47802574 mengukur efektifitas komputasi paralel melalui implementasi program prime sum
TRANSCRIPT

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-p
Mengukur Efektifitas Komputasi Paralel
melalui Implementasi Program Prime Sum,
Simpson Rule dan Merge Sort dengan
menggunakan MPICH2
Untuk Memenuhi Tugas UTS Mata Kuliah Kapita Selekta
Disusun oleh
Aji Gojali 107091003188
Dimas Riyan Hartadi 107091003148
Restyo Mahendra 107091003630
Riko Dwi Masetya107091003326
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UIN SYARIF HIDAYATULLAH JAKARTA

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-p
2010
InstalasiA. Persiapan
MPICH memerlukan sistem operasi dan beberapa program lain untuk
brjalan. Sistem
yang diperlukan haruslah terlebih dulu ada sebelum MPICH di-install.
Adapun kebutuhan
sistem tersebut antara lain:
1. sistem Operasi Windows 2000/XP/2003
2. Visual C++ 2005 dengan IDE Visual Studio 2005 (dalam laporan ini,
digunakan Visual C++ 2005 Express Edition)
B. Instalasi MPI
Setelah kebutuhan instalasi MPICH2 terpenuhi, dilakukan instalasi
MPICH2,
1. Klik ganda pada file setup MPICH2 yang telah didownload, sehingga
akan mucul screenshot sebagai berikut:
2. Setelah muncul screenshot seperti di atas, klik Next, sehingga
akan muncul jendela yang menampilkan kebutuhan system seperti

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-p
berikut:
3. Selanjutnya akan muncul jendela yang menampilkan hak cipta dan
persetujuan lisensi. Pilih radio button “I Agree”, kemudian klik next.
4. Kemudian, muncul jendela Process Manager Setup. Di dalam
jendela ini terdapat pemberitahuan untuk mengingat kata
kunci atau passphrase yang akan digunakan untuk menjalankan
service SPMD. SPMD merupakan process manager yang berjalanbaik pada Unix maupun Windows. SPMD mampu menjalankan
proses dari berbagai platform jika format binernya sama.
Passphrase yang sama pada MPICH harus digunakan untuk semua
komputer.
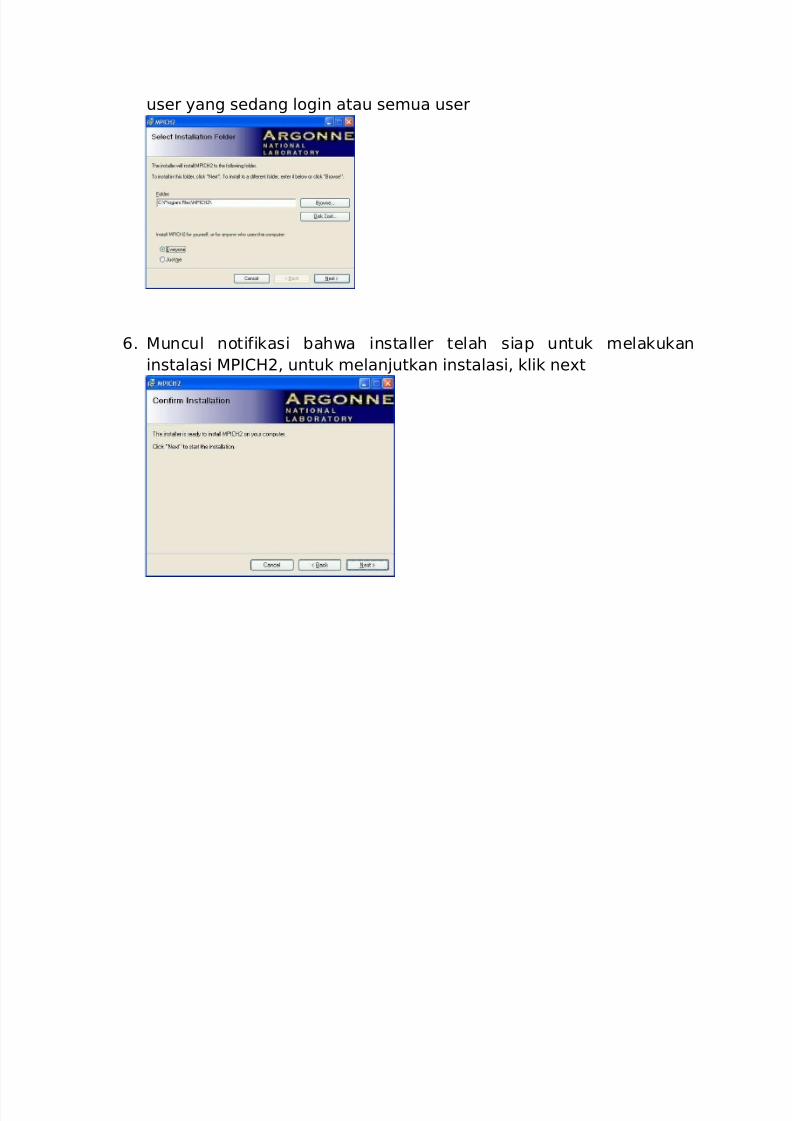
5. Berikutnya, tentukan direktori dimana kita akan meng-install
MPICH2. Jika tidak diberikan, secara default installer MPICH2
akan meletakkannya di C:\Program Files\MPICH2\. Tentukan juga
siapa yang bisa menggunakan MPICH pada komputer, hanya
5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-p
user yang sedang login atau semua user
6. Muncul notifikasi bahwa installer telah siap untuk melakukan
instalasi MPICH2, untuk melanjutkan instalasi, klik next

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-p
C. Konfigurasi
1. Pertama, dibuat projek melalui File – New – Project. Berikan nama
projek, dalam hal ini, misalnya MPI_Hello.
2. Selanjutnya, Klik OK. Pada window Win32 Application Wizard, klik
Next.
5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-p
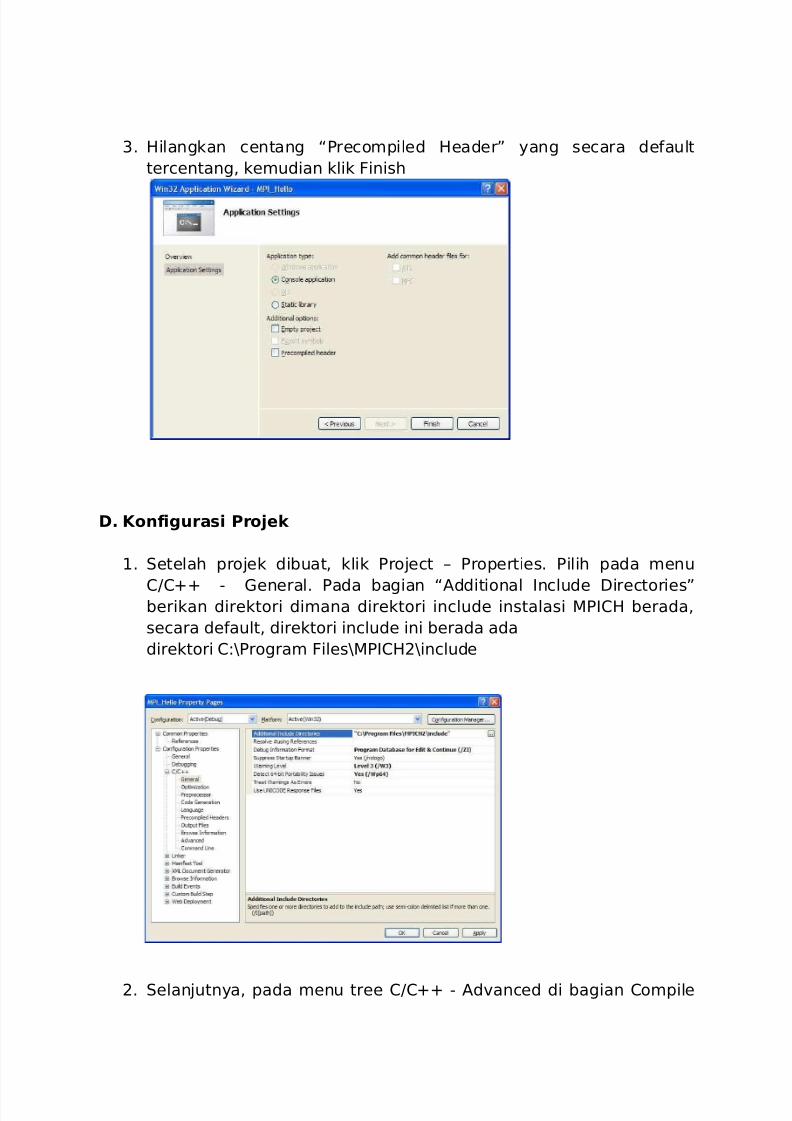
3. Hilangkan centang “Precompiled Header” yang secara default
tercentang, kemudian klik Finish
D. Konfigurasi Projek
1. Setelah projek dibuat, klik Project – Properties. Pilih pada menu
C/C++ - General. Pada bagian “Additional Include Directories”berikan direktori dimana direktori include instalasi MPICH berada,
secara default, direktori include ini berada ada
direktori C:\Program Files\MPICH2\include
2. Selanjutnya, pada menu tree C/C++ - Advanced di bagian Compile
5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-p
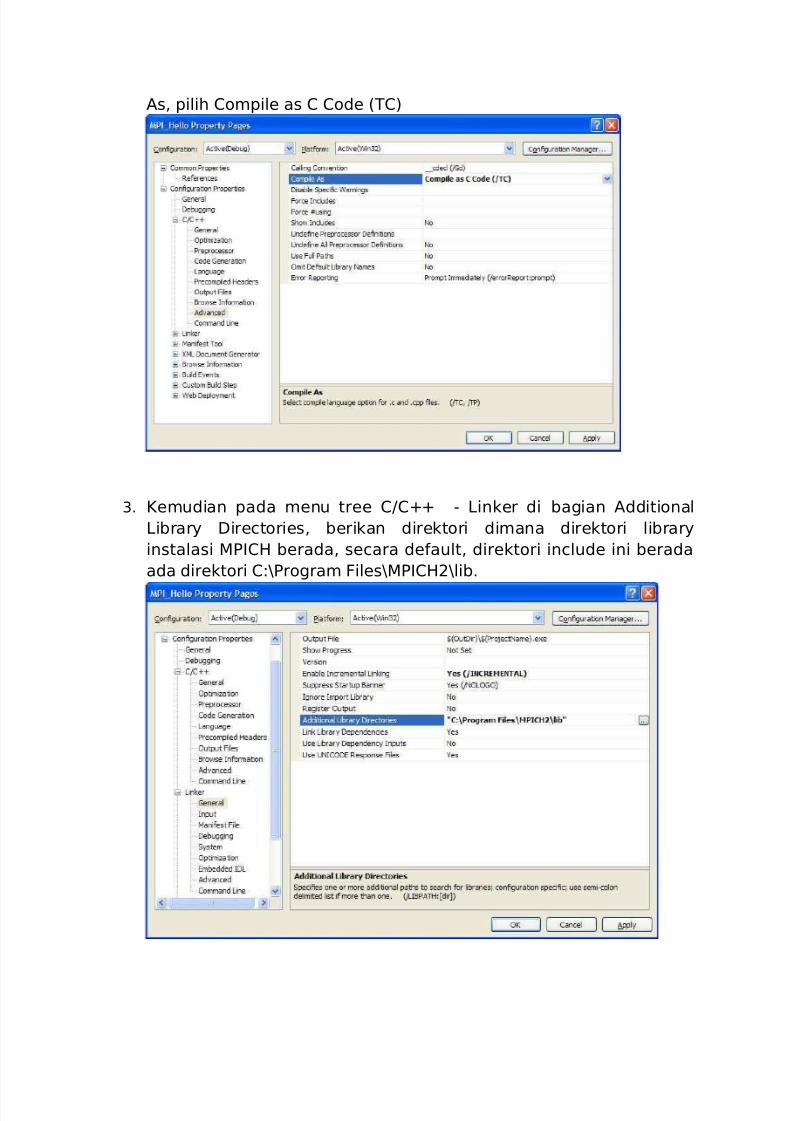
As, pilih Compile as C Code (TC)
3. Kemudian pada menu tree C/C++ - Linker di bagian Additional
Library Directories, berikan direktori dimana direktori library
instalasi MPICH berada, secara default, direktori include ini berada
ada direktori C:\Program Files\MPICH2\lib.
5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-p
4. Langkah terakhir, pada bagian additional dependencies, tambahkan
mpi.lib.
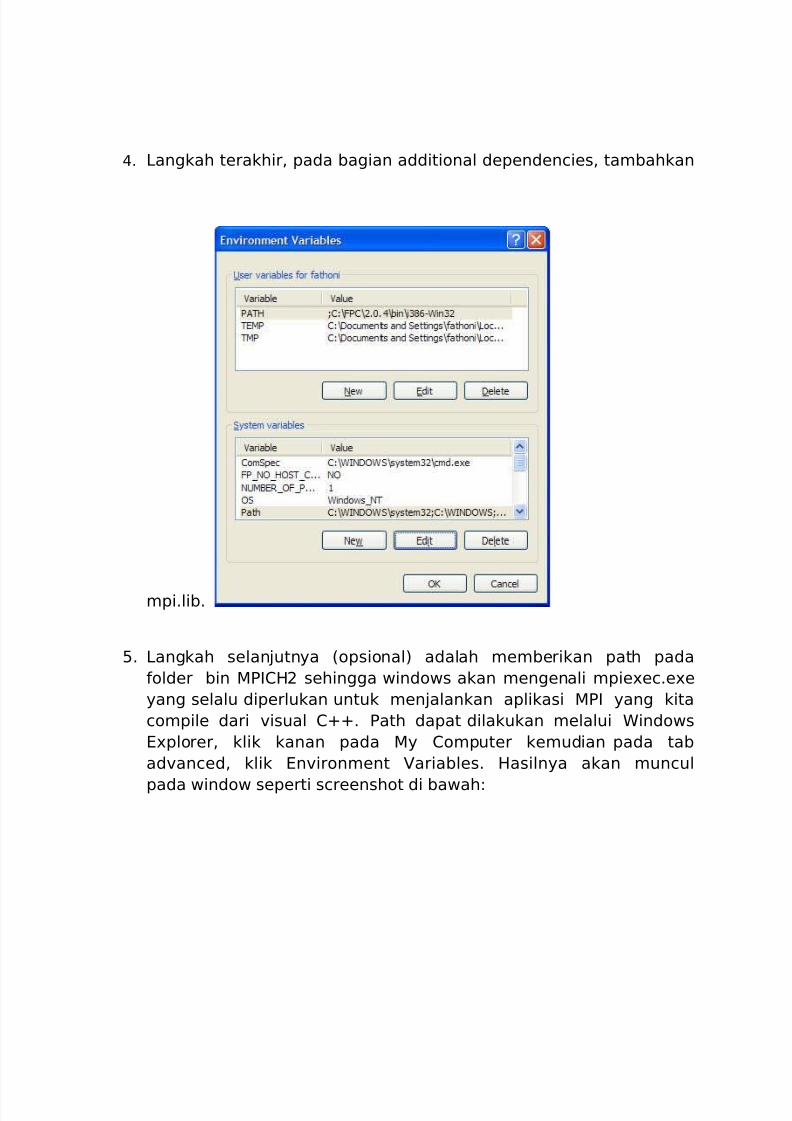
5. Langkah selanjutnya (opsional) adalah memberikan path pada
folder bin MPICH2 sehingga windows akan mengenali mpiexec.exe
yang selalu diperlukan untuk menjalankan aplikasi MPI yang kita
compile dari visual C++. Path dapat dilakukan melalui Windows
Explorer, klik kanan pada My Computer kemudian pada tab
advanced, klik Environment Variables. Hasilnya akan muncul
pada window seperti screenshot di bawah:

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-p
6. Pada bagian system variables – Path, klik bagian edit, dan
tambahkan direktori bin dari MPICH pada bagian Variable Value.
Secara default, direktori bin berada pada C:\Program
Files\MPICH2\bin.

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
Prime Sum
A. Introduction
Merupakan sebuah program yang berfungsi untuk melakukan
penjumlahan bilangan prima dengan range 0 sampai n bilangan dan
dilakukan oleh m yang merupakan variabel hosts. Variabel n dan m
nantinya akan di inputkan bersamaan dengan perintah eksekusi
mpiexec.
Contoh :
n = 10
Hosts m=2
Maka
Data bilangan prima sampai dengan n adalah: {2,3,5,7}
Mekanisme:
Data di pecah dalam kedalam beberapa bagian dengan aturan
range=n/m, maka rangenya adalah
(1-5): jumlah bilangan prima {2,3,5} jumlah = 10
(6-10): jumlah bilangan prima jumlah{7} jumlah = 7
dan output :
jumlah= 17
B. Source Code
Berikut ini adalah Source Code dari Prime Sum:
# include <stdio.h>
# include <stdlib.h>
# include "mpi.h"
int main ( int argc, char *argv[] );
/***********************************/
int main ( int argc, char *argv[] )

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
/***********************************/
/*
Tujuan :
Penulis :
John Burkardt
Dimodifikasi oleh :
dimas
aji
riko
restio
Referensi:
William Gropp, Ewing Lusk, Anthony Skjellum,
Using MPI: Portable Parallel Programming with the
Message-Passing Interface,
Second Edition,
MIT Press, 1999,
ISBN: 0262571323.
*/
{
int i;
int id;
int j;
int master = 0;
int n_hi;
int n_lo;
int total; int total_local;
double wtime;
int done = 0;
/*
Inisialisasi MPI
*/
MPI_Init ( &argc, &argv );/*

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
Mendapatkan Jumlah dari proses
*/
MPI_Comm_size ( MPI_COMM_WORLD, &p );
/*
Menentukan Rank dari suatu proses*/
MPI_Comm_rank ( MPI_COMM_WORLD, &id );
/*
Proses pembacaan input data dari argv
*/
if (argc != 2) {
if (id == master)
printf(" Petunjuk: mpiexec -n <jumlah proses> uts.exe
<jumlah data> \n Contoh : mpiexec -n 2 uts.exe 1000 \n");
MPI_Finalize();
exit(0);
}else{
n = atof(argv[1]); //proses inisialisasi data N
}
/*
Sekarang setiap proses (termasuk master) menentukan porsi dari
jangkauan data
mengikuti rumus dibawah ini yang akan membagi jangkauan data dari 2
hingga N
secara merata keseluruh proses
*/n_lo = ( ( p - id ) * 1
+ ( id ) * n )
/ ( p ) + 1;
n_hi = ( ( p - id - 1 ) * 1
+ ( id + 1 ) * n )
/ ( p );
/*
setiap proses menambahkan masukannya*/

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
wtime = MPI_Wtime ( ); //inisialsisasi waktu awal
total_local = 0.0;
for ( i = n_lo; i <= n_hi; i++ )
{prime = 1;
for ( j = 2; j < i; j++ )
{
if ( i % j == 0 )
{
prime = 0;
break;
}
}
if ( prime == 1 )
{
total_local = total_local + i;
}
}
wtime = MPI_Wtime ( ) - wtime;
printf ( " Process %d, Pembagiana Data : %d - %d\tTotal : %d\tTime :
%f\n",
id+ 1, n_lo, n_hi, total_local, wtime );
/*
setiap proses yang bekerja mengirim kembali hasilnya kepada master
*/
if ( id != master )
{
MPI_Send ( &total_local, 1, MPI_INT, master, 1, MPI_COMM_WORLD );
}
/*
Master menginisialisasi jumlah dengan nilai local miliknya
dan kemudian mengirim pesan ke proses yang lain.
*/ else

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
{
total = total_local;
for ( i = 1; i < p; i++ )
{
MPI_Recv ( &total_local, 1, MPI_INT, MPI_ANY_SOURCE, 1,MPI_COMM_WORLD, &status );
total = total + total_local;
}
}
/*
baris perintah diatas dapat saja diganti dengan bari perintah tunggal:
MPI_Reduce ( &total_local, &total, 1, MPI_INT, MPI_SUM, master,
MPI_COMM_WORLD )
yang mengumpulkan seluruh nilai TOTAL_LOCAL kedalam penjumlaha
tunggal yang
dinamakan TOTAL dan mengirimnya ke proses
*/
if ( id == master )
{
printf ( "\n Jumlah Total %d\n", total );
printf ( "PRIME_SUM:\n");
printf ( " Normal end of execution.\n");
}
/*
mematikan MPI.
*/
MPI_Finalize ( );
return 0;
}

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
C. Analisis
ada beberapa teknik dalam mengeksekusi file MPI yang dilakukan
kelompok kami, teknik itu adalah sebagai berikut:
a. Dengan 1 komputer
1. Tidak terhubung ke jaringan
2. Hanya melibatkan 1 host dengan IP Adress 192.168.1.7
3. Pada setiap PC mendaftarkan acount usernya pada
wmpiregister.exe
4. Kemudian jalankan perintah mpiexec hosts 192.168.1.7 aji.exe 100
5. Outputnya adalah sebagai berikut :
6. Dengan 1 komputer host menghasilkan waktu process = 0.000012
detik
b. Dengan 2 komputer
1. Arsitektur jaringan yang kami gunakan pada percobaan program ini
adalah Peer 2 Peer
SYUKUR MPI1
2. Pada analisis ini kami melibatkan 2 komputer sebagai host denganIP Adress sebagai berikut:
5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
MPI1 : 192.168.1.7
SYUKUR : 192.168.1.4
3. Pada setiap PC mendaftarkan acount usernya pada
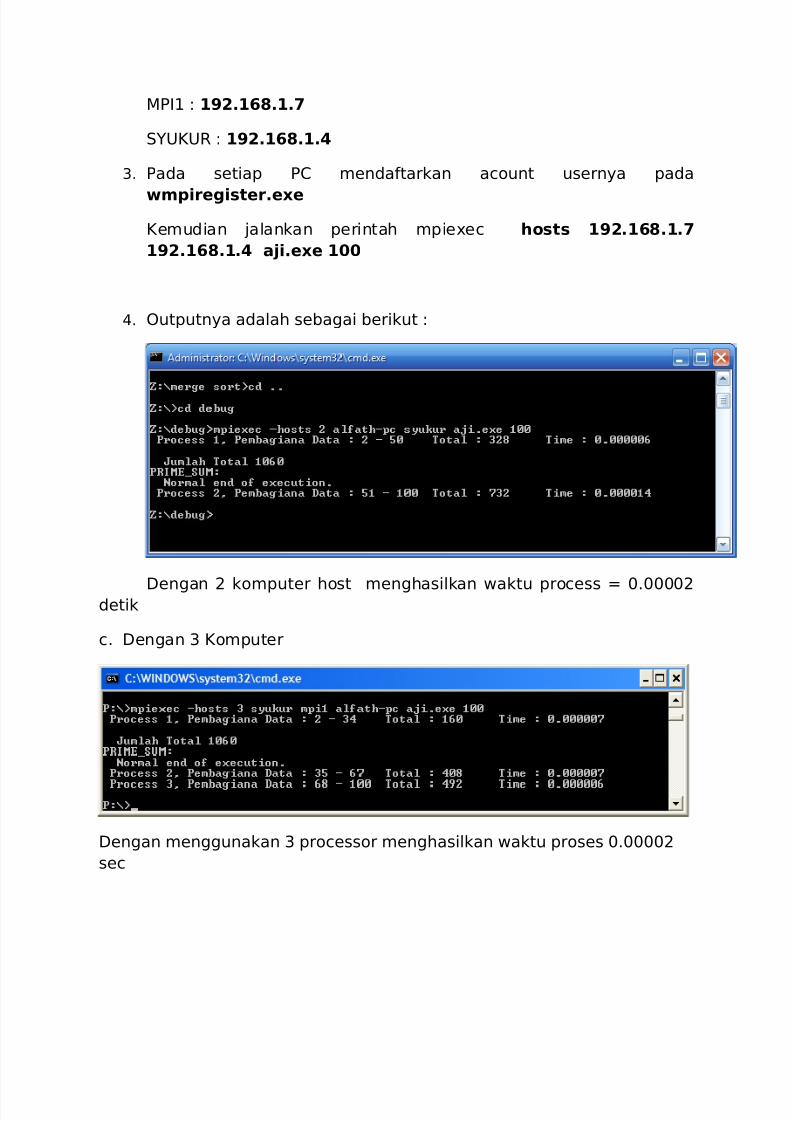
wmpiregister.exe
Kemudian jalankan perintah mpiexec hosts 192.168.1.7
192.168.1.4 aji.exe 100
4. Outputnya adalah sebagai berikut :
Dengan 2 komputer host menghasilkan waktu process = 0.00002detik
c. Dengan 3 Komputer
Dengan menggunakan 3 processor menghasilkan waktu proses 0.00002
sec

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
Simpson Rule
A. Introduction
Merupakan sebuah program yang digunakan untuk menghitung luas
dibawah kurva. Luas dibawah kurva di bagi-bagi kedalam sebuah bentuk
trapesium yang kecil-kecil, berdasarkan nilai x yang dimiliki yang
kemudian dimasukan kedalam fungsi menghasilkan nilai y. Untuk
menghitung trapesium nilai xn, xn+1, yn, yn+1 dimasukkan ke dalam
fungsi ½ ((xn+1)-(xn))*(yn+yn+1)
B. Source Code
Berikut ini adalah Source Code dari Simpson Rule :
/*--------------------------------------------*/
/* Saleh Elmohamed 1996. */
/* [email protected]. */
/* 443-9182 */
/* Example for CPS-615. */
/*--------------------------------------------*/
#include <stdio.h>#include <math.h>
#include <mpi.h>
#define approx_val 2.19328059
#define N 10000000 /* Number of intervals in each processor
*/
double integrate_f(); /* Integral function */
double simpson();
int main(int argc, char *argv[])
{
int Procs; /* Number of processors */
int my_rank; /* Processor number */
double total;
double exact_val_of_Pi, pi, y, processor_output_share[8], x1, x2, l, sum;
int i;
double starttime, endtime;

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
MPI_Status status;
/* Let the system do what it needs to start up MPI */
MPI_Init(&argc, &argv);
/* Get my process rank */
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); /* Find out how many processes are being used. */
MPI_Comm_size(MPI_COMM_WORLD, &Procs);
/* Each processor computes its interval */
x1 = ((double) my_rank)/((double) Procs);
x2 = ((double) (my_rank + 1))/((double) Procs);
/* l is the same for all processes. */
l = 1.0/((double) (2 * N * Procs));
sum = 0.0;
for(i = 1; i < N ; i++)
{
y = x1 + (x2 - x1)*((double) i)/((double) N);
/* call Simpson's rule */
sum = (double) simpson(i, y, l, sum);
}
/* Include the endpoints of the intervals */
sum += (integrate_f(x1) + integrate_f(x2))/2.0;
total = sum;
/* Add up the integrals calculated by each process. */
if (my_rank == 0)
{
starttime = MPI_Wtime();
processor_output_share[0] = total;
/* source = i, tag = 0 */
for(i = 1; i < Procs; i++)
MPI_Recv(&(processor_output_share[i]), 1, MPI_DOUBLE, i, 0,
MPI_COMM_WORLD, &status);
} else
{
/* dest = 0, tag = 0 */
MPI_Send(&total, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
}
/* Add up the value of Pi and print the result. */
if (my_rank == 0)
{
pi = 0.0; for(i = 0; i < Procs; i++)

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
pi += processor_output_share[i];
pi *= 2.0 * l/ 3.0;
printf("-------------------------------------------------\n");
printf("The computed Pi of the integral for %d grid points is
%25.16e \n",(N * Procs), pi);
/* This is directly derived from the integeration of the formula. See
the report. */
#if 1
exact_val_of_Pi = 4.0 * atan(1.0);
#endif
#if 0
exact_val_of_Pi = 4.0 * log(approx_val);
#endif
printf("The error or the discrepancy between exact and computed
value of Pi : %25.16e\n",
fabs(pi - exact_val_of_Pi));
printf("-------------------------------------------------\n");
endtime = MPI_Wtime();
printf("\n\nWaktu mulai %f detik\n",starttime);
printf("\n\nWaktu berhenti %f seconds\n",endtime);
printf("\n\nParellel Time %f seconds\n",endtime-starttime);
}
MPI_Finalize();
}
double integrate_f(double x)
{
return 4.0/(1.0 + x * x); /* compute and return value */
}
double simpson(int i, double y, double l, double sum)
{
/* store result in sum */
sum += integrate_f(y);
sum += 2.0 * integrate_f(y - l);
if (i == (N - 1))
sum += 2.0 * integrate_f(y + l);
return sum; } /* simpson */C. Analisis

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
a. Dengan 1 Komputer
1. Tidak terhubung ke jaringan
2. Hanya melibatkan 1 host dengan IP Adress 192.168.1.7
3. Kemudian jalankan perintah mpiexec -n 1 MPI_simpson.exe
4. Outputnya adalah sebagai berikut :
5. Dengan 1 komputer host menghasilkan waktu process = 0.00016
detik
b. Dengan 2 komputer
1. Arsitektur jaringan yang digunakan adalah peer 2 peer
SYUKUR MPI1
ALFATH-PC

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
2. Hanya melibatkan 3 host dengan IP Adress
SYUKUR : 192.168.1.4
MPI1: 192.168.1.7
ALFATH-PC : 192.168.1.1
3. Pada setiap PC mendaftarkan acount usernya pada
wmpiregister.exe
Kemudian jalankan perintah mpiexec -hosts 192.168.1.1
192.168.1.4 MPI_simpson.exe
4. Outputnya adalah sebagai berikut :
Dengan 2 komputer host menghasilkan waktu paralell = 0.003293
detik
jalankan perintah mpiexec -hosts 192.168.1.7 192.168.1.4
MPI_simpson.exe

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
Dengan 2 komputer host menghasilkan waktu paralell = 0.046842
detik
c. Dengan 3 Komputer
Dengan menggunakan 3 Host Mpi menghasilkan parallel Time
0.220132 detik
Merge Sort
A. Introduction
Merupakan sebuah program yang digunakan untuk mengurutkansejumlah data acak. Mekanismenya adalah membagi data ke dalam
bagian yang kecil. Setiap bagian yang kecil tersebut data diurutkan dan
kemudian di satukan kembali sehingga lebih mudah untuk diurutkan:
B. Source Code
/* menggabungkan 2 array dengan ukuran yang sama */
int *merge(int array1[], int array2[], int size) {
int *result = (int *)malloc(2*size*sizeof (int)); int i=0, j=0, k=0;
while ((i < size) && (j < size)) {
result[k++] = (array1[i] <= array2[j])? array1[i++] : array2[j++];
}
while (i < size) {
result[k++] = array1[i++];
}
while (j < size) {result[k++] = array2[j++];

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
}
return result;
}
/* validasi data terurut */
int sorted(int array[], int size) {
int i;
for (i=1; i<size; i++)
if (array[i-1] > array[i])
return 0;
return 1;
}
/*untuk qsort() */
int compare(const void *p1, const void *p2) {
return *(int *)p1 - *(int *)p2;
}
int main(int argc, char** argv) {
int i, b, nprocs, myrank;
long datasize;
int localsize, *localdata, *otherdata, *data = NULL;
int active = 1;
MPI_Status status;
double start, finish, p, s;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
MPI_Comm_size(MPI_COMM_WORLD, &nprocs);
/* Read datasize argument */datasize = (argc == 2)? atol(argv[1]) : nprocs*10;
/* Check argument */
if (!ISPOWER2(nprocs)) {
if (myrank == ROOT) printf("Jumlah Prosesor haruslah 2.\n");
return MPI_Finalize();
}
if (datasize%nprocs != 0) {
if (myrank == ROOT) printf("Besar data harus dapat dibagi jumlahprosesor.\n");

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
return MPI_Finalize();
}
/* Generate data */
if (myrank == ROOT) {data = (int *)malloc(datasize * sizeof (int));
for (i = 0; i < datasize; i++) {
data[i] = rand()%99 + 1;
}
}
/* paralel proses start */
start = MPI_Wtime();
/* Scatter data */
localsize = datasize / nprocs;
localdata = (int *) malloc(localsize * sizeof (int));
MPI_Scatter(data, localsize, MPI_INT, localdata, localsize, MPI_INT,
ROOT, MPI_COMM_WORLD);
/* Sort localdata */
qsort(localdata, localsize, sizeof (int), compare);
/* Merge sorted data */
for (b=1; b<nprocs; b*=2) {
if (active) {
if ((myrank/b)%2 == 1) {
MPI_Send(localdata, b * localsize, MPI_INT, myrank - b, 1,
MPI_COMM_WORLD);
free(localdata);
active = 0;
} else {
otherdata = (int *) malloc(b * localsize * sizeof (int));MPI_Recv(otherdata, b * localsize, MPI_INT, myrank + b, 1,
MPI_COMM_WORLD, &status);
localdata = merge(localdata, otherdata, b * localsize);
free(otherdata);
}
}
}
/*tahap akhir pemrosesan paralel */finish = MPI_Wtime();

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
/* Analisa kecepatan dan runtime */
if (myrank == ROOT) {
#ifdef DEBUG if (sorted(localdata, nprocs*localsize)) {
printf("\nParallel sorting berhasil.\n\n");
} else {
printf("\nParallel sorting gagal.\n\n");
}
#endif
free(localdata);
p = finish - start;
printf("Waktu Proses Parallel : %.8f\n", p);
/* Sequential sort */
start = MPI_Wtime();
qsort(data, datasize, sizeof (int), compare);
finish = MPI_Wtime();
free(data);
s = finish - start;
printf("Waktu Proses Sequential : %.8f\n", s);
printf("Peningkatan Kecepatan S/P: %.8f\n\n", s/p);
}
return MPI_Finalize();
}
5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
C. Analisis
a. Dengan 1 Komputer
1. Tidak terhubung ke jaringan
2. Hanya melibatkan 1 host dengan IP Adress 192.168.1.7, pc=mpi1
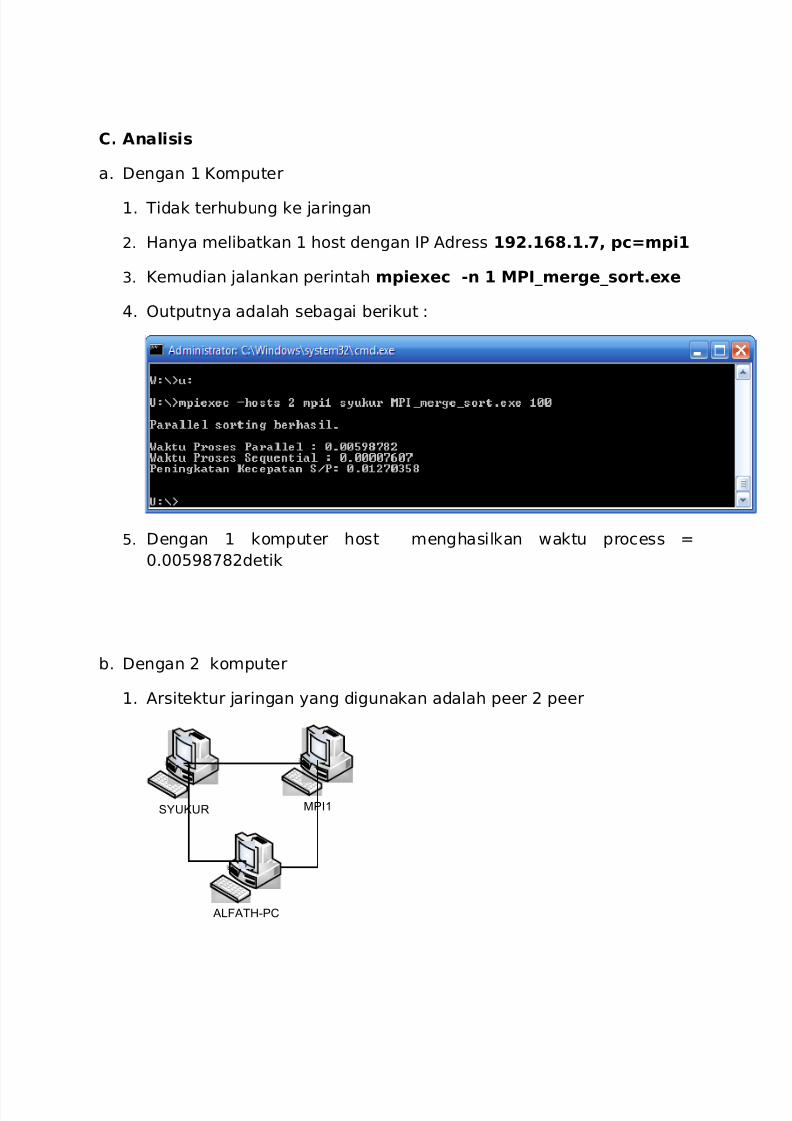
3. Kemudian jalankan perintah mpiexec -n 1 MPI_merge_sort.exe
4. Outputnya adalah sebagai berikut :
5. Dengan 1 komputer host menghasilkan waktu process =
0.00598782detik
b. Dengan 2 komputer
1. Arsitektur jaringan yang digunakan adalah peer 2 peer
SYUKUR MPI1
ALFATH-PC
5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
2. Hanya melibatkan 3 host dengan IP Adress
SYUKUR : 192.168.1.4
MPI1: 192.168.1.7
ALFATH-PC : 192.168.1.1
3. Pada setiap PC mendaftarkan acount usernya pada
wmpiregister.exe
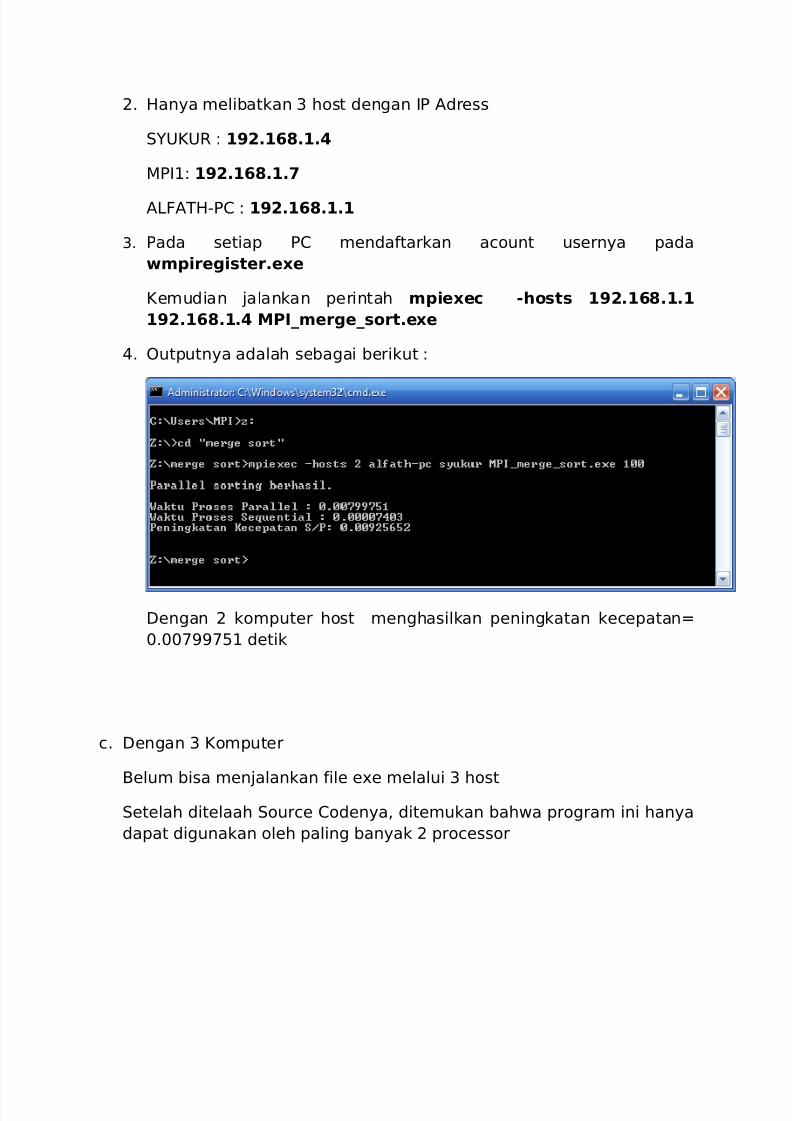
Kemudian jalankan perintah mpiexec -hosts 192.168.1.1
192.168.1.4 MPI_merge_sort.exe
4. Outputnya adalah sebagai berikut :
Dengan 2 komputer host menghasilkan peningkatan kecepatan=
0.00799751 detik
c. Dengan 3 Komputer
Belum bisa menjalankan file exe melalui 3 host
Setelah ditelaah Source Codenya, ditemukan bahwa program ini hanya
dapat digunakan oleh paling banyak 2 processor

5/12/2018 47802574 Mengukur Efektifitas Komputasi Paralel Melalui Implementasi Program Pr...
http://slidepdf.com/reader/full/47802574-mengukur-efektifitas-komputasi-paralel-melalui-implementasi-pr
Kesimpulan
Setelah mengeksekusi 3 program yang berbeda dan dengan teknik
yang berbeda pula, didapat table sebagai berikut:
No
NamaProgram
SatuProcessor
Dua Processor TigaProcessor
1 Prime Sum 0.000012 detik 0.00002 detik 0.00002detik
2 Simpson Rule 0.00013 detik 0.003293 detik 0.220132detik
3 Merge Sort 0.00598782detik
0.00799751 detik -
Dari table tersebut dapat di ambil kesimpulan bahwa semakin banyak
processor yang digunakan akan semakin lama waktu proses yang
dibutuhkan untuk mengeksekusi sebuah program dengan metode
komputasi parallel.
Hal ini mungkin disebabkan karena cakupan data yang kecil sehinggabelum efektif penggunaan komputasi parallel pada program di atas