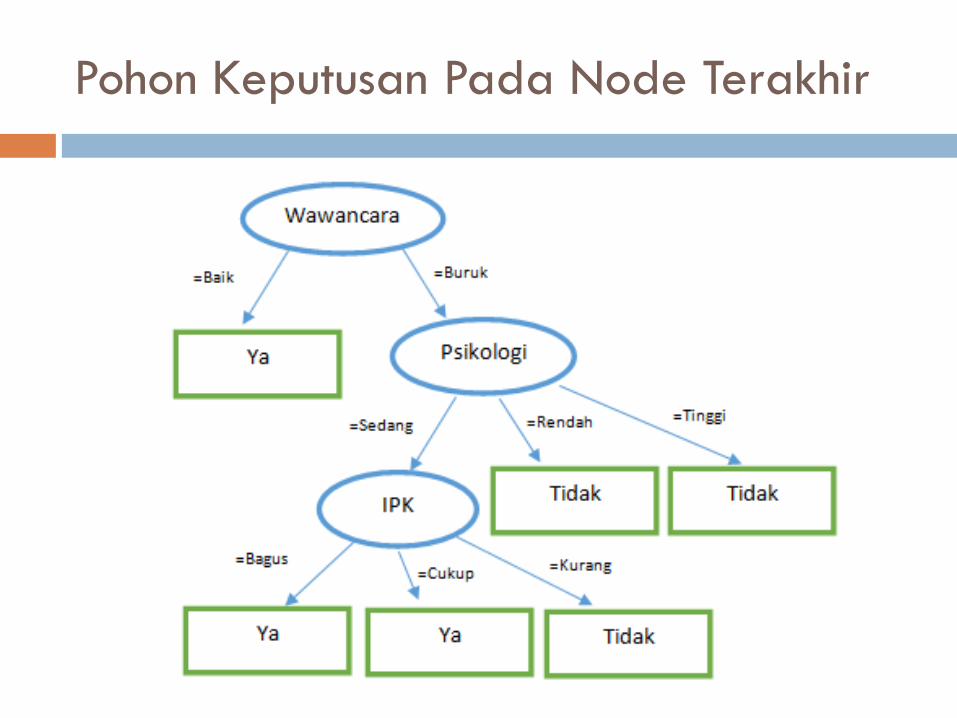
Pohon Keputusan Pada Node Terakhir

Atruan (Rule)
“JIKA wawancara = baik MAKA diterima”
“JIKA wawancara = buruk AND psikologi = sedang AND ipk = bagus MAKA diterima”
“JIKA wawancara = buruk AND psikologi = sedang AND ipk = cukup MAKA diterima”
“JIKA wawancara = buruk AND psikologi = sedang AND ipk = kurang MAKA ditolak”
“JIKA wawancara = buruk AND psikologi = rendah MAKA ditolak”
“JIKA wawancara = buruk AND psikologi = tinggi MAKA ditolak”

Aturan (Rule)
''
))''()''()''((
))''()''()''((
)''(
YaDiterima
CukupIPKSedangPsikologiBurukWawancara
BagusIPKSedangPsikologiBurukWawancara
BaikWawancara

Diskusi
Jika terdapat dua atribut dengan IG yang sama?
Jika ada data yang sama tetapi kelasnya
berbeda?
Berapa jumlah learning data minimum?
Imbalance Class?

Dua atribut dengan IG sama ?
Gain(S,IPK) = 0,0049
Gain(S,Psikologi) = 0,4040
Gain(S,Wawancara) = 0,4040
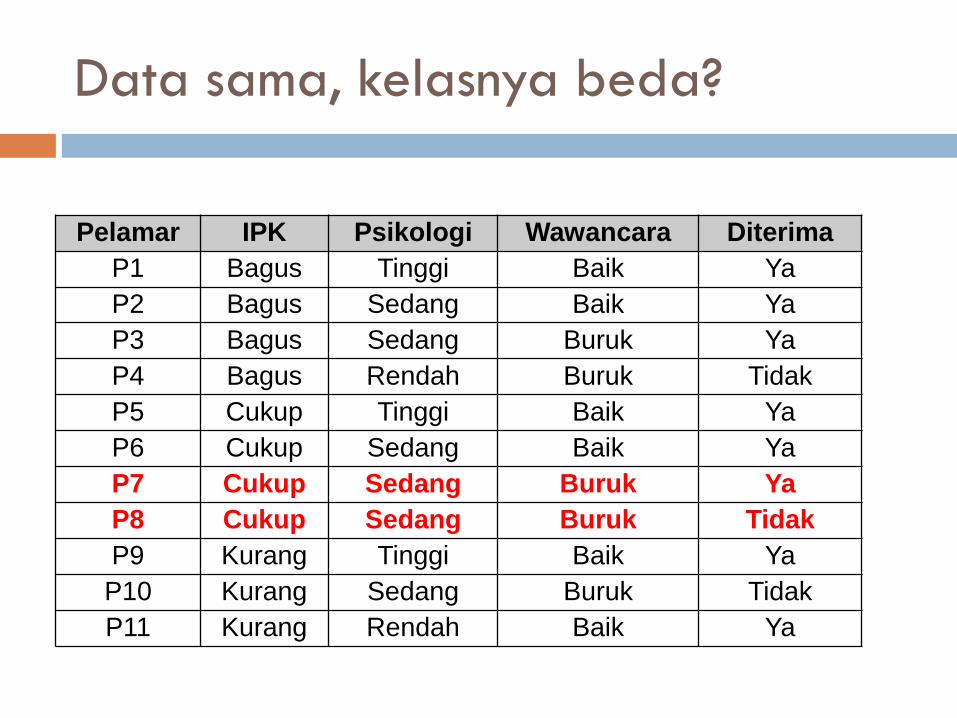
Data sama, kelasnya beda?
Pelamar IPK Psikologi Wawancara Diterima
P1 Bagus Tinggi Baik Ya
P2 Bagus Sedang Baik Ya
P3 Bagus Sedang Buruk Ya
P4 Bagus Rendah Buruk Tidak
P5 Cukup Tinggi Baik Ya
P6 Cukup Sedang Baik Ya
P7 Cukup Sedang Buruk Ya
P8 Cukup Sedang Buruk Tidak
P9 Kurang Tinggi Baik Ya
P10 Kurang Sedang Buruk Tidak
P11 Kurang Rendah Baik Ya

Jumlah learning data ?
Masalah Sentiment Analysis atau Email Spam Filtering
200.000 kata
Masing-masing kata muncul 0 – 100 kali
Training data: 10.000 postingan atau email

Imbalance Class?
Data latih untuk tiap kelas tidak seimbang
Terutama untuk kasus data kesehatan (rekam medis)
Misalnya: klasifikasi penyakit

Daftar Pustaka
Suyanto. 2007. Artificial Intelligence: Searching, Reasoning, Planning and
Learning. Informatika, Bandung Indonesia. ISBN: 979-1153-05-1.
Russel, Stuart and Norvig, Peter. 1995. Artificial Intelligence: A Modern
Approach. Prentice Hall International, Inc.







